







Please enter the answer below before you can view the full text.


2025
Volume: 40 Issue 4
13 Article(s)

Yazhou ZHU, Yuying LIU, Yadong WANG, Huiting XIE, and Gongxin LI
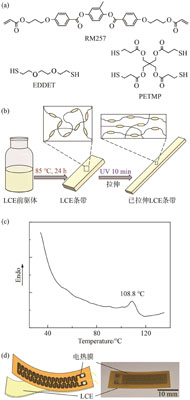
To tackle the challenges posed by traditional robots, which are often heavy and struggle to navigate complex environments in aging pipeline inspections, this paper presents a soft robot inspired by the inchworm, utilizing liquid crystal elastomers (LCE). The design features two anchoring actuators positioned at each end and a central bending-stretching actuator. These actuators are constructed primarily from liquid crystal elastomers and polyimide (PI) soft electrothermal films, functioning through electromechanical deformation of the LCEs. The soft robot achieves locomotion by managing the alternating movements of the two anchoring actuators in conjunction with the bending-stretching actuator. Initially, the paper examines how various actuator characteristic parameters influence driving performance. By integrating finite element analysis with practical experiments, the viability of the soft robot’s gait is confirmed. Additionally, motion experiments conducted in diverse environments (including flat surfaces, slopes, and complex pipelines) further assess the robot’s mobility capabilities. Experimental results indicate that the soft robot can reach a maximum speed of 24.1 mm/min and maintain stable movement in intricate pipeline environments. The liquid crystal elastomer robot developed in this study offers a novel solution for inspecting complex pipelines.
Apr. 05, 2025Vol. 40 Issue 4 527 (2025)
Peng HUANG, Feiqiang ZHOU, Yue SONG, Yihang ZHOU, Guoqiang HE, Zhongyi XIE, and Xinlong ZHANG
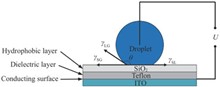
To enhance the zoom speed of electrowetting lenses, a method utilizing vibration to achieve high-speed zoom is proposed. This method drives the liquid medium to undergo periodic oscillations using an alternating electric field. Based on the interface variation patterns and the focal length change curve, the imaging moments corresponding to different focal lengths are determined to complete the zooming process. Molecular dynamics simulations indicate that, with a constant frequency, the shape of the liquid-air interface, i.?e., the lens focal length, is time-dependent within one cycle. Different frequencies generate distinct liquid-air interface shapes. Experimental results show that controlling the frequency to induce resonance in the droplet or increasing the voltage can enhance the zoom speed. For a 5 μL deionized water droplet, under 110 Hz and 190 V AC driving, optimal zoom performance and image quality are achieved. The focal length can be adjusted from 0.821 mm to infinity within 2.250 ms, with the minimum instantaneous zoom speed being 0.512 mm/ms, representing a threefold increase in speed compared to existing lenses.
Apr. 05, 2025Vol. 40 Issue 4 536 (2025)
Zhaoming PENG, Run JIANG, Yaoling XU, and Honglei JI
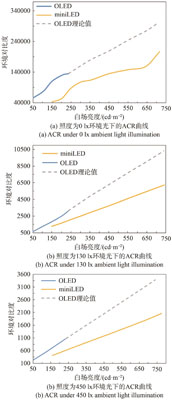
In order to explore the visual contrast effect of OLED and Mini LED display under different ambient light intensity, the parameters are measured and verified from the perspective of environmental contrast and human eye perception. We analyze the contrast performance of two display technologies in darkroom, 100 lx ambient light and 450 lx ambient light. The test results are discussed by correating with the theoretical simulation calculation. The rationality of environmental contrast is analyzed from the perspective of human eye perception. Based on human factors experiment, the equal perception contrast is studied. The experimental results show that the environmental contrast is not consistent with the perceived contrast of human eyes. To describe the perceptual contrast, we should not only focus on the brightness ratio of black and white pictures, but also consider the brightness of black field and white field. In a dark room or an ambient light of 100 lx or 450 lx, the Mini LED can achieve a visual contrast effect similar to OLED by increasing the brightness of all-white field by 1~1.7 times.
Apr. 05, 2025Vol. 40 Issue 4 547 (2025)
Jiuba GE, Mingxing LI, Shasha XU, Chen WANG, Ying ZHOU, Lin YU, Jingjing WU, and Lifa HU
The voice coil deformation mirror, due to its large modulation and lack of hysteresis, is widely used as an adaptive secondary mirror in astronomical telescopes. This paper proposes an optimization method for the voice coil driver used in a 37-element large modulation voice coil deformation mirror, followed by simulation and validation. A dynamic magnetic structure is utilized to derive the theoretical formula for the electromagnetic force of the driver and the relationship between the electromagnetic force and mirror surface strain is briefly discussed. Detailed optimization of the structure is conducted using finite element software. Ultimately, simulation analysis and aberration correction validation of the 37-element voice coil deformation mirror are performed based on the optimization results. The designed voice coil driver has an efficiency of 0.362 N/W1/2, a response speed of 0.3 ms, linearity of 1, and allows for a maximum deformation mirror stroke of 50 μm. Moreover, the designed driver excels in simplicity, miniaturization, low cost, high response speed, linear response, and high efficiency, indicating promising applications in atmospheric turbulence aberration correction, laser weapons, laser communication, and fundus imaging.
Apr. 05, 2025Vol. 40 Issue 4 555 (2025)
Dan LIU, Xiaojun FAN, Wei CEHN, Wei LIU, Chuan LIU, Hongwei DU, Sheng YANG, Xu WU, Taiye MIN, Zhangtao WANG, Haoxiong ZHANG, Wei SHEN, Niannian WANG, Yong XIONG, and Zhonghao HUANG
Gate data short (DGS) defects in IGZO TFT lead to deterioration of display performance and product scrap. It is necessary to identify the DGS mechanism, recognize the impact factors, and propose a solution to ensure the yield. In this paper, the macroscopic phenomena and microscopic morphology of DGS were analyzed. After that, the relationship between the dielectric loss of gate insulator ?(GI) and break-down voltage was explored. Then, the deterioration of display tests were conducted, and the DGS rate of different products was statistically analyzed, the effects of gate voltage and refresh rate on DGS rate were identified. Next, the experimental phenomenon is matched with the investigated DGS mechanism. Subsequently, the reasons for oxide TFT DGS being higher than a-Si TFT were analyzed. The results show that the essential of DGS is GI dielectric breakdown due to insufficient dielectric withstanding strength, while GI dielectric loss, gate voltage, and refresh rate are all the significant influencing factors of DGS. These factors, in the interaction of Cu diffusion and Cu electromigration mechanisms, reduce the GI effective thickness and increase the risk of GI thermal breakdown, which ultimately results in DGS. DGS can be suppressed by reducing thickness ratio of SiOx in the stacked GI aiming at decreasing dielectric loss and inhibiting thermal breakdown; Alternatively, DGS is ultimately suppressed by decreasing gate voltage to inhibit Cu diffusion and electromigration. By introducing the above measures as an improvement plan, the incidence rate of DGS was decreased by 73%, which successfully suppressed the DGS rate of the oxide panel and improved the product quality, providing a reference for oxide TFT process optimization.
Apr. 05, 2025Vol. 40 Issue 4 566 (2025)
Yuntao ZHAO, and Xinhui DENG
6D pose estimation that balances accuracy and applicability has been a hot and difficult research topic. To this end, a 6D pose estimation network based on attentional feature fusion of multimodal data is proposed. Firstly, a deeper structure of squeeze and excitation module is introduced to enhance the dependency to expand the receptive field by adjusting the weights of each channel to improve the effect of processing RGB image features. Further, for multimodal data, an iterative attention feature fusion module is deployed in the feature fusion stage, which solves the scale inconsistency problem in global feature fusion through multiple iterative fusion operations, and is able to capture and integrate multimodal data more accurately, which significantly improves the effect of attitude regression. Finally, in order to quantitatively assess the robustness and applicability of the model in complex environments, an invisibility percentage metric is introduced, which is capable of assessing the performance of the model when dealing with partially occluded or complex backgrounds. Through the pose prediction experiments on the public dataset, it is verified that the improved model is not only able to achieve accurate predicted poses on the validation dataset, but also the algorithmic model proposed in this paper is more applicable in complex environments compared to the densefusion model.
Apr. 05, 2025Vol. 40 Issue 4 598 (2025)
Yuxi WANG, Yang XU, and Xuxiang YUAN
In order to efficiently use depth feature information to assist salient object detection, the fusion of different scale feature information is realized. In this paper, an improved salient object detection algorithm for RGB-D image saliency based on CDINet algorithm is proposed. Firstly, a multi-scale feature fusion module is added to enhance the transmission of feature information between encoder and decoder, so as to effectively reduce shallow feature loss, and obtain more feature information of salient objects through the jump connection of auxiliary decoder. Next, a circular attention module is connected at the tail of the CDINet’s network structure, which gradually optimizes local details by using memory-oriented scene understanding. Finally, the loss function is adjusted, and the consistency enhanced loss (CEL) is used to deal with the spatial consistency caused by the fusion of different scale features, and the salient areas are uniformly highlighted without increasing parameters. The experimental results show that compared with the original CDINet algorithm model, the improved model has an F-measure increase of 0.6% and a MAE decrease of 0.4% on LFSD data set, and an F-measure increase of 0.4% and a S-measure decrease of 0.5% on STERE data set. Compared with other algorithm models, this model basically meets the requirements of better detection performance and higher adaptability.
Apr. 05, 2025Vol. 40 Issue 4 607 (2025)
Zhongqi CAI, Shanling LIN, Jianpu LIN, Shanhong LÜ, Zhixian LIN, and Tailiang GUO
Aiming to address the issues of complex detection processes, numerous parameters, low accuracy, and slow execution speed in current driver fatigue detection algorithms, we propose a lightweight model based on an improved YOLOv8n-Pose. This model optimizes the structure of YOLOv8n-Pose. Firstly, Ghost convolution is introduced into the backbone network to reduce the number of model parameters and unnecessary convolution computations. Secondly, a Slim-neck is introduced to fuse features of different sizes extracted by the backbone network, accelerating network prediction calculations.Additionally, an occlusion-aware attention module (SEAM) is added to the neck part to emphasize the facial region in images and weaken the background, improving keypoint localization accuracy. Finally, a GNSC-Head structure is proposed in the detection head part, which incorporates shared convolution and optimizes the BN layers of traditional convolution with more stable GN layers, effectively saving model parameter space and computational resources. Experimental results show that compared with the original algorithm, the improved YOLOv8n-Pose increases mAP@0.5 by 0.9%, reduces parameter count and computational cost by 50%, and increases FPS by 8%. The final fatigue driving recognition rate reaches 93.5%. Verified through experiments, this algorithm maintains high detection accuracy while being lightweight and effectively recognizes driver status, providing strong support for deployment on vehicle edge devices.
Apr. 05, 2025Vol. 40 Issue 4 617 (2025)
Haisong CHEN, Kang ZHANG, Haoran LÜ, Aili WANG, and Haibin WU
Due to the significant differences in the number of bands, spectral range and spatial resolution of different hyperspectral image datasets, the optimal network structures applicable to different hyperspectral image datasets also differ. In addition, manually designed deep learning networks need to tune a large number of hyperparameters, which undoubtedly poses a serious challenge to designing a generalized classification model applicable to various HSI datasets. Therefore, an efficient attention neural architecture search algorithm is proposed to realize the automatic design of deep learning networks. Firstly, in order to construct an efficient search process, a model is constructed based on the search of microable network architecture, which can effectively improve the search speed of hyperparametric networks. Then, in order to achieve high-precision classification results, a novel modular search space is designed. Finally, considering the misclassification problem of small samples in hyperspectral datasets, Poly loss function is used to increase the loss weights of a few categories, so as to improve the model’s ability to recognize these categories. Experimental results on publicly available hyperspectral datasets show that the overall classification accuracy of the proposed method reaches 99.50% and 97.81%, respectively. The proposed method explores the application of neural architecture search in hyperspectral classification tasks, improving classification accuracy and algorithm design efficiency.
Apr. 05, 2025Vol. 40 Issue 4 630 (2025)
Gang YAN, Ziyi SONG, and Shuze GENG
Traditional visual Mamba (VIM) methods directly flatten the two-dimensional spatial image into a one-dimensional plane, which can capture long-distance dependencies, but also disrupt the local spatial structure of neighboring pixels in the original two-dimensional plane, thereby failing to capture local details. To address this, we introduce the panoramic state-space lightweight super-resolution model (PMambaIR) and propose the residual panoramic spatial group as the core building block. The residual panoramic spatial group component mainly includes two innovative modules. Specifically, we first introduce a new cascaded scanning strategy that promotes the interaction between local information, cross-scale information, and global information, effectively capturing local information while preserving global dependencies, thereby achieving panoramic feature extraction. Secondly, we propose a hybrid state-space block, which can simultaneously model pixel information from both spatial and channel dimensions, limiting the influence of irrelevant features on the model, thereby exploiting the potential relevance of channel and spatial domain information. The PSNR of PMambaIR outperforms existing models by an average of 0.11 dB on benchmark datasets such as Set14 and Urban100. Objective quantitative and qualitative analyses indicate that this method achieves high PSNR and SSIM, while subjective experimental results demonstrate rich details and visual effects.
Apr. 05, 2025Vol. 40 Issue 4 642 (2025)
Hailong XU, Chao WANG, and Haijiang SUN
In order to extend the shooting time of high-speed camera without increasing the size and cost of high-speed camera, a parallel computing intelligent event recognition time-expanded storage method is designed and verified under the strong hardware constraints such as small storage resources of integrated high-speed camera. FPGA is used as the main control chip to realize the time-extended storage of video frame data and effectively extend the shooting time of high-speed camera. Firstly, the principle of double-ring gray scale difference algorithm is introduced and the performance of the algorithm to capture the target is analyzed. According to the location information of the target captured by the algorithm, the image data is segmented and stored, and the stored variable area is deleted from the non-variable area. When output high-speed camera shoots video, the image of the previous frame repeats the non-variable area and the current frame changes the image into a complete video frame image data. Secondly, an AXI~~DMA module is designed to reduce the hardware resource consumption of FPGA board. The hardware resource consumption is about 75% less than that of VDMA IP, which can efficiently transmit data with DDR3. Finally, the method is implemented by FPGA board and the feasibility of the method is verified. Experimental results show that the proposed method can effectively identify targets in high-speed video frame data and segment and store them, and can effectively identify targets of 50×50 size, save 47% of storage resources in 2 560×1 440 video, and effectively improve the shooting time of high-speed camera.
Apr. 05, 2025Vol. 40 Issue 4 655 (2025)
Jun YANG, Lingye CHEN, Libang CHEN, Qihang BIAN, Yikun LIU, and Jianying ZHOU
To address the decline in binocular ranging accuracy under low-contrast conditions, such as haze and strong background interference, this study integrates computer-based image enhancement techniques and optimizes depth information calculation and image processing methods to achieve high-precision passive binocular ranging in low-contrast environments. First, image enhancement techniques are applied to improve the accuracy of feature point recognition and matching in binocular images, thereby enhancing image quality in low-contrast settings. Next, a 3D display device is introduced in the image reconstruction terminal to optimize depth information calculations, ensuring accurate distance measurement even when image features are severely degraded. Through binocular stereoscopic vision, the automatic fusion and registration of target images are achieved, extending the ranging distance and improving accuracy. Experimental results show that, compared to the 10% ranging error of the traditional Type 58 rangefinder, the binocular stereo vision ranging method proposed in this paper achieves an average relative error (MRE) of less than 2.3% within a range of 500 m to 1 300 m. Additionally, this method demonstrates excellent stability, reliability, and real-time performance in low-contrast environments. The proposed method enables real-time, rapid, passive binocular ranging of moving targets in low-contrast conditions, offering high accuracy and strong anti-interference capabilities, making it suitable for industrial control, driver assistance, and target indication applications.
Apr. 05, 2025Vol. 40 Issue 4 577 (2025)
Jiawei YE, Yibo TANG, Keliang LI, Congxi SONG, Haoran XÜ, Hongmin MAO, Huanjun LU, and Zhaoliang CAO
Surface-enhanced Raman spectroscopy (SERS) substrates of silver nanoflowers were prepared based on lyotropic liquid crystals for the quantitative detection of neoCoronavirus spike protein (S protein). Firstly, a Raman spectroscopy detection scheme for neoCoronavirus was designed, and the SERS substrate was prepared using lyotropic liquid crystal soft templates and electrochemical deposition techniques. Then, spectral consistency and inter-substrate detection differences were evaluated to ensure reliable quantitative detection. Then, the sensitivity of the SERS substrate for the detection of S protein was analysed, and its detection limit was 2×10-6 mg/mL. Finally, the quantitative detection method was established, yielding a precise concentration-intensity relationship with a measurement error of 4×10-7 mg/mL. In this paper, the technique of preparing SERS substrates based on lyotropic liquid crystals was used for the high sensitivity detection of neoCoronavirus spike protein, and also provides a feasible technical way for the detection of other proteins.
Apr. 05, 2025Vol. 40 Issue 4 588 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20