










Please enter the answer below before you can view the full text.


2025
Volume: 62 Issue 14
46 Article(s)

Haoyang Li, Xie Han, and Tingya Liang
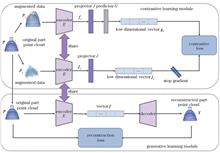
Unsupervised representation learning is a primary method for extracting distinguishable shape information from unlabeled point cloud data. Existing approaches capture global shape features of whole point clouds but often overlook local part-level details and are computationally expensive due to their reliance on whole point clouds and numerous negative samples. Inspired by the human visual mechanism of perceiving whole objects from local shapes, this study proposes an unsupervised part-level learning network, called reconstruction contrastive part (Rc-Part). First, a dataset of 40000 part point clouds is constructed by preprocessing public whole point cloud datasets. Then, Rc-Part employs contrastive learning without negative samples to capture distinguishable semantic information among parts and uses an encoder-decoder architecture to learn part structure information. Joint training with both contrastive and reconstruction tasks is then conducted. Finally, the encoder learned from the point cloud dataset is directly applied to whole-shape classification. Experiments on the PointNet backbone achieve high classification accuracies of 90.2% and 94.0% on the ModelNet40 and ModelNet10 datasets, respectively. Notably, despite containing 10000 fewer samples than the ShapeNet dataset, the part dataset achieves superior classification performance, demonstrating its effectiveness and the feasibility for neural networks to learn global point cloud data from components.
Jul. 25, 2025Vol. 62 Issue 14 1439001 (2025)
Han Han, Xin Wang, Xiankun Pu, Peifeng Pan, Yao Zha, Yajun Xu, and Jun Gao
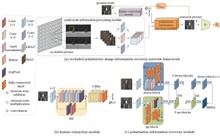
To address the challenges of restoring details in heavily occluded areas and enhancing network generalization capabilities in occluded polarized image reconstruction tasks, the research proposes a novel occluded image reconstruction model, PolarReconGAN, based on multiscale adversarial network. The proposed model integrates with polarization array imaging technology, aims to reconstruct the polarization information of occluded targets, thereby improving image quality and detail representation. We design a multiscale feature extraction module that employs a random window slicing method to prevent information loss due to image resizing, and utilizes data augmentation to enhance model generalization. Additionally, a loss function based on discrete wavelet transform is employed to further improve the reconstruction effects of image details. The experimental results demonstrate that the proposed method achieves an average structural similarity index (SSIM) of 0.7720 and an average peak signal-to-noise ratio (PSNR) of 25.2494 dB on a multi-view occluded polarization image dataset, indicating superior performance in occluded image reconstruction.
Jul. 25, 2025Vol. 62 Issue 14 1439002 (2025)
Xundong Gao, Hui Chen, Yaning Yao, and Chengcheng Zhang
Multimodal image fusion involves the integration of information from different sensors to obtain complementary modal features. Infrared-visible image fusion is a popular topic in multimodal tasks. However, the existing methods face challenges in effectively integrating these different modal features and generating comprehensive feature representations. To address this issue, we propose a dual-branch feature-decomposition (DBDFuse) network. A dual-branch feature extraction structure is introduced, in which the Outlook Attention Transformer (OAT) block is used to extract high-frequency local features, whereas newly designed fold-and-unfold modules in the Stoken Transformer (ST) efficiently capture low-frequency global dependencies. The ST decomposes the original global attention into a product of sparse correlation maps and low-dimensional attention to capture low-frequency global features. Experimental results demonstrate that the DBDFuse network outperforms state-of-the-art (SOTA) methods for infrared-visible image fusion. The fused images exhibit higher clarity and detail retention in visual effects, while also enhancing the complementarity between modalities. In addition, the performance of infrared and visible light fusion images in downstream tasks has been improved, with mean average accuracy of 80.98% in the M3FD object detection task and mean intersection to union ratio of 63.9% in the LLVIP semantic segmentation task.
Jul. 25, 2025Vol. 62 Issue 14 1439003 (2025)
Jiyu Xiao, Yunmeng Liu, Shizhao Li, and Lei Ding
This study proposed an adaptive image dehazing algorithm designed to address the limitations of the traditional dark channel dehazing algorithm, which struggles to adapt to different scenarios. The proposed algorithm first performs brightness and darkness segmentation on the image, followed by an improved method for determining atmospheric light values and transmittance for preliminary dehazing. Next, the processed image is fused with the image preprocessed using limited contrast adaptive histogram equalization and subsequently subjected to gamma correction to obtain the final dehazed image. Experimental validation was conducted using publicly available datasets and images collected from real-life scenarios. The results demonstrate that the proposed algorithm owns an effective dehazing performance, considerably enhancing image quality. Compared with the traditional dark channel dehazing algorithm, the images processed by our algorithm exhibit a 44.1% improvement in peak signal-to-noise ratio, a 32.2% increase in structural similarity, a 2.5% boost in information entropy, a 9.5% enhancement in visible edge normalization gradient mean, and a 33.7% increase in clarity measurement index.
Jul. 25, 2025Vol. 62 Issue 14 1401001 (2025)
Jiali Pan, Zhiguo Fan, and Wenhong Gao
In non-uniform haze scenarios, current dehazing algorithms often lack the ability to dynamically handle the non-uniform distribution of haze concentration, leading to the problem of residual haze that is difficult to effectively resolve. To address this problem, a double iteration separation dehazing algorithm for polarized images under non-uniform concentration is proposed. This algorithm mainly consists of two modules: concentration estimation and optimization of the double iteration separation algorithm. First, the polarization characteristics are used to construct the dynamic haze concentration function in the image. Then, the atmospheric scattering coefficient is obtained on the basis of the haze concentration function, and the atmospheric scattering coefficient is substituted into the double iterative separation algorithm to solve the optimal transmittance. Finally, the image is restored by combining the atmospheric light value at infinity estimated by the polarization difference image. Experimental results show that compared with CAP, BCCR, ZSR, PLE, BSMP, and other dehazing algorithms, the natural image quality evaluation index, fog concentration evaluation index, and mean gradient of the proposed algorithm are increased by 1.26%, 23.78%, and 75.63%, respectively, and the proposed algorithm achieves better dehazing effect for different concentration regions, and the haze residue is further reduced.
Jul. 25, 2025Vol. 62 Issue 14 1401002 (2025)
Ziqian Peng, Zhiyuan Cheng, and Jiahao Hu
A generative adversarial network model based on color correction preprocessing and an attention mechanism is proposed to address the challenges of image degradation and color shift in underwater imaging owing to scattering and absorption. In the preprocessing stage, an unsupervised image color enhancement module (UCM) is implemented to correct the color distortion of underwater images. The UCM is introduced to preprocess and enhance underwater image enhancement benchmark (UIEB) dataset, which effectively mitigates the issue of color shift. Then, in the generating adversarial network architecture, channel and spatial dual attention modules are used for feature attention of the network, thereby optimizing the ability of the image generation network for learning underwater image characteristics. Furthermore, a composite loss function is designed in the generative adversarial network to improve the performance of the generator and discriminator. Finally, enhanced images are obtained through training and testing on the underwater dataset. Compared with traditional underwater image enhancement algorithms, the proposed algorithm demonstrates better visual effects in subjective evaluations. Objective indicators show substantial improvements in the UIEB test set, with the peak signal-to-noise ratio, structural similarity index, and underwater image quality index increasing by 12%, 44%, and 12%, respectively, compared with the best-performing referenced algorithm. Experimental results show that the proposed algorithm can effectively correct color deviations in underwater images and improve image quality.
Jul. 25, 2025Vol. 62 Issue 14 1401003 (2025)
Maoheng Jing, Meishan Zhong, Wenhao Lu, Xiaoxing Wei, Zhiming Wang, Jiajie Huang, Jiguang Zhao, Liang Zhao, and Ming Zhang
To address the issue of noise interference in ultraviolet (UV) images, the denoising method based on Facet filtering and local contrast is proposed to enhance image quality for corona detection. First, Facet filtering with a small kernel is applied to the UV image to enhance target pixels and suppress high-intensity noise. Subsequently, a three-layer sliding window traverses the UV image to calculate the local contrast at three levels, generating a saliency map. Finally, noise is removed through threshold segmentation. Experimental results show that proposed method significantly improves UV image quality by enhancing the distinction between salient regions and background, thereby facilitating corona detection.
Jul. 25, 2025Vol. 62 Issue 14 1437001 (2025)
Shudong Liu, Zeyu Hao, Honghui Wang, Jia Cong, and Boyu Gu
Existing methods for few-shot fine-grained image classification often suffer from feature selection bias, making it difficult to balance local and global information, which hinders the accurate localization of key discriminative regions. To address this issue, a multiscale joint distribution feature fusion metric model is proposed in this paper. First, a multiscale residual network is employed to extract image features, which are then processed by a multiscale joint distribution module. This module computes the Brownian distance covariance between the different scales, thereby integrating both local and global information to enhance the representation of important regions. Finally, an adaptive fusion module with attention mechanism based on global average pooling and Softmax weight normalization is used to dynamically adjust feature contributions and maximize the impact of key region features on the classification results. Experimental results indicate that classification accuracies of 87.22% and 90.65% are achieved on the 5-way 1-shot task of the CUB-200-2011 and Stanford Cars datasets, respectively, demonstrating significant performance in few-shot fine-grained image classification tasks.
Jul. 25, 2025Vol. 62 Issue 14 1437002 (2025)
Ruijie Kuang, Xiang Li, Yu Liu, Bingying Hu, and Xianshun Wang
To address the challenge of balancing model complexity and real-time performance in unmanned aerial vehicle (UAV)-based forest fire smoke detection, this paper proposes a lightweight and efficient multi-scale detection algorithm based on an improved YOLOv8n architecture, named LEM-YOLO (Lightweight Efficient Multi-Scale-You Only Look Once). First, a lightweight multi-scale feature extraction module C2f-IStar (C2f-Inception-style StarBlock) is designed to reduce model complexity while enhancing the representation capability for images of flames and smoke that exhibit drastic scale variations. Second, a multi-scale feature weighted fusion module (EMCFM) is introduced to mitigate the information loss and background interference of densely packed small targets during the feature fusion process. Third, a lightweight shared detail-enhanced convolutional detection head (LSDECD) is constructed using shared detail-enhanced convolutions to reduce computational load and improve the model's ability to capture image details. Finally, the complete intersection over union (CIoU) loss function is replaced by the powerful intersection over union (PIoU) loss function to improve the convergence efficiency in handling non-overlapping bounding boxes. Experimental results indicate that, compared with the baseline model, the improved model achieves increases of 1.9 percentage points and 2.5 percentage points in mean average precision at intersection over union of 0.5 and 0.5 to 0.95, respectively, while reducing model parameters by 31.6% and computational cost by 27.2%, and the processing speed reaches 57.82 frame/s. The improved model achieves an effective balance between lightweight design and detection performance.
Jul. 25, 2025Vol. 62 Issue 14 1437003 (2025)
Fuquan Qin, and Yan Wei
To address the missed detection of small prohibited items in X-ray security inspection images due to low pixel ratios and ambiguous features, this study proposes a detection algorithm based on fine-grained feature enhancement. First, we design a learnable spatial reorganization module that replaces traditional downsampling operations with dynamic pixel allocation strategies to reduce fine-grained feature loss. Second, we construct a dynamic basis vector multi-scale attention module that adaptively adjusts the number of basis vectors according to feature entropy, enabling cross-dimensional feature interaction. Finally, we introduce a 160×160 high-resolution detection head that reduces the minimum detectable target size from 8 pixel×8 pixel to 4 pixel×4 pixel. Experimental results demonstrate that on the SIXray, OPIXray, and PIDray datasets, our algorithm achieves mean Average Precision (mAP) values of 93.3%, 91.2%, and 86.9%, respectively, showing improvements of 1.2%?3.1% over the YOLOv8 baseline model while only increasing the parameter count by 0.2×106.
Jul. 25, 2025Vol. 62 Issue 14 1437004 (2025)
Jun Li, Zhongrui Tao, Jin Liu, Fuxing Xu, Chengliang Gou, Xiaowei Xu, Dawei Zhang, and Haima Yang
Traditional optical pattern recognition methods encounter challenges in recognition accuracy and computational efficiency under the influence of atmospheric turbulence. However, deep learning methods, particularly convolutional neural networks and Swin Transformers, have gradually become effective tools for pattern recognition owing to their robust feature extraction and modeling capabilities. This study aims to improve the accuracy of multi-mode vortex optical pattern recognition under the influence of strong turbulence by developing a moving window multi-head self-attention mechanism and combining the global modeling advantage of Swin Transformers with the local feature extraction ability of a convolutional neural network. Experimental results demonstrate that the proposed model exhibits excellent performance under different transmission distances and turbulent conditions, particularly in a strong turbulent environment. At transmission distances of 1000, 1500, and 2000 m, the accuracy rates reach 99.87%, 98.50%, and 90.59%, respectively. Compared with the existing ResNet50 and EfficientNet-B0 methods, the proposed model exhibits considerable accuracy improvement under moderate and strong turbulence conditions, indicating its potential application in the field of vortex optical communication.
Jul. 25, 2025Vol. 62 Issue 14 1406001 (2025)
Zixin Gao, Yongan Zhang, Pei Liu, Wenbin Bi, Ruijin Fu, and Yaping Zhang
This study proposes a digital holographic autofocusing method employing the gray-level co-occurrence matrix (GLCM) and Lanczos interpolation. Key limitations in conventional autofocus methods, such as low clarity of focusing curves, low sensitivity near the focal point, and long computation time, are addressed. The proposed method leverages the GLCM of the reconstructed amplitude and Lanczos interpolation to compute contrast for digital holography autofocusing. Numerical and experimental simulations of resolution plate and experimental focusing results on gastric wall section cells confirm that the proposed method significantly outperforms conventional approaches. Specifically, compared with existing four typical methods, the proposed method maintains equivalent focusing accuracy while achieving an average 78-fold increase in focus curve clarity and an average 41-fold increase in sensitivity. Furthermore, compared with the existing two typical methods, it achieves an approximately 27.8% reduction in computation time.
Jul. 25, 2025Vol. 62 Issue 14 1409001 (2025)
Lingwei Gao, Zhenping Xia, Yujie Liu, Qishuai Han, and Fuyuan Hu
With the rapid advancement of the metaverse across various domains, the demand for immersive experiences in human-computer interactions continues to grow in virtual reality. Achieving realistic and distortion-free visual perception in virtual reality environments has become a critical research focus. This study addresses the mismatch between the field of view of the human eye and spatial acquisition range by constructing a virtual spatial distortion model and designing an immersive perception experiment with six distortion levels. Subjective immersion experiences are recorded using the presence questionnaire, whereas objective electroencephalogram signals are collected via portable electroencephalogram devices to assess neural responses related to immersion. The analysis of subjective and objective data reveals a highly significant effect of virtual spatial distortion on immersion levels (p<0.001), with greater distortion leading to a decline in immersion. A polynomial regression-based immersion prediction model related to virtual space distortion is developed, achieving a coefficient of determination of 0.6167. The findings of this study provide valuable insights and practical guidelines for the interactive design and perception of immersive virtual environments in the metaverse.
Jul. 25, 2025Vol. 62 Issue 14 1411001 (2025)
Quan Liu, Ying Jin, Quanying Wu, Weixuan Yi, Haofan Wang, and Guohai Situ
To improve the imaging quality of long-distance turbid underwater off-axis holographic imaging under the background of sparse ballistic photons and strong scattered light, this study proposes an underwater scattering imaging method based on off-axis digital holography. This method combines a spatial filtering device and the free regulation of a reference light intensity. A 4F filtering system can effectively filter out numerous scattered photons generated in the reflection process, thus significantly reducing the scattering noise, as well as improve the coherence of ballistic photons and optimize the imaging effect. Compared with the direct-imaging effect, the imaging distance of underwater scattering imaging with the 4F filtering system increases by 45.31% (attenuation length increases from 6.4 to 9.3). Additionally, by finely adjusting the intensity of the reference light, the effect of coherent noise can be reduced, while the image contrast and the accuracy of the reconstructed image can be improved. The structural similarity index measure (SSIM) of the reconstructed image generally increases by 0.05 to 0.13, and the peak signal-to-noise ratio (PSNR) generally increases by 0.5 dB to 2.4 dB. The proposed underwater scattering imaging method based on off-axis digital holography can increase the maximum imaging distance to 10.3. The SSIM value of the object reconstruction image is 0.175, the PSNR is 4.65 dB, and the RMSE is 164.23. After denoising by the neural network, the best imaging results are as follows: SSIM = 0.377, PSNR = 7.68 dB, and RMSE = 112.74. The proposed method provides an effective technique for long-distance turbid underwater scattering imaging.
Jul. 25, 2025Vol. 62 Issue 14 1411002 (2025)
Lei Zhong, Li Liu, Jinxiang Du, Honggang Gu, and Shiyuan Liu
Ptychography achieves large field-of-view, high-resolution imaging by leveraging relative movement between the illumination probe and the sample under test. However, its imaging resolution is highly dependent on the positioning accuracy of the motion stage. To address this limitation, we propose a scanning position error correction method for ptychographic imaging based on parallel cross-correlation. By constructing a virtual probe matrix, the method calculates the cross-correlation peaks among the actual probe before and after updating, as well as the virtual probe, in parallel. Additionally, a dynamic weighting function optimization is employed to achieve efficient and robust correction of scanning position errors. This approach significantly enhances the efficiency of actual probe correction while eliminating the need for complex parameter tuning or high upsampling rates. It effectively prevents oscillations and crosstalk during the convergence process and avoids local optima traps. Results demonstrate that the method achieves an accuracy of 0.005 pixel within 100 iterations. Compared to simulated annealing, particle swarm optimization, and serial cross-correlation position calibration methods, it improves convergence speed by 10×, 4×, and 3×, respectively, while boosting calibration accuracy by 20×, 10×, and 6×. These advancements pave the way for extending position error calibration to applications in Fourier ptychographic imaging and tomography.
Jul. 25, 2025Vol. 62 Issue 14 1411003 (2025)
Longtao Tian, Hang Wang, Penghui Bu, and Yatao Yan
To address the difficulty of the conventional binocular-stereo-matching algorithm in effectively solving the ambiguity of weak-texture-region matching, a matching cost aggregation-diffusion method based on region division is proposed. First, the texture features of the left and right images, which are classified into rich- and weak-texture regions, are analyzed. Subsequently, a boundary-preserving filtering algorithm is used to aggregate the matching costs. Finally, the matching costs of pixels in the rich-texture regions are diffused to the weak-texture regions based on the local-texture similarity to improve the accuracy of pixel stereo matching in the weak-texture regions. Test results based on datasets from the Middlebury website show that, after introducing the proposed method, the false match rate of non-occluded regions in the test image of the 2001 and 2003 datasets reduced by 1.01 percentage points on average, whereas the false match rate of the entire image reduced by 1.10 percentage points on average. In the test images of the 2005 and 2006 datasets, the false match rate of the non-occluded area reduced by 1.87 percentage points on average, whereas the false match rate of the entire image reduced by 1.87 percentage points on average. In the test images of the 2014 dataset, the false match rate of the non-occluded area reduced by 1.30 percentage points on average, whereas the false match rate of the entire image reduced by 1.31 percentage points on average. These results show that the proposed method can effectively improve the accuracy of stereo matching.
Jul. 25, 2025Vol. 62 Issue 14 1412001 (2025)
Zhaoyu Qin, Jin Han, Guangyu Yuan, Qingxiang Hu, Xiaoxing Zhang, and Wenhua Wu
To address the issue of insufficient temperature measurement accuracy caused by multiple environmental factors when using infrared thermal imager to monitor abnormal temperature rises in composite insulators, this study proposes a dynamic compensation method that combines a radio frequency identification (RFID) temperature measurement system and infrared thermal imager. This method utilizes the precise temperatures obtained in real-time through the RFID system as calibration values. Environmental parameters such as temperature, humidity, and distance are integrated, and a backpropagation neural network is incorporated to dynamically compensate for infrared measurement results, thereby achieving precise monitoring of the global temperature distribution of composite insulators. Experimental results demonstrate that the model achieves high accuracy, with a coefficient of determination of 0.99964, mean absolute error of 0.10951 ℃, and root-mean-square error of 0.15866 ℃. After temperature compensation using the proposed model, the mean relative error of infrared temperature measurements decreases from 9.62% to 0.41%, and temperature measurement accuracy improves from ±2.26 ℃ to ±0.10 ℃, indicating excellent compensation performance. This study effectively addresses the accuracy limitations of infrared temperature measurement technology, providing more reliable technical support for the condition monitoring and fault diagnosis of composite insulators.
Jul. 25, 2025Vol. 62 Issue 14 1412002 (2025)
Lei Liu, Wei Liu, and Xusheng Zhu
Due to the nonlinear motion of the scanning platform in the actual measurement system, the random scanning error is introduced, which leads to the limitation of absolute precision and measurement repeatability. In this study, a random scanning error suppression method is proposed to solve this problem. The principle of mutual calibration of the second-order slope of the theoretical modulation curves and the second-order slope of the actual modulation curves of the grating fringe is used to achieve the accurate determination of the scanning step. The feasibility and progressiveness of this method are proved by theoretical derivation, simulation and experimental verification, which demonstrates that the measurement repeatability standard deviation is better than 1 nm in simulation results, the absolute precision is better than 3 nm and the measurement repeatability standard deviation is better than 2 nm in experiments.
Jul. 25, 2025Vol. 62 Issue 14 1412003 (2025)
Zengyu Tian, Changku Sun, Yue Li, Luhua Fu, and Peng Wang
To address the challenges of low-depth estimation accuracy, blurred object contours, and detail loss caused by occlusion and lighting variations in complex indoor scenes, we propose an indoor monocular depth estimation algorithm based on global-local feature fusion. First, a hierarchical Transformer structure is incorporated into the decoder to enhance global feature extraction, while a simplified pyramid pooling module further enriches feature representation. Second, a gated adaptive aggregation module is introduced in the decoder to optimize feature fusion during upsampling by effectively integrating global and local information. Finally, a multi-kernel convolution module is applied at the end of the decoder to refine local details. Experimental results on the NYU Depth V2 indoor scene dataset demonstrate that the proposed algorithm significantly improves depth prediction accuracy, achieving a root mean square error of only 0.361. The generated depth maps exhibit enhanced continuity and detail representation.
Jul. 25, 2025Vol. 62 Issue 14 1412004 (2025)
Longfei Zhao, Mengwei Tao, Changshi Xiao, Yubin Guo, and Menghao Yang
This study proposes a visual-guided total station automatic measurement method to address the issues of insufficient accuracy, safety hazards, and low efficiency of manual total station measurement methods employed in large-scale scenarios. A connection device between a high-precision camera and a total station eyepiece is developed to obtain images of the total station telescope. A visual identifier with an ArUco QR code embedded in a concentric ring is designed to replace the traditional prism. Further, a sub-pixel center-positioning method is employed to achieve precise target positioning. Using two guiding strategies of angle pixel coefficient and angle variation, the total station is automatically aligned with the target and achieve automatic measurement. Experimental results based on the Leica TM50I total station demonstrate that for a visual identifier with a 16-cm radius, the average error is within 5 and 10 mm when automatically measured within 70 and 110 m, respectively. The proposed method exhibits high accuracy, with a single point measurement time of 13.39 s and an efficiency twice that of manual measurement. Thus, it satisfies the requirements of precision measurement in large-scale scenarios.
Jul. 25, 2025Vol. 62 Issue 14 1412005 (2025)
Qi Chen, Kangnian Wang, Zhiqiang Jiao, and Zhanhua Huang
Existing point cloud semantic segmentation methods based on Transformer model typically rely on an encoder-decoder structure with same-level skip connections. However, this structure often leads to difficulties in effectively fusing encoder features and decoder features during the feature aggregation process, and results in the loss of details during sampling. To address these issues, this study proposes an improved version of the Point Transformer v2 model based on full-scale skip connections and channel attention mechanisms. First, full-scale skip connections are utilized to effectively fuse shallow and same-level encoder features with previous decoder features, providing the decoder with rich, multi-scale information. This enhances the model's ability to perceive complex scenes and results in finer segmentation. Then, channel attention mechanism is employed to adaptively adjust the model's attention to the features of each channel in the feature sequence, further improving segmentation accuracy. Finally, the simple linear layer in the improved group vector attention mechanism is used as the weight coding layer, which significantly reduces the number of parameters in the model. Experimental results show that the proposed model achieves excellent segmentation results on the S3DIS, with a mean intersection over union (mIoU) of 71.5%, a 1.9 percentage points improvement over Point Transformer v2. Meanwhile, the model's parameter count is reduced by 14.16% compared to Point Transformer v2. The experimental results demonstrate that the proposed model offers superior segmentation performance and higher parameter efficiency.
Jul. 25, 2025Vol. 62 Issue 14 1415001 (2025)
Baoyu Wang, Hantang Li, Xiyong Chen, and Wei Yao
To address the limitations of conventional target-detection algorithms in accurately handling multi-scale targets, this paper proposes an improved algorithm based on the YOLOv8 network. The capability of the model to extract multi-scale features is enhanced by incorporating an adaptive feature pyramid network (AFPN), enabling better adaptability and robustness in identifying targets of varying sizes. The incorporation of data augmentation techniques and optimized training strategies further improves the generalization capability of the model. Experiments performed on multiple public datasets demonstrate that the proposed algorithm significantly outperforms faster region-based convolutional neural network (Faster R-CNN), RetinaNet, and the original YOLOv8 architecture in terms of detection accuracy. Furthermore, experiments on a self-made mango dataset demonstrate the outstanding performance of the proposed method in recognizing multi-scale targets. The proposed algorithm not only affords insights into optimizing object-detection algorithms but also provides an effective reference for multi-scale target-detection tasks in agriculture and other fields.
Jul. 25, 2025Vol. 62 Issue 14 1415002 (2025)
Kai Zhong, Ying Chen, Chengzhi Yan, and Han Gao
Most existing three-dimensional (3D) object detection methods are prone to missing distant targets and exhibit poor detection accuracy for small object categories. Hence, this paper proposes a 3D object detection algorithm based on a graph neural network and dynamic sampling. In the candidate box generation phase, a graph feature enhancement module strengthens the semantic information among pillar features to generate high-quality pseudo-images. In the key point sampling phase, a dynamic sampling strategy is designed to not only improve sampling efficiency but also increase the proportion of foreground points. Additionally, a dynamic farthest voxel sampling method ensures the uniform distribution of key points. In the candidate box refinement stage, a multi-scale graph pooling module extracts rich local features. Finally, an adaptive module integrates local information with key point data to enhance feature representation. Experimental results based on the KITTI dataset demonstrate that the proposed algorithm achieves mean average precision (mAP) scores of 56.08% for pedestrians and 77.65% for cyclists, representing improvements of 12.29 and 10.04 percentage points, respectively, over those of the baseline PointPillars algorithm. Moreover, the proposed algorithm exhibits higher precision in detecting distant targets, thus validating its effectiveness in both long-range target detection and small object category detection.
Jul. 25, 2025Vol. 62 Issue 14 1415003 (2025)
Shuangfei Yu, Wei Zhuo, Baohua Wang, and Zhi Yang
In the welding process, a sensor system for real-time detection is difficult to realize. To address this problem, a robust identification algorithm of weld feature points based on kernel correlation filter tracking is proposed. First, based on the traditional kernel correlation filtering theory, an occlusion discrimination mechanism is added, and the learning rate of the model is dynamically adjusted to avoid introducing welding noise. Subsequently, the accuracy of the kernel correlation filter is further improved, and the sub-pixel accuracy alignment method is proposed, enabling target positioning accuracy at the sub-pixel level. Comparative experimental results show that the performance of the improved recognition algorithm is greatly improved, demonstrating superiority over 11 common visual identification algorithms. For 1.1-million-pixel images, the average positioning error of the proposed algorithm is only 2.36 pixels, and the operation speed reaches 40 frame/s, which fully meets the needs of real-time weld detection. Practical welding experiments further prove the effectiveness of the proposed algorithm.
Jul. 25, 2025Vol. 62 Issue 14 1415004 (2025)
Qixiang Meng, Jingtao Wang, Zhilin Gao, Qiqi Kou, and Fanliang Bu
Currently, object detection and recognition technologies are rapidly developing. Criminal activities in public places are becoming increasingly diverse, and they pose significant risks and challenges to social governance. We design a YOLOv10-EN detection network to satisfy practical application requirements for public security. In the BackBone and Neck networks of the model, a multiscale convolution module MSConv is designed to capture the spatial features of multiple scales in various receptive fields, thus enhancing the adaptability of the model to the targets. In the output PSA module of the BackBone network, a coordinate attention mechanism is introduced to aggregate the horizontal and vertical feature information via one-dimensional global pooling, capture long-distance dependencies, enhance global semantic information, and form a direction-aware global representation. Simultaneously, the coordinate attention mechanism preserves the positional information of the pooling operation results on the representation direction vector for feature encoding, thus achieving precise target modeling, improving the localization precision, and reducing the model size and computational cost. In the Bottleneck of the C2f module, residual connection and multiscale convolution mechanism are introduced. The jump structure of residual connection is employed to optimize the information flow transmission, alleviate gradient vanishing and explosion, and achieve efficient feature fusion. The multiscale convolution mechanism is used to capture different receptive field feature information to futher enhance the multiscale adaptation and feature expression of the network. During model training, the EIOU loss function is introduced to improve the precision and convergence speed of the bounding box regression. The experimental results show that the YOLOv10-EN detection network achieves varying degrees of improvement in terms of four key metrics: the F1 score, mAP@0.5, model parameter size, and FLOPs. Compared with the YOLOv10n baseline model, the F1 score and mAP@0.5 of the proposed model increase by 6.25% and 6.46%, respectively, whereas the model parameter size and computational complexity decrease by 20.45% and 22.97%, respectively. The experimental results show that the YOLOv10-EN network achieves a more precise detection while being lightweight, thus meeting the need for portable deployment on edge mobile devices.
Jul. 25, 2025Vol. 62 Issue 14 1415005 (2025)
Shuang Zhang, Boao Wang, Guokai Zhu, Wei Zhang, Dongyu Sun, and Wei Liu
A new point cloud plane fitting method based on an optimized random sampling consensus (RANSAC) algorithm is proposed to improve the flatness detection accuracy of the inner side for high-speed railway wheel pair. In this study, RANSAC algorithm is optimized, and the improved optimization sparrow algorithm (SSA) is adopted. Combined with adaptive inertia weight adjustment, position update, mutation operation, and dynamic randomness reduction, the robustness and accuracy of plane fitting are enhanced. By introducing different noise ratios into the point cloud data and comparing with traditional plane fitting methods, experimental results show that for the plane fitting of the inner side of the wheel pair with 50% noise points addition, when compared with RANSAC and SSA-RANSAC algorithms, the flatness detection accuracy is improved by 93.97% and 57.58%, respectively. Furthermore, the standard deviation is reduced by 4.55% and 28.81%, respectively. These experimental results show that the optimized RANSAC algorithm can significantly improve the fitting accuracy and provide a new and reliable method for high-speed railway wheel pair flatness detection.
Jul. 25, 2025Vol. 62 Issue 14 1415006 (2025)
Zhijun Gao, Kexun Li, and Zhenbo Li
To address the problems of high computational complexity, poor real-time performance, and misdetection and omission detection in the detection of small targets in unmanned aerial vehicle (UAV) aerial images by existing algorithms, an improved YOLOv8-based algorithm, named DySC-YOLOv8, is proposed for pollutant detection on building fa?ades. The proposed algorithm introduces a dynamic upsampler (DySample) and a spatial context-aware attention mechanism (SCAM). First, the DySample module replaces the conventional dynamic convolution with point sampling, which adaptively distributes the sampling points based on the image features and fine-tunes the distribution of the sampling points based on the dynamic range factor, thus effectively reducing the amount of model computation and improving real-time detection. Second, the SCAM module enhances the global information extraction capability, which allows the model to better integrate contextual information and further enhances the retention of key point information. Consequently, the accuracy of recognizing small targets in complex backgrounds as well as the perception of important features are enhanced. Finally, the SIoU loss function is used to reduce misjudgments when the prediction frame differs slightly from the actual target frame. Experimental results show that compared with the baseline model, the proposed algorithm improves the accuracy of the self-made dataset by 6.1 percentage points, while the parameters and floating-point operations are reduced by 9.97% and 9.88%, respectively. Meanwhile, validation experiments on the UAV-DT and DIOR datasets confirmed the good generalization and effectiveness of the proposed algorithm, thus demonstrating its usefulness for engineering applications.
Jul. 25, 2025Vol. 62 Issue 14 1415007 (2025)
Xiuqing Shen, Mingling Luo, Meng Jia, Lei Lü, and Shiqian Wu
In the process of 3D reconstruction of structured light, the local specular reflection of highly reflective objects can easily lead to overexposure in the camera, resulting in the loss of detailed features in the overexposed regions. To address this issue, this study proposes a 3D reconstruction method of high reflective object surface based on transmissive liquid crystal display (LCD). Specifically, a transmissive LCD is introduced between the complementary metal oxide semiconductor (CMOS) sensor and the camera lens. It is theoretically proved that the addition of LCD has no effect on the phase unwrapping results, and a calibration algorithm for LCD pixels and CMOS pixels is proposed to achieve pixel-level control of incident light intensity. The effect estimation model of the mismatch between LCD pixels and CMOS pixels is established and the system error is analyzed. The experimental results show that the method effectively regulates the intensity of the incident light in the highly reflective region. The dynamic range of the imaging system increases from 48.13 dB to 68.95 dB. The spherical fitting error of the standard sphere is 0.072 mm, the radius error is -0.0069 mm, and the flat fitting error of the standard plate is 0.063 mm. The proposed method achieves clear imaging of localized overexposed regions on the surface of the object, and the problem of missing 3D point cloud caused by local overexposure is significantly improved.
Jul. 25, 2025Vol. 62 Issue 14 1415008 (2025)
Hailiang Wang, and Nan Ye
In the robot-assisted automatic assembly of the electrical control devices on the fuselage segment, precise positioning and alignment of multiple through-holes and threaded holes on the top and bottom covers of the control casing are required. The holes-holes alignment issue cannot be effectively addressed using force control assistance, and due to the limited space within the fuselage segment, visual cooperation targets cannot be utilized for holes-holes positioning. To solve this problem, this study proposes a monocular vision-based technique for spatial positioning of threaded holes and multi-hole alignment, innovatively transformed the multi-hole alignment problem into a multi-point and multi-line registration problem. First, a systematic calibration of the vision system is conducted to establish the transformation relationship between the camera coordinate system and the through-hole coordinate system of the top cover. Then, an elliptical center extraction algorithm based on adjacent arc segment combination is employed to effectively eliminate strong image noise interference near threaded holes. Finally, based on the geometry of visual imaging, a ray equation passing through the elliptical center in the camera coordinate system is constructed. Furthermore, a virtual multi-view geometric model is established using the robotic arm's pose, transforming the multi-hole alignment problem into an optimization solution for registering multiple rays passing through multiple points. On this basis, a multi-line to single-point registration strategy is proposed to achieve a more precise and stable pose relationship. Leveraging the hand-eye relationship, both the top and bottom cover coordinate systems are transformed to the robotic arm's end-effector frame to obtain the pose deviation, thus guiding the robotic arm to achieve multi-hole alignment of the top and bottom covers. The effectiveness of the method in this study is verified through repeated experiments. The alignment of 4 through-holes with diameter of 9 mm and threaded holes with inner diameter of 8 mm is realized on the sample parts. The maximum distance between the centers of the two holes is 0.361 mm, and the minimum distance is 0.111 mm, which meets the alignment accuracy requirement of 0.500 mm for bolts to be screwed in.
Jul. 25, 2025Vol. 62 Issue 14 1415009 (2025)
Jianxing Liu, and Gongquan Li
In the task of point cloud instance segmentation, there are data redundancy problems caused by insufficient local feature extraction and post-processing operations. In order to achieve efficient and accurate point cloud instance segmentation, this study proposes a point cloud instance segmentation network based on local perception and channel similarity (LCISNet). The local perception module extracts structural information from domain points of the center point as local features by employing the K-nearest neighbor algorithm relative to the center point. It then performs feature fusion with the center point features to enhance the understanding of local characteristics. Additionally, sphere query is utilized in the clustering stage to aggregate local features. By calculating similarity features between channels, effective channel features are enhanced and feature redundancy is minimized, thereby improving segmentation precision and reducing unnecessary computations. Experimental results demonstrate that the proposed algorithm achieves superior segmentation performance on both the outdoor STPLS3D dataset and the indoor S3DIS dataset. The average intersection-over-union (IoU) precision on the STPLS3D dataset reaches 65.0%, which is a 29.7-percentage-point improvement over 3D-BoNet. On the S3DIS dataset, the average IoU precision reaches 71.0%, representing a 7.0-percentage-point improvement over 3D-BoNet. These results confirm that the proposed method exhibits excellent instance segmentation performance and strong generalization capabilities.
Jul. 25, 2025Vol. 62 Issue 14 1415010 (2025)
Muyan Chen, Jishuai Wang, Lei Wang, Qiang Zhang, Wenchang Xu, and Wenbo Cheng
In the process of multi-focus cell image sequence acquisition, the fluidity of the medium causes the same cell to change position in different image frames, and obvious morphological differences exist between the defocused and focused cells. Therefore, the cell image sequence cannot meet the requirements of the existing multi-focus image fusion algorithm for ensuring spatial consistency of image content. To this end, this paper proposes a multi-focus cell image fusion method based on target recognition. After locking all cells in the image sequence through the improved YOLOv10 target recognition model, target tracking is performed to correlate multiple frames of cells and their motion trajectories are confirmed. After evaluating the clarity of the associated cells, the cells with the highest clarity are selected for image segmentation, extraction, and fusion to obtain the final full-focus clear image. The proposed method and seven multi-focus image fusion algorithms are applied to multi-focus cell image fusion and the results are compared and analyzed. The peak signal-to-noise ratio of the proposed method increases by 3.9993 dB on average, and the structural similarity index is above 0.9741. The fused image retains the entire content, accurate details, and high definition, realizing high-quality fusion of multi-focus cell microscopic images.
Jul. 25, 2025Vol. 62 Issue 14 1417001 (2025)
Zhongan Huang, Xinyu Li, Qiaohong Liu, min Lin, and Huayuan Yang
The integration of the Kolmogorov-Arnold network (KAN) structure into the traditional U-Net yields the U-KAN model, which demonstrates exceptional nonlinear modeling capability and interpretability in medical image segmentation tasks. To address the limitations of the U-KAN model, such as inadequate global feature capture, poor recognition of complex edges, and limited multiscale feature fusion, this study proposes a novel segmentation network, The proposed model combines a pyramid vision Transformer (PVT) with U-KAN and is referred to as PVT-KANet. While preserving the interpretability of the KAN structure, PVT-KANet overcomes the aforementioned challenges through three key innovations. First, the PVTv2 module is incorporated into the encoder to enhance the global modeling ability of lesion features at different scales. This module effectively improves the perception of complex lesion areas by leveraging a pyramid structure and a self-attention mechanism. Second, a multiscale convolutional attention Tok-KAN module is introduced, integrating a multiscale convolutional attention mechanism with the KAN structure. This module substantially enhances the ability to recognize fuzzy boundaries and fine details. Third, the inception deep convolution decoding module is employed to achieve adaptive multiscale feature fusion, thereby improving the accuracy of segmentation results. On the CVC-ClinicDB polyp dataset, the proposed model achieves a 4.66 percentage-point improvement in terms of the intersection over union compared to U-KAN. Further, the model outperforms existing models on the BUSI breast ultrasound and GlaS glandular tissue datasets. Thus, both experimental results and theoretical analysis confirm the substantial advantages of PVT-KANet in enhancing the accuracy and facilitating the generalization of medical image segmentation.
Jul. 25, 2025Vol. 62 Issue 14 1417002 (2025)
Lu Zhang, Pengju Liu, and Shigang Liu
Low-dose computed tomography (CT) imaging reduces radiation dose, but the associated artifacts and noise can compromise diagnostic accuracy. This study proposes a method for denoising low-dose CT images, based on a convolutional neural network and the dual-tree complex wavelet transform (LDTNet). The method exploits the robust information extraction capabilities of convolutional neural networks in the spatial domain and integrates the multi-scale decomposition characteristics of the dual-tree complex wavelet transform in the frequency domain to mitigate information loss typically encountered in conventional single-domain denoising approaches. In addition, the method features a large receptive field, thereby facilitating the capture of subtle structures and edge information. Consequently, the denoising process is further refined. Validation on the AAPM dataset demonstrates that LDTNet achieves significant improvements in both peak signal-to-noise ratio and structural similarity metrics, while visual assessments further confirm its superior performance in noise suppression and image detail restoration.
Jul. 25, 2025Vol. 62 Issue 14 1417003 (2025)
Chaoyun Mai, Qianwen Wang, Runqiang Yuan, Zhipeng Mai, Chuanbo Qin, Junying Zeng, Weigang Yan, and Yu Xiao
Currently, weakly supervised multi-instance learning (MIL) is widely used in computational pathology to analyze whole-slide images (WSI). However, the existing methods typically rely on convolutional neural networks or transformer models, which incur heavy computational costs and often struggle to effectively capture the contextual dependencies between different instances. To address this problem, this study proposes a state-space enhanced multi-instance learning (SKAN-MIL) method for conducting Gleason grading of prostate cancer pathological images. Specifically, this study introduces a state-space-based multi-path Mamba (MP-Mamba) module to establish relationships between sample features and incorporates Kolmogorov-Arnold networks (KAN) to further enhance the model's ability for nonlinear modeling and improve interpretability. The experimental results on the prostate cancer dataset from the Chinese Academy of Medical Sciences, Peking Union Medical College Hospital (PUMCH), and the publicly available dataset PANDA show that SKAN-MIL achieves the accuracy of 84.14% and the average area under curve(AUC) of 91.38% on the PUMCH and the accuracy of 63.92% and the average AUC of 89.50% on the PANDA. These results suggest that this method outperforms other methods, demonstrating the potential of SKAN-MIL for the clinical diagnosis of prostate cancer.
Jul. 25, 2025Vol. 62 Issue 14 1417004 (2025)
Jiejun Cao, Yan Gong, Quanying Wu, and Song Lang
Based on the large field of view, low aberration, and high sensitivity advantages of insect compound eye, a large field of view multi-aperture bionic compound eye optical system is proposed to address the shortcomings of traditional two-dimensional imaging technology in terms of field of view range and sensitivity to small target motion. The system comprises a curved sub-eye array, relay system, and image detector. The single sub-eye field of view of the system is 30°, and focal length is 24 mm. The relay system uses a fish-eye lens with an F-number of 3 and two aspheric surfaces to convert curved surface and plane images. The field of view of the total system is 160°, and the F-number is 3. In design results, the modulation transfer function of all sub-eye channels is greater than 0.3 at 156 lp/mm, and the system still satisfies the imaging requirements within a given tolerance range. Compared with the existing compound eye imaging system, the optical system designed in this study has a larger field of view and a smaller number of aspheric surfaces, which reduces the cost and improves process feasibility.
Jul. 25, 2025Vol. 62 Issue 14 1422001 (2025)
Zhaoyong Wang, Zhiqing Zhang, Yiqin Xu, Zhiliang Gu, Zhongrui Qu, and Hongzhan Liu
To alleviate the visual accommodation-convergence conflict and discomfort caused by conventional single-focus plane head-mounted displays while considering factors such as system volume, structural complexity, and cost, this study proposes a polarization multiplexed dual focal head-mounted display optical system based on the single-image generation unit. The system uses the twisted nematic liquid crystal unit and the polarization reflection film to achieve dual focal display. It features an exit pupil diameter of 8 mm, an exit pupil distance of 18 mm, and field-of-view angles of 24.0°×7.5° and 15.4°×4.8°, with the corresponding maximum distortions of -2.57% and 1.71%, respectively. Meanwhile, the focal lengths are 25.8 mm and 41.0 mm. Additionally, this study analyzes stray light in the system and proposes effective suppression measures. The research results indicate that the performance of the dual focal head-mounted display system satisfies the requirements for practical applications.
Jul. 25, 2025Vol. 62 Issue 14 1422002 (2025)
Gang Li, Liang Zhang, Ke Liu, Lu Gao, and Shitao Xiang
Segmenting roof planes from airborne LiDAR point cloud data is essential for three-dimensional (3D) building reconstruction. However, the presence of discrete point clouds and complex roof structures present significant challenges to effective roof plane segmentation. To address this, a roof plane segmentation method that leverages multi-scale voxels and graph cuts is proposed. First, an octree voxelizes the original point cloud, generating multi-scale voxels based on geometric features to precisely characterize the data. Next, a bottom-up hierarchical clustering algorithm progressively merges these multi-scale voxels to obtain initial segmentation results. Finally, graph cuts refine the initial segmentation results and address boundary aliasing. The proposed method demonstrates superior performance, achieving roof plane segmentation accuracy of over 92.6% compared to four other methods. The proposed method accurately enables the generation of accurate roof planes for 3D building reconstruction.
Jul. 25, 2025Vol. 62 Issue 14 1428001 (2025)
Xinyao Chai, Li Li, Rong Tang, Dongxuan Han, Zhangjun Peng, and Zhigui Liu
In unstructured indoor scenes, motion blur and lighting changes affect the images captured by rapidly moving drones. This leads to certain limitations in the feature extraction and real-time processing of traditional simultaneous localization and mapping (SLAM) algorithms, which then affect the positioning accuracy and operational efficiency of the drones. Considering this, a visual-inertial SLAM algorithm that combines point and line features with step-by-step marginalization is proposed. A reverse optical flow module for point feature tracking is introduced to improve the accuracy of point feature tracking through the bidirectional verification and fusion of forward and reverse optical flows. Simultaneously, line encoding feature selection and homogenization modules are integrated into the line segment detection model, and directional thresholds and spatial distance constraints are employed for screening to improve the accuracy and robustness of line feature detection. The improved marginalization strategy is used to separately optimize the visual and the residual information of inertial measurement unit. This reduces the dimensionality of the information matrix and enhances the computational efficiency and resource utilization of the SLAM system. The experimental results demonstrate that the proposed method reduces the root mean square error of the absolute trajectory error by 15.79% and 7.99% compared with PL-VINS and EPL-VINS, respectively. This indicates a significant improvement in the accuracy of the unmanned aerial vehicle pose estimation.
Jul. 25, 2025Vol. 62 Issue 14 1428002 (2025)
Mingliang Shan, Jun Ye, Peng Yan, Yangzhi Xu, Junjie Wen, Bin Xu, Xuefeng Liu, and Jichuan Xiong
With the rapid development of digital cities and machine vision, 3D reconstruction techniques for outdoor scenes based on 3D point cloud data are becoming more and more important in autonomous driving, robot path analysis, and intelligent navigation. However, the complexity of outdoor scenes and the uncertainties in data acquisition (environmental noise, sparse and uneven distribution of point clouds, low overlap rate, etc.) pose great challenges to feature extraction and reconstruction accuracy. To address these issues, this study proposes a multi-scale coherence-based point cloud registration network (MSC-Net). The network utilizes geometric coding to add geometric constraints for point cloud matching, and further improves the matching accuracy through multi-scale feature extraction and consistency constraint strategies. Experimental results on the KITTI dataset show that MSC-Net performs well in terms of registration accuracy, achieving the relative translation error of 5.4 cm and the relative rotation error of 0.22°, both of which are improved compared to existing algorithms. In addition, the proposed method is evaluated on the 3DMatch and 3DLoMatch datasets, achieving excellent results in all metrics, with the highest registration recall of 94.5% on the 3DMatch dataset.
Jul. 25, 2025Vol. 62 Issue 14 1428003 (2025)
Zhongxuan Bai, Yue Shen, and Deming Kong
Point clouds obtained by scanning the bridge unloader grab bucket with 4D millimeter-wave radar in bulk cargo ports are sparse and incomplete, making it difficult to describe the grab bucket trajectory. To address this problem, an improved point cloud registration method based on the fruit fly optimization algorithm is proposed. This supplements the point cloud obtained by 4D millimeter-wave radar by a more accurate description of the grab bucket trajectory of the unloader. First, lidar scanning is used to obtain a relatively complete point cloud, which is used as a template to extract the intrinsic shape signatures of the cloud. Subsequently, the feature points of the template point cloud and fast point feature histogram (FPFH) of the sparse target point cloud are separately registered, and feature matching is performed based on the calculated FPFH descriptors. Finally, the improved fruit fly optimization algorithm is used to obtain the positional relationship between the template and target point clouds, followed by the iterative closest point algorithm to achieve precise point cloud registration. Partial models from the Stanford point cloud database and measured point cloud data from bridge unloaders are used to compare five commonly used registration algorithms. The experimental results show that the improved registration algorithm reduces the root mean square error by more than 7.1% and mean absolute error by more than 8.7%. The proposed method has smaller errors and higher accuracy in registering sparse point clouds, and the resulting grab trajectory is smooth and stable in continuous alignment.
Jul. 25, 2025Vol. 62 Issue 14 1428004 (2025)
Zhigang Li, Xinya Niu, Haodong Huang, and Ying Guo
The estimation accuracy of geographic entity boundaries is one of the key concerns in high-precision 3D modeling. The mobile measurement system based on 3D laser scanner sensors can be used as a technical support platform for high precision object appearance measurement, where the accuracy of the plane fitting algorithm directly determines the reliability of extracting the surface feature position of the measured object from the point cloud data, thereby affecting the determination of object boundaries. To solve this problem, as the shortest distance from a point to the fitted plane serves as the fitting constraint condition, by deriving the intrinsic relationship between the coefficients of the plane equation and the deviation vectors of the point positions, a new plane equation fitting method is established. The position and attitude of the plane are calculated using the Newton iteration method and the principle of least squares. Consequently,accuracy metrics for the plane equation are established, including the plane attitude error and positioning error. Simulation and actual measurement data verify that the plane fitting method is highly accurate and reliable.
Jul. 25, 2025Vol. 62 Issue 14 1428005 (2025)
Yang Yang, Zining Wang, Qinggai Mi, Yongjun Yang, Linjie Lü, Ruoxin Mi, and Tengfei Wu
The single-photon light detection and ranging (LiDAR) with Geiger mode avalanche photo diode (Gm-APD) as the detector has a problem of difficult signal light extraction under strong background noise. One of the main reasons is that the quenching probability of the single photon detector triggered by strong background noise increases, which affects the counting efficiency of the signal light and reduces the counting signal-to-background ratio (SBR) of the Gm-APD single-photon LiDAR. In response to the above issues, a polarization degree of freedom control noise reduction method is proposed. Linear polarized light is used as the signal light, and a polarization-controlled light receiving and emitting path is designed. A probability model for photon counting is established to simulate the influence of factors such as surface material, background noise, and dead time on signal and noise counting. Experimental tests are conducted to evaluate the polarization reflection characteristics of typical targets. A complete Gm-APD single-photon LiDAR system is built for ranging and imaging verification, achieving a filtering effect of about 50% on non-polarized noise outside the detection system, and increasing the counting SBR by up to 1.8 times. The method can be applied to the field of single-photon LiDAR imaging that requires outdoor daylight detection, such as long-range vehicle mounted LiDAR. With simulation and experimental results, the method has good target universality and significant noise suppression ability.
Jul. 25, 2025Vol. 62 Issue 14 1428006 (2025)
Hui Liu, Rui Chen, Zixi Wang, Qiang Liu, and Aiqin Li
Accurate size information measurement of the sealing components of proton exchange membrane fuel cell stacks is essential for preventing the escape of reactive gases from the cell reaction zone. Consequently, this study proposes a three-dimensional (3D) reconstruction method for flexible thin-walled parts based on a laser point cloud. By designing groove calibration objects and nonchamfered measuring blocks, the calibration object features are extracted from the contour data collected by each line laser contour sensor. Subsequently, the relative positional relationship of these features is used to accurately calibrate the optical plane and linear guide motion direction. We set overlapping areas and employ an improved point-to-surface iterative nearest point algorithm to fuse the point cloud data during the motion process of a single sensor. Combined with the calibration object characteristics, the transformation relationship between the different sensor optical plane coordinate systems is calculated by employing the principal component analysis method and consequently constructing the covariance matrix. The results demonstrate that the standard deviation of the system measurement results is approximately 0.01 mm. Furthermore, the proposed method accurately measures the 3D morphology and thickness information of flexible thin-walled test objects, and the measurement efficiency and accuracy satisfy the requirements of proton exchange membrane fuel cell stack seals in the industry.
Jul. 25, 2025Vol. 62 Issue 14 1428007 (2025)
Junhong Huang, Tingdong Kou, Tianyue He, Cui Huang, Chaoqiang Wu, and Junfei Shen
In recent years, virtual staining technology based on deep learning has gradually emerged as an important research direction to replace conventional histological staining by digitally generating high-quality staining images while offering advantages of short time-consuming, low cost, and high fidelity. This paper reviews and discusses the overall process of virtual staining technology based on four key stages: data acquisition, preprocessing, network design and training, and staining-quality evaluation. Despite the substantial potential of this technology in clinical applications, breakthroughs are required to improve its staining quality and clinical evaluation. In the future, the introduction of technologies such as software and hardware collaborative optimization, improvements of deep-learning preprocessing methods, and reinforcement learning is expected to propel the clinical application of virtual staining technology and promote its wide application in pathology diagnosis and medical research.
Jul. 25, 2025Vol. 62 Issue 14 1400001 (2025)
Xiangzi Chen, Ziping Yun, Mengming Zeng, Xiaolong Zhu, Xiaoju Pan, Mingqi Xu, Enci Zhu, and Qingsheng Xue
Hyperspectral imaging detection technology is a type of detection technology that combines spectral and imaging technology, helping to bridge the gap in high-precision underwater detection. This technology enables the simultaneous acquisition of the two-dimensional spatial and one-dimensional spectral information of a target, allowing for close-range and high-resolution visualization during seafloor detection and mapping, which has significant application prospects in efficient ocean detection and seafloor target identification. Consequently, it has become a key research focus among marine researchers worldwide. This article first provides a brief description of the structural composition of the underwater hyperspectral imaging system, followed by its application in different operational platforms such as underwater fixed agitation orbits, underwater vehicles, and surface vehicles. Subsequently, the current problems and challenges facing underwater hyperspectral imaging technology are outlined, and its prospects for future development are forecasted.
Jul. 25, 2025Vol. 62 Issue 14 1400002 (2025)
Zhengheng Li, Chenyin Ni, and Chunmin Zhang
In micro focus cone beam CT imaging, a large scanning angle is usually required to obtain sufficient data. If the scanning angle is reduced, it may result in artifacts in the reconstructed image. To address the problems of stripe artifacts and image blurring owing to sparse scanning, deep learning is used to fill in information gaps caused by sparse scanning. A paired dataset is constructed using full-scan and sparse-scan reconstructed images. A dual-domain CT sparse-angle reconstruction model is proposed that combines a wavelet transform denoising diffusion probability model and a generative adversarial network (GAN)-based wavelet diffusion refinement generation (WDRG) model. This model separates the domain transforms in CT reconstruction for processing. First, a low-frequency diffusion module and a high-frequency refinement module are introduced in the sine domain. Thereafter, the sine map is fully reconstructed in the reconstruction domain. Finally, the optimized GAN model is applied in the image domain to generate the final CT-reconstructed image. Simulation experiments and actual results demonstrate that the proposed WDRG model achieves high-quality CT image reconstruction in sparse-angle scanning while considerably reducing scan time.
Jul. 25, 2025Vol. 62 Issue 14 1434001 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20