





Please enter the answer below before you can view the full text.


2025
Volume: 40 Issue 9
14 Article(s)
Zhili ZHANG, Yi SUN, Wenbin HUANG, Xiaohong ZHOU, Zhongwei YU, and Yanyan HUANG
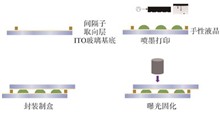
The conventional patterning of PSCLC films relies on prefabricated photomasks or complex micro/nano fabrication processes, which are costly and limited flexibility, thus restricting their applications in personalized optical devices. In this work, a drop-on-demand inkjet printing technique is employed to achieve rapid and efficient patterning, enabling programmable and highly designable liquid crystal patterns. A birefringent film is introduced to enhance optical modulation efficiency and realize gradient color variations. Experimentally, the reflection peaks of red, green, and blue PSCLC materials are centered at 680 nm, 550 nm, and 490 nm, respectively, and all enter a scattering state under applied DC voltages, demonstrating excellent electro-optical responsiveness. By optimizing the viscosity of the liquid crystal solution and the driving waveform, uniform PSCLC pixel arrays with a minimum pixel size of 60 μm are successfully fabricated, verifying the feasibility of the inkjet printing process. This low-cost and scalable patterning method significantly improves the precision of PSCLC patterning. It also expands their potential applications in flexible displays, smart photonic devices, and tunable optical elements.
Sep. 05, 2025Vol. 40 Issue 9 1243 (2025)
Yunfei YAN, Ruolong LIN, Zihan ZHOU, Hongmei MA, and Yubao SUN
To effectively prevent light emission in a certain direction from affecting viewers, such as the reflections produced by automotive display screens on the front windshield, this paper proposes a polymer-stabilized liquid crystal device that prevents light emission in a specific direction. This unidirectional light-blocking liquid crystal device is based on a twisted nematic (TN) structure. By applying an electric field, the liquid crystal director’s profile in the liquid crystal layer is appropriately controlled. In this state, ultraviolet light is used to cure the polymer monomers dispersed in the liquid crystal, forming a stable polymer network that fixes the orientation of the liquid crystal molecules. When the electric field is removed and the polarizer is adhered to, a unidirectional light-blocking effect is achieved, fulfilling the desired requirement. Experimental results show that the proposed unidirectional light-blocking device can prevent light from passing through at specific angles, with a maximum transmittance of 89% at the normal viewing angle. The double-layer structure significantly reduces light leakage at large angles while maintaining a maximum transmittance of 70% at the normal viewing angle, providing a better unidirectional light-blocking effect. This work demonstrates that polymer-stabilized twisted nematic liquid crystal devices can offer unidirectional light-blocking characteristics while maintaining high transmittance in the forward direction, making them highly suitable for special applications in personal electronic products, vehicle displays, and safety information terminals, thus possessing significant practical value.
Sep. 05, 2025Vol. 40 Issue 9 1251 (2025)
Influence of active layer thickness on performance of Al-Zn-Sn-O thin-film transistors and inverters
Laizhe KU, Chao WANG, Liang GUO, Jieyang WANG, Xuefeng CHU, Fan YANG, Yunpeng HAO, Hansong GAO, and Yang ZHAO
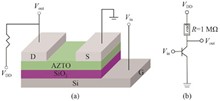
To investigate the influence of active layer thickness on the performance of aluminum zinc tin oxide (AZTO) thin-film transistors (TFTs) and inverters, and to promote their application in logic circuits, this paper prepared AZTO thin films with different thicknesses by radio frequency magnetron sputtering. These films were used as active layers to construct bottom-gate top-contact AZTO-TFT devices. The microstructure and composition of the films were characterized by field emission scanning electron microscopy (SEM) and X-ray photoelectron spectroscopy (XPS), and the electrical properties of the devices were tested.It was found that with the increase of the thickness of the AZTO active layer, the oxygen vacancy concentration gradually increased. Moderate oxygen vacancies can weaken the scattering effect of defects and impurities on carriers, reduce the transmission resistance, and thus improve the field-effect mobility. At the same time, the device can pass more carriers in the on-state, resulting in an increase in the source-drain current and the on/off ratio. The results showed that when the thickness of the active layer was 82 nm, the quality of the AZTO film was the best, and the device performance was optimal, with a field-effect mobility of 7.47 cm2 · V-1 · s-1, a threshold voltage of 14.25 V, a subthreshold swing of 1.35 V/dec, and a current on/off ratio of 6.16×10?. The resistor-loaded inverter prepared under this optimized condition achieved a high gain of 8.8 at a supply voltage (VDD) of 25 V, and had full-swing characteristics and good noise margin, which can effectively drive the next-stage components of the logic circuit.
Sep. 05, 2025Vol. 40 Issue 9 1258 (2025)
Chen WANG, Qipeng FANG, Feiyu JIANG, Chengkai LIAO, Xiuhui SUN, Chao HU, and Shaoyun YIN
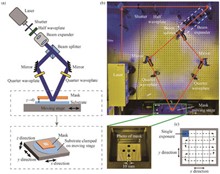
Large-aperture liquid crystal polarization gratings (LCPGs) hold broad potential applications in beam steering modules due to their advantages of high efficiency and inertia-free operation. However, limited by the aperture of optical components in polarization holographic interference exposure systems, it is challenging to fabricate LCPGs with apertures exceeding 2 in (1 in=2.54 cm) through single exposure. This paper proposes a proximity stepper holographic interference splicing exposure method. By employing a photomask placed in close proximity to the exposure substrate, precise control of single-exposure area positioning is achieved combined with a high-precision displacement stage. Stepper splicing exposure of a 150 mm aperture LCPG is realized. The fabricated grating exhibits a splicing seam of only 26.4 μm and achieves a diffraction efficiency of 96.86%. This paper provides a new idea for the efficient deflection of large-aperture beams.
Sep. 05, 2025Vol. 40 Issue 9 1268 (2025)
Jiachang DONG, Yuanyi WEN, Xifeng ZHENG, Deju HUANG, Xinyue MAO, and Liting ZHAO
Micro-LED displays achieve image rendering beyond the physical resolution of the display by means of sub-pixel multiplexing technology, which effectively reduces the production cost while improving the perceived resolution. However, the traditional unweighted average rendering algorithm for the triangular arrangement of RGB subpixels easily leads to the problem of color distortion, which in turn seriously affects the image display quality and user viewing experience. To solve this problem, this paper proposes an adaptive weighted subpixel rendering algorithm based on color difference. The algorithm consists of an image preprocessing module, a color space conversion module, an adaptive weight calculation module, and a subpixel rendering module. Firstly, the image preprocessing module extends the boundaries of the input image to ensure that no boundary-crossing problem occurs in the subsequent subpixel rendering process. Next, the color space conversion module separates and expands the channels of the read pixels and converts them from the sRGB color space to the CIELab color space. Subsequently, the adaptive weight calculation module achieves scene matching by calculating the color difference polarity between pixels and assigns values to the output subpixels. If it fails to match the corresponding scene, the center pixel is selected and the weight value is calculated based on the color difference of the neighboring pixels. Finally, the subpixel rendering module outputs the grayscale value of the subpixel based on the calculated weight value to complete the rendering of the final image. The experimental results show that compared with the traditional unweighted average subpixel rendering algorithm, the color difference-based adaptive weighted subpixel rendering algorithm proposed in this paper performs better on the DIV2K dataset. Specifically, the mean square error is reduced by 14.537 61, the peak signal-to-noise ratio is improved by 0.828 21 dB, and the structural similarity is improved by 0.014 96, the feature similarity index increased by 0.000 83, and the fidelity of visual information increased by 0.009 66. The algorithm significantly suppresses the color distortion problem, which effectively improves the display quality and the user viewing experience.
Sep. 05, 2025Vol. 40 Issue 9 1275 (2025)
Jie WANG, Yuan JI, Zhongbei JIN, Yin ZHANG, and Xingyan LIU
To address the excessive data volume issue in digitally-driven silicon-based OLED (Organic Light Emitting Diode) microdisplays under high resolution, high grayscale, and high refresh rate conditions, this study proposes a low-power dynamic-comparison interface circuit for 2k×2k microdisplays. Currently, low-power interfaces predominantly employ high-speed low-voltage differential signaling (LVDS) transmission schemes, where the analog comparators in the receiver end exhibit significant static power consumption. The proposed circuit employs dynamic comparison techniques for receiving both data and control signals, effectively reducing overall power consumption. Experimental results based on 110 nm process demonstrate that the receiver achieves correct data acquisition at 1.2 V operating voltage with 100 mV input signal swing and 1.25 GHz operating frequency. Notably, the single-channel dynamic comparison receiver consumes only 160.7 μW, representing a 29.4% reduction compared to conventional receiver circuits, while the total system power consumption is merely 4.01 mW. This dynamic-comparison interface circuit provides an innovative design solution for future digital driving circuits with increasingly demanding requirements, offering significant improvements in power efficiency without compromising performance.
Sep. 05, 2025Vol. 40 Issue 9 1289 (2025)
Zhihan FU, Zhiyi LI, Chuang DAI, and Lijuan ZHANG
To address the challenge of balancing accuracy and real-time performance in existing 3D point cloud object detection models within autonomous driving scenarios, this paper proposes an efficient point cloud object detection method. The aim is to improve detection accuracy while meeting the requirements for real-time deployment on edge devices, thereby promoting the application development in autonomous driving and intelligent transportation fields. Based on a pillar-based point cloud detection framework, a multi-pillar feature fusion model is designed. The model enhances the pillar feature representation ability by introducing point cloud variance features and positional encoding. A multi-pillar feature fusion module is proposed to improve the learning of contextual information between adjacent pillars, and a backbone network combining residual connections and Dropout regularization is used to optimize feature extraction. Furthermore, a point cloud data augmentation strategy is improved by mixing point clouds of same-category objects to enhance the model’?s generalization ability to complex scenes. Extensive experiments on the KITTI dataset demonstrate that the proposed method achieves a 3D mAP of 68.93 and a BEV mAP of 75.02. The model maintains an inference speed of 55.65 FPS. It also demonstrates excellent performance on the DAIR-V2X dataset. The proposed model achieves a balance between detection accuracy and real-time performance through multi-pillar feature fusion and an optimized data augmentation strategy, showcasing its application potential in autonomous driving scenarios. Future work could further optimize the model architecture to adapt to embedded system deployment to meet practical application needs.
Sep. 05, 2025Vol. 40 Issue 9 1296 (2025)
Luxia YANG, Zekai LIU, Hongrui ZHANG, and Yongjie MA
Aiming at the problem of low detection accuracy of small targets caused by large scale change and complex background in aerial photography, a detection algorithm based on multi-scale collaborative perception of context is proposed. Firstly, a lightweight multi-scale enhancement module (LMEM) is constructed to activate local significance information with attention mechanism to enhance feature capture capability of small targets. Secondly, the context-driven cross-level feature fusion architecture module (CCFFAM) is designed. The integration of receptive field attention convolution and dynamic sampling technology realizes multi-layer feature space-channel dual alignment and adaptive weighted fusion to enhance feature fusion capability. Finally, the scale distribution of the detection head was reconstructed, and the original loss function was replaced with Focaler-CIoU to optimize the bounding box regression process, ensuring that the model is lightweight while having a high detection efficiency. Experiments on VisDrone2019 and DOTAv1 data sets show that the proposed method reduces the number of model parameters by 27.9% (2.17M) compared with the original model, and the mAP increases by 5.3% and 1.4% respectively, which verifies that the algorithm has a good detection effect.
Sep. 05, 2025Vol. 40 Issue 9 1308 (2025)
Yudong GAO, Lingxiao HUANG, Xinbo YAO, and Yuanru ZHAO
To improve the accuracy and robustness of river edge extraction in remote sensing images, a river edge detection method based on an improved EDTER algorithm is proposed. Addressing issues such as edge detail loss and noise interference in complex natural scenes with traditional methods, a more adaptive edge detection scheme is introduced. The method employs a two-stage edge detection framework with Swin Transformer as the backbone network, incorporating a residual multilayer perceptron to enhance feature representation and designing a lightweight multi-scale decoder to improve detection efficiency. The first stage extracts global image features to generate a global edge map, while the second stage performs local feature extraction and fuses it with global features to produce the final edge detection result. Comparative experiments on the BSDS500 dataset and a self-constructed cross-regional river edge dataset demonstrate that the proposed method outperforms mainstream approaches in ODS, OIS, and AP metrics. Notably, the AP value on the cross-regional river edge dataset reaches 0.871, an improvement of approximately 3.2% over the EDTER method, indicating superior edge extraction capability in complex remote sensing scenarios. The proposed method effectively balances detection accuracy and computational efficiency, exhibiting strong generalization performance and suitability for water body edge extraction tasks in various remote sensing images, with significant engineering application value.
Sep. 05, 2025Vol. 40 Issue 9 1321 (2025)
Wen SHAO, Pan SHAO, Baogui SONG, and Biao XIONG
Building extraction based on deep learning is an important research direction in the field of remote sensing. To effectively balance computational efficiency and extraction accuracy, a lightweight building extraction network integrating wavelet transform and global awareness is proposed. First, by integrating parameter sharing, star-shaped operations, and depthwise separable convolution, a star-shared depthwise convolution block is proposed to efficiently and accurately extract building features. Secondly, wavelet transform and frequency-domain spatial attention are introduced to propose an efficient boundary enhancement module that enhances the network’s ability to characterize building boundary features. Finally, employing a lightweight non-local attention mechanism and a hierarchical feature interaction strategy, a global context-aware module is proposed. This module significantly improves the fusion effectiveness of hierarchical features and enhances the overall perception capability during the network’s decoding stage. Experimental results demonstrate that the proposed network achieves Intersection over Union (IoU) scores of 90.08% and 79.16% on the publicly available WHU and Inria building extraction datasets, respectively. Concurrently, the model maintains a low parameter count (Params) of 3.09 million, FLOPs of 4.93 billion, and an inference speed of 30.24 frames per second (FPS). Compared to existing methods such as Swin Transformer, BuildFormer, SDSCUNet, EasyNet, HDNet, and CaSaFormerNet, the proposed method achieves higher extraction accuracy while maintaining low computational complexity, achieving a superior balance between computational efficiency and extraction accuracy.
Sep. 05, 2025Vol. 40 Issue 9 1333 (2025)
Yue YANG, Yangyang CHEN, Xudong KANG, and Bin WU
To address the inefficiency of traditional methods and the insufficient utilization of texture features in existing deep learning models for tunnel leakage detection, this paper proposes a leakage image segmentation method based on longitudinal texture convolution and learnable channel attention mechanism. First, considering the longitudinal extension characteristics of leakage regions, we design a longitudinal texture convolution module consisting of three cascaded asymmetric convolutional kernels with different scales, which enhances multi-scale receptive fields to capture longitudinal texture features. Second, we introduce a learnable parameter matrix into the channel attention mechanism to dynamically optimize feature channel weights, thereby focusing on critical regions. Based on the SegNet encoder-decoder architecture, we construct a lightweight segmentation network by incorporating Sobel operator preprocessing and pooling indices upsampling technique. Experimental validation on a public dataset containing 4 555 leakage images demonstrates that compared with U-Net and DeepLabv3+, our method achieves improvements of 0.72%~2.82% in intersection over union (IoU), reaching 80.64%, with accuracy and F1-score increased to 94.68% and 89.30%, respectively. Ablation studies further verify the effectiveness of the longitudinal texture convolution (LTC) and learnable channel attention (LCA) modules, whose combination improves IoU by 3.96%. By integrating multi-scale longitudinal texture features with adaptive channel weighting mechanism, the proposed method significantly enhances segmentation precision for leakage regions, providing an efficient solution for infrastructure safety monitoring.
Sep. 05, 2025Vol. 40 Issue 9 1347 (2025)
Shisong ZHU, Hong GAO, Bibo LU, and Haijing DU
To address the challenges of low accuracy in urban road defect detection caused by varying defect scales and complex environments, this study proposes an improved detection algorithm named YOLOv8-road. The algorithm incorporates a multi-level perception attention (MLPA) mechanism into the backbone network to capture long-range dependencies and extract rich contextual information, enhancing defect feature representation and enabling the model to focus more effectively on defective regions. In the neck structure, a dilated wrapping residual convolution (DWR~~Conv) module is integrated into the C2f structure, forming a new C2f~~D module that improves multi-scale feature extraction and facilitates the capture of fine-grained defect information while reducing interference from road surface backgrounds. Additionally, the algorithm employs the WIoU loss function to optimize bounding box regression, increasing the model’s adaptability to various defect types and mitigating the negative impact of low-quality samples. Experimental results demonstrate that YOLOv8-road achieves a mean Average Precision at 50% (mAP50) of 98.5%, with a precision of 96.8% and a recall of 96.0%. Compared to the original YOLOv8n model, these metrics represent improvements of 4.2%, 3.6%, and 4.7%, respectively. The proposed YOLOv8-road algorithm exhibits superior performance in real-world urban road defect detection tasks, meeting the practical requirements of road maintenance applications.
Sep. 05, 2025Vol. 40 Issue 9 1356 (2025)
Dong WANG, Yabo LUO, Feng ZHANG, and Sui HUANG
Sprinkler trucks frequently operate during nighttime or early morning hours, when ambient illumination is extremely low. Under such conditions, traditional object detection algorithms often perform poorly, leading to frequent pedestrian missed detections or false positives, which in turn may result in unintended spraying or even safety hazards such as collisions. This performance degradation is primarily due to the insufficient brightness, blurred object edges, and weakened color and texture information in low-light images, which hinder effective feature extraction by detection models. Additionally, increased noise levels further compromise the accuracy of model inference. To address these challenges, this paper proposes a lightweight and improved detection algorithm, CORM-YOLO, based on YOLOv8n. The algorithm introduces CPA-Enhancer as a feature extraction network to enhance semantic and texture representation in low-light images; OREPA is employed to optimize convolution modules in the backbone, reducing computational complexity and parameter count; RepHead replaces the traditional detection head to improve robustness and accuracy for small object detection; and MGDLoss is introduced as a knowledge distillation mechanism to enable the lightweight model to learn discriminative features from a teacher model, thus enhancing overall performance. Experimental results show that CORM-YOLO achieves an mAP@50 of 0.845, 3.6% improvement over YOLOv8n, and an mAP@50∶95 of 0.504, with 1.8% gain, while maintaining real-time inference speed suitable for onboard deployment. The proposed method demonstrates strong applicability in ensuring safe operation of sprinkler trucks under low-light conditions and holds promising potential for broader applications in smart city and intelligent transportation systems.
Sep. 05, 2025Vol. 40 Issue 9 1369 (2025)
Qingdong HUANG, Yuhui SU, Yihua LIU, Zihuang CHEN, and Yongqi YAO
Aiming at the problem that the existing human pose transfer methods suffer from image deformation and distortion due to improper feature processing in the encoding stage, a multi-resolution human pose transfer method based on pose-attentional transfer network (PATN) and self-attention mechanism is proposed. Firstly, a pose-guided self-attention module is designed to enhance the weight of the feature channel of the key body region through the multi-head attention mechanism, reduce the influence of background-irrelevant features, and adaptively explore the correlation between the two branch features. Secondly, a multi-scale attention module is added in the decoding stage to enhance the expression of pose information at different scales, effectively improve the fidelity of local details and overall texture. Finally, the ternary pixel loss is introduced to constrain the generated image, which improves the feature consistency and structural consistency of the image. The experimental results are verified on the DeepFashion and Market-1501 datasets. They show that the proposed method is superior to the existing PATN method in terms of structural similarity (SSIM), initial score (IS) and perceptual similarity (LPIPS), and has improved visual perception and edge texture, showing important potential in the downstream task of person re-identification.
Sep. 05, 2025Vol. 40 Issue 9 1381 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20