







Please enter the answer below before you can view the full text.


2025
Volume: 62 Issue 16
45 Article(s)

Zhenghu Zhu, Zhen Su, and Wei Wang
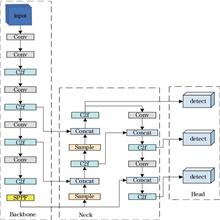
To address the common issues of false detection, low precision, and weak generalization ability in underwater image target detection algorithms, this paper proposes an underwater image target detection algorithm called AWAF-YOLO. First, the anisotropic downsample (ADown) module is used to enhance the network flexibility so as to obtain multi-scale data features more effectively. Second, wavelet transform convolution (WTConv) module is used to reduce the complexity of the model and greatly reduce the computational burden. Then, the spatial pyramid pooling fast and mixed self-attention and convolution (SPPFAC) module is constructed to improve the multi-scale feature discrimination by integrating attention and cross-channel interaction, thus to focus on key feature information more intelligently, and optimize the feature processing process. Finally, the focused intersection over union loss and metric bounding box shape and scale (FSIoU) loss function is introduced to achieve accurate location of complex targets by coupling dynamic focusing with geometric constraints. Experimental results show that compared with the baseline model, the proposed algorithm has an increase of 2.6 percentage points in mean average precision (mAP@0.50∶0.95) in TrashCan1.0 dataset, and an increase of 1.6 percentage points in mAP@0.50∶0.95 in Aquarium dataset. The proposed algorithm has good effectiveness and generalization, provides a new idea for underwater image target detection.
Aug. 25, 2025Vol. 62 Issue 16 1601001 (2025)
Zhengyu Zhang, Mingxuan Li, Boxuan Cheng, Yinxuan Qu, Chunyu Li, and Yuzhu Yang
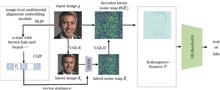
The limited generalization and dataset scarcity of existing generative facial image detection methods present significant challenges. To address these issues, this study proposes a high-quality facial image detection model based on noise variation and the diffusion model. The proposed method employs an inversion algorithm using the denoising diffusion implicit model (DDIM) to generate inverted images with text-based guidance. By comparing the noise distribution differences between real and generated images after inversion, the method optimizes a residual network to identify image authenticity, and enhances both accuracy and generalization. Additionally, a dataset of 10000 high-quality, multi-category facial images is constructed to address the shortage of available facial data. Experimental results demonstrate that the proposed algorithm achieves 98.7% accuracy in detecting generated facial images and outperforms existing methods, enabling effective detection across diverse facial images.
Aug. 25, 2025Vol. 62 Issue 16 1637001 (2025)
Zhilin Gao, Jintao Wang, Qixiang Meng, and Fanliang Bu
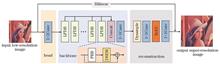
In recent years, the Transformer has demonstrated remarkable performance in image super-resolution tasks, attributed to its powerful ability to capture global features using a self-attention mechanism. However, this mechanism has high computational demands and is limited in its ability to capture local features. To address these challenges, this study proposes a lightweight image super-resolution reconstruction network based on dual-stream feature enhancement. This network incorporates a dual-stream feature enhancement module designed to enhance reconstruction performance through the effective capture and fusion of both global and local image information. In addition, a lightweight feature distillation module is introduced, which employs shift operations to expand the convolutional kernel's field of view, significantly reducing network parameters. The experimental results show that the proposed method outperforms traditional convolution-based reconstruction networks in terms of both subjective visual quality and objective metrics. Furthermore, compared to Transformer-based reconstruction networks such as SwinIR-Light and NGswin, the proposed method achieves an average improvement of 0.06 dB and 0.14 dB in PSNR, respectively.
Aug. 25, 2025Vol. 62 Issue 16 1637002 (2025)
Yufei Rao, Wei Guo, Xiaoyan Song, Gang Liang, Fengqing Cui, and Binjun Ou
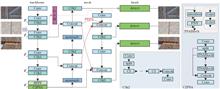
In order to solve the problems of background noise interference, variable scale and low detection accuracy caused by small scale defects in insulator defect detection, an insulator defect detection algorithm based on guided attention and scale perception (GASPNet) is proposed. First, a guided attention module (GAM) is constructed on the backbone network to guide the attention of deep features by using shallow features that have a stronger ability to express small targets, and combining channel and space bidirectional attention to reduce the interference of background noise. Second, in the neck network, a feature enhanced fusion network (FEFN) is proposed to enhance the effective fusion of semantic information and local information by cross-fusing different levels of feature information. Finally, the EIoU loss function is used to define the penalty term by combining the vector angle and position information, which improves the regression accuracy of the detection box and achieves accurate detection of small scale targets. The experimental results show that the mean average precision (mAP@0.5) of GASPNet on the insulator defect detection dataset reaches 94.8%, and the detection speed is 95.3 frame/s, which is significantly better than other detection algorithms. At the same time, the embedded experiments verify that GASPNet still has efficient real-time detection performance under the condition of limited computing resources, which is suitable for practical application scenarios.
Aug. 25, 2025Vol. 62 Issue 16 1637003 (2025)
Tianli Wang, Zequn Zhang, Jie Chen, Dunbing Tang, Lanlan Jiang, and Lingfei Qian
Lidar-scanned point cloud data often suffer from missing information, and most existing point cloud completion methods struggle to reconstruct local details because of the sparse and unordered nature of the data. To address this issue, this paper proposes an attention-enhanced multiscale dual-feature point cloud completion method. The multiscale dual-feature fusion module is designed by combining global and local features, to improve completion accuracy. To enhance feature extraction, an attention mechanism is introduced to boost the network's ability to capture and represent key feature points. During the point cloud generation phase, a pyramid-like decoder structure is used to progressively generate high-resolution point clouds, preserving geometric details and reducing distortion. Finally, a generative adversarial network framework, combined with an offset-position attention discriminator, further enhances the point cloud completion quality. The experimental results show that the complementary accuracy of this method on the PCN dataset improves by 11.61% compared to that of PF-Net, and the visualization results are better than those of other methods in comparisons, which verify the effectiveness of the proposed network.
Aug. 25, 2025Vol. 62 Issue 16 1637004 (2025)
Linglin Bao, Pengge Ma, Long Wang, Jinwang Qian, Zhaoyu Liu, and Qiuchun Jin
The aim of infrared and visible image fusion is to merge information from both types of images to enhance scene understanding. However, the large differences between the two types make it difficult to preserve important features during fusion. To solve this problem, this paper proposes a dynamic contrast dual-branch feature decomposition network (DCFN) for image fusion. The network adds a dynamic weight contrast loss (DWCL) module to the base encoder to improve alignment accuracy by adjusting sample weights and reducing noise. The base encoder, based on the Restormer network, captures global structural information, while the detail encoder, using an invertible neural network (INN), extracts finer texture details. By combining DWCL, DCFN improves the alignment of visible and infrared image features, enhancing the fused image quality. Experimental results show that this method outperforms existing approaches, significantly improving both visual quality and fusion performance.
Aug. 25, 2025Vol. 62 Issue 16 1637005 (2025)
Yu Li, Zhenming Yu, Jiawei Deng, Jiaguang Huang, and Meini Lü
To address issues such as voids and incomplete shapes in three-dimensional (3D) point clouds obtained during the current 3D reconstruction process, a multiscale hybrid feature extraction and activation query point-cloud completion network is proposed. This network adopts an encoder-decoder structure. To extract local information while considering the overall structure, a multiscale hybrid feature extraction module is proposed. The input point cloud was classified into different scales through downsampling, and the hybrid feature information of the point cloud was extracted at each scale. To maintain the high correlation of the point-cloud completion results, an activation query module that retains the feature sequences with high scores and strong correlations is proposed for scoring operations. After the feature sequences are passed through the decoder for point-cloud completion, a complete point cloud is obtained. Experiments on the public dataset PCN indicate that in the comparison of quantitative and visual results, the proposed network model achieves superior completion effects in point-cloud completion and can further enhance the quality of point-cloud completion.
Aug. 25, 2025Vol. 62 Issue 16 1637006 (2025)
Yawei Zhao, Geng Sun, Hongjie Wang, and Haonan Hu
The existing aluminum surface-defect detection algorithms yield low detection accuracy in practical tasks. Hence, this paper proposes an improved YOLOv8s aluminum profile surface-defect detection algorithm (CDA-YOLOv8). First, the 3×3 downsampling convolution in the network was improved using the context guided block (CG Block) module. This enhances the extraction of features from the global context of the target and aggregate local salient features and global features, thus improving the feature generalization ability. Second, the dilation-wise residual (DWR) module was introduced to improve the Bottleneck structure in C2f, thus improving the multiscale feature-extraction capability. Finally, to address the feature-information loss of microdefects on the surface of aluminum profiles, an ASFP2 detection layer was designed, which integrates the small-target detection layer and the scale sequence feature fusion (SSFF) module. The layer was integrated into the neck of YOLOv8s to extract and transfer more critical small-target feature information in small-sized defects, thereby enhancing the detection performance. Experimental results show that the CDA-YOLOv8 algorithm achieves 93.4%, 80.4%, and 88.1% for indicators of precision, recall, and mean average precision, respectively, which are 5.1 percentage points, 2.4 percentage points, and 4.4 percentage points higher than those of the original YOLOv8s algorithm. This algorithm significantly improves detection performance, particularly through its ability to detect microdefects.
Aug. 25, 2025Vol. 62 Issue 16 1637007 (2025)
Jun Li, Fuxing Xu, Jin Liu, Zhongrui Tao, Chengliang Gou, Wenlong Xia, Qian Lu, Xiaowei Xu, and Haima Yang
In this study, a position information detection system based on vector vortex light field is designed to achieve the synchronization of position detection under the vector vortex light field, improve the repeatability of position information detection of the three-lens module, and improve the overall accuracy of the experiment. Under the certain experimental conditions, a camera module containing three polarization angle lenses is designed according to the polarization principle of vector vortex light to obtain images of the position points in the light field, and then the polarization information of the collected points is obtained by the data processing system. Experimental results show that the position information detection system of vector vortex light can correctly obtain the data of each point in the light field, and the detection system meets the requirements of high operability, high positioning accuracy, and robustness fluctuation of less than 1%, and it can be applied to the pre-position collection of vector vortex light navigation.
Aug. 25, 2025Vol. 62 Issue 16 1611001 (2025)
Yu Zhang, Binghui Xia, Lingling Zhang, Huizhen Yang, Xianshuo Li, and Lingzhe Tang
Parity-time (PT) symmetric theory has a good application prospect in the field of optical imaging, but there is a strong nonlinear inverse problem in the design of imaging system, which makes it difficult to obtain the ideal imaging effect. In this study, a Runge-Kutta (RUN) optimizer is used for the design of optical imaging system, and a PT symmetric imaging system based on RUN optimization algorithm is proposed. The design of the PT symmetric imaging system is completed by taking the dielectric constant and thickness of the multilayer film as the optimization parameters, and the sum of reflectance and transmittance at different angles is taken as the objective function of the optimization algorithm. In order to analyze the design effect of PT symmetric imaging system based on RUN optimization algorithm, the optimization results of genetic algorithm (GA) are given. The results show that, compared with GA, the PT symmetric imaging system based on the RUN optimization algorithm can achieve independent optimization without setting the initial parameters, and can achieve the breakthrough of the transition from five layers to three layers when the same effect is obtained. The research results can provide a theoretical basis for the practical application of PT symmetric imaging system.
Aug. 25, 2025Vol. 62 Issue 16 1611002 (2025)
Xindong Zhao, Chunyu Liu, Chen Wang, and Jinghui Huang
Computational imaging for simple optical systems can achieve high-quality imaging by employing a joint imaging paradigm of optics and algorithms. However, when applied to remote sensing imaging, this technology faces the challenge of reconstructing large-scale, globally blurred images because of the rich information characteristics of the image. To address this issue, this paper proposes a generative adversarial network based on a multi-feature fusion Transformer residual module and a multi-scale residual network. Subsequently, using Zemax software, a real-blurred dataset is established for the optical aberrations of a remote sensing camera. Finally, a network restoration experiment is conducted. The peak signal-to-noise ratio (PSNR) of the restored image reaches 33.29 dB, with the structural similarity (SSIM) reaching 0.928, indicating that the restoration quality is close to that of an image formed by an eight-lens optical system. Additionally, in the generalization experiment, the PSNR of the restored image is 31.68 dB, and the SSIM is 0.912, with the network restoration effect being superior to those of similar studies. The experiments verify the high performance of the network proposed in this paper and effectiveness of the computational imaging model, providing a powerful tool for realizing the computational imaging model of a simple optical system for remote sensing cameras.
Aug. 25, 2025Vol. 62 Issue 16 1611003 (2025)
Lei Chen, Hao Liu, Zhiqiang Liu, and Mao Ye
Fresnel structure makes the aperture of the liquid crystal lens greatly increased, while maintaining a faster response speed and a larger adjustable range of focal power. In this paper, the characteristics of a Fresnel liquid crystal lens with an aperture of 2 cm are tested. The Mach-Zehnder interference optical path for testing the lens is optimized, and a clear and complete interference image is obtained. Through analysis and calculation, the focal power of the lens can be adjusted in the range of -1 D?1 D, and the root mean square aberration of the central Fresnel region is less than 0.11λ. The diffraction spot distribution of the lens is tested, and the imaging system after adding the liquid crystal lens is quantitatively analyzed. The resolution of the imaging system is obtained, and the zooming imaging function of the lens is verified. Test results show that the lens has a wide range of focusing ability and good imaging quality.
Aug. 25, 2025Vol. 62 Issue 16 1611004 (2025)
Xuejiao Zhang, Niannian Chen, Ling Wu, and Yong Fan
Existing three-dimensional surface reconstruction methods that rely on gradient fields often exhibit relatively low accuracy in practical applications, primarily due to the absence of physical constraints and their susceptibility to noise interference. To address these challenges, this paper introduces a dual-branch model based on ResUNet, referred to as DS-ResUNet. This model processes gradient information in both the x and y directions through separate dual-branch encoders and incorporates the gradient equation as a physical constraint during the reconstruction process. This approach ensures that the surface reconstruction results adhere to physical laws while effectively capturing surface features.Numerical simulations with added noise demonstrate that, compared to the DUNet method, DS-ResUNet offers significant advantages in predicting surface shapes: the mean squared error is reduced by approximately 60.94% on average; the relative root mean square error decreases by an average of 8.15%; the relative peak-to-valley value is diminished by an average of 52.37%; and there is an increase of 2.19% in the structural similarity index. The proposed DS-ResUNet model has successfully enhanced the accuracy of three-dimensional surface reconstruction across both simulated environments and real-world scenarios.
Aug. 25, 2025Vol. 62 Issue 16 1612001 (2025)
Lanxin Zhang, and De'er Liu
Traditional approaches integrating 3D Gaussian splatting (3DGS) into simultaneous localization and mapping (SLAM) are often limited to static scenes or scenarios with known camera poses. To enable fast and accurate localization and modeling in dynamic environments, this study proposes a tracking and reconstruction method based on motion representation for dynamic scenes. The tracking process computes camera poses via generalized-iterative closest point (G-ICP) and uses an optical flow-guided motion segmentation model to identify dynamic object masks for separating moving objects from static backgrounds. The mapping process leverages red green blue-depth (RGB-D) data and long-range 2D trajectories as data priors, modeling moving objects using the 3D Gaussian splatting framework based on special Euclidean motion bases. Experimental results demonstrate that the optical flow-guided motion segmentation model improves extraction precision by 23.2% compared to the original SAM 2 model. For static scene reconstruction, the proposed method achieves real-time modeling at 98 frame/s on the Replica dataset and 75 frame/s on the TUM RGB-D dataset, and high-precision scene reconstruction is realized on both datasets. In dynamic scenarios, the proposed algorithm reduces absolute trajectory error by 78.30% compared to ORB-SLAM3 algorithm, 61.35% compared to RDS-SLAM algorithm, and 36.05% compared to DS-SLAM algorithm, verifying its superior localization precision and robustness in complex dynamic environments.
Aug. 25, 2025Vol. 62 Issue 16 1612002 (2025)
Peng Wei, Chengyu Liu, Jinhua Wang, Changyu Wu, and Dong Hu
To address the issue of insufficient detection accuracy for hollow disease boundaries in existing rock paintings, this study utilizes thermal infrared imaging to acquire two-dimensional temperature field data. By reconstructing the heat flux density field through Fourier's law, we discover that the temperature distribution along hollow characteristic lines exhibits significant Gaussian distribution characteristics. Accordingly, a Gaussian function model is constructed to characterize the temperature field distribution. Through parameter sensitivity analysis, we propose a width criterion based on thermal accumulation ratio as the core parameter, and establish a quantitative identification standard for hollow boundaries. To verify the effectiveness of proposed method, 50 sets of comparative experiments are conducted using hardness testing and proposed methods in the Damaidi rock paintings. Experimental results demonstrate that the discrete sampling hardness method, limited by probe size and scale graduations, exhibits boundary interpolation errors up to ±1.5 cm and fails to achieve continuous boundary characterization. In contrast, the proposed method enhances the spatial resolution of hollow boundaries through Gaussian model analysis of temperature distribution along characteristic lines, enabling continuous damage characterization.
Aug. 25, 2025Vol. 62 Issue 16 1612003 (2025)
Le Qian, Hang Yuan, Qitai Huang, and Jianfeng Ren
To solve the issue of incomplete single-time measurements in testing large-aperture convex aspheric surfaces by the fringe reflection method, this study proposes a three-dimensional stitching of fringe reflection method based on the rotary table and marking points. In this method, the optical path is simulated by ray tracing first, and the stitching sub-apertures are divided for convex aspheric surfaces with different parameters. Then, the sub-apertures are sequentially measured by the fringe reflection method. Meanwhile, the coordinates of the marking points on the rotary table are obtained by the stereo vision technology, and the coordinates of the marker points are used to unify the sub-apertures into the same coordinate system, so as to complete the preliminary stitching. Finally, the iterative closest point algorithm is utilized to carry out high-precision stitching, and the complete surface is ultimately reconstructed. A three-dimensional stitching measurement system is actually built to test a convex hyperbolic mirror with an aperture of 150 mm, the surface figure of the mirror has the peak to valley (PV) of 1.72 μm and the root mean square (RMS) of 0.39 μm. The stitching result is compared with the full-aperture results from the LuphoScan profilometer, which has the PV of 1.38 μm and the RMS of 0.27 μm, thereby validating the methodological efficacy.
Aug. 25, 2025Vol. 62 Issue 16 1612004 (2025)
Xingzhi Ren, Yu Fang, Diqing Fan, Hao Yang, Minghong Wang, and Qiangbao Ouyang
To address the issues of reduced extraction accuracy caused by blurring or noise in power line images collected for non-contact sag measurement, an Improved-Canny algorithm for power line extraction is proposed in this study. The algorithm comprises three components: image preprocessing, power line edge detection, and power line extraction. First, the region of interest is extracted and converted to grayscale to reduce background interference and highlight power line information. Subsequently, the edge detection accuracy is enhanced by integrating Laplacian of Gaussian filtering, the Scharr operator, and the Otsu method. Finally, Hough transform is utilized to extract linear segments of power lines. The performance of the Improved-Canny algorithm is validated through comparative analysis with traditional algorithms and evaluation using peak signal-to-noise ratio and connected component metrics. The proposed algorithm is validated through practical application in sag measurement. It achieves a power line detection accuracy of 95.425% on 459 images, and the calculated sag values from 50 sampled data points has an error rate of 1.46% on average. The Improved-Canny algorithm meets the requirements for power line extraction and sag measurement.
Aug. 25, 2025Vol. 62 Issue 16 1612005 (2025)
Qixiang Meng, Fanliang Bu, and Qiqi Kou
Super-resolution reconstruction and denoising models facilitate the processing of low-resolution and noisy images in public safety scenarios. While the SwinIR model has achieved notable progress in preserving image details and modeling features in complex scenes, it is still limited by gradient optimization stability, local feature extraction, and computational cost. To address above challenges, our study proposes a hybrid residual attention module-based image super-resolution reconstruction model (EnSwinIR). During training, a perceptual loss function NormRMSE is designed to address the sensitivity of the original mean square error being affected by the absolute size of data pixels. By applying normalization and square root processing, the function enhances stability and learning efficiency. In the local feature extraction module, a four-directional shift convolution is introduced, including up, down, left, and right shifts. This approach reconstructs feature channels through displacement operations, thereby capturing multidirectional contextual information. In addition, a skip connection design combined with a residual module effectively mitigates the gradient vanishing problem often encountered in deep feature extraction. A grouped multi-scale self-attention method is incorporated in the later stages. Input features are evenly divided by channel count, and multi-scale sliding windows are implemented to string an optimal balance between performance, parameter count, and computational complexity. The experimental results indicate that the EnSwinIR model significantly outperforms existing approaches in terms of performance metrics and visual perception for super-resolution reconstruction tasks. For 2× and 4× super-resolution reconstruction, based on multisource testing scenarios, the model achieves an average increase in peak signal-to-noise ratio of 1.9 dB and 2.9 dB, respectively. Furthermore, the average structural similarity index improves by 0.029 and 0.050, respectively. The model also exhibits a reduction in complexity, with the number of parameters decreasing by 27.52% and 27.26% for 2× and 4× tasks, respectively, while the number of floating-point operations per second dropped by 30.72% and 35.65%, respectively. The model demonstrates notable improvements in multisource testing scenarios for the denoising tasks targeting images with noise levels of 15, 25, and 50. The average peak signal-to-noise ratio of the model increases by 3.77, 3.24, and 3.81 dB, respectively. Thus, the images processed by the EnSwinIR model exhibit a more realistic visual appearance and better preservation of local details, thereby demonstrating its potential for application in public safety scenarios.
Aug. 25, 2025Vol. 62 Issue 16 1615001 (2025)
Zhuoyi Chen, Haiyan Sun, Xiaobin Li, and Youlong Zeng
Extreme conditions such as high temperature, strong interference, and highly reflective metal surface in industrial scenes pose significant challenges for LiDAR and imaging devices, leading to point cloud data loss and impacting data integrity. To address these challenges, this paper proposes a similarity-driven framework based on color, elevation, and normal vector gradients. The proposed framework effectively repairs point cloud holes through multi-feature fusion and pixel-level hole location, and achieves precise reconstruction of the load surface using similarity-weighted interpolation and moving least squares smoothing. Experimental results show that the proposed method improves the normalized surface height deviation value, significantly enhancing reconstruction accuracy. The proposed method also demonstrates clear advantages in processing efficiency, enabling fast completion of 3D point cloud reconstruction. The proposed method not only successfully fills point cloud holes but also preserves geometric features, overcoming data loss and surface distortion caused by reflections, thus showing remarkable performance in 3D reconstruction in high-reflectivity environments.
Aug. 25, 2025Vol. 62 Issue 16 1615002 (2025)
Xu Zhang, Dong Wang, and Tao Wang
To address the issue of poor detection performance for small objects in current light detection and ranging(LiDAR) 3D object detection algorithms, this study proposes a 3D object detection algorithm that integrates multi-scale features and grouped convolutions. First, this algorithm uses PV-RCNN++ as the baseline network and employs a 3D multi-scale feature network to fuse features at different spatial resolutions, resulting in 3D feature volumes that contain diverse spatial semantic information. This enhances the model's ability to extract features of the model for objects of different scales and improves detection performance. Then, different channels are grouped on 2D feature maps, and each group is convolved with convolution kernels of different sizes. This produces 2D features with multiple receptive fields of different sizes. Finally, the SimAM attention mechanism is utilized to increase the weight of foreground point features in the second stage, allowing these points to play a more significant role in the refinement of candidate boxes. The experimental results on the KITTI dataset show that the proposed algorithm outperforms current mainstream object detection algorithms. Compared to the PV-RCNN++ baseline network, the detection average precision of pedestrians in easy, moderate, and hard scenarios increases by 3.12, 3.95, and 3.70 percentage points, respectively, and that of cyclists in easy, moderate, and hard scenarios increases by 4.45, 3.52, and 3.08 percentage points, respectively.
Aug. 25, 2025Vol. 62 Issue 16 1615003 (2025)
Yu Ye, Jing Zhang, Aimin Wang, Heng Liu, and Mingju Chen
To address the challenge of 6D object pose detection in unstructured scenes, where foreground-background similarity affects accuracy, we propose a 6D pose detection method based on a cross-attention weighting mechanism. Initially, an RGB-D mask isolates the region of interest (ROI) in the image. RGB semantic features are extracted using the PSPNet module, while global and local point cloud features are extracted from the corresponding region using the PointNet module, enabling dual feature representations for the same object. These RGB semantic and point cloud features are then input into a cross-attention mechanism, which facilitates their deep integration, producing foreground object fusion features with richer contextual information and enhancing the model's understanding of complex scenes. To improve robustness in scenarios with background interference and color overlap, a squeeze-and-excitation (SE) mechanism is introduced into the backbone network, allowing for the distinction between foreground and background regions with similar features. Finally, the 6D pose estimation is further optimized by utilizing both object color features and point cloud geometric transformation features, resulting in improved pose detection accuracy. Comparative experiments demonstrate that, compared to DenseFusion, the proposed method achieves a 2.5 percentage points improvement in the average average distance on the LineMOD dataset and a 1.9 percentage points improvement in the average area under curve on the YCB-Video dataset. Real-world scene tests show an overall centroid deviation of less than 2 mm and angular error below 1.5°, confirming the practical applicability of the proposed method.
Aug. 25, 2025Vol. 62 Issue 16 1615004 (2025)
Hui Liu, Siyuan Wang, Jie Xu, Yue Shen, Jinru Kai, and Xinpeng Zheng
To address semantic confusion in point cloud semantic segmentation algorithms when processing fine details of nursery plants, this paper introduces NurSegNet, a specialized point cloud semantic segmentation network designed for nursery environments. To overcome the challenges of low inter-class variability and high semantic category similarity, the model incorporates a multi-scale feature weighted fusion module that integrates characteristics at various scales to enhance detail recognition capabilities. For comprehensive neighborhood feature extraction, a multi-head self-attention local feature aggregation module implements multi-head self-attention in neighborhood spaces, enriching local feature semantic information. The model also incorporates horizontal distance encoding to expand local feature spatial information. Additionally, a maximum probability sampling method is implemented, which substantially improves sampling efficiency compared to farthest point sampling while maintaining downsampling coverage. Semantic segmentation experiments conducted on a custom nursery dataset demonstrate that NurSegNet achieves a mean intersection over union (mIoU) of 87.89%, an overall accuracy of 97.42%, and a mean accuracy of 94.27%, surpassing conventional point cloud segmentation networks such as PointNet++ and RandLA-Net. This approach effectively addresses semantic confusion and fulfills the requirements for high-precision nursery semantic map construction.
Aug. 25, 2025Vol. 62 Issue 16 1615005 (2025)
Longfei Wang, Likang Fan, Yiqiang Peng, Jie Cao, Liu He, Xulei Liu, and Xiyuan Gao
In response to the current issue that most voxel-based 3D object detection methods have relatively poor detection and recognition performance for small target objects such as pedestrians and cyclists on the road, this study proposes a single-stage 3D object detection network (Voxel-AESC), which integrates voxel texture information with deep semantic features. First, considering the spatial features of voxels under different receptive fields, a multi-scale 3D feature pyramid network module (ISC3D) is designed to enhance the extraction ability of fine-grained local information in 3D space. Then, a module integrating the channel attention and spatial attention (CASA) mechanisms of residual networks is proposed, which enables the network to adaptively extract the most discriminative features of the targets, significantly enhancing the network’s ability to focus on important information. Finally, the algorithm is verified using the KITTI dataset, the average 3D detection accuracies of the three types of targets (Car, Cyclist, and Pedestrian) in the verification set are 81.45%, 68.59%, and 52.91% respectively, while the average bird’s eye view detection accuracies are 89.16%, 71.90%, and 52.56% respectively, and the inference time is 55 ms, which indicates the detection accuracy and efficiency of the proposed algorithm are superior to those of most existing 3D object detection algorithms. Furthermore, the algorithm is deployed on a real vehicle platform to verify its engineering value.
Aug. 25, 2025Vol. 62 Issue 16 1615006 (2025)
Yanwu Ling, Junmin Rao, Yan Li, and Fanming Li
In order to solve the problems of insufficient interpretability, the increase in training cost due to the increase in the number of neurons, and the poor fusion effect of image and point cloud data in the traditional multilayer perceptron (MLP) model, a multi-modal 3D object detection network based on Kolmogorov?Arnold network (KAN) is proposed. In this network, KAN is used as the backbone, and a voxel feature encoder KANDyVFE combined with a fusion layer is designed. The fusion layer uses a self-attention mechanism to dynamically fuse image and point cloud features. In addition, cropping RGB images and rendering to generate colored point clouds also enhance point cloud feature expression. Experimental results on the KITTI data set show that compared with the baseline method SECOND, the mean average precision of the network is improved by 3.78 percentage points in the bird's-eye view detection of automobile category and 3.75 percentage points in the 3D object detection. The visualization results show that the method performs well in reducing false positives and missed detections, and verify the effectiveness of KAN in point cloud applications. The ablation experiments further prove that the proposed network has good detection performance.
Aug. 25, 2025Vol. 62 Issue 16 1615007 (2025)
Chengfeng Bao, Zhuoheng Xiang, Suilian You, Bo Zhang, Bo Lu, Cui Wang, Yan Li, and Shifeng Wang
Autonomous navigation faces significant challenges due to the limited field of view of sensors and occlusions caused by people, which can create obstructed regions. To address this, this paper proposes a dynamic crowd occlusion inference algorithm based on single-wire LiDAR, designed to integrate multimodal sensor data through occlusion inference in order to improve detection and navigation capabilities. The algorithm employs a pedestrian angle grid for interactive insights, a two-stage batch-normalized variational self-encoder to compress visible pedestrian dynamics and obstacle information into a one-dimensional representation, and a LiDAR point cloud map along with environmental background data to efficiently predict occlusion regions. Experimental results show that the algorithm achieves comparable navigation performance to that of a fully observable environment by estimating pedestrians in occluded areas. The success rate remains above 91% without the need to retrain the network for varying participant numbers. Additionally, this algorithm has been successfully applied to a wheeled mobile platform in real-world scenarios.
Aug. 25, 2025Vol. 62 Issue 16 1615008 (2025)
Siqi Huang, Nan Jiang, Hong Liang, Rong Wu, and Haoyan Li
Aiming at the problems of modeling parameters limitation, low efficiency, high labor cost and lack of detail in existing modeling methods, this study proposes a bridge realistic reconstruction algorithm based on an improved 3D Gaussian splatting—FIPT-GS. First, this algorithm constrains the size of Gaussian kernels through a 3D filter to adapt to the complex geometric structure of bridges and reduce artifacts in outdoor scene modeling. Second, it introduces Gaussian approximation of the integral calculation window area to optimize lighting processing and enhance visual realism. Then, it also uses pixel gradient scaling to change the conditions of adaptive density control, so as to deal with the variation of depth of field and amplify the contribution of each pixel. Finally, it optimizes the input value by tensor decomposition to reduce computational difficulty and improve rendering efficiency. The experimental results show that the model quality is significantly improved with only a slight increase in rendering time. The peak signal-to-noise ratio improves by 7.0%, the structural similarity increases by 2.9%, and the learned perceptual image patch similarity decreases by 16.4%. The improved model, which maintains rendering speed, exhibits stronger anti-aliasing capability, provides richer details, and achieves higher image fidelity.
Aug. 25, 2025Vol. 62 Issue 16 1615009 (2025)
Xianlu Song, Xi Kan, Yonghong Zhang, Tiantian Dong, and Haixiao Cao
To address the problems of insufficient scene perception ability and decoupling of the decision-making process from environmental dynamics when a mobile robot performs end-to-end navigation tasks in an unknown environment, we propose a navigation algorithm based on the Transformer architecture for the coupled representation of the target and the scene. First, RGB images from the visual sensor are fused with the physical state information of the target and then embedded and encoded. With FastViT (Fast Vision Transformer) as the core (serving as the main component of the perception module), local and global feature extraction is performed on the input data to learn and generate a scene feature representation that integrates target semantics. Second, a multi-modal input framework is constructed by incorporating LiDAR data to enhance the robot's ability to understand complex scenes, and the SAC (Soft Actor-Critic) deep reinforcement learning algorithm is used for action decision-making. Finally, a reward function for the deep reinforcement learning algorithm is designed based on the safety risk capsule. By dynamically quantifying collision risk in path planning, the safety of the navigation process is improved. Simulation experiments are carried out on the GAZEBO platform. The results show that, compared with mainstream algorithms in the same field, the proposed algorithm achieves a 17.36% increase in average navigation success rate and effectively avoids obstacles. This algorithm provides a new reference for the safe navigation of mobile robots in unknown environments.
Aug. 25, 2025Vol. 62 Issue 16 1615010 (2025)
Ying Li, Lu Dai, Jiaqi Wang, and Jinkai Xu
To solve the problem of low matching accuracy for weak-texture regions in stereo matching of glass-ceramics, this paper proposes a stereo matching algorithm based on scale invariant feature transform (SIFT) feature matching combined with region matching based on local entropy. First, the local entropy map of the image is obtained by introducing Gaussian weighting and gradient amplitude into the local entropy calculation, and the high entropy region is extracted. Then, the improved SIFT algorithm is used to detect the feature points in the high entropy region, and the feature matching results are obtained. Finally, the improved normalized cross correlation (NCC) region matching is used to fuse the results to obtain dense disparity results. Experimental results on datasets show that, the average matching rate of the proposed algorithm is 91.45%, which is 6.89 percentage points, 5.68 percentage points, and 5.75 percentage points higher than that of the semi-global matching algorithm, AD-Census algorithm, and PatchMatch algorithm, respectively. Results indicate that the proposed algorithm can deal with the problem of low matching accuracy in weak-texture regions and improve the matching accuracy.
Aug. 25, 2025Vol. 62 Issue 16 1616001 (2025)
Minghui Li, Shiqing Xu, Changwu Wang, and Shimin Liu
Aiming at the problems of non-overlapping regions between adjacent images, excessive black linear noise, and low image contrast in the process of glass internal texture image stitching, a new method for stitching internal texture images of glass with non-overlapping regions is proposed. First, the images are preprocessed, which includes the region of interest extraction, image correction, non-local means denoising, multi-scale detail enhancement and so on. Then, feature points are extracted using image projection and updated by the Shi-Tomasi algorithm. Finally, the background parts at the stitching boundaries are removed, and image registration is performed based on translation transformation to achieve the stitching of internal texture images of glass with non-overlapping regions. Experimental results show that the proposed method effectively addresses the problem that non-overlapping region between adjacent images leads to the difficulty of stitching, achieving high-quality image stitching with an accuracy of 95.08%.
Aug. 25, 2025Vol. 62 Issue 16 1616002 (2025)
Shaojiang Wei, and Wei Zhang
Stent target segmentation in intravascular optical coherence tomography (IVOCT) images are easily affected by complex backgrounds, leading to unsatisfactory segmentation results. To solve this issue, this study proposes a multiscale fusion attention mechanism stent segmentation network (FAU-Net) that uses U-Net as the primary part of the network structure. First, the wavelet transform downsampling module is used instead of the original pooling layer to fully retain the edge and detail information. Subsequently, a multidimensional fusion attention module is embedded in the encoder block to enhance the model's ability of detecting small target stents. Finally, a multiscale convolution module is designed at the jump connection to help the network localize the target using multiscale features, simultaneously improving the sensitivity of the network to the target surroundings. The proposed FAU-Net is evaluated on a dataset consisting of 5622 optical coherence tomography (OCT) images, and the Dice coefficient reaches 75.91%, which is 4.00 percentage points better than that of U-Net, demonstrating an improved performance.
Aug. 25, 2025Vol. 62 Issue 16 1617001 (2025)
Yifan Fang, Lijie Zhao, Mingxi Jin, Mingzhong Huang, and Zhenpeng Gao
Microscopic observation of indicator microorganisms in activated sludge is an important mean to evaluate the operating status of the sewage treatment process. Microbial communities in the context of activated sludge have a high degree of camouflage characteristics, making it difficult for traditional target detection methods to accurately identify them. To address the challenges of detecting camouflaged microbial targets, this paper constructs a camouflaged activated sludge microorganisms (CASM) dataset, which contains 25 species of activated sludge microorganisms and a total of 1888 images. This paper proposes a novel context-aware camouflage object detection model for microorganisms in activated sludge, referred to as the context-aware search identification network (CA-SINet). The proposed model employs PVT v2 as the backbone network to extract camouflage features and designs a camouflage context sensor to integrate local and global information through multi-scale feature fusion. By fully leveraging contextual information from the surrounding environment, CA-SINet achieves fine-grained detection of camouflaged microorganism features. Experiments are conducted on four public datasets as well as a self-constructed CASM dataset. Experimental results on three public datasets where the optimal results are obtained indicate that, compared with the suboptimal model, S value, weighted F value, and E value of proposed model increase by an average of 0.027, 0.008, and 0.015, respectively, and the average absolute error decreases by an average of 0.008. Experimental results on self-constructed CASM dataset indicate that, compared with the suboptimal model, S value, weighted F value, and E value of proposed model increase by 0.001, 0.010, and 0.006, respectively, and the average absolute error decreases by 0.001. CA-SINet exhibits significant performance advantages in camouflage object detection tasks.
Aug. 25, 2025Vol. 62 Issue 16 1618001 (2025)
Jinghui Huang, Chunyu Liu, Yi Ding, Chen Wang, Guoxiu Zhang, and Yingming Zhao
Aiming at the monitoring requirements of wide-area detection and human activity carbon emission sources, this paper proposes a design scheme for a wide-area high-resolution greenhouse gas imaging spectrometer for multi-gas collaborative detection. By combining the vector aberration theory with free-form surface optimization design, a large field of view and high-resolution system is achieved. Moreover, in response to the problems of an excessively large system size and the susceptibility to interference in spatial layout when both a large field of view and high resolution are considered, a multi-component coated prism color separation technology is proposed. An orthogonal combined color separation prism system is designed as a relay system. After optimization, the overall spatial layout is in the shape of a "windmill", with a compact structure. Finally, the optical system design of the spectrometer with large relative aperture, large swath width, and multiple channels is realized, with a field of view angle of 14° and a spatial resolution of 0.5 km. The imaging quality of each channel's optical system is close to the diffraction limit at the Nyquist frequency. This research provides a feasible solution for the wide-area high-precision detection of spaceborne greenhouse gas imaging spectrometers and the accurate calculation of human carbon emission sources.
Aug. 25, 2025Vol. 62 Issue 16 1622001 (2025)
Leilei Xiong, Xuejun Zhu, Huige Lai, Checao Yu, Kun Mao, Ming Yang, and Da Peng
An improved U-Net model is proposed to improve the efficiency of laser stripe extraction to address the issue of decreased accuracy in weld seam feature extraction caused by noise interference such as arc light in actual welding environments. First, VGG16 is used as the encoder foundation and transfer learning strategies are incorporated to enhance the robustness of the model. Second, in the decoder section, a lightweight cross-layer connectivity network module is designed by combining standard convolution and depthwise separable convolution in a multiscale fusion module as well as by introducing a bottleneck layer structure to reduce the computational burden and parameter count of the model. Additionally, this study proposes a lightweight coordinate attention mechanism to enhance the feature representation of bottleneck layers, thereby improving segmentation quality. Finally, different resolution features between the encoder and decoder are fused effectively via skip connections. Experimental results show that this method performs well in welding environments with arc interference, thus effectively improving segmentation accuracy and demonstrating its value in practical applications.
Aug. 25, 2025Vol. 62 Issue 16 1622002 (2025)
Shengjun Xu, Yiheng Hu, Erhu Liu, Ya Shi, Xiaohan Li, and Zongfang Ma
This study proposes a weld defect detection method that addresses the low recognition accuracy observed in industrial weld surface defect detection tasks owing to the small target size and high similarity to the background. The proposed weld defect detection method is based on improved YOLOv9. First, a dynamic sparse attention module is introduced to improve the feature extraction network of the main branch. This module enables the ability of the main branch network to extract features of targets and backgrounds in complex backgrounds via the long-distance content awareness of self-attention mechanisms and flexible computation allocation. Subsequently, an adaptive dynamic convolution module is incorporated into the backbone network of the auxiliary branch, which dynamically adjusts the convolution position based on learned offsets to accurately locate and fit target features, thereby improving the detection performance for small targets. Finally, an MPDIoU function is proposed to improve the loss function, maximizing the overlap between predicted bounding boxes and true bounding boxes, which enhances the accuracy of weld defect detection and the convergence speed of the network. Results of the experiments conducted on the self-constructed weld defect data set, WELD-DETECT, show that compared to the baseline network YOLOv9, the proposed DA-YOLO network achieves 4.9 percentage points improvement in detection accuracy and 5.5 frame/s increase in detection speed.
Aug. 25, 2025Vol. 62 Issue 16 1622003 (2025)
Fangbin Wang, Hualin Mao, Xue Gong, Darong Zhu, Weisong Zhao, and Ping Wang
Dust on the surface of photovoltaic (PV) modules significantly reduces their power generation efficiency and may also corrode the protective glass surface of the panels, necessitating monitoring and cleaning. However, existing operational and maintenance detection methods for PV power stations struggle to accurately assess the dust density on PV modules, which brings difficulties to the cleaning work of PV modules. This study proposes an image dark channel prior-based detection method of dust density on PV module surface. First, the relationship between the transmittance of dust on PV module surfaces and the dust density is derived based on the assumption of dust spherical particles. Subsequently, the calculation method for the transmittance of dust on PV module surfaces based on the image bright primary color is presented by the prior knowledge of the dark channel. Finally, an experimental platform is set up and several indoor dust density detection experiments on PV module surfaces are conducted. The experimental results indicate that there exists a clear exponential function relationship between the transmittance calculated using the image dark channel prior knowledge and the dust density. Moreover, the calculated dust density has little relation with the irradiance from light source, and the accuracy of the established model increases first and decreases later with the increase of observation angle and incident angle, which are recommended to take between 30°‒40° for practical application.
Aug. 25, 2025Vol. 62 Issue 16 1624001 (2025)
Qiang Zhang, Zhiyuan Gao, Biao Ma, Jing Gao, and Jiangtao Xu
Lateral overflow integrated capacitor (LOFIC) technology is an important method to improve the dynamic range of complementary metal-oxide semiconductor (CMOS) image sensors. However, the charge overflow mechanism in LOFIC pixels has not been thoroughly studied. An analytical model is proposed for the charge overflow process in LOFIC pixels. The electric field superposition principle is used to analyze the potential barrier along the charge overflow path. The regulation mechanism of the transfer gate voltage and light intensity on the charge overflow process is studied by iterative simulation method. The results show that the full well capacity of the pinned photodiode can be increased by reducing the transfer gate voltage and increasing the light intensity. In addition, the charge accumulation rate and charge overflow rate increase with increased illumination but are not affected by the transfer gate voltage. The model is verified with technology computer-aided design (TCAD) simulations and experimentally tested on a 100 nm-thick chip fabricated via CMOS process. The simulation and measurement results exhibit good consistency with the proposed model.
Aug. 25, 2025Vol. 62 Issue 16 1625001 (2025)
Keping Wang, Bingqian Suo, Gaopeng Zhang, Yi Yang, and Wei Qian
To address the challenges of small object detection that information loss during the down-sampling and neglect of target details by deep features, this research proposes a small object detection algorithm based on the spatial-frequency separated cross-attention Swin Transformer (SF-SCST). The SF-SCST algorithm distinguishes objects from the background in the frequency domain through the wavelet decomposition and feature concatenation (WDFC) module and a feature channel spatial-frequency decomposition and fusion (SFDF) module. Then, these features are fused with spatial domain information to enhance the target contour, effectively preserving small object features during down-sampling. Additionally, the cross-self attention Swin Transformer (CS-swin) module performs dual-attention calculation on deep and shallow features to supplement the small object information lost in the deep features and to capture the contextual information of targets. Experimental results show that the SF-SCST algorithm achieves the mean average precision with intersection over union of 0.5 (mAP50) of 69.3% and 46.0% on the UAV-DA and VisDrone datasets, respectively. The performance of proposed algorithm is superior compared with the other six algorithms, significantly improving the detection accuracy of small objects.
Aug. 25, 2025Vol. 62 Issue 16 1628001 (2025)
Yang Zeng, Feng Xu, Jihua Ming, Junjie Shen, and Ran Liu
Traditional 3D light detection and ranging (LiDAR)-based simultaneous localization and mapping (SLAM) algorithms often encounter point cloud distortion and mismatching issues in degraded environments in which geometric features are sparse or absent, leading to decreased mapping and localization accuracy. To address these problems, this study proposes a LiDAR-inertial SLAM system based on continuous motion correction and intensity assistance. First, the system utilizes inertial measurement unit measurement data and spherical linear interpolation to correct point cloud distortion. Then, it leverages point cloud intensity information to extract geometric features in degraded environments, ultimately achieving high-precision self-localization and generating a globally consistent 3D map. Results of experiments using KITTI and SubT-MRS datasets show that the proposed method can realize LiDAR-based localization and mapping in degraded environments, with improvements in localization accuracy of 6.8% and 12.3%, respectively, compared to existing techniques. It also enables mapping with richer details in degraded environments.
Aug. 25, 2025Vol. 62 Issue 16 1628002 (2025)
Qingjiang Cheng, and Lu Li
Aiming at the problems of remote sensing images, such as complex background environment, low resolution and insufficient feature information, which lead to low target detection precision, this study proposes a small target detection algorithm based on improved YOLOv8n, REI-YOLOv8n. First, in the backbone extraction network, a refined feature extraction module is designed to strengthen the network's ability of capturing subtle features to differentiate between complex backgrounds. Second, an enhanced feature fusion network framework, EiFPN, is constructed in the neck network, and an attention-based fusion module is designed to realize the efficient fusion of multi-scale features to improve the performance of small target detection. In addition, in order to fully utilize the high-resolution spatial information, a fourth detection layer is added to further strengthen the detection capability of small targets. Finally, a new bounding box regression loss Inner-PIoU is designed to enhance the localization performance of the model and accelerate the convergence speed. The experimental results show that the mAP@0.5 (mean average precision at 50% intersection over union) of the improved REI-YOLOv8n algorithm on the datasets NWPU VHR-10 and Visdrone2019 reaches 0.904 and 0.369, respectively, which is 3.7% and 6.0% higher than that of the YOLOv8n, and effectively improves the detection performance of the network on small targets in remote sensing.
Aug. 25, 2025Vol. 62 Issue 16 1628003 (2025)
Lei Zhang, Xue Ding, Jinliang Wang, Shuangyun Peng, and Rongxiang Luo
Convolutional neural networks (CNNs) and visual Transformer face the problems of difficulty in effective fusion and low segmentation accuracy when fusing global and local features in semantic segmentation of high-resolution remote sensing images. This paper proposes a highly fused hybrid network RTHNet. RTHNet adopts an encoder and decoder structure, and uses ResNet50 as the backbone network in the encoding stage to effectively extract local features in remote sensing images. An attention adaptive fusion module (AAFM) is designed to achieve efficient integration of multi-level attention features between the encoder and decoder. In the decoding stage, a global-local contextual Transform module (GLCTB) is designed to pay attention to global context information and local details at the same time. A detail enhancement module (DEM) is proposed at the end of the decoder to ensure the precision and accuracy of the segmentation results by refining the semantic consistency and spatial detail information between features. Experimental results on the Potsdam, Vaihingen, and WHDLD datasets show that, the mean intersection over union (mIoU) of RTHNet reach 79.58%, 73.61%, and 60.37%, respectively. Compared with the current mainstream segmentation networks such as MAResU-Net and UNetFormer, RTHNet has significantly improved the segmentation accuracy.
Aug. 25, 2025Vol. 62 Issue 16 1628004 (2025)
Yihan Zhou, Lan Cui, Cheng Zhang, Shuo Li, and Pei Fu
Written documents serve as crucial evidence in legal cases. The examination of suspicious documents in litigation is crucial for ensuring the authenticity, legitimacy, and validity of documents. As an important supplement to nondestructive examination of suspicious documents, hyperspectral imaging (HSI) technology integrates advanced imaging and spectral analysis technologies, which can rapidly obtain information on the composition of the document material as well as potential traces of tampering and forgery. Furthermore, it can provide accurate data on physical and chemical attributes for the examination of the authenticity of suspicious documents. In this study, a hyperspectral imaging system, image characteristics, and data analysis methods are introduced. Additionally, research progress of HSI in suspicious document inspection is reviewed from four perspectives: document material inspection, document manufacturing time inspection, document alteration inspection, and fuzzy record reading. Finally, the paper outlines the future development directions for the application of HSI technology in document examination, with the goal of offering valuable references for forensic examination of documents.
Aug. 25, 2025Vol. 62 Issue 16 1600001 (2025)
Nan Wang, Hua Wang, Dejian Wei, Liang Jiang, Peihong Han, and Hui Cao
Brain tumor is a serious central nervous system disease, with an increasing incidence rate that poses a significant challenge to global public health security. Due to the complexity of tumor growth site and the sensitivity and heterogeneity of surrounding tissues, treatment of brain tumors is often limited. U-Net and its variants have demonstrated excellent performance in brain tumor image segmentation and are therefore commonly used to assist in the diagnosis of brain tumors. First, this study summarizes U-Net improvement strategies for brain tumor image segmentation tasks, focusing on methods such as attention mechanisms, enhanced residuals, skip connections, and Transformer fusion, and analyzes their improvement effects on Dice coefficient, sensitivity, and specificity. Additionally, the study discusses the frontier research directions of U-Net, such as multimodal fusion, generative adversarial networks (GAN) applications, and self-supervised learning, to address the limitations of current technologies and expand the application scenarios of brain tumor image segmentation. Finally, the study explores the current challenges and issues in the field of brain tumor image segmentation and provides insights into future research directions.
Aug. 25, 2025Vol. 62 Issue 16 1600002 (2025)
Hongyi Ge, Shun Wang, Yuying Jiang, Chunyan Guo, Yuwei Bu, Shilei Wei, Yuan Zhang, and Yuxin Wang
In recent years, terahertz imaging has been widely used in biomedicine, security screening, and agricultural product inspection. However, the resolution of conventional terahertz far-field imaging techniques is limited to the millimeter level because of the diffraction limit. Terahertz near-field imaging techniques can break through the diffraction limit and achieve high temporal and spatial resolution imaging at the micro-nano level. This paper first outlines the basic principles of terahertz near-field imaging technology and subsequently details several methods to realize it. In addition, applications of terahertz near-field imaging technology in biomedicine, material science, and cultural relics detection are introduced. Finally, future challenges and development directions of terahertz near-field imaging technology are outlined. With continuous development and improvement, terahertz near-field imaging technology is expected to expand as part of deeper applications in additional fields.
Aug. 25, 2025Vol. 62 Issue 16 1600003 (2025)
Xinnuo Xu, and Kaikai Li
In the early stage of the investigation, the rapid detection and examination of suspicious stains at crime-related scenes are crucial. Based on the frequent use of herbicides to poison humans and livestock in grassroots public security cases in recent years, easily purchased and common herbicides are combined with white paper, fabric, and corn. All samples are scanned using a pulsed terahertz time-domain imaging system, and the reflection imaging images in the terahertz band of all samples and frequency domain spectra of some samples are obtained. The characteristics and differences between these images and spectra are analyzed and summarized. ImageJ software and the Otsu algorithm are used to process some images, and median filtering, histogram equalization, and sharpening are used to enhance the imaging results. This study validates the feasibility of using pulsed terahertz time-domain imaging technology combined with machine learning to detect suspicious stains non-destructively and effectively in grassroots cases.
Aug. 25, 2025Vol. 62 Issue 16 1630001 (2025)
Zhihui Liang, Xinyi Wu, and Wei Wu
In the field of digital radiography (DR) testing, high-resolution DR images facilitate better detection of internal defects and structural information in workpieces. However, the increase of resolution typically leads to higher equipment costs and reduced detection efficiency, while existing reconstruction methods suffer from suboptimal results and low efficiency, failing to meet the testing demands of industrial applications. To address these limitations, this study proposes a latent space diffusion model for DR image super-resolution enhancement. The algorithm employs a two-stage framework: in the first stage, a lightweight autoencoder constructed with a fully convolutional neural network maps input images to low-dimensional potential space; in the second stage, the denoising diffusion implicit model is utilized for detail reconstruction in the latent space, conditioned on the latent feature vectors. To compensate for lost high-frequency information in the latent space, a frequency-domain information-guided cross-attention structure is designed within the diffusion model's denoising network, which incorporates four frequency components obtained through wavelet transform as additional conditional inputs to enhance global modeling capabilities. Finally, the autoencoder and diffusion model are trained separately using optimized perceptual loss functions. Experimental results on the self-constructed dataset demonstrate that the proposed algorithm achieves significant advantages in both reconstruction quality and processing speed compared to various mainstream methods, confirming its effectiveness for DR image super-resolution enhancement.
Aug. 25, 2025Vol. 62 Issue 16 1634001 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20