






Please enter the answer below before you can view the full text.


2025
Volume: 40 Issue 5
13 Article(s)

Xiaohui GONG, Hao ZHANG, Dongfang YANG, and Yang LIU
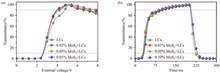
The memory behavior in liquid crystals (LCs) that is characterized by low cost, large area, high speed, and high-density memory has evolved from a mere scientific curiosity to a technology that is being applied in a variety of commodities. In this study, we utilized molybdenum disulfide (MoS2) nanoflakes as the guest in a homotropic LCs host to modulate the overall memory effect of the hybrid. It was found that the MoS? nanoflakes within the LCs host formed agglomerates, which in turn resulted in an accelerated response of the hybrids to the external electric field. However, this process also resulted in a slight decrease in the threshold voltage. Additionally, it was observed that MoS? nanoflakes in a LCs host tend to align homeotropically under an external electric field, thereby accelerating the refreshment of the memory behavior. The incorporation of a mass fraction of 0.1% 2 μm MoS? nanoflakes into the LCs host was found to significantly reduce the refreshing memory behavior in the hybrid to 94.0 s under an external voltage of 5 V. These findings illustrate the efficacy of regulating the rate of memory behavior for a variety of potential applications.
May. 05, 2025Vol. 40 Issue 5 665 (2025)
Bingxuan XIA, Jiawei JIANG, Zhanyang YU, Wenzhong CHEN, Bobo YANG, and Jun ZOU
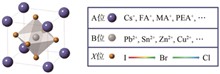
This paper reviews the research progress of pure bromine group blue light perovskite materials in recent years, mainly focused on the pure bromine group blue light perovskite synthesis method and research progress, covering the thermal injection method and ligand assisted precipitation, and through ligand engineering, A position cation engineering, quasi two-dimensional structure design and B position substitution engineering strategy to optimize its performance. Ultra-small perovskite quantum dots use ligand engineering to passivate surface defects and improve quantum dot stability. The band gap can be effectively expanded by shrinking the nanocrystals lattice, leading to PL emission blue-shift, high PLQY, narrow bandwidth and sharp exciton absorption transitions. For quasi-two-dimensional blue light perovskite, organic septal cations and additives are usually choosed to regulate the number of quasi-two-dimensional perovskite layers, so that the phase is cleaner and narrower, so as to obtain better performance of blue light devices. In addition to the common passivation agents, polymers can also act as passivation agents. For example, polyvinylidene (PVDF) effectively passivate surface defects and enhances stability. These optimization strategies have made significant progress in brightness, color purity and efficiency, providing new ideas for high-performance blue light-emitting devices.
May. 05, 2025Vol. 40 Issue 5 674 (2025)
jie LIU, QI ji, Shiyan GAO, Wenyi CHEN, Yuexin SUI, Zemin HE, Haiyan YANG, and Zongcheng MIAO
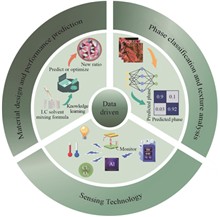
Liquid crystal materials, with their dual properties of solid and liquid states, offer unique advantages in materials science and applications. In recent years, data-driven approaches have been widely applied in research areas such as liquid crystal phase classification, material design and performance prediction, and sensor technologies. Through data-driven techniques like machine learning, significant progress has been made in the prediction of liquid crystal phase transitions, evaluation of physicochemical properties, and optimization of sensor performance. These studies have not only enhanced the performance of liquid crystal materials but also expanded their potential applications in fields such as intelligent sensors, gas detection, environmental monitoring, and biosensing. This review summarizes the domestic and international research progress on data-driven liquid crystal materials, discusses their prospects in material design, optimization, and applications, and provides insights into the future directions of liquid crystal materials science.
May. 05, 2025Vol. 40 Issue 5 685 (2025)
Zhiwei ZHANG, Xudong WEN, Xin GAO, Xinzhu SANG, Binbin YAN, Shujun XING, and Xunbo YU
The periodic structure of liquid crystal display pixels and the cylindrical lens array often leads to generating Moiré patterns within a specific range of cylindrical lens tilt angles in three-dimensional light field displays. These patterns overlay display contents, significantly degrading the viewing experience. A common approach to mitigate Moiré involves adjusting the tilt angle of the cylindrical lens array. To identify optimal tilt angles for suppressing Moiré, this study proposes a Moiré pattern visualization simulation method based on the segmentation analysis of cylindrical lens array units. Using geometric optics principles, the imaging characteristics of individual cylindrical lens units are analyzed, and the resultant imaging outputs are simulated. The simulated images are then stitched to reconstruct the complete light field display, enabling Moiré pattern visualization. Experimental results demonstrate that the proposed method effectively visualizes the overall light field display and its local structures. Additionally, the tilt angle of the cylindrical lens array can be adjusted within the range of 0° to 90°. The simulation accurately predicts Moiré patterns for various light field display devices and provides valuable guidance for determining the optimal tilt angle of the cylindrical lens array.
May. 05, 2025Vol. 40 Issue 5 697 (2025)
Chenyu NING, Ningchi LI, Yunfan HU, Xin GAO, Binbin YAN, Xinzhu SANG, and Xunbo YU
In 3D light-field display, perspective error occurs when the viewer moves forward or backward, resulting in the perception of incorrectly deformed 3D images. A perspective correction method based on optical flow prediction is presented to achieve correct perspective in 3D light-field display. A perspective relationship completion network is presented, which integrates an optical flow prediction network and a perspective transformation network, to achieve effective correction of perspective relations. The optical flow prediction network supplies depth information to assist the perspective transformation network in generating correct depth-oriented optical flow. The vertical component of the depth-oriented optical flow is retained to interpolate perspective information at any distance within the specified range. The viewer’s position is captured using an eye-tracking device, enabling real-time generation and encoding of images that are loaded on the 3D light-field display system for immediate perspective correction. Experimental results demonstrate the method can effectively correct perspective relations and present correct 3D images when the viewer moves forward or backward.
May. 05, 2025Vol. 40 Issue 5 707 (2025)
Yifei HONG, Zihan NIE, Xinzhu SANG, and Shujun XING
Grating stereoscopic display is currently one of the most popular naked eye three-dimensional(3D) displays, and optimizing its parameters is a key step in the display design process. This article proposes an optimization method for grating stereoscopic displays based on simulation image evaluation. This method is based on existing grating stereoscopic display simulation platforms and assesses display quality by evaluating simulation images, which is more intuitive and convenient, rather than optical indicators. This research invites reviewers to conduct subjective experiments and selects the most suitable evaluation criteria for 3D display simulation images: learned perceptual image patch similarity (LPIPS). A joint optimization experiment is conducted on the parameters of a cylindrical lens grating stereoscopic display using Bayesian method, and compares with the traditional optical optimization results of Zemax. The diffuse spot radius of the center field of view is 15.567 μm, and the diffuse spot radius of the edge field of view is 89.744 μm, both of which meets the design standards of empirical requirements. The experiment results show that this method can correctly optimize the commonly used parameters of the display and achieve the same effect as traditional optical design software. This method has significant potential in the optimization design of grating stereoscopic displays, further provides a new approach for the design process of naked eye 3D displays.
May. 05, 2025Vol. 40 Issue 5 716 (2025)
Heng ZHANG, Lei WANG, Pengchang ZHANG, Jian CHANG, and Xing HE
In order to solve the problem that the simultaneous localization and mapping (SLAM) algorithm has low positioning accuracy and cannot generate effective dense maps in dynamic scenes, a visual SLAM algorithm based on dynamic feature culling and dense mapping is proposed. Based on the ORB-SLAM3 algorithm, a feature point screening thread is added, and the lightweight YOLOV8 network is used to detect dynamic objects in the environment, and the dynamic feature points in the environment are eliminated by combining the optical flow method and the polar geometric constraint. The dense point cloud map is constructed by using the generated keyframes and calculated poses in the newly added dense mapping thread. Compared with the original ORB-SLAM3, the positioning errors are reduced by 90%. At the same time, the ghosting caused by dynamic objects is removed from the dense mapping results. The new algorithm effectively solves the problem that the visual SLAM algorithm cannot locate and establish an effective map in the dynamic environment by adding the feature point screening thread and dense mapping thread, and greatly enhances the accuracy and robustness of the SLAM system in dynamic scenes.
May. 05, 2025Vol. 40 Issue 5 727 (2025)
Xuan JIA, Ye ZHANG, Xuling CHANG, and Jianbo SUN
To address the issue of low recognition accuracy in scene images caused by subtle inter-class differences and ambiguous intra-class classifications, this paper proposes a novel semantic segmentation framework. By introducing deep metric learning and focusing on the semantic relationships between pixels, the model’?s recognition accuracy can be improved. Firstly, feature extraction is performed through the hollow space pyramid pooling module. Then, in the decoding process, the shallow high-resolution features and deep low resolution features are fused using a structure to better restore the details and boundaries in the image. Secondly, in the deep metric learning module, a well structured pixel semantic embedding space is learned to effectively classify pixels by maximizing the Euclidean distance between pixels of different categories and minimizing the Euclidean distance between pixels of the same category. Finally, a fusion loss function combining weighted focus loss and contrast loss is adopted to balance the importance between different samples, thereby more accurately measuring the performance of the model and improving the accuracy and robustness of scene recognition. The experimental results demonstrate that the average intersection to union ratios of the model on the publicly available datasets ADE20K and Cityscapes are 47.6% and 83.1%, respectively. Compared with the baseline of today?’?s advanced scene recognition methods, the results show that the proposed method is feasible and progressiveness.
May. 05, 2025Vol. 40 Issue 5 740 (2025)
Jianqiang ZHANG, and Qiusheng HE
Aiming at the problem of low brightness and blurred detail information in low-light images, this paper proposes a context-aware low-light image enhancement algorithm. First, the context-aware module for extracting detail information and edge artifacts was investigated. Nonlinear mapping was performed using activation functions to get the importance of features in the current context. Second, the model used linear attention gating mechanism instead of the multi-head attention module in Transformer. It reduced the computational complexity in high-resolution images while maintaining the performance. Finally, the reconstruction guidance module was designed to focus on the information in the low-light region during image reconstruction. The correlation information between the positions in the input sequence was captured to improve the expressiveness of the model for the reconstruction processing task. The results show that compared with the existing typical low-light enhancement algorithm URetinex, the PSNR and SSIM of images generated on the dataset LOL are increased by 1.33% and 3.73%, and the PSNR and SSIM of images generated on the dataset SICE are increased by 1.2% and 2.8%. The proposed algorithm can effectively enhance low-light images and generate clear and high-fidelity images.
May. 05, 2025Vol. 40 Issue 5 751 (2025)
Lanlan WANG, and Yan YANG
To address the issues of distortion in thin fog areas and incomplete dehazing in dense fog areas present in current dehazing algorithms, we propose an image dehazing algorithm that combines fog concentration segmentation with atmospheric light mapping. First, we analyze the fog concentration distribution in different regions of the image and construct a fog concentration estimation model using saturation and chromiance, a fuzzy clustering algorithm is then applied for region segmentation, effectively identifying thin and dense fog areas. Next, based on the relationship between fog concentration and atmospheric light, we design specific atmospheric light estimation models for different regions to ensure accurate processing of various fog concentration areas. Finally, by utilizing the brightness component of the fog concentration, we improve the estimation of local atmospheric light and obtain a fog-free image based on the atmospheric scattering model. The experimental results indicate that the algorithm effectively addresses the poor image restoration performance in non-uniform foggy conditions. Compared to current mainstream dehazing algorithms, it achieves improvements of 39% in visible edge increase rate, 28% in normalized average gradient, 10% in image entropy, 20% in visibility balance metric, 37% in visual contrast, 47% in image contrast, and 35% in computation time.
May. 05, 2025Vol. 40 Issue 5 761 (2025)
Longchun WANG, Wei FANG, Lijuan ZHANG, and Dongming LI
Aimed at overcoming issues like limited object types, missed detection, and false positives in existing models, an improved object detection algorithm for autonomous driving based on YOLOv8s is proposed. Ordinary convolutions in the YOLOv8s backbone are replaced with RepConv (Re-parameterization Convolution) to enhance target perception while reducing computational load and memory consumption, thereby improving model efficiency. Additionally, an efficient multi-scale attention (EMA) mechanism is introduced after the neck’s C2f block to strengthen feature attention and accelerate model convergence. A P2 detection head is also added to improve small object detection capabilities. Finally, the WIoU (Wise-IoU) loss function, featuring a dynamic non-monotonic focusing mechanism and gradient gain allocation strategy, is employed to boost overall detector performance. On a manually labeled Car dataset, the improved model achieved mAP50 and mAP(50-95) scores of 81.2% and 58.4%, respectively, 1.5% and 1.2% higher than the original YOLOv8s model. Precision and recall are improved by 1.9% and 0.8%, and the parameter count is decreased from 11.14M to 10.87M. The proposed modules increase detection accuracy while reducing parameter count, making the model more suitable for autonomous driving applications.
May. 05, 2025Vol. 40 Issue 5 773 (2025)
Wenshun SHENG, Jiahui SHEN, and Qi CHEN
Aiming at the challenges of pedestrian tracking, such as local occlusion and frequent ID change, which is frequently encountered in the complex and variable traffic environment, a multi-target pedestrian tracking method integrating YOLOv8 and DeepSORT (Simple Online and Realtime Tracking with a Deep Association Metric) is proposed. Firstly, in the detection stage, to enhance the ability of capturing the feature information for target pedestrians in dense traffic scenarios, YOLOv8 algorithm is selected, which is renowned for its efficient small-scale feature processing capability, ensuring the accuracy and speed of detection. Secondly, to fulfill the requirement of real-time tracking, OSNet (Omni-Scale Network) is introduced as the feature extraction network based on DeepSORT. Through the multi-scale dynamic fusion strategy, OSNet provides a richer and more accurate information basis for subsequent tracking. Thirdly, in view of the limitations of traditional Kalman filtering in nonlinear motion trajectory prediction, an innovative filter smoothing Kalman algorithm (FSA) is designed, which can flexibly adjust filtering parameters and effectively cope with the uncertainty of pedestrian movement in traffic scenes, significantly enhancing the accuracy of prediction. Additionally, to improve the stability and accuracy of data matching in the tracking process, the original intersection over union (IOU) association matching mechanism of DeepSORT is replaced with the improved complete-intersection over union (CIOU) algorithm. CIOU not only considers the degree of overlap between objects but also incorporates geometric information such as shape and size, effectively reducing the rate of missed and false detection. Finally, to further mitigate the impact of multiple noises on tracking performance, the trajectory feature extractor (GFModel) is introduced. The model combines local details with global context information through average pooling technology to achieve accurate tracking and prediction of the target pedestrian trajectory. Experimental results demonstrate that the proposed method achieves 77.9% tracking accuracy while maintaining a processing speed of 55.8 frame per second (FPS), which fully meets the demand for efficient and accurate tracking in actual complex traffic environment.
May. 05, 2025Vol. 40 Issue 5 785 (2025)
Bin LIU, Qian LIU, Weiwei MING, and Xiaojin HUANG
Due to the unique geometric characteristics and dimensional constraints of gold-plated rotary workpieces, it is challenging to quickly and accurately capture their full-surface images. To address these issues, a novel full-surface imaging method based on adaptive brightness correction is proposed. Firstly, to recover information in low-brightness regions, an adaptive brightness adjustment algorithm is introduced. This algorithm initially applies global brightness mapping for pre-adjustment, followed by guided filtering instead of traditional Gaussian filtering to enhance local contrast across multiple scales while preserving features such as scratches and edges. Secondly, an innovative image stitching method based on adaptive Region of Interest (ROI) cropping is designed, which utilizes threshold segmentation in the HSV color space and homography estimation to accurately extract valid regions from the input images. This approach minimizes influence of surface projection distortion and parallax during image fusion and improves computational efficiency. Experimental results show that the brightness correction algorithm improves the quality of image features, leading to a reduction of approximately 50% in the average back-projection error during registration, with image stitching speeds reaching 1.25 frame/s. Compared with classic algorithms like Autostitch and LPC, the proposed method demonstrates notable advantages in both accuracy and efficiency. The proposed method is suitable for acquiring full-surface images and detecting defects on rotational workpieces in industrial environments.
May. 05, 2025Vol. 40 Issue 5 796 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20