







Please enter the answer below before you can view the full text.


2024
Volume: 61 Issue 12
45 Article(s)

Simultaneous Retrieval of Ozone Concentration and Aerosol Optical Parameters using Ultraviolet LiDAR
Xiaomin Ma, Huihui Shan, Hui Zhang, Kaifa Cao, Jiajia Han, Shenhao Wang, Shaoqing Zhao, Lingling Huang, Pengyu Tao, Changjiang Zhang, and Zongming Tao
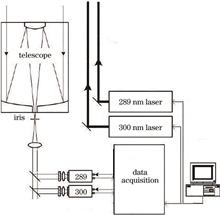
Aerosols are the main components of air pollutants, and ozone also has a certain impact on human health. Light detection and ranging (LiDAR) is a powerful tool for detecting the atmosphere. Ozone has a strong absorption in the ultraviolet (UV) band with a wavelength less than 320 nm. Using UV laser (with a wavelength less than 320 nm) to detect aerosols will cause mutual effects between aerosol absorption, ozone absorption, and atmospheric molecular absorption. Consequently, retrieving aerosol optical parameters from the UV LiDAR equation will be more complex than that from the visible LiDAR equation. A dual-wavelength UV LiDAR detection system was designed to obtain UV LiDAR echo signals at two wavelengths. An iterative algorithm was proposed to simultaneously invert the ozone concentration profile and aerosol optical parameter profile from the two LiDAR equations, with ozone concentration profile as the constraint condition. The calibrated three-wavelength UV ozone LiDAR of Anhui Kechuang Zhongguang Technology Co., Ltd., and the dual-wavelength UV LiDAR of our group were used to verify the correctness of the proposed inversion algorithm in the same place at the same time. The ozone concentration profiles retrieved by the two LiDARs were compared and analyzed, with a relative error less than 13%. Based on this, the designed dual-wavelength UV LiDAR detection system was used to detect atmospheric for continuous 10 h. The process involved comparing and analyzing the ozone concentration retrieved near the ground with ozone concentration detected by national control stations. The relative errors of both are less than 17.6%. The results of the two comparative experiments indicate that the proposed inversion algorithm is feasible and reliable.
Jun. 25, 2024Vol. 61 Issue 12 1201001 (2024)
Zheng Zhou, Yu Yang, Gan Zhang, Libing Xu, Mingqing Wang, and Qibing Zhu
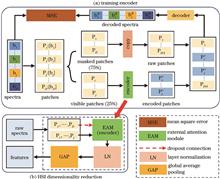
To address the low hyperspectral image (HSI) pixel classification accuracy caused by few number of labeled training samples and high-dimensional spectral data, this study proposes a self-supervised learning-based feature extraction method to extract low-dimensional features representing crucial information of HSI data. First, an unsupervised data augmentation was used to expand the HSI training dataset. Then, the feature extraction module constructed by an external attention module was trained using an extended training dataset under a self-supervised framework. The self-affinity features between bands of a single sample and the potential correlation between different samples were extracted under the supervision of the intrinsic co-occurrence attributes of the spectral data. Finally, the trained feature extraction module was applied to reduce the dimension of raw HSI data, and the low-dimensional features were input to the subsequent classifier to classify the HSI pixels. The feasibility and effectiveness of the proposed method were evaluated through quantitative evaluation of dimensionality reduction results on Indian Pines, Salinas, and Pavia University datasets. The experimental results show that the feature extraction module generated using the proposed method can fully extract the spatial-spectral features from the original spectra. The proposed method is insensitive to the size of the training set and is suitable for small-sized HSI data.
Jun. 25, 2024Vol. 61 Issue 12 1237001 (2024)
Fangke Jing, Hongge Ren, and Song Li
A small-target traffic sign detection algorithm based on multiscale feature fusion is proposed to address the limited effectiveness of the existing target detection algorithms in detecting traffic signs with small sizes or inconspicuous features. First, a bidirectional adaptive-feature pyramid network is designed to extract all detail features and jump connections to enhance multiscale feature fusion. Second, a dual-head detection structure is proposed for the scale characteristics of small targets, focusing on small-target feature information while reducing the number of model parameters. Next, using the Wise-IoU v3 bounding box loss function and a dynamic nonmonotonic focusing mechanism, the harmful gradients generated by low-quality examples are reduced by employing the anchor-box gradient gain allocation strategy. Finally, coordinate convolution (CoordConv) is incorporated into the feature extraction network to enhance the spatial awareness of the model by improving the network's focus on coordinate information. The experimental results on the Tsinghua-Tencent 100K dataset show that the improved model has a mean average precision (mAP) of 87.7%, which is a 2.2 percentage points improvement over YOLOv5s. Moreover, the number of parameters is only 6.3×107, thereby achieving a detection effect with fewer parameters and higher accuracy.
Jun. 25, 2024Vol. 61 Issue 12 1237002 (2024)
Kai Wang, Jie Ren, and Weichuan Zhang
In few-shot image classification tasks, capturing remote semantic information in feature extraction modules based on convolutional neural network and single measure of edge-feature similarity are challenging. Therefore, in this study, we present a few-shot image classification method utilizing a graph neural network based on Swin Transformer. First, the Swin Transformer is used to extract image features, which are utilized as node features in the graph neural network. Next, the edge-feature similarity measurement module is improved by adding additional metrics, thus forming a dual-measurement module to calculate the similarity between the node features. The obtained similarity is used as the edge-feature input of the graph neural network. Finally, the nodes and edges of the graph neural network are alternately updated to predict image class labels. The classification accuracy of our proposed method for a 5-way 1-shot task on Stanford Dogs, Stanford Cars, and CUB-200-2011 datasets is calculated as 85.21%, 91.10%, and 91.08%, respectively, thereby achieving significant results in few-shot image classification.
Jun. 25, 2024Vol. 61 Issue 12 1237003 (2024)
Zhihong Hu, Xiaobao Liu, Tinqiang Yao, and Jihong Shen
Aiming at the problem that the inter-layer resolution of computed tomography (CT) sequence images is much lower than the intra-layer resolution, an inter-layer interpolation network for CT images combined with feature pyramid and deformable separated convolution is proposed. The network consists of two modules, the image generation module and the image enhancement module. The image generation module utilizes the MultiResUNet to achieve feature extraction of the input image, and uses two different sets of deformable separation convolutions to generate candidate inter-layer images by performing convolution operations on the input image respectively. The image enhancement module fuses the multi-scale features of the input image through the feature pyramid and the image synthesis network, and generates additional images focusing on contextual details to further enhance the texture details of the candidate inter-layer images. The experimental results show that the inter-layer images generated by the proposed inter-layer interpolation network achieve better results in both qualitative and quantitative analysis, and perform better in the processing of image edge contours and texture details, which can effectively improve the inter-layer resolution of CT sequence images.
Jun. 25, 2024Vol. 61 Issue 12 1237004 (2024)
Xianfeng Wang, Shiben Liu, Jiandong Tian, Juanping Zhao, yajing Liu, and Chunhui Hao
The existing deep-learning-based high dynamic range (HDR) image reconstruction methods used for HDR image reconstruction are prone to losing detailed information and providing poor color saturation. This is because the input image is overexposed or underexposed. To address this issue, we propose a dual-attention network-based HDR image reconstruction method. First, this method utilizes the dual-attention module (DAM) to apply the attention mechanism from pixel and channel dimensions, respectively, to extract and fuse the features of two overexposed or underexposed source images, and obtain a preliminary fusion image. Next, a feature enhancement module (FEM) is constructed to perform detail enhancement and color correction for the fused images. The final reference to contrastive learning is generating images closer to the reference image and away from the source image. After multiple trainings, the HDR image is finally generated. The experimental results show that our proposed method achieves the best evaluation results on peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and learned perceptual image patch similarity (LPIPS). Moreover, the generated HDR image exhibits good color saturation and accurate details.
Jun. 25, 2024Vol. 61 Issue 12 1237005 (2024)
Wan Jiang, Kai Yang, Chunrong Qiu, and Liming Xie
Accurate detection of foreign objects on ballastless railway track beds is crucial for ensuring train safety. Although unsupervised anomaly detection algorithms based on deep learning address the effect of insufficient abnormal data on detection, the "generalization" ability of the encoder can proficiently reconstruct anomalous instances, thereby affecting detection accuracy. To solve this problem, this study proposes an anomaly detection framework for ballastless track beds utilizing image inpainting. First, inpainting was employed to obscure and subsequently restore the image using training on nonanomalous and incomplete image data, aiming to improve the model's contextual semantic understanding and enhance its reconstruction ability. Second, the maximum value obtained from the average anomaly map of the test and reconstructed images, which was analyzed across multiple scales, was utilized as the reconstruction error to calculate the anomaly score. This step aimed to widen the reconstruction error boundary between the abnormal and normal images. Finally, experimental results show a notable advantage of the proposed algorithm over alternative methods on public datasets, such as MNIST, CIFAR-10, and the ballastless track bed dataset.
Jun. 25, 2024Vol. 61 Issue 12 1237006 (2024)
Xuguang Zhang, Yunmeng Liu, Chan Tan, and E Zhang
With the gradual expansion of human activities into space, Earth's outer space, especially its geosynchronous orbit, is becoming increasingly crowded. A large amount of space debris is generated from abandoned space equipment and space activity waste. Scattered space debris may cause space accidents, leading to damage or derailment of space equipment. Therefore, space object detection systems are of great significance for ensuring the safety of the space environment. Stellar image preprocessing can improve image quality and target signal-to-noise ratio (SNR), which is significant for space target recognition, space target tracking, spacecraft navigation, and spacecraft attitude determination. This study mainly focuses on image denoising, background correction, threshold processing, and centroid extraction. The existing methods and their advantages and disadvantages are summarized, and the corresponding improvement methods are proposed. For image denoising and background correction, different algorithms are validated using a real stellar image. Additionally, the processing effects are analyzed using SNR gain and background suppression factor, and the effect for the targets with different SNRs are analyzed. Consequently, the neighborhood maximum filtering and improved background correction methods are proposed. In the threshold processing section, we analyze the histogram characteristics of real stellar images and propose an iterative adaptive threshold method based on them. For centroid extraction, we use Gaia data to generate a simulated stellar image based on the Gaussian point spread function. After adding white noise, we analyze the sub-pixel centroid extraction error and calculation time of different algorithms. Finally, based on the study results, the urgent need for future space target recognition is pointed out, and relevant suggestions are proposed.
Jun. 25, 2024Vol. 61 Issue 12 1237007 (2024)
Wenyue Hao, Huaiyu Cai, Tingtao Zuo, Zhongwei Jia, Yi Wang, and Xiaodong Chen
Most intravascular ultrasound (IVUS) image segmentation methods lack capture of global information, and the topological relationships of segmentation results do not conform to medical prior knowledge, which affects subsequent diagnosis and treatment. To address the above issues, an image segmentation method is proposed that combines convolutional neural networks (CNN) and Transformer dual branch backbone networks with topological forcing networks. A backbone network is constructed by juxtaposing CNN branches and Transformer branches to achieve the fusion of local and global information. The modules that make up the Transformer branch combine axial self attention mechanism and enhanced mixed feedforward neural network to adapt to small datasets. In addition, connecting the topology forcing network after the backbone network and using a bilateral filtering smoothing layer instead of a Gaussian filtering smoothing layer can further improve the segmentation accuracy while ensuring the correctness of the topology structure of the segmentation results. The experimental results show that the Jaccard measure coefficients of the lumen and media obtained by the proposed method are 0.018 and 0.016 higher than those of the baseline network, and the Hausdorff distance coefficients are 0.148 and 0.288 higher, respectively. Moreover, the accuracy of the topological structure is 100%. This method can provide accurate, reliable, and topologically correct segmentation results for IVUS images, and performs well in visualization results and various evaluation indicators.
Jun. 25, 2024Vol. 61 Issue 12 1237008 (2024)
Yang Tao, Bangqian Zhong, Wenbo Zhao, and Kun Zhou
In this study, a YOLOv5-based underwater object detection algorithm is proposed to address the challenges of mutual occlusion among underwater marine organisms, low detection accuracy for elongated objects, and presence of numerous small objects in underwater marine biological detection tasks. To redesign the backbone network and improve feature extraction capabilities, the algorithm introduced deformable convolutions, dilated convolutions, and attention mechanisms, mitigating the issues of mutual occlusion and low detection accuracy for elongated objects. Furthermore, a weighted explicit visual center feature pyramid module is proposed to address insufficient feature fusion and reduce the number of failed detections for small objects. Moreover, the network structure of YOLOv5 is adjusted to incorporate a small object detection layer that uses the fused attention mechanism, improving the detection performance for small objects. Experimental results reveal that the improved YOLOv5 algorithm achieves a mean average precision of 87.8% on the URPC dataset, demonstrating a 5.3 percentage points improvement over the original YOLOv5 algorithm while retaining a detection speed of 34 frame/s. The proposed algorithm effectively improves precision and reduces missed and false detection rates in underwater object detection tasks.
Jun. 25, 2024Vol. 61 Issue 12 1237009 (2024)
Lü Fu, Xiangyan Cui, and Tie Liu
To address issues such as detail loss, artifacts, and unnatural appearance associated with current low-illumination image enhancement algorithms, a multiscale low-illumination image enhancement algorithm based on brightness equalization and edge enhancement is proposed in this study. Initially, an improved Sobel operator is employed to extract edge details, yielding an image with enhanced edge details. Subsequently, the brightness component (V) of the HSV color space is enhanced using Retinex, and brightness equalization is accomplished via improved Gamma correction, yielding an image with balanced brightness. The Laplacian weight graph, significance weight graph, and saturation weight graph are computed for the edge detail-enhanced image and brightness-balanced image, culminating in the generation of a normalized weight graph. This graph is then decomposed into a Gaussian pyramid, while the edge detail-enhanced image and brightness-balanced image are decomposed into a Laplacian pyramid. Finally, a multiscale pyramid fusion strategy is employed to merge the images, resulting in the final enhanced image. Experimental results demonstrate that the proposed algorithm outperforms existing algorithms on the LOL dataset in terms of average peak signal to noise ratio, structural similarity, and naturalness image quality evaluator. This algorithm effectively enhances the contrast and clarity of low-illumination images, resulting in images with richer detail information, improved color saturation, and considerably enhanced quality.
Jun. 25, 2024Vol. 61 Issue 12 1237010 (2024)
Yiting Xu, Huajun Li, Yingkuang Zhu, Lianjie Chen, and Youhu Zhang
A linear back projection Pix2Pix (LBP-Pix2Pix) image reconstruction method, based on generative adversarial networks, is proposed to address the issues of heavy artifacts, high noise levels, and long processing times in optical tomography reconstruction. This method utilizes the LBP technique to reconstruct the absorption coefficient distribution within the object's cross-section. The initial reconstructed image and the true distribution are used as training samples for the Pix2Pix model. The optimal reconstruction model is obtained through adversarial training of the generator and discriminator. Using the model to process LBP-reconstructed images yields reconstructed images with fewer artifacts and clear edges. Five cross-sectional distributions are tested, and the results show that the reconstruction error range of the LBP-Pix2Pix method is 5.20%?13.15%, and the correlation coefficient range is 88.34%?99.08%. Compared with other reconstruction techniques, this method significantly enhances the imaging speed and image accuracy, presenting a novel image reconstruction approach for optical tomography.
Jun. 25, 2024Vol. 61 Issue 12 1211001 (2024)
Xiaomei Xue, Lijun Sun, Tianfei Chen, and Pengxiang Fan
To reduce the phase error caused by the nonlinear response in the digital phase-shifting fringe projection system, a self-correction method based on the universal rational polynomial model is proposed. The method first uses polynomials to model the unknown nonlinearity of the projector, and then establishes the phase error function. Second, the outlier detection algorithm is used to eliminate the deviation points, and the phase error coefficient in the error function is solved iteratively by using the optimization function. Finally, the phase with error is substituted into the phase error function, and the phase error is corrected point by point through fixed point iteration. The experimental results show that the proposed self-correction method is easy to implement and does not require pre-calibration, and can effectively reduce the nonlinear errors in the digital phase-shifting fringe projection process without the need of data calibration in advance, which is helpful to improve the measurement accuracy and efficiency of the system.
Jun. 25, 2024Vol. 61 Issue 12 1211002 (2024)
Zelin Zhang, Xing Cao, Lei Wang, and Xuhui Xia
To improve the remanufacturing efficiency of used mechanical parts and detect their surface failure state comprehensively, this paper proposes a color three-dimensional (3D) reconstruction technique using an improved semi-global matching (SGM). Traditional SGM algorithms often produce unsatisfactory parallax maps owing to the complex structure of mechanical parts and large illumination interference in a real environment. Addressing this, we propose a multifeature cost fusion strategy, which integrates color cost, Census transform, and gradient data to establish a more comprehensive similarity measurement function to improve the reliability of the initial cost. Furthermore, in the process of cost aggregation, a gradient threshold distinguishes between weak textures and edge regions. Moreover, we employ the Gaussian function to determine the distance weight of the local cross region to improve the algorithm's matching performance in the image light distortion region, weak part texture, and complex edge structures. Finally, we obtain a refined parallax map using parallax calculation and multistep parallax optimization. Besides, by merging this with an RGB image via texture mapping, we achieve a 3D color model reconstruction for used machinery components. Experimental outcomes indicate that the proposed method offers precise texture details and minimal size error for 3D color models and can be applied to the online detection of the surface failure information of used mechanical parts in the real production line.
Jun. 25, 2024Vol. 61 Issue 12 1211003 (2024)
Jingfa Lei, Bo Zhao, Ruhai Zhao, Yongling Li, and Miao Zhang
Binocular digital fringe projection has been widely used in three-dimensional (3D) shape measurement. However, for objects with considerable variations in surface reflectance, the information on digital fringes may be lost due to overexposure, resulting in a decrease in measurement accuracy. Therefore, this paper proposes an adaptive binocular digital fringe projection method to address this issue. First, grayscale images with different intensities are projected onto the object's surface to create a mask image. Furthermore, multiple sets of saturated point pixel clusters are generated, and the surface reflectance of the object within these clusters is calculated. Besides, the optimal projection light intensity value for each pixel in the clusters of saturated pixel points is determined. Second, the generated adaptive digital fringe sequence is projected onto the object's surface using the mapping relationship between the camera and projector pixel points. Finally, the phase is solved using the multifrequency heterodyne method, and the 3D object shape is reconstructed through phase matching performed by the left and right cameras. The experimental results show that the proposed method achieves a reduction of 99.57% and 96.57% in phase root mean square and average relative errors, respectively, compared with the existing binocular methods. Additionally, more accurate phase extraction and matching of the saturated exposure area are realized, and the relative error of height in the fitting model is reduced by 72.12%, thereby enhancing the measurement accuracy of the 3D shape of the strongly reflective object surfaces.
Jun. 25, 2024Vol. 61 Issue 12 1211004 (2024)
Weikun Zhang, Qiaohong Liu, Xiaoxiang Han, Yuanjie Lin, and Keyan Chen
Magnetic resonance imaging (MRI) is an important clinical tool in medical imaging. However, generating high-quality MRI images typically requires a long scanning time. To increase the speed of MRI and reconstruct high-quality images, this study proposes a magnetic-resonance reconstruction network that combines dense connections with residual modules in frequency and image domains. The proposed model comprises a frequency-domain reconstruction network and an image-domain reconstruction network. Each network is based on a U-shaped encoder-decoder architecture and transformed between the two domains using inverse Fourier transformation. The encoder utilizes densely-connected residual blocks, which enhances feature reuse and alleviates the issue of vanishing gradients. Coordinate attention is introduced at skip connections to extract global features and enhance the recovery of texture details. The performance of the proposed model is evaluated on the publicly-available CC-359 dataset. The experimental results show that the proposed method outperforms the existing methods by effectively removing artifacts and preserving more texture details at different sampling rates and masks, resulting in high-quality reconstructed MRI images.
Jun. 25, 2024Vol. 61 Issue 12 1211005 (2024)
Lei Nie, Jianglin Liu, Ming Zhang, and Renxing Luo
With the continuous increase in through-silicon via (TSV) packaging density, the detection of the defects hidden inside the package has become increasingly challenging. To address the difficulties in detecting multiple defects inside TSVs and the low efficiency of such detection, a method based on active infrared excitation for TSV internal defect classification and localization is proposed. First, through simulation analysis, the external performance patterns of TSV internal defects under active excitation are studied. Then, a convolutional neural network classification model is constructed and trained using simulated data to achieve the classification and localization of multiple internal defects. Finally, a platform for detecting internal defects in packaging is established to conduct experimental research. Near-infrared laser is used as the active excitation to stimulate internal defects in the packaging model. Infrared thermography is employed to capture images, which are then fed into the convolutional neural network for classification. The results show that this method can effectively identify the defect types and locations without damaging the samples, with an accuracy rate reaching 96.20%. It provides a reliable approach for the reliability analysis of TSV 3D packaging.
Jun. 25, 2024Vol. 61 Issue 12 1211006 (2024)
Beibei Ye, Jun Liu, Ming Gao, and Qingsong Wang
In the field of three-dimensional imaging, the accurate dephasing of wrapped phase is an important research area. Branch-cutting and least-squares methods are used to depict the phase diagram of the parcel phase with a single frequency. However, due to the influence of noise or shadow, branch-cutting method tends to produce an "island" effect, and results obtained using the least-squares method may deviate from the true value of the phase. Consequently, a phase unwrapping algorithm based on central curl segmentation is proposed. It calculates the central curl of each pixel in the parcel phase map, divides the area with a central curl of 0 and the area without 0, solves the parcel phase wrap using flood filling and second-order differential reciprocal sorting, and performs phase uplift processing at the regional boundary to obtain a complete absolute phase map. Simulation results reveal that the unwrapping performance of the algorithm proposed herein is remarkably better than that of the branch-cutting and least-squares methods. Experimental results reveal that the phase unwrapping algorithm based on central curl segmentation can effectively achieve the three-dimensional imaging for the surface contour information of the measured object. Moreover, the three-dimensional measurement error of the blade surface is ≤0.08 mm, and the measurement error of length for the 30-mm standard gauge block is ≤0.06 mm.
Jun. 25, 2024Vol. 61 Issue 12 1211007 (2024)
Chaochao Li, Zhenping Xia, Yueyuan Zhang, Tao Huang, and Changlong Guo
As a strong competitor of the next-generation high-dynamic-range (HDR) display, liquid crystal displays (LCDs) with a minilight-emitting-diode (Mini-LED) backlight are an essential approach for developing new display technologies. LCDs with a Mini-LED backlight inevitably introduce the halo effect because of their structural characteristics, such as local dimming and light leakage. Therefore, to investigate the effect of ambient light on the halo perception of LCDs with a Mini-LED backlight, we propose a fundamental LCD with a Mini-LED backlight simulation model and design a systematic visual perception experiment based on the proposed model. Furthermore, we investigate halo perception under different ambient illuminances, Mini-LED backlight block sizes, and contrast ratios of liquid crystal panels. Additionally, we explore the influence mechanism of ambient light on halo perception based on actual light measurements. The results show that ambient light has a substantial effect on halo perception; ambient light can affect the contrast ratio of the image; and ambient illuminance is negatively correlated with halo perception intensity. Therefore, this study provides a reference for designing and optimizing LCDs with a Mini-LED backlight under different ambient light conditions.
Jun. 25, 2024Vol. 61 Issue 12 1211008 (2024)
Zeshen Zhang, Yi Jin, Guiqiang Li, and Chang'an Zhu
Energy flux density distribution of the concentrating collector can be used to evaluate the performance of the mirror field and the collector. The direct or indirect measurement methods commonly used to measure the energy flux density distribution often suffer from issues such as low accuracy and long measurement times. To address these problems, we propose an image processing based method for analyzing the solar-focused spot. It utilizes a megacam to capture images of the solar-focused spot, the irradiance values at different positions of the spot are calculated using a multilayer perceptron, and a novel energy flux density grading measurement method is proposed to improve the dynamic range of irradiance measurement. The mean absolute percentage error of the system is in the range of 2.5% to 3.5%, and the measurement period is about 2 s. The system does not require a diffuse reflection target and offers advantages such as high accuracy, fast measurement speed, short measurement time, and low sensitivity to environmental conditions. Experimental results validate the effectiveness and accuracy of the system in measuring the energy flux density of focused spots in different irradiance ranges, which provide a new idea for measuring the energy flux density of concentrating collectors.
Jun. 25, 2024Vol. 61 Issue 12 1212001 (2024)
Jisheng Jin, Weihong Ma, Hui Tian, and Fan Wang
Aiming at the detection problem of deformation on the inner surface of conical tubes in diversified application fields, a deformation detection method for conical tubes based on image analysis is proposed. The aim is to achieve quantitative analysis of deformation variables on the inner surface of conical tubes of 2 mm and above, and qualitative analysis of the circumferential direction of deformation. To this end, a complementary metal-oxide-semiconductor image-capturing module was first installed within a conical tube to acquire images of predefined circular-ring lines. Subsequently, these images were processed to detect the circular-ring lines using the smallest circumscribing circle, and an enhanced Canny edge detection algorithm was employed to extract edge details. Furthermore, feature data from the center of the ring lines were analyzed to ascertain deformation extents and locations. The analysis outcomes were then converted based on the relationship between the pixel space and spatial coordinates of the inner surface of the conical tube. Remarkably, this method facilitates high visualization and precise localization accuracies. Experimental results demonstrate that this method offers superior edge extraction, effective identification of deformations exceeding 2.05 mm with a relative error within 0.15 mm, and a localization precision of 0.01° for the deformations. These features satisfy the requisites for both qualitative and quantitative analyses of deformations within conical tubes across diverse application scenarios.
Jun. 25, 2024Vol. 61 Issue 12 1212002 (2024)
Jianyang Song, and Changjie Liu
The application of adhesive on the white body is a crucial part of automotive production, and achieving automatic detection of adhesive defects on the white body is of great significance for improving the quality and efficiency of automotive production. However, based on traditional image processing and deep learning, current visual detection methods cannot effectively detect adhesive defects. Therefore, we propose a white body adhesive defect detection method combining deep learning and traditional image processing. First, Faster R-CNN was used to locate and extract adhesive strips, and the presence of adhesive breakage defects was determined based on the number of regions of interest. Then, the pixel area, length, and width of the adhesive strip were calculated using breadth-first search and skeleton extraction algorithms. Finally, the mapping ratio of actual width to pixel width was obtained through camera calibration, and the actual width of the adhesive strip was evaluated to determine whether the adhesive width was qualified and achieved defect detection of the adhesive. The validation experiment was conducted using a (10 ± 1) mm adhesive coating, and the results demonstrate that this method can accurately identify adhesive breakage defects. The measurement error of the width of the adhesive strip is found to be within ±0.35 mm. Furthermore, the detection speed is approximately 19.50 frame·s-1, which meets the requirements of actual production.
Jun. 25, 2024Vol. 61 Issue 12 1215001 (2024)
Wei Zhang, Jie Song, Lü Sheng, Zhilong Zeng, Qi Fang, and Shenghuai Wang
To solve the problem that the exposure cannot be determined accurately in the acquisition process of structured light 3D measurement, we propose a method to solve the optimal exposure time based on the camera response function. The background segmentation of different measured object images is mainly performed by using the Otsu method, and then the camera response function is utilized to solve the relationship between the true pixel value and the exposure time, so as to obtain the optimal exposure time under the ideal pixel mean value. In addition, an image quality evaluation method is constructed by calculating the ratio of overexposed and underexposed pixel points in the image and the normalization of other basic image quality evaluation parameters such as pixel mean value, which is capable to effectively evaluate the measured object images. Experiments are conducted using different exposure times for binocular structured light 3D measurements to compare the number of phase-matched points and key feature measurements in the model reconstruction. The results show that when the optimal exposure time is used to acquire the measured object, the image evaluation values are above 90%, the number of phase-matched points are the highest during the model reconstruction process, and the key features are measured accurately with a maximum measurement error of 0.02 mm compared with other measuring methods. Meanwhile, the quality evaluation results of the measured object image are positively correlated with the number of phase-matched points, which proves the effectiveness of the evaluation method. This study provides a scientific basis for the selection of the exposure in structured light 3D measurement.
Jun. 25, 2024Vol. 61 Issue 12 1215002 (2024)
Changlong Guo, Zhenping Xia, Chaochao Li, Hao Chen, and Yuanshen Zhang
Point cloud denoising is crucial for ensuring the quality of three-dimensional point clouds. However, existing denoising methods are extremely prone to error removal for object point clouds while removing noise points, and the error increases with the improvement of noise recognition accuracy. To address this issue, a point cloud denoising algorithm that incorporates improved radius filtering and local plane fitting is proposed. To achieve effective noise point removal, noise points are divided into far- and near-noise points based on their Euclidean distance from the object point clouds and are successively processed using different denoising strategies. First, the far-noise points are removed using improved radius filtering based on the density characteristics of the point clouds. Next, the near-noise points, which are closely located to the object point clouds and attached to their surfaces, are removed using a geometrical feature assessing the deviation of the point cloud from the local fitting plane. Finally, experiments are conducted on common point cloud datasets and the proposed method is validated by comparing its performance with that of three other advanced methods. The results show that the proposed method outperforms all three methods in all indexes under the same noise level. Our proposed method effectively improves the object point cloud recognition accuracy while achieving higher noise recognition accuracy, with the denoising accuracy reaching 95.9%.
Jun. 25, 2024Vol. 61 Issue 12 1215003 (2024)
Saisai Zhang, and Hongfei Yu
The rapid development of autonomous driving necessitates precise multisensor data fusion to accurately perceive the surrounding vehicular environment. Central to this is the precise calibration of LiDAR and camera systems, which forms the basis for effective data integration. Traditional neural networks, used for image feature extraction, often yield incomplete or inaccurate results, thereby undermining the calibration accuracy of LiDAR and camera parameters. Addressing this challenge, we propose a novel method hinged on multidimensional dynamic convolution for the extrinsic calibration of LiDAR and camera systems. Initially, data undergoes random transformations as a preprocessing step, followed by feature extraction through a specialized network based on multidimensional dynamic convolution. This network outputs rotation and translation vectors through feature aggregation mechanism. To guide the learning process, geometric and transformation supervisions are employed. Experimental validation suggests an enhancement in feature extraction capabilities of the neural network, leading to improved extrinsic calibration accuracy. Notably, our method exhibits a 0.7 cm reduction in the average error of translation prediction compared with the leading alternative approaches, substantiating the efficacy of the proposed calibration method.
Jun. 25, 2024Vol. 61 Issue 12 1215004 (2024)
Jing Zhang, and Guangfeng Chen
Due to the huge modal difference between visible and infrared images, visible-infrared person re-identification (VI-ReID) is a challenging task. Recently, the main problem of VI-ReID is how to effectively extract useful information from the shared features across modalities. To solve this problem, we propose a dual-flow cross-modal pedestrian recognition network based on the visual Transformer, which utilizes a modal token embedding module and a multi-resolution feature extraction module to supervise the model in extracting discriminative modal shared information. In addition, to enhance the discrimination of the model, the modal invariance constraint loss and the feature center constraint loss are designed. The modal invariance constraint loss will guide the model to learn the invariant features between modalities. The feature center constraint loss will supervise the model to minimize inter-class feature differences and maximize intra-class feature differences. Extensive experimental results on the SYSU-MM01 dataset and RegDB dataset show that the proposed method is better than most existing methods. On the large-scale SYSU-MM01 dataset, our model can achieve 67.69% and 66.82% in terms of the first matching characteristic and the mean average precision.
Jun. 25, 2024Vol. 61 Issue 12 1215006 (2024)
Lei Zhou, Bao Zhao, Dong Liang, Zihan Wang, and Qiang Liu
Three-dimensional (3D) local feature description is an important research direction in 3D computer vision, widely used in many tasks of 3D perception to obtain point correspondences between two point clouds. Addressing the issues of low descriptiveness and weak robustness in existing descriptors, we propose a local divisional attribute statistical histogram (LDASH) descriptor. The LDASH descriptor is constructed based on local reference axes (LRA). First, the local space is partitioned radially, and then five feature attributes are computed within each partition, comprehensively encoding spatial and geometric information. In LDASH descriptor, we introduce a new attribute called distance weighted angle value (DWAV) for local feature description. DWAV is not dependent on LRA, thus enhancing the descriptor's robustness against LRA errors. Furthermore, a robustness enhancement strategy is proposed to reduce the interference of point cloud resolution variations in practical testing on the descriptors. The performance of the LDASH descriptor is extensively evaluated on six datasets with different application scenarios and interference types. The results demonstrate that LDASH descriptor outperforms existing descriptors in all datasets. Compared to the second-best method (divisional local feature statistics descriptor), LDASH descriptor exhibits an average improvement of approximately 16.3% in discriminability and 7.5% in robustness. Finally, LDASH descriptor is applied to point cloud registration, achieving a correct registration rate of 73% when combined with the five transformation estimation algorithms.
Jun. 25, 2024Vol. 61 Issue 12 1215007 (2024)
Junyu Qi, Zaifeng Shi, Fanning Kong, Tianhao Ge, and Lili Zhang
Spectral computed tomography (CT) can provide attenuation information at different energy levels, which is essential for material decomposition and tissue discrimination. Sparse-view projection can effectively reduce radiation dose but can cause severe artifacts and noise in the reconstructed spectral CT images. Although deep learning reconstruction methods based on convolutional neural networks can improve the image quality, a loss in the tissue detail features is observed. Therefore, a spectral CT reconstruction method based on a hybrid attention module combined with a multiscale feature fusion edge enhancement network (HAMEN) is proposed. The network first extracts edge features of the input images through the edge enhancement module and concatenates them on the images, enriching the input image information. Next, a hybrid attention module is used to generate channel attention and spatial attention maps, which are used to refine the input features. The multiscale feature fusion mechanism is developed at the encoder, and some skip connections are added to minimize feature loss caused by the stacking of convolutional layers. The experimental results show that the peak signal-to-noise ratio of the CT images obtained using the proposed method is 37.64 dB, and the similarity structural index measure is 0.9935. This method can suppress artifacts and noise caused by sparse-view projection while preserving the tissue detail information. Furthermore, the CT image quality is improved for subsequent diagnosis and other works.
Jun. 25, 2024Vol. 61 Issue 12 1217001 (2024)
Liang Chen, Xi Chen, Jiancong Li, Yueqiao Wang, and Rongqing Xu
Based on the near-infrared autofluorescence characteristics of a parathyroid gland, a rapid intraoperative parathyroid identification device using highly sensitive laser-induced fluorescence (LIF) technology was developed. This paper describes the development of a fiber-optic probe-based non-invasive identification device for intraoperative parathyroid recognition. The device used a novel near-infrared sensing unit incorporated into a fluorescence collection module. By performing fluorescence experiments using indocyanine green (ICG) solution as a simulation of parathyroid autofluorescence, it was observed that the device exhibited a linear relationship between fluorescence intensity and ICG concentration, even at a low concentration of 0.05 nmol/L. The correlation coefficient between fluorescence intensity and ICG concentration was 0.999, indicating a strong correlation that closely matched the theoretical expectations. The device was tested in clinical experiments at the First People's Hospital in Guangzhou City. The experimental results demonstrated that the device successfully elicited autofluorescence from parathyroid glands. The fluorescence intensity of the parathyroid glands was approximately five times higher than those of other tissues, allowing for clear differentiation between the parathyroid glands and other tissues. Clinical experts concluded that the device can rapidly, non-invasively, and accurately identify parathyroid tissue, providing significant clinical value.
Jun. 25, 2024Vol. 61 Issue 12 1217002 (2024)
Chenwei Huang, Hesong Jiang, Xueyuan Wang, Qiuyue Xu, and Wanfen Han
To address the blurring of imaging images caused by unfavorable factors such as CCD acquisition and imaging focus depth in optical microscopic imaging systems, this study proposes a method for enhancing the clarity of bright-field microscopic images of unsharp masks by improving the anisotropy-guided filtering. First, the image noise is eliminated by improving the anisotropy-guided filtering of the adaptive regularization term while strongly retaining the edge detail information. Next, the isotropic Gaussian filtering is used to achieve strong smooth image structure information and the details are strongly preserved. The detail-preserving image is subtracted from the strongly-smoothed image to obtain the mask image. Finally, the input image is fused with the mask image to obtain a clear microscopic image. The proposed method overcomes the phenomenon that the traditional unsharp mask algorithm amplifies the image noise and reduces the recognition of image detail features. Furthermore, our method reduces the blurring of the image to a certain extent and avoids gradient inversion and halo artifacts in the filtering results. In the experimental results of the Leishmania parasite dataset on the Mendeley data public database, the average value of the sharpness evaluation indicators such as the peak signal-to-noise ratio, root mean square error, and average structural similarity is 41.1430, 0.000090, and 0.9905, respectively. Meanwhile, in the experimental results on the PanNuKe public database, the average value of the abovementioned three indicators is 28.8541, 0.001939, and 0.9283, respectively. Subjective and objective experimental results show that the proposed method can reduce noise interference and suppress detail "halo" problems as well as enhance edge detail information.
Jun. 25, 2024Vol. 61 Issue 12 1218001 (2024)
Fanfan Zhang, Jun Liu, Ming Gao, and Lü Hong
In view of the all-weather, large-field and high-resolution imaging requirements of photoelectric imaging systems, we design a wide-area high-resolution optical imaging system with a wide band of 0.4?1.7 μm based on the principle of multi-scale imaging. The system consists of a concentric sphere objective and 37 relay subsystem arrays. Multiple relay subsystem arrays perform field segmentation, imaging and aberration correction of the primary intermediate image surface obtained by the concentric sphere objective, so as to achieve wide-area high-resolution imaging. After optimizing the design, a wide-band large-field high-resolution optical system with a wide field of view of 105.6°×25.6° is finally obtained. The maximum root mean square radius value of the point column plot within the single-channel full field of view of the system is less than one cell size, and the value of each field of view modulation transfer function is greater than 0.6 at the spatial frequency of 33 lp/mm, and the curve is smooth and concentrated. The analysis results show that the system meets the requirements of high-resolution, all-weather imaging with a large field of view. It can provide a feasible reference for the design of subsequent wide-band large-field high-resolution optical imaging systems.
Jun. 25, 2024Vol. 61 Issue 12 1222001 (2024)
Yibo Wang, Song Dai, Dongmei Song, Guofa Cao, and Jie Ren
The fusion of hyperspectral and LiDAR data has broad application potential in the field of ground object classification. However, because of the Hughes phenomenon, extracting complete joint features from hyperspectral and LiDAR data is difficult. Therefore, this paper proposes a hyperspectral and LiDAR data fusion classification method based on an autoencoder to overcome the limitations in existing data fusion algorithms by eliminating heterogeneous data differences and achieving full fusion of cross-modal features. First, convolutional neural network models are used to extract deep features from hyperspectral and LiDAR data, effectively eliminating the differences in the original data space of heterogeneous data. Then, the feature information of different remote sensing data sources is fully learned by constructing a convolutional autoencoder for data feature fusion and adopting a cross-modal reconstruction strategy. Finally, the effectiveness of the proposed model is verified using the Houston and Trento datasets. Results show that the proposed method is remarkably superior to four methods, namely, SVM, ELM, EndNet, and MML, in terms of overall classification accuracy, average accuracy, and other evaluation indicators, thus confirming the superiority of the proposed method in urban land classification.
Jun. 25, 2024Vol. 61 Issue 12 1228001 (2024)
Shengwei Wu, Jiaoli Fang, and Daming Zhu
Aiming to solve the semantic recognition error of traditional methods in semantic segmentation of remote sensing imagery with complex background, we propose a simple but effective convolutional attention module, region squeeze and excitation block (RSE-block), based on squeeze and excitation block (SE-block). This block can squeeze regional context information of features, guides the network to screen more important features and excite features expression in both spatial and channel dimensions. In addition, it can be added to any convolutional neural network and trained end-to-end with the network. Meanwhile, we propose a multi-scale integration method supported by this block to solve the recognition problem of different size ground objects, and a new semantic segmentation network, RSENet, is constructed on these bases. The experimental results show that RSENet is superior to the baseline in terms of mean F1-score and mean intersection over union by 0.028 and 0.021 respectively on the Potsdam dataset, and is more competitive with some current advanced methods.
Jun. 25, 2024Vol. 61 Issue 12 1228002 (2024)
Zhuo Tang, Jinsong Wang, Qun Niu, and Xiaohua Liu
We propose a fast testing method based on an oversampling model to meet the demands for rapid modulation transfer function detection in low-light level CMOS image sensors. This method optimizes the inclined edge technique to enhance its accuracy. The testing procedure employs an adaptive dual-threshold Canny edge detection algorithm to enhance edge detection precision. Geometrically rotating the edge angle space oversamples the edge extension response, and we accomplish fitting using the cubic Fermi function equivalent model. This approach significantly mitigates the influence of noise on testing outcomes during natural low-light imaging. When applying this method for practical CMOS sensor testing, we compared the experimental results with the standard values using various target images, and errors remained within 0.06. These findings validate the feasibility and effectiveness of this method, fulfilling the requirements for CMOS sensor performance assessment.
Jun. 25, 2024Vol. 61 Issue 12 1228003 (2024)
Zhaohua Hu, and Yuhui Li
Remote sensing target detection is an important aspect in the fields of environmental monitoring and circuit patrol. A remote sensing target detection algorithm based on YOLOX is proposed for the difficulties of remote sensing images with large target scale differences, blurred targets and high background complexity. First, a regional context aggregation module is proposed to expand the perceptual field using the dalited convolutions with different expansion rates to obtain multi-scale contextual information, which is beneficial to the detection of the small targets. Second, the feature fusion module is proposed, and two different scale transformation modules are used to achieve the fusion of features at different scales, fully fusing shallow location information with deep semantic information to improve the detection performance of the network for targets at different scales. Finally, a feature enhancement module is introduced to the multi-scale feature fusion network part and combined with the attention mechanism CAS [CA (coordinate attention) with SimAM (simple parameter-free attention module)] to make the network pay more attention to the target information and ignore the interference of complex background, while the shallow feature layer is fused with the deep detection layer for feature fusion to prevent the low detection performance affected by the loss of feature information at the prediction end. The experimental results show that the improved algorithm achieves 73.87% and 96.22% detection accuracy on DIOR and RSOD remote sensing datasets, which is 4.08 and 1.34 percentage points higher than the original YOLOX algorithm, and has superiority in both detection accuracy and detection speed compared with other advanced algorithms.
Jun. 25, 2024Vol. 61 Issue 12 1228004 (2024)
Yuanze Wang, Haiyang Zhang, Xuan Wu, Chunxiu Kong, Yezhao Ju, and Changming Zhao
Medical-action recognition is crucial for ensuring the quality of medical services. With advancements in deep learning, RGB camera-based human-action recognition made huge advancements. However, RGB cameras encounter issues, such as depth ambiguity and privacy violation. In this paper, we propose a novel lidar-based action-recognition algorithm for medical quality control. Further, point-cloud data were used for recognizing hand-washing actions of doctors and recording the action's duration. An improved anchor-to-joint (A2J) network, with pyramid vision transformer and feature pyramid network modules, was developed for estimating the human poses. In addition, we designed a graph convolution network for action classification based on the skeleton data. Then, we evaluated the performance of the improved A2J network on the open-source ITOP and our medical pose estimation datasets. Further, we tested our medical action-recognition method in actual wards to demonstrate its effectiveness and running efficiency. The results show that the proposed algorithm can effectively recognize the actions of medical staff, providing satisfactory real-time performance and 96.3% action-classification accuracy.
Jun. 25, 2024Vol. 61 Issue 12 1228005 (2024)
Target Detection in Remote Sensing Image Based on Deformable Transformer and Adaptive Detection Head
Haokang Peng, Yun Ge, Xiaoyu Yang, and Changquan Hu
To address the challenges of precise localization of targets in optical remote sensing images and conflict between classification and localization features in the detection head, a remote sensing image target detection method based on Deformable Transformer and adaptive detection head is proposed. First, we design a feature extraction network based on feature fusion and Deformable Transformer. The feature fusion module enriches the semantic information of shallow convolution neural network features, and the Deformable Transformer establishes dependencies on distant features. This in turn effectively captures global semantic information and improves feature representation capability. Second, an adaptive detection head based on task learning module is constructed to enhance task awareness within the detection head. It automatically learns and adjusts the feature representation for classification and localization tasks, and thereby, mitigates feature conflicts. Finally, the L1-IoU loss is proposed as a localization loss function to provide a more accurate assessment of localization error between candidate boxes and ground truth boxes during training, thereby improving the accuracy of object localization. The effectiveness of the proposed method is evaluated on high-resolution remote sensing datasets, NWPU VHR-10 and RSOD. The results show significant improvements when compared to other methods.
Jun. 25, 2024Vol. 61 Issue 12 1228006 (2024)
Mang Huang, Bin Hui, Zhaoji Liu, and Tianming Jin
With the continuous increase in the sampling rate of LiDAR, systems can rapidly acquire high-resolution point cloud data of scenes. Dense point clouds are advantageous for improving the accuracy of 3D object detection; however, they increase the computational load. In addition, point-based 3D object detection methods encounter the challenges of balancing speed and accuracy. To enhance the computational efficiency of multilevel downsampling in 3D object detection and address issues such as low foreground point recall rate and size ambiguity of the one-stage network, a fast two-stage method based on semantic guidance is proposed herein. In the first stage, a semantic-guided downsampling method is introduced to enable deep neural networks to efficiently perceive foreground points. In the second stage, a channel-aware pooling method is employed to aggregate semantic information of the sampled points by adding pooled points, thereby enrich the feature description of regions of interest, and obtain more accurate proposal boxes. Test results on the KITTI dataset reveal that compared with similar two-stage baseline methods, the proposed method achieves the highest detection-accuracy improvements of 4.62 percentage points, 1.44 percentage points, and 3.91 percentage points for cars, pedestrians, and cyclists, respectively. Furthermore, the inference speed reaches 55.6 frame/s, surpassing the fastest benchmark by 31.1%. The algorithm exhibits strong performance in accuracy and speed, holding practical value for real-world applications.
Jun. 25, 2024Vol. 61 Issue 12 1228007 (2024)
Ningke Zhu, Qing Ge, Hanwen Wang, and Pengfei Yu
For handling low detection accuracy, poor real-time performance, and large model size of small target traffic sign detection, a real-time road traffic sign detection algorithm based on Yolov5 is proposed. First, the inverted residual structure in Mobilenetv3 was improved and applied to the backbone network of Yolov5 to align with the lightweight network design. Then, the lightweight upsampling universal operator CARAFE (content-aware ReAssembly of FEatures) replaced the nearest neighbor interpolation upsampling module of the original network, reducing the loss of upsampling information and increasing the receptive field. Finally, global and local fusion attention (GLFA) was used to focus on the global and local scales to enhance the sensitivity of the network for small target objects. Experiments on the self-made Chinese multiclass traffic sign dataset (CMTSD) show that the enhanced algorithm improves mean accuracy precision (mAP) @0.5 by 2.58 percentage points based on the model size reduction of 8.76 MB compared with the algorithm before enhancement. Furthermore, the detection speed reaches 62.59 frame/s. Compared with other mainstream object detection algorithms, the proposed algorithm exhibits certain advantages in detection accuracy, speed, and model volume and performs better in real complex traffic scenes.
Jun. 25, 2024Vol. 61 Issue 12 1228008 (2024)
Wei Wang, and Luhe Zhang
Based on basic principle of slanted-edge for on-orbit test, the slanted-edge is introduced into the short-wave infrared band. By analyzing the on-orbit test processes, ground targets with clear boundaries are selected as edge images to calculate the modulation transfer function within the cut-off frequency. The results at the Nyquist frequency in the along-track and cross-track directions are approximately 0.1. The results show that the on-orbit slanted-edge-based modulation transfer function test method can overcome the limitations of ground pixel resolution on sampling areas, which is suitable for short-wave infrared cameras with small pixel arrays and low resolutions.
Jun. 25, 2024Vol. 61 Issue 12 1228009 (2024)
Shen Tong, Jincheng Zhong, Xinlin Chen, Ping Qiu, and Ke Wang
Multiphoton imaging is extensively used in biomedical research, especially in brain science, providing noninvasive and nondestructive imaging methods for investigating the structure and dynamics of deep biological tissues. However, the absorption and strong scattering characteristics of these biological tissues limit the depth of imaging. Recently, owing to advances in principles and technology, remarkable improvements have been realized in multiphoton imaging with respect to imaging depth in living organisms. Among them, multiphoton imaging obtained by exciting the 1700 nm wavelength band considerably reduces tissue absorption and scattering, achieving the current maximum imaging depth compared with other excitation bands. This article introduces the imaging principles of multiphoton microscopy and utilizes the soliton self-frequency shift effect to construct a femtosecond pulse light source with a 1700 nm band. Furthermore, the application of multiphoton imaging in live mouse brain, skin structure, and hemodynamic imaging is discussed. Finally, the current challenges and future development directions of 1700 nm excitation multiphoton imaging are analyzed and summarized.
Jun. 25, 2024Vol. 61 Issue 12 1200001 (2024)
Lan Ma, YunHong Liao, and YanDong Gong
Based on the principles of interference and diffraction, holographic imaging has achieved the reconstruction of amplitude and phase information of objects and thus has been widely studied. Metasurface is a new material with a subwavelength unit structure, which can realize many physical properties that are not available in nature. Furthermore, it can flexibly adjust and control the phase and amplitude of electromagnetic waves and complete the complex wave front adjustment and control through metasurface materials. Moreover, metasurface enhances the performancs of traditional spatial light modulators in imaging resolution, imaging efficiency, and imaging field-of-view angle. Consequently, the emergence of metasurface materials provides a solution for studying holographic imaging in the terahertz band. Therefore, this study first introduces the basic optical principles of holographic imaging. It then reviews current research progress of algorithms used in metasurface holographic imaging in different electromagnetic wave bands, especially in the terahertz band, domestically and internationally. Furthermore, it introduces the basic principles of several common metasurface design algorithms and the impact of various algorithms on imaging results. Additionally, it provides a comparative analysis and summary of these algorithms, which provides a reference for selecting metasurface design algorithms for terahertz band holographic imaging.
Jun. 25, 2024Vol. 61 Issue 12 1200002 (2024)
Da Ai, Xiaoyang Zhang, Ce Xu, Siyu Qin, and Hui Yuan
Point cloud data can provide rich spatial information about any object or scene in the real world. Accordingly, the rapid development of the three-dimensional (3D) vision technology has promoted the point cloud data application, in which the task of performing a large-scale point cloud semantic segmentation containing millions or billions of points has received wide attention. Semantic segmentation aims to obtain the semantic class of each point, which is used to better understand 3D scenes. Driven by the common progress of the 3D scanning and deep learning technologies, point cloud semantic segmentation is being widely applied in the fields of intelligent robotics, augmented reality, and autonomous driving. First, the recent large-scale point cloud semantic segmentation methods based on deep learning are comprehensively categorized and summarized to demonstrate the latest progress in the field. Next, the commonly-used large-scale point cloud datasets and evaluation metrics for evaluating semantic segmentation models are introduced. Based on this, the semantic segmentation performances of different algorithms are compared and analyzed. Finally, the limitations of the existing methods are determined, and the future research directions for the large-scale point cloud semantic segmentation task are prospected.
Jun. 25, 2024Vol. 61 Issue 12 1200003 (2024)
Jiatao Yan, Yun Tang, Rui Yuan, Penghui Zou, Ping Liao, Jingfeng Li, and Xuxiang Peng
Optical coherence tomography (OCT) is a nondestructive low-coherence biomedical imaging technology that has developed rapidly in recent years. Owing to its ability to detect the microstructure information of biological tissues, OCT has brought great convenience to biomedical basic and clinical research. OCT has helped to achieve a comparison between dynamic and static structures in ophthalmology, from exploring the initial macular structure to evaluating the retinal and choroidal vascular systems. Additionally, with the development of light sources, the OCT system has become a standard examination method in multiple clinical fields, such as dermatology, gastrointestinal diseases, and cardiovascular diseases. Our article reviews the development of OCT, introduces various types of OCT systems, and compares their imaging principles, performance, advantages, and disadvantages. Finally, the summary and prospective applications of this technology in biomedicine are presented.
Jun. 25, 2024Vol. 61 Issue 12 1200004 (2024)
Gaoxiang He, Bin Zhu, Bo Xie, and Yi Chen
One highly focused research direction in neural rendering is the neural radiance field (NeRF), which offers a novel implicit representation of three-dimensional scenes. NeRF conceptualizes the scene as a medium comprising numerous luminescent particles and applies a differentiable volume rendering equation to aid virtual cameras in rendering corresponding scene images. Its implicit and differentiable characteristics confer remarkable advantages on NeRF, particularly in the field of new viewpoint synthesis. This review thoroughly examines the latest research progress of NeRF in the domain of new viewpoint synthesis. Moreover, this study comprehensively analyzes how NeRF addresses unbounded scenes, dynamic environmental scenes, and sparse viewpoint scenes in practical applications, along with its advancements in training and inference acceleration. Concurrently, this study highlights NeRF’s challenges in this task and presents a vision for future research.
Jun. 25, 2024Vol. 61 Issue 12 1200005 (2024)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20