








Please enter the answer below before you can view the full text.


2021
Volume: 58 Issue 22
56 Article(s)

Jingjing Zhu, Jingwei Zhang, Ying Mao, and Zhongfeng Qiu
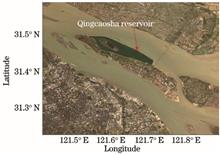
The Qingcaosha reservoir at the Yangtze River estuary is an important source of drinking water, and its water quality must be assessed. This paper takes suspended solids in the water body as a key parameter to evaluate water quality and conducts related research using high spatial resources data of Landsat-8 Operation Land Imager (OLI) to objectively and scientifically evaluate the water quality of Qingcaosha reservoir. An inversion algorithm for suspended particulate matter (SPM) in Qingcaosha reservoir was developed using satellite data and field observations. Field observations were used to verify the accuracy of the developed algorithm. The results showed that the correlation coefficient was high and the root mean square error was low, indicating that the algorithm is effective. In addition, the inversion accuracy is high and the inversion result is credible. The Landsat-8 OLI data from 2013 to 2019 were processed using the proposed algorithm to obtain the average spatial distribution and time distribution characteristics of SPM. The SPM concentration in Qingcaosha reservoir was found to be the lowest in the estuary. The difference of SPM concentration in the reservoir’s upper part is the largest in winter and the smallest in spring. The concentration of SPM in the reservoir’s middle and lower parts is low, and the change is small. According to the research results, the Qingcaosha reservoir at the Yangtze River estuary is clean and has good water quality.
Nov. 10, 2021Vol. 58 Issue 22 2201001 (2021)
Qingrong Wang, Lei Yang, and Songsong Wang
To address the issues associated with traditional methods for mechanical fault diagnosis, such as difficulties in feature extraction and complex classifier training, we proposed a rolling bearing fault diagnosis method based on S-transform and the convolutional neural network (CNN). First, the original data of the bearing were subjected to S-transform to obtain a time-frequency image. Then, secondary feature extraction was performed using the CNN. Next, fault classification was conducted using the classifier and the fault diagnosis of the rolling bearing was performed. Experimental results show that compared with long short-term memory networks, CNN, and support vector machine, the proposed method achieves higher diagnostic accuracy and better stability.
Oct. 29, 2021Vol. 58 Issue 22 2207001 (2021)
Yao Li, Xin Wang, Wentao He, and Baodai Shi
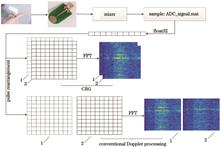
Aiming at the problems of low echo signal-to-noise ratio, large amount of data, and weak interpretability of features in radar micro-motion gesture recognition, a micro-motion gesture recognition system using an ultra-wideband radar based on random forest is proposed. The small radar cross section of the micro-motion gesture causes problems such as low signal-to-noise ratio and blurred positive features. As for these problems, the clustering algorithm is used to extract the main vector of echo and construct polynomial features to reduce redundant data and improve the signal-to-noise ratio of gesture echo signals. For the destruction of interpretability during training process of feature maps, random forest is used to visualize the feature contribution rate and select features for applying to the model. Experimental results show that the algorithm has better recognition performance than other algorithms under echo signals with different noise floors, which verifies the effectiveness of the algorithm.
Oct. 29, 2021Vol. 58 Issue 22 2207002 (2021)
Faqiang Zhang, Bin Feng, and Hongshun Li
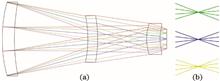
Athermalization is one of the important aspects of infrared optical system design. This article introduces the principle and method of athermalization design of infrared optical system using wavefront coding technology, analyzes the basic principles of wavefront coding, and gives the expression of modulation transfer function (MTF) of wavefront coding optical system. On this basis, the image quality of the three-plate long-wave infrared optical system at room temperature (+20 ℃), -40 ℃ and +60 ℃ is analyzed by using ZEMAX optical design software. The analysis results show that the imaging quality of the system is close to the diffraction limit at room temperature, but when the temperature changes between -40 ℃ and +60 ℃, the MTF value decreases rapidly and appears zero, indicating that the imaging quality of the system deteriorates sharply and no longer meets the requirements of use. The MTF value is no longer sensitive to temperature when the wavefront coding phase plate is added to the design of dethermal error, and a clearer target image can be obtained at different temperatures, indicating that the wavefront coding technology can realize the athermalization design of the infrared optical system.
Oct. 29, 2021Vol. 58 Issue 22 2208001 (2021)
Zeyu Wang, Chenchen Li, YiQiang Gao, Hao Sun, Minghui Yang, and Xiaowei Sun
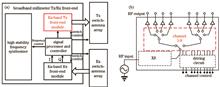
With the application of active millimeter-wave holographic imaging as the background, the heterojunction AlGaAs/GaAs PIN diode millimeter-wave switch developed by the Shanghai Institute of Microsystem and Information Technology, Chinese Academy of Sciences is a key core device in security imaging field. A compensation structure based on high and low impedance transform lines is proposed to optimize the matching degree at high frequencies. A millimeter-wave frequency doubling link, a low-insertion-loss bandpass filter, and a low insertion loss and high isolation switch channel array are designed to achieve a transmission front end that meets the requirements of the system with output power and consistency and good harmonic suppression. The results reveal that in the 28--34 GHz frequency band, the output power of each channel is more than 10 dBm, the harmonic suppression is more than 22 dBc, the channel isolation between channels is more than 23 dB, and the channel difference is less than 2 dB, all of which meet the requirements of active imaging transmitter. The imaging experiment can be performed after integrating the appropriate antenna array and the receiving front end, and the millimeter-wave imaging with a resolution of 0.5 cm can be acquired.
Oct. 29, 2021Vol. 58 Issue 22 2209001 (2021)
Liangfu Li, Nan Wang, Biao Wu, and Xi Zhang
This study proposes a bridge crack image segmentation algorithm based on modified PSPNet to resolve the problems such as the low detection accuracy of the traditional bridge crack detection algorithms, loss of details in crack images and discontinuous findings of the existing mainstream semantic segmentation algorithms. First, the bridge images are acquired using an unmanned aerial vehicle, and the bridge crack datasets are procured via image enhancement processing. Second, the crack features are initially extracted using the residual network with dilated convolution. Then, the extracted features are sent to the serial structure of the spatial position self-attention module (SPAM) and pyramid pooling module, enabling the features to achieve rich contextual information in spatial dimensions. The experimental results reveal that the proposed algorithm obtains more precise crack details compared with the existing mainstream semantic segmentation algorithms, with each segmentation index being greatly improved, reaching 84.31% on mean intersection over the union. The proposed algorithm can extract small bridge cracks accurately and completely.
Oct. 29, 2021Vol. 58 Issue 22 2210001 (2021)
Ke Zhang, and Liang Zhang
Aiming at automatic detection of contraband in security X-ray images is difficult, the EM2Det (Enhanced M2Det) model is constructed using different scale feature proportional balance modules, U-shaped network recursive modules, and residual edge attention modules, which it can further improve the detection performance of the M2Det model. First, considering the high semantic information in the deep layer of the backbone network and the detailed feature information in the shallow layer, the feature fusion enhancement module is designed by referring to the feature pyramid idea to enhance its ability to extract features of different scales in the backbone network. Then, the CBAM (Convolutional Block Attention Module) is used to build a residual edge attention module to focus on effective features and suppress useless background interference. Finally, the model is verified on the SIXray~~OD dataset. The experimental results show that each module of the design has different degrees of improvement effects, and the average accuracy of the EM2Det model is 6.4 percentage higher than that of the M2Det model.
Oct. 29, 2021Vol. 58 Issue 22 2210002 (2021)
Liang Hu, Xuejuan Hu, Zhenhong Huang, Lu Xu, and Lijin Lian
As an efficient method of information fusion, multi-focus image fusion has attracted increasing interests in image processing and computer vision. A multi-focus image fusion algorithm based on discrete Walsh-Hadamard transform (DWHT) and guided filtering is proposed. First, a new focus region detection method is proposed, which uses DWHT and calculates L1 norm to obtain the initial decision map; then, the mathematical morphology method and guided filtering optimization are used to generate the final decision map; finally, the fused image is obtained by using the pixel-wise weighted-averaging rule and the final decision map. In order to verify the effectiveness of the proposed algorithm, three groups of multi-focus images commonly used in research are selected for experiments, and the proposed algorithm is applied to two groups of multi-focus sequence images collected in practical application, compared with other algorithms, the proposed algorithm shows obvious advantages in subjective qualitative analysis and objective quantitative evaluation indicators. Experimental results show that compared with other multi-focus image fusion algorithms, the proposed algorithm can extract the focus region from the source image more effectively, and enhance the detail retention ability and spatial continuity of the fused image.
Nov. 05, 2021Vol. 58 Issue 22 2210003 (2021)
Hanhong Ren, Weiyuan Huang, Nanshou Wu, Jiayi Wu, Jiayi Lin, Yongbo Wu, Chujun Zheng, Xiaofang Jiang, and Zhilie Tang
Motion artifact is a crucial issue in optical coherence tomography angiography (OCTA) top view. A compensated eigenimage filtering (CEF) algorithm is proposed to remove the motion artifact in the top view of OCTA. First, the top view of OCTA is expanded into a series of eigenimages by singular value decomposition (SVD); then, the high-pass eigenimage and the orthogonal compensation product extracted from the first feature image are used to reconstruct the restored image. Experimental results verify that the CEF algorithm can remove stripe noise better, and the image recovered by CEF algorithm has better image quality than the traditional eigenimage filtering algorithm. The CEF algorithm provides a new reference for other scanning imaging systems removing similar stripe noise.
Oct. 29, 2021Vol. 58 Issue 22 2210004 (2021)
Jiansi Liu, Liju Yin, Jinfeng Pan, Yumin Cui, and Xiangyu Tang
Due to the imaging characteristics of images under low illumination and uneven scene light conditions, ordinary edge detection methods cannot effectively detect complete and clear edge images. This paper proposes a new edge detection algorithm based on the advantages of the parameterized logarithmic image processing (PLIP) model, which is sensitive to low-brightness images and the processing effect is close to the results of human visual observation. First, we use the PLIP model theory to derive a new gradient operator, and then analyze the shortcomings of the traditional Canny algorithm to detect the edge process and improve it, and replace the gradient in the traditional Canny algorithm with the new gradient derived from the Canny algorithm. The best edge detection standard extracts the edge of the image. Finally, the edge detection is compared and verified by the low illuminance image obtained by the low-light experimental platform and the image under the uneven scene light environment. The experimental results show that the linear connection degree of the edge detection of the new algorithm is about 10%, 30%, and 4% higher than that of the traditional Canny algorithm, Sobel algorithm, and original LIP algorithm, respectively, and its detection effect is better.
Oct. 29, 2021Vol. 58 Issue 22 2210005 (2021)
Xiangming Qi, and Yifan Feng
This paper proposes an Attention-HardNet feature-matching algorithm in the sub-window scale space to protect the scale space’s edge and corner information and improve the reliability of the feature-matching algorithm. First, a sub-window box filter was used to construct the scale space for fully retaining the scale-space image’s edge and corner information. Second, the FAST algorithm was used to extract the scale-space feature points for increasing the speed of feature-point extraction, and the circular non-maximum suppression algorithm was used to suppress the scale-space feature points. It was optimized to improve the accuracy. Then, the SENet attention mechanism was added to the HardNet feature-extraction network to form the Attention-HardNet network, which extracted more robust 128-dimensional floating-point feature descriptors. Finally, L2 distance was used to measure the similarity of different descriptors. The image’s feature-point matching was complete. On the Oxford dataset, tests on the matching algorithm’s anti-scale, compression and illumination performances show that when compared with the commonly used matching algorithms, the matching accuracy rate of the proposed algorithm has been greatly improved. Compared with the deep learning methods such as L2net and HardNet, the matching accuracy rate of the proposed algorithm is increased by ~3%, and the speed is increased by ~10%.
Nov. 10, 2021Vol. 58 Issue 22 2210006 (2021)
Xiaolong Chen, Ji Zhao, Siyi Chen, Xinhao Du, and Xin Liu
The application of deep learning and self-attention mechanism greatly improves the performance of semantic segmentation network. Aiming at the roughness of the current self-attention mechanism that treats all channels of each pixel as a vector for calculation, we propose a grouped dual attention network based on the spatial dimension and channel dimension. First, divide the feature layer into multiple groups; then, adaptively filter out the invalid basis groups of each feature layer to capture accurate context information; finally, fuse multiple groups of weighted information to obtain stronger context information. The experimental results show that the segmentation performance of this network on the two data sets is better than dual attention network, the segmentation accuracy on the PASCAL VOC2012 verification set is 85.6%, and the segmentation accuracy on the Cityscapes verification set is 71.7%.
Oct. 29, 2021Vol. 58 Issue 22 2210007 (2021)
Binzhou Wang, and Zhiyong Xiao
The content of fine-grained image recognition research is the problem of sub-category recognition under broad categories. The key is to find the key regions in the image and extract effective features from them. Aiming at the problem that the existing methods cannot balance the accuracy and the amount of calculation when locating key areas, a multi-branch network that introduces an efficient channel attention module is proposed in this paper. First, the channel attention is introduced on the basis of the recurrent attention convolutional neural network to locate the target position in the image. Then, the traditional convolution operation is replaced with depthwise over-parameterized convolution, which increases the parameters that the network can learn. Finally, the advanced attention part module is used to cut out multiple image key area components to capture rich local information. Experimental results show that the method has a better recognition effect in weakly supervised situations, and the recognition accuracy rates on the two commonly used fine-grained datasets Stanford Cars and Food-101 are 95.4% and 90.6%, respectively.
Nov. 05, 2021Vol. 58 Issue 22 2210008 (2021)
Jiaxin Wang, Sheng Chen, and Minghong Xie
Aiming at the feature that convolutional sparse coding can better retain image information features, a multi-source image fusion method based on low-rank decomposition and convolutional sparse coding is proposed. In order to avoid the impact of image block processing on the image structure, each image to be fused is processed globally. First, the image is decomposed into low-rank and sparse parts by low-rank decomposition. Then, a set of sparse filter dictionaries can be trained by convolution decomposition of sparse parts, and the convolution sparse coding is applied to image fusion. Second, different fusion rules are designed for the low-rank and sparse components to obtain the low-rank and sparse components, and finally the fusion image is obtained. Finally, in order to verify the fusion effect of the proposed method, the proposed method is compared with other methods. The experimental results show that the proposed method has achieved good results in terms of visual effects and objective evaluation indicators.
Nov. 05, 2021Vol. 58 Issue 22 2210009 (2021)
Zhongzhi Tang, Bing Yan, Yan Huang, Chunrong Hua, and Dong Zheng
A robust scale invariant feature transform (SIFT) algorithm based on bidirectional pre-screening is proposed to resolve the problem of the traditional SIFT algorithm, which includes redundant feature points and large computation. First, feature points are pre-screened using the pixel 8-neighborhood standard deviation similarity method before constructing difference of gauss space. Then, feature points are precisely located via the extremum detection method. Considering low matching efficiency of the traditional random sample consensus (RANSAC) algorithm, an adaptive 3D multi-peak histogram voting method is proposed to filter initial matching, whose results are considered as the initial interior point set of RANSAC to purge initial matching. Finally, the model parameters are calculated in the optimal point set. The experimental results in different types of images indicated that in contrast to SIFT+RANSAC algorithm, the feature point detection time and total running time adopting the proposed algorithm are reduced by the average of 11.7% and 10.7%, respectively. Further, the correct matching numbers are increased by 2.8% on average, while the recall rate and F value are raised averagely by 4.9 percentage and 2.7 percentage, respectively. The effectiveness of the comprehensive performance with the proposed algorithm is validated.
Nov. 05, 2021Vol. 58 Issue 22 2210010 (2021)
Zhenjie Bao, and Ru Xue
In order to protect the image privacy and solve the problem that optical image encryption relies on high precision of optical instrument, an optical image encryption method based on an autoencoder is proposed. In this method, a deep neural network is used to simulate double random phase encoding. The target random image added into the input is used for simulating the first random phase template, and the convolution kernel of the encoding network is used for simulating the second layer random phase template. The experimental results of satellite images show that this method can effectively encrypt optical images, and the pixel distribution of ciphertext images on histograms is relatively uniform. Compared with the encryption method based on CycleGAN, this method is simpler and consumes less computing resources. The peak signal-to-noise ratio (PSNR)value of the encrypted image decreases by 6.5745, and the absolute values of the correlation coefficients of adjacent pixels in the horizontal, vertical, and diagonal directions decrease by0.110375, 0.118625, and0.01335, respectively. The PSNR value of the decrypted image increases by 1.4075, and the structural similarity value increases by 0.0428.
Nov. 05, 2021Vol. 58 Issue 22 2210011 (2021)
Yan Yang, and Jinlong Zhang
Aiming at the problems of color cast and incomplete dehazing in dehazing process, an image dehazing algorithm based on haze distribution and adaptive linear attenuation is proposed. Based on the nature of hazy image degradation and the negative correlation between haze and transmittance, an adaptive linear attenuation model is proposed to estimate the dark channel of clear image, and the transmittance is obtained. According to the characteristic that atmospheric light can only reflect brightness information, the haze distribution can be used to improve the local atmospheric light, and the dehazing result can be obtained by atmospheric scattering model. The experimental results show that the proposed algorithm has the advantages of thorough dehazing, natural color and suitable brightness, and has achieved satisfactory results in both subjective and objective evaluation.
Nov. 10, 2021Vol. 58 Issue 22 2210012 (2021)
Jianmin Zhao, Xuedong Li, and Baoshan Li
It is a time-consuming and laborious task to manually count the number of sheep in the process of pastoral livestock production. Counting the number of sheep in grassland animal husbandry has been helpful for overgrazing monitoring and grassland ecology assessment. A unmanned aerial vehicle (UAV) is used to obtain aerial images, and a UAV sheep counting (USC) dataset is made to provide data support for the study of flock dense counting. Based on the USC dataset, experiments with network models, included MCNN, CSRNet, SFANet, and Bayesian Loss are carried out. The experimental results show that due to occlusion, irregular distribution of sheep, great changes in sheep size, shape, and density, MCNN, CSRNet ,and SFANet models apply the assumed Gaussian kernel to point labeling to calculate the truth density map, which are difficult to achieve high quality. However, the Bayesian loss function proposed by Bayesian Loss model supervises the counting expectation of each sheep’s labeling points. The average absolute error (MAE) of the density map obtained by the Bayesian Loss model is 3.56, the mean square error (MSE) is 5.46, and the average relative error (MRE) is 1.86%, which provides a useful reference for the dense counting of grassland sheep.
Nov. 05, 2021Vol. 58 Issue 22 2210013 (2021)
Hongbo Jia, Yunyu Shi, Xiang Liu, and Jingwen Zhao
At present, there are different degrees of saturation area in a large number of low illumination images,these images are mainly formed due to the large difference in the brightness of the foreground and background. For these kinds of low illumination images, how to enhance the low illumination area while retaining the detailed texture of the saturated area as much as possible has become a difficult point for research. A low illumination image enhancement algorithm based on light remapping is proposed. Starting from the camera imaging principle, the algorithm uses the camera response model to readjust the brightness information through regionalization processing and nonlinear transformation. Experimental results show that the proposed algorithm has the advantages of wide enhancement area, high texture fidelity, and fast speed, etc., which has achieved good results in the subjective visual evaluation and objective indicators.
Nov. 05, 2021Vol. 58 Issue 22 2210014 (2021)
Feipeng Shen, Tong Zhu, Henan Zhang, and Zhenghao Chen
In recent years, there have been a large number of studies on the quality evaluation of non-reference blur images, but many methods ignore the influence of image content on the evaluation results. The blur evaluation methods of the no-saliency object image with pure background and the saliency object image with background are different. Based on the human attention mechanism, the former focuses on the overall blur of the image, while the latter focuses more on the local detail blur of the image. Overall blur refers to the sharpness information of the overall content of the image, while local detail blur refers to the local sharpness information of different locations of the image. The two can better combine visual salience and image content. To solve the above problems, this paper proposes a non-reference blur image quality evaluation method based on saliency object classification. Firstly, this paper proposes an object classification algorithm based on saliency detection, which classifies the saliency objects of the evaluation image, and extracts the local and global blur features according to the classification results. Finally, the two features are fused to obtain the final quality evaluation score. The experimental results show that the algorithm not only achieves the optimal evaluation effect on the BLUR database, but also has good results on the LIVE, CSIQ, and TID2013 databases, with good robustness. In addition, the algorithm in this paper also shows excellent statistical performance in various databases.
Nov. 05, 2021Vol. 58 Issue 22 2210015 (2021)
Bin Fang, and Jiayi Chen
In order to address the deficiencies of existing algorithms for impulse noise removal, and to further improve denoising performance and robustness, a wavelet threshold denoising algorithm for impulse noise removal is proposed in this paper. First, based on the gray-scale characteristic of impulse noise, the randomness and approximate uniformity of its distribution, the noisy pixels are identified by using statistical method. Then, a wavelet denoising method based on an adaptive threshold of the signal-to-noise intensity and a differentiable shrinkage function is used to restore the noisy pixels. The experimental results show that, compared with the existing algorithms, the image visual perception effect, peak signal-to-noise ratio and edge preservation index obtained by the proposed algorithm are greatly improved, and it has better robustness.
Nov. 05, 2021Vol. 58 Issue 22 2210016 (2021)
Benyuan Lü, Zhenfu Zhuo, Yongsai Han, and Lichao Zhang
Aiming at the target detection algorithm based on Faster region-based convolutional neural network, we propose an adaptive candidate-region suggestion network. During training, the number of candidate regions is adjusted according to the current loss feedback to ensure that the candidate regions change dynamically in a certain range for cost savings. The number of candidate regions with the best performance is recorded. The recorded candidate regions are tested during testing. An adaptive confidence threshold selection algorithm is proposed to solve the time cost problem and the reduced accuracy of a small target detection caused by artificial confidence threshold selection when Softmax function is used for classifying candidate regions. Experimental results show that compared with the traditional algorithm, the detection speed of the algorithm improves by 25% and the average detection accuracy improves by 1.9 percentage points.
Nov. 05, 2021Vol. 58 Issue 22 2210017 (2021)
Xiaojuan Ning, Zhiwei Lu, and Jie Ma
Due to diversity of object species, complexity of object geometric information and intensiveness of object in indoor scene such that the reconstruction of the indoor scene structure has a big challenge. First, “structure analysis” is taken as the main line, and the rough division of room layout is detected by using improved random sample consensus (RANSAC) algorithm and mean shift algorithm. Then, on the basis of transforming the preliminary division results into undirected graphs, the subdivision results of room layout are obtained by using graph-cut algorithm. Finally, the overall reconstruction of the indoor scene layout is completed by combining the reconstructed wall, floor and ceiling information. The experimental results show that the reconstruction results obtained by the improved algorithms and the proposed methods are more accurate and better.
Nov. 01, 2021Vol. 58 Issue 22 2210018 (2021)
Zhenli Wang, Qun Wang, Rupo Ma, and Xianyi Chen
Although range Doppler (RD) algorithm is widely used in synthetic aperture radar (SAR) imaging, the poor images produced by this algorithm fail to satisfy the needs of practical applications. In order to solve the key technical problems that restrict the imaging quality of traditional methods, a high resolution SAR imaging algorithm based on optimal sampling length is proposed. The proposed algorithm designs the calculation formula of the initial sampling length according to the imaging parameters of the range direction and azimuth direction of SAR. Combining the obtained initial sampling length and the evaluation criteria of SAR image quality performance with the curve extremum, the optimal sampling lengths of range direction and azimuth direction within a reasonable scope of changes are determined. The experimental results of point target imaging of airborne SAR and the measured data of space-borne SAR show the effectiveness of the proposed algorithm.
Nov. 05, 2021Vol. 58 Issue 22 2210019 (2021)
Haifei Zeng, Changpei Han, Kai Li, and Huangwei Tu
The key step of digital image technology to realize autofocus is effective image sharpness evaluation. Aiming at the problems of poor anti-noise and low real-time performance of traditional gray gradient algorithms, an improved sharpness evaluation algorithm is proposed. First, the image adaptive segmentation threshold is calculated by the OSTU method and the global variance. Then, the adaptive segmentation threshold and the local variance of the image pixels are compared to extract the edge pixels in the entire image. Finally, considering the characteristics of human vision, the multi-direction Tenengrad operator is used to evaluate the image, and then the evaluation operation values of the edge pixels in the image are superimposed to obtain the quantized value of the image sharpness. In order to measure the performance of the improved algorithm, it is compared with the traditional gray gradient algorithm. The experimental results show that compared with the traditional gray gradient algorithm, the proposed algorithm has the advantages of high real-time performance, high sensitivity, and good anti-noise ability.
Nov. 05, 2021Vol. 58 Issue 22 2211001 (2021)
Wenjing Yang, Ming Chen, and Guofu Feng
Affected by strong underwater light attenuation or scattering, underwater images have problems such as color distortion, blur, and loss of detail, which seriously affect the accuracy of underwater target recognition. To address the above problems, this paper proposes a scheme that combines image enhancement for turbid waters and the YOLOv4 algorithm. First, the improved multi-scale Retinex with color restoration is used to enhance the underwater image, and then the fully convolutional generative adversarial network is used to achieve image color correction and detail restoration. Finally, the enhanced image is used for fish target recognition through YOLOv4 algorithm. The results show that the mAP (mean Average Precision) of the proposed method combining the image enhancement method with the YOLOv4 algorithm can reach 89.59%, which is 7.46% higher than that of original image after training, and the detection speed reaches 90 frame·s -1.
Nov. 05, 2021Vol. 58 Issue 22 2211002 (2021)
Haoyue Liu, Wenwei Ma, Xiao Fu, Chengxiu Shen, and Yaling Wang
How to accurately detect the manipulation trace in images is the research focus in digital image passive forensics. Traditional methods use artificial features to detect, without enough robustness. Although the method based on deep learning has strong detection ability, it pays less attention to false detection on normal images. An improved RGB-N image manipulation detection algorithm is proposed. The algorithm uses F1 score to evaluate the detection performance of manipulation targets, and introduces the false detection rate index on normal images to evaluate the practicability of the algorithm. An adaptive spatial rich model filter is designed, a multi-scale fusion feature extraction network is constructed, and the self attention module is connected to enhance the ability of the model to obtain the global information of the images and improve the detection performance; In order to reduce false detection rate, the authenticity judgement module is designed. The output heat map is used to judge whether the detected target is mistaken. Furthermore, a strategy of manipulating target source image to choose negative samples is applied to increase the distinguishing ability of model. The experiment result shows that the F1 score of improved RGB-N model is 0.759 on the data set with target stitching and erasure, the false detection rate is 0.2% on the non manipulated image data set, and the improved RGB-N model has a good robustness under JPEG compression attack.
Nov. 05, 2021Vol. 58 Issue 22 2211003 (2021)
Wenjun Chen, Chao Cong, and Liwen Huang
In the interpretability research of convolutional neural network (CNN), the quantitative analysis of feature information is the focus of the research. In this paper, we proposed a feature measurement method based on information entropy to quantitatively analyze the performance of feature extraction in CNN. Firstly, aiming to the different types of images, the activation histogram of the feature layer is calculated, and then the normalized entropy is calculated to define the characteristic purity. Different CNN models and their feature purity of internal structures were quantitatively evaluated on CIFAR10 and ImageNet datasets. At the same time, visual interpretation was performed by combining class activation maps to verify the relationship between feature extraction ability and feature purity of a specific CNN model. The experimental results show that the feature purity is significantly correlated with the feature extraction ability and classification performance of the model. At the same time, the calculation of feature purity is not dependent on the classification label, is not limited to the specific network structure, and has strong robustness and practical value. The proposed quantitative evaluation method can effectively evaluate the feature extraction performance of CNN.
Nov. 05, 2021Vol. 58 Issue 22 2211004 (2021)
Hui Luo, Jian Li, and Chen Jia
In the rail surface defect detection, the rail surface image has the problem of uneven background, large variation of defect scale, and insufficient sample data. Therefore, this paper proposes a rail surface defect detection method based on image enhancement and improved Cascade R-CNN. First, the improved Retinex algorithm is used to process the rail surface image to enhance the contrast between the defects and the background. Then, an improved Cascade R-CNN is adopted to detect rail surface defects, and the intersection over union (IoU) balanced sampling, region of interest align and complete intersection over union (CIoU) loss are applied to solve the imbalance between training sample IoU distribution and the difficult sample IoU distribution, the misalignment between region of interest and extracted feature map caused by rounding quantization in region of interest pooling, and the inaccuracy of the regression loss Smooth L1 for the regression of predicted bounding box. Finally, the dataset of rail surface defect images is expanded using methods such as flipping transformation, random cropping, brightness transformation, and generative adversarial networks, so as to solve the phenomenon of over-fitting of network training caused by insufficient sample data. Experimental results show that the average accuracy of the proposed method, using ResNet-50 as the feature extractor, can reach 98.75%, which is 2.52% higher than the unimproved Cascade R-CNN, and the detection time is reduced by 24.2 ms.
Nov. 05, 2021Vol. 58 Issue 22 2212001 (2021)
Yunlin Lin, Shuncong Zhong, Jianfeng Zhong, and Tie Xu
Aiming at the problem of simultaneous measurement of three-dimensional (3D) vibration of structures, a monocular vision 3D vibration measurement method based on composite feature patterns is proposed. A monocular camera is used in continuous imaging of the composite feature pattern, which is composed of the circular patterns and sinusoidal fringe patterns and pasted on the surface of the structure to be tested. Barycenter coordinates of circle pattern features are extracted by the image barycenter algorithm, which is used to calculate the two-dimensional vibration information parallel to the imaging plane. Meanwhile, the density information of sinusoidal fringes is extracted by the spectral centrobaric correction method (SCCM), which is used to calculate the vibration information perpendicular to the imaging plane, and then the 3D vibration of the structure can be measured synchronously. The effects of image noise, imaging resolution, and pattern dynamic feature extraction algorithm on measurement performance are analyzed by simulation. Experimental measurement for a cantilevered beam excited by an impulse excitation is carried out, whose results are compared with the ones obtained by Hough transform circle detection algorithm. The experimental results demonstrate that the proposed method can simultaneously measure 3D vibration information of structures with high precision.
Nov. 05, 2021Vol. 58 Issue 22 2212002 (2021)
Zhaoxu Wang, Yanjun Fu, Ye Li, Kejun Zhong, and Wei Bao
Aiming at the limitations of complex calibration model and the need for special targets of the existing line structured light measurement system, a new calibration method for the line structured light measurement system is proposed. The precision guide rail is used to move the plane target at least twice in one direction in space, creating a set of parallel feature lines on the laser plane. According to the principle of vanishing point, a new mathematical model is established to calibrate the direct correspondence between the imaging pixels and the one-dimensional information in the moving direction. Changing the moving direction of the guide rail, the pixel-dimension correspondence in the other two orthogonal spatial directions can be obtained by the same way. Compared with the traditional calibration methods, the proposed calibration model does not need to calibrate multiple sets of spatial relationships of the system, which correspondingly simplifies the traditional calibration process and reduces the accumulation of errors. In addition, the target can be an ordinary plane, which avoids the difficult manufacturing of a special target. The experimental results show that the root mean square error (RMSE) of the measurement results of the proposed method is 0.0359 mm, the mean absolute error (MAE) is 0.0306 mm, which can be efficiently used for line structured light three-dimensional (3D) measurement.
Nov. 05, 2021Vol. 58 Issue 22 2212003 (2021)
Bin Yang, Xiao Yun, Kaiwen Dong, Xixiang Liu, and Han Huang
Traditional human action recognition algorithms in petrochemical scenarios focus only on human behaviors and cannot recognize other dangerous behaviors prompted by human-object interactions, such as cell phone calls and smoking. To solve this problem, this paper introduces the object detection mechanism in skeleton-based human action recognition task and proposes a recognition algorithm for human-object interaction using deep learning. First, we used the OpenPose algorithm for pose estimation and then employed the action recognition method to obtain the initial action label. Second, to solve the problems of losing background and semantic informations in traditional methods, the YOLOv3 algorithm was used to detect the objects of interest and obtain their category and location informations. Then, we characterized the human-object interaction relationship by determining the spatial relationship between humans and objects. Finally, a decision-making fusion strategy was proposed, merging the initial action categories of the human, object information, and human-object interaction relationship, to obtain the final action recognition result. Cell phone calls and smoking behaviors were used as examples to verify and analyze the proposed algorithm. Results show that the proposed algorithm can accurately identify dangerous personnel behaviors in a petrochemical scene.
Nov. 05, 2021Vol. 58 Issue 22 2215001 (2021)
Chunjian Hua, Rui Pan, and Ying Chen
Aiming at the problems of high mismatch rate and low measurement accuracy of the traditional binocular vision measurement method based on feature point matching, a binocular ranging method based on ORB (Oriented Fast and Rotated Brief) feature and random sample consensus (RANSAC) is proposed in this paper. First, the method of combining epipolar constraint based on binocular position information and feature matching based on Hamming distance is used to delete mismatched points, get the correct matching point pair initially screened. Then, the sequential consistency constraint method of nearest neighbors based on k-dimension tree is used to screen out the initial interior point set, and the iterative pre-check method is used to improve the matching speed of RANSAC. Finally, in order to improve measurement accuracy, the sub-pixel point disparity is obtained by quadric surface fitting, and calculated actual distance. Experiments show that the method can effectively improve the matching speed and measurement accuracy of features, and meet the requirements of real-time measurement.
Nov. 05, 2021Vol. 58 Issue 22 2215002 (2021)
Zhengyi Zhang, Jianwei Ding, Huiwen Wei, and Xiaotong Xiao
To address the problem of limited discriminative power in existing person re-identification algorithms owing to the loss of details, a multi-level features cascade for person re-identification algorithm based on attention mechanism is proposed in this paper. First, the algorithm is used to cascade features at different depths to fully utilize the features of various levels and replenish detailed information in high-level feature maps. Then, a pair of complementary attention mechanism modules is introduced to integrate similar pixels and channels in the high-level feature maps, compensate for the space location information in the features, and improve the discriminativeness of the features. Finally, extensive experiments are performed on Market-1501, DukeMTMC-ReID, and CUHK03 data sets. Results show that the algorithm shows better recognition and average accuracies than most current mainstream algorithms.
Nov. 10, 2021Vol. 58 Issue 22 2215003 (2021)
Hongfeng Zhang, Shoudong Ni, Liang Zhao, and Meng Zhang
To solve the problems of low calibration accuracy and poor repeatability of traditional camera calibration methods, a camera calibration method based on sparrow search algorithm (SSA) is proposed. Firstly, the initial values of internal and external parameters of the camera are obtained by using the calibration toolbox in MATLAB software,and the running interval of SSA is determined based on the initial estimates. Then, the camera parameters in the determined interval are optimized by SSA, and a small average reprojection error is obtained. Finally, the results of the proposed calibration method are compared with those of calibration methods based on beetle antennae search algorithm and particle swarm optimization algorithm. It is found that the average reprojection error of the camera calibration method based on SSA is the smallest (0.0326 pixel) and the repeatability of the method is the best.
Nov. 10, 2021Vol. 58 Issue 22 2215004 (2021)
Yunzuo Zhang, Panliang Yang, and Wenxuan Li
Aiming at the problems of large amount of detection data of cable leakage fixtures and low manual detection efficiency in tunnel, a cable leakage fixture detection algorithm in tunnel based on the improved single shot MultiBox detector (SSD) algorithm is proposed. This algorithm uses feature maps with different scales to detect fixture objects, and improves the SSD network structure in terms of network width and network depth. The network width is deepened by combining the Inception structure, the residual structure is used to optimize network depth structure while increasing network depth, the depthwise separable convolution and 1×1 convolution structure are used to reduce the amount of model parameters and improve the model structure, so as to improve the model detection efficiency. The improved model is applied to the image detection of cable leakage fixture in tunnel. Experimental results show that the average detection accuracy of this algorithm reaches 86.6%, and the detection speed reaches 26.6 frame/s, which has obvious advantages over the original SSD algorithm and MobileNet SSD algorithm.
Nov. 05, 2021Vol. 58 Issue 22 2215005 (2021)
Jiaojiao Kou, Xiaoxue Chen, Yuehua Yu, Linqi Hai, Pengbo Zhou, Haibo Zhang, and Guohua Geng
The three-dimensional dense point cloud model of cultural relics obtained by laser scanners can easily lead to excessive consumption of resources in data storage, remote transmission, and processing. To solve this problem, the paper proposes a fast compression and recovery framework based on greedy algorithm. First, the point cloud model is regarded as a three-dimensional discrete geometric signal, and the octree method based on Hash function is used to construct the neighborhood constraint relationship for the dense point cloud. Then, the point cloud adjacency matrix is calculated and a discrete Laplacian is constructed to sparse the original signal, and the original signal is randomly sampled through a random Gaussian matrix to complete signal compression. Finally, the L0 regularization operator and four classical greedy algorithms are introduced to solve the problem quickly. The simulation test is carried out with the point cloud model of the terracotta warriors head and the three-dimensional cultural relic point cloud model of the Tang Sancai Huren figurines. The results show that this framework can complete the effective compression of the dense point cloud model and the rapid reconstruction of the model.
Nov. 10, 2021Vol. 58 Issue 22 2215006 (2021)
Fangfang Xue, Yueming Wang, and Qi Li
Considering the limitation of manual and contact monitoring of cattle’s daily behavior, this paper proposes a recognition method of the cattle daily behavior based on the spatial relationship of feature parts. First, YOLOv5(You only look once, v5) target detection model is used to locate the position of the cattle feature parts in the image, and the spatial relation vector of the cattle feature parts is constructed based on the position information of the feature parts. Thereafter, the fully connected neural network is used to classify the spatial relation vector to recognize the cattle’s standing, lying, and feeding behaviors. Finally, the method’s feasibility is demonstrated by counting the duration of each behavior in a video. The experimental results show that the method has a high recognition accuracy for the standing, lying, and feeding behaviors of cattle, and the relative error of each behavior duration in the statistical video is low, meeting the needs of daily behavior monitoring of cattle.
Nov. 10, 2021Vol. 58 Issue 22 2215007 (2021)
Hao Wang, and Li Peng
In the face of massive video data, video summarization technique plays an increasingly important role in video retrieval, video browsing and other fields. It aims to obtain important information in input videos by generating short video clips or selecting a set of key frames. Most of the existing methods focus on the representativeness and diversity of video summarization, without considering the multi-scale contextual information such as the structure of the video. To solve the above problems, a video summarization model based on improved fully convolutional network is proposed, in which time pyramid pooling is used to extract multi-scale contextual information, and the fully connected conditional random field is used to label the video frame sequence. Experiments on SumMe and TVSum datasets show that the proposed model achieves better performance than fully convolutional sequence networks, and the F-score indexes on these two data sets are improved by 1.6% and 3.0%, respectively.
Nov. 10, 2021Vol. 58 Issue 22 2215008 (2021)
Zhongfa Liu, Yizhe Yang, Yu Fang, Xiaojing Wu, Siwei Zhu, and Yong Yang
To improve the quality of cell refractive index microscopy imaging and enhance feature recognition, this paper proposes a fusion method for cell refractive index and bright-field micrographs based on convolutional neural network algorithm, which overcomes the shortcomings of traditional fusion methods involving manual formulation of fusion rules, and learns adaptive strong robust fusion functions from training data to obtain better fusion results. The subjective and objective evaluation results show that the proposed method effectively improves the resolution of the cell refractive index micrographs, which in turn improves feature recognition
Nov. 10, 2021Vol. 58 Issue 22 2217001 (2021)
Ming Yang, Quanchang Sun, and Huayi Hou
A blood flow-mediated skin fluorescence spectrum (FMSF) detection system was developed to noninvasively detect the dynamic changes of the fluorescence spectrum of nicotinamide adenine dinucleotide (NADH) in the human skin. The fluorescence probe in the system was simulated and designed to improve the collection efficiency of the NADH fluorescence. First, we constructed a seven-layer human skin structure model and used the Monte-Carlo method for simulating the transmission of photons in tissues. Then, we investigated the influence of the core diameter of the collection fiber-optics, distance between the excitation and collection fiber-optics, and distance between the fiber-optics probe and skin on the fluorescence spectrum detection. Finally, we developed a fiber-optics probe according to the simulation results and applied it to the skin NADH fluorescence spectrum detection. The results show that the NADH fluorescence spectrum can be measured using the FMSF detection system with post occlusion reactive hyperemia, and the NADH fluorescence intensity shows a dynamic change. Compared with the existing technology, the skin NADH detection method based on FMSF technology has the advantages of rapid measurement and noninvasion; thus, providing advanced technology for studying mitochondrial energy metabolism, diabetes, and other related diseases.
Nov. 10, 2021Vol. 58 Issue 22 2217002 (2021)
Jiefei Han, Bobo Lian, and Liying Sun
In the field of computational ghost imaging based on compressed sensing, the design of the measurement matrix has always been a subject of research. The ideal measurement matrix must possess high sampling efficiency, good reconstruction effect, and low hardware-implementation difficulty. To reduce the difficulty of designing and implementing the measurement matrix, this paper proposes a method for constructing a binary measurement matrix based on deep learning. This method uses convolution to simulate the compressed sampling process of the image and trains the image data through the designed sampling network to adaptively and iteratively update the measurement matrix. The results of the simulation and experiments show that the constructed measurement matrix can obtain high-quality reconstructed images under low sampling rate, which further facilitate the practical application of computational ghost imaging.
Nov. 10, 2021Vol. 58 Issue 22 2220001 (2021)
Huawei Zhang, Wenjuan Jia, Jinlong Zhang, and Panfeng Li
Aiming at the problems of halo and artifacts caused by minimum filtering as well as sky distortion caused by insufficient transmittance estimation, one dehazing algorithm is proposed, which is based on quadratic constraints and haze distributions. Firstly, the Canny detection operator is used to obtain the coarse texture distributions of hazy images, and the mist distribution maps of hazy images are obtained on the basis of scene depth. Second, according to the image characteristics, a quadratic constrain model based on adaptive haze coefficients is proposed to estimate the minimum channel of clear images, and the atmospheric scattering model is used to obtain rough transmittance. Third, the transmittance is optimized through adaptive lower boundary constraints and bilateral filtering, and local atmospheric light is improved through morphological operations. Finally, the dehazing images are obtained according to the restoration model. Experiments show that the proposed algorithm has achieved ideal results in both subjective and objective evaluations, and it can better solve the problems including halos, artifacts, and sky distortion in dehazing images.
Nov. 10, 2021Vol. 58 Issue 22 2228001 (2021)
Chengzhou Jiang, Jianbo Liu, Jin Yang, Yong Ma, and Wutao Yao
Lunar calibration is one of the important ways of satellite reflective solar bands on-orbit calibration. The most critical step in lunar calibration is to select the timing of observation. A rapid lunar observation forecast model is proposed, which is suitable for area-array cameras. The model first determines the distribution range of the time window by a fixed time step, and then selects several iso-distance scattering points on the projection circle of the moon in the direction of the satellite field of view, which is used to accurately determine the relationship between the moon and the satellite field of view. Subsequently, it uses the Fibonacci sequence search method to quickly calculate the time window of the moon entering and leaving the camera field of view. The simulation experiments show that the proposed model can improve the computational efficiency, reduce the computation cost, and make the prediction more accurate if compared with the conventional track propagation methods. The average deviation of visibility calculation accuracy between the proposed method and the Satellite Tool Kit (STK) method is in the sub-second scale.
Nov. 10, 2021Vol. 58 Issue 22 2228002 (2021)
Guoliang Yang, Jiaren Gong, Hao Xi, and Dingling Yu
In this study, to suppress the interference of mixed pixels and noise in hyperspectral images (HSI) on abnormal target detection in a complex background and fully extract and utilize the spectral and spatial features of HSI, a HSI abnormal target detection algorithm based on end-member extraction and low-rank and sparse matrix decomposition is proposed. First, optimal fractional-order Fourier transform is applied to the original HSI. Then, the sequential maximum angle convex cone algorithm is used to extract the endmembers of the transformed HSI; subsequently, the end members and corresponding abundance matrix are obtained. The abundance matrix is decomposed into a low-rank background component and an abnormal component with sparse characteristics using the solution of the low-rank and sparse matrix decomposition method with row constraints. Finally, the background covariance matrix is constructed and abnormal targets are detected using the Mahalanobis distance. Experimental results show that the proposed algorithm exhibits good performance in HSI abnormal target detection.
Nov. 10, 2021Vol. 58 Issue 22 2228003 (2021)
Mengli Guo, Shunling Ruan, Caiwu Lu, and Qinghua Gu
An improved road network extraction method of open-pit mine based on DeepLabv3+ is proposed to address road boundary information loss and inaccurate road network extraction during road extraction of open-pit mine images captured using unmanned aerial vehicle. First, the Retinex algorithm is used to preprocess the original images to get a dataset with balanced color and light. Second, because the proportion of pixels between the road region and background are largely different, the proportion weighting method is used to correct the serious imbalance between positive and negative samples in network training. Finally, a densely connected ASPP module with different rates is built using the DeepLabv3+ model to optimize the feature extraction of the open-pit mine road, thereby expanding the receptive field of the road feature points and improving the coverage of multiscale features. Experimental results show that the semantic segmentation method is better than the original DeepLabv3+ algorithm. The mean intersection over union reaches 79.27%, accurately extracting road areas in a large range. The proposed method can be applied to extract the main road network of open-pit mines.
Nov. 10, 2021Vol. 58 Issue 22 2228005 (2021)
Qize Li, Chaoqi He, and Jingbo Wei
Due to high-quality earth observation requires spatiotemporal continuous high-resolution remote sensing images, the research on spatiotemporal fusion is widely carried out and focused on Landsat and MODIS satellites. At present, the method of spatiotemporal fusion using convolutional neural networks has been proposed, but the network is shallow, so the fusion performance is limited. Aiming at the most widely used one-pair image spatiotemporal fusion, a new spatiotemporal fusion method based on deep neural network is established. Firstly, the basic network framework consists of two cascaded upsamplers with quadruple magnification to approximate the spatial difference and sensor difference between Landsat and MODIS satellites. Then, the residual error between the reconstructed image and the real image is learned by the convolutional neural network to make the reconstructed image closer to the real image. Moreover,the time prediction is carried out by highpass moduation strategy. Finally, the proposed method is tested on different Landsat and MODIS satellite images and compared with many spatiotemporal fusion algorithms. The experimental results show that, compared with the existing fusion algorithms, the reconstruction effect of the proposed method is better and the processing speed is faster.
Nov. 10, 2021Vol. 58 Issue 22 2228006 (2021)
Chuanzhou Liu, and Linghua Zhang
In the field of wireless sensor network positioning, the DV-Hop algorithm is widely used for its simple implementation. Aiming at the problem of large positioning error, a weighted positioning algorithm based on DV-Hop multiple communication radii is proposed. The algorithm refines and optimizes the number of hops through multiple communication radii and the introduction of correction factors, then corrects the average hop distance through the minimum mean square error criterion and weighted method, and finally estimates the coordinates of unknown nodes with the weighted least squares method. Through simulations, it is concluded that the positioning accuracy of the proposed algorithm is improved by about 60.5% compared with the DV-Hop algorithm and by about 36.4% and 13.8% compared with the dual communication radius optimization algorithm and the 3-DV-Hop algorithm respectively under the same experimental conditions.
Nov. 10, 2021Vol. 58 Issue 22 2228007 (2021)
Chao Chen, Xingyuan Zhang, and Siye Lu
Aiming to solve the problem of difficult quantitative identification of surface defect depth during laser ultrasonic detection, a particle swarm (PSO) optimized quantitative identification method for BP neural network surface rectangular defect depth is proposed. Based on the thermoelastic mechanism, a finite element model for laser ultrasonic detection of aluminium materials containing surface defects was established by using the finite element software COMSOL, the transmission wave signals corresponding to defects of different depths under pulsed laser irradiation were obtained, and then the time domain peak, centre frequency, 3 dB bandwidth in the frequency domain, upper cut-off frequency, and lower cut-off frequency of the transmission wave signals were extracted as the feature vectors of the neural network. A quantitative recognition model of PSO-BP neural network defect depth was developed to achieve the quantitative recognition of defects from 0.1 mm to 3 mm in depth. The calculation results show that the BP neural network optimized by the particle swarm algorithm can accurately identify the depth information of metal surface defects, and the relative error of identification is within 6%, which proves that the neural network model has certain feasibility and accuracy for the identification of rectangular defect depth.
Nov. 10, 2021Vol. 58 Issue 22 2228008 (2021)
Yangping Wang, Xibing Liu, Jingyu Yang, and Jianwu Dang
When the patch-based multi-view stereo (PMVS) algorithm is applied to the three-dimensional (3D) scene reconstruction of multi-view remote sensing terrain images, due to the existence of weak texture and areas with no obvious change of gray value, there is the phenomenon that the reconstructed 3D terrain point cloud has low density of overall distribution and local holes. Combining the characteristics of remote sensing terrain images, this paper proposes an improved PMVS algorithm based on the concurrent SIFT operator of the image block and the ground elevation scope constraint. Firstly, uniform feature points with dense distribution are obtained in the feature extraction stage. Then through the propagation process of matching based on the ground elevation scope constraint, the seed patches are efficiently calculated. Finally, the 3D point cloud data of the terrain images is obtained by the iteration of the expansion and by filtering of seed patches. Experimental results show that compared with the original PMVS algorithm, the improved PMVS algorithm in this paper can reconstruct dense point clouds on multi-view remote sensing terrain images with wide and weak textures, effectively repair holes in the terrain point cloud scene, and improve the reconstruction time efficiency.
Nov. 10, 2021Vol. 58 Issue 22 2228009 (2021)
Xiao Wang, Shijie Tu, Xin Liu, Yuehan Zhao, Cuifang Kuang, Xu Liu, and Xiang Hao
Super-resolution microscopy techniques are versatile and powerful tools for visualizing organelle structures, interactions, and protein functions in biomedical research, and its resolution ability to break the optical diffraction limit provides new analytical frameworks for cell biology on the nanoscale, which is indispensable to life science related fields. However, due to the effect of the diffraction limit, the axial resolution of a super-resolution microscope is more arduous to improve than the lateral resolution, which hinders the realization of sub-hundred-nanometer resolution three-dimensional imaging of cellular structures. Therefore, based on the two main techniques, stimulated emission depletion microscopy and single-molecule localization microscopy, the present paper introduces the principles and characteristics of a variety of existing three-dimensional imaging techniques, and finally discusses the future of that. Finally, we briefly discuss the research trend of the two techniques in the three-dimensional imaging area.
Oct. 19, 2021Vol. 58 Issue 22 2200001 (2021)
Jinqiu Rao, Liyi Chen, Pengpeng Bai, Tingting Zhang, Qiduo Zhao, and Feng Qiu
As an important traditional Chinese medicines (TCMs) for promoting qi, activating blood, and relieving pain, Curcuma has attracted wide attention in recent years. In order to identify and control the quality of four origins of Curcuma, the terahertz time-domain spectroscopy combined with chemometric method (support vector machine method and principal component analysis method) was used to classify and identify the four origins of Curcuma. In this study, three models of slope loss multi-class support vector machine methods (Ramp Loss K-SVC method), random forest (RF), and extreme learning machine algorithm (ELM) were constructed to distinguish Curcuma with four different origins. It was developed the Ramp Loss K-SVC method and optimized the model parameters that the identification rate of the four types of Curcuma were increased to 93%. This paper provides a new identification technique for the identification of four easily confused origins.
Oct. 29, 2021Vol. 58 Issue 22 2200002 (2021)
Jun Jiao, Yang Sheng, Biao Wang, Qingxiao Ma, Chun Li, and Ling Jiang
Recently, the spectroscopy technology has advanced extremely rapidly. It can utilize the characteristics of light absorption, reflection, and transmission of materials to perform the qualitative and quantitative analysis of materials. It is a fast, nondestructive detection technology widely used in the testing of agricultural products. Walnut is an important agricultural product with rich nutritional value and long cultivation history in my country. Many scholars have conducted long-term and in-depth research on walnut. This review summarizes the research progress on hyperspectral and infrared spectroscopy with respect to walnut detection from four aspects: variety identification, growth monitoring, quality identification, and sorting and processing. Furthermore, this review compares and analyzes the advantages and disadvantages of various spectral detection technologies and proposes existing problems in walnut correlation detection. The development prospect of walnut nondestructive testing is prospected.
Oct. 29, 2021Vol. 58 Issue 22 2200003 (2021)
Shiyu Deng, Chengzhi Liu, Yong Tan, Delong Liu, Chunxu Jiang, Zhe Kang, Zhenwei Li, Cunbo Fun, Chengwei Zhu, Nan Zhang, Long Chen, Bingli Niu, and Zhong Lü
As a way to obtain the feature information of space targets, the spectral observation technology provides an important solution for the identification and performance analysis of the surface materials of space targets. At present, the degree of precision of optical information collection components is high, so the space target observation technology also shows diversity. Based on the 1.2 m space target optical telescope at the Changchun Satellite Observatory, three terminal devices of the push-broom grating spectrometer, the optical fiber spectrometer, and the filter spectrometer camera are used to observe stars and space targets and thus spectral data are obtained. Further, the adaptive analysis of the observation technology is conducted through the data. The results show that the three methods are all suitable for the observation of stars and high-orbit space targets, and can obtain better spectral data. In contrast, the filter spectroscopic cameras and the fiber spectrometers are suitable for observing the low-orbit space targets, however the push-broom grating spectrometers and the filter spectroscopic cameras are suitable for observing the medium-orbit space targets. In addition, the filter spectroscopic cameras can provide an observation reference for the acquisition of spectral data of precision-tracked space targets. For different application environments, the equipment cost, the optical path debugging degree, the obtained light intensity, the adjustable observation band, and the degree of data processing can be used as a reference for subsequent programs.
Nov. 10, 2021Vol. 58 Issue 22 2230001 (2021)
Kunshan Gu, and Jifen Wang
To achieve fast, non-destructive, and accurate classification of paint evidence, the infrared raw and derivative spectral data of fifty paint samples from five common crime scenes were collected. The paint classification models based on KNN, SVM, and stepwise discriminant analysis were created using spectral fusion technology. The experimental results show that the three classification models for the fusion spectrum have a higher recognition rate than a single spectrum. The recognition rate of the KNN and SVM classification model for three paint samples is high, but the classification effect for the remaining two samples is not good. The recognition rate of the stepwise discriminant analysis completely model for all kinds of spectral data of five paint samples is higher than that of the KNN and SVM models. To achieve 100% recognition of the training and test sets, the Smallest F ratio discriminant model of stepwise discriminant analysis identifies the first derivative and third derivative spectral fusion data. This method has high efficiency and strong qualitative ability, and it meets the requirements for rapid inspection of relevant material evidence by public security organs. It also provides criminal technicians a quick way to identify paint evidence.
Nov. 10, 2021Vol. 58 Issue 22 2230002 (2021)
Xinyi Fang, Xiaoxia Wan, Shuo Shi, Xiao Teng, and Junyan Yu
In order to solve the problem of real color reproduction in real three-dimensional images of multispectral lidar system, a dimensionality reduction method of multi-spectral color data based on sparse signal representation is proposed in this paper. This method utilizes dictionary learning and alternate update of sparse coding to correct spectral errors in an iterative way. Root mean square error of the experimental results show that the proposed method is the principal component analysis is reduced by 35.29%, the average of spectrum fitting coefficient reaches more than 99.8%, and the average of chromaticity accuracy than principal component analysis on average increases by 70.23%, under different light source observation conditions still can maintain the stability of color, its reconstruction precision is better than that of the principal component analysis. The sparse representation can recover high-dimensional sparse signals through low-dimensional observation vectors. This method can accurately recover a large number of test samples from a relatively small number of training samples, which improves the cost efficiency of data processing and is of great help to truly reflect the ground object information of remote sensing multi-spectral images.
Nov. 10, 2021Vol. 58 Issue 22 2230003 (2021)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20