







Please enter the answer below before you can view the full text.


2025
Volume: 45 Issue 11
36 Article(s)

Hui Yang, Chengfeng Wen, Jiacheng Weng, and Haifeng Li
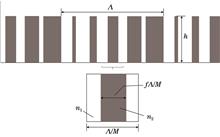
ObjectiveIn recent years, augmented reality (AR) display systems have attracted extensive attention. Diffractive waveguides have become the preferred choice for commercial AR devices. However, current AR-HMDs still face challenges in simultaneously achieving a large field-of-view (FOV) and high angular uniformity. The FOV determines the user’s viewing angle range, and uniformity is a key factor affecting the optical performance of the waveguide display system. Therefore, it is of great significance to design a grating that can meet the requirements of large FOV and high angular uniformity.MethodsBased on the propagation phase modulation principle and the effective medium theory, we designed the initial structure of the grating. We divided a grating period into M equal parts, and calculated the refractive index of each sub-period according to the equivalent refractive index theory. We also discussed the number of sub-periods in a cycle to determine the most reasonable initial structure. We used the rigorous coupled-wave algorithm (RCWA) to calculate the diffraction efficiency of the grating. We adopted the multi-objective genetic algorithm (NSGA-II) based on the Python evolutionary computing framework Geatpy. The period, height, and the width and spacing of the nanopillars were used as optimization variables to perform multi-objective collaborative optimization on the optical performance (uniformity and diffraction efficiency) under TE polarization. Considering the actual application of AR head-mounted devices, we set the horizontal FOV to 30° and the vertical FOV to 50° according to the aspect ratio of mainstream displays. We optimized the uniformity of both TE and TM polarizations, with each polarization state accounting for 50%. The metasurface grating was fabricated using processes including plasma-enhanced chemical vapor deposition (PECVD), electron-beam lithography(EBL), and inductively coupled plasma (ICP) dry etching. We observed the processed structure using a scanning electron microscope. For testing, we measured the diffraction efficiency using a power meter and a specific optical path. We also tested the FOV range of the grating by setting the incident angles and calculating the positions of the out-coupling gratings.Results and DiscussionsBy simulation, we found that dividing the period into three sub-periods as the initial structure was the most appropriate. The initial structure had an average diffraction efficiency of 0.6649 and a uniformity of 70.77% within the FOV, indicating that there was room for improvement. After optimization by the genetic algorithm, we obtained a structure with an angular uniformity of 90.27% and an average diffraction efficiency of 0.72 under TE polarization, which was a 8.3% increase in diffraction efficiency and a 27.5% increase in uniformity compared with the initial structure (Fig. 4). For the case of simultaneous incidence of TE and TM polarized light, the overall uniformity exceeded 88%, and the average diffraction efficiency reached 0.56. The diffraction efficiency distribution of the full FOV was shown in Fig. 5. When the grating height h varied within ±15 nm, the average diffraction efficiency and uniformity were greater than 0.517 and 82.36%, respectively. Similar results were obtained for the variations of other parameters such as the width and spacing of the nanopillars (Table 2, Fig. 6). In the wavelength band of 600?680 nm, the lowest diffraction efficiency of different FOVs was greater than 0.4, the average diffraction efficiency was greater than 0.52, and the angular uniformity was greater than 83% (Fig. 7). The processed grating had a structure with a period uniformity, and the size error was within ±3 nm compared with the processing layout. The measured angular uniformity was 91.23%, which was consistent with the simulation results. The average diffraction efficiency was 0.366, slightly lower than the simulation result due to processing and interface reflection losses. The grating could reach a diagonal FOV of 50°, and the energy ratio of the three out-coupling patterns was 1∶0.991∶0.995, indicating uniform output energy (Fig. 12).ConclusionsWe designed a multi-nanopillar metasurface grating structure based on the equivalent refractive index theory and the multi-objective genetic algorithm. Under TE polarization, it achieved an angular uniformity of over 90% and an average diffraction efficiency of 0.72 in the 30° horizontal FOV. For the simultaneous incidence of TE and TM polarized lights, it maintained an angular uniformity of 88% and an average efficiency of 0.56 in the 56° diagonal FOV. The vertical nanopillar structure has excellent structural stability, overcoming the process bottleneck of traditional structures that are prone to collapse. Through processing and testing, we achieved a processing accuracy with a key size error within ±3 nm. The measured diffraction efficiency uniformity reached 91.23%, and the diagonal FOV was extended to 50°. This grating structure is expected to be applied to in-coupling and out-coupling of AR display diffractive waveguides to achieve a wide FOV and high-angular-uniformity display effect. Future work can focus on improving grating performance, improving processing technology, and expanding application scenarios.
Jun. 18, 2025Vol. 45 Issue 11 1105001 (2025)
Hui Chen, Shiyi Cai, Pufeng Gao, Beilei Wu, Jianyong Zhang, Yan Liu, Fengping Yan, Desheng Chen, Han Zhang, and Muguang Wang
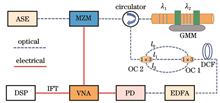
ObjectiveFiber optic magnetic sensors have gained significant interest due to their advantages of miniature size, resistance to electromagnetic interference, and the ability to operate under harsh conditions. Optical fiber-based sensors are usually demodulated using an optical spectrum analyzer to monitor wavelength shifts or power variations. However, the demodulation speed and resolution are limited by the capabilities of the measurement equipment. Recently, optical carrier-based microwave interferometry (OCMI) has gained attention for its advantages in sensing applications, including insensitivity to polarization variation, high signal-to-noise ratio, and clear interference fringes. These features make OCMI ideal for interrogating FBG sensors. However, fiber optic sensors are typically sensitive to multiple parameters. For instance, fiber optic magnetic field sensors combining giant magnetostrictive material (GMM) with fiber Bragg grating (FBG) are sensitive to both temperature and magnetic field. Therefore, although the OCMI demodulation technique enhanced by the vernier effect increases sensitivity to the target parameter, it also amplifies errors caused by interfering factors, limiting the application of such FBG magnetic field sensors. The proposed sensing system features high sensitivity, a simple setup, and low temperature cross-sensitivity, and holds potential value in magnetic field sensing applications.MethodsThe sensing unit is composed of GMM-FBG and FBG. The system mainly consists of the sensing unit, a three-arm Mach-Zehnder interferometer, and dispersion-compensated fiber, forming a six-tap incoherent microwave photonic filter (MPF). A vector network analysis (VNA) is used to collect the system’s frequency response, and an inverse Fourier transform (IFT) is applied to obtain the MPF’s time-domain response. This response consists of a series of pulses with different delays. By applying a gate function to any two pulses and then performing a Fourier transform (FT), the microwave interferogram of a specific RF Fabry-Perot interferometer (FPI) can be reconstructed. The vernier effect is achieved by superimposing two reconstructed FPI microwave interference spectra. Magnetic field and temperature changes can then be demodulated by tracking the frequency drift of the dip in the envelope signal of the superimposed spectrum. In temperature sensing, the sensitivity of the vernier envelope is minimized, while an enhanced vernier effect is applied in magnetic field sensing. This allows for high-sensitivity magnetic field sensing with low temperature cross-sensitivity. In the experiment, the sensor unit is placed in a coil for magnetic field detection and in a temperature control box for temperature measurement. To evaluate sensing performance, the magnetic field is increased in 10 mT steps from 20 to 50 mT, which is the optimal operating range of the probe, by adjusting the power supply current.Results and DiscussionsThe frequency response of the sensing system is collected by the VNA. By applying IFT to the microwave spectrum, a time-domain response of the sensing system is obtained. Using the gate function, a selected time-domain signal is used to reconstruct the microwave interference spectrum via FT. After applying the vernier effect, the free spectral range of the envelope signals required for magnetic field and temperature demodulation are 350 MHz and 99 MHz, respectively (Fig. 4). When the magnetic field increases from 0 to 50 mT, the dip frequency of the envelope signal shifts from 3.259 to 3.5946 GHz [Fig. 5(c)]. Fitting results show a magnetic field sensitivity of 6.792 MHz/mT, with a correlation coefficient (R2) of 99.9% [Fig. 5(f)]. This sensitivity is 43 times higher than that achieved by tracking the frequency drift of a single interference spectrum [Fig. 5(e)]. When the temperature increases from 35.0 ℃ to 39.5 ℃, fitting results show that temperature sensitivity decreases to 0.040 MHz/℃, with an R2 of 90% [Fig. 6(f)]. This reduces the magnetic field demodulation error caused by temperature crosstalk to 5.9 μT in the range of 35.0?39.5 ℃.ConclusionsWe propose a magnetic field sensor with low temperature cross-sensitivity based on the vernier effect and OCMI. The sensor system converts the wavelength shift in the FBG, caused by magnetic field and temperature changes, into dip frequency shifts of the reconstructed interference spectrum. When the magnetic field changes, the reconstructed interference spectra of FPI 1 and FPI 2 shift in opposite directions, resulting in amplified magnetic sensitivity in the superimposed spectrum. When temperature changes, the interference spectra of FPI 3 and FPI 4 move in the same direction, thus minimizing the sensitivity of the vernier envelope to temperature. Experimental results demonstrate a magnetic field sensitivity of 6.792 MHz/mT within the range of 0?50 mT, and a temperature-induced magnetic field demodulation error reduced to 5.9 μT in the range of 35.0?39.5 ℃. In summary, the proposed OCMI demodulation scheme combined with the vernier effect offers a simple system configuration and low temperature cross-sensitivity, providing an effective solution for fiber optic magnetic field sensing in applications such as resource exploration and aerospace.
Jun. 24, 2025Vol. 45 Issue 11 1106001 (2025)
Pengcheng Zhang, Hui Yang, Jihui Sun, Lin Jiang, and Lianshan Yan
ObjectiveHigh-speed PAM4 direct-detection optical transmission systems are highly susceptible to multipath interference (MPI), which induces elevated bit error rates (BERs) even under normal link power conditions. Conventional impairment compensation algorithms, such as feed-forward equalization (FFE), exhibit limited capability in mitigating MPI. Consequently, MPI has emerged as one of the primary limiting factors for the performance of high-speed PAM4-based intensity modulation and direct detection (IMDD) systems. In the time domain, MPI causes stochastic signal fluctuations, while in the frequency domain, it manifests as low-frequency noise. To address these challenges, the exploration of novel MPI suppression scheme is essential for advancing the reliability and efficiency of next-generation optical communication systems.MethodsMPI induces stochastic temporal fluctuations in optical signals, with the fluctuation amplitude escalating proportionally to signal intensity levels. Building on the characteristic of MPI, we propose an MPI suppression scheme based on joint probabilistic shaping and peak-mean compression (PS-PMC). At the transmitter, probabilistic shaping is employed to reduce the occurrence probability of high-level symbols, thereby decreasing the symbol error rate. At the receiver, from a time-domain perspective, the signal is compressed based on the peak and mean values of each data frame, effectively mitigating signal fluctuations induced by MPI.Results and DiscussionsUnder laser linewidths of 0.1 MHz, 1 MHz, and 10 MHz, the proposed PS-PMC algorithm improves the MPI tolerance by 6.1 dB, 4.9 dB, and 3.7 dB, respectively. Compared to the baseline A1 algorithm, these enhancements correspond to additional gains of 2.2 dB, 2.0 dB, and 1.6 dB under the same linewidth conditions. Therefore, the PS-PMC algorithm significantly enhances the system’s tolerance to MPI. The receiver-side PMC algorithm achieves performance comparable to the A1 algorithm. However, as the laser linewidth increases, the MPI suppression effectiveness of both algorithms diminishes. This occurs because larger laser linewidths increase the frequency of MPI-induced temporal signal fluctuations, which reduces the efficacy of the PMC algorithm that relies on per-frame peak and mean processing. At the transmitter side, probabilistic shaping performs worse than the receiver-side PMC algorithm under small laser linewidth conditions. However, its performance remains more stable across varying laser linewidths, and it even outperforms the PMC algorithm when the laser linewidth is large. This is because probabilistic shaping directly adjusts the probability distribution of PAM4 symbol levels at the transmitter, reducing the proportion of high-level symbols. Consequently, it decreases the number of high-level symbol misinterpretations at the receiver, making it less affected by laser linewidth variations.ConclusionsMPI has a significant impact on the performance of high-speed PAM4 direct detection optical transmission systems. We propose an MPI suppression scheme based on joint probabilistic shaping and peak-mean compression (PS-PMC). At the transmitter, probabilistic shaping is employed to reduce the occurrence probability of high-level symbols, thereby decreasing the symbol error rate. At the receiver, from a time-domain perspective, the signal is compressed based on the peak and mean values of each data frame, effectively mitigating signal fluctuations induced by MPI. Simulation results demonstrate that under different laser linewidths and signal-to-interference ratio (SIR) conditions, the proposed PS-PMC scheme significantly enhances the system’s MPI tolerance. For laser linewidths of 0.1 MHz, 1 MHz and 10 MHz, the proposed scheme improves the MPI tolerance of a 25 Gbaud PAM4 signal transmitted over 15 km by 6.1 dB, 4.9 dB and 3.7 dB, respectively.
Jun. 20, 2025Vol. 45 Issue 11 1106002 (2025)
Longyao Xu, Zhengxuan Li, Hao Li, Yuanzhe Qu, Yingxiong Song, Yingchun Li, and Yanyi Wang
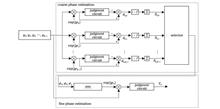
ObjectiveThe advancement of satellite communications has revealed limitations in traditional microwave communications due to restricted bandwidth resources and transmission capacity. While optical fiber communications offer alternatives, they present challenges in deployment costs and maintenance, particularly for intersatellite and deep space applications. Space coherent optical communication enables information transmission through phase modulation and coherent detection technology, utilizing light’s amplitude, frequency, and phase dimensions. This technology increases single-channel capacity to more than tenfold compared to traditional intensity modulation techniques. The system offers advantages including narrow laser emission angles, enhanced confidentiality, minimal emission aperture, and flexible deployment capabilities. However, atmospheric channels significantly constrain space optical communication development. The extended communication distance results in substantial laser signal energy loss, necessitating high receiver sensitivity in the absence of relays. Additionally, atmospheric turbulence causes fluctuations in the atmospheric refractive index, leading to laser beam intensity flickering and phase disturbances. These effects introduce random carrier phase disturbances at the receiving end, increasing the likelihood of signal phase misidentification. Digital signal processing algorithms are essential for compensating received signals to mitigate atmospheric channel impacts. Blind phase estimation, while effective for signal compensation, requires optimization due to its high complexity.MethodsThe optimization of blind phase estimation algorithms follows two primary approaches: modifying the BPS function’s error function to reduce multiplier usage, and implementing a two-step phase estimation through coarse and fine estimation. The first approach effectively reduces computational complexity but often compromises the BPS algorithm’s estimation accuracy, resulting in significant error vector amplitude performance loss. The second approach maintains estimation accuracy while moderately reducing computational complexity. However, these methods have not addressed the fundamental issue of the BPS algorithm’s high computational complexity, as numerous phase test angle calculations remain necessary. This paper addresses computational complexity reduction through optimization of the phase test angle search strategy. The methodology primarily employs piecewise parabolic interpolation for secondary estimation. The process begins with traditional BPS for coarse phase estimation, followed by piecewise parabolic interpolation iteration for refined phase estimates, with accuracy determined by predetermined termination conditions.Results and DiscussionsThe piecewise parabola interpolation algorithm demonstrates comparable performance to traditional BPS in estimated angle accuracy while achieving significant computational complexity reduction. Indoor coherent optical communication experiments utilizing 5 Gbit/s QPSK verify the algorithm’s estimation effectiveness across different phase intervals [Fig. 4(a)]. Results indicate that π/16 and π/32 systems achieve 0.5 dB sensitivity improvement compared to π/8 system. Subsequent testing with π/16 phase interval compares BPS and P-BPS algorithm sensitivities at various phase test angles [Fig. 4(b)], revealing 0.5 dB sensitivity improvement at reduced computational complexity. The algorithm shows substantial computational efficiency improvements compared to previously published methods (Table 1). Error vector amplitude comparisons demonstrate enhanced accuracy of the P-BPS algorithm while maintaining reduced computational complexity (Fig. 5). Field verification experiments achieve spatial coherent optical communication over 29 km. Comparative analysis of bit error rate performance between P-BPS and BPS algorithms, with received optical power between -30 dBm and -40 dBm, demonstrates superior P-BPS performance under identical test angles (Fig. 8).ConclusionsThis paper presents a low-complexity P-BPS algorithm addressing the computational complexity challenges of the BPS algorithm in phase estimation. The algorithm enhances the BPS exhaustive search method through piecewise parabolic interpolation, implementing initial rough estimates with minimal test phase angles followed by interpolated phase test angle refinement. This approach eliminates comprehensive angle testing while improving receiving sensitivity and reducing computational complexity. Experimental validation through indoor coherent optical communication and field testing demonstrates P-BPS’s superior capability in correcting phase offset with reduced computational requirements compared to traditional BPS. The algorithm proves particularly effective in conditions of significant phase noise caused by atmospheric turbulence, requiring fewer phase test angles than traditional BPS for accurate estimation. P-BPS thus represents an efficient, practical solution for phase estimation in spatial coherent optical communication.
Jun. 24, 2025Vol. 45 Issue 11 1106003 (2025)
Jie Zhang, Zhuo Chen, Qi Yang, Xiaoxiao Dai, and Deming Liu
ObjectiveWith the rapid advancement of emerging technologies such as artificial intelligence, cloud computing, 6G mobile communications, and data center interconnection, modern optical communication systems are facing unprecedented challenges in transmission capacity, speed, and distance. In particular, long-haul and unrepeatered transmission systems are critically constrained by the accumulation of Kerr nonlinear effects—especially self-phase modulation (SPM)—as transmission distance and launch power increase. This accumulation causes severe signal distortion and elevated bit error rates, significantly affecting system stability and reliability. Although digital backpropagation (DBP) and optical phase conjugation (OPC) have been proposed to mitigate such impairments, their practical application in unrepeatered links is limited due to excessive hardware complexity or strict requirements on link symmetry. To address these issues, a low-complexity, hardware-independent compensation scheme called Phase Conjugate Twin-Wave Optimization for Unrepeatered Transmission (PCTWO-UT) is proposed, tailored for long-distance fiber links without inline amplification.MethodsThe core idea of the PCTWO-UT scheme is to construct a pair of conjugated signals over orthogonal polarizations (x and y polarizations) at the transmitter. These signals propagate through the fiber and undergo opposite nonlinear evolutions. At the receiver, they are coherently summed to cancel first-order Kerr nonlinear distortions. Compared with traditional PCTW methods, which are sensitive to polarization variations, PCTWO-UT introduces mutually uncorrelated QPSK training sequences in both polarization paths. This design enables full-rank channel estimation under polarization rotation conditions and resolves the convergence issue of constant modulus algorithm (CMA) based blind equalizers, which may fail when the input signal matrix is rank-deficient.Furthermore, in high-speed or high-dispersion transmission scenarios, pulse broadening breaks the dispersion and power symmetry required for effective nonlinear compensation. To address this problem, the scheme incorporates distributed Raman amplification. By configuring pump wavelengths and power levels, a symmetric power distribution along the fiber can be achieved. Combining with pre-dispersion compensation at the transmitter helps restore the real-valued nature of the nonlinear transfer function, thereby improving the compensation effectiveness of the PCTWO-UT scheme under high-dispersion conditions.Results and DiscussionsA 60 Gbit/s PCTWO-UT-QPSK unrepeatered transmission system was established using a co-simulation platform based on VPI TransmissionMaker and Matlab. Simulation results show that in a 250 km standard single-mode fiber (SSMF) link, the proposed scheme achieves a maximum signal-to-noise ratio (SNR) improvement of 10.8 dB compared to a conventional single-polarization QPSK system affected by SPM (Fig. 2). This SNR gain is equivalent to tolerating an additional 64 km of fiber-induced loss. Within the practical launch power range (≤10 dBm), the system consistently maintains over 80% nonlinear compensation efficiency, demonstrating excellent robustness. Moreover, the scheme provides stable SPM suppression across different transmission distances (Fig. 3).When the baud rate increases, the compensation performance degrades due to increased waveform distortion and the loss of the required link symmetry. As shown in Fig. 4, the scheme’s effectiveness sharply declines beyond 13 Gbaud. To further investigate the impact of chromatic dispersion, a 10 Gbaud signal was simulated over fibers with varying dispersion coefficients. Results reveal that when the dispersion exceeds 12 ps·nm-1·km-1, the compensation ability drops significantly (Fig. 5), emphasizing the need for dispersion-aware link design. While dispersion-shifted fibers can address this issue theoretically, standard single-mode fibers are more prevalent in practice. Therefore, this work adopts distributed Raman amplification as a more practical optimization approach.In this configuration, the receiver-end EDFA is replaced with a second-order distributed Raman amplifier. Pump wavelengths of 1450 nm and 1360 nm are deployed with powers of 225 mW and 425 mW, respectively, to form a nearly symmetric power distribution across a 150 km SSMF span (Fig. 6). This power symmetry, combined with dispersion pre-compensation, significantly improves the system’s ability to suppress nonlinear effects. The constellation diagrams show reduced phase noise and improved clustering compared to the traditional EDFA-only setup (Fig. 7). Quantitatively, the nonlinear compensation gain increases from 2.3 dB to 5.2 dB, and the compensation efficiency rises from 32% to 62% (Fig. 8, Table 1), validating the effectiveness of Raman-based optimization in high-speed, high-dispersion scenarios.ConclusionsThis work proposes a PCTWO-UT-based nonlinear compensation scheme for long-haul unrepeatered coherent optical transmission systems. Based on phase-conjugated dual-polarization signal generation and coherent summation at the receiver, the scheme effectively cancels first-order SPM distortions without requiring additional optical hardware. The introduction of uncorrelated training sequences improves equalizer convergence under polarization rotation, while distributed Raman amplification restores power symmetry and extends the scheme's applicability to high-baud-rate, high-dispersion systems. Simulation results confirm that the proposed method significantly improves nonlinear tolerance and transmission performance, offering a practical and scalable compensation solution for future large-capacity, long-distance optical networks.
Jun. 23, 2025Vol. 45 Issue 11 1106004 (2025)
Yulan Han, Yaozu Zhai, Tong Wu, and Chaofeng Lan
ObjectiveThe increasing demand for applications in target detection, identification, and military surveillance necessitates rapid and accurate traffic target detection, particularly in complex environments such as smoke or nighttime conditions. Infrared (IR) and visible light (VIS) image fusion technology plays a vital role in these scenarios by combining complementary information from both image types. This fusion integrates the detailed edges and features of VIS images with the thermal radiation data from IR images. However, conventional image fusion algorithms depend on hand-crafted fusion rules to combine depth features, potentially resulting in important information loss. Additionally, the lack of explainability in deep learning models compounds this challenge, constraining potential algorithmic improvements. We introduce the semantic information driven multimodal image fusion (SIDM-Fusion) network, designed to effectively and accurately identify targets such as people, vehicles, and backgrounds in complex scenes.MethodsThe SIDM-Fusion network represents an innovative fusion framework based on the self-encoder model. It incorporates two essential components: the dual branch-by-layer interactive feature coding network (DBL-IFCN) and the semantic prior classification network (SPC-Net). The DBL-IFCN enables adaptive extraction of multi-scale and salient features, effectively addressing challenges associated with varying target sizes and complex environments. The SPC-Net employs a lightweight encoder architecture to extract deep features and utilizes the class-activation mapping mechanism to implement a dichotomous, learnable fusion rule. The fused features subsequently pass through a pre-trained decoder to generate the final image. To minimize information loss during multimodal fusion, content loss and saliency loss are employed to constrain the information loss in the SIDM-Fusion network. Furthermore, a cross-entropy loss function is used to regulate the semantic prior assignment network. Comprehensive experiments are conducted using multiple datasets, including the multi-sensor road scenes (MSRS) and Netherlands organisation for applied scientific research (TNO) datasets, to validate the network’s semantic segmentation accuracy and evaluate its performance comprehensively.Results and DiscussionsThe SIDM-Fusion network exhibits superior performance across various datasets. Compared to alternative fusion algorithms, the network enhances the average gradient (AG) and mutual information (MI) metrics by approximately 22% and 14%, respectively. Fig. 1 depicts the structural components of the network model, while Figs. 5 and 6 showcase visual quality comparisons across different datasets. The ablation experiments results, presented in Table 3 and Fig. 7, demonstrate the essential contributions of the MEGB, significantly dense residuals block (SDRB), spatial bias module (SBM), and SPC-Net modules to overall performance improvement. Specifically, the MEGB enhances texture details, the SDRB module strengthens pixel distribution, and the SBM module facilitates progressive feature fusion. The integration of SPC-Net further optimizes intensity distribution while maintaining key features. The final model demonstrates excellent performance across all evaluation metrics, validating the effectiveness of the proposed architecture. Additionally, semantic segmentation experiments confirm the network’s feasibility, demonstrating robust performance under diverse weather conditions and varying lighting environments, making it suitable for practical applications.ConclusionsTo overcome the limitations of existing methods that often prioritize visual effects over supporting high-level tasks, the SIDM-Fusion network is engineered to deliver more accurate information for real-world applications by simultaneously addressing both image visual quality and utility in complex environments. The two-branch, layer-by-layer interactive feature coding network preserves edge information, enhances texture details, and improves edge clarity. Furthermore, the SPC-Net effectively captures pixel correlation within local windows and across windows, utilizing the class-activation mapping (CAM) mechanism. Through class-activation weights, the network assigns fusion weights to channels, implementing a learnable fusion rule based on binary classification. This approach effectively addresses the challenge where models emphasize visual quality at the expense of practical image functionality. Experimental results demonstrate that the proposed method efficiently utilizes complementary information from multimodal images, significantly reducing information loss. Future research will focus on optimizing network speed and efficiency to enhance its practical applicability across various domains.
Jun. 23, 2025Vol. 45 Issue 11 1110001 (2025)
Zhiniu Xu, Tianjie Ma, Yangyang Cai, and Lijuan Zhao
ObjectiveSubstations are critical components of power systems, serving as essential hubs for power transmission and distribution. Intrusions caused by human activity pose significant threats to substations, potentially leading to severe safety issues and substantial economic losses. The security and protection of these facilities are paramount, as any intrusion or damage can result in widespread power disruptions and compromise grid stability. Traditional perimeter security methods such as video surveillance and infrared detection systems face several limitations: video surveillance systems often have blind spots and lack automatic alarm capabilities, while infrared detection systems require flat installation environments and suffer from poor reliability. To enhance performance, distributed acoustic sensing (DAS) technology based on phase-sensitive optical time-domain reflectometry (φ-OTDR) is employed for perimeter security in this paper. By deploying optical fiber in the designated area, vibration signals are collected, and intrusion events are classified using a feature extraction and classification model. These systems offer distinct advantages, including strong anti-electromagnetic interference capabilities, high sensitivity, compact size, and excellent stability in harsh environments. Moreover, DAS enables continuous, real-time monitoring along the entire fiber length, effectively eliminating blind spots. However, accurate identification and classification of different intrusion events using DAS signals remains challenging due to signal complexity and environmental interference. Conventional recognition systems primarily rely on extracting features from signals in either the time or frequency domain, followed by classification using methods such as support vector machines, neural networks, or other deep learning models. These approaches face challenges such as underutilization of signal information across both domains, redundant classification parameters, and computational complexity. To address these issues, we propose a novel intrusion event identification method that combines DAS with advanced signal processing and deep learning techniques. The method integrates the Gramian angular difference field (GADF) for signal encoding and a multi-scale convolutional neural network (MSCNN) enhanced with a cross attention fusion module (CAFM). This approach aims to improve the accuracy of substation perimeter security monitoring by overcoming the limitations of conventional single-scale neural networks and enhancing feature extraction capabilities.MethodsA DAS system is implemented using a narrow-linewidth laser (1550.12 nm) with a pulse repetition rate of 1 kHz and pulse width of 40 ns. The sensing fiber (155 m) is deployed in an S-shaped configuration, with vibration events simulated at the 8-m end section. The system collects vibration signals for five different scenarios: no invasion, striking, climbing, trampling, and shoveling. Raw vibration signals are obtained through in-phase/quadrature (I/Q) demodulation, and the signals are segmented into 1-s frames (1000 data points). The data is then resampled to 224 points. The GADF technique converts time-domain signals into 224 pixel×224 pixel images, which are used as input to the CAFM-MSCNN. After feature extraction through the first convolution layer, the model performs convolution operations using kernels of sizes 3, 5 and 7. The multi-scale fusion framework is built using these different kernel sizes. Each convolutional channel contains several convolutional layers and max pooling layers to extract features and capture complementary information of different scales. The features extracted from the three channels are then fused into feature vectors. The spliced feature vectors are classified by a classifier layer to determine the vibration categories. The model is built based on the PyTorch framework, and the program is written in Python 3.9. The optimal parameters are determined through repeated experimentation: batch size is set to 32, the maximum number of epochs is set to 100, the learning rate is set to 0.001, and the Adam optimizer is used. The confusion matrix is adopted as the evaluation metric of the model.Results and DiscussionsThe experimental results show that the classification accuracies for the five types of vibration events by the proposed model are 100%, 97.65%, 97.22%, 98.32%, and 99.25% (Fig. 9), respectively. Compared with convolutional neural networks (CNN), long short term memory (LSTM) networks, time convolutional neural networks (TCN), CNN-LSTM, and MSCNN, the classification accuracy of the proposed model improves by 3.27 percentage points, 15.16 percentage points, 8.06 percentage points, 7.12 percentage points, and 0.83 percentage points, respectively (Table 4).ConclusionsWe propose a novel approach for substation perimeter security using DAS combined with GADF-CAFM-MSCNN architecture. The method achieves high accuracy in identifying different types of intrusion events, with an average accuracy of 98.49%. The integration of multi-scale feature extraction and cross-attention mechanisms effectively addresses the limitations of traditional approaches. The system’s robustness under various noise conditions, along with its improved performance over existing methods, demonstrates its potential for practical substation security applications. The proposed method offers a new and effective technical solution for enhancing the safety and reliability of intrusion detection.
Jun. 10, 2025Vol. 45 Issue 11 1110002 (2025)
Yanpeng Zhang, Rongrong Zhang, Hongyan Zhang, and Hongfei Yang
ObjectiveAccurate train position information is crucial for communication-based train control (CBTC) systems to ensure the safety of train running. With the rapid development of vehicle-to-vehicle communication for CBTC systems, higher demands have been placed on positioning accuracy. When using optical camera communication for train positioning, the acquisition of positioning lamps directly affects positioning accuracy. Existing research has validated the feasibility and effectiveness of visible light communication (VLC) for positioning through various methods and has investigated camera rotation adjustments to stabilize target acquisition. However, limited attention has been given to the challenge of stably acquiring positioning lamps for fast-moving objects on tracks with different curve radii in tunnel scenarios. The extended state observer (ESO), as an intelligent observer, can dynamically adjust camera angles to maintain targets within the field of view, which demonstrates wide applications in autonomous driving, mobile robotics, and navigation. In the present study, we report an adaptive method for capturing lamps for train positioning using optical camera communication with ESO, ensuring stable lamp acquisition across tracks with varying curve radii. The proposed method enhances continuous positioning accuracy in tunnel environments.MethodsIn this study, the precise positioning of the train is achieved by adaptively adjusting the camera azimuth to continuously capture LED lamps on the tunnel wall. First, the influence of camera azimuth on acquiring train positioning lamps is analyzed to determine its critical conditions. Then, the current camera azimuth is measured using an inertial measurement unit (IMU) and optical flow sensor, while an ESO model for camera azimuth is constructed to estimate azimuth states. By calculating azimuth errors, disturbance information caused by external interference and unmodeled dynamics is estimated in real time. Then, a velocity-dependent adaptive control strategy for camera azimuth is designed using Lyapunov theory and adaptive backstepping, followed by dynamic surface control (DSC) approximation of virtual control derivatives to optimize response time and stabilize positioning lamp acquisition. Finally, the actual position of the train is calculated based on the coordinates of the positioning lamps, which enables continuous high-precision positioning in the tunnel environment. To verify the feasibility of the proposed method, we utilize line data and equipment information from Chengdu Metro Line 1 to establish an experimental platform for train positioning and use MATLAB to analyze the experimental results of positioning lamp acquisition and train positioning.Results and DiscussionsUsing the distance between two LED lamps as one positioning unit, a train positioning experimental platform with dimensions of 20.0 m×2.0 m×1.5 m is established to validate the effectiveness of the proposed method. Under different curve radii, the maximum adjustment deviations of the camera azimuth are measured as 0.26°, 0.28°, 0.31°, and 0.34°, respectively (Fig. 8). The successful rate of capturing positioning lamps with a fixed azimuth is 79.98%, 71.89%, 62.40%, and 57.01%, while the successful rate with adaptive azimuth adjustment is 99.87%, 99.01%, 95.89%, and 93.95%, respectively (Fig. 9). When a train runs on a curve with a radius of 250 m at speeds of 20 km/h, 40 km/h, 60 km/h, 80 km/h, and 100 km/h, the successful rate of capturing positioning lamps is 92.29%, 91.84%, 91.63%, 91.48%, and 91.39%, respectively (Fig. 10). The maximum error in train positioning is 20.87, 22.35, 24.97, 27.84, and 30.04 cm, respectively (Fig. 11). When the train runs at a speed of 100 km/h, the maximum error of train positioning for the proposed method, traditional ESO, and the method without ESO is 30.04, 38.26, and 39.66 cm, respectively (Fig. 12). The maximum time for train positioning is 51.66, 60.56, and 67.64 ms (Table 2). The positioning accuracy and real-time performance of the proposed method both meet the train positioning requirements specified in IEEE Standard 1474.1-2025.ConclusionsTo address the issues of difficult acquisition of train positioning lamps due to curve radius limitations, we propose an ESO-based method for adaptively adjusting camera azimuth to reliably capture positioning lamps across varying curve radii. We utilize ESO to estimate camera azimuth disturbance and implement a train velocity-dependent adaptive control strategy for disturbance compensation, enabling adaptive azimuth adjustment. The research results show that while azimuth adjustment errors increase with decreasing curve radius, the process exhibits no significant overshoot or hysteresis. When a train runs at different speeds, the successful rate of capturing positioning lamps is higher than 91.00%, and the maximum error in train positioning is 30.04 cm. When a train runs at 100 km/h, the maximum time for train positioning is 51.66 ms. Compared with the traditional ESO method and the method without ESO, the positioning accuracy of the proposed method improves by 21.48% and 24.25%, respectively, when the curve radius is at its minimum. The proposed method enables continuous high-precision train positioning throughout the entire line.
Jun. 23, 2025Vol. 45 Issue 11 1111001 (2025)
Ting Wang, Chao Wang, Xinkai Wu, Hongyu Sun, and Jianan Liu
ObjectiveWith the rapid advancement of optical imaging technologies, there is an increasing demand for higher resolution, better image quality, and more compact, cost-effective optical systems. In recent years, super-resolution imaging based on digital micromirror devices (DMDs) has attracted considerable attention for its ability to surpass the resolution limits of traditional optical systems. However, the integration of DMDs introduces challenges such as optical eccentricity and tilt-induced aberrations. To mitigate these issues, the design of DMD-based super-resolution imaging systems often requires additional optical lenses and complex surface types to correct aberrations and enhance imaging quality. While this improves accuracy, it reduces energy transmittance and significantly raises manufacturing costs. In this paper, we focus on the simplified design and image quality optimization of such systems, aiming to enhance system performance and imaging accuracy.MethodsTo meet the needs of simplified design and improved imaging quality in DMD-based infrared super-resolution systems, we examine the computational super-resolution imaging theory based on DMDs, analyze their working mechanisms and applications, and propose a simplified design approach. The original projection lens is then simplified using Zemax software, and the point spread function (PSF) of the modified system is obtained. Building on this, we develop a super-resolution restoration and image quality optimization model using T-L (TVAL3-Lucy Richardson), along with an algorithm that combines super-resolution reconstruction and image deblurring restoration. This algorithm improves both resolution and clarity in degraded images captured by the simplified system. Simulation, indoor target, and outdoor scene imaging experiments are conducted to validate the method's accuracy. The findings offer new insights for designing cost-effective DMD-based optical systems.Results and DiscussionsTo validate the method, two images with a resolution of 512 pixel×512 pixel and two images with a resolution of 144 pixel×144 pixel are selected for simulation experiments (Fig. 8). Based on evaluation metrics (Table 3), the average peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) outperform other restoration methods, with PSNR exceeding 27 and SSIM exceeding 0.85. Compared to blurred images captured by the simplified system, PSNR improves by an average of 78%, and SSIM by 71%. The root mean square error (RMSE) decreases by 36% compared to blurred images captured by the simplified system. Indoor target imaging experiments (Fig. 11, Table 4) demonstrate significant improvements after restoration, with PSNR reaching 20.37 and SSIM rising to 0.77, representing improvements of 58.5% and 57.1%, respectively, over the original images. Meanwhile, RMSE drops to 27.46, a 27% reduction. Finally, outdoor scene imaging experiments (Fig. 13) demonstrate excellent image enhancement under various distance conditions. Compared to direct super-resolution methods, the proposed approach significantly enhances detail reproduction while maintaining overall imaging stability. The natural image quality evaluator (NIQE) values (Table 5) for two outdoor scenes decreases from 8.10 to 5.13 and from 7.75 to 4.09, representing reductions of 36.7% and 47.2%, respectively.ConclusionsThe proposed method effectively simplifies the structure of DMD-based infrared super-resolution imaging systems, reduces alignment complexity, improves infrared transmittance, and lowers production costs. By iteratively combining super-resolution reconstruction and deblurring, and analyzing convergence, optimal image enhancement is achieved. Theoretically, the TVAL3 algorithm uses total variation (TV) regularization to enable sparse reconstruction while preserving edges and textures, thus reducing artifacts. The Lucy-Richardson algorithm iteratively corrects blur and enhances image sharpness. In simulations, PSNR improves by an average of 78% and SSIM by 71%, compared to directly captured images. In indoor experiments, PSNR improves by 58.5% and SSIM by 57.1%. In outdoor scene experiments, the method effectively restores details compared to degraded images captured by the simplified system. The proposed restoration method improves resolution and quality, simplifies system structure, and reduces both cost and operational complexity, facilitating integration and deployment. It is well-suited for applications requiring high portability and low cost, such as portable security monitoring, spaceborne remote sensing, and field exploration.
Jun. 23, 2025Vol. 45 Issue 11 1111002 (2025)
Zaiwu Sun, Fanjiao Tan, Pengliang Yu, Zongling Li, Rongshuai Zhang, Changjian Yang, and Qingyu Hou
ObjectiveThe awareness of depth is important for many computer vision tasks, such as autonomous driving and 3D reconstruction. Existing depth estimation methods include methods using structured light, time of flight, stereo-based depth estimation and monocular depth estimation. Monocular depth estimation has significant advantages in terms of power consumption, cost, and size. There are two ways to achieve monocular depth estimation. One is to learn the depth clues contained in the scene itself in the image through the neural network, such as texture gradients, shading, occlusions, and the type and size of the object. But this method is lack of interpretability. The other is depth from defocus (DFD) or depth estimation based on coded aperture, which estimates depth by identifying depth-related optical features in the optical system. This method often requires the addition of a phase mask to the existing camera, and does not utilize the depth information encoding ability of the lens itself. Therefore, we propose a depth estimation method based on single-lens optical system, which further reduces the size and volume of the optical system on the basis of existing single-lens depth estimation, while improving the accuracy of depth estimation.MethodsA monocular depth estimation system usually consists of a camera and diffractive optical elements. The implementation method involves designing a diffraction optical element such that the point spread functions (PSFs) at different depths present different spatial or spectral structures. Using optical system to encode scene depth information into 2D images, then a decoding algorithm is used to decode the encoded image to estimate the scene’s depth map. The single-lens optical system also has the capability to present different spatial or spectral structures for objects at varying depths.For this specific imaging system of a single lens, we propose a simulation model for the four-dimensional point spread function that varies with multi-wavelength, depth-aware, spatially-variant four-dimensional point spread functions along with a differentiable optical imaging model. We then introduce an optimization constraint method for depth estimation tasks, which regulates the point spread function in both depth and field dimensions. For the depth estimation algorithm, we should consider that depth estimation methods relying on different spatial or spectral structures of PSFs are quite dependent on the object’s texture in the scene. Since the semantic information of the scene can compensate for this limitation, we propose a depth estimation network that includes a semantic information extraction preprocessing model. We connect the imaging model and depth estimation algorithm, jointly designing the single-lens optical system and the depth estimation algorithm. Finally, a visible light depth detector which includes an aspherical single-lens optical system and corresponding depth estimation algorithm is designed.Results and DiscussionsTo verify our method, we train and test it on the NYU Depth V2 dataset, set the target depth range from 1.0 m to 5.0 m, The initial single-lens optical system, characterized by a focal length of 31.4 mm and a field of view of approximately 10°, is optimized along with its corresponding depth estimation algorithm. we compare our method with three alternative approaches: 1) the conventional depth from defocus model, which treats the lens as a thin lens; 2) phase coded-aperture model implemented with a diffractive optical element size of 256×256; 3) phase coded-aperture model which has a phase mask with several concentric rings. Our designed single-lens depth estimation model achieved a relative error of as low as 0.083 on the NYU Depth V2 dataset, demonstrating the lowest relative error among the compared methods. To further evaluate the contribution of our proposed method, we conducted ablation experiments. Specifically, we replaced the optimized single-lens optical system with an unoptimized version and substituted the semantic information extraction preprocessing step with a neural network lacking this preprocessing capability. Both modifications resulted in a degradation of depth estimation accuracy, thus substantiating the effectiveness of our method in improving the depth estimation model.ConclusionsWe introduce an end-to-end single-lens depth estimation model. Firstly, in order to accurately simulate the out-of-focus and off-axis aberrations in the real camera lens in the depth scene, we propose a differentiable imaging model. Then, we introduce a single lens optimization constraint method to regulate the point spread functions of a single lens optical system to improve the depth dependence of the imaging response features of the optical system, so that the single lens can be optimized along the direction of maximizing the depth estimation performance of the model. In this paper, a preprocessing method combining semantic information is proposed to make up for the lack of dependent image texture in decoding process. Finally, by jointly optimizing the single-lens optical system and the depth estimation algorithm, the depth estimation model based on the minimalist optical system is realized, and the simulation and test are carried out on the NYU Depth V2 dataset. The results show that the design method can greatly reduce the volume of the depth estimation system while maintaining a high depth estimation performance. It has certain significance in the application of unmanned aerial vehicle platform distance sensor and other fields.
Jun. 23, 2025Vol. 45 Issue 11 1111003 (2025)
Yuanjue Ma, Jingyi Xu, Jun Yan, and Liang Li
ObjectiveIntraoperative precise navigation plays a crucial role in minimally invasive liver surgery, where binocular endoscopy enables depth information acquisition from the field of view, providing essential data support. However, current binocular endoscopic systems require manual depth perception by surgeons and lack digital integration with surgical instruments. This study investigates a binocular endoscopic stereoscopic imaging method based on the CroCo v2 stereo matching network to address the challenge of generating rapid and stable three-dimensional depth information through computer stereo vision technology. This approach aims to provide surgeons with direct three-dimensional digital image information and establish a foundation for future digital automatic navigation and early warning systems for surgical instruments.MethodsTo address the challenge of limited binocular endoscopic datasets, this study introduces a pre-training approach utilizing simulation datasets generated from human organ models. The methodology employs an open-source human cardiac anatomical model to generate simulation datasets through Blender. A binocular endoscope system is developed by horizontally aligning two identical camera models with adjustable baseline distance and focal length parameters to replicate various endoscopic configurations. The CroCo v2 stereo matching network undergoes a three-phase optimization process: initial pre-training with simulation datasets, fine-tuning using the SCARED training dataset, and comprehensive evaluation using both the SCARED test dataset and clinical binocular endoscopic datasets to verify cross-domain generalization capabilities.Results and DiscussionsThe experimental results on the SCARED test dataset demonstrate that networks pre-trained solely with simulation data achieve competent disparity estimation performance. Notably, the network fine-tuned after simulation-based pretraining produces clearer and more accurate disparity maps compared to the network trained exclusively on the SCARED training dataset (Fig. 4). This demonstrates the effectiveness of the simulation dataset in enhancing network performance. At the same time, it can be observed that as the number of simulation datasets increases, the training accuracy of the network improves (Table 2). However, under the premise that the network parameters and algorithms are already determined, the improvement in training accuracy achieved by simply changing the number of training datasets is not linear; there is an upper limit to this improvement. To evaluate the advancement of the proposed method, comparative experiments are conducted on the SCARED dataset against other state-of-the-art approaches, including STTR, BDIS, MonoDiffusion, EndoDAC and the method proposed by Yang et al. Among these, BDIS represents a traditional algorithm while the others are deep learning-based methods. It can be observed that the proposed method achieves comparable performance to state-of-the-art approaches, outperforming both traditional algorithms and other advanced deep learning methods (Table 3). Additionally, the results indicate that the network maintains robust performance in weakly-textured regions, reflective areas, and low-light conditions while preserving fine local details (Fig. 5). To validate the generalization capability of the network, the final trained model is tested on a dataset collected from clinical procedures using a daVinci Xi binocular endoscopic. The network is deployed on a consumer-grade NVIDIA GeForce RTX 4090 graphics card, consuming an average of 3.9 GB of VRAM per image pair and taking 400 ms for inference. As observed, the disparity maps produced by the network are clear and complete, without any gaps (Fig. 6). Furthermore, there is no significant degradation in the results in areas with weak texture, reflections, or low light. This indicates that the well-trained network exhibits excellent generalization ability on the clinically collected dataset. Furthermore, the relatively low local deployment cost and short inference time make it capable of meeting the real-time requirements of clinical settings.ConclusionsThe proposed method effectively addresses the challenge of insufficient datasets through an innovative training paradigm for simulation datasets, overcoming limitations of conventional simulation methods that depend on ultra-precise models yet demonstrate poor clinical generalization capability. Additionally, the network architecture exhibits lightweight characteristics, achieving optimal real-time performance without compromising training accuracy while maintaining straightforward local deployment.
Jun. 24, 2025Vol. 45 Issue 11 1111004 (2025)
Junwei Chang, Zhi Wang, Yining Mu, He Wang, Xueyi Wang, and Yicheng Wang
ObjectiveThe relentless pursuit of miniaturization in confocal endoscopic imaging systems encounters a fundamental physical paradox at submillimeter scales: the mutually exclusive demands between scanning precision and device compactness, governed by the mechanical energy density ceiling of microelectromechanical system (MEMS) scanners and the unyielding conservation of optical étendue. This study introduces a waveguide spatial optical scaling transformation technique that circumvents these fundamental limitations through strategic reconstruction of optical field phase-energy distributions. Central to this breakthrough is the resolution of dual constraints plaguing fiber-coupled systems: the mode-selective transmission characteristics of micro-scale imaging fibers that enforce stringent light field propagation rules, and the nonlinear dynamics of MEMS micromirrors that induce counteractive speed-precision tradeoffs within the critical 1°?6° mechanical tilt range. These limitations manifest as significant spatial frequency response degradation, particularly evident in edge-field performance deterioration under high-resolution imaging conditions.MethodsThese limitations originate from the planar geometry of imaging fiber endface (non-aspheric surfaces), where two-dimensional laser scanning introduces angle-dependent coupling efficiency variations across different fields of view. This geometric limitation propagates through the photomultiplier chain, resulting in pronounced moiré patterns at the imaging plane. Analysis reveals a critical design paradox: increasing the fiber endface diameter nonlinearly amplifies moiré modulation depth through combined mode interference and wavefront vector mismatch, while reducing endface dimensions compresses angular tolerance to arc-second levels-an impractical requirement for practical endoscopic maneuvering. Additionally, MEMS scanner design confronts an inherent trilemma among drive voltage, angular precision, and scanning speed. As shown in Fig. 3(a), y-axis mechanical tilt exhibits progressive precision degradation with increasing scan frequency, reaching 6.5% positioning error at mechanical angular displacement below 3.5° tilts (calibration error is ±0.1°). These results from insufficient driving torque in millimeter-scale devices, where energy storage capacity scales positively with actuation force. Figure 3(b) illustrates the speed-resolution tradeoff: while 2°?6° tilt expansion improves line-scan resolution by 25%, exceeding 12 Hz scan rates induces inertial-delay-induced resolution loss due to coupled damping dissipation. These limitations fundamentally stem from insufficient energy transfer efficiency in microscale electromechanical systems, making conventional designs unable to achieve both high frame rates and superior resolution.Results and DiscussionsTo quantitatively evaluate the optimization efficacy of waveguide optical cones on spatial frequency response, we established a full-field modulation transfer function (MTF) measurement system based on the knife-edge method (Fig. 6). Utilizing a Thorlabs Nano Max precision translation stage (10 nm stepping accuracy) to scan a standard knife-edge along the optical axis, we captured diffraction patterns at the edge transition region (interference fringe spacing around 2.8 μm, Fig. 6 inset). Three independent experimental trials with Fourier-transform-derived MTF curves demonstrated repeatability errors below ±3.5% across 0?350 lp/mm spatial frequencies. In conventional direct coupling configurations, the system exhibited marked spatial non-uniformity (uniformity coefficient is 0.58), with central field MTF15 (15% contrast threshold) reaching 317.71 lp/mm versus edge-field MTF10 (10% contrast) declining to 214.55 lp/mm. This performance degradation stems from phase mismatch in higher-order mode groups during scanning angle escalation, where mechanical angles below 3° induce 23.7% intensity fluctuation standard deviation through multimodal interference, significantly deteriorating imaging signal-to-noise ratio. The introduced waveguide optical cone architecture addresses these limitations through dual physical mechanisms: synergistic effects between graded refractive index distribution and conical geometry concentrate beam energy while suppressing higher-order mode noise. Experimental data confirm transformative improvements- at the original edge-field resolution benchmark of 214.55 lp/mm, the MTF value increases from 0.24 to 0.28 (18% contrast enhancement), with central field performance at 317.71 lp/mm, and MTF is improved to 0.33. System-wide uniformity coefficient uniformity coefficient increases to 0.91, achieving near-perfect field consistency. The MTF curve slope moderates from -0.42 dB·lp-1·mm-1 to -0.28 dB·lp-1·mm-1, reflecting a 67% efficiency gain in transmitting 50?100 lp/mm high-frequency components that correspond to 5?10 μm feature resolution. These metrics validate the waveguide cone’s capacity to optimize beam propagation paths through conical structural modulation, counteracting the inherent limitations of direct-coupled systems where uncontrolled beam divergence exacerbates mode mismatch and scattering, particularly in peripheral fields.ConclusionsThe fundamental challenge in confocal endoscope miniaturization arises from the intrinsic physical incompatibility between the conservation of optical étendue at microscales and the energy density limits of scanning components. Through the development of a waveguide spatial optical transformation model, this work achieves synergistic optimization of light field manipulation and scanning precision at submillimeter dimensions, providing both theoretical foundations and engineering solutions to overcome conventional technical barriers. The primary innovation lies in uncovering the phase reconstruction mechanism enabled by graded-index waveguide coupling effects: modal gradient compression in tapered geometries effectively suppresses higher-order mode excitation. Experimental validation demonstrates an 18% enhancement in edge-field MTF contrast ratio alongside optimized full-field uniformity coefficient (uniformity coefficient is 0.91 vs baseline uniformity coefficient is 0.58), enabling high-resolution imaging within a 6.2 mm-diameter probe. These advancements provide quantifiable modeling support for device-oriented design of confocal endoscopic systems, bridging the critical gap between theoretical predictions and clinical-grade miniaturization requirements.
Jun. 23, 2025Vol. 45 Issue 11 1111005 (2025)
Qiming Wang, Qing Guo, Ruoduan Sun, Caihong Dai, Ling Li, Yanfei Wang, Junchao Zhang, and Zhifeng Wu
ObjectiveAn array spectroradiometer can rapidly measure spectra and is widely used in fields such as aerospace, remote sensing, photovoltaics, and environmental monitoring. Currently, the dynamic range of array spectroradiometers is increasing. When measuring light sources at different radiation levels, it is crucial to determine whether the spectroradiometer’s responsivity remains constant. Due to the low stray light suppression ratio of array spectroradiometers, a spectrally stable, wide-band, adjustable light source with a large dynamic range must be designed for linearity testing. Traditional dual-beam superposition methods can only provide a relatively spectrally invariant light source over about three orders of magnitude, while cascaded integrating sphere superposition with dual light sources and neutral density filter methods both alter the relative spectral distribution. To accurately assess the measurement capability of the array spectroradiometer, a spectral radiance linearity measurement facility has been designed.MethodsThe linearity measurement facility integrates an integrating sphere light source, interchangeable apertures, a diffuse reflective whiteboard, and a linear guide rail. Different apertures (20, 6, or 2 mm) are used to adjust the exit surface size of the integrating sphere light source, and the radiation from the aperture irradiates the whiteboard at normal incidence. The distance between the aperture and the whiteboard can vary from 30 to 100 cm. The aperture size is small compared to the distance between the aperture and the whiteboard, so the irradiance at the center of the whiteboard is approximately proportional to the aperture area and inversely proportional to the square of the distance. The whiteboard exhibits excellent spectral flatness characteristics and demonstrates Lambertian reflectance behavior over a 2π steradian solid angle. By changing the aperture area and the distance between the aperture and the whiteboard, it is possible to achieve a 6-order-of-magnitude variation from the spectral radiance of the integrating sphere light source to the reflective radiance of the whiteboard. The consistency of the whiteboard’s reflectance factor verifies that the relative spectrum of the facility is nearly constant from 380 to 780 nm. Table 1 lists the theoretical spectral radiance ratios under different measurement conditions for the linearity measurement facility. The nonlinearity of the spectroradiometer is defined as the deviation between the measured ratio and its theoretical counterpart under each specified condition.Results and DiscussionsBefore characterizing the nonlinearity of the array spectroradiometer, we first evaluate the stability of the light source and the differences in aperture changes of the linearity measurement facility. Experimental results show that the drift rate of the light source is less than 0.07% per hour, and the back-reflections to the light source as well as diffraction errors during size changes are negligible. As shown in Fig. 7, when the distance between the aperture and the whiteboard is fixed at 30 cm and the aperture diameter is reduced from 20 to 2 mm, the experimental results exhibit wavelength-dependent nonlinearity. The nonlinearity reaches 5.6% at 380 nm, and the maximum nonlinearity from 550 to 780 nm is about 0.5%. When the array spectroradiometer is calibrated at the intermediate level (r=10 mm, d=300 mm as in Table 1) and the measurement range is extended by three orders of magnitude toward both higher and lower intensity levels, the nonlinearity reaches a maximum of approximately 10%, as shown in Fig. 8. The nonlinearity remains predominantly within ±1.0% for wavelengths above 450 nm. The measurement uncertainties of the facility when extended towards both small and large values are 0.50% (k=2) and 0.72% (k=2), respectively. When the linear measurement system performs a six-order-of-magnitude downward extension from the integrating sphere source radiance level, the measurement uncertainty of the system is evaluated as 0.76% (k=2). Results show that the nonlinearity around 380 nm exceeds 15%.ConclusionsThe designed linearity measurement facility is used to characterize the nonlinear response of an array spectroradiometer. Measurement results indicate that the nonlinearity of the spectroradiometer exhibits a significant dependence on both wavelength and integration time. When performing measurements across a broad range of magnitudes, the nonlinearity of the spectroradiometer must be corrected. Furthermore, the dynamic range of the linearity measurement facility can be extended by using a much longer linear guide rail and a high-temperature blackbody matched to the integrating sphere’s correlated color temperature. When employing a 3-m linear guide rail, the dynamic range can be increased to seven orders of magnitude. By using a blackbody instead of the integrating sphere light source, the facility can be used to calibrate spectroradiometers with a much higher measurement limit.
Jun. 10, 2025Vol. 45 Issue 11 1112001 (2025)
Miaoyan Tong, Youjian Yi, Ping Zhu, Xiuyu Yao, Ailin Guo, Dongjun Zhang, Hailun Zeng, Zezhao Gong, Lijie Cui, Meizhi Sun, Xiao Liang, Xinglong Xie, and Jianqiang Zhu
ObjectiveHigh-power laser systems, characterized by ultra-high peak power and ultrashort pulse durations, play pivotal roles in inertial confinement fusion, particle acceleration, and ultrafast science. However, their performance is increasingly limited by spatiotemporal coupling effects that distort focal spot quality. Recent advances like STRIPED FISH, enable single-shot measurements but introduce reference-arm errors, while hyperspectral approaches suffer from limited channel capacity. Compressed sensing shows promise through sub-Nyquist sampling, yet conventional implementations (CASSI, CUP) recover only intensity. Phase-sensitive compressed sensing techniques (COFT, CS-CMUI) enable complex-field measurement, whereas hyperspectral compressive wavefront sensing can achieve similar results but requires deep learning-based reconstruction, which demands extensive experimental datasets for neural network training. To address the limitations of conventional measurement methods in spectral bandwidth and channel capacity, we present a spatiotemporal optical field measurement technique based on compressed sensing and quadriwave lateral shearing interferometry, which overcomes the channel number constraints of traditional systems. We aim to develop a robust single-shot technique combining compressed sensing with shearing interferometry to achieve 3D spatiotemporal complex-field characterization of high-power lasers. Multiplexing in the spatial and spectral domains is accomplished through compressed sensing, while complex amplitude reconstruction is achieved via quadriwave lateral shearing interferometry. When an input pulse interacts with a 2D phase grating, it generates wavelength-dependent interference patterns. These patterns are encoded by a random binary mask and spectrally dispersed before camera acquisition, creating a compressed image containing multiplexed spectral and spatial information. The reconstruction process involves two key steps: first, the TWIST-TV algorithm is employed to reconstruct wavelength-specific interference patterns from the compressed image, followed by Fourier-based phase recovery techniques to extract the complete complex field (including both amplitude and phase information) at each wavelength from the decoded interferograms.MethodsWe conduct a systematic simulation analysis of the measurement technology based on the combination of compressive quadriwave lateral shearing interferometry. Through mathematical modeling incorporating 38 dB Poisson noise, an imaging system resolution limit of NA=0.1, and a 10 μm defocus, we systematically investigate the effect of critical parameters—including the interference pattern period-to-encoding pixel size ratio, channel number, and frame number—on phase recovery accuracy, providing theoretical guidance for subsequent experimental optimization. The three key parameters—the interference pattern period-to-encoding pixel size ratio (γ), channel number, and frame number—are mutually independent in governing the reconstruction performance, which enables their systematic investigation through controlled-variable simulations. This parametric independence arises because the γ exclusively controls the spatial sampling adequacy of interference fringes, the channel number determines the spectral degrees of freedom without affecting spatial sampling, and the frame number provides additional linearly independent equations without altering the system’s spectral or spatial resolution.Results and DiscussionsFirst, to determine the optimal γ value for single-shot 20-channel phase reconstruction under near-experimental conditions, we vary the coding mask’s pixel size to adjust γ and evaluate phase recovery. The results show that γ=6?10 provides robust phase retrieval, with γ=10 yielding the smallest reconstruction error. Secondly, to investigate the influence of channel number on phase reconstruction accuracy in single-shot measurements, we systematically increase the spectral channels while maintaining a 2 nm resolution per channel, and evaluate the phase recovery performance under γ=10. The results demonstrate that approximately 20 channels provide the optimal reconstruction accuracy. Beyond this, additional channels lead to degraded performance due to noise accumulation and increased processing complexity. Thirdly, to assess the influence of frame number on phase reconstruction accuracy in multi-frame compressive sensing, we systematically increase the number of frames (distinct coding patterns) while maintaining 100 spectral channels under γ=10 conditions, and evaluate phase recovery performance. The results show that at least 12 frames are required to achieve reliable reconstruction accuracy, with γ=10 maintaining optimal performance. To validate the feasibility of the measurement technology based on the combination of compressive quadriwave lateral shearing interferometry, we implement an experimental setup featuring a broadband source (40 nm bandwidth centered at 800 nm). The system successfully achieves single-shot spatio-spectral phase measurements, which demonstrates accurate wavefront reconstruction across 20 spectral channels with 2 nm resolution. Key design parameters include a 64 μm-period phase grating, a γ=11.2 pattern sampling ratio, and optimized 5× magnification optics. Quantitative evaluation demonstrates excellent reconstruction accuracy, with a mean RMSE of 0.0078λ and a mean ΔPPV=0.0128λ.CouclusionsThe experimental results have validated the optimal parameters obtained from the simulations, further confirming the reliability of these simulation parameters. This provides a solid foundation for single-shot broadband spectral measurements. Building upon these validated simulation parameters, future work will focus on extending the measurement bandwidth to progressively achieve ultra-broadband pulse measurement capabilities.
Jun. 23, 2025Vol. 45 Issue 11 1112002 (2025)
Wei Zhang, Qin Yu, Zifan Wang, Fang Cheng, Yin Wang, Ting Liu, and Weifeng Zheng
ObjectiveTraditional chromatic confocal measurement primarily relies on single-point detection, resulting in low efficiency, as each measurement cycle yields only the axial height of a single point. To enhance measurement efficiency, we propose a line-array spectral confocal measurement system. The system uses a 7-channel fiber bundle as an optical beam-splitting device to achieve a 2 mm linear measurement range for line-array illumination. A custom-designed dispersive objective lens generates a 2.5 mm spot, and an area-scan spectrometer, composed of a reflective grating and an area-scan camera, replaces the conventional spectrometer to enable simultaneous processing of multi-point spectral signals. Experimental results demonstrate that the system achieves an axial measurement range of approximately 200 μm, a repeatability within 0.95 μm, a lateral resolution of 1.183 μm, and an axial resolution of 2.287 μm, with measurement accuracy at the micrometer level.MethodsTo improve measurement efficiency, we propose a measurement system based on line-array spectral confocal technology. A fiber bundle is used as the optical splitter to focus multiple beams onto the surface of the measured sample, thus enabling line-array parallel illumination. A spectrometer system consisting of a reflective grating and an area-scan camera replaces the traditional spectrometer to receive and process multi-point spectral signals. In addition, a data processing method based on virtual grid transformation is designed. This method allows for the adjustment of the virtual grid size according to the actual experimental conditions, making it adaptable to different measurement requirements. A series of experimental studies are conducted on the constructed measurement system: 1) System calibration: A flat mirror is used to determine the system’s axial measurement range and to establish a mapping between virtual grid positions and axial displacement. 2) Reproducibility test: Multiple measurements at varying axial positions verify the system’s stability and reproducibility. 3) Step height measurement: Gauge blocks are used to simulate step samples, validating axial resolution and accuracy. 4) 3D surface reconstruction: Step samples are reconstructed in 3D to evaluate the system’s capability in surface morphology recovery.Results and DiscussionsThe system calibration experiment determines that the system’s axial measurement range is 0?200 μm. Compared to traditional single-point methods, the proposed system improves measurement speed by approximately sevenfold, attributed to the fiber bundle’s line-array illumination which enables simultaneous multi-point data acquisition. The measurement accuracy of the system reaches the micrometer level, indicating that the signal reception device and data processing algorithm used effectively enhance the reliability of the measurement results. In reproducibility tests, standard deviation remains under 0.95 μm, demonstrating excellent stability and reliability. This result indicates that the line-array spectral confocal measurement system maintains high consistency across multiple measurements, making it suitable for precise surface profile measurements. In the 3D reconstruction of the step surface, the system’s axial resolution and measurement accuracy are validated, with a population standard deviation of less than 1 μm. The system successfully reconstructs the object’s surface morphology, with the reconstruction results aligning with the design specifications. These findings confirm the system’s effectiveness and applicability in real-world scenarios, particularly where high-resolution surface profile data is required. The virtual grid transformation algorithm significantly improves data processing accuracy. It also offers strong flexibility, allowing the system to adapt to various measurement conditions and enhancing its dynamic response capability.ConclusionsIn this paper, we propose a novel line-array spectral confocal measurement system that replaces the traditional single-point fiber with a fiber bundle to realize multi-point, line-array detection. The system integrates a spectrometer structure composed of a reflective grating and an area-scan camera for synchronous multi-point spectral acquisition. A virtual grid transformation algorithm is developed for data processing, tailored to the characteristics of the captured images. Experimental validation confirms that the system improves measurement efficiency by a factor of seven compared to conventional methods. It achieves an axial measurement range of approximately 200 μm, with reproducibility under 0.95 μm and micrometer-level resolution. The system successfully reconstructs step morphologies in 3D, demonstrating its robustness and applicability in precision surface metrology.
Jun. 23, 2025Vol. 45 Issue 11 1112003 (2025)
Chao Wang, Haitao Wang, Qida Yu, and Bo Ni
ObjectiveCamera parameter estimation is a key research content in the field of visual measurement, with wide applications in robotics, augmented reality, autonomous driving, and other areas, holding significant academic and practical value. However, traditional PnP methods often heavily rely on the complete intrinsic parameters of the camera, particularly the focal length, which leads to a significant decrease in estimation accuracy in situations where the focal length is unstable or unknown. While traditional PnPf methods can handle cases with unknown focal length, they involve more unknown parameters, making the equation solving process more complex and less efficient. Moreover, most of these traditional methods are based on idealized geometric models, lacking in-depth analysis of the statistical properties of the estimators and failing to fully account for the impact of projection noise on estimation accuracy, making unbiased estimation difficult to achieve. In situations where the focal length is unknown, how to quickly, accurately, and robustly estimate both the camera pose and focal length remains an important problem that needs to be addressed and improved.MethodsThis paper revisits the PnPf problem from a statistical perspective and proposes a globally consistent PnPf solver. First, both the camera pose and focal length are treated as unknowns to be solved. A linear equation is constructed based on the original projection model to simplify the solving process, and a least squares solution is obtained that includes both the camera pose and focal length. Then, the asymptotic bias in the solution is eliminated through consistent estimation of the noise variance, resulting in a consistent and unbiased estimate of the camera pose and focal length. Finally, the solution is further optimized using the Gauss?Newton iterative method.Results and DiscussionsThe experimental results obtained using synthetic data and real data are as follows. 1) In synthetic data experiments, the method proposed in this paper demonstrates significant advantages in camera pose and focal length estimation. Compared to other existing methods, its estimation error is noticeably smaller, regardless of the noise intensity (Fig. 2). 2) Four images are selected from the ETH3D Benchmark dataset as experimental data, with each image containing thousands of feature points, indicating that designing a consistent solver is feasible (Fig. 3). 3) In real data experiments, the proposed method shows higher accuracy in camera pose and focal length estimation, and its running time is the shortest, and the solution efficiency is better than that of the current mainstream methods (Fig. 4).ConclusionsIn response to the high computational complexity and bias issues in traditional algorithms for camera pose estimation, we propose a new CPnPf solver aimed at reducing computational complexity while achieving more accurate camera pose and focal length estimation. The algorithm simplifies the solving process through linearization, enabling rapid estimation of camera pose and focal length. Additionally, from a statistical perspective, we revisit the PnPf problem and introduce a bias elimination method that effectively removes the impact of projection noise on the estimation results, thereby enhancing the overall solution accuracy. To validate the effectiveness of this method, we compare it with other state-of-the-art PnP and PnPf algorithms. Extensive experiments on both synthetic and real-world data demonstrate that the proposed algorithm outperforms existing algorithms in terms of both accuracy and efficiency.
Jun. 24, 2025Vol. 45 Issue 11 1115001 (2025)
Jiarui Lei, Jipeng Guo, Lan Wu, and Dong Liu
ObjectiveWith the accelerated progression of industrialization in China, the annual volume of decommissioned steel has surged significantly, resulting in the accumulation of massive steel scrap resources that form “urban mines”. These waste materials not only occupy substantial land resources but also pose potential environmental threats. In this context, short-process steelmaking, which utilizes electric arc furnaces to remelt steel scrap for new steel production, transforms scrap into a green and eco-friendly “industrial bloodstream” . Within this process chain, accurate and efficient evaluation and acceptance of steel scrap constitute a critical link for ensuring production efficiency and cost control. However, current manual inspection methods exhibit inefficiency and subjectivity, thereby constraining production scalability. Furthermore, valuation discrepancies among different inspectors can reach up to 300 yuan per ton, increasing the risk of transaction disputes and integrity violations. In present study, we report a hierarchical scene-based recognition framework and propose a multi-dimensional temporal deduplication algorithm for steel scrap, aiming to effectively address background interference, achieve precise deduplication, and maintain inter-frame consistency. The proposed method demonstrates significant advantages in terms of deduplication granularity, accuracy, and robustness, providing critical technical support for high-precision automated grading of steel scrap. We anticipate that this approach can be further extended to intelligent lifecycle management of steel scrap and contribute to establishing a traceable dispute resolution system for scrap recycling. This advancement is expected to facilitate the digital-intelligent transformation of the scrap recycling industry.MethodsThis paper proposes an intelligent steel scrap grading framework based on temporal deduplication technology, comprising four progressive operational phases. Initially, the system automatically extracts keyframe images from unloading videos by analyzing spatial relationships between grab buckets and cargo compartments. Subsequently, panoptic segmentation is applied to each frame to obtain category-agnostic steel scrap instances, followed by a bidirectional association algorithm for cross-frame object ID assignment. The backward association matches current-frame detections with prior-frame instances to inherit or allocate new IDs, while the forward association retroactively corrects prior-frame associations using current-frame IDs. The SAM2 tracker enhances temporal consistency through its visual similarity computation module, where memory encoders and attention mechanisms effectively address target morphological variations. Next, a change detection algorithm localizes dynamic regions within the compartment to filter background-interference IDs, thereby focusing statistical analysis on valid areas. Finally, a hybrid material-type recognition algorithm classifies retained instances. A composite segmenter, integrating EfficientViT-SAM, first generates target proposals via FastSAM and then refines mask segmentation. Material type proportions are statistically derived through ID-indexed recognition results. This temporal deduplication mechanism synergizes bidirectional association with composite segmentation, reducing inter-frame redundancy while ensuring spatiotemporal continuity in steel scrap counting, thereby providing a robust solution for industrial material grading applications.Results and DiscussionsThis paper presents comprehensive experimental evaluations to validate the proposed methodology. First, the designed Area-of-Interest (AOI) attention module was tested in smoke-occluded scenarios. Without AOI integration, detection results suffered significant smoke interference, achieving only 48% Intersection over Union (IoU) in changing regions. In contrast, AOI-enhanced implementation attained 96% IoU (Fig. 9), demonstrating exceptional robustness. Second, critical threshold parameters in the bidirectional association algorithm were optimized using Identity Switches as evaluation metrics, yielding optimal combinations of threshold parameters σb=0.1, σf=0.9 and σa=0.1. Subsequent visual analysis of algorithm stages (Fig. 10) reveals that the complete bidirectional association effectively integrates complementary advantages of backward and forward associations, ensuring unique ID assignment and precise temporal visualization for identical targets. Furthermore, real-time performance evaluation of the multi-dimensional temporal deduplication method quantified computational efficiency improvements. Optimized backward and forward associations reduced processed object counts from 290 to 50 and 240 to 70 respectively, with total execution time decreasing from 17.7 s to 7.4 s,notably below the 21.2 s average grab cycle duration. Finally, comparative analysis using relative error metrics demonstrates the superiority of our method, achieving merely 5% error versus conventional approaches [direct counting (160.7%), NMS (72.0%), LASER (41.1%), standalone backward association (67.3%), and standalone forward association (11.2%)]. These results conclusively establish the proposed method’s state-of-the-art performance in long-sequence scrap temporal deduplication tasks.ConclusionsCurrent intelligent steel scrap research predominantly focuses on “quality inspection” tasks, while the critical temporal deduplication problem in “grading” scenarios remains understudied. This paper presents the first systematic exploration of scrap temporal deduplication through a hierarchical scene recognition framework. Addressing multiple challenges including background interference, precise deduplication, and temporal consistency, we propose a multi-dimensional temporal deduplication algorithm for scrap materials. Experimental results demonstrate that our method exhibits significant advantages over existing technologies in deduplication granularity, robustness, and accuracy. Despite these advancements, the algorithm’s performance remains partially dependent on the underlying object tracker’s effectiveness. Particularly when handling multiple targets with high visual similarity, the tracker may generate unstable temporal associations (e.g., temporal ID flickering observed in the red truck side-rail case shown in Fig. 11), thereby compromising the robustness of final temporal deduplication. Future work will prioritize resolving precise deduplication challenges involving multiple visually similar objects to enhance system reliability.
Jun. 20, 2025Vol. 45 Issue 11 1115002 (2025)
Jingsai Ai, Zheng Sun, Yingsa Hou, and Meichen Sun
ObjectivePhotoacoustic spectral (PAS) imaging is a hybrid imaging modality that combines the photoacoustic effect with ultrasound detection to visualize biological tissues. This technique provides valuable information of the functional and molecular characteristics of tissues. By irradiating the target with multi-wavelength pulsed lasers, transient photon fields are generated within the tissue, leading to broadband ultrasound detected by an array of transducers. These signals undergo spectral unmixing, which enables the reconstruction of images that visualize and quantify various tissue components. However, a significant challenge in deep-tissue PAS imaging arises from the nonlinear dependence of the received signals on local molecular distributions, complicating accurate spectral decomposition. Traditional spectral unmixing methods, such as vertex component analysis (VCA) and independent component analysis (ICA), suffer from limitations due to their sensitivity to noise and the assumption of linear relationships.MethodsWe introduce a novel unsupervised deep learning framework, unsupervised photoacoustic spectral unmixing network (UPSU-Net), which accurately separates mixed spectra into individual component spectra without a priori data of absorption spectra, thus enhancing the precision and reliability of photoacoustic spectra. The proposed UPSU-Net utilizes a 3D convolutional autoencoder architecture designed to capture both spatial and spectral information from multi-wavelength PAS images. The encoder employs 3D convolutional layers to compress the input data while preserving spatial features, followed by an attention module that highlights critical features and reduces noise interference. The attention module is composed of global pooling and 3D convolution. Compared to traditional 2D convolution, 3D convolution is not only capable of processing 2D image data that contains spatial information (width and height) but also simultaneously capture information in an additional wavelength or temporal dimension. Therefore, it is more suitable for handling multi-dimensional data such as PAS data. The decoder consists of three fully connected layers, receiving the low-dimensional abundance features output by the encoder. After processing and nonlinear transformation through three fully connected layers, it learns the complex relationships between endmembers and ultimately reconstructs a high-resolution PAS image sequence, facilitating precise estimation of endmember spectra and their corresponding abundance.The network model is trained using a simulated dataset in an end-to-end manner and is tested using simulated, phantom, and in vivo datasets. The training procedure includes two phases: encoding and decoding. During the encoding phase, the input samples are encoded to obtain the expected output. In the decoding phase, the output of the encoding layer is decoded to produce the reconstructed result of the input samples. By adjusting the network parameters, the reconstruction error is minimized to achieve the optimal abstract representation of the input features. The loss function incorporates terms for data fidelity, regularization, and smoothness constraints, ensuring optimal feature extraction and preventing overfitting. Adam optimization with a learning rate of 0.001, a maximum epoch of 225, and a batch size of 64 is employed for training.Results and DiscussionsExperimental results demonstrate that UPSU-Net significantly outperforms traditional methods such as VCA and ICA, as well as other deep learning models like U-Net and cascaded autoencoders (CAE). Specifically, UPSU-Net achieves reductions in root mean square error (RMSE) of approximately 15.00% and 27.66% in estimating abundance compared to VCA and ICA, respectively. The structural similarity index (SSIM) increases by 15.39% and 17.86% compared to VCA and ICA. When compared to U-Net and CAE, UPSU-Net shows RMSE improvements of 34.62% and 24.44%, and SSIM improvements of 13.79% and 3.77%, respectively. The robustness of the network model is further validated under various conditions, including different noise levels and varying numbers of wavelengths. Ablation studies confirm that both 3D convolutions and the attention mechanism significantly enhance the accuracy of spectral unmixing.For simulated data, UPSU-Net successfully distinguishes optical absorbers with different components, even under nonlinear mixing scenarios where VCA struggles with noise and complex mixtures. In phantom experiments, UPSU-Net reliably identifies the positions and abundances of inclusions, whereas VCA, ICA, U-Net, and CAE exhibit reduced contrast between inclusions and background and suffer from significant artifacts. In vivo experiments further demonstrate that UPSU-Net provides clearer and more accurate depictions of target abundances, particularly for low-absorption endmembers, in comparison to baseline methods.ConclusionsUPSU-Net represents a significant advance in unsupervised spectral unmixing for multi-spectral photoacoustic imaging. By using 3D convolutions and attention mechanisms, UPSU-Net captures complex spatial-spectral relationships without relying on linear or independence assumptions, thereby improving sensitivity to low-absorption endmembers. Future work will explore the integration of PAS imaging models with advanced deep learning frameworks to implement spectral unmixing in a model-data co-driven manner. The deep learning model will not only learn the mapping relationship between PAS imaging data and endmember distributions and abundance from a large amount of data, but also make full use of the structured information provided by the physical model. This will result in better generalization capabilities, ensuring the accuracy of unmixing while reducing model complexity and dependence on training data. Furthermore, expanding the methodology to include four-dimensional (3D+spectral dimension) photoacoustic imaging could offer comprehensive structural and functional information, significantly advancing medical research and clinical applications. The robust performance of UPSU-Net across diverse datasets underscores its potential to make a substantial impact on the field of photoacoustic spectroscopy.
Jun. 24, 2025Vol. 45 Issue 11 1117001 (2025)
Zheng Wang, Jian Li, Biao Zhang, Chuanlong Xu, and Rui Guo
ObjectiveLight-field micro-particle image velocimetry (Micro-PIV) technology enables three-dimensional micro-scale flow field measurements using a single camera. The implementation of light-field Micro-PIV involves capturing light-field images, reconstructing the three-dimensional spatial distribution of tracer particles, and analyzing the particle field through cross-correlation methods to measure micro-scale flow fields. The rapid and accurate reconstruction of three-dimensional spatial particle distribution remains crucial for precise velocity field measurement. Traditional reconstruction techniques, including Lucy?Richardson iterative deconvolution, demonstrate inefficiencies and significant axial elongation of reconstructed particles. Despite various optimizations, these conventional algorithms retain inherent limitations. Recent research has introduced deep learning-based methods for particle field reconstruction. However, purely data-driven deep learning models exhibit limited reconstruction accuracy and generalization performance, often producing artificial particles and residual axial elongation effects. This paper addresses these limitations by proposing a physics-informed deep learning for particle reconstruction (PIDLR) model that incorporates physical constraints into deep learning processes to enhance particle field reconstruction quality and model generalization capability.MethodsThe methodology comprises several key steps. Initially, a particle field reconstruction network based on the U-Net architecture undergoes training using the particle distribution-optical field image dataset. The process then incorporates a forward imaging mechanism model to refine the pre-trained inverse reconstruction network, followed by performance evaluation. Numerical reconstruction methods assess the PIDLR model’s reconstruction quality and accuracy, comparing its performance against purely data-driven deep learning models. The final phase involves experimental measurement of laminar flow on a Y-typed microfluidic chip, comparing the velocity measurement accuracy between the proposed model and the purely data-driven U-Net model to evaluate practical application effectiveness.Results and DiscussionsReconstruction of numerical simulation data indicates that within the tracer particle concentration range from 0.4 ppm (particle per microlens) to 1.2 ppm, the PIDLR model outperforms the U-Net model by improving the reconstruction quality factor by 16.31% (Fig. 8). In addition, it also reduces the degree of axial stretching and thus improves the axial resolution (Fig. 7). For the experimental validation, the three-dimensional velocity field within a Y-typed microfluidic chip is calculated through cross-correlation algorithm. The PIDLR model effectively captures the flow characteristics at various locations inside the Y-shaped channel (Fig. 11). At the central cross-section of the channel (z=50 μm), the velocity distribution derived from the PIDLR model exhibits a strong agreement with the theoretical velocity field (Fig. 13). Additionally, a quantitative comparison of velocity measurements in the xoy plane reveals that the average relative errors for PIDLR and U-Net are 14.82% and 11.35%, respectively. These findings confirm that PIDLR can realize the velocity field measurement with higher accuracy than the purely data-driven U-Net model, thus demonstrating its practical potential.ConclusionsThis paper presents a PIDLR model for three-dimensional particle spatial distribution in light field micro-particle image velocimetry, addressing the limitations of purely data-driven deep learning models. Numerical simulations and experimental flow measurements of a Y-shaped microchannel demonstrate the model’s effectiveness. Within the particle concentration range of 0.4?1.2 ppm, simulation results reveal that PIDLR improves the reconstruction quality factor by 16.31% and enhances axial resolution by 33.47% compared to the U-Net model. For particle concentrations outside the training dataset range (0.3 ppm and 1.3 ppm), PIDLR achieves an average reconstruction quality factor up to 10% higher than the U-Net model, demonstrating superior reconstruction performance and generalization ability. In Y-shaped microchannel laminar flow measurements, the velocity field calculated using PIDLR shows a relative error of 11.35% compared to theoretical values, outperforming the U-Net model’s 14.82% error. These results validate the effectiveness of the PIDLR model in improving velocity field measurement accuracy.
Jun. 10, 2025Vol. 45 Issue 11 1118001 (2025)
Guanglu Zhang, Wentao Zhang, Yiqiang Sun, Qirui Wang, Zhipeng Wang, Zhihong He, and Shikui Dong
ObjectiveIn the solid rocket motor exhaust system, the spectral radiation of high-temperature alumina particles in the tail flame enhances the infrared radiation signal of the flame, which is particularly important for early warning, detection, identification, and tracking of flight targets. Therefore, it is necessary to accurately measure the spectral radiation characteristics of alumina at high temperatures (above 2000 K). When measuring the spectral radiation signal of a high-temperature alumina sample, it is necessary to both maintain uniform temperature to ensure accurate measurement results and keep the maximum thermal stress within the sample below its bending strength, so that the entire measurement process runs smoothly. Therefore, a new heating scheme should be designed to ensure the temperature uniformity and low stress in alumina samples at high temperatures.MethodsTo investigate the temperature and stress distribution within samples during high-power laser heating, a multi-physics coupling model in radiation-heat-mechanics (Fig. 1) is established in COMSOL for numerical simulation. Considering the translucent nature of alumina, we introduce a penetration index (Fig. 3) derived from the absorption coefficient (Fig. 2). Based on the magnitude of the penetration index at different wavelengths, the entire spectrum is divided into distinct intervals, and a CO2 laser with a wavelength of 10.6 μm is selected as the heat source due to its inability to penetrate the alumina sample, which enables effective heating. Next, the model’s computational results are compared with literature data, showing a relative error of less than 2.5% (Fig. 6), which validates the accuracy of the proposed model. Building upon the original heating scheme, a new heating strategy (Fig. 7) is designed, which incorporates a beam-shaping system for optimized energy distribution, a beam-expanding system to reduce power density, and thermal insulation measures to minimize heat loss. Comparative analyses in terms of temperature uniformity and low stress levels demonstrate the superiority of the new laser heating scheme. Finally, the temperature and stress characteristics of the improved design are analyzed, which reveals the temperature-power relationship and stress-power correlation under varying laser power.Results and DiscussionsUnder identical laser power conditions, the optimized laser heating system significantly reduces dimensionless temperature differences in both axial and radial directions compared to the original system, thus achieving substantial improvements in temperature uniformity (Fig. 9). For alumina samples under the proposed heating scheme, the axial maximum temperature difference increases gradually with rising sample temperature but remains strictly controlled within 5 K [Fig. 10(a)]; Radial maximum temperature difference ranges between 15?40 K [Fig. 10(b)], with a peak dimensionless difference of 1.51%, which confirms effective temperature homogeneity at elevated temperatures. Subsequently, the hemispherical emissive power distribution of the sample surface under the optimized laser heating system is compared with that under ideal conditions (uniform temperature distribution). The results indicate close alignment between them (Fig. 12), which demonstrates that the temperature uniformity of high-temperature alumina samples achieved by the proposed heating system meets the requirements for radiation property measurements in experimental applications. Additionally, stresses exceeding the bending strength of alumina (379 MPa) lead to catastrophic fracture in plate-like samples. Under 240 W laser power with fixed bottom-surface boundary conditions (zero axial displacement at the lower surface), the redesigned heating system (Fig. 13) significantly reduces internal thermal stresses compared to the original system. Importantly, the stresses remain consistently below 379 MPa throughout the heating process (Fig. 14), which effectively prevents sample fragmentation. Finally, for temperature characteristics of alumina samples, the steady-state temperatures of the alumina sample under varying laser power density rates are systematically analyzed. Results demonstrate that under fixed boundary conditions, the maximum steady-state temperature during high-power laser heating is solely dependent on the laser power density, independent of its temporal variation rate (Fig. 15). Further investigation reveals a near-perfect power-law relationship between the maximum steady-state temperature (1500?2250 K) and the applied laser power density. A temperature characteristic curve is derived through regression fitting with an R2 value of 0.99998 (extremely close to 1), which confirms the exceptional accuracy of the model (Fig. 16). For thermal stress characteristics of alumina samples, under specified geometric and material properties of the alumina sample, the stress loading coefficient (proposed in this study) is substituted for the laser power density variation rate to investigate the variation of maximum internal thermal stress under diverse conditions. However, estimating the maximum thermal stress solely from laser power density or thermal stress loading coefficients proves to be challenging (Fig. 17). To address this, the ratio of maximum thermal stress to laser power density loading time is introduced, which reveals an approximately linear proportionality to the stress loading coefficient. A thermal stress characteristic line is fitted to the data with an R2 value of 0.99874, which demonstrates a robust correlation (Fig. 18).ConclusionsWe focus on alumina samples, establishing a multi-physics coupling model in radiation-heat-mechanics to investigate the internal temperature and stress distributions under high-power CO2 laser irradiation. A novel heating strategy is proposed, utilizing a beam shaping system and beam expanding system combined with lateral thermal insulation, with key improvements over the original method. This optimized approach significantly enhances temperature uniformity in high-temperature alumina samples. Under operating conditions above 2000 K, axial and radial temperature differences are controlled within 5 and 40 K, respectively. Additionally, it effectively reduces thermal stresses during heating, which ensures that stresses remain below the material’s bending strength throughout the process. Finally, the relationships between laser power parameters (magnitude and rate of change) and the resulting temperature/stress profiles are systematically analyzed. We provide temperature-power and stress-power characteristic curves for alumina under this heating scheme, offering critical references for experimental optimization.
Jun. 10, 2025Vol. 45 Issue 11 1122001 (2025)
Shucong Zhao, Lin Yan, Yujie Peng, Peng Xiao, Jiaming Tang, Wanjun Hu, Junwen Xue, and Siguang Ma
ObjectiveThe characterization of single-photon detectors (SPDs) plays an important role in the development and application stages of SPDs. The demand grows as the application of solid-state SPDs rapidly increases in fields such as LiDAR and low-light imaging. Since SPDs typically respond to incident photons over a wide spectral range, measurement of the photon detection efficiency (PDE) of an SPD over its entire spectral response range (i.e., PDE spectrum) becomes a complex and time-consuming task. Traditionally, the correlated-photon method and the standard detector substitution (SDS) method are commonly used for the measurement of PDEs of SPDs. However, these methods require additional measurements and corrections for the dead time, afterpulsing, and dark count effects to obtain an accurate PDE. This limitation can be overcome using our recently proposed event-refreshed time-to-digital converter (ER-TDC)-based method. In this study, we design and develop an automatic PDE spectrum testing system based on ER-TDC to improve measurement efficiency and repeatability, and its performance is fully tested.MethodsA dedicated system, consisting of a light-emitting diode (LED) array and an ER-TDC, is designed and developed for measuring PDE spectra (400?1100 nm) of SPDs [Fig. 2(a)], with the supporting automatic measurement procedure (Fig. 4) implemented in Python. The spectral and temporal emission characteristics of the LEDs at different powers (1.0?800.0 nW) are measured using a fiber optic spectrometer and ER-TDC, respectively. Power calibration measurements are conducted on the automatic system exploiting two calibrated photodiodes (PDs). The performance of the automatic system is tested at various LED emitting powers using a commercially available silicon single-photon avalanche diode (Si-SPAD), and the resulting PDE spectrum is compared with that measured by the traditional SDS method [Fig. 2(b)].Results and DiscussionsThe central wavelength (Fig. 5) and power calibration coefficient (Fig. 8), which are two parameters required for PDE calculations, are determined from the LED emission spectra and power calibration measurements, respectively. The spectral characteristics of each single-color LED employed in the LED array (Fig. 6) and the corresponding measured PDE (Fig. 11) are independent of the emitting powers of the LEDs, which is a significant advantage of the developed technique. The PDE spectrum of the Si-SPAD measured by the automatic system is in excellent agreement with that obtained by the traditional SDS method [Fig. 12(a)], which demonstrates the accuracy and effectiveness of the automatic system. In addition, the developed automatic system achieves a measurement speed of 122 s/point and a relative standard uncertainty of less than 3.1% in the 400?1000 nm range [Fig. 12(b)], and these performance parameters are comparable to those of the traditional SDS method.ConclusionsAn automatic system based on an LED array and an ER-TDC is designed and developed for measuring PDE spectra of SPDs. The spectral and temporal emission characteristics of each single-color LED, and the power calibration coefficients, are presented. The performance of the automatic system is tested and demonstrated using a Si-SPAD. This system enables fully automatic measurements of PDE spectra in the 400?1100 nm range, achieving a measurement speed of 122 s/point while maintaining a relative standard uncertainty below 3.1% over the 400?1000 nm sub-range. The developed automatic system is easy to operate, cost-effective, and eliminates the need for additional measurements and corrections for the dead time, afterpulsing, and dark count effects, which makes it suitable for batch characterization of PDE spectra of visible and near-infrared SPDs.
Jun. 24, 2025Vol. 45 Issue 11 1122002 (2025)
Shi Yan, Feng Luo, Shangyu Zhang, Jian Dong, and Wenjie Zhang
ObjectiveOptical solar reflectors (OSRs) are widely used as radiative cooling coatings in spacecraft thermal control systems due to their low solar absorptivity and high infrared (IR) emissivity. With the continual increase in spacecraft power density, the demand for improved thermal dissipation capabilities in OSRs has grown. However, traditional OSRs exhibit intrinsically low emissivity in parts of the mid-to-far infrared range, primarily due to abrupt changes in the optical constants of surface materials such as quartz glass around 8.9 and 20.8 μm. This significantly limits their radiative cooling performance. To address this issue, we propose a novel surface microstructure design aimed at enhancing IR emissivity and improving thermal dissipation efficiency. Previous research on radiative property modulation through microstructured surfaces has mainly focused on optimizing dimensional parameters within predefined geometries. Such approaches are constrained by fixed geometric morphologies, thus limiting the ability to achieve true structural optimization. To overcome these limitations, we employ the material-field series-expansion (MFSE) topology optimization method, which enables simultaneous optimization of both geometric morphology and dimensional parameters. This approach allows the discovery of globally optimal structures beyond predefined shapes. In addition, the MFSE method substantially reduces the number of design variables while maintaining high optimization precision, thus lowering computational costs.MethodsThe effectiveness of topology optimization based on the pseudo-density method has been widely demonstrated. In this paper, it is applied to optimize OSR surface microstructures, aiming to maximize average emissivity over the 5?30 μm range to enhance thermal dissipation. A quartz glass OSR coated with aluminum is selected as an example. A surface layer of specified thickness is selected as the design domain, which is discretized into finite elements. The geometric center of each element serves as an observation point for constructing the material field. To avoid the formation of unmanufacturable suspended structures due to simultaneous optimization along both the x and y directions, different coherence lengths are assigned to each axis, restricting optimization to the x direction for structural feasibility. The material field is then expanded using eigenvalue decomposition and truncated based on a predefined threshold to achieve dimensionality reduction. The reduced-order material field model is integrated with material properties using an interpolation function to represent the OSR surface microstructure. Spectral emissivity is computed using the finite element method (FEM), and the sensitivity of the objective function with respect to the MFSE coefficients is evaluated. This sensitivity is fed into the method of moving asymptotes (MMA) for iterative optimization until convergence is reached, completing the topology optimization process.Results and DiscussionsMFSE-based topology optimization yields a surface grating microstructure for the OSR (Fig. 6). Unlike traditional methods that optimize size with a single periodic geometry, the proposed method generates multiple protrusions of varying widths, achieving simultaneous optimization of geometry and size. Under p-polarized incidence, the previously low emissivity in the infrared range is almost entirely eliminated. Improvements are also observed under s-polarized incidence (Fig. 7). To evaluate the overall thermal control performance, We calculate the Planck-averaged solar absorptivity, average infrared emissivity, and the solar absorption-emission ratio before and after optimization are calculated. The results indicate a significant increase in average emissivity across the 5?30 μm range, with minimal change in solar absorptivity in the 0.3?2.5 μm range (Table 1). Electric field distribution analysis of the optimized microstructure (Fig. 8) shows that surface phonon polariton (SPhP) modes are excited, resulting in multiple regions of high electric field intensity near the microstructure boundaries. These strong field areas enhance the power absorption density of the OSR (Fig. 9), thereby effectively improving its absorption characteristics in the infrared range.ConclusionsTo address the intrinsic low emissivity at 8.9 and 20.8 μm that limits the thermal dissipation performance of traditional OSRs, we employ the MFSE topology optimization method to design a novel surface microstructure for quartz glass aluminum-plated OSRs. The optimized structure significantly enhances infrared emissivity and improves thermal dissipation efficiency. Results demonstrate that the method surpasses conventional geometric constraints by enabling simultaneous optimization of shape and size, while greatly reducing the number of design variables and enhancing optimization efficiency. After optimization, the minimum emissivity under p-polarized incidence at 8.9 and 20.8 μm increases from 0.28 and 0.43 to 0.91 and 0.89, respectively. Under s-polarized incidence at 20.8 μm, emissivity rises from 0.43 to 0.81. Overall, the average emissivity in the 5?30 μm range increases from 0.839 to 0.941, while solar absorptivity in the 0.3?2.5 μm range remains unchanged. The solar absorption-emission ratio drops from 0.00739 to 0.00244, a 67% reduction, and thermal dissipation efficiency improves by 12.2%. These improvements are attributed to the excitation of SPhP modes and enhanced local electric fields. The proposed method offers a novel approach for optimizing thermal control coatings in spacecraft, with significant implications for performance improvement and lightweight design.
Jun. 23, 2025Vol. 45 Issue 11 1122003 (2025)
Zhuo Zou, Wenbin Feng, Zhiqiang Liu, Ning Wei, and Mao Ye
ObjectiveLiquid crystal (LC) lenses have attracted widespread attention in modern optics due to their tunable focal lengths and adaptability in a range of cutting-edge applications, including virtual reality (VR), augmented reality (AR), and machine vision systems. These lenses exploit the unique electro-optical properties of liquid crystals to achieve variable optical characteristics. However, conventional LC lenses often face limitations due to the necessity of operating within the linear response region of LC materials. This constraint not only restricts the achievable focal power but also limits the effective utilization of birefringence, which is critical for optimizing lens performance. In this paper, we aim to address these inherent limitations by proposing an innovative circular LC lens design that enables a parabolic phase distribution even under nonlinear voltage driving. This approach provides greater flexibility and efficiency in light modulation, leading to enhanced optical performance across a wider range of operating conditions. By overcoming the constraints of linear behavior, our design maximizes the potential of liquid crystal materials and paves the way for advanced optical systems. Ultimately, this paper highlights the potential of nonlinear dynamics in LC lens technology and demonstrates their value for future adaptive optics applications.MethodsWe develop a hybrid approach combining electrode structure optimization and nonlinear voltage driving. Concentric circular electrodes with envelope functions are designed to generate voltage distributions suitable for the nonlinear response region of the liquid crystal material (HTG116900-100, Δn=0.206). These electrodes are fabricated using photolithography, and the liquid crystal cells are assembled with a 20-micron thick LC layer. Interferometric measurements (Fig. 7) are conducted to capture the phase profiles under varying voltages, allowing analysis of LC’s optical characteristics and phase behavior. Zernike polynomial fitting (Figs. 9 and 11) is applied for phase distribution and wavefront analysis. Image quality is evaluated by measuring the root mean square contrast (RMS contrast) and birefringence utilization rates (Table 3). RMS contrast reflects image clarity and contrast of the image, while birefringence utilization rate reflects the effective use of the material’s optical anisotropy. These metrics provide crucial insight into the practical performance and future optimization of the proposed LC lens design. This integrated approach enables improved optical behavior under nonlinear driving conditions, enhancing the competitiveness of LC lenses in advanced optical systems.Results and DiscussionsThe proposed design achieves parabolic phase profiles in both linear and nonlinear response regions. Key results include: 1) enhanced birefringence utilization. The birefringence utilization rate increases from 33.3% to 66.2% for positive lenses and from 32.1% to 67.6% for negative lenses, corresponding to improvements of 98.93% and 110.4%, respectively (Fig. 11). 2) Nonlinear voltage compatibility. With the optimized envelope function of the concentric electrodes (Fig. 4), the lens maintains a parabolic phase distribution even at voltages beyond the linear threshold (V=4.5Vrms), with R-Square values above 0.99 for phase fitting (Table 2). 3) Imaging performance. Resolution tests using ISO 1233 charts demonstrate accurate focusing at the designed voltages (Figs. 13 and 14), supported by RMS contrast values peaking at 0.2550 (Table 3).ConclusionsIn this paper, we present an innovative design for a circular LC lens that extends the operating voltage range into the nonlinear response region while maintaining a parabolic phase distribution. By optimizing the electrode structure and driving method, the proposed design significantly enhances both focal power and birefringence utilization, addressing long-standing limitations in LC lens technology. The improved electrode configuration enables effective control of the liquid crystal materials across a wider voltage range, thus expanding the application potential of LC lenses in dynamic imaging systems. This design not only improves image quality but also flexibly meets optical requirements under various operating conditions, offering new opportunities for the development of compact and high-performance optical devices. Moreover, the results demonstrate that the optimized driving method allows more efficient utilization of the birefringence properties of the LC material, leading to further improvements in optical performance. This is particularly critical for multifunctional optical systems that require fast response and wide dynamic range. Future research will focus on the scalability of this LC lens design, aiming to support mass production and explore its integration into multifunctional optical platforms. In combination with other optical technologies, this approach may further enhance LC lens performance and facilitate the widespread adoption of LC technology in emerging fields, such as wearable devices, intelligent imaging systems, and miniaturized optical instruments.
Jun. 20, 2025Vol. 45 Issue 11 1123001 (2025)
Jinqun Zhou, Hua Miao, and Xiaofeng Liu
ObjectiveFlexible polymer waveguides, characterized by high bandwidth, low loss, shape flexibility, ease of integration, high-density interconnection capabilities, and high reliability, represent a prime choice for realizing high-speed, reliable, and cost-effective optical interconnections within next-generation high-performance board-level interconnection architectures. Nevertheless, challenges such as mode-related losses and coupling issues in these waveguides remain to be resolved. This work is dedicated to the fabrication of high-reliability flexible polymer waveguide devices and a comprehensive exploration of their high-speed transmission performance.MethodsThe flexible waveguide lamination structure and mechanically transferable (MT) component coupling structure were meticulously regulated. The core and cladding materials with a refractive index difference of about 0.011 at 850 nm were used. The flexible waveguide was fabricated on polyimide substrate via conventional lithography techniques. Passive horizontal coupling termination of the flexible waveguide was combined with MT components, and an epoxy encapsulation adhesive was utilized for molding purposes.Results and DiscussionsThe fabricated flexible waveguide device demonstrated outstanding alignment, with waveguide channel coupling misalignment effectively confined within 8 μm. For a 220-mm-long flexible waveguide link, the average insertion loss was 6.64 dB, which could be decomposed into a waveguide transmission loss of 3.30 dB, an average coupling loss of 0.5 dB at the Tx port, and an average coupling loss of 2.84 dB at the Rx port, primarily attributed to mode mismatch. When integrated into a 10 Gbit/s high-speed transmission system, error-free transmission was successfully achieved, accompanied by the acquisition of an open eye diagram. The device exhibited robust optical properties, and its high-speed transmission performance remained largely unaffected under a bending radius of 2.5 mm and two twists, with negligible degradation in the eye diagram. Following an aging test with a temperature of 85 ℃ and a relative humidity of 85% and a temperature cycling test, the transmission performance of the waveguide device did not exhibit significant deterioration.ConclusionsThis work successfully realized rapid horizontal coupling termination of flexible waveguides via passive alignment methods. The fabricated flexible waveguide devices feature precise alignment, low insertion loss, and exceptional high-speed transmission performance and reliability. These devices hold great promise for substituting fiber arrays and serving as core optical components in the domain of board-level optical interconnections.
Jun. 23, 2025Vol. 45 Issue 11 1123002 (2025)
Wenjun He, Mingxing Li, Jiaxin Hou, Yuan Liu, Yajun You, and Yi Liu
ObjectiveA microwave photonic filter (MPF) is a key processing device used to accurately extract the target signal, eliminate or suppress noise and stray signals, improve the purity of the signal spectrum, and meet the strict transmission performance requirements of modern communication systems. It has advantages such as large bandwidth, low transmission loss, fast processing speed, and strong resistance to electromagnetic interference. With the development of communication systems, various types of dual-band MPF research have emerged. The stimulated Brillouin scattering (SBS) effect is widely used to realize narrow-band MPF due to its ultra-narrow gain spectrum and large suppression ratio. The natural linewidth of the Brillouin scattering gain spectrum is mainly affected by the phonon lifetime in fiber materials, typically between 10?20 MHz. This characteristic limits the application of Brillouin scattering in high-resolution filtering. Therefore, the key to further reducing the filter passband bandwidth lies in achieving a narrower Brillouin gain spectrum. To achieve a passband bandwidth below 1 MHz, other performance aspects, such as the out-of-band rejection ratio, also need to be optimized. We construct a dual-wavelength laser by exciting a second-order Stokes light and combine the excellent narrowing Brillouin gain linewidth effect based on the Brillouin laser resonator with the dual-ring cavity dual-wavelength structure to obtain a dual-channel narrow-bandwidth Brillouin fiber laser microwave photonic filter.MethodsA 10 m unpumped erbium-doped fiber (UP-EDF) is used to form a saturated absorption ring, while a 100 m single-mode fiber (SMF) ring forms a dual-ring cavity structure. The dual-channel narrow-bandwidth microwave photonic filter is created by combining the Vernier effect of the dual-ring cavity with the dual-wavelength Brillouin fiber laser. By using two different cavity lengths to match different resonant modes for mode selection, the filter passband of MPF is narrowed, thus achieving side mode suppression. The radio frequency (RF) signal output by the microwave source remains unchanged at 5 GHz, and the Brillouin gain amplifies the sweep modulation signal, forming two passbands at the center frequencies of 5.735 and 16.475 GHz.Results and DiscussionsWe test the performance of the proposed dual-channel narrow bandwidth Brillouin fiber laser microwave photonic filter. According to the structure shown in Fig. 1, the frequency-shifted modulated signal light and the dual-wavelength single-longitudinal-mode Brillouin laser spectrum are measured, as shown in Fig. 4. The bandwidth and side-mode suppression ratio of the dual-band filter are tested. When the sub-ring cavity is not connected, only the Brillouin laser resonator is used for the filtering test. The passbands of the two comb filters are measured by vector network analyzer (VNA), which are 5.735 and 16.475 GHz, respectively. As shown in Fig. 5(a), the Brillouin gain spectrum is narrowed to a comb, and the comb bandwidth is significantly smaller than the Brillouin gain bandwidth. The out-of-band rejection ratios of the two passbands are 7.8 dB and 9.0 dB, respectively. When the sub-ring cavity is connected, the results are shown in Fig. 5(b). The side mode suppression ratios of 28.1 dB and 27.9 dB are obtained at 5.735 and 16.475 GHz, respectively. Then, the bandwidth of the proposed MPF is tested, and Lorentz fitting is performed on the amplified bandwidth. The 20 dB bandwidth extended at 5.735 GHz is 152 Hz, and the bandwidth extended at 16.475 GHz is 118 Hz, as shown in Fig. 5(b). A long-time filter stability test is conducted. At 5.735 GHz, continuous measurement is performed for 120 min at room temperature of (25±1) ℃, with an interval of 10 min. The experimental results are shown in Fig. 6. The drift of the center frequency is about 150 Hz, and the measured value of the narrow linewidth jitter is about 10 Hz, which may be caused by the sensitivity to ambient temperature and noise. Therefore, it is believed that as the basic performance of the filter, the performance of the filter is relatively stable.ConclusionsIn summary, we propose and experimentally verify a dual-channel narrow-bandwidth Brillouin fiber laser microwave photonic filter based on a second-order Brillouin laser. Two single-mode fibers with different cavity lengths of 100 and 10 m, un-pumped erbium-doped fibers, are used to match different resonant modes for mode selection, forming a Vernier effect that narrows the filtering bandwidth of the MPF and achieves high side mode suppression. This method solves the issue of the comb gain spectrum formed by the long cavity corresponding to the small FSR and ensures that there is only one filter passband in a single gain spectrum. The dual-passband is the signal light generated by the VNA sweep modulation. When passing through the dual-wavelength Brillouin laser, the optical power located in the Brillouin gain spectrum is amplified to achieve frequency selection. By combining this with the dual-ring cavity structure, the passband bandwidth is further narrowed, which results in higher out-of-band suppression, with values of 28.1 dB and 27.9 dB. The final filter bandwidths of the microwave photonic filter are 152 and 118 Hz, with high-frequency precision filtering. Theoretically, as long as the pump power is large enough, third-order or even higher-order Stokes light can be generated, corresponding to a triple-passband or even multi-passband filter. This research is of great significance for the development of microwave photonic filter devices with multi-band collaborative processing and high-frequency resolution. It is expected to break through the physical bottleneck of traditional microwave filters and provide high-performance, intelligent spectrum management solutions for the next generation of communication, sensing, and defense electronic systems.
Jun. 23, 2025Vol. 45 Issue 11 1123003 (2025)
Jiankang Guo, Hanxiang Jia, Qian Gao, and Xun Cao
ObjectiveElectrochromic devices (ECDs) based on the resonant cavity structure can convert subtle changes in the refractive index of the electrochromic thin film into color changes with high contrast, based on the principle of optical interference, thus enabling the regulation of multiple colors. They exhibit great potential in the fields of dynamic color display, wearable electronics, and anti-counterfeiting. However, at present, the vast majority of research is based on liquid or gel electrolyte systems, which have defects such as liquid leakage and poor cycling stability in practical applications. These drawbacks severely limit their future development. In contrast, all-solid-state ECDs are free from these concerns. They have good cycling stability and the potential for industrial production, allowing for large-scale manufacturing. Nevertheless, due to the multi-layer thin-film stacking structure of all-solid-state ECDs and considering the ion transport efficiency and electrochromic performance, it is difficult to construct a resonant cavity structure to achieve multiple color changes. If multi-color regulation can be realized in all-solid-state ECDs, the application scope of colored ECDs will be further expanded, and they will have broader application prospects in fields such as color display, wearable electronics, and anti-counterfeiting.MethodsIn this study, without altering the structure of traditional all-solid-state ECDs, a dielectric-metal-dielectric (DMD) composite electrode was fabricated using the magnetron sputtering method. The effects of three different metal materials (Au, Ag, and Cu) and the thickness of the indium tin oxide (ITO) dielectric layer on the DMD structure were investigated respectively. An in-situ reflection spectrum of the samples in the range of 350 to 750 nm was characterized using a Hitachi UV-4100 ultraviolet/visible/near-infrared spectrometer at a scanning speed of 1200 nm·min⁻¹ to select the optimal metal material. By using an optical simulation software and the optical constants of ITO and Ag, the human eye’s photopic luminous efficiency integral value (R) was calculated to further optimize the thickness of each film layer in the DMD structure, aiming to optimize the experimental spectrum and achieve a variety of gorgeous structural colors. Subsequently, all-solid-state ECDs were prepared. The cross-sectional morphology of the samples was characterized using a field-emission scanning electron microscope (model: FEI Magellan 400), and a line-scan energy-dispersive X-ray spectroscopy (EDS) was performed to identify the distribution of characteristic elements in each film layer, so as to optimize the thin-film preparation process.Results and DiscussionsBy utilizing the DMD composite electrode structure, a resonant cavity was constructed inside the electrode. Based on the principle of optical interference, a variety of static structural colors were successfully achieved. Moreover, before and after the color change of WO3, multiple color changes were realized (Fig. 1). Silver (Ag) was selected as the optimal metal layer, and it was found that when the thickness of the Ag layer was optimized to 10 nm, the DMD structure could produce significant optical changes, enabling the dynamic modulation of various visible lights. Based on the simulation of the R value, by adjusting the thickness of the ITO layer and the multi-layer DMD structure, seven static structural colors with high brightness and high saturation were successfully obtained [Fig. 6(a)]. Additionally, an all-solid-state ECD with a red structural color was fabricated. Under the action of an applied voltage, a reversible conversion from red to deep red was successfully achieved (Fig. 7).ConclusionsIn this study, the difficulty in constructing a resonant cavity within the all-solid-state electrochromic system was overcome. Without altering the structure of traditional all-solid-state ECDs, a DMD composite electrode structure was designed and fabricated. A systematic exploration was carried out on the collaborative regulation mechanism of three different metal materials, namely Au, Ag, and Cu, and the effect of thickness of the indium tin oxide (ITO) dielectric layer on the interfacial light transmission behavior was studied. Various DMD composite electrode structures were prepared using the magnetron sputtering method, and with the effect of WO₃, the regulation of multiple color changes was achieved. Both experimental results and optical simulations demonstrate that when the thickness of the Ag layer is 10 nm, it forms the best match with the dielectric constant gradient of ITO, resulting in the strongest light interference effect, which enables the preparation of various structural colors. Meanwhile, by precisely controlling the thickness gradient of the ITO layer in the DMD structure, seven different static reflective structural colors in the CIE 1931 chromaticity diagram were realized within the all-solid-state system. Furthermore, by combining with the electrochromic ability of the WO₃ thin film, an all-solid-state ECD with a reversible conversion from red to deep red was successfully fabricated, achieving a reflection modulation amplitude of up to 50% in the visible light band. It has promising application prospects in fields such as color display, wearable electronics, and anti-counterfeiting.
Jun. 10, 2025Vol. 45 Issue 11 1123004 (2025)
Gongli Xiao, Linglong Pei, Hongyan Yang, Kai Li, Hui Li, Haiou Li, and Zanhui Chen
ObjectiveTo address the limitations of static multifunction devices and the functional singularity of dynamic single-function devices, this study presents an innovative design of a stretchable chiral metasurface with multifunctional characteristics and extensive dynamic adjustment capabilities. The chiral metasurface comprises a polydimethylsiloxane (PDMS) substrate, a polyimide dielectric layer, and upper and lower aluminum (Al) metal resonant layers. The asymmetrical distribution between the upper and lower Al metal resonant layers enables multiple simultaneous functions. Additionally, the stretchable properties of PDMS allow for enhanced asymmetrical distribution through unidirectional mechanical stretching of the PDMS substrate, enabling extensive dynamic adjustment of its multiple functions. Numerical simulation results demonstrate wide-ranging dynamic tuning of various optical phenomena, including asymmetric transmission, polarization conversion, circular dichroism, and asymmetric reflection, each exhibiting substantial dynamic adjustment ranges. This research demonstrates superior versatility while providing extensive dynamically adjustable characteristics. The proposed metasurface combines the excellent performance of both static multifunctional devices and dynamic single-function devices, showing significant potential for next-generation optical devices and providing theoretical foundation for the design of advanced stretchable multifunctional electromagnetic sensors and optical displays.MethodsIn this study, we propose a multifunctional, dynamically tunable stretchable chiral metasurface. The structure comprises a PDMS substrate, a polyimide dielectric layer, and metal layers. This metasurface exhibits excellent performance metrics, including an asymmetric transmission (AT) factor of 0.77, a polarization conversion rate (PCR) of 1.00, a circular dichroism (CD) parameter of 0.81, and an asymmetric reflection (AR) factor of 0.77. Furthermore, by stretching the PDMS substrate, the metasurface demonstrates a wide range of dynamic tunability: the AT factor can be adjusted within a range of 0.45, the PCR within 0.82, the CD parameter within 0.81, and the AR factor within 0.65. This research not only showcases superior multifunctionality but also offers extensive dynamic tunability, presenting significant potential for application in next-generation optical devices.Results and DiscussionsThe results demonstrate that the J-shape resonant structure combined with the PDMS substrate exhibits multifunctional and dynamically adjustable characteristics. The design supports AT, PCR, CD, and AR capabilities (Fig. 2). Through unidirectional mechanical stretching of the PDMS substrate, significant dynamic adjustments are achieved: at 1.16 THz, the AT factor varies from 0.32 to 0.77, spanning a range of 0.45; peak PCR adjusts between 0.91 and 0.18 at 1.0 THz, covering a range of 0.82; CD parameters range from 0 to 0.81 at 0.90 THz, with a range of 0.81; and the AR factor varies from 0.12 to 0.77, encompassing a range of 0.65 (Fig. 3). Electric field analysis reveals that stretching the PDMS substrate enhances charge asymmetry between upper and lower metal layers during polarized light incidence, enabling extensive dynamic adjustment of asymmetric transmission and polarization conversion characteristics. For circularly polarized light incidence, substrate stretching amplifies the asymmetrical charge distribution between metal layers relative to skewed lines, facilitating wide-ranging dynamic adjustment of circular dichroism and asymmetric reflection properties (Figs. 4 and 5). The developed metasurface demonstrates superior performance and extensive dynamic property adjustment compared to previously reported designs (Table 2).ConclusionsIn this paper, a multifunctional dynamically adjustable stretchable chiral metasurface is proposed. The effect of unidirectional mechanically stretched PDMS substrates on the large-scale dynamic adjustment of multifunctional chiral metasurface functions is studied by numerical simulations by finite difference time domain (FDTD) method. When entering the ray polarization wave, the PDMS substrate is stretched to make the maximum values of AT factor and PCR up to 0.77 and 1.00, and the adjustment range can reach 0.45 and 0.82, and when the incident circular polarization wave is informed, the maximum values of CD parameters and AR factor can reach 0.81 and 0.77, and the adjustment range can reach 0.81 and 0.65. The cause of the asymmetry is verified by electric field distribution analysis. The device not only has excellent multifunctional characteristics, but also has the ability to dynamically adjust a wide range, and has a good application prospect in related fields such as next-generation stretchable multifunction electromagnetic sensors and optical displays.
Jun. 24, 2025Vol. 45 Issue 11 1124001 (2025)
Xuening Kou, and Youliang Cheng
ObjectiveWith the depletion of fossil energy resources and their associated environmental challenges, vigorous development of the solar energy industry holds significant importance in alleviating the strain on fossil fuel utilization, achieving the “dual carbon” goals, and constructing novel power systems. Solar cells, which harness the photovoltaic effect to directly convert solar energy into electricity, represent a critical technology in this endeavor. Among these, solid-state dye-sensitized solar cells (ss-DSSCs) stand out as an attractive third-generation photovoltaic technology. They overcome the risks of volatility and leakage inherent in traditional liquid electrolytes, offering enhanced stability, lower production costs, simplified encapsulation processes, superior temperature adaptability, minimal visible light absorption, and compatibility with 3D printing technologies. The selection of dye layer materials profoundly influences device performance. This study focuses on organic dyes as the research subject, which exhibit distinct advantages over conventional metal-based dyes, including simplified synthesis processes, reduced costs, and environmental friendliness. By establishing a computational model for organic dyes to investigate performance variations and optimize device architectures, this work aims to provide theoretical insights and methodological guidance for experimental research in advancing high-efficiency, eco-friendly ss-DSSCs.MethodsBased on the SCAPS-1D software platform, an initial computational model, namely FTO/TiO2/S5/Spiro-OMeTAD/Ag, was established and validated through fitting with experimental data to ensure accuracy. Subsequently, systematic investigations were conducted to evaluate the effects of multiple parameters on the four key performance parameters (i.e., open-circuit voltage Voc, short-circuit current density Jsc, fill factor FF, and photoelectric conversion efficiency PCE) and current density-voltage (J-V) characteristics. Multiple parameters include the thickness and defect density of the dye layer, doping type and concentration in the charging transport layers, back-contact work function, and operating temperature. Through comprehensive parametric optimization, the optimal values and device architecture were determined. By analyzing the performance variation trends under different parameters, the underlying mechanisms were elucidated through the following aspects: band alignment relationships, carrier recombination and transport dynamics, bulk and interfacial defects, and heterojunction contact types. This comprehensive analysis provides insights into the fundamental factors affecting device performance, offering a mechanistic framework for optimizing the design and operation of solid-state dye-sensitized solar cells.Results and DiscussionsThe dye S5 selected in this study exhibits a large absorption coefficient. As the thickness of the dye layer increases, the Jsc shows an upward trend, and the PCE reaches its maximum value at a thickness of 1 μm (Fig. 7). However, due to the increased probability of recombination, higher defect density, and elevated internal resistance, the FF and the Voc are lower compared to their initial values. The acceptor doping density in the hole transports layer (HTL) has a more significant impact on device performance than the donor doping density in electron transports layer (ETL), primarily due to the energy level alignment between the layers. Increasing the HTL doping concentration significantly improves Voc, with optimal performance achieved at a doping concentration of 1×1017 cm-3 (Fig. 8). Conversely, excessive doping in the ETL introduces new defect states, leading to a decline in device performance. The optimal ETL doping concentration is 1×1018 cm-3 (Fig. 9). The increase in defect density adversely affects all performance metrics. Considering the limitations of fabrication processes, the optimal defect density is determined to be 1×1013 cm-3 (Fig. 10). For the back-contact metal, identifying a cost-effective alternative to precious metals is crucial for reducing device costs. Studies reveal that as the work function of the metal approaches 5 eV, the device performance initially improves and then gradually saturates (Fig. 11). Therefore, nickel (Ni) with a work function of 5.15 eV can be considered as promising candidate material. Temperature rise enhances Jsc but negatively impacts PCE and Voc (Fig. 13). Additionally, elevated temperatures accelerate device aging and shorten operational lifetime.ConclusionsIn this simulation study, we employed a novel organic dye, S5, as the research subject and established an FTO/TiO?/S5/Spiro-OMeTAD/Ag model (Fig. 4) using the SCAPS-1D software, which was subsequently validated by fitting with experimental data. We systematically investigated the effects of defect density and thickness of the dye layer, doping concentrations of HTL and ETL, and the work function of the back-contact metal on the four key performance parameters of the device. The underlying mechanisms were analyzed, and the optimal parameter values for maximizing device performance were identified, realizing the optimization of the initial model into an optimal configuration. The optimized device achieved the PCE of 15.72%, the Voc of 1.167 V, the Jsc of 17.99 mA/cm2, and the FFof 74.87%. Moreover, the absorption coefficient exhibited a significant enhancement within the wavelength range of 400?670 nm (Fig. 14). Furthermore, it is important to note that organic dyes exhibit a wide variety of types, with significant differences in key parameters such as bandgap, electron affinity, absorption coefficient, spectral absorption range, and HOMO and LUMO energy levels. However, when investigating the influence of material parameters on cell performance and optimizing device structure accordingly, the research approach and methodology adopted in this study possess universal reference value. This work highlights the immense potential of organic dyes in DSSC applications, providing a theoretical foundation and optimization framework for the further development and application of organic dyes, as well as offering valuable insights for future research on novel dye materials.
Jun. 23, 2025Vol. 45 Issue 11 1125001 (2025)
Tianjun Liao, Dongbing Han, and Zhimin Yang
ObjectiveThe photonic radiation device (PRD) has attracted considerable attention for its potential applications in energy conversion and optoelectronics. Previous research has established an innovative equivalent circuit model for the PRD, elucidating the impacts of the carrier radiative recombination current ratio, series internal resistance, and parallel resistance on its volt-ampere characteristics and power density. However, the understanding of cooperatively regulating the PRD’s thermal, optical, and electrical properties remain limited. This study aims to develop a comprehensive theoretical framework that illuminates the interrelation of these properties and provides guidance for optimizing the PRD’s performance. The PRD represents an advanced technology with substantial potential in sustainable energy solutions and advanced optoelectronic applications. Its capacity to convert thermal energy into electrical energy through photonic radiation establishes it as a promising candidate for renewable energy systems. While the equivalent circuit model offers while providing valuable insights into the PRD’s electrical behavior, its correlation with thermal and optical properties requires further investigation. This study addresses to bridge this knowledge gap by examining the synergistic effects of these properties on the PRD’s overall performance. Through understanding these property interactions, this study aims to establish guidelines for enhancing the PRD’s efficiency and stability, facilitating its implementation in practical applications.MethodsWe begin by establishing the relationship between the carrier’s non-radiative recombination rate and key parameters. This involves a detailed analysis of how non-radiative recombination processes compete with radiative ones, affecting the PRD’s output characteristics. By integrating the equivalent circuit model with Planck’s thermal radiation theory and carrier recombination theory, we systematically explore how doping concentration, output voltage, heat source temperature, and defect energy level influence the PRD’s energy conversion performance. This multi-disciplinary approach allows us to model the PRD’s behavior across different operational conditions and parameter variations. Numerical simulations are employed to model the PRD’s performance under varying doping concentrations and output voltages. These simulations take into account the complex interplay of thermal, optical, and electrical factors, providing a comprehensive view of the PRD’s behavior. Optimization techniques are then applied to identify the optimal operating conditions that maximize both power density and conversion efficiency. The study also examines the impact of defect energy levels on carrier recombination processes, revealing how these levels can be engineered to enhance the PRD’s performance.Results and DiscussionsThe findings reveal that optimizing the output voltage and doping concentration can substantially enhance the PRD’s performance. At 800 K, the PRD achieves a maximum power density of 450 W·m-2 and a conversion efficiency of 9.79%. This represents a significant improvement over previous designs and demonstrates the effectiveness of our theoretical framework. A trade-off analysis delineates the optimal regions for doping concentration and voltage, providing practical guidelines for PRD design. Importantly, defect energy levels near the valence band top prove most effective for high-efficiency energy conversion. This is attributed to the reduced non-radiative recombination rates at these energy levels, which enhance the PRD’s thermal-to convert thermal-electrical energy intoconversion electricalcapability. The study also highlights that while power density increases with operating temperature, there is an optimal temperature for maximizing conversion efficiency. This optimal temperature balances the competing effects of increased thermal energy input and the associated rise in non-radiative recombination processes. The study addresses practical considerations regarding semiconductor stability at highelevated temperatures are also discussed. The research underscores the importance of selecting an appropriate heat source temperature, as excessively high temperatures may compromise semiconductor stability and longevity, thereby limiting the PRD’s operational lifetime.ConclusionsThis research advances the theoretical understanding of the PRD’s energy conversion mechanisms by examining the cooperative effects of its thermal, optical, and electrical properties. The integration of multiple theoretical models provides a robust foundation for optimizing PRD performance. The insights gained offer critical guidance for the design and development of PRDs, supporting their application in energy harvesting and optoelectronic technologies. Future research could further explore material innovations and nanostructured designs to enhance PRD capabilities, such as using novel semiconductor materials with tailored band structures or incorporating nanostructuring techniques to improve carrier transport and reduce recombination losses. Additionally, experimental validation of the theoretical findings would strengthen the practical relevance of this research, paving the way for real-world applications of PRD technology. By addressing both theoretical and practical aspects, this study contributes to the broader goal of developing efficient and sustainable energy conversion technologies for the future.
Jun. 23, 2025Vol. 45 Issue 11 1125002 (2025)
Senhao Zhao, Chenwei Tu, Zhengchen Lu, Yangbin Ma, Xinguang Wang, and Le Wang
ObjectiveAbruptly autofocusing beams exhibit a sudden and significant increase in intensity at the focal point, with enhancements reaching several orders of magnitude. This effect is achieved without relying on conventional lenses or nonlinear effects, while the beam maintains a low-intensity profile prior to focus. This unique property has demonstrated significant potential for diverse applications ranging from optical manipulation to optical trapping and biomedical therapy. In recent years, regulating and optimizing the autofocusing characteristics of beams through light field design has attracted extensive attention. While traditional Airy beams have been extensively studied for their exceptional self-accelerating, self-bending, and self-healing properties, butterfly beams have emerged as a novel research focus due to their controllable parametric properties and stable higher-order focal dispersion structures. The propagation dynamics of the new beam combining these two autofocusing beams with additional vortex-phase modulation are highly anticipated. In this paper, we propose a novel circular butterfly Airy vortex beam (CBAVB) and systematically investigate its autofocusing properties in free-space propagation. The results are expected to provide a reference for the application of CBAVB in optical communication, optical trapping, and biomedical therapy.MethodsInitially, we utilize the split-step Fourier algorithm to numerically simulate the propagation of CBAVB in free space. Subsequently, the influence of different parameters on the autofocusing characteristics of the beam is investigated. Furthermore, the energy flow of the beam and the influence of optical vortices are analyzed using the Poynting vector and angular momentum density vector, respectively. Finally, we analyze the autofocusing performance of CBAVB through a comparative study.Results and DiscussionsThrough numerical simulations of the beam propagation dynamics, the superior autofocusing characteristics of CBAVB are demonstrated. The incorporation of optical vortices can significantly improve the focusing performance coefficient of CBAVB (Fig. 2). By adjusting the position of the optical vortex and the size of the topological charge, the autofocusing behavior can be flexibly controlled while maintaining the position of maximum intensity (Fig. 3). Simultaneously altering the transverse scale factor and spatial offset factor can enhance the beam’s focusing performance coefficient while effectively regulating the focus position (Fig. 4). The autofocusing mechanism of CBAVB (Fig. 5) and the influence of optical vortices on the beam (Fig. 6) are analyzed based on the beam’s Poynting vector and angular momentum density vector. In addition, compared with CAVB and CBVB, CBAVB demonstrates superior autofocusing performance (Fig. 7).ConclusionsIn this paper, we propose a novel autofocusing circular butterfly Airy vortex beam (CBAVB), whose propagation in free space is numerically simulated using the split-step Fourier algorithm. The effects of topological charge, optical vortex position, transverse scale factor, and spatial offset factor on the autofocusing characteristics of the beam are investigated. Furthermore, the propagation dynamics of CBAVB are further analyzed through the Poynting vector and angular momentum density vector. The research results show that the incorporation of optical vortices significantly promotes the maximum focusing performance coefficient of CBAVB. By adjusting the position of the optical vortex and the size of its topological charge, the transverse intensity distribution of CBAVB can be flexibly regulated, and the beam’s focusing performance coefficient can be improved. Altering the transverse scale factor and spatial offset factor can also regulate the focusing position and effectively enhance the beam’s autofocusing performance. Compared with the CAVB and CBVB, CBAVB demonstrates superior autofocusing performance. These results suggest the promising potential of CBAVB for applications in free-space optical communications, biomedical imaging, optical manipulation, and related fields.
Jun. 24, 2025Vol. 45 Issue 11 1126001 (2025)
Ting Guo, Xin Lü, Gang Wang, Shaoding Liu, Yanxia Cui, Rong Wen, and Guohui Li
ObjectiveAll-inorganic CsPbX? perovskite quantum dots (QDs) are ideal materials for high-quality single-photon sources in quantum information applications, as the performance of single-photon sources is closely related to the size of perovskite QDs. However, the lack of effective methods to reduce the size of CsPbX3 QDs remains one of the major obstacles to achieving single-photon emission. In this study, we employ an efficient and low-cost doping synthesis strategy, directly introducing ammonium bromide (NH4Br) into the lead precursor via the hot-injection method, successfully preparing CsPbBr3 perovskite QDs. By utilizing NH4Br to regulate crystal growth kinetics and passivate surface defects, we effectively suppress the Ostwald ripening process, significantly reducing the average size from the original 10.07 nm to 6.87 nm while improving size uniformity. The size reduction enhances the quantum confinement effect, leading to a blue shift in the photoluminescence (PL) emission peak from 520 nm (undoped) to 505 nm. Additionally, autocorrelation tests reveal that the g2(0) value of the doped QDs decreases from 0.45 to 0.22, which indicates a significant improvement in single-photon purity. We present an innovative and straightforward synthesis strategy, successfully producing CsPbBr3 perovskite QDs with a narrow size distribution. The incorporation of NH?Br enhances the single-photon purity of the QDs, which provides an ideal material system for single-photon emission applications and lays an important foundation for their commercialization.MethodsIn our study, CsPbBr? QDs, and NH?Br-doped CsPbBr? QDs are synthesized using the hot-injection method to achieve size reduction and improved size uniformity. The synthesis process consists of two main steps. Firstly, the cesium precursor is prepared by heating a mixture of cesium carbonate, oleic acid, and 1-octadecene in an inert atmosphere at 120 ℃ for 2 h, followed by increasing the temperature to 160 ℃. The resulting solution is then cooled to room temperature and stored under sealed conditions. Secondly, the synthesis of CsPbBr? QDs and NH?Br-doped CsPbBr? QDs is carried out by heating a mixture of lead bromide, ammonium bromide, oleic acid, oleylamine, and 1-octadecene in an inert atmosphere for 2 h, with the temperature raised to 150 ℃. Subsequently, 0.4 mL of cesium oleate precursor is rapidly injected. After 5 s of reaction, the mixture is immediately cooled using an ice-water bath. Well-dispersed QD solutions are obtained by high-speed centrifugation. Throughout the synthesis process, QDs with different doping concentrations are prepared by controlling the amount of ammonium bromide added.Results and DiscussionsThe prepared NH4Br-CsPbBr3 QDs, with the Br/Pb molar ratio less than 7, exhibit a distinct decreasing trend in particle size as the Br/Pb molar ratio increases. The average particle size of CsPbBr? QDs significantly decreases from 10.07 to 6.87 nm, which results in a blue shift of the PL emission peak from 520 nm (undoped) to 505 nm (Br/Pb molar ratio is 7). Statistical analysis of the same number of grains further shows that the particle size distribution narrows from 4?19 nm to 5.5?9 nm, which confirms that ammonium bromide doping effectively improves the morphological uniformity of the QDs. However, when the Br/Pb molar ratio exceeds 7, excess ammonium bromide disrupts the controllability of the QD morphology, which leads to distortion of the cubic structure. Therefore, the effective doping range of ammonium bromide is limited to a Br/Pb molar ratio of less than or equal to 7. Furthermore, the doping of ammonium bromide strengthens the covalent bonding of Pb-Br, which enhances the stability of the QD crystal structure and increases the quantum yield of the QDs from 31.22% to 61.65%, while the fluorescence lifetime extends from 1.15 ns to 2.80 ns. The reduction in QD size induced by NH?Br doping enhances the quantum confinement effect. This enhanced quantum confinement leads to a more discrete energy level structure in the QDs, which significantly reduces the probability of multiphoton emission, thereby improving the purity of single-photon emission. After doping, the second-order autocorrelation function g2(0) of the QDs decreases from the original value of 0.45 to 0.22, which indicates that ammonium bromide doping effectively improves the single-photon emission purity of the QDs.ConclusionsOur study systematically reveals the effect of NH?Br doping on the size control of CsPbBr? perovskite QDs, its intrinsic mechanisms, and the effect on single-photon properties. Experimental results show that within the doping concentration range where the Br/Pb molar ratio is less than or equal to 7, the QD size decreases in a regular pattern as the doping concentration increases, with the average particle size significantly reducing from 10.07 nm (undoped) to 6.87 nm (at a Br/Pb molar ratio of 7). More importantly, the uniformity of the doped QDs’ size is improved, with the particle size distribution narrowing from 4?19 nm to 5.5?9 nm. This improvement primarily stems from the bromine-rich environment provided by ammonium bromide, which not only effectively fills the bromine vacancies on the QD surface [as confirmed by X-ray photoelectron spectroscopy (XPS) quantitative analysis, showing an increase in the Br/Pb molar ratio from 3.85 to 4.21] but also narrows the size distribution by suppressing Ostwald ripening and through the synergistic coordination of NH4+ ions with the [PbBr6]4- octahedral structure. We find that after doping, the g2(0) value of the QDs decreases from 0.45 to 0.22, which indicates that NH4Br doping helps improve the single-photon purity of the QDs. The innovative findings of this study open new avenues for the application of perovskite crystal QDs in single-photon sources, which is of great significance for advancing the development of single-photon technology in cutting-edge fields, such as quantum communication, quantum computing, and quantum information processing.
Jun. 24, 2025Vol. 45 Issue 11 1127001 (2025)
Xinghua Tu, and Jie Ou
ObjectiveSecond-harmonic signal processing is critical for tunable diode laser absorption spectroscopy (TDLAS), where accurate signal extraction and noise suppression directly affect gas concentration inversion accuracy. Traditional filtering methods, such as empirical mode decomposition and Savitzky-Golay filtering, often struggle to balance noise suppression and feature preservation, especially under low signal-to-noise ratio (SNR) conditions. To address these challenges, we propose a multi-level feature fusion dual-channel convolutional neural network (PCA-GASF-DCResNet) for second-harmonic signal denoising. The method integrates feature dimensionality reduction, time-series feature encoding, and deep learning-based noise suppression to improve signal representation and denoising robustness.MethodsThe proposed method integrates Principal Component Analysis (PCA) and Gramian Angular Summation Field (GASF) transformation to enhance feature representation, where PCA removes redundant information and reduces data dimensionality while GASF encodes one-dimensional second-harmonic signals into two-dimensional matrices to enhance temporal dependencies for deep learning models. To extract both global and local features, a dual-channel convolutional neural network (CNN) is designed, where one channel processes PCA-reduced one-dimensional signals with large convolution kernels to capture global features, while the other channel applies small convolution kernels to the GASF-transformed two-dimensional signals for fine-grained local feature extraction. Residual learning (ResNet) is incorporated to optimize deep network performance by mitigating gradient vanishing issues, accelerating convergence, and maintaining model stability. The proposed PCA-GASF-DCResNet is systematically evaluated under various SNR conditions using simulated noisy second-harmonic signals, and its performance is compared with conventional denoising methods, including EEMD-WT, VMD-WTFD, VMD-SG, and CNN, to validate its effectiveness in low-SNR environments. Ablation studies are conducted to assess the contributions of each channel and feature fusion. Furthermore, to validate the robustness of the proposed method, it is tested on signals with varying gas concentrations. The proposed method is further applied to experimentally measured TDLAS signals to demonstrate its practical utility in improving gas concentration inversion accuracy.Results and DiscussionsThe proposed PCA-GASF-DCResNet model is systematically evaluated in both simulations and experiments. Compared to traditional denoising approaches, PCA-GASF-DCResNet achieves a substantial SNR improvement, significantly enhancing second-harmonic signal recovery (Table 1). The impact of each channel is assessed by introducing PCA-ResNet and GASF-ResNet as single-channel models. The results show that single-channel processing achieves only moderate SNR improvements, while the dual-channel fusion in PCA-GASF-DCResNet leads to superior noise suppression and feature retention, validating the necessity of multi-level feature fusion. The robustness verification indicates that the denoised second-harmonic signal maintains a high level of consistency across different concentration levels. The linear correlations of the peak and peak-trough values with gas volatilization time reach 0.99989 and 0.99987, respectively (Fig. 8). Furthermore, experimental results based on the absorption line of CO2 at the center wavelength ν0=1578.2 nm confirm that the proposed method effectively suppresses noise and baseline fluctuations and the full width remains stable over time. Additionally, the peak fitting correlation reaches 0.99138, further demonstrating the accuracy and reliability of the algorithm for gas concentration inversion (Fig. 10).ConclusionsIn this paper, we propose PCA-GASF-DCResNet, a dual-channel convolutional neural network for second-harmonic signal denoising in TDLAS. The method integrates PCA for dimensionality reduction and GASF transformation to enhance feature extraction and improve denoising performance. Using the 1578.22 nm CO2 absorption line, noisy second-harmonic signals were simulated and validated through simulations and experiments. The results demonstrate that PCA-GASF-DCResNet significantly improves SNR and produces denoised signals closest to the ideal second-harmonic waveform. Ablation studies confirm that dual-channel fusion outperforms single-channel processing, further enhancing SNR. Additionally, experimental results show that the denoised signal’s peak values exhibit a strong linear correlation with gas volatilization time, while baseline fluctuations are significantly reduced, maintaining stability even under low SNR conditions. These findings highlight the superior denoising performance and practical applicability of the proposed method.
Jun. 23, 2025Vol. 45 Issue 11 1128001 (2025)
Baiyu Yang, Jingli Wang, Yuxin Yang, Yu Guo, Jun Wang, Cuilian Xu, Jing Liu, and Qi Fan
ObjectiveAccurately determining the optical constants (refractive index n and extinction coefficient k) of transparent solid materials is a crucial issue in optical design. The dual thickness transmittance method offers a straightforward approach that does not require the Kramers-Kronig relationship. For weakly absorbing materials, high-precision measurement results can be obtained by changing the thickness. The double thickness transmittance method establishes nonlinear equations about optical constants by measuring the transmittance of materials with two different thicknesses. Due to the complexity of the equations, it is difficult to obtain analytical solutions, and inversion methods are often used to solve optical constants. These inversion methods present challenges including computational time requirements, iterative errors, and multiple potential values for refractive index results. While researchers have attempted to address these issues through faster iterative algorithms or combinations with methods such as ellipsometry, the outcomes remain suboptimal.MethodsRecent research has employed transmittance spectra of stacked samples combined with inversion methods to determine material optical constants, though the inherent limitations of inversion methods persist. An alternative approach utilizing dual spectral analysis for determining optical constants based on transmittance and reflectance spectra of single-layer samples has been proposed. However, this method faces challenges due to inconsistent experimental conditions between transmittance and reflectance measurements. The present study integrates the advantages of both stacked sample transmittance spectrum inversion and single-layer sample dual spectrum analysis methods. The approach involves measuring transmittance of various stacked sample combinations and deriving single-layer sample reflectance through algebraic operations. This enables optical constant determination without direct reflectance measurement while avoiding inversion method limitations. This analytical method based on stacked sample transmittance spectra significantly streamlines experimental measurement and calculation processes. For demonstration, transmittance measurements of Zinc Selenide samples under various stacking combinations were conducted using a Fourier transform infrared spectrometer in the 2?18 μm infrared band. The optical constants were determined using this novel method, followed by error analysis of extinction coefficient and refractive index measurements. Finally, the factors affecting the accuracy of optical constant measurement were studied by combining experiments and numerical simulations.Results and DiscussionsThe optical constants of Zinc Selenide were measured using an application example. The relative uncertainty of the extinction coefficient k was less than 10% in the ranges of 3.5?5.5, 7.0?8.5, and 14?18 μm, and less than 5% in the range of 15.0?17.5 μm (Figs. 4 and 5). The relative uncertainty of refractive index n is less than 0.5% in the range of 3?15 μm, and less than 0.25% in the range of 7?12 μm (Figs. 6 and 7). Comparatively speaking, the measurement accuracy of refractive index is higher, and the extinction coefficient and its errors have almost no effect on the refractive index and its measurement accuracy. The main source of error for both is the measurement error of sample transmittance. The influence of sample thickness on the transmittance of stacked samples was studied through numerical simulation, and it was pointed out that sample thickness is crucial for reducing measurement errors in transmittance (Figs. 10 and 11). The new method proposes requirements for the transmittance t and thickness L of single-layer samples: under the condition of a spectrometer transmittance accuracy of 0.001, the transmittance t of single-layer sample should be greater than 0.004 and less than 0.953; adjusting the sample thickness L to ensure that the transmittance of the stacked sample falls as close as possible to the middle position between t2 and t/(2-t), will help improve the measurement accuracy of transmittance and achieve accurate determination of optical constants.ConclusionsThis study combines the advantages of the stacked sample transmittance spectrum inversion method and the single-layer sample dual spectrum analysis method, and proposes an analytical model based on the stacked sample transmittance spectrum. It realizes the use of the single-layer sample dual spectrum analysis method to determine optical constants without measuring reflectance, while avoiding the disadvantages of inversion methods and greatly simplifying the experimental measurement and solution calculation process. The application example uses transmittance of Zinc Selenide stacked samples to demonstrate the specific use of the new method, and the results show that the method is feasible. Numerical simulation was conducted to study the influence of sample thickness on the transmittance of stacked samples. Adjusting the sample thickness reasonably to make the transmittance curve of stacked samples as close as possible to the middle position of its allowable range will help improve the measurement accuracy of transmittance and achieve accurate determination of optical constants. Our research results provide an alternative solution for the precise determination of the optical constants of transparent solids.
Jun. 20, 2025Vol. 45 Issue 11 1130001 (2025)
Libo Wang, Jingjing Xia, Siwen Lu, Xinshang Niu, Xiaochuan Ji, Hongfei Jiao, Jinlong Zhang, Zhanshan Wang, and Zihua Xin
ObjectiveBased on the evolution of traditional atomic layer deposition (ALD) technology, plasma-enhanced atomic layer deposition (PEALD) has achieved technological breakthroughs in two key dimensions by introducing radio frequency plasma sources. First, radical reactions activated by plasma extend the process temperature window from the conventional ALD range of 200?400 ℃ to 30?300 ℃, which significantly enhances compatibility with thermally sensitive substrates. Second, plasma-induced surface activation increases the growth rate to 0.05?1 ?/cycle while maintaining atomic-level thickness uniformity. These dual advantages of low-temperature processing and accelerated growth make PEALD particularly advantageous in advanced manufacturing fields, including flexible electronics, photovoltaic passivation layers, and three-dimensional packaging. Contemporary ALD research primarily focuses on three-dimensional structure-property relationships: 1) the correlation between precursor chemical systems (metalorganic compounds/halides) and intrinsic film properties; 2) the regulatory mechanisms of process parameters (temperature, pulse sequence, purge efficiency) on interfacial reactions; 3) the coupling mechanisms between microstructural characteristics (crystalline phase composition, defect density, stress state) and functional properties (dielectric constant, transmittance). Notably, despite PEALD’s breakthrough in deposition kinetics, significant knowledge gaps remain regarding the dynamic evolution of amorphous/crystalline structures during ultra-thick film deposition (>1000 nm) and their impact on optical properties. Specifically, nonlinear relationships exist between the evolution of optical constants and the cross-scale surface morphology transitions (layer-by-layer growth, island formation, surface roughening) from initial ultrathin films (10 nm) through submicron (300 nm) to ultra-thick (>1000 nm) film systems. Investigating the co-evolution of optical properties and surface microstructure in the 10?1250 nm thickness regime is crucial for advancing PEALD applications in high-precision optical coatings and graded-index devices.MethodsWe fabricate Si(100) substrates with two distinct surface morphologies through chemical mechanical polishing, where the substrate exhibiting fractal characteristics in surface topography is designated as S-1, while that lacking fractal features is labeled as S-2. Ultrathin (~10 nm) to ultra-thick (~1250 nm) Al2O3 films are deposited via PEALD using trimethylaluminum (TMA) and oxygen plasma. The process parameters are maintained at constant values: plasma power (200 W), oxygen flow rate (150 cm3/min), and reaction temperature (100 ℃). The deposition cycle consists of sequential steps: TMA pulse (150 ms), purge (10 s), oxygen plasma pulse (6 s), and purge (10 s), with 70, 176, 352, 705, 2130, 3650, and 9250 cycles. Film thickness and refractive index are determined through spectroscopic ellipsometry analysis (240?1240 nm spectral range) using a multi-layer fitting model comprising: effective medium approximation (EMA) layer, Al2O3 layer, SiOx interface layer, and Si substrate. Surface microtopography characterization is performed via atomic force microscopy (AFM) in tapping mode with operational parameters: scanning rate (1 Hz), scanning lines (256), and multiple scanning areas (1 μm×1 μm, 5 μm×5 μm, 10 μm×10 μm, 50 μm×50 μm). Crystallographic analysis is conducted using X-ray diffraction (XRD) in the 2θ range of 35°?90° with 0.02° step increments, employing Jade software for peak deconvolution and removal of silicon substrate diffraction artifacts. For samples with 70, 176, 352, and 705 deposition cycles, additional X-ray reflectivity (XRR) measurements are performed using a BrukerTM D8 Discover system (incidence angle range: 0°?4°, step size: 0.004°), with subsequent GenX3 software modeling to extract film thickness and density parameters.Results and DiscussionsFigure 2 illustrates the evolution of deposition rate, refractive index, and density of Al2O3 thin films as functions of deposition cycles in the PEALD process. It is observed that both the density and refractive index of the films exhibit continuous enhancement with increasing thickness, stabilizing beyond a thickness of 500 nm. Notably, no significant crystallization is detected even when the film thickness reaches 1250 nm. The effective filling of substrate polishing marks by PEALD-deposited Al2O3 films is demonstrated in Fig. 4. However, starting from 705 deposition cycles, distinct characteristic microstructures emerge on the film surface. Their dimensional growth with increasing film thickness significantly elevates surface roughness and modifies the evolution of power spectral density (PSD), as shown by the scanning results in Fig. 5 and Fig. 6. These findings collectively indicate the unsuitability of PEALD for fabricating thick Al2O3 films. The growth kinetics of the films conform to the ABC-type evolutionary model, with corresponding fitting parameters systematically presented in Table 1 and Table 2. The comparative analysis of Figs. 8 and 9 reveals that the initial growth stages of PEALD-deposited Al2O3 films are critically influenced by substrate surface topography, where substrates with higher initial roughness induce premature transitions in growth modes. Figure 10 further demonstrates that the substrate’s morphological influence persists beyond the nucleation phase, which continues to govern the PSD evolution of submicron-scale films. Remarkably, even when the film thickness attains micrometer dimensions, the PSD characteristics remain partially constrained by the underlying substrate morphology.ConclusionsWe employ PEALD to deposit Al2O3 thin films (10?1250 nm) on two Si substrates with distinct surface topographies. Systematic investigations are conducted on the evolution of film growth rate, refractive index, and density as functions of deposition cycles. Key observations are as follows. 1) The growth rate demonstrates a gradual decrease followed by convergence with increasing deposition cycles, while both density and refractive index exhibit progressive enhancement before stabilization. 2) Characteristic microstructures emerge on film surfaces, with dimensional expansion proportional to film thickness. 3) Spectral analysis of PSD demonstrates effective retention of low-frequency substrate characteristics, while progressive masking occurs in medium-to-high frequency ranges. Notably, the medium-to-high frequency PSD components of films display an ascending trend with deposition cycles, which indicates gradual decoupling from substrate influences. The evolution of surface roughness exhibits substrate-dependent behavior: S-1 substrates with lower initial roughness demonstrate increasing roughness values due to microstructure development, whereas S-2 substrates with higher initial roughness show surface smoothing effects. Post-deposition analysis reveals that although medium-to-high frequency PSD components follow systematic evolutionary patterns across different substrates, complete elimination of substrate-induced PSD variations remains unattainable. The residual PSD discrepancies in deposited films are fundamentally attributed to the persistent influence of underlying substrate topography characteristics.
Jun. 23, 2025Vol. 45 Issue 11 1131001 (2025)
Guopeng Zhou, Zhijie Tan, and Hong Yu
ObjectiveIn X-ray optical systems, conventional camera-based direct imaging cannot achieve positioning accuracy below the size of a single pixel. Therefore, developing enhanced spot localization methods for X-rays is crucial for obtaining higher accuracy position information. This paper presents a novel X-ray spot localization method utilizing a dual-grating approach through diffraction grating positioning calibration. The method detects the diffraction pattern of the beam passing through the dual gratings on the detector simultaneously, integrates and compares scattered photons in different regions through regional division, enabling convenient and rapid determination of the X-ray spot position on a two-dimensional plane. This approach facilitates single calibration spot positioning in X-ray optical systems.MethodsThe schematic of the dual-grating positioning system is presented in Fig. 1(a). X-rays emitted from a miniature X-ray source irradiate the dual-grating structure, where gratings G1 and G2 partially overlap to modulate the X-ray beam and induce diffraction. As illustrated in Fig. 1(c), the X-ray spot incident on the dual gratings is divided into three distinct regions including areas where the spot passes through either the transverse or longitudinal gratings alone, as well as the overlapping region where it traverses both gratings simultaneously. The diffracted X-rays from the dual-grating structure are detected by a single-photon-sensitive detector, with the resultant diffraction pattern displayed in Fig. 1(b). By correlating the segmented regions of the X-ray spot in Fig. 1(c) with the corresponding zones in the diffraction pattern shown in Fig. 1(b), the light intensities of these specific regions are extracted. The movement of the spot signifies a change in the area, which covers through different structural parts of the dual gratings, leading to variations in the integrated intensity of different regions. Consequently, the position of the X-ray spot’s center is calculated by integrating the diffraction intensities across the defined regions on the detector.Results and DiscussionsSimulations indicate that positioning errors follow a normal distribution. Results demonstrate that with photon counts exceeding 105, the positioning accuracy reaches below 2 μm, while photon counts above 106 achieve sub-micrometer precision. Additionally, multi-point sampling (e.g., two sampling points) further enhances accuracy to approximately 1 μm. The study also reveals that higher grating throughput in specific quadrants improves measurement accuracy. When the number of sampling points exceeds four positions, the 3σ accuracy tends to be saturated, which can reach up to 0.5 μm.ConclusionsThis paper presents a novel X-ray spot positioning method based on dual-grating technology. The theoretical framework demonstrates how positioning is achieved by correlating regional light intensities with the spot’s center position, with simulation results validating the method’s feasibility. The calculations indicate that the proposed scheme enables simultaneous acquisition of positional coordinates in two directions from a single exposure. Under conditions of 10? scattered photons, the method achieves micron-level positioning accuracy. Simulations demonstrate that increased photon counts enhance positioning accuracy in single exposures. The research examines positioning accuracy relative to spot location and grating structure, revealing that greater spot-grating structure overlap yields higher positioning accuracy. Furthermore, enhanced positioning accuracy is achievable through multiple samplings of diffraction data at different positions. This positioning method presents significant potential for applications in X-ray optical systems requiring precise spot positioning.
Jun. 24, 2025Vol. 45 Issue 11 1134001 (2025)
Xinxin Lin, Zhiting Chen, Chuandong Tan, and Liming Duan
ObjectiveComputed tomography (CT) technology encounters significant limitations in performing high-precision non-destructive testing (NDT) of plate-like objects with high aspect ratios due to system structural constraints and X-ray energy limitations. Rotational computed laminography (RCL) technology enables high-resolution three-dimensional (3D) imaging of plate-like objects through adjustment of the angle between the rotation axis and X-ray beam centerline (less than 90°). However, incomplete projection data leads to aliasing artifacts and loss of edge details in reconstructed images, particularly when examining plate-like structures. These limitations compromise image quality and impair the detailed representation of target features. Conventional iterative reconstruction algorithms utilizing single a priori information, fixed a priori informations, or complex registration processes demonstrate limitations including inadequate artifact suppression, excessive edge smoothing, and high noise sensitivity. To address these challenges, this paper introduces an iterative reconstruction algorithm based on dynamically updated hybrid a priori constraints (DUHP), incorporating a dynamically updated structural self-prior (DUSSP) and a truncated adaptively weighted total variation (TAwTV) regularization term based on gradient sparsity a priori information. The proposed methodology effectively suppresses aliasing artifacts while enhancing edge detail preservation, resulting in superior image reconstruction quality.MethodsThe proposed DUHP algorithm achieves high-quality 3D reconstruction of plate-like objects by implementing a DUSSP regularization term and combining it with the TAwTV based on gradient sparsity a priori information. Initially, the algorithm extracts and updates the mask image of the target region from previous reconstruction results at a fixed frequency to establish a dynamically updated structural self-prior. This approach enhances global structural information preservation, increases the adaptability of the structural a priori information during reconstruction, and prevents error accumulation associated with fixed a priori informations. Subsequently, the TAwTV constraint adaptively optimizes local gradients, reducing the excessive smoothing effect typical of conventional TV constraints while improving edge detail reconstruction quality. The complementary interaction between these regularization terms enables DUHP to enhance aliasing artifact suppression while improving both local and global structural feature restoration in reconstructed images, ultimately enhancing visual quality and quantitative evaluation metrics. To validate the algorithm’s effectiveness, two representative circuit board models are designed for simulation experiments to assess DUHP algorithm robustness under varying structural complexities and noise conditions. The experiments examine two circuit board models: one featuring through-holes and fracture defects (model 1) and another with a more complex circuit structure (model 2). The adaptability of DUHP under different noise levels is evaluated and compared qualitatively and quantitatively against SART-TV, SART-TAwTV, and SPI-TV. Additionally, real data from RCL-scanned decoder module circuit boards are utilized in practical reconstruction experiments to evaluate the DUHP algorithm’s feasibility in real-world engineering applications.Results and DiscussionsThe experimental results demonstrate that the DUHP algorithm effectively reduces aliasing artifacts and significantly improves edge detail restoration in cases of incomplete projection data. In the model 1 experiment, the DUHP algorithm produced reconstructed images with sharper edge features compared to SIRT, SART-TV, SART-TAwTV, and SPI-TV, effectively restoring internal defect structure and location (Fig. 5). In the model 2 experiment, the DUHP algorithm successfully suppressed noise while accurately recovering fine structures in high-contrast regions. The algorithm improved inter-layer consistency of the reconstructed image and maintained superior depth resolution along the xoz direction [Fig. 11(b)], enhancing the resolution of the circuit board’s complex multilayer structure (Fig. 9). The RMSE convergence curves and SSP from simulation experiments with model 1 and model 2 (Figs. 8 and 11) demonstrate the DUHP algorithm’s effectiveness in suppressing aliasing artifacts while preserving edge details, improving inter-layer consistency, and maintaining higher depth resolution along the xoz direction. The quantitative evaluation metrics RMSE, PSNR, and SSIM further confirm the reconstruction advantages of the DUHP algorithm under varying noise conditions and structural complexities (Tables 2 and 3). In the real-data experiment with the decoder module circuit board, the DUHP algorithm maintained overall structural integrity while substantially reducing artifacts in soldering areas, enhancing reconstructed result visualization quality (Fig. 13). The comparison of reconstruction times (Table 5) indicates that the DUHP algorithm achieves an optimal balance between computational efficiency and reconstruction quality. Experimental results confirm DUHP’s suitability for nondestructive testing of planar objects, effectively suppressing aliasing artifacts while preserving high-frequency edge information and maintaining high reconstruction quality across various structural complexities and noise environments.ConclusionsThis paper introduces an iterative reconstruction algorithm utilizing DUHP to enhance the suppression of aliasing artifacts in RCL image reconstruction while preserving high-frequency edge information, thus improving overall image quality. The algorithm’s primary innovation lies in developing a dynamic updating mechanism of DUSSP regular term combined with the adaptive gradient truncation strategy of TAwTV regular term. This approach progressively extracts and optimizes structural a priori information through iteration without requiring complex image alignment processes, while effectively preventing the accumulation of a priori errors associated with traditional parsing algorithms that extract fixed a priori information. Additionally, the dynamic updating mechanism enables DUHP to continuously refine a priori information quality during iterations, thereby enhancing final reconstruction quality and robustness. In comparison to conventional methods including SIRT, SART-TV, SART-TAwTV, and SPI-TV, DUHP demonstrates enhanced adaptability to complex structures through its dynamic updating of structural self-prior information, resulting in superior performance in both visual quality and quantitative evaluation metrics. Future research directions may explore additional adaptive parameter optimization strategies to enhance the stability and applicability of DUHP across various imaging conditions.
Jun. 24, 2025Vol. 45 Issue 11 1134002 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20