








Please enter the answer below before you can view the full text.


2025
Volume: 62 Issue 6
46 Article(s)

Jun Wu, Long Jin, Shuo Huang, Jinsong Lian, Jiusheng Chen, and Runxia Guo
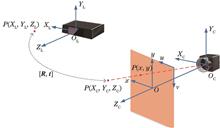
To address the issues of high computational complexity and insufficient real-time performance encountered in three-dimensional object detection for complex aircraft maintenance scenes, a three-dimensional object detection method which integrates visual camera and LiDAR data and based on prior information is proposed. First, the parameters of a camera and LiDAR are calibrated, the point cloud obtained by LiDAR is preprocessed to obtain an effective three-dimensional point cloud, and the YOLOv7 algorithm is used to identify aircraft fuselage targets in the camera images. Next, the depth of the target object is calculated based on its prior length using the Efficient Perspective-n-Point (EPnP) method. Finally, depth information and point cloud clustering methods are utilized to complete three-dimensional object detection and identify obstacles. Experimental results show that the proposed method can accurately detect targets from environmental point clouds, with a recognition accuracy of 94.70%. Furthermore, the processing time for one frame is 42.96 ms, which indicates good performance in terms of both recognition accuracy and real-time capability, thus satisfying the collision risk detection requirements during aircraft movement.
Mar. 25, 2025Vol. 62 Issue 6 0637001 (2025)
Haitao Yin, and Changsheng Zhou
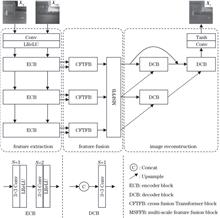
Existing infrared and visible image fusion methods cannot effectively balance the unique and similar structures of infrared and visible images, resulting in suboptimal visual quality. To address these problems, this study proposes a cross-fusion Transformer-based fusion method. The cross-fusion Transformer block is the core of the proposed network, which applies a cross-fusion query vector to extract and fuse the complementary salient features of infrared and visible images. This cross-fusion query vector balances the global visual characteristics of infrared and visible images and effectively improves the fusion visual effect. In addition, a multi-scale feature fusion block is proposed to address the problem of information loss caused by the down-sampling operation. Experimental results on the TNO, INO, RoadScene, and MSRS public datasets show that the performance of the proposed method surpasses existing representational deep-learning-based methods. Specifically, comparing with the suboptimum results on the TNO dataset, the proposed method obtains ~27.2%, ~29.2%, and ~9.9% improvements in terms of standardized mutual information, mutual information, and visual fidelity metrics, respectively.
Mar. 25, 2025Vol. 62 Issue 6 0637002 (2025)
Yaling Ju, Xiucheng Dong, Bing Hou, Jinqing He, and Xiao Yong
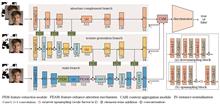
An improved multilayer progressive guided face-image inpainting network is proposed to solve problems such as artifacts and incongruent facial contours after face-image inpainting. The network adopts an encoding-decoding structure comprising structure-complement, texture-generation, and main branches, and gradually guides the generation of structure and texture features among different branches. A feature-extraction module is introduced to enhance the connection between different branches when the feature transfer is carried out in different branches. Additionally, a feature-enhancing attention mechanism is designed to strengthen the semantic relationship between channel and spatial dimensions. Finally, the output features of different branches are passed on to the context aggregation module such that the inpainting images become more similar to the actual images. Experimental results show that, compared with PDGG-Net (Progressive Decoder and Gradient Guidance Network), the proposed network in the CelebA-HQ dataset presents average improvements of 0.003 and 0.13 dB in terms of the SSIM and PSNR, respectively. To prevent overfitting, multi-dataset joint training and fine-tuning are performed in the sparse profile dataset, which improves the SSIM and PSNR by 0.003 and 0.29 dB on average, respectively, compared with the results of direct training using the profile dataset.
Mar. 25, 2025Vol. 62 Issue 6 0637003 (2025)
Lijing Bu, Beini Yang, Guoqiang Dong, Zhengpeng Zhang, Yin Yang, and Yujie Feng
To address the challenges in traditional image restoration algorithms based on regularization models that the information encapsulated in the regularization term prior may not be sufficiently rich, and determining the regularization coefficients can be cumbersome or require adaptive adjustments, combining the advantages of traditional and deep learning methods, this paper combines L2-norm regularization with deep learning, proposes a deep learning network with strict mathematical model foundation and interpretability: interpretable deep learning image restoration algorithm with L2-norm prior. Nonlinear transformations are employed to replace the regularization term in the traditional model, and deep learning networks are utilized to solve the regularization model. This not only optimizes the model solving process but also enhances the interpretability of the deep learning network. Experimental results demonstrate that the proposed algorithm is capable of effectively removing image blurriness while suppressing image noise, thereby improving image quality.
Mar. 25, 2025Vol. 62 Issue 6 0637004 (2025)
Yue Wang, Haifeng Zhang, Fengying Yue, and Xiaodong Song
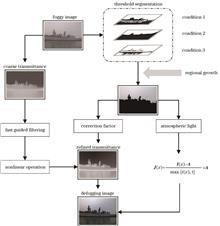
To address the problems of detail loss, low brightness and color distortion when processing sea fog images by dark channel prior defogging algorithm, this paper proposes a sea fog image defogging algorithm based on sky region segmentation. First, accurate segmentation of the sky region is achieved through threshold segmentation and region growing. On this basis, an approach with stronger anti-interference capabilities is used to optimize the atmospheric light intensity, the median value of the top 0.1% pixels belonging to the region with the highest luminance is chosen as the atmospheric light intensity. Second, the transmittance is refined using fast bootstrap filtering and an adaptive correction factor is introduced to adjust and optimize the transmittance mapping. Finally, the obtained transmittance and atmospheric light intensity are utilized with an atmospheric scattering model to restore the defogging image. Experimental results demonstrate that the algorithm significantly enhances evaluation metrics such as structural similarity and peak signal-to-noise ratio, effectively improving the quality of the defogging image.
Mar. 25, 2025Vol. 62 Issue 6 0637005 (2025)
Qinghua Su, Jianhong Mu, Wenhui Liang, Xiyu Wang, and Juntao Li
With the traditional attention mechanism, the representational ability and detection performance of the model are limited or its complexity and calculation cost are high. To solve these problems, an innovative lightweight multi-head mixed self-attention (MMSA) mechanism is proposed, aimed at enhancing the performance of object detection networks while maintaining the model's simplicity and efficiency. The MMSA module ingeniously integrates channel information with spatial information, as well as local and global information, by introducing a multi-head attention mechanism, further augmenting the network's representational capabilities. Compared to other attention mechanisms, MMSA achieves a superior balance between model representation, performance, and complexity. To validate the effectiveness of MMSA, it is integrated into the Backbone or Neck portions of the YOLOv8n network to enhance its multi-scale feature extraction and feature fusion capabilities. Extensive comparative experiments on the CityPersons, CrowdHuman, TT100K, BDD100K, and TinyPerson public datasets show that, compared with the original algorithm, YOLOv8n with MMSA improved their mean average precision (mAP@0.5) by 0.9 percentage points, 0.9 percentage points, 2.3 percentage points, 1.0 percentage points, and 1.7 percentage points, respectively, without significantly increasing the model size. Additionally, the detection speed reached 145 frame/s, fully meeting the requirements of real-time applications. Experimental results fully demonstrate the effectiveness of the MMSA mechanism in improving object detection outcomes, showcasing its practical value and broad applicability in real-world scenarios.
Mar. 25, 2025Vol. 62 Issue 6 0637006 (2025)
Dahua Li, Wenpeng Zheng, Xuan Li, Xiao Yu, and Qiang Gao
In the infrared- and visible-image alignment of power equipment, severe nonlinear radial aberrations as well as significant viewing-angle and scale differences occur between the infrared and visible images, which result in image-alignment failure. Hence, a local normalization-based algorithm for the infrared- and visible-image alignment of power equipment is proposed. First, local normalization was performed to eliminate the nonlinear distortion of the images and improve the accuracy of the curvaturescale space (CSS) algorithm in extracting the feature points. Subsequently, the main direction of the feature points was calculated based on the local curvature information, and the multiscale oriented gradient histogram (MSHOG) was used as the feature descriptor. Finally, the features were matched using the proposed accurate matching method to obtain the parameters of the inter-image projective transformations. The proposed algorithm has average root mean square errors of 2.18 and 2.24 and average running times of 13.09 s and 12.07 s under infrared- and visible-image datasets of electric power equipment, respectively. Experimental results verify the effectiveness of the method in addressing images to be aligned with obvious differences in viewpoints and proportions, as well as in realizing the high-precision alignment of infrared and visible images of electric power equipment.
Mar. 25, 2025Vol. 62 Issue 6 0637007 (2025)
Tongyu Li, Jie Chen, Mengyue Zhang, Jiangning Yang, Dianji Jia, and Yuan Li
Due to significant brightness differences in airborne flare-containing marine optical images, the image enhancement process may result in low contrast and fuzzy details. To solve these problems, an image enhancement method based on local compensation and non-subsampled contourlet transform (NSCT) is proposed. First, the image is segmented into high-brightness area and low illumination area by mean filtering and the maximum interclass variance method. Then, contrast limited adaptive histogram equalization (CLAHE) algorithm is used to balanced image brightness of high-brightness area, and NSCT algorithm is used to decompose the low illumination area into low-frequency component and several high-frequency components. Subsequently, the uneven illumination of low-frequency component is corrected by the multi-scale-Retinex algorithm, while the high-frequency components are adjusted to improve the details by Laplace operator. The processed low-frequency and high-frequency components are subjected to NSCT reconstruction, and CLAHE algorithm is used to further improve the contrast of image. Finally, by using improved local compensation model, the enhanced low-illumination area is compensated, and therefore the enhanced image can be obtained. Experimental results show that, compared with other methods, the image information entropy, average gradient, and contrast of the algorithm in this paper are improved by 1.35%, 40.62%, and 77.15% on average. Besides, the enhanced image also performs better in terms of image brightness, contrast and texture details.
Mar. 25, 2025Vol. 62 Issue 6 0637008 (2025)
Tianxin Zhu, Chunmei Chen, Guihua Liu, Lingling Yuan, and Yuhan Zhang
Nighttime images suffer from low visibility due to insufficient illumination and glow effects caused by artificial light sources, which severely impair image information. Most existing low-light image enhancement algorithms are designed for underexposed images. Applying these methods directly to low-light images with glows often intensifies the glow regions and further degrades image visibility. Moreover, these algorithms typically require paired or unpaired datasets for network training. To address these issues, we propose a zero-shot enhancement method for low-light images with glows, leveraging a layer decomposition strategy. The proposed network comprises two main components: layer decomposition and illumination enhancement. The layer decomposition network integrates three sub-networks, including channel attention mechanism modules. Under the guidance of glow separation loss with an edge refinement term and self-constraint information retention loss, the input images is decomposed into three components: glow, reflection, and illuminance images. The illuminance map is subsequently processed via the illumination enhancement network to estimate enhancement parameters. The enhanced image is reconstructed by combining the reflection map and the enhanced illuminance map, following the Retinex theory. Experimental results demonstrate that the proposed method outperforms state-of-the-art unsupervised low-light image enhancement algorithms, achieving superior visualization effects, the best NIQE and PIQE indices, and a near-optimal MUSIQ index. The method not only effectively suppresses glows but also improves the visibility of dark regions, producing more natural enhanced images.
Mar. 25, 2025Vol. 62 Issue 6 0637009 (2025)
Zeping Deng, Hui Liu, Jiliang Tu, Shenhui Ye, Naizhi Liao, and Guochao Lai
The existing algorithms for detecting dress code violations at airports exhibit high computational complexity and weak real-time performance. Furthermore, they are prone to errors and omissions during detection in complex airport security scenarios, making it difficult to meet the requirements of real-time security detection. In response to this situation, a method called SGS-YOLO is proposed based on the YOLOv8n technology route for detecting violations of dress code by airport security personnel. First, a parameter-free SimAM attention mechanism is introduced into the backbone network of the model to enhance the perception ability of important features and improve the accuracy of object detection. Second, GSConv and VoV-GSCSP modules are introduced into the neck network to reduce the number of parameters, which helps achieve lightweighting of the model. Finally, a detection box regression loss function based on SIOU is adopted to reduce misjudgments in cases involving small changes between the predicted and real target boxes. The experimental results show that compared with the baseline model, the SGS-YOLO improves the average accuracy by 6.3 percentage points. Further, it reduces the number of parameters and floating-point operations by 9.63% and 8.64%, respectively. The proposed approach effectively achieves a balance between model lightweighting and performance, and thus, it possess good engineering application value.
Mar. 25, 2025Vol. 62 Issue 6 0637010 (2025)
Yue Hou, Ziwei Hao, Zhihao Zhang, and Jie Yin
Aiming to solving the problems of feature redundancy and blurred edge texture in images reconstructed via some of the existing image super-resolution reconstruction algorithms, an image super-resolution reconstruction network with spatial/high-frequency dual-domain feature saliency is proposed. First, the network constructs a feature distillation refinement module to reduce feature redundancy via introduction of blueprint separable convolution, and it then designs parallel dilated convolutions to refine extraction of multiscale contextual features so as to reduce feature loss and compensate for loss of texture in local regions. Second, a spatial dual-domain fusion attention mechanism is designed to enhance the high-frequency feature expression for fully capturing long-range dependency between different locations and channels of the feature map while facilitating reconstruction of edge texture details. The experimental results demonstrate that with its reconstructed image quality, the proposed model outperforms other comparison algorithms both in terms of objective metrics and subjective perception on multiple datasets. At a scaling factor of 2, compared with the VapSR, SMSR, and EDSR, the proposed method enhances the peak signal-to-noise ratio (PSNR) by an average of 0.14 dB, 0.36 dB, and 0.35 dB, respectively.
Mar. 25, 2025Vol. 62 Issue 6 0637011 (2025)
Low-Light Image Enhancement Algorithm with Light Perception Enhancement and Dense Residual Denoising
Boran Yang, Zilong Du, Yong Wang, Lijun Jiang, and Wenming Yang
Although Transformers excel in global feature extraction, they often have limitations in capturing local image details, leading to the loss of some local lighting information and uneven overall lighting distribution. To address this issue, this study proposes a low-light image enhancement algorithm based on light perception enhancement and dense residual denoising. The proposed algorithm leverages the advantages of Transformer and convolutional neural networks and effectively enhances the visual quality and lighting uniformity of low-light images through a detailed light perception mechanism. The network architecture features a codec design that integrates multilevel feature extraction and attention fusion modules internally. The feature extraction modules capture both global and local image features, and the attention fusion modules filter and combine these features to optimize information transmission. Additionally, to address the issue of noise amplification in low-light image enhancement, the enhanced image denoising module effectively reduces the noise of the enhanced image using dense residual connection technology. The performance of the proposed algorithm in processing low-light images is evaluated via comparative experiments. The experimental results show that the proposed algorithm can not only improve the problem of uneven lighting but also significantly reduce image noise and achieve higher quality image output.
Mar. 25, 2025Vol. 62 Issue 6 0637012 (2025)
Qianyu Dong, Qiuxiang Yang, and Yin Zhao
To address the problem of reduced clarity caused by detail information degradation during haze processing in complex scenes, this study presents a multi-scale feature fusion dehazing network based on U-net. In the encoder component, we employ a dynamic large kernel convolution with a dynamic weighting mechanism to enhance global information extraction. This mechanism allows for adaptive adjustment of feature weights, thereby improving the model's adaptability to complex scenes. In addition, we introduce a parallel feature attention module PA1 to capture critical details and color information in images, effectively mitigating the loss of important features during the dehazing process. To tackle the challenges posed by complex illumination changes and uneven haze conditions, we incorporate coordinate attention in the decoder's parallel feature attention module PA2. This approach integrates spatial and channel information, allowing for a more comprehensive capture of key details in feature maps. Experimental results show that the proposed network model achieves excellent dehazing effects across various datasets. The proposed network model outperforms classical dehazing networks such as FFA-Net and AOD-Net, effectively addressing detail loss while providing superior image dehazing performance.
Mar. 25, 2025Vol. 62 Issue 6 0637013 (2025)
Haoqian Zhang, and Kai Zhao
The increasing application of ultrasonic phased array technology for detecting defects in pipelines and plates highlights the importance of imaging algorithms for enhancing defect imaging quality. Building on the fully focused imaging (TFM) approach, the phase coherent imaging (PCI) algorithm is introduced in this study, which substantially improves the signal-to-noise ratio and lateral resolution of defect imaging by refining phase information processing and incorporating phase weighting. To further address challenges in defect classification accuracy and efficiency, a PCI-support vector machine (PCI-SVM) system is developed using the SVM algorithm. By optimizing the parameters and adjusting the model, the system automatically classifies pitting and crack defects with a classification accuracy of 94.6%. The experimental results demonstrate that the PCI-SVM system improves both defect detection accuracy and operational efficiency, offering a new and effective solution for industrial nondestructive testing. This study provides a theoretical foundation and practical guidance for advancing and optimizing ultrasonic phased array technology in real-world applications.
Mar. 25, 2025Vol. 62 Issue 6 0611001 (2025)
Kunran Yi, Han Wang, Daohua Zhan, Zhuohao Shi, Yibin Chen, and Feiyu Fang
The total variation (TV) minimization algorithm is widely applied for handling sparse or noisy projection data in computed tomography (CT), to enable high-precision CT image reconstruction. However, traditional TV regularization terms suffer from issues of isotropy and single directionality, which limit improvements in the quality of reconstructed images. To address this problem, this paper proposes a sparse angle CT image reconstruction algorithm based on multi-directional total variation. This method incorporates information from multiple directions and adjusts the regularization factor, to better preserve the structural characteristics of the reconstructed image. Experiments were conducted using the Shepp-Logan phantom model and gear CT projection data, with peak signal-to-noise ratio, root mean-square error, and structural similarity used as evaluation criteria for reconstruction image quality. The results were compared with those of three other traditional reconstruction algorithms. The experimental results show that the images reconstructed by the proposed algorithm are closer to the original images and superior in detail preservation compared to those of the other three algorithms.
Mar. 25, 2025Vol. 62 Issue 6 0611002 (2025)
Cunlong Su, Jing Liu, Runna Liu, Shuwei Yang, Keding Yan, Siyi He, and Yang Zhou
A low-cost portable microimaging system was designed to address the limitations of traditional microscopes in the immediate point-of-care testing (POCT) environment, including their inability to perform rapid image acquisition and their large size and high price. The system is based on a fully programmable ZYNQ system-on-chip to achieve rapid image acquisition and overall control, utilizing its parallel processing capability and efficient data stream processing to enable fast and simple sample detection. The mechanical structure was designed using NX12.0 and manufactured using three-dimensional printing technology. The device is compact (~20 cm3), lightweight (~2 kg), and low-cost (~1400 yuan). Test results show that the system transmission rate reached 60 frame/s corresponding to Gigabit Ethernet transmission speed, and the resolution under the 10× objective lens reached the resolution plate limit of 2.19 μm. Hence, the system enables quick acquisition and analysis of sample images, thereby meeting the need for simplified testing methods and portable equipment in the medical testing field.
Mar. 25, 2025Vol. 62 Issue 6 0611003 (2025)
Haibin Wan, Wei Huang, Lin Ji, Shuang Wu, Wei Xia, Yulong Liu, and Yunhai Zhang
To address the issue of degraded image quality caused by interline misalignment in images when line-by-line sampling is performed for imaging in laser-scanning confocal microscopic imaging systems, a dislocation correction method is proposed in this study. Based on prior knowledge that the similarity between natural image lines is high, this study calculates the cross-correlation of even and odd rows of dislocated image to obtain the line misalignment. Additionally, the effect of the image dark regions on the misalignment calculation is eliminated using the k-means clustering algorithm, and the total misalignment is calculated. Under the scanning imaging process, the image is converted into one-dimensional data. Subsequently, a method based on the Fourier transform is used to correct the image data in the frequency domain at the subpixel level. Experiments conducte using the self-constructed laser-scanning confocal imaging system verifies that the proposed algorithm reduces the misalignment by ~96% in a high-speed imaging scene featuring 30 frame/s. Thus, it can effectively correct the dislocation image and offers a certain robustness.
Mar. 25, 2025Vol. 62 Issue 6 0611004 (2025)
Binbin Du, and Changjie Liu
Flange docking and positioning are crucial steps in the unloading process of liquefied natural gas (LNG). The precise extraction of the inner diameter and elliptical contour of a flange is a prerequisite for achieving the pose positioning of the flange, based on the elliptical feature curve. Given that current ellipse extraction methods struggle to accurately extract the inner diameters of flanges in the presence of localized bright spots, a robust ellipse extraction method that is tailored for flange inner diameters is proposed. First, the flange region in the image is localized using YOLOv4 to narrow the target scope. Subsequently, the fast ellipse detection based on the arc adjacency matrix (AAMED) is employed to preliminarily extract the elliptical contour of the flange inner diameter. Finally, geometric constraints are established to gradually approximate the edge of the flange inner diameter. For the highlight regions present on the edge of the flange, the extracted elliptical arc segments are further optimized through the curvature characteristics of arcs and slope variation characteristics between line segments segmented from arcs. These optimized arc segments are then used to fit the ellipse. Experiments are conducted using large caliber LNG unloading flanges to verify the accuracy and robustness of this method in ellipse extraction. The proposed method ensures ellipse extraction error within 1 pixel and localizes the centers of flanges via monocular vision based on ellipse feature curves. The proposed method achieves a maximum error of 1.93 mm, compared with the measurement results of the total station, and satisfies complex industrial measurement requirements.
Mar. 25, 2025Vol. 62 Issue 6 0612001 (2025)
Yang Chen, Xiaojing Chen, wen Shi, Zhonghao Xie, Guangzao Huang, and Liang Zhao
To validate the feasibility of laser-speckle imaging for detecting defects in snack food packaging, a laser-speckle measurement system is established to capture images of packaging with and without defects, such as bag swelling and air leakage. Gray-histogram features are extracted from preprocessed speckle images, including the mean value, variance, peak value, and skewness. Additionally, four features (angular second moment, entropy, moment of inertia, and correlation) derived from the gray-level co-occurrence matrix along with their corresponding standard deviations are extracted from the speckle images, thus resulting in 12 feature groups. Subsequently, these extracted features are classified using various models, including random forest (RF), k-nearest neighbor (KNN), support vector machine (SVM), binary logic regression (LR), and linear discriminant analysis (LDA). The results show that the RF model achieves the highest classification accuracy rate of 96.08%. Furthermore, by evaluating the feature importance via RF analysis and analyzing the single-feature quantities as well as the pairwise and three-three combinations of these quantities, we discover that the pairwise combinations yield the best performance with a classification accuracy rate of 94.12%. The overall test results indicate that combining laser-speckle imaging technology with machine vision is feasible for detecting defects in food packaging.
Mar. 25, 2025Vol. 62 Issue 6 0612002 (2025)
Zhuoran Cao, Fajie Duan, Xiao Fu, and Guangyue Niu
To address the issue of low detection efficiency resulting from the limited field of view in oil abrasive particle image detection, a telecentric imaging-based method for abrasive particle image detection is proposed. The effects of field depth and magnification on channel depth, detection field of view, and pixel accuracy are examined using the principle of telecentric imaging. The traditional microscope lens is replaced with a telecentric lens, and a specialized microchannel structure for abrasive particle detection is designed. Further, we develop an online detection system for abrasive particle images using telecentric imaging, which ensures resolution while providing a larger field of view and channel depth, thereby enhancing detection efficiency. The collected images are preprocessed, and the abrasives are classified into four categories based on their morphological characteristics using the random forest (RF) algorithm: normal abrasives, fatigue abrasives, cutting abrasives, and spherical abrasives. The influence of the number of decision trees and features on the classification performance is investigated, and the parameters are optimized based on the findings. The experimental results indicate that the system can detect abrasive particles in a field of view of 2.1 mm×1.8 mm and a channel depth of 0.2 mm. The RF algorithm outperforms the K-nearest neighbor and support vector machine algorithms, achieving a classification accuracy of 93.75% for abrasive particles. This result validates the effectiveness and practicality of the proposed method, providing a novel solution for the online detection of abrasive particle images.
Mar. 25, 2025Vol. 62 Issue 6 0612003 (2025)
Xiufen Dong, Haodong Sun, Dengke Zhou, Dongdong Meng, Ao Yu, Pengge Ma, Zhaobing Qi, and Jianye Chen
Damage to wind turbine blades can easily lead to wind power equipment failures, posing a threat to personnel safety. The existing methods for fan-blade damage detection require stopping the fan blades, which is time-consuming and costly.A photoelectric detection and recognition method for blade damage based on pulse laser synchronization is proposed to address this issue.First, a 535 nm sub-nanosecond high-frequency laser is designed to irradiate the observation area of the fan blades. When the blade rotates to the laser path, an echo signal is generated, which is detected and converted into an electrical pulse signal by the silicon photodiode receiving module. This further triggers the large format camera Phase One to take photos within the field of view. After obtaining the blade image, deep learning algorithms are used to segment and extract the image blades through a priori data samples, and based on the YOLOv5 algorithm, wind turbine blade damage detection and recognition are implemented, outputting the damage category and locating the damage location. Experimental results show that the proposed method effectively improves the fan maintenance efficiency and offers a higher blade-damage-detection accuracy than conventional methods. The results of this study can provide a reference for the health monitoring of fan blades.
Mar. 25, 2025Vol. 62 Issue 6 0612004 (2025)
Ruiting Chen, Zhibin Qiu, Zhiwen Cai, and Zeding Yang
Defects in photovoltaic cells can reduce their photoelectric conversion efficiency. At present, defects in photovoltaic cells are commonly detected using electroluminescence (EL) technology. This study proposes a three-stage, attention-based cascaded lightweight model called YOLO-FEE for fast and accurate recognition of defects in EL images of photovoltaic cells. First, we constructed a photovoltaic cell EL image dataset containing seven types of defects. We then constructed the proposed three-stage cascaded lightweight object detection network using CSP-FBE, Faster PANet, and EMSHead. During the experimental evaluation, YOLO-FEE reduced the parameter number and computational complexity by 26.34% and 40.74%, respectively, from those of the YOLOv8n model. The mean average precision of YOLO-FEE reached 96.4%, confirming the accurate and rapid detection of defects in photovoltaic cells. This model is easily deployable on mobile and embedded devices, allowing the automatic EL detection of photovoltaic cell defects in practical industrial environments.
Mar. 25, 2025Vol. 62 Issue 6 0612005 (2025)
Zhenyu Zhang, Xiaogang Yang, Ruitao Lu, Siyu Wang, and Zhengjie Zhu
To address the issue of low accuracy and poor robustness in traditional visual odometry methods in weak texture environments, a visual feature-enhanced optical flow-based visual odometry model is proposed. The model first employs a convolutional feature enhancement module that integrates central differential convolution with activation followed by a pooling operation to enhance feature expression and effectively capture local details and edge information. Next, a global local fusion module is implemented to combine detailed and global contextual information, resulting in an aggregated feature representation. Finally, in the offset prediction stage, a convolutional gated linear unit network is used to replace the traditional multilayer perceptron network, thereby enhancing the nonlinear modeling capabilities and improving the accuracy of the auxiliary feature point prediction. The robustness and accuracy of the algorithm are significantly improved by sampling auxiliary features to further enhance the source features. The simulation experiments demonstrate that the proposed model provides more accurate and robust position estimation under weak texture conditions than traditional visual mileage calculation methods.
Mar. 25, 2025Vol. 62 Issue 6 0612006 (2025)
Zheyu Hu, Lijie Zhang, Ze Xu, Honglei Fan, and Lingfeng Han
The stability of docking between a landing gangway and an offshore wind turbine landing platform under a wave impact directly influences personnel safety and work efficiency. To enhance docking stability, a laser point cloud and image fusion method for measuring the attitude of the offshore wind turbine landing gangway is proposed. A lidar and an industrial camera are assembled at the front end of the landing gangway to implement the proposed method. The proposed method consists of two main components: object detection and attitude estimation. In the object detection component, an improved YOLOv8 network and PointPillar network are introduced, incorporating a point cloud and image fusion branch for detecting offshore wind turbine landing platform objects. In the attitude estimation component, the color and geometric features of the target are integrated, and an objective function based on a distance weight function is designed. In addition, we propose an improved fast global registration (FGR) algorithm that uses integrated features and distance weighting. The experimental results demonstrate that under level 4 sea conditions, the proposed method achieves an attitude measurement error of less than 0.676°. The target detection algorithm improves detection accuracy by 13.8% compared to the classical PointPillar network, while the attitude measurement algorithm enhances attitude angle measurement accuracy by at least 7.9% relative to the classical FGR algorithm.
Mar. 25, 2025Vol. 62 Issue 6 0612007 (2025)
Tieqiang Sun, Zhaozhi Hong, Chao Song, and Pengcheng Xiao
Insulator defect detection often faces challenges such as large model parameters, significant interference from complex backgrounds, and suboptimal performance in detecting small target defects. To address these issues, in this study, an improved YOLOv8n-based insulator defect detection algorithm is proposed. The approach introduces a novel C2f-RE module applied to the backbone network, which reduces model parameter redundancy, suppresses background interference, and enhances feature extraction capabilities. Additionally, the neck structure is redesigned, incorporating the focusing diffusion pyramid network (FDPN). This modification aims to improve small target feature extraction by integrating multiscale feature information across high, medium, and low dimensions. Furthermore, a lightweight shared detail-enhanced convolutional detection head (LSDECD) is proposed to facilitate multiscale feature information interaction while minimizing the number of model parameters. Additionally, an improved Inner-WIoU loss function is employed to effectively focus on small target samples and ordinary quality annotation samples. Experimental results demonstrate that the proposed algorithm realizes a mean average precision PmA of 97.1%, representing a 2.6% increase in PmA and a 4% boost in recall R when compared to the original YOLOv8n algorithm. Finally, the number of parameters and computational costs are reduced by 35.5% and 23.5% respectively, and the model size is reduced by 1.8 MB. The method effectively balances detection accuracy with lightweight characteristics, and it exhibits strong robustness against complex weather interference.
Mar. 25, 2025Vol. 62 Issue 6 0612008 (2025)
Yue Cai, Lei Guo, Zhongyu Chen, Xie Han, Shichao Jiao, and Huiyan Han
The unsupervised domain adaptation (UDA) method aims to utilize a labeled data domain (source domain) to enhance the model's generalization ability in another unlabeled data domain (target domain). In the three-dimensional (3D) real-world context, significant differences in the geometry and distribution of data exist between the source and target domains. However, current 3D UDA methods have not paid sufficient attention to such domain gap issues, resulting in decreased predictive performance in the target domain. Therefore, a 3D UDA method based on balanced geometric perception is proposed. To achieve consistent underlying geometric information across domains, a self-supervised pretraining task based on implicit fields is designed, which involves training a point cloud implicit field using balanced local distances. Through this method, the model can fully leverage underlying geometric information and effectively learn implicit representations at varying densities, thereby mitigating the impact of outlier point cloud data. In addition, a point cloud hybrid enhancement strategy is adopted to interpolate the point cloud data and labels. This provides more intermediate state information for the point cloud data, increases the diversity of the training data, and further improves the model's generalization ability. Experimental results show that the proposed method achieves a mean intersection-over-union of 65.2% on the segmentation dataset PointSegDA and an accuracy of 71.8% on the classification dataset PointDA-10, demonstrating the effectiveness of the proposed method.
Mar. 25, 2025Vol. 62 Issue 6 0615001 (2025)
Shirui Liu, Yongjie Ren, Zhiyuan Niu, and Jiarui Lin
In response to the challenges of complex site setup and low measurement efficiency in existing flange pose measurement methods, a high-precision flange pose measurement method based on three-point centering is proposed. A three-point centering model based on the laser ranging is established, and the system parameters of the model are calibrated using the Levenberg-Marquardt (L-M) algorithm. A monocular visual pose measurement model based on an active luminous target is established, and the Sequential Quadratic Programming Perspective-n-Point (SQPnP) algorithm is employed for pose estimation. A portable integrated tool that integrates a laser displacement sensor and an active luminous target is designed, and this tool is mainly divided into a centering module and pose module. The laser displacement sensor is placed and calibrated according to the three-point centering model in the centering module, and landmark points are added to the target topology in the pose module to optimize the matching strategy for the feature points. Measurement errors owing to insufficient manufacturing accuracy are analyzed, and the effectiveness of the proposed method is proven. Experimental results demonstrate that the proposed method exhibits good repeatability and high accuracy. The average three-point centering error is 0.018 mm, maximum flange center distance error is 0.242 mm, and maximum angle error is 0.103°. Moreover, the results indicate that the proposed method can satisfy the requirements of engineering applications.
Mar. 25, 2025Vol. 62 Issue 6 0615002 (2025)
Zechuan Wang, Zhenhua Zhang, jin Liu, and Haima Yang
With the increasing demand for processing point cloud data of aircraft blades, existing algorithms face challenges of long registration times and insufficient accuracy when registering large-scale point clouds. In response to this situation, this paper proposes a coarse registration algorithm that constructs feature vectors of point clouds. First, the source and target point clouds are decentralization, and feature points are identified by traversing the Euclidean distance between the decentralization point cloud and the origin point. Based on these feature points, feature vectors for both point clouds are constructed separately. Then, the rotation axis is determined according to the two feature vectors, and the rotation matrix is calculated using the Rodrigues formula to align the two feature vectors. Subsequently, the rotation matrix is calculated with the feature vectors of target point clouds as the rotation axis to ensure the alignment of the feature points. Finally, the source point cloud is aligned with the target point cloud through translation. Through two sets of experiments, the proposed algorithm is compared with three classical algorithms. Results demonstrate that the proposed algorithm has higher accuracy and time efficiency when dealing with medium-scale point cloud data. In the rough registration stage, compare to the comparison algorithms, the registration time of the proposed algorithm is reduced by more than 80%, maintained the registration accuracy of 0.1 mm level, and preserved good precision.
Mar. 25, 2025Vol. 62 Issue 6 0615003 (2025)
Qiangqiang Xu, Jingjing Wu, and Chengtong Miao
This study proposes an invalid phase point recognition method for applications in stripe projection contour measurement technology. Based on various characteristics such as data modulation, error energy, phase continuity, and depth maps, a K-means clustering algorithm and statistical methods are introduced to automatically set relevant thresholds and help remove invalid points for complex modulation objects. Finally, continuity features are utilized to repair the misclassified effective points to avoid the erroneous removal of the effective point cloud. The experimental results show that the proposed method effectively solves the problem of removal of phase invalid points in object reconstruction with complex modulation.
Mar. 25, 2025Vol. 62 Issue 6 0615004 (2025)
Yuchuan Tao, Hongce Liu, Rui Ma, Binyuan Liu, and Xueyuan Wang
Currently, the manufacturing process of the calibration equipment suitable for near-infrared cameras is complex and expensive. This increases the development cost of the optical surgical navigation system. Simultaneously, owing to the lack of reliable feature point centers extraction method, it is difficult to have an error-free positioning accuracy of the navigation system. To address this, we use LEDs to design a target suitable for near-infrared cameras, inspired by the hardware structure of circular marker array target. A sorting method with unique result is proposed, and the ellipse fitting method is improved. During feature point extraction, we used Otsu thresholding for preprocessing. Subsequently, we applied a Gaussian kernel convolution based on the average radius of the feature points to attenuate the scattering halo of the LEDs and then used Zernike moment to detect the subpixel edges of the feature points and remove some abnormal edges. Furthermore, we performed secondary fitting to obtain more accurate center coordinates of feature points. Finally, we completed the stereo near-infrared camera calibration using Zhang's method. Experimental results show that, after removing some abnormal edges, the reprojection error is reduced by approximately 3% and standard deviation of the stereo reconstruction samples is reduced by approximately 3.3%.
Mar. 25, 2025Vol. 62 Issue 6 0615005 (2025)
Yayun Liu, Gongwei Li, Huajie Ren, Jingmei Li, Dong Chen, Xuyuan Zhang, Fang Huang, Lingling Ma, and Ning Wang
Point cloud data obtained via spaceborne photon-counting lidar contain substantial background noise that significantly affects the high-precision extraction of surface elevation information. To address the limitations of existing algorithms in high-noise and undulating terrain areas, this paper proposes a single-photon point cloud denoising algorithm based on improved local distance statistics. This method employs a multilevel denoising strategy that progresses from coarse to fine stages. Specifically, in the fine denoising stage, an elliptical filtering kernel that better matches the distribution characteristics of the scene's photon point cloud is utilized. Additionally, a Gaussian bimodal model is used to fit the distance histogram and determine the optimal denoising threshold. Experiments conducted with ICESat-2 data demonstrate that the proposed method achieves an average precision of 97.11%, average F1 score of 92.57%, and average accuracy rate of 91.66%, which is approximately 3.35 percentage point higher than those of existing algorithms. These findings indicate that the proposed method exhibits superior denoising performance in high-noise and undulating terrain areas. Therefore, this study provides a valuable reference for denoising photon point clouds in complex scenes.
Mar. 25, 2025Vol. 62 Issue 6 0615006 (2025)
Guangle Wang, Yatong Zhou, and Zhao Wang
The lightweight YOLO-WWSP model is designed to address two main challenges in the detection model for workwear wearing—large parameter count and insufficient detection accuracy. First, a lightweight detection head based on shared convolution and task alignment is developed, which reduces parameters while aligning localization and classification tasks. Second, a depthwise separable convolution and element-wise multiplication operations at the neck of the model is used, which reduces the parameter and computational complexity of the model. Finally, a grouping coordinate attention mechanism that integrates multiscale local information is designed to enhance the feature extraction capability of the backbone, and parameter pruning techniques is used to reduce the number of redundant parameters in the model. The experimental results show that compared with the baseline model YOLOv8n, YOLO-WWSP exhibits a 69.8% decrease in parameter count and a 39.1% decrease in computational complexity, and mAP@0.5 and mAP@0.5∶0.95 increased by 0.7 percentage points and 1.5 percentage points, respectively, demonstrating the effectiveness of YOLO-WWSP in detecting improper workwear wearing.
Mar. 25, 2025Vol. 62 Issue 6 0615007 (2025)
Sufu Li, Kun Wang, Gang Wang, Haochen He, Zexin Chen, and Jiyu Zhou
Aiming to solve the problems of missing parts of the point cloud in existing methods and overcome the limitations of the internal connection form of the research object, a target workpiece positioning algorithm based on feature surface extraction and point cloud registration is proposed for a concave-convex workpiece. First, this study extracts and restores the feature surface with obvious geometric features of the workpiece and roughly estimates the pose of the workpiece according to its pose. Second, the improved iterative closest point (ICP) registration algorithm is used to further refine the location. Additionally, to improve the ICP registration algorithm, the description of global features and loss function are added to the local features to limit the registration direction. Finally, positioning experiments under different stacking degrees show that the workpiece positioning is accurate. Moreover, the experimental results show that the proposed algorithm is suitable for workpiece positioning under different stacking conditions and is applicable to the grasping and positioning of industrial robots.
Mar. 25, 2025Vol. 62 Issue 6 0615008 (2025)
Yang Wu, Chunyuan Wang, Xiaolong Li, and Lianlei Lin
Synthetic aperture radar (SAR) images are characterized by their single channel, low resolution, and low signal-to-noise ratio, whereas target detection methods based on visible image design lack the corresponding optimization. Moreover, Many ship detection tasks need to be run on resource-constrained embedded devices, which poses new challenges to the performance and model volume of detection networks. Hence, this study introduces a lightweight SAR ship detection approach that enhances contour information to tackle these challenges. Initially, anisotropic diffusion filtering and a four-directional Sobel operator are applied to expand the single-channel SAR image to three channels for network learning. Then, drawing inspiration from the lightweight feature extraction network FasterNet and the non-local attention mechanism, an innovative lightweight backbone feature extraction network is designed. This network adeptly models the long-distance contextual relationships of features, achieves multiscale feature fusion, and reduces the parameter count of the detection model without compromising detection accuracy. Algorithm evaluations on public data sets, satellite ship detection data sets (SSDD), and high-resolution SAR image data sets (HRSID) demonstrate that the proposed network excels not only in reducing model size and complexity but also in maintaining high detection accuracy.
Mar. 25, 2025Vol. 62 Issue 6 0615009 (2025)
Junchao Zhu, Siyuan Song, Fangfang Han, and Minghui Zhang
Considering the problems of complex parameter setting, cumbersome threshold setting, and low registration accuracy in the traditional point cloud feature extraction method, a geometric feature extraction method based on the surface feature degree of point cloud is proposed. First, the normal vector and curvature of the point cloud are determined according to the weighted covariance matrix and combined with both the angle and curvature feature of the normal vector to form the surface feature degree. The median value is used as the threshold to automatically screen the feature points. Then, based on the improved dung beetle optimization algorithm (ST-DBO), the six parameters of point cloud registration are automatically optimized. The ST-DBO algorithm enhances the global optimization ability, which can prevent falling into a local optimal solution and determine the optimal parameters of the registration. Finally, through comparison experiments on the two public data sets and the actual collected point cloud data, the experimental results show that the registration accuracy of the proposed algorithm is improved by up to 33.12% compared to that of the typical traditional point cloud feature extraction method. Moreover, the feature extraction efficiency is significantly improved, such that it can adapt to different point cloud data. Additionally, the registration accuracy is improved by 29.13% compared to those with other registration algorithms. Under different parameter settings and noise interferences, the proposed algorithm exhibits strong robustness, good feature extraction efficiency, and improved registration accuracy.
Mar. 25, 2025Vol. 62 Issue 6 0615010 (2025)
Qiu Fang, Xinghao Guo, and Zhiyuan Huang
To address the issue related to the recalibration of external parameters when a camera pose changes in the surround view, this paper proposes a method based on deep learning to correct the surround-view camera pose. First, a random pose-deviation value is added to the original image and the deviation image is converted into the input feature-extraction network in the bird's eye view. Second, a phased training strategy that uses different loss functions to learn the changes in the camera's key angle and position in the image is adopted. Finally, four directional features are aggregated and the six degree-of-freedom (DOF) pose-deviation values for each camera are returned. Experimental results show that the proposed method can estimate the camera pose deviation in real time, is better than similar calibration methods, and offers corrected surround-view images with an accuracy level suitable for practical applications.
Mar. 25, 2025Vol. 62 Issue 6 0615011 (2025)
Gan Zhang, Yuhui Peng, Baozhe Sun, Shenyang Lin, and Jiaming Zhang
To address the challenge of low detection accuracy of small targets, such as cyclists and pedestrians in the PointPillars algorithm, an improved PointPillars algorithm based on point cloud feature enhancement is proposed. First, the quality of the input point cloud data is improved by increasing the environmental density aware sampling and IFPS point cloud sparsity. Second, a stepped ECA attention mechanism is integrated into the point cloud feature encoding to enhance the point cloud features through multilevel attention guidance, and a feature fusion enhancement module is added to the backbone network to strengthen the interaction between feature maps at different levels. Finally, the introduction of the EMA attention mechanism further enhances the point cloud features in the feature map. The experimental results based on the KITTI dataset indicate that the proposed improved algorithm improves the three-dimensional average detection accuracy of pedestrians and cyclists in simple, moderate, and difficult scenarios by 7.9 percentage points, 8.6 percentage points, 8.3 percentage points, and 4.0 percentage points, 2.9 percentage points, 3.8 percentage points, respectively, compared to the original algorithm. Furthermore, the average directional similarity increases by 7.5 percentage points, 7.9 percentage points, 5.9 percentage points, and 4.4 percentage points, 5.2 percentage points, 6.1 percentage points, respectively.
Mar. 25, 2025Vol. 62 Issue 6 0615012 (2025)
Leijun Xu, Yafei Zhou, Jianfeng Chen, and Xue Bai
Carbon fiber composites are widely used in different fields owing to their unique properties. However, the presence of defects adversely affects the performance of the material, thus causing significant economic losses and safety hazards. In this study, a transmissed-terahertz continuous wave detection system was constructed to detect samples with internal defects, perform image preprocessing on the detection results, and construct the target dataset. To address industrial scenarios involving significant image background interference, easy confusion of defect categories, significant variation of defect scales, and unsatisfactory detection of small defects, an improved YOLOv5s algorithm was proposed, which improves the accuracy and speed of intelligent defect recognition by increasing the small-target detection layer and the attention network's convolutional block attention module (CBAM), as well as by improving the loss function. Experimental results show that the improved YOLOv5s algorithm yields an accuracy of 92.3% and a recall of 80.8% on the test set, which are 10.6 percentage points and 3.0 percentage points higher than those of the original YOLOv5s algorithm, respectively. Furthermore, it exhibits better feature extraction and greater robustness, which eliminates the issue of misdetection.
Mar. 25, 2025Vol. 62 Issue 6 0615013 (2025)
Qiming Jin, Feng Wang, Juanjuan Yang, Yang Pang, and Jianwu Dang
Existing unmanned aerial vehicle (UAV) image three-dimensional (3D) reconstruction algorithms suffer from a lack of attention to spatial geometric information and global feature perception. Therefore, the reconstructed point cloud models have holes and their accuracy is low in case of weak textures and complex areas. Herein, a 3D reconstruction algorithm for unmanned aerial vehicle images is proposed. This algorithm combines spatial geometric information and global features to address the abovementioned issues. First, a feature descriptor self-mapping layer is designed. This layer uses multilayer perceptrons to map geometric spatial information to high-dimensional feature vectors, thereby improving feature point matching performance while enhancing 3D reconstruction accuracy. In addition, a lightweight Transformer structure model is proposed based on the characteristics of drone images. This model achieves cross perception of feature descriptors, obtains global contextual feature information, improves the global perception ability and distinguishability of features while maintaining 3D reconstruction efficiency, enhances 3D reconstruction accuracy, and reduces point cloud reprojection errors. Finally, combining the FastAP loss function with the descriptor-enhanced loss function accelerates model convergence and improves the quality of the reconstructed point clouds. To verify the effectiveness of the proposed algorithm, experiments are conducted on three drone highway datasets. Experimental results show that the proposed algorithm improves the reliability and accuracy of the reconstructed point cloud while maintaining 3D reconstruction efficiency.
Mar. 25, 2025Vol. 62 Issue 6 0615014 (2025)
Ziwen Ren, Huaiguang Liu, and Wei Sun
A lens is installed into the laser before leaving the factory to ensure focusing. However, the laser beam is particularly sensitive to focusing and can easily become out of focus, with the machine shaking during the focusing process, further complicating the focusing. To solve this problem, an image sequence prediction model PCLT-Net (PMA-ConvNeXt-LSTM-TA), which combines a convolutional neural network with parallel multi-attention (PMA), a long shortterm memory (LSTM), and temporal attention mechanism (TA),was built for real-time prediction of the in-focus or out-of-focus state of laser beams. First, a convolutional neural network was used to extract the spatial features of each frame. Then, a recurrent neural network was used to learn the temporal dependencies, and a temporal attention mechanism was used to highlight the key frames. Finally, the focus state of the laser beam was predicted using a classifier. In the experimental results, this method achieved 90% accuracy in the real-time laser focusing state prediction task, significantly improving the quality and production efficiency of laser products.
Mar. 25, 2025Vol. 62 Issue 6 0615015 (2025)
Nuo Xu, Qi Li, Hanlin Huang, Longhai Shen, Dongli Qi, Hongda Li, and Yu Feng
Breast cancer is one of the most common malignant tumors, and its molecular typing can effectively guide individualized treatment. However, its clinical detection is relatively complex and time consuming. Fluorescence spectroscopy is convenient and efficient; hence, it is widely used for tumor detection. Meanwhile, studies involving molecular typing are few. In this study, a new method for detecting breast cancer via molecular typing is proposed, which is based on a principal component analysis and support vector machine (PCA-SVM) model combined with fluorescence spectroscopy. A laser-induced fluorescence detection system with a wavelength of 405 nm is constructed and the autofluorescence spectra of breast cancer tissues are measured. The results of Gaussian fitting show that the peak intensity of fluorophores in different subtypes of breast cancer are different. Through further analysis using the PCA-SVM model, the molecular subtypes of breast cancer are identified with an accuracy of 95.0%, a precision of 95.9%, and a balanced F-score of 94.9%. Moreover, the discriminant sensitivities of the four subtypes are 91%, 94%, 97%, and 100%. This scheme improves the analysis efficiency of high-dimensional spectral data and provides a new direction for the rapid identification of breast cancer via molecular typing.
Mar. 25, 2025Vol. 62 Issue 6 0617001 (2025)
Tie Li, Hongfeng Jin, and Zhiqiu Li
To achieve full utilization of the spatial and spectral information in hyperspectral images and address the problems of insufficient training samples and small pixel targets being misidentified as background, we propose a hyperspectral target detection method based on spatial-spectral restructuring and operator weighting. This method eliminates the need for a coarse separation of target and background pixels and comprehensively learns image features through spatial-spectral combination learning. A feature enhancement coefficient was first derived using the hyperbolic tangent function to improve the contrast between the target and background. Principal component analysis was next employed to obtain a feature vector matrix that retains significant features, which was then used to construct an operator for projecting the data into a new principal component space. An operator was then used in this new space to weight the averages of the original image and the enhanced images, thus facilitating object detection. We tested this method on six hyperspectral image datasets, and the results show that the proposed method effectively detects targets and outperforms the comparison methods, achieving an average detection accuracy of 99.8% and thus verifying the accuracy and robustness of the proposed approach.
Mar. 25, 2025Vol. 62 Issue 6 0628001 (2025)
Quan Feng, Liang Luo, and Xiaoqian Zhang
This study proposes a remote-sensing image detection method based on context aware and sparse feature fusion to address the problems of missed detections and low detection accuracy. Such problems are caused by complex target background areas and insufficient small target feature information. First, a context aware unit was designed to mine spatial contextual feature information during feature extraction, enhancing the ability to capture small target features. Second, a sparse feature fusion strategy was developed to guide more effective feature fusion between shallow and deep features in the network by learning sparse representations. Finally, the Slim-Neck design paradigm was introduced at the network neck to reduce the complexity of the network model. The experimental results show that on the NWPU VHR-10 and DIOR remote sensing datasets, the proposed method reduces computational and parameter complexity by 3.1% and 6.3%, respectively, and improves detection accuracy by 1.6 percentage points and 2.6 percentage points, respectively, compared with YOLOv8s. And the proposed method performs better than the six mainstream detection methods.
Mar. 25, 2025Vol. 62 Issue 6 0628002 (2025)
Bo Li, Lingyun Kong, Mingwei Zhao, and Xinyu Liu
Super-resolution reconstruction technology has found extensive applications across various fields, yet challenges persist in reconstructing remote sensing images. To balance local details and global structures in super-resolution remote sensing, we propose a novel model that integrates multiscale receptive fields with a multilevel hybrid transformer. The generator network combines multiscale receptive fields with a multilevel hybrid transformer architecture, progressively enhancing image features from low to high resolution, notably improving reconstruction quality and detail restoration. The discriminator network incorporates independent global, multiscale, and hierarchical discriminators for a comprehensive and refined evaluation of reconstructed remote sensing image quality, enhancing training stability and accelerating convergence. Experimental results on five publicly available datasets demonstrate that the proposed method achieves the highest structural similarity (0.988) and feature similarity index (0.993) in the 4× magnification task, surpassing state-of-the-art methods such as SRFormerV2 and SRTransGAN. Notably, the model showed remarkable improvement in FSIM, with reconstructed remote sensing images exhibiting finer textures and sharper features, providing robust support for subsequent remote sensing applications.
Mar. 25, 2025Vol. 62 Issue 6 0628003 (2025)
Yingquan Li, Jianyu Hua, Linsen Chen, and Wen Qiao
Augmented reality (AR) three-dimensional (3D) display is a key technology for future"metaverse"scenarios. With the advantages of high transparency, true 3D, and natural interaction, AR-3D displays have great potential for innovative applications such as smart healthcare, smart culture and tourism, smart transportation, and intelligent manufacturing. This paper first reviews existing AR-3D display technologies. These technologies are then classified according to different 3D-display implementation methods, including stereoscopic, multi-plane, and light-field AR-3D displays. The development processes of various AR-3D display technologies are also described. Finally, the industrialization of AR-3D display technology in the context of future metaverse applications is analyzed. The rapid development of AR-3D displays is crucial for our country to gain competitive advantages in the novel display industry. This paper provides suggestions for the rapid development of this field.
Mar. 25, 2025Vol. 62 Issue 6 0600001 (2025)
Jie Cao, Yanan Sun, Long Liang, Zhijun Li, Tao Liu, Yukai Wang, and Qun Hao
Light Detection and Ranging (LiDAR), an essential technology for acquiring three-dimensional spatial data, has been extensively utilized in various fields such as autonomous driving, intelligent transportation systems, and aerospace. The simulation of LiDAR technology is crucial for the development of algorithms, assessment of equipment performance, and integration and verification of systems. Firstlly, this paper outlines the context of LiDAR's three-dimensional imaging simulation applications and provides a detailed analysis of the current state of research in this field globally, focusing on two main aspects: enhancing system performance and visualizing and applying point cloud data. Furthermore, it summarizes the challenges and prospects in the advancement of LiDAR three-dimensional imaging simulation, which include the development of high-fidelity simulation models, integration of multi-sensor data, and the growth of LiDAR data enhancement and simulation techniques. This study sets a solid foundation for further progress in the field of LiDAR three-dimensional imaging simulation.
Mar. 25, 2025Vol. 62 Issue 6 0600002 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20