







Please enter the answer below before you can view the full text.


2025
Volume: 54 Issue 8
33 Article(s)
Haiming DENG, Baoyuan DENG, Hongjin WANG, Xiaofei ZHANG, and Yunze HE
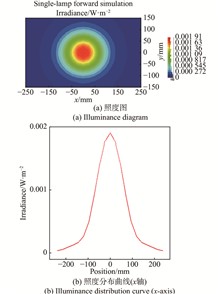
ObjectiveAs a key component of active infrared thermography detection technology, the excitation source has a direct impact on the detection effect, and the halogen lamp, as a commonly used excitation source in infrared thermography detection, has the advantages of rapid heating, high stability and strong adjustability, and has become a cost-effective excitation source in active infrared thermography. Halogen lamps can be used as excitation sources with a single halogen lamp or multiple halogen lamps as excitation, and their main differences are heating uniformity and irradiation intensity, which will affect the performance of the excitation source and thus the detection of defects. Therefore, the study of the irradiance distribution of a single halogen lamp and multiple halogen lamps and their detection effect as an excitation source on carbon fiber composites can provide guidance for the design of effective halogen lamp excitation sources, so as to improve the detection effect of carbon fiber composites.MethodsThe irradiance simulation of a single halogen lamp and multiple halogen lamps was carried out to explore their irradiance distribution. The finite element simulation of carbon fiber composites by a single halogen lamp and a halogen lamp array was carried out to explore their heating effects on carbon brazing composites. COMSOL was used to perform a finite element simulation of thermal imaging of absorber coating debonding defects, and to explore which single halogen lamp or halogen lamp array as an excitation source was better for detecting absorber coating debonding defects. Periodic thermal imaging experiments were carried out to investigate the actual detection effect of a single halogen lamp and a halogen lamp array as an excitation source on the debonding defects of the absorbing coating.Results and DiscussionsFrom the irradiance simulation results, it can be seen that the irradiance uniformity of the single lamp is poor, and the irradiation intensity is also low, with the maximum irradiation intensity of only 0.001 9 W/mm2, and the irradiance uniformity and irradiation intensity of the halogen lamp array are good (Fig.4). From the finite element simulation of carbon fiber composite heating, it can be seen that a single halogen lamp only heats a small circular area in the center of the specimen, while the halogen lamp array can achieve uniform heating of the specimen in the area size of 280 mm× 160 mm (Fig.9). From the finite element simulation of the debonding defects of the absorbing coating, it can be seen that a single halogen lamp can only detect defects in the heating area as an excitation source, and the halogen lamp array can heat the whole specimen more uniformly, and the defect detection effect is better (Fig.14). The results of the final periodic thermal imaging experiments show that the infrared heat map noise obtained by a single halogen lamp as an excitation source is larger, and the infrared heat map noise obtained by the halogen lamp array as an excitation source is significantly less, and the minimum diameter of the defects with a buried depth of 0.3 mm, 0.5 mm, 1 mm and 2 mm can be detected is 3 mm,which verifies the effectiveness of the halogen lamp array as an excitation source for thermal imaging (Fig.19).ConclusionsBy simulating the irradiance distribution of a single halogen lamp and a plurality of halogen lamps, it is concluded that the irradiance distribution range of a single halogen lamp is small and the irradiance distribution is uneven, while for multiple halogen lamps, the irradiance distribution uniformity and irradiation range can be increased by adjusting the spacing between halogen lamps and increasing the number of halogen lamps. From the results of thermal imaging finite element simulation, it can be seen that a single halogen lamp as an excitation source can heat the carbon fiber composite material in a small range and heating unevenly, while the halogen lamp array can provide uniform heating within a certain range, and the irradiation intensity is also greater than that of a single halogen lamp because the total output power of the halogen lamp array is higher. It can be seen from the detection results of the debonding defects of the absorbing coating that the detection effect of halogen lamp array as an excitation source is better than that of a single halogen lamp as an excitation source. From the point of view of defect detection, it is suitable to detect defects with shallow burial depth in the early stage of heating, and suitable for detecting defects with deep burial depth in the late heating stage. The above research content can provide guidance for the design of effective thermal imaging halogen lamp excitation source.
Aug. 25, 2025Vol. 54 Issue 8 20250126 (2025)
Binyao FENG, Hui QIAO, Yizhen YU, Liyi YANG, Xiangrong HE, Runze XIA, and Xue LI
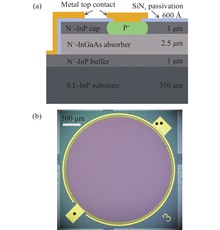
Objective Short-wave infrared indium gallium arsenide (InGaAs) detectors are crucial infrared devices, characterized by high quantum efficiency and high sensitivity at room temperature, thus finding extensive applications in aerospace remote sensing, industrial and agricultural production, security monitoring, biomedical imaging, and other fields. Dark current is a key performance parameter of short-wave infrared InGaAs detectors; reducing dark current under various bias voltages can enhance the detection capability of devices in different application scenarios. During the growth of semiconductor materials and the fabrication of devices, various types of defects are introduced, which affect the dark current and noise characteristics of the devices. In the development of photovoltaic devices, plasma hydrogenation technology can be utilized to passivate the surface or interface states of semiconductor materials through hydrogen. By eliminating the electrical activity of defects in semiconductor materials, photovoltaic cells can improve the quantum efficiency of semiconductor devices. However, there are few studies on the optimization of detector performance using plasma hydrogenation technology for room-temperature-operated PIN-type InGaAs detectors, especially regarding its impact on dark current mechanisms and noise. Therefore, this work focuses on the application of plasma hydrogenation technology in PIN-type InGaAs detectors.Methods Room-temperature plasma hydrogenation technology was applied to the fabricated planar InGaAs detectors. A plasma etching machine was used to achieve hydrogen passivation of the devices. During the process, the devices were attached to the carrier with their photosensitive surfaces facing upward using vacuum silicone grease and placed inside the equipment chamber, i.e., the device surfaces were fully exposed to the hydrogen plasma atmosphere. The planar InGaAs detectors before and after hydrogenation were tested using an Agilent B1500A semiconductor analyzer to obtain their I-V characteristics. A current-voltage conversion amplifier and a lock-in amplifier were used to test the dark noise of the devices. To evaluate the impact of plasma hydrogenation on the response spectrum of the detectors, a Fourier transform infrared spectrometer and a current-voltage conversion amplifier were employed for testing.The relationship between hydrogenation and dark current mechanisms as well as noise characteristics was analyzed in combination with the measured data.Results and DiscussionsThe I-V test results showed that the dark current of the InGaAs detectors decreased significantly after the hydrogenation process (Fig.6). At a relatively large bias voltage of -1 V, the average dark current density decreased from 36.13 nA/cm2 to 17.42 nA/cm2; under the near-zero bias condition of -0.02 V, the average dark current density decreased from 6.54 nA/cm2 to 2.44 nA/cm2. After room-temperature plasma hydrogenation, the dark current density under different bias voltages decreased by 2-3 times. Further analysis of the dark current mechanism revealed that the diffusion current, generation-recombination current, and shunt current were all suppressed to varying degrees (Fig.8). Diffusion current dominated in the bias range of 0 to -0.27 V both before and after hydrogenation, but the critical voltage where diffusion current dominates decreased by 0.15 V after hydrogenation. At large bias voltages, the proportion of shunt current increased slightly after hydrogenation. Since the minority carrier lifetime of InGaAs increased 6-fold from 10.7 μs to 75.2 μs after hydrogenation (Tab.1), and the zero-bias resistance increased by 1.75 times, the measured dark noise of the detectors decreased by approximately 40% (Tab.2).ConclusionsThrough systematic electrical tests and analyses, the room-temperature plasma hydrogenation process effectively modified the dark current mechanism of PIN-type InGaAs detectors and improved the dark current levels of various components, with the three main current components decreasing by 2-3 times to varying degrees. By optimizing the minority carrier lifetime of InGaAs, the dark noise of the detectors was reduced by approximately 40%. Therefore, the application of room-temperature plasma hydrogenation holds significant technical reference value for the development of high-sensitivity InGaAs detectors.
Aug. 25, 2025Vol. 54 Issue 8 20250135 (2025)
Xuchang ZHOU, Zhi JIANG, Xuefeng BAN, Haipeng WANG, Jincheng KONG, Gongrong DENG, Biao YUE, Junbo HUANG, Yingchun MU, Xiaohong LEI, Rui CHEN, Haihu WANG, Jie CHEN, Yan ZHOU, Biwen DUAN, and Shufen LI
ObjectiveInAs/GaSb type-II superlattice infrared detectors have advantages such as adjustable wavelength, high temperature sensitivity, and good uniformity. However, there is still a certain gap between their performance and that of traditional mercury cadmium telluride devices. Mechanistically, the defects in the GaSb layer of the superlattice are considered to be the main factor restricting the minority carrier lifetime. Some studies suggest that increasing the temperature can effectively improve the quality of the superlattice material. However, the InSb interface adopted in the superlattice based on the GaSb substrate is relatively fragile and prone to failure at high temperatures. In this paper, based on the InAs/GaSb superlattice system with the GaAs interface, the research on long-wave superlattice infrared focal plane detectors is carried out by using methods such as molecular beam epitaxy technology and the double-barrier structure.MethodsHigh-quality PB1nB2N double-barrier superlattice materials were grown on InAs substrates using molecular beam epitaxy (MBE) technology. The introduction of the GaAs interface enabled an increase in the growth temperature of the superlattice materials, which improved the crystalline quality of the materials and reduced dark current. Additionally, through structural design, an electric field was applied to the wide-bandgap electron and hole barrier layers, achieving separation between the narrow-bandgap absorption layer and the depletion region, thereby minimizing generation-recombination dark current. In the chip fabrication process, smooth mesas are prepared using dry etching technology, and low sidewall leakage is achieved through sulfurization/dielectric film composite passivation.Results and DiscussionsThe 640×512 pixels long-wavelength infrared superlattice FPA detector was fabricated, which shows a cut-off wavelength of 10.14 μm, a temporal noise equivalent temperature difference (NETD) of 17.8 mK, an operability of 99.89%, and quantum effiency of 37%. The camera with this detector shows high-quality imaging capability.The analysis suggests that it is related to the following factors: Based on the high-temperature resistance characteristics of the GaAs interface, the high-temperature (440 ℃) molecular beam epitaxy (MBE) growth technology is adopted. The crystal quality and electrical properties of the superlattice layer have been effectively improved compared with those of the epitaxial materials grown at the conventional temperature (around 400 ℃). As a result, the dark current is effectively reduced while maintaining a relatively high quantum efficiency. By introducing the double-barrier structure, the material structure is improved, and the device impedance is increased. Through the optimization of the device process, the sidewall leakage current is effectively eliminated.ConclusionsA high-performance long-wave superlattice focal plane detector has been developed on the n-type absorption layer/double-barrier long-wave superlattice material with GaAs interface grown by molecular beam epitaxy. The main performance parameters have reached the best levels reported both at home and abroad, verifying this technical route that is different from the material schemes of traditional superlattice infrared detectors. It shows that the n-type absorption layer material using hole minority carriers can achieve high quantum efficiency and low dark current, and it is possible to further improve the device performance by optimizing the material structure and epitaxial conditions to enhance characteristic parameters such as the carrier lifetime.
Aug. 25, 2025Vol. 54 Issue 8 20250139 (2025)
Weiyi ZENG, Yang XU, Jialing LE, Kai YANG, Futian XIE, and Genming CHAO
ObjectiveWhen the air breathing vehicle works at high altitude, the surrounding air is thin and the unit Reynolds number of the incoming flow is small, so it is difficult for the front compression surface to transition into turbulence, which makes the boundary layer easily separate and leads to the degradation of vehicle performance. To increase the turbulence degree of the gas entering the vehicle, a forced transition device can be installed to make the boundary layer transition ahead of time. Forced transition methods can be divided into the following two types: one is the passive control of transition induced by rough elements such as diamonds and slopes; Secondly, by introducing the active control of micro-jet induced transition on the wall, it can control the jet pressure according to the actual needs, and then change the jet penetration height and adjust the early transition degree. At present, active transition control has become a research hotspot at home and abroad. Most of the related experimental studies use infrared cameras to obtain temperature distribution, or pulsating pressure sensors to analyze the pulsating information of the wall, which can more clearly understand the flow mechanism behind it. The purpose of this thesis is to study the influence of jet pressure ratio, jet gas and other parameters on transition by combining infrared and atomic layer thermopile measurement methods, and to analyze the influence mechanism of jet pressure ratio on transition.MethodsTaking the forebody configuration as the research object (Fig.5), a micro-jet test scheme with 0.5 mm orifice diameter based on high-pressure storage-bottom pressure injection was designed (Fig.2), and the high-altitude low Reynolds number inflow was simulated in a 1m hypersonic wind tunnel, and the influence of micro-jet on the flow state near the wall was analyzed. An experimental method of jet-induced transition based on infrared thermogram and fluctuating heat flow data is proposed, and the flow mechanism of jet-induced transition is analyzed from the perspective of frequency domain and time domain (Fig.6). A transition evaluation method based on average transition initiation position and average critical Reynolds number is introduced, and the transition initiation position is given.Results and DiscussionsWith the increase of injection pressure ratio, the initial position of transition gradually moves forward (Fig.7-Fig.8), which shows that the jet promotes transition by two ways: instability of sinusoidal mode with frequency of about 60 kHz and generation of curvature mode. When there is no jet, an unstable wave near 60 kHz is captured at the axial X=400 mm and X=600 mm, which may be a sinusoidal mode. When the injection pressure ratio P2/P1=40, the amplitude of unstable wave increases at the axial direction X=400 mm, which may be due to the fact that the micro-jet under this injection pressure ratio mainly promotes the amplitude of sinusoidal mode to increase, resulting in unstable transition. When the injection pressure ratio P2/P1=100, the amplitude of unstable wave decreases again at the axial direction X=400 mm, which is similar to the case without jet. It shows that the high penetration depth under the injection pressure ratio has little influence on the development of sinusoidal mode, and the jet mainly promotes transition by curvature mode. When the injection pressure ratio P2/P1=200, the unstable waves at axial X=400mm and X=460mm disappear, which shows that the wall transition occurs soon after the jet is ejected at this injection pressure ratio, which makes it difficult for ALTP sensors to capture the unstable waves (Fig.9). Under the conditions of the same injection pressure ratio and the same injection flow rate, the initial position of transition is He, N2 and CF4 in order, and the higher the molecular weight is, the more the initial position of transition is (Fig.10-Fig.13).ConclusionsWhen micro-jet is used to actively induce transition at the compression surface of forebody, micro-jet can promote boundary layer transition by promoting sinusoidal mode instability and generating curvature mode. When the injection pressure is relatively small, the jet can induce transition by promoting the instability of sinusoidal mode; When the injection pressure ratio increases above 100, the boundary layer instability can be caused by the curvature mode generated by the jet. When He, N2 and CF4 are injected into the mainstream, the average transition initiation position moves upstream and the average critical Reynolds number decreases with the increase of the molecular weight of the jet gas, which indicates that the transition promotion effect becomes more and more obvious with the increase of the molecular weight of the jet gas.
Aug. 25, 2025Vol. 54 Issue 8 20250198 (2025)
Zhongjie GUO, Weiwei LI, Ruiming XU, Suiyang LIU, and Longsheng WU
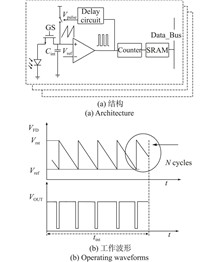
ObjectiveIn the field of infrared imaging technology, the digitization of infrared readout circuits has emerged as a significant research trend. Compared with traditional analog infrared focal plane arrays (FPAs), digital infrared FPAs demonstrate substantial advantages, including enhanced signal processing accuracy, superior anti-interference capability, and improved integration potential. Consequently, research on digital infrared FPAs has become a focal point, with the design and optimization of pixel-level infrared readout circuits constituting a central research focus. Currently, most digital infrared readout circuits employ a pulse-frequency modulation (PFM) architecture. This structure achieves signal digitization by modulating input signals into variations in pulse frequency. However, in the long-wave infrared (LWIR) band, where detectors generate relatively large equivalent photocurrents, the PFM architecture exhibits notable limitations in terms of power consumption and linearity. Specifically, under high-injection-current conditions, PFM-based circuits suffer from elevated power dissipation and susceptibility to nonlinearity between input and output signals, leading to signal distortion. This phenomenon is particularly pronounced in LWIR FPAs, ultimately constraining the performance enhancement of LWIR detectors.MethodsCurrently, PFM ADC also faces two problems. The first problem is that increasing the maximum flip times of the counter and comparator within the integration time can enhance the dynamic range, but it will also consume more power. The second problem is that in existing works, subthreshold comparators are used to reduce power consumption, which increases the delay time of the comparator and reduces the linearity. In this paper, a low-power digital pre-comparator is introduced to achieve the precise interval working mechanism. At the same time, the delay time of the comparator is reduced by no longer limiting the bias current of the comparator during the comparison stage to achieve the goal of reducing the power consumption of the readout circuit and improving the linearity of the readout circuit.Results and DiscussionsThe method proposed in this paper is completely designed and simulated based on 55 nm CMOS technology. The experimental results show that: When the input voltage is 3.3 V and the typical light intensity is 20 nA, the overall power consumption of the pixel unit is only 0.65 μW, while the delay time of the comparator module is greatly reduced compared with the traditional structure, so that the input-output nonlinear error is only 0.105%, the charge processing capacity reaches 3.1 Ge-, and the center distance of a single pixel is 20 μm, and the imaging results are shown (Fig.14). The structure proposed in this paper can restore the original image well.ConclusionsThis paper presents an improved PFM ADC and realizes the infrared readout circuit of 2k×2k array. By improving the integral-reset module and adding a low-power pre-comparator, the overall power consumption of the pixel unit is only 0.65 μW under the typical light intensity value of 20 nA. Meanwhile, the comparator module is no longer limited by power consumption, and the input-output nonlinear error is only 0.105%. The charge processing capacity reaches 3.1e- and the center spacing of a single pixel is 20 μm, which provides a scheme for realizing low power consumption and high sensitivity infrared focal plane digital readout circuit.
Aug. 25, 2025Vol. 54 Issue 8 20250212 (2025)
Bingfeng LIU, Lianqing ZHU, Lidan LU, Chen FANG, Weiqiang CHEN, and Mingli DONG
ObjectiveThe suppression of dark current and enhancement of epitaxial quality remain critical challenges for mid-wave infrared (MWIR) detectors based on Type-II superlattices (T2SLs). InAs/InAsSb T2SLs offer tunable bandgaps and long carrier lifetimes, yet high defect density in barrier layers and suboptimal barrier design have limited device performance. Therefore, this study focuses on the design of an nBn MWIR detector architecture employing AlAsSb as the unipolar barrier and on optimizing its epitaxial growth parameters to achieve low dark current, high detectivity, and material uniformity.MethodsA continuum k·p band-structure model was employed to simulate the coupling between thickness and Sb composition in InAs/InAs1-xSbx T2SLs, enabling precise tuning of the 3-5 µm cutoff wavelength (Fig.1). Strain-balanced InAs/InAs0.6Sb0.4 superlattices were grown on GaSb (001) substrates via molecular-beam epitaxy (MBE), with substrate rotation and a V/III beam-flux ratio optimized to promote uniform composition and period thickness. High-resolution X-ray diffraction (HRXRD) rocking-curve measurements at four wafer positions quantified period deviation (2.46%) and strain distribution. The AlAs1-xSbx barrier layer (x≈0.91) was deposited at three temperatures (385 °C, 400 °C, 420 °C) to assess morphology and strain via atomic-force microscopy (AFM) and reciprocal-space mapping (RSM).Results and DiscussionsHRXRD characterization confirmed exceptionally uniform superlattice growth, with full-width at half-maximum (FWHM) of satellite peaks ranging 19.3''-19.8'' (Fig.3). AFM analysis revealed minimum surface roughness (RMS = 0.252 nm) and reduced defect formation for AlAsSb barriers grown at 400 °C (Fig.6). RSM data demonstrated minimal residual strain under optimized Sb/In and As/In flux ratios (8∶1.8), consistent with RSM measurements (Fig.7). At 77 K and –0.6 V bias, Al2O3-passivated devices exhibited dark-current density of 5.30×10-6 A/cm2 and resistance-area product (RA) of 4.13×104 Ω·cm2 (Fig.8). Peak specific detectivity reached 8.35×1011 cm·Hz1/2/W at λpeak = 4.49 µm, and at the 50% cutoff of 5.00 µm, D* remained 5.01×1011 cm·Hz1/2/W (Fig.9). This indicates the device’s performance is comparable to MWIR T2SL detectors with similar cut-off wavelengths.ConclusionsThe combination of k·p band modeling, strain-balanced MBE growth, and AlAsSb barrier optimization has yielded an nBn InAs/InAsSb T2SL detector with comparable performance in the MWIR range. AFM and RSM results validate the growth‐temperature window (400 °C) that minimizes AlAsSb barrier surface roughness and strain. Al2O3 passivation further suppresses surface leakage dark current, enabling D* exceeding 1011 cm·Hz1/2/W under cryogenic operation. These results validate the feasibility of our barrier-structure design and epitaxial process optimizations, laying a technical foundation for high-performance MWIR Type-II superlattice detectors in large-format focal-plane array applications.
Aug. 25, 2025Vol. 54 Issue 8 20250340 (2025)
Xinyang HU, Ming LI, Yingjie MA, Hongbin LIU, Jiayi SHEN, Fengxiang WANG, Genghua HUANG, and Rong SHU
ObjectiveThis study proposes a sparse photon simulation model and a point cloud registration method based on a matrix array single-photon lidar, analyzing the factors that influence point cloud matching performance. The primary application scenario is the space rendezvous and docking process, with the Tianghe core module as the target(Fig.4). The research aims to design and optimize lidar systems for precise detection and positioning during space station docking operations.MethodsThe simulation model is constructed using the design parameters of the lidar hardware (Fig.1, Tab.1). It simulates the generation of the target's point cloud under various detection conditions, accurately reproducing the spatial distribution and geometric features of the target. The model incorporates environmental factors such as lighting, noise, and system errors to ensure high-fidelity point cloud data generation (Fig.6, Tab.2). For the point cloud registration process, a dynamic matching weight factor and a nonlinear optimization objective function are proposed, enhancing matching accuracy and efficiency. The performance of the proposed method is compared with traditional Iterative Closest Point (ICP) and deep learning-based approaches. Additionally, an ablation study is conducted to evaluate the impact of different modules on the results.Results and DiscussionsThe proposed registration method shows a 25% improvement in matching accuracy over the ICP-based methods, and a 45% increase in matching efficiency compared to deep learning-based methods (Tab.3). The influence of various parameters, including the field of view and the array size, on point cloud sparsity and matching accuracy is explored (Tab.4, Tab.5). The results suggest that optimizing the FoV can balance precision and system complexity, while selecting an appropriate detector array size is essential for meeting both application needs and cost-effectiveness (Fig.10, Fig.12). Furthermore, the simulation model is demonstrated to provide reliable data for the optimization of lidar system design in space docking missions(Fig.3).ConclusionsThis study provides a robust simulation model and an efficient point cloud registration method for space station docking applications, especially in environments with sparse and noisy point clouds. The findings contribute to the development of high-precision, real-time lidar systems for space rendezvous and docking tasks. The proposed model and methods offer valuable insights for the design, optimization, and practical implementation of lidar systems in complex space exploration scenarios.
Aug. 25, 2025Vol. 54 Issue 8 20250134 (2025)
Simin LIN, Bin YUE, Xiaoya GUO, Jinxian FANG, and Mingjia SHANGGUAN
ObjectiveAs the second most significant greenhouse gas after carbon dioxide (CO2), methane (CH4) exhibits a 100-year global warming potential (GWP) 27.9 times greater than that of CO2. However, current methane monitoring technologies face limitations in spatiotemporal resolution and multi-parameter synchronization, hindering precise emission source identification. This study aims to advance the application of absorption spectroscopy-based spectral fitting inversion techniques for atmospheric CH4 detection, enabling simultaneous high-precision retrieval of methane column-averaged concentration ($ {X}~~{{\mathrm{C}}{{\mathrm{H}}}~~{4}} $), temperature (T), and water vapor concentration ($ {X}~~{{{\mathrm{H}}}~~{2}{\mathrm{O}}} $). The proposed system provides critical technical support for global methane emission monitoring and dynamic assessment of carbon neutrality progress.MethodsThe retrieval of methane concentration is critically dependent on precise temperature parameters. In differential absorption lidar (DIAL), a temperature deviation of 1 K results in approximately 14 ppb of methane concentration retrieval error (Fig.3). Leveraging the absorption spectral characteristics of CH4 at the 1645 nm band, we validated the feasibility of simultaneous temperature inversion using CH4 absorption spectra. By optimizing the methane absorption spectral model—combining a nine-peak Lorentzian profile with a binomial background (parameters of the nine absorption peaks detailed in Tab.1)—the fitting efficiency and accuracy were significantly enhanced. The number of fitting parameters was reduced from 30 to 6 key variables. The scanning strategy was further optimized, with the refined strategy illustrated in Fig.7(a),(b). Systematic errors of the nine-peak model were analyzed under diverse environmental conditions. Subsequently, numerical simulations established analytical relationships between retrieval error standard deviations, signal-to-noise ratio (SNR), and detection distance, offering theoretical guidance for experimental design and advancing high-precision atmospheric methane detection.Results and DiscussionsAfter optimization of the scanning strategy, the noise-free fitting results and residuals are shown in Fig.7(c),(d). Under diverse environmental conditions, the nine-peak model demonstrated robust performance, with retrieval deviations of $ {X}~~{{\mathrm{C}}{{\mathrm{H}}}~~{4}} $, T, and $ {X}~~{{{\mathrm{H}}}~~{2}{\mathrm{O}}} $ below 1 ppb, 0.6 K, and 0.05%, respectively. Backscattered signal spectra were generated under varying SNR and detection distances, with Poisson noise added to 100 independent datasets. The standard deviations of retrieved parameters were analyzed to derive analytical expressions for error distributions across optical path lengths and SNR (Fig.8). At an SNR of 104, retrieval errors within 1-10 km ranged below 7 ppb for $ {\Delta X}~~{{\mathrm{C}}{{\mathrm{H}}}~~{4}} $, 0.5 K for $ \Delta T $, and 0.01% for $ {\Delta X}~~{{{\mathrm{H}}}~~{2}{\mathrm{O}}} $ (Fig.9).ConclusionsThis study proposes a novel absorption spectroscopy-based lidar algorithm for simultaneous retrieval of atmospheric $ {X}~~{{\mathrm{C}}{{\mathrm{H}}}~~{4}} $, T, and $ {X}~~{{{\mathrm{H}}}~~{2}{\mathrm{O}}} $, demonstrating exceptional precision and stability across diverse environmental conditions and detection distances. The breakthrough enables revolutionary advancements in high-precision atmospheric methane detection and global carbon cycle research, with significant potential for long-term climate monitoring missions. This technology serves as a pivotal tool for supporting global methane mitigation commitments and optimizing carbon neutrality strategies.
Aug. 25, 2025Vol. 54 Issue 8 20250186 (2025)
Tianzhi WU, Shijie FU, Hongru ZHAO, Haichen XU, Chunpeng SHI, Quan SHENG, Wei SHI, and Jianquan YAO
Objective2.3 μm Tm-doped fiber lasers can be widely used in environmental gas detection, medical imaging, non-invasive blood glucose measurement and other fields. The 2.3 μm and 1.9 μm dual-wavelength laser cascaded amplification technology based on Tm-doped fiber can effectively suppress the amplified spontaneous emission and parasitic lasing in the 1.9 μm band, and achieve high-power 2.3 μm laser output. Further improvement of 2.3 μm fiber laser power significantly depends on the development of large mode area single-mode Tm-doped fiber. Traditional core-cladding structure optical fiber has difficulty maintaining single-mode operation when the core diameter increases, resulting in degradation of the beam quality in laser system based on large-mode-area fiber. All-solid anti-resonant fiber has attracted widespread attention due to its properties on large mode area single-mode operation, wide transmission bandwidth, and flexible structural parameter design. Active fiber realized by doping rare earth ions in the fiber core has potential application in high-power fiber laser generation. A large mode area single-mode Tm-doped all-solid anti-resonant fiber with a core diameter of 40 μm was designed based on tellurite glass, and a 2.3 μm and 1.9 μm cascade fiber amplifier based on this fiber was numerically simulated in this paper.MethodsComsol Multiphysics was used to build the fiber model, simulate fiber loss, get overlap integral, and design the anti-resonant fiber. Then, a numerical simulation model was built based on the rate equations of thulium ions and the power transmission equations of the amplifier, and was used in numerical simulation of the 1.9 μm and 2.3 μm dual-wavelength fiber amplifier based on the designed fiber.Results and DiscussionsBased on the mode coupling between the high-order modes and the cladding mode, an anti-resonant fiber with fundamental mode loss less than 1 dB/m, while the loss of all high-order modes greater than 10 dB/m in the 1.8-2.5 μm band was demonstrated (Fig.3). The comparison of 2.3 μm single-wavelength amplification and 1.9 μm and 2.3 μm dual-wavelength amplification shows that injecting 1.9 μm seed light into the amplifier can effectively suppress amplified spontaneous emission in the 1.9 μm band during 2.3 μm laser amplification (Fig.4). Signal laser in 2.3-2.4 μm band can be efficiently amplified (Fig.6). The slope efficiency of the dual-wavelength laser amplifier based on the designed fiber is about 30.6% for 1.9 μm signal, and about 23.6% for 2.3 μm signal with pump power of 100 W, and the 2.3 μm signal can be amplified from 2 W to 24.8 W (Fig.7).ConclusionsA single-mode Tm-doped tellurite all-solid anti-resonant fiber with core diameter of 40 μm is designed, which achieves a fundamental mode loss of less than 1 dB/m in the 1.8-2.5 μm band, and all high-order mode losses are greater than 10 dB/m, ensuring the single-mode transmission of signal light in the 1.9 μm and 2.3 μm bands. The numerical simulation of the 1.9 μm and 2.3 μm dual-wavelength fiber amplifier based on the designed fiber shows that the parasitic oscillation of the Tm-doped tellurite fiber amplifier in the 1.9 μm band can be effectively suppressed by only using 0.2 W of 1.9 μm seed light, and tens of watts of 2.3 μm laser amplification can be achieved. It can be indicated that the designed fiber would exhibit good laser amplification performance in the wide band range of 2.3-2.4 μm. The design process of the active all-solid antiresonant fiber proposed in this paper can be applied to the design of large mode area active fiber in other wavelength bands, which can serve as a reference for the design of large mode area single-mode fiber used in high-power fiber lasers and amplifiers.
Aug. 25, 2025Vol. 54 Issue 8 20250199 (2025)
Kunpeng SHI, Jiayi REN, Youqiang HAO, Dongdong HAN, Tiantian LI, and Zhanqiang HUI
ObjectiveFiber lasers based on the Dissipative Four-Wave Mixing (DFWM) effect possess advantages such as high output pulse repetition frequency, narrow pulse width, good beam directivity, and simple structure. They have demonstrated immense application potential in fields including fiber communication, optical sensing, precision metrology, and microwave photonics. However, traditional implementation schemes often rely on complex structures or high-cost devices. In response to this requirement, this paper proposes a low-cost solution based on novel two-dimensional NbTe2 nanosheets. By fabricating nonlinear photonic modulation devices and tunable Mach-Zehnder interferometer (MZI), the DFWM effect is achieved under low pump power. This not only provides a low-cost technical solution for the realization of high-repetition-frequency pulsed fiber lasers but also paves a new way for exploring the application of this material in the field of ultrafast photonics.MethodsThe NbTe2 nanosheets were prepared using the liquid-phase exfoliation method, and the closed-aperture Z-scan technique was employed to investigate their third-order nonlinear optical properties at a wavelength of 1550 nm. A nonlinear photonic modulation device was fabricated by combining the optical deposition method, and a MZI with adjustable arm length was designed as a comb filter through the combination of theoretical simulation and experimental verification. A ring-cavity erbium-doped fiber laser based on the above-mentioned devices was constructed. By leveraging the nonlinear optical properties of NbTe2 and the spectral regulation ability of the filter, high-repetition-rate laser pulse output based on the DFWM effect was achieved.Results and DiscussionsThe nonlinear optical properties of NbTe2 nanosheets were applied to a DFWM fiber laser, and high-repetition-rate pulses were successfully generated under low pump power. The innovative achievements include: 1) The Z-scan method was used to measure the nonlinear refractive index coefficient of NbTe2 nanosheets (at 1550 nm, the maximum value of n2 is 1.39×10-12 m2/W) (Fig.4). 2) Combining the tunable free spectral range (FSR) periodic filtering characteristics of the fiber MZI, a high-repetition-rate pulsed laser output based on the principle of DFWM was achieved (Fig.6). 3) By adjusting the optical delay difference between the two arms of the MZI, the repetition rate of the output laser pulses can be tuned. High-repetition-rate pulses with repetition rates of 80.6 GHz and 121.9 GHz were obtained respectively (Fig.10).ConclusionsBased on the fabricated NbTe2 nanosheet nonlinear photonic modulator and the MZI filter with tunable FSR, a ring-cavity erbium-doped fiber laser with tunable repetition rate was constructed based on the principle of DFWM. This provides a feasible and cost-effective technical solution for the realization of high-repetition-rate pulsed fiber lasers, and also opens up a new avenue for exploring the application of NbTe2 nanosheets in the field of ultrafast photonics.
Aug. 25, 2025Vol. 54 Issue 8 20250215 (2025)
Huaji WANG, Haodong XU, Wenguo CHEN, and Yushan DAI
ObjectiveLaser selective melting technology is widely used in various fields such as aerospace, aviation, ships, transportation, biomedicine, etc. due to its advantages of large forming freedom, high forming accuracy, and controllable surface roughness in the solid part forming process. Due to the large internal temperature gradient caused by the rapid melting and solidification process of materials under the action of the single laser beam, it is easy to result in uneven structural density, high porosity, high residual stress and poor surface quality of the formed parts. Therefore, referring to the current multi-beam laser selective melting technology that uses multiple mirrors to diverge multiple lasers for selective melting and forming, a multi-beam selective laser isometric follow-up scanning melting and forming strategy is proposed. This strategy regulates the dynamic state of the molten pool through the coordinated action of multiple beams along a certain motion trajectory and time interval. When the main beam performs melting scanning, auxiliary beams with a specific phase difference of each beam synchronize and follow, forming a controllable temporal and spatial superimposed energy distribution. The power of the auxiliary beam is set to 60% of that of the main beam. This simulation experiment takes TC4 titanium alloy as the research object and analyzes the thermal mechanical coupling results of laser path scanning under different time and space characteristics through numerical simulation. The feasibility of this strategy is verified and the changes in temperature field and stress field and their influencing factors in the actual forming process are predicted. The results showed that by controlling the space-time characteristics such as scanning path, phase difference and scanning rate of multiple beams, the residual stress in the isolated region decreased by about 20 MPa and the residual stress in the multi-beam synchronous re-scan node reached about 870 MPa. Under the change of spatial characteristic scanning strategy, the residual stress decreased to 760 MPa. Therefore, it can effectively reduce the cooling rate of metal materials, superimpose melting effects, fill gaps, improve structural density, improve surface quality and reduce residual stress.MethodsA multi-beam laser isometric follow-up scanning selective melting forming strategy is proposed. Based on the multi-beam selective laser melting technology (Fig.1), TC4 titanium alloy was selected as the research object and a finite element model is established(Fig.3). The selective laser melting forming and multi-beam Selective Laser melting forming methods are compared through numerical simulation and simulation experiments for analysis.(Fig.4) Temperature (Fig.5) and stress (Fig.6) were predicted, and the temperature field distribution and residual stress distribution in the joint area and isolated area under different forming strategies are compared. The residual stress and deformation in the joint area are controlled by optimizing the scanning strategy.Results and DiscussionsDue to multiple laser re-scans in the splicing area, the forming quality of the splicing area is poor. The cooling rate and temperature gradient of nodes within the isolated zone are not significantly affected by the scanning strategy. For the splicing area, compared with the basic scanning strategy, the cooling rate and temperature gradient are significantly reduced. In the same direction isometric follow-up scanning mode, using the spatial characteristic scanning strategy results in a larger space for heat transfer in the Y direction of the melt pool, leading to an increase in the cooling rate of the joint area. On the basis of temperature field analysis, the influence mechanism of stress evolution process in multi-beam laser melting forming under the scanning strategy of time and space characteristics was established and a method for controlling residual stress was proposed. Compared with the basic scanning strategy, in the inward (outward) symmetric equidistant follow-up scanning mode, the residual stress of the multi-beam synchronous re-scan node is as high as about 870 MPa. When using the spatial characteristic scanning strategy, the residual stress in the isolated area decreases by about 20 MPa(Fig.6). In the same direction isometric follow-up scanning mode, changing the spatial and temporal characteristics separately does not have a significant effect on the residual stress changes in the joint area.ConclusionsBy controlling the space-time characteristics such as scanning path, phase difference, and scanning rate of multiple beams, the residual stress in the isolated region decreased by about 20 MPa. Under changing the spatial characteristic scanning strategy, the residual stress decreased to 760 MPa. On the basis of using mature process parameters, the quality of the formed parts can be improved by optimizing the scanning strategy. By selecting the space-time characteristic scanning strategy between multiple beams, the residual stress in the joint area can be reduced while controlling the residual stress in the isolated area within a certain range.
Aug. 25, 2025Vol. 54 Issue 8 20250301 (2025)
[in Chinese], Ming LI, Shengzhi XU, and Huimin CHEN
Significance Continuous-variable quantum key distribution (CV-QKD) has emerged as a prominent research focus in quantum communication, owing to its cost-effectiveness and compatibility with existing optical infrastructure. Nevertheless, achieving efficient data reconciliation under low signal-to-noise ratio (SNR) conditions remains a critical challenge impeding its widespread deployment. Low-density parity-check (LDPC) codes, recognized as a state-of-the-art error correction technique, have demonstrated significant potential for enhancing post-processing efficiency in CV-QKD systems. Leveraging their sparse parity-check matrix structure and iterative belief propagation decoding, LDPC codes enable robust error correction during quantum signal transmission, thereby optimizing the reconciliation process. This comprehensive review systematically examines recent advancements in LDPC code applications for both fiber-optic and free-space CV-QKD systems. The review analyzes key developments in code design, decoding algorithms, and implementation strategies that have contributed to improved reconciliation performance. Furthermore, The study identify promising research directions that could address current limitations and facilitate the transition of CV-QKD technology from experimental demonstrations to practical commercial applications.Progress The evolution of LDPC codes in CV-QKD reconciliation can be categorized into three transformative phases. Initially, traditional LDPC codes demonstrated promising results, achieving reconciliation efficiencies of up to 88.7% at an SNR of 1.76 dB. However, their performance degraded significantly in ultra-low SNR regimes (<0.1 dB), limiting their applicability for long-distance quantum communication. The second phase marked a breakthrough with the introduction of multi-edge-type (MET) LDPC codes, which exhibited superior performance in low-SNR conditions. These codes achieved remarkable reconciliation efficiencies of 96.9% at an SNR of 0.029 dB, enabling secure key distribution over distances extending to 140 km. Further enhancements were realized through GPU-accelerated quasi-cyclic MET-LDPC (QC-MET-LDPC) variants, which pushed reconciliation efficiencies close to 99% while maintaining high processing speeds. For free-space CV-QKD systems, the dynamic and unpredictable nature of atmospheric turbulence poses additional challenges. Adaptive-rate LDPC codes have been developed to mitigate these effects, dynamically adjusting code rates in response to fluctuating channel conditions. These adaptive schemes have demonstrated significant improvements, boosting key rates by 87.5 kbit/s in experimental settings. Moreover, the integration of type-based-protograph (TBP) LDPC codes with high-dimensional reconciliation techniques has further enhanced performance, increasing secure key rates by up to 165% compared to traditional methods.Conclusions and Prospects LDPC codes have firmly established themselves as the foundational technology for achieving high-efficiency reconciliation in CV-QKD systems. The development of MET-LDPC codes and structured variants such as QC-MET and TBP LDPC codes has demonstrated transformative capabilities, delivering near-optimal reconciliation efficiencies (>96%) even in challenging low-SNR conditions (<0.03 dB). These advancements have been instrumental in extending secure transmission distances beyond 140 km in fiber-based systems while maintaining robust performance in turbulent free-space channels. Moving forward, five key research directions is critical for future development: 1) Innovative LDPC architectures, such as hybrid Quasi-Cyclic Accumulate-Repeat-Accumulate (QC-ARA) designs, to bridge the efficiency gap in ultra-low-SNR regimes (<0.01 dB); 2) Dynamic adaptation mechanisms leveraging machine learning for real-time optimization under channel fluctuations; 3) Hardware-algorithm co-design, aiming for high-throughput (>1 Gbps) FPGA/ASIC implementations with improved energy efficiency; 4) Cross-layer integration strategies that unify LDPC optimization with discrete modulation and post-processing to maximize end-to-end key rates; and 5) Synergy between quantum-classical network architectures, including quantum repeaters and measurement-device-independent protocols, to enhance scalability and practicality. To overcome these challenges, researchers must focus on optimizing LDPC code performance, developing adaptive reconciliation protocols, and improving hardware implementations. These advancements will enable the transition from experimental CV-QKD systems to practical, high-speed quantum networks, establishing LDPC codes as essential components of future-proof cryptographic infrastructure.
Aug. 25, 2025Vol. 54 Issue 8 20250226 (2025)
Xiaowei WU, Zhanhu WANG, Juan DUAN, and Lei DING
ObjectiveTo obtain an ideal interference pattern using an interferometer with a planar mirror structure, the moving mirror and the fixed mirror of the instrument are required to be conjugate to each other through the beam splitter in theory. However, a series of factors, such as changes in ambient temperature, vibration during transportation, shock environment during satellite launch, vibration interference from satellite platform may cause the tilt of fixed mirror relative to moving mirror, as a result, the performance of the interference spectrometer in orbit may degrade or even become unusable. Therefore, there is an urgent need for a calibration method to correct the collimation deviation of the instrument after its entry into orbit and to restore its performance.MethodsIn this paper, a calibration system based on the attitude adjustment of the fixed mirror for interferometric spectrometers, which can be applied in space is designed and established. The system is primarily composed of interference signal acquisition unit, interference signal sampling unit, calibration controller, fixed mirror driving mechanism, moving mirror driving mechanism. This system is characterized by a large adjustment range, strong adaptability, and high reliability. Based on the peak-to-peak amplitude of the infrared interferogram, the attitude of the fixed mirror is adjusted to achieve optimal collimation and restore the performance of the instrument using ether command-control mode between the satellite and the ground or automatic-control mode.Results and DiscussionsDuring the ground vacuum environment calibration tests of the interferometric spectrometer, both the remote-command-control mode calibration and the automatic-control mode calibration functions were tested. The peak-to-peak values of the interference signals and the instrument performance were evaluated after calibration using these two methods, The results indicate that the deviation in peak-to-peak values does not exceed 2%, and the NEDT is essentially consistent, which meets the design specifications of the instrument (Fig.9). The on-orbit calibration was performed for the HIRAS of FY-3F satellite, which utilizes this system. After calibration, the NEDT and the spectral responsivity of the instrument were significantly recovered. The average NEdT across the entire detection band decreased by 0.15 K, the spectral responsivity in the long-wave band improved by 3%, and the spectral responsivity in the two mid-wave bands improved by 7% and 15%, respectively. The instrument's performance meets the design specifications (Fig.10).ConclusionsThe results from ground tests and on-orbit practical applications demonstrate that the calibration system can restore the instrument's misalignment within the designed adjustment range of 4500 μrad. The deviation in the peak-to-peak values of the infrared interference signals between the remote-command mode calibration and the automatic mode calibration does not exceed 2%. After calibration, the instrument's performance improved significantly. This system has achieved the first domestic correction of misalignment for on-orbit interferometric spectrometers and has been applied to multiple on-orbit interferometric spectrometers. Its development provides reliable support for ensuring that interferometric spectrometers can continue to operate with high performance under various adverse conditions.
Aug. 25, 2025Vol. 54 Issue 8 20250140 (2025)
Huitian ZOU, Mingxu PIAO, Xian ZHANG, Yingran TONG, Haoran WANG, Yichen LOU, and Hongmei JIANG
ObjectiveIn traditional optical systems, increasing the number of lenses is usually used to improve the imaging quality of the system, but it will also lead to a substantial increase in the size, weight and cost of the optical system. To reduce the weight and volume of the optical system and expand their application range, single-element imaging has become an important direction for lightweight optical systems. Currently, single-element imaging components, such as metalenses and Fresnel zone plates (FZPs), face challenges for widespread adoption due to low diffraction efficiency, manufacturing difficulties, and performance limitations. Compared with traditional element imaging, diffractive elements offer advantages such as greater design freedom, unique dispersion characteristics, ease of fabrication, and a wider material selection.However, at the same time, the application of diffraction elements in the wide band will cause background blurring due to diffraction efficiency issues, and the unique dispersion characteristics will cause severe chromatic aberration. These are all critical issues that degrade the imaging quality. Therefore, in order to solve the above problems, this paper studies the design of optical system for larger bands, the establishment of a higher-accuracy image degradation models, the use of computational imaging technology to mitigate the degradation caused by the low efficiency diffraction of a single diffraction element, and correct the chromatic aberration. Furthermore, their impact on imaging can be compensated for through computational imaging techniques.MethodsTo achieve miniaturization and lightweighting in optical systems, a design method of the CSDOE (Computational Single-layer Diffractive Optical Element) is proposed. The optimization of the CSDOE is realized by using the relationship between the thickness, the diffraction phase coefficient and the chromatic aberration of the CSDOE (Fig.1). A computational imaging method (Fig.3) is introduced to correct the chromatic aberration. The diffraction efficiency energy distribution matrix model is established by using the equivalent diffraction efficiency method, the cross-channel similarity model is established by using the similarity relationship between color channels, and the PSF (point spread function) model at the pupil is constructed by using the generalized pupil function. Combined with the above three models, a higher-accuracy image degradation function model is constructed. Through this model, an optimized iterative algorithm is established to restore the blurred color images and improve the imaging quality. And the effect of the method is verified by a design example (Fig.4). Four evaluation methods are used to compare the processed image with the blurred image.Results and DiscussionsA CSDOE imaging system with a focal length of 50 mm, F value of 5 and field of view of 3° is designed, and its RMS value is 23.367 μm. Wide-band imaging was simulated using optical software (Fig.11(a)). In this paper, a high-accuracy PSF function model is constructed to mitigate the influence of diffraction efficiency and chromatic aberration, and the color image is restored (Fig.11(b)). In addition, the CSDOE imaging system was experimentally implemented (Fig.12), and captured images were restored by the model (Fig.13), which verified the feasibility of the CSDOE design method under theoretical simulation and physical tests.ConclusionsThe CSDOE with focal length of 50 mm, F number of 5 and field of view of 3° is simulated and verified. Four evaluation methods are used to compare the processed image with the blurred image. Specifically, contrast increased by 39, gray value gradient increased by 0.5696, and standard deviation increased by 20.6064. In the actual test, contrast increased by 32, gray value gradient increased by 1.3049, and standard deviation increased by 1.2725. The contrast, gray value gradient and standard deviation of the image are increased by 17%, 22.2%, 21.7% and 17.6%, 41.1% and 10.3% respectively in simulation and actual test. In addition, in the actual test, the NIQE was reduced by 0.8902, making the image more natural overall. This paper describes an imaging system that utilizes computational imaging to eliminate the effects of chromatic aberration and diffraction efficiency on image quality, and provides new insights into the integration and miniaturization of optical systems.
Aug. 25, 2025Vol. 54 Issue 8 20250200 (2025)
Yang YANG, Gaoyong LU, Hongran ZENG, and Xiaowei LI
ObjectiveIntegral imaging, compared to other naked-eye 3D imaging techniques, offers significant advantages such as full parallax, true color, pseudo-continuous light field display, lightweight design, and cost efficiency. However, with the growing adoption of integral imaging in applications like remote healthcare, education, and data visualization, the security of 3D light field data during transmission and storage has become a pressing concern, as unauthorized tampering or leakage could lead to privacy breaches or economic losses. Existing steganographic methods for integral imaging primarily focus on robust watermarking for image sourcing, lacking functionalities for authenticity verification and tampering detection. This research aims to fill this gap by introducing a tampering detection approach that not only ensures the integrity of received images but also supports accurate decision-making based on the embedded content. Successfully implementing this technique will enhance the security and reliability of integral imaging applications, fostering broader adoption across critical fields, such as battlefield situation awareness, remote healthcare, and intelligent education. For this purpose, a multifunctional three-dimensional optical information hiding technology based on integral imaging and light field saliency is designed in this paper.MethodsSteganography with different modalities and functionalities was performed on integral imaging in this paper. The algorithm implements three functions based on the significance of different regions of the 3D light field, providing a foundational reference framework for multilayer steganographic techniques targeting naked-eye 3D images. By combining elemental image sequences and neural networks, the algorithm achieved pixelwise extraction of regions of interest (ROI) and regions of non-interest (RONI) for light field 3D objects, significantly improving the precision of saliency extraction in 3D space (Fig.2, Fig.6). For the irregular spatial distribution of ROIs in light field 3D objects, a histogram-based fragile steganography algorithm instead of those based on two-dimension energy concentration was proposed, which defines embedding strength according to varying saliency levels within the ROI to balance invisibility and watermark sensitivity (Fig.3, Fig.9). Additionally, multi-logo fused multi-depth light field images were used as robust watermarks for RONI steganography, enhancing the robustness of the watermark under various attacks and its concealment within the host (Fig.10).Results and DiscussionsExperimental results show that the structural similarity index (SSIM) of the embedded ROI and RONI averages above 0.99 (Fig.7-Fig.8), with the ROI achieving a tampering character error rate exceeding 96% under six attacks (Fig.9), and the robust watermarks extracted in the RONI achieving an average SSIM of 0.7 compared to the original watermark (Fig.10). The results demonstrate that the proposed multifunctional three-dimensional optical information hiding technique achieves desirable invisibility, sensitivity, and robustness.ConclusionsThis study proposes a multifunctional three-dimensional optical information hiding technique for integral imaging, leveraging its spatial and angular characteristics in combination with light field saliency extraction. First, the method integrates elemental image sequence with neural networks to extract 3D ROI and RONI characterized by multi-depth and continuous viewpoint transformation features. Then, a saliency histogram of the ROI is utilized to embed textual data as fragile watermarks in a pseudo-continuous manner. Multiple logo patterns are fused into multi-depth virtual light fields to construct multi-logo-multi-depth-watermark, embedded into the RONI. This approach enables users to verify whether the image has been tampered with based on the embedded textual data and interpret the naked-eye 3D image more accurately using the embedded reports. Additionally, robust watermarks embedded across multiple depths ensure image sourcing of the 3D light field image. Experimental results show that this approach offers high invisibility and both authenticity and integrity of information, paving a way for omnidirectional and multi-insurance steganography for 3D light field imaging.
Aug. 25, 2025Vol. 54 Issue 8 20250001 (2025)
Xiaolong HE, Feipeng DA, and Shaoyan GAI
ObjectiveThe rapid advancement of virtual human technology and 3D face reconstruction has led to its wide application in virtual characters, film production, and human-computer interaction. However, traditional single-modal approaches, such as image- or audio-driven models, often struggle to capture rich emotional details and maintain temporal consistency in dynamic expressions. To address these challenges, this research proposes a novel multi-modal facial expression encoder that integrates image, text, and audio modalities to enhance the accuracy, naturalness, and emotional consistency of 3D facial expression generation in both static and dynamic scenarios.MethodsThe proposed method introduces a multi-modal facial expression encoding approach that leverages the complementary strengths of image, text, and audio modalities (Fig.2). The image modality captures visual facial features, while the text modality provides semantic cues via predefined descriptors, and the audio modality refines temporal dynamics by modulating the image-text similarity. Initially, an image–text feature extraction module regresses facial expression and pose parameters, followed by dynamic adjustment of text-driven features based on their relevance to the visual data. In the final stage, audio features guide the expression synthesis through cross-modal attention, aligning visual expressions with the emotional content of the audio (Fig.3). Additionally, a temporal modeling module captures sequential dependencies between frames, ensuring smooth transitions and consistent emotional expression over time (Fig.4). This integration of multi-modal fusion and temporal modeling yields natural, expressive, and temporally coherent 3D facial animations.Results and DiscussionsThe experimental results confirm the effectiveness of the proposed method. In static 3D face reconstruction, the integration of text and image modalities leads to high emotional consistency (Fig.6) and improved expression and pose regression precision (Tab.3). When audio is incorporated, the method generates dynamic expressions with enhanced emotional consistency and visual quality, outperforming existing approaches in both static and dynamic scenarios (Tab.4, Fig.7). Moreover, the temporal modeling module guarantees smooth transitions between frames, resulting in a more natural sequence of expressions.ConclusionsThis study introduces a novel multi-modal facial expression encoder that fuses image, text, and audio modalities to enhance the accuracy, naturalness, and emotional consistency of 3D face reconstruction. The model effectively captures both static and dynamic expressions, addressing limitations of single-modal methods. By integrating cross-modal attention and temporal modeling, it generates realistic and emotionally expressive 3D facial animations, demonstrating the potential of multi-modal fusion in virtual humans, film production, and human-computer interaction. Future work may incorporate additional modalities like gesture or contextual information to further improve realism and expressiveness.
Aug. 25, 2025Vol. 54 Issue 8 20250129 (2025)
Method and validation in second near-infrared window for multi-scale fluorescence intravital imaging
Chenglei YE, Zhiping HE, Xuehan WANG, and Aijun JIN
ObjectiveWith the rapid development of life sciences and biotechnology, the demand for observing the structure and function of living organisms has been increasing. Common imaging methods such as nuclear imaging, magnetic resonance imaging, and computed tomography have been unable to accurately and continuously monitor living organisms due to issues such as radiation and expensive equipment. Although slice detection is highly accurate, it cannot directly observe living organisms. Fluorescence imaging works by marking specific molecules within cells or body fluids with fluorescent probes, making the fluorescence signal much stronger than the organism's own luminescence, thereby enabling the observation and measurement of target tissues. However, current fluorescence in vivo imaging instruments mainly focus on single-scale detection. If multi-scale in vivo detection that combines macroscopic and microscopic scales can be achieved, it will have significant implications for the rapid detection of human diseases.MethodsNear-infrared II (NIR-II, 900-1880 nm) based in vivo fluorescence imaging technology is currently a cutting-edge in vivo biological imaging technique, which offers a deeper tissue penetration depth. This method first genetically induces live laboratory rat to become fluorescent live laboratory rat through the iRFP713 fluorescent protein. To locate the diseased organs, the laboratory rat can be placed under the macroscopic imaging function module for observation. After analyzing and identifying the target area of interest, the live animal is pushed into the microscopic imaging function module for microscopic observation. Through scanning and image stitching, a full-field microscopic image is obtained. Additionally, by traversing and photographing the microscopic images and then using image stitching, a full-field microscopic image can be synthesized, thereby achieving non-invasive and rapid detection of live animals.Results and DiscussionsThe experiments of macroscopical imaging and microscopical imaging in living laboratory rat were carried out by using multi-scale NIR-II fluorescence imaging method. Macroscopic: Figure 3(a) shows live laboratory rat without fluorescent liver. At this time, the camera exposure time is 250 ms, and the laser power is 150 mW. Figure 3(b) shows live laboratory rat with fluorescent liver. At this time, the camera exposure time is 90 ms and the laser power is 150 mW. It can be seen that the liver in vivo showed a relatively complete state under the observation of this system, especially the concave flap structure in the middle of the liver. Microscopic: Scanning and photographing in Z-shape step by step with the lens, 180 images were obtained. As shown in Figure 3(d), 180 images were spliced and the microscopic global image of the liver was shown in Figure 3(e). The approximate location of the liver in the laboratory rat is shown in Figure 3(f). Objects of different scales can be clearly identified, and the function of the system meets the needs of multi-scale imaging.ConclusionsTo address the scale limitation of existing NIR-II fluorescence imaging instruments to a single scale, this paper proposes a multi-scale NIR-II fluorescence in vivo imaging method and develops an experimental verification device to verify the feasibility of the method. The method is as follows: We take the liver of an experimental laboratory rat as the observation object. First, we conduct macroscopic observation of the live laboratory rat to obtain a large field-of-view image and identify the organ with lesions. To obtain further information about the lesion, we then perform microscopic in vivo imaging of the organ to obtain microscopic images of the lesion organ in the live experimental laboratory rat. By stitching the images, we can obtain an image data set with higher information density than macroscopic in vivo imaging, facilitating the subsequent collection of specific lesion information. The multi-scale imaging system we built has a large imaging field-of-view and high imaging resolution. The macroscopic imaging field-of-view can reach 192 mm × 154 mm, with a resolution of 300 μm; the microscopic imaging range can reach 3.2 mm × 2.56 mm (5× objective lens), 0.8 mm × 0.64 mm (20× objective lens), with a resolution of 5 μm (5× objective lens)/1.25 μm (20× objective lens). The final experimental image data show that under the macroscopic imaging function, the fluorescent liver of the live laboratory rat can be clearly imaged, and the macroscopic contour of the liver can be distinguished; under the microscopic imaging function, the details inside the liver can be observed, and microscopic whole-field imaging can be achieved by using image stitching technology.
Aug. 25, 2025Vol. 54 Issue 8 20250136 (2025)
Long WANG, Jian ZHOU, Yaoyun CAO, Fangfang WANG, Xiangxiao YING, Shouhai TANG, Lingfang WANG, Yunmeng LIU, Yi ZHOU, and Jianxin CHEN
Objective Due to the process defects of the micro-polarizer array and the matching error between the polarizer array and the focal plane array, the polarization modulation of the incident light with the same intensity and the same polarization direction is different, resulting in more blind pixels and more serious non-uniformity problems in the polarization integrated imaging system. Due to the influence of blind pixels and non-uniformity, infrared images will introduce noise, information loss and error increase. Therefore, the data preprocessing of polarization integrated detection system is particularly important.Methods In this paper, the linear response model of the polarization detector is established. On the basis of the response correction, the parameters of the micro-polarizer are calibrated, and the polarization correction of the incident radiation is realized. A blind pixel detection method based on nonlinear least squares fitting Marius curve is proposed. The standard curves of each channel are calibrated. Using the curve deviation and fitting parameters, the simultaneous detection of response blind pixel and polarization blind pixel is achieved.Results and Discussions The self-developed mid-wave infrared polarization integrated detector is used for experimental verification. The correction results show that the non-uniformity after polarization correction is reduced by 98.14% and 40.46% respectively compared with the original data and response correction data. 563 response blind pixels and 86 polarization blind pixels are detected. The imaging results show that the blind pixel recognition of this method is accurate, while the national standard method has the problem of blind pixel missed detection. The corrected polarization information can highlight the target contour of the imaging scene. The problem of the original data of the detector is effectively solved, which provides a reference for the data processing and polarization imaging quality improvement of the polarization integrated detector.Conclusions This paper first analyzes the classification and causes of blind pixels. Due to the limitations of traditional detection methods and the influence of focal plane inhomogeneity, it is impossible to accurately determine the response blind pixels and polarization blind pixels. On the basis of non-uniformity correction, a nonlinear least squares fitting Marius response curve is proposed, and blind pixel detection is realized by means of curve deviation and fitting parameters. The experimental verification was carried out based on the polarization integrated detector developed by our research group. There are 563 response blind pixels detected by curve deviation and 86 polarization blind pixels detected by fitting parameters. The results show that the method in this paper can detect blind pixels more accurately than the national standard method, and reduce missed detection to a certain extent. Finally, the blind pixel compensation and imaging work are carried out. The imaging results show that the polarization imaging can better highlight the edge contour contrast of the target. The data preprocessing method of polarization integrated infrared detector in this paper can provide reference for subsequent high-quality polarization imaging detection.
Aug. 25, 2025Vol. 54 Issue 8 20250149 (2025)
Binghui LI, Zhilong YE, Xuwei ZHANG, Xunjiang ZHENG, and Jianling SUN
ObjectiveAs a high-precision attitude measurement device, star sensors are widely used to determine the attitude of spacecraft in space. With advancements in detection technology, all-day star sensors have been applied to atmospheric platforms such as aircraft, vehicles, and ships. However, their performance is constrained by the low signal-to-noise ratio (SNR) of faint stars under daylight backgrounds. Traditional single-frame threshold segmentation struggles to extract faint stars, while existing multi-frame adding alignment methods mostly rely on external gyroscope attitude information, which is affected by gyroscope drift errors and is unsuitable for long-duration adding. Additionally, inter-frame image transformation models often use approximate models, introducing systematic errors that lead to insufficient alignment accuracy under large attitude changes, resulting in limited SNR improvement. This paper proposes a multi-frame adding method based on inter-image correlation, establishing an unbiased inter-frame image transformation model to optimize alignment accuracy and significantly enhance the extraction capability of faint stars.MethodsThis method initially extracts a small number of star points from a single frame and then utilizes prior information to rapidly extract visible star points from adjacent frames using a tracking gate. It establishes inter-frame correlations and calculates the relative attitude changes of the star tracker between frames based on the star vector information of correlated star points. The method then reprojects these points onto the current frame's image plane based on this relative attitude, achieving unbiased transformation of inter-frame star images. These star images are then streamed and recursively added to enhance the signal-to-noise ratio (SNR) of the star points. Finally, threshold segmentation is used for coarse extraction, and Gaussian surface fitting is employed for precise localization.Results and DiscussionsThe simulation analysis demonstrates that the alignment error of the traditional rigid-body transformation and affine transformation models generally increases with the augmentation of the attitude transformation angle when superimposing faint stellar points (Fig.6). Under a 3° attitude variation, the systematic error of the traditional rigid-body transformation and affine transformation models exceeds 5 pixels across a large area (Fig.5). This error prevents the energy of faint stellar points from concentrating, thereby hindering the effectiveness of the superimposition enhancement. In contrast, the attitude projection model proposed in this study does not exhibit such systematic errors. The sequence star image superposition experiments reveal that the proposed method can effectively extract faint stellar points that are invisible in a single frame. The superimposed faint stellar points exhibit complete morphology without any trailing effects (Fig.9), and their central positions align with the theoretical positions, indicating that the method can avoid alignment errors during the superposition process of faint stellar points in image transformation. Compared to the traditional rigid-body transformation and affine transformation models, the proposed method extracts a greater number of faint stellar points, demonstrates enhanced detection capability, and achieves signal-to-noise ratio improvements of 85.0% and 118.5%, respectively. Additionally, the positioning errors are reduced by 89.4% and 77.9%, respectively.ConclusionsThis paper addresses the issue of stellar point alignment errors in traditional multi-frame superposition methods for all-day star sensors under dynamic conditions by proposing a novel multi-frame superposition method based on image autocorrelation. By establishing precise correspondence relationships of stellar points between adjacent frames, the relative attitude changes of the star sensor are determined, and an unbiased transformation of the star map is achieved based on the spatial projection model of the camera. This approach fundamentally eliminates the systematic biases introduced by traditional approximate models such as rigid-body transformation and affine transformation. The proposed method significantly reduces alignment errors during transformation, effectively enhances the signal-to-noise ratio of stellar points, improves the capability to extract faint stellar points, and markedly increases positioning accuracy. This method effectively resolves the application limitations caused by model errors and external dependencies in traditional multi-frame accumulation techniques, providing both theoretical support and engineering practice solutions for the autonomous attitude determination capability of all-day star sensors in highly dynamic environments.
Aug. 25, 2025Vol. 54 Issue 8 20250184 (2025)
Zifen HE, Qigang WANG, Yinhui ZHANG, Ying HUANG, Wei PENG, and Guangchen CHEN
ObjectiveUAVs equipped with infrared cameras can efficiently acquire and continuously track ground targets without being detected. Aiming at the problems of blurring of image contour caused by long distance in UAV infrared imaging and degradation of segmentation accuracy due to changes in target scale, this paper proposes a segmentation model of UAV infrared target instances with dynamic feature aggregation and multilevel synergy.MethodsA dynamic feature aggregation and multilevel perception UAV infrared target instance segmentation model-DFANet is proposed on the basis of YOLOv8n algorithm (Fig.1) in this paper. Firstly, the standard convolution in the network backbone is replaced with a regional feature adaptive convolution module (Fig.2), which enhances the benefit of feature extraction. Secondly, the original up-sampling module is replaced with a redesigned feature-aware reorganized up-sampling module (Fig.3) to better extract the infrared image target edge feature information; finally, a multi-scale context-aggregated feature extraction module is embedded in the backbone network to reduce the effect of target scale variation (Fig.4).Results and DiscussionsIn order to evaluate the segmentation performance of the proposed network model, various metrics such as mAP50, mAP50-95, size, GFLOPs and inference time are used in this paper for a comprehensive comparison. The ablation study in Table 2 shows that the average segmentation accuracy of the improved IR target segmentation model increases from 67.6% to 78.4% and the inference time slightly increases from 5.5 ms to 10.8 ms. The comparison experiments in Tables 3 and 4 comparing the proposed module with other modules of the same type show that our proposed module has better results for infrared target instance segmentation. Finally, the comparison experiments of different networks in Table 5 illustrate that the improved model outperforms the current state-of-the-art networks yolov11n and YOLOV12n in terms of segmentation accuracy.ConclusionsThis study proposes a dynamic feature aggregation and multilevel synergistic UAV infrared target instance segmentation model, targeting the challenges of missing target details in infrared imaging and low accuracy of multi-scale target recognition, and realizing performance breakthroughs through three core innovations: designing a regional feature adaptive convolution module, based on the spatial attention-guided dynamic weight allocation strategy, to enhance the feature focusing ability on the target's key regions; constructing a feature-aware restructuring up-sampling module, which realizes efficient reconstruction of high-resolution features through content-driven dynamic kernel generation and local affine transformation; and the development of a multi-scale context aggregation module, which fuses cavity convolution and feature pyramid structure to capture cross-level contextual dependencies. Experiments on the aerial infrared vehicle dataset show that DFANet achieves mAP50 78.4% and mAP50-95 51.1%, which improves the segmentation accuracy by 9.7% and 5.6% respectively compared to the benchmark model, and achieves the comprehensive optimal result in experimental comparison with other mainstream instance segmentation networks.
Aug. 25, 2025Vol. 54 Issue 8 20250209 (2025)
Rui YAO, Kai WANG, Haofan GUO, Wentao HU, and Xiangrui TIAN
ObjectiveThe goal of infrared and visible light image fusion is to amalgamate image data from disparate sensors into a unified representation that preserves the complementary information and salient features inherent to both modalities. The autoencoder framework offers significant advantages in imagine fusion, whose encoder can efficiently extract image features, and decoder can precisely reconstruct the image. Moreover, by introducing mechanisms such as attention, the issues of detail loss and information retention can be effectively addressed. However, existing fusion methods still have many shortcomings: 1) Conventional autoencoder frameworks struggle to effectively learn deep features, leading to gradient vanishing issues during the image reconstruction process; 2) In low-light conditions, existing algorithms are frequently impeded by the suboptimal quality of visible light images, which significantly degrades the overall fusion quality; 3) Existing deep learning-based algorithms are often computationally intensive, thus being unsuitable for real-time applications. Therefore, a novel infrared and visible light image fusion algorithm based on Cross-modal Feature Interaction and Multi-scale Reconstruction, CFIMRFusion, has been proposed.MethodsThe proposed algorithm comprises four key components: a convolutional attention enhancement module, an encoder network, a cross-modal feature interaction fusion module, and a decoder network based on multi-scale reconstruction (Fig.1). The convolutional attention enhancement module extracts features through convolutional operations, and enhances the contrast and texture visibility of degraded visible light images, thereby enhancing the detailed features of the images. The encoder module employs convolutions to extract deep features from both infrared images and the enhanced visible light images. To fully leverage the multi-modal features of infrared and visible light images, a cross-modal feature interaction fusion module has been developed, which performs complementary fusion on infrared and visible light image via a channel-spatial attention mechanism. Additionally, considering that the encoder structure with direct connections is prone to feature vanishing during training, a decoder network based on multi-scale reconstruction has been developed, where fused features extracted by encoders at different levels are skip-connected to the decoder network.Results and DiscussionsIn the objective analysis of the proposed algorithm compared with GANMcC, SwinFuse, U2Fusion, LapH, MUFusion, CMRFusion, and TUFusion, the proposed algorithm obtained six optimal values and one suboptimal value on the TNO dataset (Tab.2) and LLVIP dataset (Tab.3), three optimal values and four sub-optimal values are obtained on the MSRS data set (Tab.4). The subjective evaluations on TNO, LLVIP, and MSRS datasets are shown in Fig.3-Fig.5 respectively. The fused images exhibit superior detail features and overall visual effects compared with the benchmark algorithms. Moreover, the fusion speed is 24.1%, 23.86% and 25.2% of the fastest comparison algorithm respectively.ConclusionsA novel infrared and visible light image fusion algorithm based on cross-modal feature interaction and multi-scale reconstruction, CFIMRFusion, has been developed, to enhance information acquisition in low-light conditions and produce fused images with clear details and improved visual effects. Initially, the degraded visible light image is fed into a convolutional attention enhancement module to obtain enhanced features. Subsequently, the enhanced visible light image and the infrared image are fed an autoencoder network to extract multi-scale features, which are then complementarily fused via a cross-modal feature interaction fusion module. Finally, a decoder network based on multi-scale reconstruction is employed to generate the fused image with rich details and clear structures. Experimental results indicate that, compared to the optimal comparison algorithm, the fused images of CFIMRFusion achieved 15.8% and 18.2% increase in average gradient and edge intensity, respectively, on the TNO dataset; 11.5% and 9.5% increase in mutual information and standard deviation on the LLVIP dataset; and 10.1% increase in edge intensity in the MSRS dataset. Moreover, ablation studies further demonstrate the effectiveness of each module in the algorithm, where the complete model outperforms partial module combinations in terms of AG, EI, SD, SF, and VIF metrics. Regarding computational efficiency, the proposed CFIMRFusion algorithm achieves the shortest average runtime and is thus capable of satisfying the real-time requirements of applications in low-light scenarios with high temporal constraints.
Aug. 25, 2025Vol. 54 Issue 8 20250210 (2025)
Zhongmin LIU, Yang LIU, and Wenjin HU
ObjectiveDunhuang mural restoration is a vital task in preserving cultural heritage, yet it faces significant challenges due to the intrinsic complex degradation patterns of these ancient artworks. The murals often exhibit multi-scale cracks, localized missing regions, and chromatic fading, which not only obscure the subtle textures and structural details but also make it extremely difficult to balance high-fidelity restoration with computational efficiency. Existing methods, constrained by quadratic computational complexity and susceptible to interference from irrelevant features, perform inadequately when dealing with high-resolution murals with intricate structural details. To address these challenges, this study proposes a joint gated attention and residual dense Transformer model (MGRT) specifically designed for mural inpainting. This approach aims to: 1) significantly reduce the quadratic complexity of traditional attention mechanisms while preserving essential global feature interactions; 2) effectively mitigate the interference of invalid features during restoration through adaptive gating; and 3) enhance structural coherence via hierarchical feature fusion.MethodsIn this paper, a novel framework is proposed that integrates three key components. First, a Focused Linear Attention Module (FLAM) is introduced to replace the conventional Softmax attention mechanism. By approximating the exponential operations using a first-order Taylor series expansion, FLAM achieves linear computational scaling while accurately modeling long-range dependencies. Second, a joint gated attention mechanism is incorporated that fuses spatial-channel gating with mask-aware positional encoding. This mechanism dynamically suppresses irrelevant features and amplifies critical structural and textural cues in damaged regions. Third, a Residual Dense Transformer Block (RDTB) is seamlessly embedded within a U-Net architecture to establish cross-scale feature propagation pathways through densely connected self-attention layers, enabling the progressive refinement of intricate mural details. Together, these components deliver enhanced computational efficiency and restoration quality, providing a robust solution for high-fidelity mural inpainting.Results and DiscussionsExtensive experiments on the Dunhuang mural dataset demonstrate the significant advantages of the proposed method, with similarly promising results observed on the FFHQ dataset (Fig.8). Quantitative evaluations reveal that our approach outperforms the compared methods in both subjective and objective assessments. Specifically, ablation studies confirm that the model improves the Structural Similarity Index (SSIM) by 0.001 to 0.012, increases the Peak Signal-to-Noise Ratio (PSNR) by 0.053 to 0.215 dB compared to baseline algorithms, reduces the L1 error by 0.001 to 0.007, and decreases the LPIPS metric by 0.007 to 0.009 (Tab.2). These results highlight the robustness and effectiveness of our method in achieving high-fidelity mural restoration.ConclusionsThe proposed Mural Restoration via Joint Gated Attention and Residual Dense Transformer (MGRT) model successfully addresses the challenges of long-range dependency and detail preservation in mural restoration. The framework uses a Focused Linear Attention Module (FLAM) module to reduce computational complexity from quadratic to linear while effectively capturing critical texture and structural features. In addition, the Residual Dense Transformer Block (RDTB) enhances feature reuse by establishing dense residual connections between shallow and deep layers, which improves the fusion of high-frequency details such as edges and textures. Experiments on the Dunhuang mural dataset demonstrate that the MGRT model achieves superior structural coherence and detail fidelity compared to existing methods, with both subjective and objective evaluations indicating a closer resemblance to the original murals. This work offers a practical solution for high-fidelity restoration of cultural heritage artifacts with complex degradation patterns.
Aug. 25, 2025Vol. 54 Issue 8 20250217 (2025)
Guoping WANG, Bo ZHANG, Wenzhuo GAO, Xue LI, Yang PAN, and Lei ZHU
ObjectiveInfrared target detection technology is essential in numerous applications, including autonomous driving, military reconnaissance, underwater exploration, and medical imaging. Compared to visible light imaging, infrared imaging can operate effectively in low-light and nighttime environments where visible imaging is limited, offering all-weather capability and strong anti-interference performance. However, infrared images often suffer from low contrast, insufficient texture details, and blurred feature contours,which lead to low detection accuracy and poor performance in small object detection. To address these issues, this paper proposes a deep learning-based detection algorithm employing multi-scale feature fusion, which significantly improves detection accuracy, reduces model parameters, and enhances overall performance, especially in small object detection.MethodsThis work proposes MSFFNet, a multi-scale feature fusion-based infrared target detection (Fig.1). First, the feature fusion network is restructured by incorporating a Scale-Sequence Feature Fusion (SSFF) module (Fig.2) to improve multi-scale infrared feature integration within the deep learning framework. Second, a Triple Feature Encoding (TFE) module (Fig.3) is incorporated to improve the detection of small targets in complex backgrounds. Third, a Dual-Channel Attention Mechanism (DCAM) module (Fig.4) is proposed to better integrate features across different channels. Fourth, a Shared Detail-Enhancement Detection (SDED) Head (Fig.5) is designed to reduce the number of network parameters while improving the ability to capture fine details of infrared small targets. Finally, the Wise-Inner-MPDIoU (WIMPDIoU) loss function (Fig.6) is adopted to optimize the bounding box more effectively.Results and DiscussionsThis study utilizes the FLIR ADAS v2 infrared dataset, collected by Teledyne FLIR, which comprises images captured by vehicle-mounted infrared cameras. To validate the effectiveness of the proposed method, the distribution of targets at different scales is analyzed (Fig.7). Evaluation metrics include mAP@0.5, mAP@0.5:0.95, the number of parameters, floating-point operations (FLOPs), and inference time. Ablation experiments (Tab.1) confirm the effectiveness of the proposed improvements, demonstrating that the enhanced network achieves increases of 5.25% and 4.59% in mAP@0.5 and mAP@0.5:0.95, respectively, compared to the baseline model. Furthermore, experiments incorporating the SSFF and TFE modules are conducted to verify their contributions (Tab.2), alongside comparisons of fusion layer feature maps before and after the enhancements (Fig.8), evaluation of the DCAM module (Tab.3), and performance under different loss functions (Tab.4). The contribution of the SDED head to small object detection is also analyzed (Fig.9). Additionally, the performance of various detection algorithms is compared (Tab.5), detection results are visualized (Fig.10), and Grad-CAM (Fig.11) is employed to verify the enhanced network’s superiority in preserving infrared target feature information compared to the original model.ConclusionsThis paper proposes a multi-scale feature fusion-based network for infrared target detection.By reconstructing the feature fusion network, the method strengthens the multi-scale integration of infrared target features and enhances detection performance for small targets in complex backgrounds within a deep learning framework. The proposed Shared Detail-Enhancement detection head reduces the number of network parameters while enhancing the ability to capture fine details of small infrared targets. The improved WIMPDIoU (WIMPDIoU) loss function further optimizes the bounding box regression. The optimized algorithm demonstrates superior detection performance on the test set.
Aug. 25, 2025Vol. 54 Issue 8 20250223 (2025)
Ying CHEN, Xiaoxia ZHOU, and Li CAI
ObjectiveIn a dense wavelength-division multiplexing (DWDM) system, the narrow-band filter is a core component ensuring the quality of information transmission, and its importance is self-evident. As data transmission continues to develop towards larger capacity and higher density, the DWDM system faces even greater challenges. To improve the utilization rate of optical fiber transmission channels, the number of multiplexing needs to be continuously increased, which leads to a continuous narrowing of the channel spacing. Therefore, the filters with high transmittance, ultra-narrow bandwidth, and large aperture have attracted increasing attention from researchers. Zero-index metamaterial (ZIM) possess a series of unique physical properties, and their zero-index characteristic only exists within a narrow frequency range. This characteristic is extremely beneficial for the design of ultra-narrow-band optical filters. For this purpose, an ultra-narrow-band compsite filter baseed on ZIM is designed.MethodsFirstly, a ZIM material with a thickness of d2 is designed to be embedded in the resonant cavity of the filter to compose a composite filter (Fig.2). The degeneracy frequency ωd of the ZIM is designed to be equal to the center frequency ω0 of the resonant cavity with a thickness of d1, that is, ω0=ωd. Subsequently, the COMSOL Multiphysics software is used to simulate the transmission curve (Fig.3(a)) of the composite filter and the electric-field distribution at the frequency of ω0 (Fig.3(b) and Fig.3(c)). Furthermore, the equivalent permittivity and permeability of the ZIM at the Dirac-like frequency point are calculated (Fig.4). Finally, in order to analyze the mechanism of the compression of the transmission bandwidth of the composite filter, the influence of the thickness d2 on the bandwidth of the composite filter is simulataed (Fig.5).Results and DiscussionsTo compose a composite filter, a ZIM with a thickness of d2=2.8 μm is embedded in a resonant cavity with a defect of d1=0.3 μm (Fig.2(b)). The simulated results indicate that the resonant frequencies of these two cavities are nearly identical (Fig.3(a)). This phenomenon suggests that light with resonant frequency experiences almost no phase delay when passing through the ZIM material. Through further calculations and analyses, it is found that the equivalent refractive index of the ZIM approaches zero (Fig.4(a)). In such a situation, the transmittance of the composite filter is hardly affected by the thickness of the ZIM, which is consistent with that of a single line-defect filter without ZIM. At the resonant frequency of 195.9 THz, the full-width at half-maximum (FWHM) of the proposed composite filter is only 70 GHz (Fig.4(b)). Compared with the 300-GHz FWHM bandwidth of a sigle line-defect filter, its bandwidth is compressed by a factor of approximately 4.5 (Fig.4(b)), fully demonstrating the characteristics of ultra-narrowband filtering. Meanwhile, the quality factor of the composite filter is also significantly improved. Finally, by thoroughly calculating the influence of the thickness d2 on the bandwidth of the proposed composite filter, the simulated results show that the thickness of the ZIM has little effect on the resonance mode of the composite filter. Moreover, the ultra-narrowband characteristics of the composite filter can be optimized through the meticulous design of the ZIM thickness d2 (Fig.5).ConclusionsThe rapid growth in demand for ultra large capacity and high-density information transmission in the era of intelligence has led to increasing attention being paid to the research of ultra narrowband filters. An optical metamaterial with degenerate energy bands and Dirac-like point are introdeced into the traditional resonant cavity structure filter model, and a composite ultra-narrow-band filter that combines zero refractive index effect and resonant effect is proposed. The COMSOL Multiphysics software is used to simulate the transmission rate of the optical filter and its electric-field distribution. The simulation results show that when the Dirac-like frequency point coincides with the resonant frequency of the cavity, the zero-phase-delay characteristic and the strong dispersion characteristic of ZIM will work together, and the filtering bandwidth of the proposed filter can be significantly compressed. Specifically, a composite filter based on ZIM material with a thickness of 2.8 μm and a 0.3 μm-line-defect resonant cavity is designed. At the resonant frequency of 195.9 THz, the FWHM of the composite filter is only 70 GHz. Compared with the 300-GHz bandwidth of a single line-defect filter, its bandwidth is compressed by a factor of approximately 4.5, fully demonstrating the characteristics of ultra-narrowband filtering. An in-depth analysis of the mechanism of bandwidth compression and explores the optimization design of ultra-narrow-band are also provided. The research results provide new technical ideas for the design and application of optical communication devices based on optical metamaterials.
Aug. 25, 2025Vol. 54 Issue 8 20250101 (2025)
Cheng ZHU, Lei ZHANG, Sibo PAN, Dewang LIU, and Jiate WANG
ObjectiveSensible heat flux constitutes the foundation for exploring the mechanisms of global climate change and Earth system operations. Delving into its variation patterns and influencing factors holds immense value for improving the accuracy of climate predictions and enhancing ecological environmental protection. Although large-aperture scintillometers serve as a crucial tool for measuring sensible heat flux and play a significant role, they often suffer from data anomalies due to scintillation saturation, affecting the accuracy and reliability of the data. In response to this issue, an innovative regional sensible heat flux prediction method based on neural networks is proposed. This method not only achieves continuous and high-precision predictions of sensible heat flux but also significantly enhances the utilization efficiency of meteorological parameters, providing a new perspective for the in-depth exploration of meteorological data. Additionally, it offers a real-time interpolation solution for data anomalies in large-aperture scintillometers, ensuring the integrity and continuity of the data stream.MethodsA nonlinear mapping relationship between meteorological parameters and sensible heat flux is established through a BP (Back Propagation) neural network, and a genetic algorithm is utilized to optimize the model for improved accuracy. Experimental tests are conducted in typical urban and rural environments, targeting diverse regions and various measurement ranges, to verify the prediction precision and generalization performance of the model.Results and DiscussionsThe optimization of the BP neural network using genetic algorithms has enhanced the prediction accuracy of the model (Fig.8, Fig.9). The trend of the model's predicted values aligns closely with the actual measured values, achieving a prediction accuracy of 98.5646%. Specifically, the Mean Absolute Error (MAE) is 0.4221, the Mean Squared Error (MSE) is 0.3094, the Root Mean Squared Error (RMSE) is 0.5562, and the Mean Absolute Percentage Error (MAPE) is 1.4354% (Fig.10). To verify the accuracy of the model's predictions, predictions were conducted at Observation Point 2 (Fig.11) and Observation Point 3 (Fig.12), with accuracies of 95.3316% and 93.6891% respectively. The excellent prediction results provide a method for regional sensible heat flux prediction.ConclusionsA neural network-based method for predicting sensible heat flux is proposed. This method conducts an in-depth analysis of the characteristics of sensible heat flux across different regions and measurement ranges, and accordingly identifies nine input parameters: temperature, atmospheric pressure, relative humidity, wind speed, wind direction, time, surface temperature, air-surface temperature difference, and height-related temperature difference. Predictive validation of the model across various measurement ranges and regions has demonstrated prediction accuracies of 95.3316% and 93.6891% respectively, fully showcasing the model's high prediction accuracy and reliable generalization capability. This approach not only offers an innovative means for measuring regional sensible heat flux but also successfully validates its feasibility in accurately interpolating measurement bias data from large-aperture scintillometers caused by scintillation saturation issues.
Aug. 25, 2025Vol. 54 Issue 8 20240586 (2025)
Hu TAO, Zhulian LI, Kai HUANG, Junfeng CUI, and Yuqiang LI
ObjectiveHigh-precision prediction of space debris positions is critical for the successful implementation of laser ranging to space debris. Currently, the prediction using TLE (Two-Line Element) data for space debris is subject to significant errors. When tracking a target, these errors mainly manifest as positional bias within the telescope's field of view and distance bias between the ground station and the target. Excessive positional bias can prevent laser pulses from hitting the target, while large bias in the predicted distance between the station and the target can cause a mismatch between the expected and actual echo arrival times. This mismatch can result in the failure of the single-photon detector to detect echo photons during the distance gate opening period. To improve the success rate of laser ranging to space debris, this paper proposes an optimization method for predicting space debris positions based on time bias correction. This method aims to improve the accuracy of position and distance predictions for the target, thereby enhancing the probability of laser pulse hits and the detection capability of echo signals.MethodsTo theoretically verify the effectiveness of time bias correction for optimizing orbit prediction, three low Earth orbit satellites with SP3 precise orbit data were selected. The SP3 data is used for high-precision orbital analysis and serves as the nominal orbit for comparison with TLE data. The specific calculation process is as follows: based on the Kunming observation station, visible observation arcs predicted by TLE are selected, and SP3 data for the same time period is matched. Subsequently, both the TLE and SP3 data are converted into azimuth and elevation angle observations for the observation station. These observations are then compared to identify the closest azimuth and elevation angles between TLE and SP3, determining the time bias of the TLE prediction. After correcting the time bias, the remaining azimuth and elevation bias are calculated.Based on theoretical calculations, this study uses the 1.2-meter telescope space debris laser ranging system of the Yunnan Astronomical Observatory, Chinese Academy of Sciences, for experimental verification, investigating the impact of time bias on space debris position prediction. Prior to the experiment, to achieve high-precision pointing, a new pointing model for the 1.2-meter telescope was established, and system errors were recalibrated. During the experiment, the 1.2-meter telescope tracks space debris based on TLE orbit data. Once the target is captured in the CMOS camera, the time bias is first corrected to adjust the target's position in the camera. When the azimuth or elevation deviation approaches zero, further corrections to azimuth and elevation bias are made. After the target enters the center of the telescope’s ranging system field of view, the corrected time bias, azimuth deviation, and elevation deviation data are recorded.Upon completing the data collection, the data is analyzed to determine the azimuth and elevation angles of the space debris when it first enters the field of view, when it is at the center of the field of view, and after time bias correction. The azimuth and elevation bias of the space debris relative to the center of the field of view are first calculated, followed by the reduction in bias after time bias correction. This evaluation assesses the improvement in prediction accuracy for space debris positions due to time bias correction, thereby validating the effectiveness of this method.Results and DiscussionsTo verify the effectiveness of time bias correction for optimizing orbit prediction, theoretical calculations were first conducted for three low Earth orbit satellites with SP3 precise orbit data: Starlette, Larets, and Lares. The azimuth and elevation angle data from TLE and SP3 were compared. Since both azimuth and elevation bias need to be minimized during theoretical calculations and actual ranging processes, the sum of azimuth deviation and elevation deviation was used as the evaluation criterion in the theoretical analysis. The theoretical results showed that after time bias correction, the average correction percentages of the sum of the absolute values of azimuth and elevation bias for Starlette, Larets, and Lares were 51.7%, 76.0%, and 95.0%, respectively, proving that time bias correction has a significant effect on optimizing the orbital prediction of space debris. Meanwhile, this paper proposes a method for calculating time deviations by treating the forecast azimuth and elevation angle time series as a whole, and achieves the simulation calculation of time deviations for three satellites. Based on the theoretical calculations, this study conducted optical tracking experiments on space debris. Analyzing tracking data for 179 orbits, it was found that after time bias correction, the average correction percentage of azimuth deviation was 83.5%, and that of elevation deviation was 79.8%. This indicates that the time bias correction method can effectively reduce most of the positional prediction errors. From April 23, 2024, to May 18, 2024, tracking experiments of 37 different pieces of space debris were conducted at the Kunming station. It was found that 15 pieces of space debris exhibited a significant positive and negative pattern in their time bias, with 14 showing a clear positive pattern and 1 (ID 00694) having negative pattern.It was also observed that using time bias correction to adjust the predicted positions of space debris resulted in more stable tracking compared to correcting only the telescope's azimuth and elevation. After time bias correction, the telescope was able to maintain the space debris more stably at the center of the camera's field of view, requiring smaller adjustments in azimuth and elevation. For space debris with small time biases, azimuth, and elevation bias, an analysis of their orbits revealed that the difference between the perigee and apogee was within 15 km. Selecting near-circular orbit space debris with a difference between the perigee and apogee of less than 50 km from the tracking experiment data, it was found that the mean absolute value of time bias correction for near-circular orbit space debris was 59.5 ms, while for elliptical orbit space debris it was 80.9 ms. This indicates that near-circular orbit space debris generally has a lower time bias correction, and that the shape of the orbit has a significant impact on the time bias.ConclusionsThis study proposes a space debris position prediction optimization method based on time bias correction. Theoretical calculations and experimental validation demonstrated that this method can significantly improve the accuracy of space debris position prediction, reduce positional bias within the telescope's field of view, and decrease the distance deviation between the observation station and the target. This provides methodological support for stable tracking of space debris and enhances the success rate of laser ranging to space debris. Analysis of observational data also revealed that the shape of the orbit is a key factor influencing the time bias of space debris, and that some space debris exhibits a pattern of positive and negative time bias. The time bias correction method not only improves the tracking stability of space targets during twilight periods but can also be extended to daytime observations. In particular, for specific space debris in Earth's shadow regions, the regularity of the time bias can be used to optimize search strategies, improve search efficiency, and avoid blind searches.
Aug. 25, 2025Vol. 54 Issue 8 20250141 (2025)
Tianpeng XIE, Chunxiao WANG, Yan JIANG, Chenghao JIANG, and Jingguo ZHU
ObjectiveThe advancement of electro-optical observation and targeting systems has introduced new challenges for electro-optical countermeasures. Laser-based active detection of cat-eye targets has become a prominent research focus in this field due to its capability for 24/7 monitoring of optical devices including sniper rifle scopes and binoculars, demonstrating considerable practical significance and academic value. However, the small size, significant scale variations, and lack of distinctive texture features of cat-eye targets present significant challenges for reliable detection and recognition, often leading to high false alarm rates in complex environments. To address these limitations, we propose a novel target detection algorithm specifically designed to suppress false alarms while ensuring robust detection performance.MethodsWe propose a Decision-level Fusion based on Spatial Context (DFSC) algorithm for cat-eye target detection. The algorithm consists of three modules: In the cat-eye target detection module, an image binarization method based on adaptive iterative maximum inter-class variance is proposed. This method incorporates an iterative foreground refinement strategy and a dynamic convergence mechanism to accurately extract the connected regions of cat-eye targets while preserving local detail information. Additionally, feature descriptors based on the Fourier power spectrum and normalized weighted centroid deviation are constructed to enhance the discriminability between cat-eye targets and interfering objects. Furthermore, a multi-dimensional feature weighted fusion method based on adaptive environmental perception is introduced to achieve adaptive optimization of feature weights. In the general object detection module, deformable convolution (DCNv3) is integrated into the C2f module of the YOLOv8 backbone network, improving detection performance for occluded and small targets. In the decision-level fusion module based on spatial context, the spatial relationship between cat-eye targets and interfering objects is evaluated by calculating the occlusion rate of cat-eye targets, effectively suppressing false alarms.Results and DiscussionsTo evaluate the performance of the proposed algorithm, a comparative analysis is conducted against several representative algorithms in recent years, including three traditional methods and two deep learning-based methods. The evaluation is carried out quantitatively from five aspects: recall, miss rate, precision, false alarm rate, and algorithm runtime. The proposed DFSC algorithm effectively combines low-level visual features from target local regions with high-level spatial contextual information of interfering objects, significantly mitigating the impact of distractors in complex environments. Experiments conducted on a self-constructed cat-eye target detection dataset under complex environmental conditions show that, compared with existing mainstream algorithms, the recall rate is improved from 92.2% to 98.9%, and the precision is increased from 49.0% to 74.5%. The algorithm achieves a processing speed of 8.3 ms per frame while significantly reducing the false alarm rate in complex environments. Since the background environment in the field experiments is relatively simple and lacks interference from complex high-reflective targets such as pedestrians or vehicle lights, the algorithm is able to achieve stable detection of cat-eye targets at various distances, with virtually no false alarms. In dynamic scenarios, when a cat-eye target happens to be located at the edge of a driving vehicle and nearly overlaps with the position of the car's taillight, the algorithm may mistakenly classify the cat-eye target as an interfering object, leading to a drop in recall. However, this scenario represents a rare and atypical case, thus having a limited impact on the overall performance of the algorithm.ConclusionsTo address the performance limitations of cat-eye target detection in complex environments, we propose the DFSC algorithm. The method integrates an adaptive iterative Otsu image binarization approach with a novel feature descriptor combining the Fourier power spectrum and normalized weighted centroid offset. An adaptive environment-aware multi-dimensional feature fusion strategy is introduced to dynamically optimize detection robustness. Furthermore, DCNv3 is incorporated into the YOLOv8 backbone network, leveraging spatial contextual relationships between interference targets and surroundings to enhance decision-level fusion. Experiments were conducted on a cat-eye target detection dataset built using a self-developed laser active detection system. The results show that, compared with existing mainstream algorithms, the proposed method improves the recall from 92.2% to 98.9% and the precision from 49.0% to 74.5%, with a per-frame processing time of 8.3 ms. The results demonstrate that the proposed algorithm significantly reduces false alarm rates while maintaining high computational efficiency, providing an effective and reliable solution for cat-eye detection in complex scenarios.
Aug. 25, 2025Vol. 54 Issue 8 20250158 (2025)
Zheng FANG, Yuao GAO, and Hanbo WANG
Significance Fourier Transform Infrared Spectrometers (FTIR) play a crucial role in remote sensing, atmospheric monitoring, and gas composition analysis. However, their measurement accuracy is highly susceptible to temperature drift, which results in spectral deviations and compromises the reliability of collected data. This issue is particularly critical in applications where environmental temperatures fluctuate due to variations in geographical location, flight altitude, and seasonal or diurnal temperature changes. As a result, the spectrometer’s ability to provide precise and stable measurements is significantly challenged, limiting its effectiveness in practical scenarios. Temperature-induced spectral drift occurs when changes in ambient conditions affect the optical and electronic components of the spectrometer, leading to systematic errors that must be corrected to maintain measurement integrity. Traditional calibration methods often fail to account for the complex, nonlinear nature of temperature drift, necessitating the development of more advanced correction techniques. To address this issue, this study investigates the effects of temperature variations on spectral measurements and proposes a novel deep learning-based correction framework. The primary objective is to restore spectral data obtained at non-standard temperatures to their corresponding standard-temperature equivalents, thereby improving measurement accuracy and enhancing the robustness of FTIR spectrometers for real-world applications.Progress In our experimental setup, spectral curves were collected from a single emission source while the environmental temperature was systematically varied between 55 ℃ and 5 ℃, with 25 ℃ designated as the standard temperature. This dataset allowed for an in-depth analysis of spectral drift characteristics across different thermal conditions. Initially, a Long Short-Term Memory (LSTM) neural network was employed for spectral correction, leveraging its ability to capture temporal dependencies in sequential data. The LSTM model successfully learned the nonlinear relationships between temperature variations and spectral deviations, leading to a significant improvement in correction accuracy compared to traditional approaches. However, while LSTM effectively addressed short-term dependencies, it exhibited limitations in capturing long-range correlations across the spectral data. To further enhance correction accuracy and improve generalization performance, we introduced a Hybrid Model (HM) that integrates LSTM with Transformer. This model exploits the advantages of both architectures: LSTM excels in sequential feature extraction, while Transformer’s self-attention mechanism enables global feature modeling, allowing the network to identify complex dependencies between different spectral wavelengths. By combining these two approaches, the Hybrid Model offers a more comprehensive correction mechanism, reducing errors and improving spectral alignment across varying temperatures. Experimental results demonstrate that, compared to standalone LSTM, the Hybrid Model significantly improves key performance metrics, including mean squared error (MSE) and coefficient of determination (R2). Specifically, the Hybrid Model achieves a 86% reduction in prediction errors relative to standard spectral values, demonstrating its superior capability in mitigating spectral drift. These findings confirm that the proposed method effectively enhances the accuracy and stability of FTIR spectrometer measurements under varying temperature conditions.Conclusions and Prospects This study highlights the effectiveness of combining LSTM and Transformer in a Hybrid Model to address spectral temperature drift in FTIR spectrometers. By leveraging LSTM’s sequential learning capabilities and Transformer’s ability to model global dependencies, this approach offers a more accurate and robust correction framework than conventional deep learning techniques. The Hybrid Model significantly improves spectral correction accuracy, ensuring that FTIR spectrometers maintain high measurement precision even in harsh and rapidly changing environmental conditions. The results also suggest that this method has broad applicability beyond FTIR spectrometers, as it can be extended to other spectroscopic instruments experiencing temperature-induced deviations. This has important implications for various fields, including remote sensing, environmental monitoring, industrial quality control, and atmospheric research. Looking ahead, future work will focus on optimizing the Hybrid Model’s computational efficiency to enable real-time spectral correction, improving its adaptability to a wider range of operational scenarios. Additionally, further investigations will explore integrating physics-informed models with deep learning techniques to enhance interpretability and reliability. As advancements in remote sensing and spectroscopy continue, refining temperature drift correction algorithms will be essential to achieving more precise, stable, and versatile spectroscopic measurements across diverse applications.
Aug. 25, 2025Vol. 54 Issue 8 20250164 (2025)
Jiashi YAO, Zhaohui LI, Zhen MAO, Wei LIU, Liang NIE, Quan ZHOU, Yong LIU, and Shasha YIN
ObjectiveIn the measurement system of the backscattered light of a gravitational wave telescope, the beam splitter plays a vital role. Its core function is to efficiently separate the incident light from the backscattered light. The intensity of the light beam output by the beam splitter is directly related to the accuracy of the final measurement results. As the structural basis of the beam splitter, the scattering effect caused by the transparent substrate will further affect the accuracy of the overall measurement system. The scattered light of the transparent substrate mainly comes from the surface scattering induced by surface roughness and the volume scattering caused by the inhomogeneity of the refractive index inside the substrate. When the light beam impinges on the surface of the transparent substrate, these two scattering mechanisms are coupled with each other, making it extremely difficult to measure either of them separately. In response to this challenge, this study has set up an experimental optical path based on the theory of polarization scattering.MethodsThis study analyzed various scattered light testing methods. Based on this, an experimental optical path (Fig.6) was established using the theory of polarization scattering. The volume scattering of transparent substrates made from different base materials, the volume scattering of substrates with the same base material but different thicknesses, and the scattering introduced by sample pieces with identical base material, same thickness but different surface roughness were compared. A transparent substrate with a thickness of 3 mm and surface roughness of 3 nm was selected as the experimental sample. This sample was used to measure surface and volume scattering under different incident and scattering angles (Tab.5), thereby determining the distribution of surface and volume scattering in transparent substrates across various incident and scattering angles. Additionally, a transparent substrate with 0.3 nm roughness and 3 mm thickness was used to validate the accuracy of the testing system.Results and DiscussionsAccording to the basic principles of the polarization scattering theory, the polarization directions of the surface scattering and volume scattering under different incident angles and scattering angles are obtained. By using the principle of polarization separation, either the surface scattering or the volume scattering can be completely eliminated to achieve the purpose of separating the surface scattering from the volume scattering. An experimental optical path based on the polarization scattering theory was set up. A sapphire substrate with a thickness of 3 mm and a roughness of 3 nm was used as a sample (Tab.4), and a detector with adjustable gain was selected to measure the surface scattering and volume scattering under different incident angles and scattering angles (Tab.5). The distributions of the surface scattering and volume scattering of the transparent substrate under different incident angles and scattering angles were determined.ConclusionsAn experimental optical path was set up based on the principle of polarization scattering. A sapphire substrate with a thickness of 3 mm and a roughness of 3 nm, which has the same surface scattering intensity and volume scattering intensity, was selected as the experimental sample. Meanwhile, a detector with adjustable gain was chosen to measure the surface scattering and volume scattering at different incident angles and scattering angles. Then, a sapphire sample with a thickness of 3 mm and a surface roughness of 0.3 nm was used to verify the accuracy of the experimental results.The experimental results show that this method can successfully separate and independently measure the surface scattering and volume scattering. This solution provides a testing basis for the subsequent back - scattered light measurement system of high - sensitivity gravitational wave telescopes to screen materials with low volume scattering at a roughness of 3 - 8 nm.
Aug. 25, 2025Vol. 54 Issue 8 20250178 (2025)
Biao CHEN, Jinfeng ZHANG, Jiandong SUN, and Hua QIN
ObjectiveAccurate velocity measurement of high-speed projectiles, such as those launched by electromagnetic guns or artillery systems, is essential for evaluating weapon performance in terms of range, trajectory stability, and terminal effects. Traditional photoelectric velocimetry technologies, including laser screens, radar, and high-speed photography, face severe limitations in environments with plasma, smoke, and electromagnetic interference. For instance, visible and infrared wavelengths are strongly attenuated by smoke and high-temperature backgrounds, while microwave-based systems exhibit poor plasma penetration and susceptibility to low-frequency noise. Additionally, X-ray methods, though penetrative, suffer from bulky equipment and radiation hazards. To address these challenges, this study proposes a terahertz-based velocimetry system that leverages the unique advantages of terahertz waves (0.1-10 THz), including their ability to penetrate plasma and smoke, immunity to electromagnetic interference, and non-ionizing safety. The research aims to establish a compact, high-precision measurement framework capable of operating in complex battlefield environments.MethodsThe proposed system integrates a single terahertz source (94 GHz) with a multi-channel AlGaN/GaN high-electron-mobility transistor (HEMT) detector array. The terahertz wave is generated by a Gunn diode and collimated using a conical horn antenna and polytetrafluoroethylene (PTFE) lens, achieving a narrow beam divergence of 0.1 mrad and a gain of 34.5 dBi (Fig.5). The detector array comprises 50 pixels with a 3 mm pitch and 110 GHz sensitivity, designed with silicon lens-coupled non-symmetric dipole antennas to enhance signal capture efficiency. A hybrid Gaussian quasi-optical-Poisson point positioning (GQ-PPP) algorithm is developed to resolve terahertz diffraction effects and beam divergence. This algorithm processes the "W"-shaped voltage response generated by the detector array, identifying local maxima (Poisson points) within filtered signal intervals through Savitzky-Golay filtering and arithmetic averaging (Fig.3, Fig.7(c)). The system’s compact architecture reduces optical components by 50% through a single-source multi-channel illumination strategy, supported by lithium battery power and modular signal processing units to minimize environmental interference. Experimental validation combines numerical simulations—modeling Gaussian beam propagation and diffraction effects (Fig.2, Fig.4)—with laboratory tests using a motor-driven aluminum foil target to replicate 3000 m/s projectile motion under controlled conditions.Results and DiscussionsThe GQ-PPP algorithm effectively suppresses terahertz diffraction, enabling precise time-stamp extraction from the "W"-shaped voltage response (Fig.3). Geometric correction for beam divergence, derived from Gaussian beam propagation theory (Eq.11), reduces velocity errors from >10% to 0.83% at 3000 m/s (Tab.1). Laboratory tests demonstrate corrected velocities with a maximum error of 0.288% across a 3.5-4.5 m measurement range (Tab.1). The system achieves 0.1 mrad beam collimation and a 40% volume reduction compared to conventional laser-based setups (Fig.5). Key innovations include the integration of terahertz penetration capabilities with high-speed HEMT detectors and the miniaturized architecture, resolving the traditional trade-off between beam collimation and energy density. Error analysis identifies spatial misalignment (e.g., ±0.1 mm detector pitch error contributing 0.167% velocity error) and beam divergence calibration as primary error sources. These errors are mitigated through high-frequency sampling (10 MHz), adaptive signal filtering, and laser-assisted alignment techniques. The system’s robustness is further validated through repeated experiments, showing an average relative error of 0.83% under varying propagation distances and target size. The terahertz wave’s longer wavelength (3.2 mm) inherently reduces sensitivity to small-scale environmental disturbances, while the HEMT detector’s pW-level sensitivity ensures reliable signal detection even in low-power scenarios.ConclusionsThis study establishes a robust terahertz interception velocimetry framework for high-speed projectile measurement in complex environments. By combining terahertz wave advantages, HEMT detector arrays, and the GQ-PPP algorithm, the system achieves sub-1% velocity errors, outperforming traditional photoelectric methods in terms of penetration, accuracy, and portability. The compact design, enabled by single-source multi-channel architecture and lithium battery power, demonstrates significant potential for field deployment. Future work will focus on high-density detector arrays to improve spatial resolution, FPGA-based real-time processing for dynamic target tracking, and field testing under realistic battlefield conditions to validate practical reliability. These advancements position terahertz velocimetry as a transformative technology for military and industrial applications requiring high-precision measurements in adverse environments.
Aug. 25, 2025Vol. 54 Issue 8 20250195 (2025)
Cijun YU, Qingguo LI, Pujia FENG, Junjie HU, and Shouguo ZHENG
ObjectiveAs a high-precision measurement instrument, laser trackers are widely employed in aircraft assembly to verify geometric dimensions and positional accuracy. When measuring large components or operating in complex environments where single-station measurements are insufficient, station relocation becomes necessary. The relocation accuracy critically influences assembly quality. While advancements in tracker calibration, matching algorithms, and operator proficiency have improved measurement stability, empirical evidence identifies temperature variation as the predominant factor affecting relocation accuracy. Non-uniform thermal fields in hangar environments induce tooling structure deformations that generate registration errors, significantly compromising measurement precision. Current thermal compensation methods, designed for uniform temperature conditions, fail to address spatiotemporal thermal gradients, highlighting the need for dynamic compensation strategies in thermally heterogeneous industrial settings.MethodsTo address this issue, a registration error compensation method was developed for a typical aircraft fuselage assembly frame based on non-uniform temperature field thermal deformation. A thermal deformation model under non-uniform temperature fields was established. Temperature data from strategic field monitoring points were acquired in real time. Thermal deformation displacements at each Enhanced Reference System (ERS) point were calculated using the finite element method, and actual ERS positions were dynamically corrected to reduce registration errors.Results and DiscussionsComparative analysis of mean transfer station errors (ME) revealed: The proposed method reduced average errors by 16.6% (X: 0.1696 mm→0.1416 mm), 43.2% (Y: 0.0702 mm→0.0398 mm), and 19.0% (Z: 0.1247 mm→0.1010 mm) versus uncompensated measurements (Tab.6), demonstrating particularly strong Y-direction improvement due to the frame's long span and cumulative thermal effects (Fig.10(b)). While all ERS points showed positive compensation in X (Fig.10(a)), some exhibited reverse fluctuations in X/Z directions (Fig.10(b),(c)), potentially attributable to local stiffness variations or sensor placement. These phenomena warrant further investigation to optimize model robustness.ConclusionsAiming at the thermal deformation model under non-uniform temperature field, the temperature data of specific points in the field are collected in real time, and the thermal deformation displacement of each ERS point is calculated based on the finite element method, and the actual position of ERS points is corrected, so as to reduce the station error. The thermal and mechanical coupling simulation of the simplified model is carried out by ABAQUS, and the results show that the thermal deformation displacement trend calculated by the finite element method is consistent with the simulation results. Engineering examples show that the proposed method can effectively improve the accuracy of the laser tracker in the non-uniform temperature field.This method breaks through the limitation of traditional uniform temperature field compensation, and realizes the high-precision characterization of complex thermal deformation through space temperature gradient modeling, which provides a new idea for thermal error compensation of large tooling. However, it was found in the experiment that local structural stiffness differences and sensor layout may affect the compensation effect, and subsequent studies need to further optimize the temperature monitoring network and verify the universality of the model in different structural tools.
Aug. 25, 2025Vol. 54 Issue 8 20250196 (2025)
Shuai ZHI, Shihao HAN, Guopeng DING, Haodong YAN, Yonghe ZHANG, and Zhencai ZHU
ObjectiveWith the rapid development of complex space missions such as deep-space exploration, on-orbit services, and space debris removal, pose measurement technology for space targets has emerged as a core enabler for autonomous spacecraft operations and mission safety. Accurate pose measurement is directly critical to the successful execution of space missions, highlighting the critical supporting role of this technology in space tasks. As a non-contact measurement method, visual measurement has been widely adopted due to its advantages of low cost, simple installation, and high precision. However, a single visual sensor has significant limitations due to factors such as illumination and measurement range constrains. To enhance mission success rates, multi-sensor joint measurement has become the mainstream solution. The combined use of stereo vision and laser rangefinders can complement each other's advantages, effectively addressing issues such as low initial ranging accuracy, high algorithm redundancy, and weak image information display capabilities, while retaining the benefits of non-contact measurement, fast speed, and easy automation, thus showing broad application prospects in the aerospace field. Calibration between sensors is a prerequisite for ensuring high-precision system measurement. To guarantee the measurement accuracy of the entire system, the relative installation matrix between sensors must be accurately determined, necessitating high-precision joint calibration of the measurement system.MethodsA joint calibration method is proposed for a multi-modal measurement system composed of stereo vision cameras and a laser rangefinder. The method takes the optical center of the left camera as the origin of the system coordinate system, and uses ZHANG's calibration method to determine the internal and external parameters of the stereo cameras. Line constraints formed by sequential laser spots are employed to calculate the external parameters of the laser emission port in the left camera coordinate system. By integrating the reprojection error of the circular center of a high-precision circular target and the reprojection error constraints of laser spots, the external parameters are optimized to achieve high-precision system calibration (Fig.6). Aiming at issues such as inaccurate determination of the geometric center of laser spots and unstable calibration results caused by poor imaging quality in existing methods (Fig.3), a sub-pixel edge positioning method based on local effects is proposed. The algorithm offers significant advantages in terms of time-space complexity and robustness while ensuring extraction accuracy.Results and DiscussionsThe sub-pixel edge positioning method based on local effects proposed analyzes the grayscale gradient distribution of the local edge of the light spot and calculates the edge vector, which can effectively suppress the influence of noise and reduce the computational load while ensuring accuracy (Tab.2). The joint calibration employs multiple geometric constraints, avoiding the error accumulation issue of traditional global optimization methods, reducing the impact of single-point outliers on the overall result, and improving the system's robustness (Tab.3, Tab.4).ConclusionsA sub-pixel edge positioning method based on local effects was proposed, which analyzes the grayscale gradient distribution in the edge region of the laser spot to reduce the computational load of centroid extraction while ensuring accuracy. By utilizing multiple geometric constraints formed by the reprojection error of the circular target spot center and the distance error between sequential laser spots, the method minimizes the impact of outliers on the overall result and achieves high-precision joint calibration of the system. Compared with traditional methods, the centroid extraction accuracy of laser spots using this approach is improved by 30%. The overall calibration results are robust, stable, and reliable, providing solid technical support for fields such as pose measurement of space targets.
Aug. 25, 2025Vol. 54 Issue 8 20250201 (2025)
Xuewei WANG, Ninghua ZHANG, and Qiang WANG
ObjectiveMulti-missile collaborative guidance has become the main form of modern battlefield, and efficient information transmission between missiles is particularly important. When using lasers as carriers for information transmission between missiles, the presence of atmospheric turbulence has a serious impact on the Pointing, Acquisition and Tracking system. Therefore, it is urgent to propose a beacon positioning method that can accurately calculate the center position of the light spot under different atmospheric turbulence conditions, meeting the stability requirements of inter-missile laser communication. This paper proposes a beacon light spot positioning method based on optical flow features, which has high positioning accuracy and stability.MethodsThe flowchart of the center position positioning method proposed by this paper is shown in Fig.1. The collected light spot image is converted into a grayscale image, and the corner detection method is used to select feature points, then the feature points are further screened by maximum suppression, and sparse optical flow method is used to track the screened feature points to obtain their inter frame offset. Calculate the average inter frame offset of all feature points to approximate the center position offset of the light spot, iteratively compensate it to the initial center coordinates of the light spot, and achieve continuous prediction of the center position of the light spot.Results and DiscussionsSelect continuous images of light spots under different intensities of atmospheric turbulence, light spot center position positioning methods based on optical flow features and grayscale centroid method were used for continuous positioning. The average positioning errors and variances in x-direction and y-direction were compared accordingly. The comparison results under weak turbulence conditions are shown in Tab.1, results under moderate turbulence conditions are shown in Tab.2, and results under strong turbulence conditions are shown in Tab.3. The results indicate that our method has high positioning accuracy and stability under various intensities of atmospheric turbulence.ConclusionsA beacon light spot positioning method based on optical flow characteristics has been proposed in this paper, this method is simple to implement and has high accuracy. Continuous spot images under weak, medium, and strong atmospheric turbulence conditions were collected by 11.16 km urban link optical communication experiment, proving that our method has high positioning accuracy under different atmospheric turbulence conditions, which provides an experimental basis for the study of 10 km level laser communication between missiles and has practical reference value.
Aug. 25, 2025Vol. 54 Issue 8 20250229 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20