



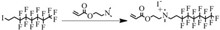


Please enter the answer below before you can view the full text.


2025
Volume: 40 Issue 8
13 Article(s)

Longxiao MI, and Xunda FENG
The formation of lyotropic liquid crystalline (LLC) phases from photocurable amphiphilic small molecules offers an effective strategy for fabricating polymeric materials with well-defined nanostructures. Such self-assembly is primarily driven by phase separation between hydrophilic and hydrophobic segments, with hydrophobic interactions playing a crucial role in the formation of ordered structures. However, conventional amphiphiles typically employ hydrocarbon tails, which require relatively long chain lengths to provide sufficient hydrophobic driving force, thereby limiting the achievable structural miniaturization (typically >3 nm). To overcome this limitation, we designed and synthesized a novel polymerizable ionic amphiphile, EAF8-AC, featuring a fluorocarbon tail with high hydrophobicity and low conformational freedom. The LLC behavior of hydrated EAF8-AC at room temperature was systematically investigated. A concentration phase diagram was established, and the self-assembled structures were characterized using polarized optical microscopy (POM) and small-angle X-ray scattering (SAXS). The evolution of mesophase structures was interpreted based on the critical packing parameter (CPP) theory. Compared to conventional hydrocarbon-based amphiphiles, EAF8-AC enables the formation of more compact ordered structures, demonstrating its potential for constructing high-resolution nanomaterials.
Aug. 05, 2025Vol. 40 Issue 8 1093 (2025)
Xi ZHANG, Bin LIU, Shuo ZHANG, Congyang WEN, Qi YAO, Jian GUO, Ce NING, Guangcai YUAN, Feng WANG, and Zhinong YU
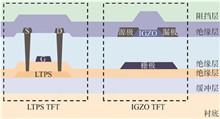
Low temperature polycrystalline oxide (LTPO) display technology is a new integrated display technology that integrates low temperature polycrystalline silicon (LTPS) and metal oxide semiconductors (MOS) to achieve high performance and low power consumption display solutions. During the LTPO integration process, hydrogen may diffuse from the low-temperature polysilicon layer to the metal oxide layer, resulting in device threshold voltage drift and deterioration of stability, affecting display product performance. The differences of hydrogen in LTPS and MOS devices and the effects of hydrogen on MOS devices are discussed in detail. Two types of hydrogen blocking methods for MOS devices are summarized: using different dielectric layers and ion doping technology. In addition, the paper also arranges the hydrogen barrier for LTPO devices to improve the stability and reliability of LTPO devices. Finally, the wider application of LTPO technology in the field of high performance display through hydrogen blocking is prospected.
Aug. 05, 2025Vol. 40 Issue 8 1100 (2025)
Runfang JIANG, and Longzhen QIU
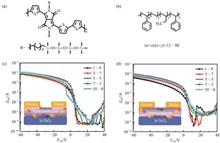
Conventional conjugated polymers face the critical challenge of achieving simultaneous optimization of electrical and mechanical properties. This study focuses on siloxane-side-chain-functionalized diketopyrrolopyrrole (DPP)-based conjugated polymer (DPP-4Si) blended with hydrogenated styrene-butadiene block copolymer (SEBS). Through precise control of film preparation and microphase separation structures, we developed high-performance elastic semiconductor films with a maximum mobility of 1.08 cm2·V-1·s-1. Fully stretchable transistors fabricated using the optimal blend ratio demonstrated remarkable electromechanical stability, maintaining over 72% current retention even under 100% tensile strain, showcasing exceptional stretchability.
Aug. 05, 2025Vol. 40 Issue 8 1115 (2025)
Kai WANG, Baolong ZHANG, Dan LI, Yufeng MA, and Zhao LI
Optical microscope objectives are widely utilized in medical imaging and biological research. However, conventional objectives based on Snell’s law face the challenges in miniaturization due to their multi-lens configurations. Metalens technology, grounded in the generalized Snell’s law, offers a promising solution. This study derives the ideal refractive index distribution for metalenses by integrating the generalized Snell’s law with the equal optical path principle. Liquid crystal materials, leveraging their electrically controlled birefringence, inherently satisfy this distribution. A refractive index distribution model for liquid crystal lenses is established, accompanied by a novel tilted ITO driving electrode structure. Techwiz LCD 2D simulations demonstrate that under a 7 V applied voltage and 20° ITO tilt angle, the refractive index profile optimally aligns with the ideal parabolic curve. Zemax-based optical performance analysis reveals that the liquid crystal microscope objective achieves a 50× magnification, 1.584 mm focal length, 0.124 numerical aperture, and 2.37 μm resolution in the visible spectrum. Spot diagram analysis confirms RMS radii smaller than the Airy disk radius across scenarios, indicating superior energy concentration. MTF curves exhibit values exceeding 0.3 from low to high frequencies, meeting standard detector imaging requirements.
Aug. 05, 2025Vol. 40 Issue 8 1122 (2025)
Haoran WANG, Xueying CHANG, Qilong CHEN, Zhenyao BIAN, Hongbo LU, and Miao XU
Liquid crystal lenses have the advantages of compact structure, high integration, and adjustable focal length. This article proposes a method for preparing a liquid crystal micro lens array (LCMLA) with modal control for integrated imaging 3D display. Firstly, the influence of voltage amplitude and frequency on the potential distribution of liquid crystal lenses without and with high resistance layers was analyzed using simulation software COMSOL Multiphysics. Secondly, a transparent high resistance layer of polymer poly (3,4-ethylenedioxythiophene): polystyrene sulfonate (PEDOT∶PSS) and polyvinyl alcohol (PVA) was fabricated on a copper circular hole array electrode. And a comparative experiment was conducted to verify it, the experimental results show that the LCMLA without adding a high resistance layer changes the focal length from ∞ to 25.8 mm and the response speed is 645.7 ms when the voltage changes from 0 to 40 V at a fixed sine wave frequency of 1 kHz. The LCMLA with modal control incorporating a high resistance layer can adjust the lens characteristics by changing either the amplitude or frequency of the driving voltage. When the fixed frequency is 75 kHz, the voltage changes from 0 to 5 V, the focal length changes from ∞ to 19.5 mm, and the response speed is 621.4 ms. When the fixed voltage is 5 V, the frequency changes from 1 kHz to 75 kHz, the focal length changes from ∞ to 19.5 mm, and the response speed is 146.4 ms. Applying the prepared LCMLA with modal control to integrated imaging 3D display can achieve good 3D display effect and fast switching characteristics at low voltage.
Aug. 05, 2025Vol. 40 Issue 8 1132 (2025)
Fei YAN, Ye JIANG, Lijuan ZHANG, Peng WANG, and Yinping LIU
With the widespread application of 4K ultra-high-definition video technology in medical and security fields, field-programmable gate arrays (FPGAs) are increasingly employed for collaborative processing of large-scale UHD video tasks. To address the low data bandwidth utilization caused by 8b/10b encoding in high-speed transceivers, this paper proposes an FPGA-based 4K video board-to-board transmission and display system. The system architecture utilizes FPGA as the core controller, integrated with an STM32 microcontroller and GSV2011 codec chip to manage data transmission modes, while optimizing the hardware interface of GTX transceivers. By employing 64b/66b encoding in multi-channel GTX transceivers and designing encoding/decoding logic aligned with 4K video stream timing, the system achieves efficient transmission. Key innovations include multi-channel data synchronization mechanisms and DDR multi-frame buffering logic, effectively resolving channel-skew-induced transmission deviations and display frame tearing caused by clock rate mismatches during read/write operations. Experimental results demonstrate that the system stably realizes real-time 4K@60 Hz video transmission between boards with low hardware resource consumption. Compared with 8b/10b encoding, it reduces effective bandwidth requirements by 3.12 Gb/s while maintaining equivalent transmission performance. This solution provides a flexible, cost-efficient transmission framework for multi-FPGA collaborative processing in UHD video scenarios, demonstrating significant engineering application value.
Aug. 05, 2025Vol. 40 Issue 8 1145 (2025)
Shasha XU, Chenglin YANG, Mingxing LI, Jiuba GE, Jingjing WU, Lin YU, Huaxin ZHU, and Lifa HU
Phase-shifting interferometry is a widely used technique in precision optical metrology. However, conventional PSI methods typically require three or more phase-shifted interferograms, which limits their applicability in dynamic measurements and vibration-sensitive environments. To address this issue, this paper proposes a deep learning-based framework named PSI-IPENet. The framework adopts a Two-to-One structure, where two phase-shifted interferograms are used as dual-channel input, corresponding to a single phase map as the supervisory signal, and a dedicated dataset is constructed for training. PSI-IPENet leverages the feature extraction capability of IPENet and incorporates the physical characteristics of interferometric imaging, thereby enhancing the robustness and noise resistance of phase retrieval. Experimental results demonstrate that the proposed method maintains high-precision phase recovery performance even with a low number of input frames. Compared with the traditional four-step phase-shifting method, it shows significant advantages in terms of signal-to-noise ratio and phase error metrics.
Aug. 05, 2025Vol. 40 Issue 8 1154 (2025)
Wenbiao LI, Yang TAO, Yuan DONG, and Liqun ZHOU
To address the degradation issues in underwater images, such as color distortion, contrast reduction, and detail blurring, we propose an underwater image enhancement algorithm based on color prior guidance and attention mechanisms. We designed a Bayesian posterior feature extraction module to fuse color-prior-corrected image with the original image, and a color prior guided attention Transformer to utilize the prior information to guide the image enhancement process, which reduces the burden of color restoration during training. We constructed a hybrid multi-scale attention module to enhance feature representation in key regions. A dual-axis decoupled attention module was introduced to eliminate feature redundancy at the bottleneck layer, suppress overfitting, and improve the detail restoration. The proposed algorithm achieves PSNR/SSIM scores of 24.33/0.910 9 on UIEB, 28.40/0.885 9 on UFO, and 29.00/0.899 ?1 on EUVP, demonstrating superior performance compared to state-of-the-art approaches on all three benchmarks. In addition, the proposed algorithm improves the UIQM and UCIQE metrics by 12.81% and 5.19%, respectively, compared to the original images. These results verify the effectiveness of the proposed algorithm in improving image sharpness, structural similarity, and overall visual quality.
Aug. 05, 2025Vol. 40 Issue 8 1163 (2025)
Ning MA, Xia CHANG, and Weibing ZHANG
To address the issues of inaccurate atmospheric light estimation, low color saturation, and dim brightness in highlight regions after dehazing using dark channel prior-based methods, this paper proposes a novel dehazing approach based on superpixel segmentation and dark-bright channel fusion. This method utilizes superpixel segmentation to refine the segmentation of hazy images, clustering regions with similar depth-of-field characteristics into superpixel blocks, using these blocks to replace traditional fixed filtering windows, which effectively suppresses the blocking effect in areas of gradient abruptness. Through adaptive threshold segmentation, the algorithm identifies highlight and dark regions, and utilizes a hybrid dark channel strategy to enhance the robustness of the dehazing algorithm across various scenes. We construct an atmospheric light estimation model with joint constraints from dark and bright channels, and apply guided filtering for refinement, improving both the accuracy and spatial consistency of atmospheric light estimation. Based on optimized transmission and atmospheric light parameters, fog-free images are derived through inverse calculation using the atmospheric scattering model. Experimental results demonstrate that the proposed method achieves a PSNR of 26.815 dB on the OTS dataset, an SSIM of 0.576 on the O-HAZE dataset, and requires only 36.281 s of processing time on the I-HAZE dataset, with average improvements of 13% and 5% in PSNR and SSIM, respectively. The proposed method effectively mitigates the persistent challenges of low saturation and insufficient luminance in highlight regions of reconstructed images, with both objective metrics and subjective evaluations demonstrating superior performance compared to state-of-the-art algorithms.
Aug. 05, 2025Vol. 40 Issue 8 1177 (2025)
Weiwei KONG, Zejiang LI, Leilei HE, and Yusheng DU
There are differences in spatial information distribution among different medical imaging models, which is not conducive to the effective alignment of the depth feature space, resulting in the loss of shallow information in a specific area of the fusion image or excessive dependence on the information of a certain mode. To solve these problems, an asymmetric medical image fusion model based on Restormer and dual attention mechanism was proposed. Firstly, Restormer module is used to dig deep features of different modal images, and dual attention mechanism is introduced to extract global and local features of different modal images. Secondly, an asymmetric feature fusion strategy is designed, in which an independent feature encoder is designed for each mode and the extracted features are fused. Finally, the fused features are generated by the decoder. This model adopts two stages of training, the first stage mainly extracts global and local features from different modal images, and attempts to reconstruct the original image to calculate the loss; the second stage continues to extract deep features and generate fusion images. Compared with the seven mainstream image fusion models, the seven evaluation indicators, standard deviation, spatial frequency, visual information fidelity, spectral relevance, mutual information, average gradient, and Q index used to evaluate hybrid fusion have an average increase of 12.63%, 28.30%, 31.37%, 27.40%, 19.01%, 37.36%, 32.44%, respectively. The fusion strategy of this model can not only efficiently integrate the coding features from different modes, but also complete the integration of complementary information and the interaction of global information without manually designing fusion rules, and can better integrate images from different modes.
Aug. 05, 2025Vol. 40 Issue 8 1189 (2025)
Shiyan GAO, Jie LIU, Wenyi CHEN, Zemin HE, Haiyan YANG, and Zongcheng MIAO
Single object tracking is a crucial task in computer vision, aiming to accurately locate a target in a video sequence. Although deep learning has significantly advanced the field of single object tracking, challenges such as target deformation, complex backgrounds, occlusion, and scale variation still remain. This paper systematically reviews the development of deep learning-based single object tracking methods over the past decade, covering traditional sequence models based on convolutional neural networks, recurrent neural networks, and Siamese networks, as well as hybrid architectures combining convolutional neural networks with Transformers and the latest approaches entirely based on Transformers. Furthermore, we evaluate the performance of different methods in terms of accuracy, robustness, and computational efficiency on benchmark datasets such as OTB100, LaSOT, and GOT-10k, followed by an in-depth analysis. Finally, we discuss the future research directions of deep learning-based single object tracking algorithms.
Aug. 05, 2025Vol. 40 Issue 8 1202 (2025)
Na LI, Jinting PAN, Rongji LI, and Yufei WANG
To balance the trade-off between tracking accuracy and model complexity, an efficient single-object tracking method is proposed based on a siamese network. The method employs a lightweight MobileNet-V3 as the backbone network, significantly reducing the computational load and number of parameters for feature extraction. Additionally, a hybrid feature fusion module is designed, comprising a rapid feature refinement unit and a dual-branch feature aggregation unit. The rapid feature refinement unit effectively decreases the number of feature vectors by aggregating queries and optimizing keys, thereby quickly extracting key information about the target object. The dual-branch feature aggregation unit further enhances tracking performance through a multi-head attention mechanism that fuses features from different branches. Comparative experiments with other tracking algorithms are conducted on the LaSOT, OTB100, and UAV123 datasets. Experimental results demonstrate that the proposed method maintains satisfactory tracking performance while exhibiting lower model complexity. Furthermore, it sustains robust tracking capabilities in various complex scenarios, including fast motion and rotation.
Aug. 05, 2025Vol. 40 Issue 8 1219 (2025)
Xiwei REN, Yan LIU, Man XIAO, Shiduan JIA, Rui WANG, and Lifeng HE
To address the limitations of existing video summarization algorithms in preserving activity integrity due to neglected shot-level information and the ineffectiveness of traditional RNNs and LSTMs in capturing long-range dependencies for lengthy videos, this paper proposes a hierarchical video summarization algorithm based on independent recurrent neural networks (HIRVS) by leveraging the inherent hierarchical structure of video sequences. Specifically, HIRVS is divided into three components: (1) Visual features for each shot are generated by the IndRNN, where the final hidden state represents a temporally weighted aggregation of all frame features within that shot; (2) Shot-level feature sequences are modeled for temporal relationships using a bidirectional IndRNN, capturing long-range dependencies between shots; (3) A self-attention video encoder is introduced to extract global dependencies across the entire video. Key shots are then selected based on predicted importance scores to generate the video summary. Experiments are conducted on two public datasets, SumMe and TvSum. On SumMe, an F-score of 51.0% is achieved, representing a 1.2% improvement over VOGNet. On TvSum, an F-score of 61.3% is obtained, surpassing the current state-of-the-art method VJMHT by 0.3%. Experimental results validate the effectiveness of HIRVS for video summarization tasks, demonstrating improved summary generation efficiency.
Aug. 05, 2025Vol. 40 Issue 8 1233 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20