









Please enter the answer below before you can view the full text.


2024
Volume: 61 Issue 10
42 Article(s)

Zhenyang Hui, Zhuoxuan Li, Penggen Cheng, Zhaochen Cai, and Xianchun Guo
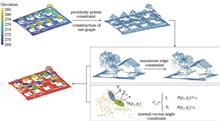
A LiDAR point object primitive obtaining method still encounters challenges, such as large computation amount and ineffective segmentation for different building roof planes. A point object primitive obtaining method based on multiconstraint graph segmentation is proposed to address these challenges. A graph-based segmentation strategy is adopted for this method. First, constraint conditions of adjacent points are used to construct a network graph structure to reduce the complexity of the graph and improve the efficiency of the algorithm. Subsequently, the angle of the normal vectors of adjacent nodes is constrained using a threshold value to divide the point cloud located in the same plane into the same object primitive. Finally, the maximum side length constraint is performed to separate the building point cloud from its adjacent vegetation points. Three sets of public test data provided by the International Society for Photogrammetry and Remote Sensing (ISPRS) and two datasets located in Wuhan University were selected for testing to verify the validity of the proposed method. Experimental results show that the proposed method can effectively divide different roof planes of buildings. DBSCAN and spectral clustering methods were used for comparison, and precision, recall, and F1 score were adopted as evaluation indexes. Compared with the other two methods, the proposed method achieves the best overall segmentation results in case of the five datasets with different building environments, with better recall and F1 score.
May. 25, 2024Vol. 61 Issue 10 1037001 (2024)
Yan Zhang, Minglei Sun, Yemei Sun, and Fujie Xu
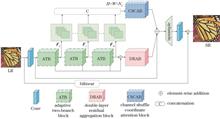
Recently, attention mechanisms have been widely applied for image super-resolution reconstruction, substantially improving the reconstruction network's performance. To maximize the effectiveness of the attention mechanisms, this paper proposes an image super-resolution reconstruction algorithm based on an adaptive two-branch block. This adaptive two-branch block designed using the proposed algorithm includes attention and nonattention branches. An adaptive weight layer would dynamically balance the weights of these two branches while eliminating redundant attributes, thereby ensuring an adaptive balance between them. Subsequently, a channel shuffle coordinate attention block was designed to achieve a cross-group feature interaction to focus on the correlation between features across different network layers. Furthermore, a double-layer residual aggregation block was designed to enhance the feature extraction performance of the network and quality of the reconstructed image. Additionally, a double-layer nested residual structure was constructed for extracting deep features within the residual block. Extensive experiments on standard datasets show that the proposed method has a better reconstruction effect.
May. 25, 2024Vol. 61 Issue 10 1037002 (2024)
Yi Huang, and Tao Xiong
Herein, an end-to-end deep neural network based on iterative adaptive filtering principle is proposed. This network aims to solve the significant image edge blurring caused by the optical structure of simple lenses. A pixel level deblurring filter is proposed, using a single glued lens with a large field of view, to effectively adapt to the spatial changes of blur and restore the blurry features of the input image. The effectiveness of the proposed method is verified through simulation and experiments conducted on a prototype camera system.
May. 25, 2024Vol. 61 Issue 10 1037003 (2024)
Guoli Zhang, Shuai Chang, Yansong Song, and Tianci Liu
At present, most of the multi-spectral pedestrian detection algorithms focus on the fusion methods of visible light and infrared images, but the number of parameters to fully fuse multi-spectral images is huge, resulting in lower detection speed. To solve this problem, we propose a multi-spectral pedestrian detection algorithm based on YOLOv5s with high timeliness. To ensure the detection speed of the algorithm, we select the merging method of visible light and infrared light channel direction as the input of the network, and improve the detection accuracy by improving the traditional algorithm. First, some standard convolution is replaced by deformable convolution to enhance the ability of the network to extract irregular shape feature objects. Second, the spatial pyramid pooling module in the network is replaced by multi-scale residual attention module, which weakens the interference of the background to the pedestrian target and improves the detection accuracy. Finally, by changing the connection mode and adding the large-scale feature splicing layer, the minimum detection scale of the network is increased, and the detection effect of the network for small targets is improved. Experimental results show that the improved algorithm has obvious advantages in detection speed, and improves the mAP@0.5 and mAP@0.5∶0.95 by 5.1 and 1.9 percentage points over the original algorithm, respectively.
May. 25, 2024Vol. 61 Issue 10 1037004 (2024)
Keyan Chen, Qiaohong Liu, Xiaoxiang Han, Yuanjie Lin, and Weikun Zhang
A segmentation network of heart magnetic resonance image that combines prior knowledge in the frequency domain and feature fusion enhancement is proposed to address the issues of unclear boundaries caused due to the small grayscale differences among the heart substructures in heart magnetic resonance images and the varying shapes and sizes of the right ventricular region, affecting segmentation accuracy. The proposed model is a D-shaped structured network comprising a frequency domain prior guidance and feature fusion enhancer subnetworks. First, the original image is transformed from the spatial domain to the frequency domain using Fourier transform, extracting high-frequency edge features and combining the low-level features of the frequency domain prior-guided subnetwork with the corresponding stages of the feature fusion enhancement subnetwork for improving the edge recognition ability. Second, a feature fusion module with local and global attention mechanisms is introduced at the jump connection of the feature fusion enhancer network to extract contextual information and obtain rich texture details. Finally, the Transformer module is introduced at the bottom of the network to further extract long-distance semantic information, enhance the expression ability of the model, and improve segmentation accuracy. Experimental results on the ACDC dataset reveal that compared to existing methods, the proposed method achieves the best results in objective indicators and visual effects. Good cardiac segmentation results can provide reference for subsequent image analysis and clinical diagnosis.
May. 25, 2024Vol. 61 Issue 10 1037005 (2024)
Qingqing Wang, Yuelan Xin, Jia Zhao, Jiang Guo, and Haochen Wang
To address the prevalent focus on reducing the parameter counts in current efficient super-resolution reconstruction algorithms, this study introduces an innovative efficient global attention network to solve the issues regarding neglecting hierarchical features and the underutilization of high-dimensional image features. The core concept of the network involves implementing cross-adaptive feature blocks for deep feature extraction at varying image levels to remove the insufficiency in high-frequency detail information of images. To enhance the reconstruction of edge detail information, a nearest-neighbor pixel reconstruction block was constructed by merging spatial correlation with pixel analysis to further promote the reconstruction of edge detail information. Moreover, a multistage dynamic cosine thermal restart training strategy was introduced. This strategy bolsters the stability of the training process and refines network performance through dynamic learning rate adjustments, mitigating model overfitting. Exhaustive experiments demonstrate that when the proposed method is tested against five benchmark datasets, including Set 5, it increases the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) performance metrics by an average of 0.51 dB and 0.0078, respectively, and trims the number of parameters and floating-point operations (FLOPs) by an average of 332×103 and 70×109 compared with leading networks. In conclusion, the proposed method not only reduces complexity but also excels in performance metrics and visualization, thereby attaining remarkable network efficiency.
May. 25, 2024Vol. 61 Issue 10 1037006 (2024)
Hongda Guo, Xiucheng Dong, Yongkang Zheng, Yaling Ju, and Dangcheng Zhang
In this study, a low-light image enhancement algorithm based on multiscale depth curve estimation is proposed to address the poor generalization ability of existing algorithms. Low-light image enhancement is achieved by learning the mapping relationship between normal images and low-light images with different scales. The parameter estimation network comprises three encoders with different scales and a fusion module, facilitating the efficient and direct learning for low-light images. Furthermore, each encoder comprises cascaded convolutional and pooling layers, thereby facilitating the reuse of feature layers and improving computational efficiency. To enhance the constraint on image brightness, a bright channel loss function is proposed. The proposed method is validated against six state-of-the-art algorithms on the LIME, LOL, and DICM datasets. Experimental results show that enhanced images with vibrant colors, moderate brightness, and significant details can be obtained using the proposed method, outperforming other conventional algorithms in subjective visual effects and objective quantitative evaluations.
May. 25, 2024Vol. 61 Issue 10 1037007 (2024)
Haiyang Ding, Mingli Dong, Chenhua Liu, Xitian Lu, and Chentong Guo
To solve the problem of insufficient use of source image information by existing fusion methods, a method is proposed using rolling guided filter and anisotropic diffusion to extract the base and detail layers of an image, respectively. These layers were then fused using visual saliency mapping and weight map construction, and a certain weight was added to merge the fused layers into the final image. The proposed method was tested and verified using several scenes from an open dataset. The experimental results show that the final images obtained using the proposed method exhibit better contrast, retain richer texture features at edge details, and maintain a uniform image pixel intensity distribution; furthermore, the visual effects and fusion accuracy of the final images are better than other existing fusion methods. Moreover, significant progress has been made in indicators, such as average gradient, information entropy, and spatial frequency.
May. 25, 2024Vol. 61 Issue 10 1037008 (2024)
Jingyu Lu, Haiyang Zhang, Wenxin Wang, and Changming Zhao
The emergence and application of attention mechanisms have addressed some limitations of neural networks concerning the utilization of global information. However, common attention modules face issues with the receptive field being too small to focus on overall information. Moreover, existing global attention modules tend to incur high computational costs. To address these challenges, a lightweight, universal attention module, termed"global-sampling spatial-attention module", is introduced herein based on convolution, pooling, and comparison methods. This module relies on the comparison methods to derive spatial-attention maps for intermediate feature maps generated during deep network inference. Moreover, this module can be directly integrated into convolutional neural networks with minimal costs and can be end-to-end trained with the networks. The introduced module was primarily validated using a randomly selected subset of the ImageNet-1K dataset and a proprietary low-slow-small drone dataset. Experimental results show that compared with other modules, this module exhibits an improvement of approximately 1?3 percentage points in tasks related to image classification and small object detection and recognition. These findings underscore the efficacy of the proposed module and its applicability in small object detection.
May. 25, 2024Vol. 61 Issue 10 1037009 (2024)
Yanqiong Shi, Changwen Wang, Rongsheng Lu, Zhao Zha, and Guang Zhu
To resolve the problems of scattered focus-edge blurring, artifacts, and block effects during the multifocus image fusion, an algorithm based on low-rank and sparse matrix decomposition (LRSMD) and discrete cosine transform (DCT) is designed to achieve the multifocus image fusion. First, the source images were decomposed into low-rank and sparse matrices using LRSMD. Subsequently, the DCT-based method was designed for detecting the focus regions in the low-rank matrix part and obtaining the initial focus decision map. The decision map was verified using the repeated consistency verification method. Meanwhile, the fusion strategy based on morphological filtering was designed to obtain fusion results of the sparse matrix. Finally, the two parts were fused using the weighted reconstruction method. The experimental results show that the proposed algorithm has the advantages of high clarity and full focus in subjective evaluations. The best results for the four metrics, including edge information retention, peak signal-to-noise ratio, structural similarity, and correlation coefficient in objective evaluations, improved by 62.3%, 6.3%, 2.2%, and 6.3%, respectively, compared with the other five mainstream algorithms. These improvement results prove that the proposed algorithm effectively improves focused information extraction from source images and enhances the focused edge detail information. Furthermore, the algorithm is crucial for reducing the artifact and block effects.
May. 25, 2024Vol. 61 Issue 10 1037010 (2024)
Haocheng Qi, Xunbo Yu, Zhaohe Zhang, Xinzhu Sang, Binbin Yan, Xin Gao, and Shujun Xing
A light-field display device based on dual-layer halftone image joint encoding is proposed herein, consisting of collimated backlight, a double-layer film, a filter, an aspherical cylindrical lens array, and a vertical diffusion film. The double-layer film is used for displaying halftone light-field-encoded images; the filter is used for generating red, green, and blue channels; and the aspherical cylindrical lens array and the vertical diffusion film are used for controlling the direction of light emission. Dense viewpoints and high-grayscale light-field display are obtained with the double-layer film. The number of viewpoints is increased through light-field encoding, and light-field-encoded images are synthesized on double-layer film structures using a halftone image joint optimization method. Thus, the grayscale range is expanded. In a verification experiment, a three-dimensional light-field display effect with dense viewpoints, high grayscale, and color was realized (165 viewpoints with a grayscale of 256×256×256).
May. 25, 2024Vol. 61 Issue 10 1011001 (2024)
Jia Liu, Ji Tan, Xu Wang, Wenqing Su, and Zhaoshui He
The binary defocusing technique (BDT) is advantageous in high-speed dynamic three-dimensional (3D) measurement. However, its depth range is limited, since the defocused projection mode determines that it can only obtain high-quality measurement results when the defocusing degree is appropriate. To expand the measurement depth, this study proposes a deep learning-driven binary focusing projection 3D measurement method. The proposed method does not necessarily consider the influence of defocusing degree, thus overcoming the limitations of BDT. Furthermore, a two-stage deep learning framework is designed to process binary fringes. In this framework, the adversarial learning realizes the generation of high-quality sinusoidal fringes in the whole depth range. Moreover, the branch residual learning outputs fringe orders to assist phase unwrapping, reducing the edge jump error caused by the traditional BDT. The experimental results show that the proposed method significantly expands the measurement depth range while maintaining high-quality 3D reconstruction in the whole depth range.
May. 25, 2024Vol. 61 Issue 10 1011002 (2024)
Yanfang Zhao, Peng Sun, Mingli Dong, Qilin Liu, Bixi Yan, and Jun Wang
Space operations such as on-orbit assembly and maintenance hinges on the use of large-scale and high-precision on-orbit measurement methods. Vision measurement holds the greatest potential in this regard. However, insufficient assistant artificial targets necessitate the deployment of on-orbit targets to reliably and accurately calibrate the multi-camera vision measurement system. To address this issue, this study proposes an exterior parameter calibration method using fixed stars and scale rulers. First, we propose an imaging model of fixed stars and scale rulers based on relative exterior parameters to solve the problem of multi-camera localization and orientation when there are insufficient artificial target points. Then, we propose a weighted joint bundle adjustment algorithm based on prior error estimation, which fuses three different kinds of observation data to achieve high-precision exterior parameter calibration. Real data experiments demonstrate that this calibration method yields standard deviations of image errors of the fixed stars and the scale ruler endpoints of 0.48 μm (1/7 pixel) and 0.21 μm (1/16 pixel), respectively. In addition, with this calibration method, the standard deviations of spatial coordinate measurement errors along the X, Y, and Z axes are 0.15 mm, 0.04 mm, and 0.05 mm, respectively, within the measurement range of 2.5 m×1.4 m. This study provides a method and reference data for calibrating vision system parameters in on-orbit applications.
May. 25, 2024Vol. 61 Issue 10 1011003 (2024)
Yu Yao, Yang Zheng, Ziyi Cheng, Chao Gao, Xiaoqian Wang, and Zhihai Yao
The conventional edge detection encounters limitations in practical applications due to its low imaging quality. By contrast, the edge detection encounters based on ghost imaging can achieve a high signal-to-noise ratio for the edge imaging of object. Accordingly, this paper proposes a computational ghost imaging based on the edge detection using the Scharr operator. The Scharr operator has low computational complexity, enhancing its effectiveness for image processing. Hence, a new set of speckle functions is generated by applying the Scharr operator to speckle. When the Scharr operator template is applied to speckle movement, information will miss along a certain direction in edge extraction results. To address this problem, a new operator template is generated by converting the positive and negative values of the operator template. Thus, a new illumination speckle is created by applying the newly generated operator template to the moving speckle, thereby obtaining complete information along all directions in the edge detection results. Additionally, based on the basic method of computational ghost imaging, edges of unknown images are extracted theoretically and experimentally. The simulation and experimental results show that the proposed method can obtain complete and clear edges of the tested object.
May. 25, 2024Vol. 61 Issue 10 1011004 (2024)
Xinjun Zhu, Ruiqun Sun, Linpeng Hou, Haichuan Zhao, Limei Song, and Hongyi Wang
The traditional quality guided phase unwrapping method cannot correctly perform phase unwrapping for multiple objects. To overcome this problem, this study proposes a stereo quality guided phase unwrapping method based on region segmentation. Based on the phase edge of the isolated object, the wrapped phase is divided into several regions, and a stereo matching algorithm establishes the initial point of multi-view binocular phase unwrapping for each isolated region. Furthermore, the quality guided phase unwrapping algorithm realizes the phase unwrapping of multi-view isolated object. A single-frequency fringe structured light three dimensional (3D) measurement based on regional binocular stereo unwrapped phase matching is proposed, which achieves 3D reconstruction of multiple isolated objects under a single-frequency wrapped phase. The experimental results show that the proposed method can achieve a 3D reconstruction of multiple isolated objects in motion. The mean absolute error of diameter for the reconstruction of a standard sphere under four-step phase shifting and single-frame conditions is 0.0135 mm and 0.0347 mm, respectively.
May. 25, 2024Vol. 61 Issue 10 1011006 (2024)
Zixiong Peng, Zhenping Xia, Yueyuan Zhang, Chaochao Li, and Yuanshen Zhang
Three-dimensional (3D) imaging technology is widely used in augmented, virtual, and mixed realities. Dynamic virtual spatial distortion is an important factor that affects visual comfort. This study analyzes the processes involved in 3D image acquisition, display, and human eye perception to quantify the spatial distortion of virtual space in 3D imaging accurately. This study also simulates different spatial distortions that may occur in the process. The point cloud data of the object in the virtual space before and after distortion are compared and analyzed by first dividing and then aggregating. The quantitative model of static geometric distortion is thus established. The dynamic geometric distortion quantification model is obtained by combining the static model and the object motion attributes. The effectiveness of the proposed method is verified by simulating 10 different degrees of geometric distortion based on six groups of point clouds and comparing the subjective and objective consistencies between the proposed and classical method through subjective evaluation experiments. The results demonstrate that the proposed method has the best index performance in quantifying the geometric distortion of virtual space, and the Pearson's linear correlation coefficient obtained is 0.93, which accurately reflects the geometric distortion perceived by the test subjects. The research will provide a theoretical reference for the research in geometric distortion optimization and visual comfort improvement of 3D displays.
May. 25, 2024Vol. 61 Issue 10 1011007 (2024)
Yihua Wu, Zheng He, and Shengmei Zhao
A classification method based on support vector machine and correlation imaging is proposed to address the problem of unknown object recognition. The method utilizes linear discriminant analysis to extract feature vectors from the objects. Based on these feature vectors, the characteristic speckle patterns are designed and applied to a correlation imaging system. By illuminating the objects with the characteristic speckle patterns, the bucket detector values are obtained from the correlation imaging system. The support vector machine is then employed to discriminate and classify the objects based on these bucket detector values. The feasibility of this approach is validated on the MNIST dataset. The results demonstrate that high classification accuracies can be achieved by the proposed method in all ten classification tasks, with an average classification accuracy of 90.5%. The comparison results with other classification methods indicate that the proposed method has more advantages in accuracy.
May. 25, 2024Vol. 61 Issue 10 1011008 (2024)
Xinyue Chai, Hao Hu, Xiaoxue Hu, Xinru Ma, Sixing Xi, and Xiaolei Wang
Target surface scattering characteristics are the physical basis of terahertz waves used in radar imaging and target recognition and location. The main factors affecting target surface scattering characteristics are the target material and surface roughness. This study uses metal aluminum as an example and fits the Drude model parameters of aluminum at 0.1 THz. Based on the fitting results, the scattering coefficient of a Gaussian random rough aluminum surface is analyzed using Kirchhoff approximation (KA) method. Subsequently, Monte-Carlo rough targets with different roughness are modeled, and the radar scattering cross-section (RCS) is calculated to image the two-dimensional inverse synthetic aperture radar (ISAR). The research results show that the target RCS simulation results are consistent with KA theory analysis, that is, surface roughness is negatively correlated with RCS at a small pitch angle, whereas surface roughness is positively correlated with RCS at a large pitch angle. In addition, in a certain rough range, as the surface roughness increases, the scattering center of the target surface increases, and the ISAR image forms a dense "speckle" effect, which can better reflect the shape and structure of a target.
May. 25, 2024Vol. 61 Issue 10 1011009 (2024)
Maoxin Hou, and Zhaotao Liu
To address the problem of poor reconstructed image quality of traditional ghost imaging in handwritten digit recognition, this paper proposes a quality optimization method for ghost imaging based on the advantageous fast data generation in generative adversarial networks. The proposed method can improve the reconstruction quality of ghost images at a low sampling rate. Furthermore, the method concretely comprised the following steps: initially, a barrel detector collected the light intensity of the handwritten digital image irradiated by a series of scattering spots to obtain the total light intensity value; subsequently, a deep convolutional generative adversarial network applicable to the principle of ghost imaging was built, and the light intensity value was used as an input to train the model; finally, comparative analyses were performed with the traditional ghost imaging method and u-net network to verify the effectiveness and validity of the proposed method. The experimental results show that the reconstructed image obtained using the proposed method is considerably superior to the comparison methods. Additionally, at sampling rates of 0.0625 and 0.25, the peak signal-to-noise ratio and structural similarity of reconstructed image are 18.9%/51.9% and 38.29%/42.35% higher than those obtained using the u-net network, respectively.
May. 25, 2024Vol. 61 Issue 10 1011010 (2024)
Leiying Zhai, Yijie Wang, Liyu Zhao, and Jingchang Nan
The spatial structure of 3D objects is inherently complex, and making an accurate description of the light wave field using specific functions is challenging. Hence, achieving 3D display is very difficult. In this paper, a 3D display technology is proposed by integrating the silicon-based micro-electro-mechanical system (MEMS) 2D scanning platform with the metasurface element. By leveraging the persistence of vision, an on-chip scanning structure was created to realize 3D display. As a result, the object image information was theoretically reconfigured to 3D display. Further, the chromatography method was used to construct 3D display, and the phase value of the single layer 2D image element was obtained using the Gerchberg-Saxton (GS) algorithm. Then, 2D metasurface structures were established based on the geometric phase principle, and the corresponding 2D holographic plane images were achieved based on the principle of Fraunhofer diffraction. Finally, a 3D display was built through those above discrete metasurface holograms according to space and time series. The results show that the peak signal-to-noise ratio of 2D holograms is greater than 20 dB. Moreover, the proposed on-chip 2D scanning platform can assemble nine pieces of 2D holograms within 0.1 s, thereby enabling a reconfigured 3D display that can achieve a frame rate of 11 frame/s. Thus, this research findings provide a miniaturized system-level settlement and theoretical model for fast-modulating 3D display.
May. 25, 2024Vol. 61 Issue 10 1011011 (2024)
Sijing Wang, Shilei Jiang, Bo Wang, Jin Zhang, Xiaowei Chen, Qiang He, Shaoyin Wang, and Xuhang Gong
The automotive head-up display (HUD) system is a type of driving assistance technology that visually projects vehicle information into the driver's frontal field of vision. To meet the diverse needs of drivers for accessing information at various distances—ranging from far to near—during driving, we employ a dual free face-off three-reflection system to design an AR-HUD light path. This design facilitates virtual image distances of 10, 7.5, and 3.5 m, accompanied by corresponding field-of-view angles of 15°×5°, 12°×3°, and 6°×1°, respectively. In this setup, the optical path's image plane at the 3.5 m projection distance shows only essential driving information like speed and fuel level; it is a static image plane. At distances of 7.5 and 10 m, the image planes show additional information such as road conditions, navigation, and other auxiliary driving information. The image plane at a 10-m projection distance can seamlessly integrate virtual imagery with the actual road, with the two image planes dynamically switching based on the proximity to obstacles ahead, effectively alleviating visual fatigue in drivers. Notably, all three light spots at the eye point's center fall within Airy spots while achieving a modulation transfer function closely approaching the diffraction limit. Furthermore, the mesh distortion value is <5%, and the dynamic distortion value is <5′.
May. 25, 2024Vol. 61 Issue 10 1011012 (2024)
Hongzhi Xu, Yu Wang, Lingling Yang, Lu Liu, and Wenhui Hou
Phase-shifting profilometry (PSP) is a well-established technique for the accurate measurement of three-dimensional (3D) shapes. Nonetheless, it faces a significant challenge when the object under study experiences motion, as this can alter the phase-shifts between adjacent fringes, introducing periodic errors known as motion-induced errors. A three-dimensional measurement method for moving objects based on color stripe projection is proposed to address the above issues. This method encodes cosine and sine fringes into the red and blue channels of color images, respectively. Then, a phase shift algorithm is used to extract two phase maps with reverse motion errors from the two color channels. Finally, the average phase map is calculated to compensate for periodic motion errors, and the impact of color crosstalk on this method is further analyzed. Both simulation and real experimental results show that the proposed method can effectively suppress motion errors, achieve accurate three-dimensional measurement of moving objects, and is less affected by color crosstalk.
May. 25, 2024Vol. 61 Issue 10 1011013 (2024)
Li He, and Hualing Guo
Currently, laser ultrasonic synthetic aperture focusing technology (SAFT) is being increasingly used for imaging and detecting internal defects. A method, based on the synthetic aperture postprocessing imaging methods, for achieving high-quality detection of rectangular defects inside a specimen is proposed using laser ultrasonic mode wave imaging optimization under multifusion preprocessing signal technology. Differential calculation, envelope extraction of signals, linear interpolation of maximum values, and removal of artifacts using the mean value are performed on the detected laser ultrasonic mode waves, and then we select the processed mode waves for SAFT imaging. The comparison with the imaging results from mode waves without prior processing indicates that the postprocessing imaging method can accurately and qualitatively identify defects. Furthermore, errors in longitudinal depth detection and transverse width detection of defects are reduced by 2.37% and 30.88%, respectively, improving the accuracy of defect size and their location determination. Thus, the imaging quality is considerably improved, as evidenced by a 1.88-fold increase in the average value of the energy gradient (EOG) function, which characterizes imaging quality. This postprocessing imaging method achieved qualitative and accurate identification of internal defect positions, precise size detection, and high-quality imaging, providing a promising postprocessing solution for laser ultrasound-based internal defect detection methods.
May. 25, 2024Vol. 61 Issue 10 1011014 (2024)
Hao Tong, Jingjing Wu, and Congying An
This study proposes a dense target detection algorithm utilizing array distribution information guidance to address challenges related to positioning errors and false targets commonly occurring during the detection process of numerous similar targets in industrial settings. The methodology involves extracting seed targets from dense target images and implementing a four-direction search matching strategy based on target array layout rules. It forms candidate target matching regions from the surrounding four regions of the seed targets, thereby updating the target position index through a re-indexing algorithm and conducting continuous traversing to precisely position all targets. Additionally, to address the difficulty of detecting similar targets, a Transformer self-attention structure is introduced in front of the convolutional neural network to extract correlation features of positions and categories among samples. Subsequently, a classification network based on the twin convolutional Transformer is devised to enhance structured information within adjacent target images, enabling accurate classification of dense and similar targets and thereby accomplishing robust target detection tasks. Experiments are conducted on a large number of dense target image datasets, and the results show that the proposed algorithm outperforms the comparison algorithms in accuracy, achieving detection and classification accuracy of 98.71%. Therefore, it can effectively extract targets and conduct precise classification.
May. 25, 2024Vol. 61 Issue 10 1012001 (2024)
Haiwen Liu, Yuanlin Zheng, Chongjun Zhong, Kaiyang Liao, Bangyong Sun, Hanxiang Zhao, Jie Lin, Haoqiang Wang, Shanxiang Han, and Bo Xie
Herein, to address the issues associated with traditional manual defect detection in printing production, such as time and effort consumption, difficulty in detecting small defect areas, and poor robustness, an improved YOLOv5l-based printing defect detection algorithm is proposed. First, by expanding the detection scale by adding shallow feature maps to capture small defect information, the ability of the network to detect small targets is improved. Subsequently, the ordinary convolution in the Neck area is replaced with full-dimensional dynamic convolution to enhance the ability of the network to capture contextual printing defect information. Finally, to address the issue of reduced detection speed caused by the aforementioned two modifications, the C3 module in the Neck area is replaced with C3Ghost to improve detection speed to the maximum extent possible with considerably low detection accuracy loss. Experimental results show that the proposed algorithm has a detection speed of 44.1 frame/s, and its mean average precision (mAP) reaches 97.3%, which is 2.9 percentage points and 2.7 percentage points higher than those of the original YOLOv5l algorithm and an existing printing defect detection algorithm-Siamese-YOLOv4, respectively. The proposed algorithm outperforms the original YOLOv5l and Siamese-YOLOv4 algorithms in classifying and locating defects in printed products with high detection accuracy and speed. Thus, the proposed algorithm can be applied to print quality inspection to improve production quality control levels and reduce labor costs.
May. 25, 2024Vol. 61 Issue 10 1012002 (2024)
Chunjian Hua, Mingchun Sun, Yi Jiang, Jianfeng Yu, and Ying Chen
A defect detection model based on improved YOLOv7-tiny is proposed herein to address the problem of different detection methods for different defects on apple surface. Combined with RGB+NIR multispectral images collected by a camera, various defects on the apple surface are detected and classified. First, to extract more effective feature information and improve the ability to locate defects, coordinate attention (CA) is used to aggregate coordinate information in the backbone network, and a contextual transformer (CoT) module is added behind the backbone network to increase the global receptive field. Second, it is combined with the weighted bidirectional feature pyramid to adjust the proportion of each branch in the structure to enhance the feature fusion ability of efficient layer aggregation networks. Finally, the loss function is replaced by Focal-EIoU loss to solve the problem of unbalanced samples. The mean average precision (mAP) @0.5 of the improved network increases by 1.2 percentage points to 93.2%, and the recognition speed is 89.3 frames/s. The research content of this paper provides a more efficient method for apple surface defect detection and a more accurate basis for apple grading.
May. 25, 2024Vol. 61 Issue 10 1012003 (2024)
Shunqin Xu, Lihong Yang, Qinyue Fu, Qianxi Chen, Xingyuan Li, and Hang Ge
Aiming at the problems of low contrast of the optical lens image and low recognition rate of optical lens surface defects under single illumination when detecting optical lens surface defects by machine vision, a visual detection method of optical lens surface defects under dual light sources is proposed. According to the scattering imaging principle, the optical lens images containing defects are obtained by using the image sensor under two different illumination modes, the forward light and the backlight, and then the images are fused into one image by the image fusion algorithm. Finally, the defect size information of optical lens surface is obtained by using the recognition algorithm. Two different defects (scratch, pitting) are detected, and the test results of this system are compared with the processing results of the ZYGO interferometer, and the comparative results show that the pitting error and the scratch error of proposed method are less than 2.7% and 0.8%, respectively, the detection efficiency is inproved by 98.24% compared with the interferometer, and the detection time is shortened. Compared with the detection method under single illumination and manual detection, the identification rate and accuracy of defects detected by the proposed method is higher.
May. 25, 2024Vol. 61 Issue 10 1012004 (2024)
Haoyue Liu, Linghui Yang, Luyao Ma, and Yiyuan Fan
The advancement of intelligent, extendable surface measurement, exemplified by high-speed railway and track detection, necessitates improvements in on-line measurement, efficiency, and accuracy. This requirement presents a new challenge to dynamic performance. Multiframe measurement methods using stereoscopic line-scan camera systems facilitates high-resolution and high-speed data acquisition. Similarly, the three-dimensional shape measurement method, which employs fringe projection with line-scan cameras, facilitates high-resolution and rapid data collection. These methods are advantageous for achieving high-quality three-dimensional reconstruction of extendable surfaces in motion. However, a robust fringe projection measurement method requires multiple frames to obtain accurate phase information, leading to low encoding efficiency. Thus, reducing the measurement period and decreasing the number of required image frames remain critical issues for enhancing dynamic performance. To mitigate these challenges, we introduced a dynamic measurement method for extendable surfaces using stereoscopic line-scan cameras and color-encoded three-frequency-fringe projection. We employed composite stripe projection based on color-structured light to minimize the number of projected patterns and three solid color images for effective crosstalk compensation. We sequentially projected a color-encoded sine fringe and white patterns onto the object, incorporating one-dimensional background normalization to mitigate the influence of the object's surface optical properties. This enables the acquisition of unwrapped phases based on color encoding information. Pixels in the images obtained from both cameras that share identical unwrapped phases are identified as corresponding pixels. The proposed method effectively exploits the dynamic capabilities of line-scan technology, thus achieving high-quality contour mapping through two frames and facilitating texture mapping.
May. 25, 2024Vol. 61 Issue 10 1012005 (2024)
Kuo Zhang, Xinyue Fan, Jiahui Li, and Gan Zhang
Cross-modal person re-identification is a challenging pedestrian retrieval task. Existing research focuses on reducing inter-modal differences by extracting modal shared features, while ignoring the processing of intra-modal differences and background interference. In this regard, a mask reconstruction and dynamic attention (MRDA) network is proposed to eliminate the influence of background clutter by reconstructing the features of human body regions, thereby enhancing the robustness of the network on background changes. In addition, the dynamic attention mechanism is combined to filter irrelevant information, dynamically mine and enhance the discriminating feature representations, and eliminate the influence of intra-modal differences. The experimental results show that the probability the first search result matches successfully (Rank-1) and mean average precision (mAP) in the all-search mode of the SYSU-MM01 dataset reach 70.55% and 63.89%, respectively. The Rank-1 and mAP in the visible-to-infrared retrieval mode of the RegDB dataset reach 91.80% and 82.08%, respectively. The effectiveness of the proposed method is verified on the public datasets.
May. 25, 2024Vol. 61 Issue 10 1015001 (2024)
Xiyang Yin, Pei Zhou, and Jiangping Zhu
Point cloud completion refers to the process for reconstructing a complete 3D model using incomplete point cloud data. Most of the existing point cloud completion methods are limited by the point cloud disorder and irregularity, which makes it difficult to reconstruct the local detail information, thus affecting the completion accuracy. To solve this problem, an attention-based multi-stage network for point cloud completion is proposed. A pyramid feature extractor that satisfies the replacement invariance is designed to establish the dependence between points within a localization as well as the correlation between different localizations, so as to enhance the extraction of local information while extracting global feature information. In the point cloud reconstruction process, a coarse-to-fine completion method is adopted to first generate a low-resolution seed point cloud, and then gradually enrich the local details of the seed point cloud to obtain a finer and denser point cloud. Comparison results of the experiments conducted on the public dataset PCN demonstrate that the proposed network can effectively reconstruct the local detail information, and improves the completion accuracy by at least 5.98% over the existing methods. The ablation experimental results also further validate the effectiveness of the designed attention module.
May. 25, 2024Vol. 61 Issue 10 1015002 (2024)
Hao Tang, Dong Li, Cheng Wang, Sheng Nie, Jiayin Liu, and Ye Duan
To address the issue of drift errors and inadequate precision in point clouds produced by laser-based simultaneous localization and mapping (SLAM) algorithms during lengthy scanning trajectories, this study presents a global point cloud registration approach for laser SLAM that relies on graph optimization. We constructed initial and iterative pose graphs for cascaded optimization in succession for laser SLAM point clouds with specific drift errors. The pose graph is initially created using point cloud similarity and centroid distance of segments to reduce trajectory drift error, resulting in SLAM point clouds with smaller drift errors. From this, iterative pose graphs are formed based on the overlap of point clouds between segments. Subsequently, the point clouds are coarsely and finely adjusted in an iterative manner to produce higher precision SLAM point clouds. Experiments were performed in this paper using one set of handheld and three sets of vehicle-mounted laser SLAM data. After optimization, the point clouds of the four experimental data sets were well overlapped by their respective repeated scans. The distance root mean square error (RMSE) between the matched keypoints is reduced to 0.158, 0.211, 0.218, and 0.157 m from 2.667, 10.348, 19.018, and 3.412 m, respectively, before the optimization. Experimental results indicate that the proposed algorithm can resolve the issue of drift error during laser SLAM point cloud long trajectory scanning, ultimately improving the accuracy of the point cloud data.
May. 25, 2024Vol. 61 Issue 10 1015003 (2024)
Qi Ouyang, Mengyao Liu, Yan Ning, Jie Cao, Qun Hao, and Yang Cheng
In this study, a transverse moving infrared optical continuous zoom system based on the Alvarez lens is proposed to address the challenges associated with the complex structure and large volume of traditional axial-moving mechanical optical zoom systems. The system consists of two sets of Alvarez lenses, apertures, focusing lenses, and infrared detectors. Herein, two sets of Alvarez lenses adopt a Kepler-type telescope structure, where the first set of Alvarez lenses functions as the zoom group and the second set of Alvarez lenses serves as the compensation group. The infinitely far incident light passes through two sets of Alvarez lenses and exits, the emitted parallel light is then focused and imaged onto the target surface of the infrared detector through a fixed focal lens. Utilizing Zemax software for optical simulation, our designed optical zoom system covers the 8?12 μm long wave infrared band, with a maximum field of view angle of 6°, a maximum pupil diameter of 6 mm, an F-number of 2, distortion of <2.1%, and a total optical length of ~74 mm. The Alvarez lens only requires to be horizontally moved by ~1 mm to achieve continuous optical magnification from 5× to 15×. Moreover, the modulation transfer function of the proposed optical zoom system can attain up to 0.5@17 lp/mm, assuming a resolution of 320×240 and pixel sizes of 30 μm for the infrared detector. The simulation results indicate that the system has the advantages of high magnification, a compact structure, and high imaging quality, making it a promising candidate for applications in the field of miniaturized infrared zoom imaging.
May. 25, 2024Vol. 61 Issue 10 1022001 (2024)
Xiuzai Zhang, Tao Shen, and Dai Xu
A target detection algorithm based on improved YOLOv8 is proposed to address the issues of high-missed and false-detection rates, inaccurate target positioning, and inability to accurately identify target categories in remote-sensing image target detection algorithms. To improve the flexibility of the loss function of the model in gradient allocation and adapt to various object shapes and sizes, a boundary box regression loss function is designed, which combines a nonmonotonic focusing mechanism with geometric factors of the boundary box. To expand the receptive field of the model and weaken the influence of the remote-sensing image background on the detection target, a residual global attention mechanism is designed by combining global attention mechanism and residual blocks. To adapt the model to the deformation and irregular arrangement of target objects in remote-sensing images, the C2f module in the YOLOv8 model is improved by incorporating deformable convolution and deformable region-of-interest pooling layers. Experimental results show that on DOTA and RSOD datasets, mean average precision (mAP@0.5) of the improved YOLOv8 algorithm reaches 72.1% and 94.6%, which are better than other mainstream algorithms. It improves the accuracy of remote sensing image target detection and provides a new means for remote sensing image target detection.
May. 25, 2024Vol. 61 Issue 10 1028001 (2024)
Xirui Song, and Hongwei Ge
Herein, we propose a Transformer multiattention network (TransMANet), a network structure based on Transformer and attention mechanisms, to address the issues of low segmentation accuracy, inadequate global feature extraction, and insufficient association between the multiattention network (MANet) algorithm and image semantic information. This network structure features a dual-branch decoder that combines local and global contexts and enhances the semantic information of shallow networks. First, we introduce a local attention embedding mechanism that enhances the embedding of context information and semantic information of high-level features into low-level features. Then, we design a dual-branch decoder that combines Transformer and convolutional neural networks, which extracts global context information and detailed information with different scales, thereby modeling global and local information. Finally, we improve the original loss function and use a joint loss function that combines cross-entropy loss and Dice loss to address the class imbalance problem often encountered in remote sensing datasets and thus improve segmentation accuracy. Our experimental results demonstrate the superiority of TransMANet over MANet and other advanced methods in terms of intersection over union on UAVid, LoveDA, Potsdam, and Vaihingen datasets. This indicates the strong generalization capability of TransMANet and its effectiveness in achieving accurate segmentation results.
May. 25, 2024Vol. 61 Issue 10 1028002 (2024)
Ran He, Liang Zhu, Junfa Dong, Zhenzhong Xiao, and Yuming Dong
The LiDAR based on single-photon avalanche diode (SPAD) is widely used in 3D perception due to its advantages of high sensitivity, long detection distance and high integration level. The LiDAR system based on SPAD contains various sub-modules, and studying the influence of different types of sub-modules on the performance of LiDAR system can help optimizing the system scheme, improving R&D (research and development) efficiency, and reducing R&D cost. Therefore, according to the feature of sub-modules, we use the time-correlated single-photon counting technology (TCSPC) and the Monte Carlo method to establish the LiDAR model based on SPAD. The effects on system performance of passive reset circuit and active reset circuit, single-event first-photon TDC (time to digital converter) and multi-event TDC are obtained. The results show that the system performance of the active reset circuit and the passive reset circuit is basically the same under the conditions of the time of fight of 20 ns, the ambient light of 50×103 lx, and the target reflectivity of 10%. After the target reflectivity increases to 50%, the system performance of the active reset circuit is better than that of the passive reset circuit. Similarly, the system performance of multi-event TDC is better than that of single-event first-photon TDC, mainly because the noise of multi-event TDC is uniformly distributed, and compared with single-event first-photon TDC, the peak value of signal count of multi-event TDC is more likely to be greater than the peak value of noise floor count, and the corresponding solution range algorithm is simpler and requires less computing power. The simulation results show that in order to optimize the system performance, the sub-module of the SPAD integrated chip should adopt the architecture of active reset circuit and multi-event TDC.
May. 25, 2024Vol. 61 Issue 10 1028003 (2024)
Chengfeng Li, Tao He, Yuzhi Shi, Zeyong Wei, Zhanshan Wang, and Xinbin Cheng
Deflecting light waves is an important capability in the manipulation of optical fields and serves as a fundamental aspect in numerous optical applications. With the vigorous development of optical technology, there is an urgent need for optical devices that balance miniaturization and beam deflection ability. Metasurfaces, which are planar devices constructed by arranging sub-wavelength nano-structures with specific order, can redirect light waves towards non-specular directions due to the ability to modulate electromagnetic waves with arbitrary customization, offering the potential to play a significant role in practical applications. In this paper, we first introduce the physical mechanisms underlying the high-efficiency anomalous deflection metasurfaces, then provide a review and discussion of the applications of anomalous deflection metasurfaces and finally summarize potential challenges, offer a glimpse into the future development of anomalous deflection metasurfaces and their applications.
May. 25, 2024Vol. 61 Issue 10 1000001 (2024)
Zhijuan Sun, Dongdong Han, and Yonglai Zhang
Microlens arrays, as an optical element, can realize high-quality imaging because of their high resolution and infinite depth of field. Additionally, they exhibit important applications in the fields of optical communication and optical sensing. In recent years, advancements in optoelectronics, micro and nanotechnology, smart materials, and other disciplines have spurred research on the tunability of microlens arrays, enabling microlens arrays to overcome the defects of fixed focal lengths. Furthermore, tunable microlens arrays greatly improve the flexibility of devices. This paper summarizes the recent research progress in three aspects, including shape tuning of microlenses, refractive index tuning, and superlens tuning; describes the principles and methodologies involved in tuning microlens arrays in detail; discusses the advantages and drawbacks of various tuning methods; introduces the application potential of tunable microlens arrays; and finally envisages their future development trends.
May. 25, 2024Vol. 61 Issue 10 1000002 (2024)
Xiadi Ye, Jiangjie Huang, Wen Kong, Lina Xing, Yi He, and Guohua Shi
Fundus imaging plays a vital role in research on the ophthalmology, diagnosis, and treatment of fundus diseases. Confocal scanning laser ophthalmoscope has superior imaging quality, wide applicability, and unique axial resolution, making it dominant in fundus imaging. We present a review of the principle and technical developments of confocal scanning laser ophthalmoscopy in ultra-wide field and high-resolution fundus imaging and analyze the challenges of confocal scanning laser ophthalmoscopy. Finally, we discuss the future development prospects based on existing challenges.
May. 25, 2024Vol. 61 Issue 10 1000003 (2024)
Jiawei Luo, Daixuan Wu, Jiajun Liang, and Yuecheng Shen
Optical scattering induced by microscopic inhomogeneities in the refractive index poses a remarkable challenge to achieve optical focusing inside deep biological tissues. The wavefront shaping technique is emerging as a promising solution to this challenge because optical focusing is achieved through scattering media by compensating phase delays among different scattering paths. The effectiveness of this technique relies on the deterministic design of the scattering medium because even minor changes in scatterers can disrupt phase compensation, thereby resulting in degraded focus quality or complete loss of focus. However, practical applications often involve dynamic scattering processes. For example, physiological activities in living organisms, such as blood flow, heartbeat, and breathing, induce dynamic scattering processes. Consequently, enhancing the modulation speed of the wavefront shaping system is crucial to ensure successful operation in biomedical applications involving live tissues. To address this challenge, this review offers a comprehensive introduction to the state of high-speed wavefront shaping systems, outlines future directions for optimizing system speed, analyzes potential applications in biomedical science, and provides a prospective outlook on the future development of wavefront shaping.
May. 25, 2024Vol. 61 Issue 10 1000004 (2024)
Qi Wang, and Jiashuai Mi
Single-pixel imaging reproduces scene images by modulating the light field to measure the intensity response of the scene with a single-pixel detector. Compared with traditional imaging techniques that rely on arrays of detectors to capture image information, single-pixel imaging excels in low-cost, broad-spectrum, and application-specific scenes. This technique is a novel imaging approach that shifts from the physical to the computational domain; hence, many studies are exploring efficient computational approaches. Owing to the powerful learning capability of neural networks in the computational domain, deep learning techniques have been extensively employed in single-pixel imaging and have made remarkable progress. In this paper, deep learning single-pixel imaging is categorized into three modes: data-driven, physical-driven, and hybrid-driven modes. Within each mode, neural networks are further categorized as "image-to-image" and "measurements-to-image" imaging methods. The basic theories and typical cases of single-pixel imaging methods based on deep learning are reviewed from six perspectives, and the advantages and shortcomings of each method are discussed. Finally, single-pixel imaging methods based on deep learning are summarized and discussed, and promising applications include hyperspectral imaging, transient observation, and target detection.
May. 25, 2024Vol. 61 Issue 10 1000005 (2024)
Zhaoyu Zong, Junpu Zhao, Bo Zhang, Yanwen Xia, Ping Li, and Wanguo Zheng
Single-shot ultrafast optical imaging is a technique that can characterize transient events under universal conditions, opening the door to the study of nonrepeatable and difficult-to-reproduce ultrafast phenomena. It is an essential tool for exploring unknown fields and has great scientific and technological value. This article introduces the research progress of single-shot ultrafast optical imaging in recent years, including the principles, technical characteristics, applications, advantages, and limitations of typical representative technologies. Specifically, we summarize the active detection methods, focusing on 15 representative techniques in 5 subcategories. Then, we provide a brief explanation of the passive detection methods. Finally, we review the applicable scenes and existing problems of various single-shot ultrafast optical imaging techniques and discuss the possible development trend in the future.
May. 25, 2024Vol. 61 Issue 10 1000006 (2024)
Zhuojian Tong, Jinbin Gui, Lei Hu, and Xianfei Hu
Holographic display technology, which is considered to be the most ideal three-dimensional (3D) display technology, can accurately recover 3D image containing all the information of the object and provide the user a natural and real visual experience. Accurate acquisition of 3D real-scene data is important for realizing high-quality holographic 3D display and application. This paper compares various methods of 3D scene data reconstruction, introduces the basic principles of active, passive, and deep-learning-based reconstruction methods, analyzes the characteristics, advantages, and disadvantages of various methods, summarizes the basic methods of 3D reconstruction based on deep learning, and discusses the application prospect of combining them with holographic display technology. This article provides a reference for the further research on holographic 3D displays.
May. 25, 2024Vol. 61 Issue 10 1000007 (2024)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20