





Please enter the answer below before you can view the full text.


2025
Volume: 40 Issue 6
13 Article(s)

Zhenda CHEN, Haitao DAI, Xiaodong ZHANG, Xichen HAO, Jiachen DENG, Yaxian CAO, Arain SAMIA, Ahmad ANEELA, Changlong LIU, Minxuan LI, and Shouzhong FENG
Au nanoclusters, as a quasi-zero-dimensional semiconductor fluorescent material with excellent luminescence and photostability, have been widely used in the field of bioimaging. The material also has a wide range of application prospects in electroluminescent devices as well as displays. This study proposes a novel ligand engineering strategy employing thermally activated delayed fluorescence (TADF) mechanisms to significantly improve the photoluminescent performance of Au nanoclusters (Au NCs). The proposed methodology focuses on the efficient harvesting of triplet excitons, which effectively inhibits non-radiative transition pathways. Ultra-small core-shell structured TPA-DCPP/TOAB/AuCs nanoclusters (CS-AuCs) with a size of (1.97±0.31) nm which exhibits thermally activated delayed fluorescence (TADF) were successfully synthesized via ligand engineering. Subsequently, the electronic energy level structure, exciton dynamics, and transition mechanisms were analyzed through the absorption and emission spectra of CS-AuCs via a combined analysis of temperature-dependent absorption/emission spectra and transient photoluminescence (TRPL) measurements. The results show that the short-wavelength fluorescence peaks (507 nm and 528 nm) of CS-AuCs exhibit TADF characteristics, i.e., their luminescence intensity is enhanced with increasing temperature. The CS-AuCs thin film demonstrated a maximum fluorescence peak intensity enhancement of 5.10-fold@80 ℃. The long-wavelength emission peak(797 nm), on the other hand, exhibits the temperature-dependent property of normal fluorescence peaks, i.e., the luminescence intensity decreases with increasing temperature. Meanwhile, the film-forming experiments demonstrated that CS-AuCs has excellent compatibility and film-forming properties while maintaining the fluorescence characteristics, which enhances the potential of Au nanoclusters for applications in display devices such as cluster light emitting diodes (CLED).
Jun. 05, 2025Vol. 40 Issue 6 809 (2025)
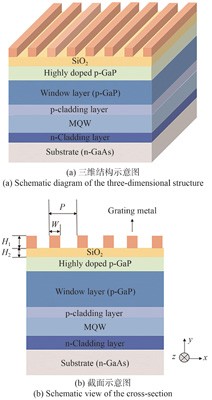
Yawei WANG, Kaifeng ZHENG, Jinguang LÜ, Guangtong GUO, Siyao MA, Yupeng CHEN, Baixuan ZHAO, Yingze ZHAO, Haitao NIE, Yuxin QIN, Bin LI, Weibiao WANG, and Jingqiu LIANG
Micro-LED display technology is regarded as the most promising next-generation display technology due to its advantages such as high brightness, high resolution, and high contrast. The development and application of technologies such as 3D display, medical detection, information encryption, visible light communication, efficient liquid crystal backlight display, polarized microscopy, and sensing have introduced new requirements for Micro-LEDs to achieve high extinction ratio polarized light output. To realize the design of a miniaturized red-light Micro-LED device capable of emitting linearly polarized light, this study integrates subwavelength metal gratings on the surface of AlGaInP-based red-light Micro-LEDs and employs the finite-difference time-domain (FDTD) method to conduct theoretical analysis and structural optimization of the metal gratings. The results demonstrate that by optimizing the grating parameters and the thickness of the dielectric layer, a red-light Micro-LED with a chip size of 50 μm achieves an extinction ratio of 26 dB, enabling high extinction ratio linearly polarized light output. The AlGaInP-based linearly polarized Micro-LED designed in this study exhibits significant potential for applications in the field of 3D Micro-LED displays.
Jun. 05, 2025Vol. 40 Issue 6 818 (2025)
Xinyu FANG, Jiahui ZHAO, Xiao YU, Qilin JIA, Jingqi TIAN, Ziye WANG, Jidan YANG, and Bingxiang LI
Traditional optical beam splitters are limited by their fixed geometric structures and static working modes, making it challenging to meet the demands of dynamically reconfigurable photonic systems. To achieve polarization-controllable laser beam splitting, this study developed a programmable optical device based on liquid crystal gradient refractive index distribution. By establishing an equivalent refractive index model for liquid crystal planar structures, triangular-patterned liquid crystal cells with alignment angles of 30°, 45°, 60°, and 90° were fabricated using digital mask lithography via a digital micromirror device (DMD) chip, systematically constructing the mapping relationship between alignment angles and effective refractive indices. Experimental results revealed that as the alignment angle increased from 30° to 90°, the corresponding effective refractive index exhibited a monotonically increasing trend. Under horizontally linear polarized light incidence, the refraction angle of extraordinary light (e-light) showed a linear growth with increasing incident angle (15°~75°), confirming the applicability of Snell's law in liquid crystal media. During continuous polarization state modulation from horizontal to vertical orientations, the intensity ratio between e-light and ordinary light (o-light) demonstrated regular evolution, reaching a 1∶1 balanced state at a 46° polarization angle. Circularly polarized light excitation generated symmetrical dual beams, revealing the regulatory mechanism of birefringence phase difference on beam splitting behavior. This work realizes polarization-encoded beam splitting through gradient refractive index design in patterned liquid crystal devices, with its dynamically tunable characteristics providing both theoretical foundation and technical pathways for developing novel reconfigurable photonic devices.
Jun. 05, 2025Vol. 40 Issue 6 827 (2025)
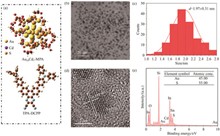
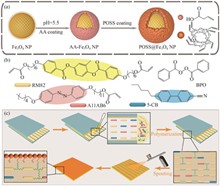
Yujie CAI, and Huaiping CONG
In order to endow liquid crystal elastomers (LCE) with multiple-stimuli-responsiveness and enhance their potential application in flexible robotics, we developed an interfacial polymerization strategy to fabricate a bilayer nanocomposite LCE with photochemical, photothermal, and magnetic responsiveness. The Fe3O4 nanoparticles coated with octa-vinyl polyhedral oligomeric silsesquioxane (POSS@Fe3O4 NPs) were sprayed onto the surface of partially polymerized azobenzene LCE, and then induced the free radical polymerization between the unreacted acrylic-ester groups in the polymeric matrix and the abundant vinyl on the magnetic nanomaterials layer, to yield a POSS@Fe3O4 NPs-LCE composite (PFe-LCEs) with a tightly-integrated organic-inorganic interface. With merits of the UV-induced isomerization of azobenzene mesogens and the photothermal conversion capability of POSS@ Fe3O4 NPs, the composite elastomer could generate a 200° bending in 2 s under UV irradiation and returned to its initial state within 7.5 s under infrared light exposure. In contrast, utilizing visible light irradiation for 50 s can only restore 83% of the original shape. Additionally, this material exhibits magnetic responsiveness, allowing it to deflect under an applied magnetic field. The PFe-LCE was used to fabricate a quadrupedal transport robot capable of grasping, transporting, and releasing cargo through light-magnetic synergistic actuation in a complex environment. The demonstrated environmental adaptability highlighted a novel strategy for intelligent actuation in soft robotics.
Jun. 05, 2025Vol. 40 Issue 6 836 (2025)
Junhui WANG, Xuan LIU, Xia DUAN, Boyuan LI, Conglong YUAN, and Zhigang ZHENG
Micro-nano structures play a crucial role in numerous fields, particularly in optics, sensing, and display technologies. Although various techniques have been developed for micro-nano structure fabrication, achieving these structures through simple and low-cost approaches remains a significant challenge. To address this issue, this paper proposes a design based on patterned oriented guest-host liquid crystals, which successfully realizes the preparation of mask templates constructed on demand. Specifically, the patterned mask is successfully established through the combination of the anisotropic absorption characteristics of guest-host liquid crystals to polarized light and the photo-alignment technology, achieving precise spatial intensity regulation of the incident light field. By introducing it into the laser direct writing system, micro-nano structures with various geometric patterns were successfully formed on the surface of the photoresist. The structure is in close agreement with the predefined mask, demonstrating the capability of structural manufacturing at the micron level (feature size 5 μm). In addition, the self-assembly of liquid crystal on the micro-nano structure enable period grating, thereby achieving stable diffraction under short-wavelength conditions. This result further demonstrates that the designed liquid crystal mask can achieve precise control over the intensity of incident light by accurately modulating the spatial distribution of the optical field. This study provides a novel and cost-effective approach for microstructure fabrication, offering new opportunities for the development of large-area, rapid manufacturing techniques for complex micro-nano structures.
Jun. 05, 2025Vol. 40 Issue 6 846 (2025)
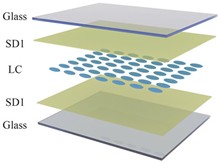
Rui ZHOU, Honglong NING, Xiaoqin WEI, Jianhua ZHOU, Yuxiang LIU, Kangping ZHANG, Muyun LI, Lei WANG, Rihui YAO, and Junbiao PENG
Liquid Crystal Display (LCD) is a technology that uses liquid crystal materials to display images. It has advantages such as high durability, reliability, low power consumption, high resolution, and low radiation, and is widely used in military, automotive, medical equipment and other fields. In actual application environments, due to the differences in application regions and fields, LCD modules are often in wet and hot or cold environments. In humid-heat and cold environments, LCD modules will encounter problems such as image distortion, internal structure corrosion, “Mura” defects, and deformation of liquid crystal molecules. All these may cause irreversible damage to the modules and lead to the screen being unable to function properly. This paper provides a comprehensive review of damage conditions in LCD modules under humid-heat and cold environments. It introduces the fundamental components and working principles of liquid crystal displays, discusses the optimization measures implemented under different environmental conditions, and analyzes the potential issues and challenges in future development. The study concludes with perspectives on technological advancements and application prospects in this field.
Jun. 05, 2025Vol. 40 Issue 6 854 (2025)
Jia LIU, Nanxuan HUANG, Dapeng CHEN, and Lina WEI
Existing 3D hand mesh reconstruction methods face multiple challenges, especially when dealing with occlusion and highly flexible hand poses, which lead to issues such as missing geometric information and topological errors. To enable accurate and efficient 3D hand reconstruction under occlusion, this paper proposes a two-stage network framework for real-time and efficient reconstruction of hand 3D meshes from monocular RGB images. In the first stage, the adaptive occlusion recovery module is designed by introducing learnable attention weight masks and region consistency loss within the attention mechanism. This module targets occluded regions and adaptively recovers information, significantly enhancing feature representation ability under occlusion. In the second stage, the paper combines static topology modeling and dynamic pose perception, as well as feature information exchange between bidirectional graph convolutions and a novel joint rotation-aware attention. This results in the topology-pose bidirectional perception module, which achieves complementary enhancement of static and dynamic features, improving the ability to capture fine-grained joint details. The proposed method is evaluated through qualitative and quantitative experiments on the FreiHAND and InterHand2.6M datasets, compared with state-of-the-art methods. Experimental results show that on the FreiHAND dataset, the proposed method achieves the PA-MPVPE reduction to 6.1 mm with an inference speed of 39 FPS, and on the InterHand2.6M dataset, the MPJPE of the proposed method is reduced to 8.07 mm, and the MPVPE is reduced to 8.22 mm. The proposed approach meets the requirements for robust occlusion handling, real-time performance, and accurate pose estimation in 3D hand reconstruction.
Jun. 05, 2025Vol. 40 Issue 6 867 (2025)
Dunpan SHI, Wei XU, Yongjie PIAO, Yinghong FANG, Haolin JI, and Pengfei LI
Video snapshot compressive imaging (SCI) is a novel imaging technique. It captures three-dimensional video data using a two-dimensional detector within a single exposure time and then reconstructs the original video data with appropriate algorithms. Although many current algorithms have outstanding performance in the reconstruction tasks of video SCI, the improvement of their reconstruction quality often comes at the cost of sacrificing the reconstruction speed, which significantly reduces the real-time performance of the algorithms. To balance reconstruction quality and speed, this paper proposes an end-to-end deep video SCI reconstruction method based on Mamba-2, namely M2BA-SCI. The M2BA-SCI network consists of a preprocessing module, a token generation block, Mamba attention blocks, and a video reconstruction block. Among them, the Mamba attention blocks are mainly composed of Mamba-2 linear attention blocks and feed-forward neural networks. A large number of experiments on simulated and real video datasets show that M2BA-SCI achieves a more balanced effect compared with previous algorithms. It maintains a relatively fast reconstruction speed while improving the reconstruction quality. In the benchmark grayscale video dataset, the average PSNR is 34.85, the average SSIM is 0.966, and the running time is 0.23 s. In the benchmark color video dataset, the average PSNR is 36.21, the average SSIM is 0.963, and the running time is 1.03 s. M2BA-SCI brings new ideas to video SCI reconstruction and provides a reference for designing algorithms with higher reconstruction quality based on the Mamba model.
Jun. 05, 2025Vol. 40 Issue 6 881 (2025)
Qi LUO, Wangming XU, Yaoxiang LI, and Yuhang ZHAO
Aiming at the problem that the stitching of borehole wall images in geological exploration is easily affected by multiple factors such as imaging illumination conditions, probe disturbance, and information missing of depth or azimuth, a robust stitching method for borehole wall images under multi-interference imaging conditions is proposed. Firstly, an image mapping method with conditional constraints is adopted to expand a specific sampling region of the borehole wall image into a narrowband image that can be effectively used for stitching under the interference of the imaging light source. Then, the intrinsic characteristics of the images in borehole video are utilized, and an ROI-based registration strategy is adopted to realize the accurate registration of the unfolded narrowband borehole images under the conditions of probe disturbance and information missing of depth and azimuth, and then a precise registration of the unfolded narrowband image of the borehole under the conditions of probe disturbance, missing depth or azimuthal angle. At the same time, a grid-based matching strategy is applied to improve the registration speed. Finally, a row-by-row dynamically weighted image fusion method is adopted to eliminate the stitching traces according to the registration results, which further optimizes the quality of the stitched images. Through the experiments on the simulated images under different geological conditions, the performance indexes of the proposed method with average value of SSIM of 71.39%, average value of PSNR of 26.74, and average value of registration accuracy of 92.38% are better than those of the comparison method. Through the experimental results on the real images of different borehole videos, the objective evaluation indexes of the stitching results obtained by the proposed method, such as EN, SF, AG, MI, and QMI, etc., are all improved.
Jun. 05, 2025Vol. 40 Issue 6 895 (2025)
Kun BAI, Zhe WANG, Long MA, Yao XUE, Guodong LI, Tian YAN, and Xiaotian WANG
Text detection techniques have become highly mature, but detecting text with arbitrary shapes remains a major challenge in text detection tasks due to geometric encoding limitations of text boxes. In natural scenes, text exhibits a diverse range of shapes, and real-world text is subject to influences such as shooting angles, physical distortions of background objects, and the inherent curvature of the text itself. Merely using rectangular bounding boxes proves insufficient for encompassing irregular text instances. To improve the issue of detecting text with arbitrary shapes, a method that utilizes Fourier transforms in the frequency domain to construct text features is proposed, enabling the reconstruction of predicted boxes by predicting the text’s central line. The predicted text central line not only assists in reconstructing text boxes with complex shapes, but also aids in the subsequent text recognition process through central line correction. The proposed method achieves quite competitive performance on challenging arbitrary-shaped text detection dataset CTW1500, TotalText.
Jun. 05, 2025Vol. 40 Issue 6 905 (2025)
Zhihao ZHANG, Xiaorun LI, and Shuhan CHEN
Small object detection in UAV aerial images faces challenges such as small object sizes, complex backgrounds, and limited computational resources. Most existing object detection models deployed on UAVs suffer from low accuracy and struggle to achieve a good balance between detection accuracy and efficiency. To address these issues, this paper proposes a lightweight small object detection algorithm, ACFI-YOLO11 (Attention-based Cross-layer Feature Interaction-YOLO11), based on YOLO11 framework. First, this paper designs a Tiny Head branch, which enhances the model’s ability to detect tiny objects by introducing higher-resolution feature maps. Second, this paper proposes a novel attention-based cross-layer feature interaction module (ACFI). This module uses a layer feature aggregation (LFA) mechanism and a Transformer encoder to enable direct information exchange between the current layer and its adjacent layers. This approach addresses the limitations of the original model’s neck network, where features were passed sequentially and primarily focused on the preceding layer, failing to fully explore and leverage cross-layer feature correlations. The proposed module significantly enhances the model’s representational capacity. Finally, this paper introduces space-to-depth (SPD) convolution to replace traditional convolution. This reduces the model’s parameters and computational cost while preserving critical spatial information during downsampling, thereby improving detection accuracy for small objects. Experimental results on the VisDrone2021 dataset show that compared to YOLO11s, ACFI-YOLO11 achieves improvements of 4.2%, 3.5%, 5.2%, and 4.0% in APS, APXS, mAP50, and mAP50-95, respectively, and outperforms other comparison algorithms with a mAP50-95 of 31.7%. Furthermore, comparative experiments on the UAVDT dataset validate the superiority of ACFI-YOLO11, achieving a mAP50-95 of 83.3%, significantly outperforming other state-of-the-art algorithms. These results demonstrate that ACFI-YOLO11 not only achieves a lightweight model design but also significantly enhances detection performance, providing an efficient and practical solution for small object detection in drone aerial imagery.
Jun. 05, 2025Vol. 40 Issue 6 915 (2025)
Ximing MA, Ning LI, Di WU, Jianfei WANG, and Xiangyue YU
In dense scenes, occlusion of the pedestrian body and varying pedestrian scales are the main reasons for the degradation of pedestrian detection accuracy. Since the head region of pedestrians is less occluded, it can be used to assist detection. In this regard, this paper improves the Faster R-CNN algorithm and proposes a multi-scale pedestrian detection algorithm based on the joint head and overall information. First, a recursive multi-scale feature extraction network incorporating the coordinate attention mechanism is designed for obtaining rich and detailed multi-scale feature information and enhancing the sensitivity of the network to small-scale pedestrian locations. Then, the region proposal network is utilized to simultaneously generate pedestrian head and body proposals, and a head and body detection branch is constructed for joint detection. Finally, an adaptive joint non-maximum suppression algorithm is proposed so that the detection boxes with severe overlap are not over-suppressed and the false detection boxes generated by the two detection branches are screened out simultaneously to further enhance the accuracy of pedestrian detection. The experimental results show that compared with the baseline algorithm, the proposed algorithm improves the average precision by 2.9% on the CrowdHuman dataset and reduces the log-average miss detection rate by 4%, and reduces the log-average miss detection rate by 2.4% and 2.2% on the two small-scale subsets of the TJU-DHD-pedestrian dataset, which verifies the effectiveness of the proposed algorithm in the dense scene.
Jun. 05, 2025Vol. 40 Issue 6 931 (2025)
Zongcheng MIAO, Runxi ZHOU, Jie LIU, and Haiyan YANG
In recent years, the application fields of UAV technology have been expanding, covering a wide range of fields such as military and civilian. Especially in the field of absolute visual localization, the introduction of deep learning has brought significant breakthroughs to traditional methods and promoted the technological development in this field. Compared with the early methods relying on traditional computer vision feature extraction, absolute visual localization methods based on deep learning have achieved significant improvements in localization accuracy and robustness. In this paper, we systematically review deep learning-based absolute visual localization methods for UAVs, and explore the application potential and development prospects of absolute visual localization technology by analyzing the limitations of global navigation satellite systems and relative visual localization in complex environments. The key research progress in this field is summarized, including dataset construction and deep learning model optimization, and the current technical bottlenecks are dissected. Finally, future research directions are proposed to further promote the wide application and sustainable development of absolute visual localization technology in the field of autonomous UAV navigation.
Jun. 05, 2025Vol. 40 Issue 6 942 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20