








Please enter the answer below before you can view the full text.


2025
Volume: 62 Issue 10
43 Article(s)

Jiannan Liu, Shuxian Liu, Hankiz Yilahun, and Askar Hamdulla
Infrared detection serves as a crucial tool for remote search and surveillance, and it plays a significant role in many applications. To enhance the infrared detection accuracy of small targets in complex backgrounds, a Trans-YOLO detection framework based on an improved YOLOv8 model with RT-DETR is proposed. First, to avoid the issue of non-maximum suppression (NMS) in YOLOv8 erroneously suppressing true targets, the Head component of YOLOv8 is replaced with the Decoder & Head from RT-DETR. Furthermore, to address the challenges of weak signal strength and small size of infrared small targets, an RGCSPELAN module is designed to enable the detection network to perform more fine-grained processing of the input features. Finally, to reduce the semantic disparity between deep and shallow features, a new feature fusion strategy, called CAFM-based fusion (CAFMFusion) mechanism, is designed to facilitate the flow of different types of feature information within the network, thereby enhancing the model's ability to detect targets of varying sizes. Experimental results show that the proposed Trans-YOLO model achieves 86. 1% and 99. 5% mean average precision at IoU=0.5 (intersection over union) on two public datasets with complex scenarios, representing improvements of 7.7 percentage points and 3.0 percentage points over the original YOLOv8 model, respectively. Additionally, the model achieves the processing speed of 371.9 frame/s and 369.4 frame/s on the two datasets, respectively, effectively balancing accuracy and speed.
May. 25, 2025Vol. 62 Issue 10 1037001 (2025)
Lang Liu, Yanlin Shao, Qihong Zeng, Kunpeng Zhao, Changhui Zhou, Peijin Li, and Rui Zeng
There are problems such as uneven point cloud density distribution and limited separability of single-point reflectance arise in the task of semantic segmentation of outcrop point clouds. To achieve efficient and accurate lithology segmentation of outcrop point clouds, this research proposes a lithology segmentation method with efficient channel attention mechanism (ECA) based on the multiple eigenvalues of outcrop voxel (MGECA). First, this method voxelizes the raw point cloud and computes the spatial-spectral feature parameters of each voxel. Then, a multi-granularity convolutional neural network is used for multi-scale feature fusion. Next, the classical self-attention mechanism in the Transformer model is improved using an ECA, allowing the weighted encoding of feature maps so the model can establish global spatial and spectral correlations. Finally, designs a dual-channel group convolution to connect the convolutional neural network and ECA, and achieve spatial and spectral feature integration, while reduce computational complexity. Experimental results show that MGECA achieved a lithology recognition total accuracy of 90.6% and a mean intersection over union of 70.4% on the Crescent Bay laser outcrop point cloud dataset, representing improvements of 31.7 percentage points and 24.7 percentage points, respectively, compared to DGPoint model. Results indicate that the proposed method has a significant advantage in segmentation performance within outcrop point cloud scenarios compared to existing methods.
May. 25, 2025Vol. 62 Issue 10 1037002 (2025)
Jingwen Ding, Ying Lu, Huiqin Wang, Ke Wang, and Zhan Wang
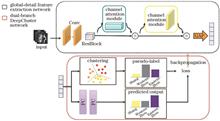
Bronze inscriptions are invaluable for studying ancient politics, economy, and culture. However, minimal stylistic variations and the predominance of unlabeled data in unearthed inscriptions pose challenges for computer-aided inscription analysis. To address this issue, a bronze inscription age clustering network based on a deep unsupervised clustering model is proposed. In the first stage, a ResNet50-based feature extraction module is constructed, incorporating an improved multiscale CBAM attention mechanism. This enhancement allows the network to simultaneously capture detailed and global features, thereby overcoming the limitations of traditional feature extraction methods that struggle with incomplete feature representation for inscriptions of similar ages. In the second stage, K-means clustering is applied to the extracted features. The clustering branch results serve as pseudo-labels, which are then used to compute the cross-entropy loss against the predictions of the model's prediction branch. In the third stage, iterative training is performed using cross-entropy loss backpropagation to continuously optimize the model parameters, enhancing the accuracy of feature extraction and clustering. The experimental results demonstrate that the proposed network achieves an overall accuracy of 89.43% on the standard inscription dataset, surpassing traditional unsupervised clustering networks by more than 14%.
May. 25, 2025Vol. 62 Issue 10 1037003 (2025)
Xin Guo, Jiabin Wu, lin Li, Chun Jiang, and Zhiyong Wu
The conventional pattern-recognition star-identification algorithm requires parameter setting in advance and is slow under high limit magnitudes. A star-identification algorithm based on the Voronoi graph is proposed. The algorithm extracts stars in the star map and normalizes them to a spherical point set. Next, it calculates the Voronoi graph and the corresponding star polygon features, including the perimeter, area and number of edges to be combined into the star-recognition feature. Subsequently, the features are matched against the navigation catalog and pointing is calculated based on matching star pairs. Simulation results show that the algorithm is feasible and can yield the match ratio under different conditions. The operating time of the algorithm is less than 100 ms in the optimal case, and the effects of position noise, pseudo stars, and missing stars on the matching rate of the algorithm were tested and verified. The recognition rate of the proposed algorithm under different fields of view and limit magnitude was obtained experimentally, and the optimal combinations were obtained. The recognition rate of the algorithm does not decline under a 1‰ position error. A comparison with the star-identification algorithm using radial and cyclic features shows that the proposed algorithm offers a higher recognition rate, a shorter recognition time, and better anti-position noise performance than the conventional pattern-recognition star-map recognition algorithm. Furthermore, the proposed algorithm requires neither parameter setting nor adjustment.
May. 25, 2025Vol. 62 Issue 10 1037004 (2025)
Xin Wang, Yuan Cheng, Ruoyu Zhang, Yao Fan, Jizhong Huang, Yue Zhang, and Hongbin Yan
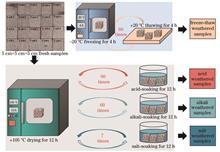
Stone cultural heritage is a precious carrier of human history and culture. However, weathering problems severely threaten the long-term preservation of stone cultural heritage sites. Determining the main weathering environment is crucial for developing the corresponding protection measures. However, determining the weathering environment in a non-destructive and contract-free manner is challenging. Therefore, this study proposes a weathering-environment evaluation method based on hyperspectral imaging technology. First, the visible-near-infrared (VNIR) and short-wave infrared (SWIR) spectral data of weathered sandstones in different environments were obtained using hyperspectral imaging technology. The spectra were preprocessed using standard normal variation (SNV) and multiple scattering calibration (MSC), the spectral features were downscaled via principal component analysis, and multiple machine-learning and deep-learning algorithms were used to establish classification models for weathering environments of stone cultural heritage. The results show that the classification model established based on SNV preprocessed spectral data has a higher overall accuracy rate. The deep-learning model outperformed the conventional machine-learning model, with a maximum accuracy rate of 0.98 attained. The proposed method enables a rapid, contact-free assessment of the weathering environments of stone cultural heritage sites and provide important support for targeted cultural-heritage protection.
May. 25, 2025Vol. 62 Issue 10 1037005 (2025)
Yixin Yang, Xinjian Gao, Ye Ma, and Jun Gao
Single-image rain removal aims to remove rain streaks from rainy images and restore rain-free images, to provide support for subsequent tasks such as detection and tracking. However, current rain removal methods have problems, such as image blur, detail loss, and color blur after rain removal. To address the limitations of existing methods, a two-stage rain removal and residual diffusion detail recovery network is proposed. In the first stage, to strengthen local rain streak feature learning and improve global information utilization ability, a dual-attention module (DAB) and a dual-attention U-shaped network (DAU-Net) are proposed by combining channel attention and multi-head self-attention mechanisms, so that the model can dynamically identify various rain streaks and remove them. In the second stage, the characteristics of the diffusion model that first constructed the overall semantic information and captured detailed information are used to leverage the powerful generation ability. The rain removal results of the first stage are used as conditions to guide the diffusion model to reverse sample and generate residual information, to address the problem of detail loss and image blur. Experimental results show that the proposed method performs well on both synthetic and real datasets. On the Rain100H and Rain100L test sets, peak signal-to-noise ratio (PSNR) of 31.75 dB and 39.12 dB and structural similarity (SSIM) of 0.912 and 0.981 are obtained, respectively. The two-stage rain removal network can effectively various complex rain streaks in various scenes and recover more of the image details to achieve better visual effects.
May. 25, 2025Vol. 62 Issue 10 1037006 (2025)
Ziyuan Yin, and Yun Wu
The automatic segmentation of dental images plays a crucial role in the auxiliary diagnosis of oral diseases. To address the issues of large parameter sizes in existing segmentation models and low segmentation accuracy of medical dental images, a lightweight dental image segmentation model, namely, the quadrant oblique displacement (QOD) UNeXt is proposed. First, QOD blocks are designed to displace features along four oblique directions, that is, the upper-left, upper-right, lower-left, and lower-right, to diffuse features and dynamically aggregate tokens, which thereby enhances segmentation accuracy. Second, a localized feature integration (LFI) module is incorporated into the decoder to improve the ability of the model to integrate detailed and global information. Finally, an efficient channel attention (ECA) module is introduced at the skip connections to further fuse local and global features. Experimental results on the STS-MICCAI 2023 and Tufts public datasets demonstrate that QOD-UNeXt significantly improves segmentation accuracy while maintaining a lightweight structure. Therefore, QOD-UNeXt exhibits excellent performance in dental medical image segmentation tasks.
May. 25, 2025Vol. 62 Issue 10 1037007 (2025)
Jia Zhao, Yuelan Xin, Jizhao Liu, and Qingqing Wang
To address the issue of insufficient extraction and fusion of complementary information in infrared and visible image fusion, this study proposes a pulse-coupled dual adversarial learning network. The network utilizes dual discriminators that target infrared objects and visible texture details in the fused images, with the goal of preserving and enhancing modality-specific features. We also introduce a pulse-coupled neural network featuring a combined learning mechanism to effectively extract salient features and detailed information from the images. During the fusion stage, we implement a cross-modality fusion module guided by cross-attention, which further optimizes the complementary information between modalities and minimizes redundant features. We conducted comparative qualitative and quantitative analyses against nine representative fusion methods in the TNO, M3FD, and RoadScene datasets. Results show that the proposed method demonstrates superior performance in evaluation metrics, such as mutual information and sum of correlation differences. The method produces fused images with high contrast and rich detail and achieves better results in target detection tasks.
May. 25, 2025Vol. 62 Issue 10 1037008 (2025)
Lizhi Zhu, and Hui Wei
To address the challenges of insufficient feature information in small targets within unmanned aerial vehicle (UAV) aerial images and significant variation in target scales, a small target detection algorithm based on an improved YOLOv8n is proposed. The improvements focus on the following aspects: i) design of a multi-scale feature fusion layer in the detection layer tailored for feature extraction and processing of small targets to improve the ability to collect detailed information of small targets; ii) concerning the neck network, a triple-feature fusion module and a scale sequence feature fusion module are introduced to effectively fuse the detailed information from low-level feature maps with the semantic information from high-level feature maps. This enhances detection capabilities across targets of varying scales. In the backbone network, ConvNeXt v2 is used to replace the backbone network, thereby enhancing the localization and feature extraction capabilities of small targets against complex backgrounds. To optimize the deployment of the model in embedded systems, a layer adaptive amplitude pruning algorithm is adopted to balance the computational complexity and detection accuracy of the model. The algorithm performance is tested using the VisDrone2019 dataset and compared with several mainstream models. The experimental results indicate that the improved algorithm attains a detection accuracy (mAP50) of 30.2%, which is 3.8 percent point higher than that of the benchmark model, YOLOv8n, while reducing the parameter count by 1.63×106.
May. 25, 2025Vol. 62 Issue 10 1037009 (2025)
Wan Liang, Meizhen Huang, and Guilin Xu
Aiming at the problems of edge blurring and loss of edge details that occur in the convolutional neural network image dehazing method when dealing with the image edge texture, in this study, a single image dehazing network design method, guided by multilevel edge a priori information, is proposed. The design method integrates an edge feature extraction block, an edge feature fusion block, and a dehazing feature extraction block, which performs rich edge feature extraction on foggy images and reconstructs the edge image. Furthermore, the edge feature fusion block efficiently fuses the edge a priori information with the context information of the foggy image at multiple levels. Then, the dehazing feature extraction block performs multiscale deep feature extraction on the image and adds attention mechanism to the important channels. A large number of experiments are conducted on the RESIDE dataset and compared with the mainstream dehazing methods, in which the peak signal-to-noise ratio and structural similarity index measurement of the indoor dataset reach 37.58 and 0.991, respectively. Additionally, the number of parameters and amount of computation are only 2.024×106 and 24.84×109, which shows that the method in this study effectively defogs the image while reducing the number of parameters and amount of computation. Moreover, the method exhibits good performance and edge detail preservation ability.
May. 25, 2025Vol. 62 Issue 10 1037010 (2025)
Lihu Sun, Pingping Li, Sujuan Liu, Xiaodong Zhang, Nannan Liu, and Xinpeng Wu
An information encoding and decoding scheme based on vector vortex beam and deep learning was proposed to improve the encoding novelty and mode recognition accuracy in vector optical communication. A novel encoding method was designed to embed grayscale image information into the characteristic parameters of vector vortex beams. Equivalent phase screens were used in the laboratory to simulate the effects of no, weak, moderate, and strong atmospheric turbulence environments on beam wavefront. A mode-recognition neural network consisting of cascaded dense blocks was constructed to decode the polarization distribution characteristics of beam modes at the receiving end. The mode recognition accuracies of the no, weak, moderate, and strong atmospheric turbulence environments are 100%, 99.96%, 99.93%, and 93.75%, respectively. A Lena grayscale image with a resolution of 80×80 was experimentally encoded and transmitted in each of the four atmospheric turbulence environments to verify the feasibility of the scheme. The bit-error-ratios of the image decoding are 0, 1.56×10-4, 7.8125×10-4,and 4.898×10-2, respectively. The results demonstrate that the proposed scheme can achieve high-quality encrypted encoding, transmission, and decoding of grayscale image information, and it has potential application value in the structured optical communications in atmospheric turbulence environments.
May. 25, 2025Vol. 62 Issue 10 1007001 (2025)
Qingxin Yang, Deming Kong, Jing Chen, Xiaowei Li, and Yue Shen
To address the problem of low detection accuracy for cars and cyclists in the PointPillars three-dimensional (3D) object detection network, an improved PointPillars method based on density clustering and a dual attention mechanism is proposed. This method improves PointPillars in two key areas: 1) introducing a density clustering algorithm in the point cloud processing module to screen and filter out non-clustered points, reduce the influence of irrelevant point cloud information while preserving effective point clouds as much as possible; 2) integrating an attention mechanism in the column feature extraction module of the column feature extraction network. A self-attention mechanism is used to establish connections between points within columns, and a cross-attention mechanism is employed to strengthen connections between columns after column feature extraction, thereby expanding the receptive field and enabling better focus on crucial point cloud information while preserving directional data. The experimental results obtained on the KITTI autonomous driving dataset reveal that PointPillars++ improves the 3D car detection accuracy and the average directional similarity (AOS). Compared to the original network, improvements in detection accuracy were 2.41, 3.48, and 4.87 percentage points, and AOS improved by 2.47, 2.06, and 0.74 percentage points across the simple, moderate and difficult levels, respectively. For 3D cyclist detection, accuracy and AOS increased by 6.26, 1.40, and 1.64 percentage points, and by 6.13, 6.53, and 6.37 percentage points, respectively, across the same difficulty levels.
May. 25, 2025Vol. 62 Issue 10 1012001 (2025)
Pengfei Gao, Liya Zhang, Yukun Wang, and Lin Zhang
Pavement cracks can affect driving safety and service life, thereby increasing the risk of traffic accidents. Therefore, detecting and managing pavement cracks in a timely manner is particularly important. To address the problems of limited receptive field, inability to add location information, and poor effectiveness of traditional convolutional neural networks, a pavement crack segmentation model that integrates multiple attention mechanisms is proposed. ResNeSt and Swin Transformer enhance the information transmission effect of the model for the network to better utilize information at different levels and generate more accurate predictions. Among public online datasets, a dataset with 8251 real road images is used for the experiment, obtaining intersection over union, precision, recall, and F1 score values of 73.24%, 82.84%, 86.12%, and 84.44%, respectively. Although the recall is slightly inferior to that of DeepLab v3+, better performance is exhibited in terms of crack recognition accuracy and robustness in complex road environments.
May. 25, 2025Vol. 62 Issue 10 1012002 (2025)
Shuang Yan, Guofeng Wang, Jiefeng Li, Wei Tang, Zhizhuo Wang, and Yanliang Sheng
An automated bolt measurement method based on machine vision is proposed to address the limitations of low efficiency and accuracy in bolt size measurement and the reliance on manual operations in the aerospace manufacturing industry. First, the acquired bolt images are preprocessed, and subpixel contour coordinate vectors of the bolts are extracted. Subsequently, a binary tree structure is established based on the contour vectors, where a pre-order traversal of the contour binary tree is used to stitch the contours, achieving the initial decomposition of the bolt contour. The decomposition results are further optimized in the curvature scale space. Finally, a three-level feature tree is developed based on the relationship between the decomposed contour segments and the bolt features to be measured, enabling multi-feature recognition and size measurement of bolts. Experimental validation shows that the proposed algorithm achieves a recall rate of 98% for bolt feature recognition, an average absolute error in size measurement within 0.010 mm, a repeatability error within 0.005 mm, and an average measurement time of only 1.41 s. The results indicate that the proposed algorithm can accurately recognize multiple features of different bolt types, offer highly adaptive measurement capabilities, and fulfill the high-precision automated inspection requirements for aerospace bolts.
May. 25, 2025Vol. 62 Issue 10 1012003 (2025)
Kun Mao, Xuejun Zhu, Huige Lai, Checao Yu, Leilei Xiong, Ming Yang, and Da Peng
A printed circuit board (PCB) defect detection algorithm based on multi-scale fusion optimization is proposed to address the low accuracy of traditional detection algorithms, which struggle with small surface defects resembling background features. Building on YOLOv8, a Swin Transformer module is integrated at the end of the backbone network's feature fusion layer to capture global information and enhance the understanding of both detailed and overall features. A global attention mechanism is embedded in the backbone to focus on target areas and reduce background interference. The WIoU loss function replaces the original CIoU, incorporating differential weighting to improve regression performance for small targets and complex backgrounds. Comparative experiments are conducted using different algorithms on the PCB~~DATASET and DeepPCB datasets. The proposed algorithm improves detection accuracy by 3.64 and 2.42 percentage points on the PCB~~DATASET and DeepPCB datasets, respectively, significantly enhancing defect recognition accuracy.
May. 25, 2025Vol. 62 Issue 10 1012004 (2025)
Bin Zhang, Xiaohui Xu, and Haihong Li
The illumination conditions under black factory lights are poor, and the structural characteristics of some areas are similar. Hence, the TSR-LIO-SAM algorithm is proposed to improve the accuracy of the synchronous positioning and mapping algorithm of mobile robots under black factory lights. The LiDAR is tightly coupled with the inertial measurement unit (IMU), and a pre-integration factor is used to compensate the dynamic error of the IMU. The IMU high-frequency output is used to eliminate the LiDAR point cloud distortion. Simultaneously, a key frame selection and local mapping strategy based on the time-space threshold is proposed. The iterative closest point (ICP) algorithm is improved by combining the line-surface features and point cloud probability distribution, and the dynamic weight is configured to optimize the point cloud registration. Experimental results show that, compared with the LEGO-LOAM and LIO-SAM algorithms, the average error of the TSR-LIO-SAM algorithm is reduced by 77.96% and 9.77% respectively, and the root mean square error is reduced by 78.64% and 8.49% respectively, which prove the effectiveness of the TSR-LIO-SAM algorithm in indoor environments.
May. 25, 2025Vol. 62 Issue 10 1015001 (2025)
Hongxu Li, Yitao Lu, Ronghua Chi, Shiyu Li, and Zhenbo Yang
The existing point cloud segmentation techniques can neither easily and effectively eliminate invalid noise points in the feature-extraction stage nor adequately capture key global and local features. Therefore, this study proposes an improved point cloud feature extraction network based on the PointGroup segmentation model, which is named deep residual shrinkage Transformer U-Net (DRST-UNet). The proposed network combines the deep residual shrinkage attention module and lightweight Transformer encoding, which removes invalid noise points by soft thresholding to shrinkage the residual block, combines with the attention mechanism such that the network prioritizes the important features, and utilizes the Transformer to capture the long-distance dependency and high-level interactions between point samples, thus enhancing the accuracy and efficiency of feature extraction. Experimental results show that the DRST-UNet is superior to existing methods in terms of segmentation accuracy based on ScanNetV2 and S3DIS datasets, in particularly for cases involving complex indoor scenes. The maximum average precision when the intersection ratio threshold is 50% (AP50) of the proposed method is 66.4% on the ScanNetV2 dataset, which is an improvement by 2.8 percentage points compared with the result of the baseline model, and the added module incurs almost no time cost. The maximum AP50 on the S3DIS dataset is 61.7%, which is an improvement by 3.9 percentage points compared with the result of the baseline model.
May. 25, 2025Vol. 62 Issue 10 1015002 (2025)
Tao Song, Daiheng Yue, Yichen Yang, Ting Chen, and Yuan Gong
In traditional visual simultaneous localization and mapping (SLAM) algorithms, it is typically assumed that the objects in the environment are static. Nevertheless, dynamic objects are inevitably present in practical applications. The participation of imaging feature points in feature matching and pose estimation introduces errors that influence back-end optimization and subsequently weaken the robustness of the SLAM system, which makes it impossible to obtain globally consistent pose trajectories and maps. This paper proposes a dynamic SLAM algorithm that combines the feature point extraction of the geometric correspondence network v2 (GCNv2) and adaptive separation of dynamic targets via YOLOv8s-seg semantic segmentation. First, the ORB-SLAM3 framework is utilized to extract the feature points based on GCNv2 and generate the corresponding descriptors. Then, the YOLOv8s-seg network is employed to segment the dynamic objects, and the dynamic targets in the scene are detected using the optical flow method. Meanwhile, the optical flow field is used to statistically measure the dynamic degree of the targets, and the threshold for eliminating dynamic feature points is adaptively adjusted based on the dynamic degree to reduce the pose estimation error of the SLAM system. Finally, the static feature points are fused via nonlinear optimization, loop closure detection, and local mapping in the back-end of ORB-SLAM3. Experimental results obtained using the TUM dataset show that, in highly dynamic scenarios, the root mean square error (RMSE) of the absolute trajectory error (ATE) of the proposed algorithm decreases by an average of 77.75%, and the standard deviation (SD) decreases by an average of 69.75%, compared with ORB-SLAM3. The proposed method also achieves significant progress in comparison with Dyna-SLAM and DS-SLAM in that it effectively enhances the positioning accuracy and tracking robustness of ORB-SLAM3 in dynamic scenarios.
May. 25, 2025Vol. 62 Issue 10 1015003 (2025)
Zhipeng Zhai, Jinju Shao, Song Gao, Zhibing Duan, and Lei Wang
This study aims to enhance the extraction capabilities of point cloud features in LiDAR object detection and improve the accuracy of object detection. This study proposes a multi-stage feature extraction method target detection for object detection based on PointPillars. First, the maximum pooling in the point cloud feature encoding target detection module is improved by introducing combined pooling to minimize spatial information loss during the pooling process. Additionally, a global attention mechanism is introduced to enhance the ability of the pseudo-image feature to express information. Finally, a cavity convolution module is integrated into the column feature extraction network to increase the receptive field and further improve the feature extraction capability. Experimental results on the KITTI data set show that the average detection accuracy of the proposed method improves by 2.91 percentage points compared with the original network. Moreover, the inference speed reaches 17.08 frame/s, which meets the requirements for real-time detection in autonomous driving.
May. 25, 2025Vol. 62 Issue 10 1015004 (2025)
Weichao Chen, Lingchen Zhang, Ronghua Chi, Zhenbo Yang, Qi Liu, and Hongxu Li
To address the deficiencies of existing point cloud classification and segmentation methods in processing local features and contextual information, this research proposes a novel network architecture—the COGCN model, which integrating the advantages of convolutional neural network and graph convolutional network, and incorporating the channel and spatial enhanced edge convolution (CSEConv) module and offset attention mechanism. The CSEConv module enhances the extraction of local features from point clouds, while the offset attention module captures contextual features and inter-neighborhood relationships, facilitating more effective information fusion among features. Experimental results on ModelNet40, ShapeNet, and S3DIS datasets show that, the COGCN model has achieved a high accuracy of 93.2% in point cloud classification task, a segmentation mean intersection over union (mIoU) of 86.1% in point cloud segmentation task, and a mIoU of 60.3% in semantic segmentation task, the results are better than the existing algorithms.
May. 25, 2025Vol. 62 Issue 10 1015005 (2025)
Leicheng Yang, Yuhong Du, and Guangyu Dong
3D point clouds provide accurate 3D geometric information and are therefore widely used in fields such as robotics, autonomous driving, and augmented reality. Current point cloud classification models improve performance by continuously increasing the number of parameters. However, this trend leads to an increase in model complexity and computation time. To address these issues, a lightweight point cloud classification model named Point-PT is designed based on a biased attention mechanism. The model constructs a local feature aggregation module through simple positional encoding and linear layers to extract local features of the point cloud, and it embeds an offset attention mechanism to screen local features and extract key information. The experimental results show that when the model parameter number is 0.4 Mbit, the proposed method is 12 times faster than PointMLP, and the number of parameters is reduced to 1/32 of the original, with an overall accuracy of 92.9%. Moreover, when the model parameter number is 0.8 Mbit, the overall accuracy is improved to 93.9%, representing increases of 2.0, 0.7, 0.1, and 1.0 percentage points, compared with those of PointNet++, point cloud transformer (PCT), PointPN, and dynamic graph convolutional neural network (DGCNN), respectively. The results of this study validate that the proposed model has not only a higher correctness rate but also lower model complexity.
May. 25, 2025Vol. 62 Issue 10 1015006 (2025)
Wenxuan Deng, Jianwu Dang, and Jiu Yong
To address challenges such as time consumption, interference from dynamic objects, insufficient feature points leading to low real-time performance, reduced mapping accuracy, and inaccurate pose estimation in indoor dynamic environment mapping of visual SLAM (simultaneous localization and mapping) systems, this study proposes a visual SLAM algorithm based on object detection and point-line feature association, referred to as LDF-SLAM. To mitigate time consumption and dynamic object interference, MobileNetV3 is introduced to replace the YOLOv8 backbone network, thereby reducing the number of network parameters. A parameter-free attention-enhanced ResAM module is designed and integrated with the MobileNetV3 network to create a lightweight detection network to enhance detection capability and efficiently identify dynamic objects. Subsequently, the multi-view geometry method is introduced to compensate, filter and reject potential dynamic feature points together with the improved lightweight network, and the remaining static feature points are used to construct a dense point cloud map, thereby improving the mapping accuracy of the SLAM system. In addition, to resolve inaccuracies in pose estimation due to insufficient static feature points, a fusion FLD line feature extraction method is proposed to enhance pose estimation accuracy. A line segment length suppression mechanism is also designed to ensure the system's real-time performance and improve its robustness. Experiments conducted on the TUM and Bonn data sets demonstrate that the root-mean-square-error (RMSE) of absolute trajectory error of LDF-SLAM is reduced and outperforms other mainstream SLAM algorithms, significantly enhancing the robustness and accuracy of the SLAM system in dynamic environments.
May. 25, 2025Vol. 62 Issue 10 1015007 (2025)
Hailong Qu, Shiqiang Wang, Zhaozong Meng, Nan Gao, and Zonghua Zhang
Multibeam LiDAR can directly capture the distance to target points and perceive three-dimensional information. However, its low vertical resolution results in sparse single-frame point clouds. Hence, an external rotating axis was designed to densify the point cloud obtained by the multibeam LiDAR. This paper proposes a method using a multilevel perforated circular calibration board to establish the relationship between the LiDAR and external rotating axis. First, the external rotating axis scans the calibration board at different angles to obtain multiple single-frame point cloud data and solve the initial external parameters. Second, an optimization model is established using two sets of calibration board point-cloud data scanned by the external rotating axis within 0°?180° and 180°?360° intervals. Ultimately, the initial values are input into the optimization model to refine the initial pose such that precise pose parameters can be obtained. Experimental results show that the proposed method offers high accuracy and dense distributions in point-cloud reconstruction. When measuring a standard sphere, its absolute error is 0.9 cm, which satisfies the requirement for practical applications.
May. 25, 2025Vol. 62 Issue 10 1015008 (2025)
Shengjun Xu, Zhiwei Cui, Ya Shi, Xiaohan Li, Erhu Liu, and Abdelhamid Hameg
Aiming at the problem that it is difficult to recognize object grasp points because of overlap or occlusion between multiple objects in stacked scenes, a multiscale regional-attention stacked-object grasp detection network is proposed. First, a multiscale regional-attention feature fusion module is proposed based on the feature pyramid architecture, which improves the network's ability to pay attention to different feature dimensions by introducing deformable convolution and full convolution. Second, a multiscale region-attention mechanism is used to decouple the grabbable area from the background in the stacked scene image. Different regions of different scale feature maps are weighted gradually to improve the network's ability to pay attention to the saliency of the grabbable area and its background-noise anti-interference ability. Finally, a double sampling region candidate module is proposed to further refine the candidate anchor boxes on the basis of the target ground truth, eliminate a large number of negative samples, and thus improve the quality of the candidate anchor boxes. The final grasp detection results are output by the classification regression module. Stacked-object grasp detection accuracy experiments are carried out on the VMRD and Cornell datasets. The experimental results show that the average detection accuracy of the proposed network on the VMRD dataset is 98.18%, whereas it is 98.0% on the Cornell dataset. The proposed network has accurate grasp detection effect and strong robustness in complex scenes.
May. 25, 2025Vol. 62 Issue 10 1015009 (2025)
Fan Zhang, and Wanyue Jiang
To address the issue of adaptability to the new semisolid lidar and unsatisfactory robustness in degradation environments in current studies pertaining to laser simultaneous localization and mapping (SLAM), a geometric feature extraction method is proposed, where the features are stored in voxel grids. By selecting features based on the curvature information of each voxel, one can effectively extract the desired planar features while maintaining the accuracy even when using non-periodic scanning patterns. Compared with neighborhood search methods based on k-dimensional trees, neighborhood search based on voxel grids is more efficient and significantly reduces the computing time. By using a graph optimization algorithm framework, the modules can be set more flexibly and excellent global optimization results can be obtained. Experimental results on the VECtor public dataset and a self-developed dataset are analyzed, which show that in indoor environments, the proposed algorithm offers higher positioning accuracies by approximately 48% and 64% compared with FAST-LIO2 and iG-LIO, respectively, and a lower single-frame time by 42% compared with LIO-SAM. The experimental results show that the proposed algorithm passes all the specified test sequences, thus demonstrating its superior comprehensive performance.
May. 25, 2025Vol. 62 Issue 10 1015010 (2025)
Kun Zhang, Junjie Zhao, Xiaoming Zhang, and Xuefei Li
Multisensor collaboration is a key technology in autonomous driving and environmental perception. Owing to the inevitable external force, the sensor shifts during the measurement process, thus necessitating a real-time dynamic calibration network. Therefore, this paper proposes a novel dynamic calibration network for Lidar and camera based on cost-volume construction (DC-LCNet). First, a dual-channel map comprising a depth map and reflection map is established as the network input, and the sparse point-cloud problem is solved using the features of radar point-cloud data. Additionally, to obtain high-quality discriminative features between the two modal data features, feature transformer is designed for both point-cloud and image modalities. Finally, a cost-volume construction quantity for stereo matching is proposed to describe the feature correlation between two modalities. The experimental results of the network on the KITTI dataset show translation and rotation errors of 0.246 cm and 0.021°, respectively, whereas those on the nuScences dataset indicate 0.336 cm and 0.053°, respectively. In terms of error calibration, the proposed network can manage variations of up to ±1.5 cm and ±20° for the translation and rotation errors, respectively. The most accurate network reported thus far exhibits translation and rotation errors of 0.380 cm and 0.048° on the KITTI dataset, respectively. The experimental results show that DC-LCNet enable new breakthroughs to the dynamic calibration of Lidar and cameras.
May. 25, 2025Vol. 62 Issue 10 1015011 (2025)
Hao Wu, Shuanggao Li, Xiaomei He, Xuetao Zhang, Anbing Sun, Xiang Huang, and Guoyi Hou
To address the low efficiency and lack of precision in existing methods for extracting rivet unevenness features from three-dimensional point clouds, we propose an accurate extraction method based on point cloud dimensionality reduction. First, the surface variant of the point cloud is calculated, and the surface normal variant is color-mapped through mathematical processing. Next, principal component analysis projection technique combined with two-dimensional meshing is used for point cloud dimensionality reduction, generating an image, and the relevant image processing algorithms are used for the coarse segmentation of the point cloud in the rivet region. Finally, hierarchical structure fitting is applied to accurately extract the rivet head and skin point clouds, allowing for the calculation of rivet unevenness. Experimental results show high computational efficiency with large point cloud datasets and a computational error of less than 0.013 mm.
May. 25, 2025Vol. 62 Issue 10 1015012 (2025)
Xu Zhu, Xiping Xu, Ning Zhang, Zhi Meng, Hongwei Tan, Luqing Zhang, Yiming Hu, and Jiaxu Zhang
To solve the decline in simultaneous localization and mapping (SLAM) accuracy caused by the inferior quality of line-feature extraction in low texture areas and dynamic lighting environments, this paper proposes a point-line binocular vision SLAM method based on the improved ELSED line-feature-extraction algorithm. In the feature-extraction stage, the angle difference and distance threshold are introduced to merge short line segments, and the mask technique is used to homogenize the distribution of line features to improve the quality of line features. In the feature-matching stage, a matching threshold condition and bidirectional consistency-detection mechanism are used to improve the feature-matching accuracy. In the back-end optimization, the joint optimization function is constructed by extending the PnPL formula of line features, and the reprojection errors of point and line features are uniformly incorporated into the optimization objective. Experiments are performed on the EuRoC, KITTI, and UMA datasets. The results show that the proposed algorithm significantly improves the robustness and positioning accuracy of the system compared with other point-line SLAM algorithms. Compared with the results yielded by ORB-SLAM3, the positioning accuracy on the three datasets improved by 49.6%, 19.6%, and 82.3%, respectively.
May. 25, 2025Vol. 62 Issue 10 1015013 (2025)
Yingjie Peng, Qianlin Lian, Yue Ma, Xiaohan Nie, and Jianjun Chen
Liver cancer has high mortality and low early detection rates. To enable timely and accurate auxiliary diagnosis of liver cancer, this study uses laser-induced breakdown spectroscopy (LIBS) combined with machine learning to perform elemental imaging and classification of liver tumor tissue and adjacent muscle tissue in a nude mouse. First, sample slices of liver tumor and adjacent muscle tissues of a nude mouse were prepared, and characteristic element spectra and spatial distribution maps were obtained using an LIBS system. Second, 400 spectral data points from the two tissue types were preprocessed and randomly divided into training, validation, and test sets. Support vector machine, Fisher discriminant analysis, kernel extreme learning machine (KELM), random forest (RF), and Bayes classification algorithms were used to develop a discriminant model for the full spectrum data of the sample slices for the classification. Finally, principal component analysis (PCA) was applied for feature extraction. The results showed differences in element content between the LIBS spectra and the Ca, K, and Mg distribution maps of liver tumor and adjacent muscle tissues. Further the classification of sample slices using the aforementioned algorithms revealed that full-spectrum classification accuracy exceeded 95%; however, modeling and classification required considerable time. Selecting eight principal components with a cumulative contribution rate of 95% from PCA as input data can considerably reduce the modeling and classification time while maintaining accuracy. Compared with full-spectrum RF and KELM, the classification time using PCA-RF was reduced to 0.13 s, demonstrating a substantial optimization effect. PCA-KELM achieved the best overall modeling and classification performance, reducing the modeling time to 0.04 s. These findings indicate that, when combined with appropriate machine learning algorithms, LIBS can effectively differentiate liver tumors from adjacent muscle tissue, which could be valuable for clinical applications in the future.
May. 25, 2025Vol. 62 Issue 10 1017001 (2025)
Xueli Shen, Xiaoming Zhu, and Haibo Jin
A lightweight remote sensing image super-resolution reconstruction network is introduced to address issues of deployment complexity, limited feature extraction methods, and insufficient ability to capture edge high-frequency information in existing approaches. First, the proposed method initially employs a lightweight saliency detection module to generate a saliency map that emphasizes crucial information regions. Subsequently, a dynamic routing perception module dynamically selects network paths based on the reconstruction difficulty of image patches and salient sub-patches, which enhances model performance. This module integrates multi-scale atrous separable convolution with an information distillation module that features a dual-edge detection operator attention mechanism. Hence, the proposed method can comprehensively extract remote sensing image features and enhance image detail representation ability. Finally, a dual-path upsampling module minimizes model parameters to enable high-quality remote sensing image reconstruction. The experimental results show that the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) of the GeoEye-1 dataset are improved by 0.12 dB and 0.0033, respectively, compared with the saldrn algorithm when the images in the GeoEye-1 dataset are magnified by 4 times, while using fewer parameters and achieving faster speeds, thereby demonstrating its advantages in reconstruction performance and effectiveness.
May. 25, 2025Vol. 62 Issue 10 1028001 (2025)
Dan Fan, Zhengwei Yang, Xia Li, Chao Feng, and Chuangjiang Rao
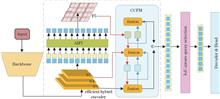
Deep learning has emerged as a cutting-edge approach for land cover classification using hyperspectral remote sensing images. However, hyperspectral remote sensing images suffer from two inherent limitations: spectral similarity between different objects and the absence of ground height information. To address these issues, this study proposes a multimodal land cover classification algorithm based on cross-feature granularity fusion network (CFCGNet), which establishes feature fusion between LiDAR data and hyperspectral remote sensing images. CFCGNet incorporates a multimodal cross-feature fusion module designed to extract high-order semantic features and complementary information from multisource data. Moreover, a composite granularity feature integration module is designed to integrate multiscale semantic information from various data sources. To mitigate the issue of uneven distribution of land use type samples, a weighted loss function is developed to optimize the model training process. Experimental results on the publicly available MUUFL, Houston 2018, and Trento datasets demonstrate that the proposed CFCGNet algorithm improves classification efficiency and enhances theoretical interpretability.
May. 25, 2025Vol. 62 Issue 10 1028002 (2025)
Lunming Qin, Wenquan Mei, Haoyang Cui, Houqin Bian, and Xi Wang
To address the issues of missed and false detection in high-resolution optical remote sensing images caused by complex backgrounds, large variations in target sizes, and a high proportion of small targets, an improved YOLOv8s object detection algorithm is proposed. First, the weighted bi-directional feature pyramid network (BiFPN) structure is introduced to replace the original neck network, and an additional branch from the backbone network is added to capture shallow features, thereby enhancing the performance of small-target detection. Second, the efficient multi-scale attention (EMA) mechanism is incorporated into the Bottleneck of the neck's cross-stage partial network fusion (C2f) module to improve the focus on spatial and channel information while reducing interference from irrelevant information. Finally, based on SCYLLA-IoU (SIoU), SWIoU loss function is designed by combining the dynamic non-monotonic focus coefficient from wise-IoU (WIoU). This strengthens the performance of bounding box regression and considers the directional matching between the predicted and ground truth boxes, further improving the detection accuracy of the algorithm. On the DOTA dataset, the improved algorithm achieves a mean average precision (mAP50) of 73.0%, which is a 3.0 percentage points increase compared to that of YOLOv8s, and its detection results also outperforms other mainstream algorithms. Furthermore, the experimental results obtained on the RSOD and NWPU NHR-10 datasets further validate the generality and adaptability of the proposed algorithm across different datasets.
May. 25, 2025Vol. 62 Issue 10 1028003 (2025)
Jingyu Yang, Yahui An, Jianwu Dang, Feng Wang, and Jiuyuan Huo
To address the issue of false changes in remote-sensing image-change detection caused by lighting conditions, seasonal variations, and differences in objects, this paper proposes a change-detection method based on depth-information fusion. First, depth information from remote-sensing images was extracted via a depth-estimation network as auxiliary information. Second, a self-supervised learning module based on aligned representation and mask modeling was designed to extract texture features with global semantic separability and higher-order representations of depth information. Finally, selective feature fusion and edge-enhancement mechanisms were employed to effectively suppress noise introduced during depth-map generation, thus resulting in fully integrated texture and higher-order features. This method yields F1 scores of 90.35% and 92.60% as well as intersection-over-union (IoU) scores of 82.40% and 86.22% on the LEVIR-CD and CDD datasets, respectively. Experimental results demonstrate the effectiveness of this method in suppressing pseudo-changes.
May. 25, 2025Vol. 62 Issue 10 1028004 (2025)
Qing Fu, Jun Chen, Weijian Liang, and Wenlang Luo
This study introduces a high-precision geometric positioning method for high-resolution optical satellite imagery that does not rely on ground control points (GCPs), utilizing preconditioned conjugate gradient (PCG) and graphics processing unit (GPU) acceleration. The core technologies used in this method include an adjustment model that is constructed based on virtual control points (VCPs), a sparse matrix storage format, and parallel block adjustment accelerated by PCG-GPU. By employing a sparse matrix storage format to reduce computer memory requirements, PCG-GPU parallel acceleration technology enhances the efficiency of block adjustment parameter processing. Experimental verification is performed using 829 Ziyuan-3 (ZY-3) satellite images from Jiangxi area. The results show that the proposed PCG-GPU accelerated parallel block adjustment method is approximately 9.5 times more efficient than traditional serial computing methods. In addition, following block adjustment, the root mean square error (RMSE) is 0.461 pixel and 0.652 pixel in the x and y directions, respectively, which meets the stringent accuracy requirements for high-precision satellite image mapping.
May. 25, 2025Vol. 62 Issue 10 1028005 (2025)
Xueting Jia, Weidong Song, and Shangyu Sun
This study proposes a road-change detection method, STSNet, that integrates the Swin Transformer. First, the model utilizes the Swin Transformer as the backbone network and employs a dual network structure with shared weights and a window self-attention mechanism to efficiently capture long-range dependencies. A gradient-aware multi-scale feature fusion module is next designed to merge changing gradient information with the multi-scale features, further enhancing the model's ability to obtain global change information and recognize edge features, thereby addressing the issue of blurred contours of changing targets. Finally, the scale-aware stripe attention module adaptively integrates features from the encoder and decoder to effectively combine local information and reduce the model's missed detection rate. This study used the self-made LNTU~~SCD~~GF and WRCD datasets for training and testing, respectively. The results demonstrate that the STSNet change detection method outperforms five comparative methods in terms of F1 value, intersection ratio, and recall, particularly excelling in small-scale road-change detection.
May. 25, 2025Vol. 62 Issue 10 1028006 (2025)
Yuheng Zhou, Shenbo Liu, Huang He, Ying Tan, Zhaowen Sun, Xiaokuo Liu, and Lijun Tang
Aimed at the problem of insufficient multi-scale feature information extraction and fusion in the remote sensing change detection task, which makes it difficult to accurately detect targets with significant shape differences, this paper proposes an MFFNet model for remote sensing image change detection. First, the model takes HRNet combined with Coord convolution as the backbone network, and a multi-scale difference feature extraction and fusion module is employed to improve the model's sensitivity to change information. Second, a dual time converter is constructed based on Transformer to model the remote sensing image context. Finally, CARAFE is used in the network prediction head to avoid the problem of small sensing field caused by up-sampling. The algorithm is experimentally validated on the remote sensing change detection dataset LEVIR-CD, WHC-CD, and DSIFN. The F1-scores are 90.75, 90.53, and 86.34 and intersection of unions are 83.07%, 82.70%, and 76.91%, which are higher than those of eight compar methods, which fully proves the validity of the algorithm in improving detection performance and accuracy.
May. 25, 2025Vol. 62 Issue 10 1028007 (2025)
Hanming Wu, Jiaqin Li, Ze Yang, and Lingling Huang
Three-dimensional imaging and holographic display technologies can capture and present the three-dimensional light-field information of objects, making them vital sensing and display technologies in the industrial and commercial sectors. These technologies urgently need to meet certain performance requirements, such as a wide field of view, large numerical aperture, high spatial bandwidth product, high resolution, and compact size. Owing to their single functionality, large size, and difficulty in integration, traditional optical elements struggle to meet these requirements simultaneously. Metasurface technology leverages the interaction between light and matter at subwavelength scales, using carefully designed nano-antenna arrays to arbitrarily manipulate the propagation characteristics of electromagnetic waves, such as amplitude, phase, polarization, and frequency. This offers new possibilities for developing thin, multifunctional, planar, and easily integrated optical elements. This paper discusses the research progress on metasurfaces in three-dimensional imaging technology, including both active and passive three-dimensional imaging methods. Active imaging techniques include structured light technology and beam scanning technology, whereas passive three-dimensional imaging includes binocular vision, lens array, and standard point spread function engineering types. Based on this, the latest advancements made by our research group in the field of metasurface holographic displays are introduced. Finally, the limitations and future development directions of metasurfaces in three-dimensional imaging and holographic displays are discussed.
May. 25, 2025Vol. 62 Issue 10 1000001 (2025)
Yuwang Deng, Jun Liu, Hailong Xiao, Shijiang Shu, Shennan Wang, and Biao Zhang
Single-photon detection (SPD) lidar is an innovative technology designed to detect weak light levels, enabling the detection and counting of single photons. This lidar system offers outstanding features, including high resolution, high accuracy, and continuous data acquisition. Unlike traditional lidar systems, SPD lidar reconstructs the discrete waveform of echo photons through time integration, enabling it to capture reflected signals from various atmospheric components. It is capable of detecting aerosols, clouds, greenhouse gases, wind fields, atmospheric density, and visibility. This research highlights SPD technology and summarizes its atmospheric applications and advancements worldwide. SPD lidar presents significant engineering prospects and plays an increasingly important role in atmospheric sounding. Finally, future trends in the development of this lidar technology are discussed.
May. 25, 2025Vol. 62 Issue 10 1000002 (2025)
Wanyun Li, Yasheng Zhang, Yuqiang Fang, Qinyu Zhu, and Xinli Zhu
With the rapid advancement of deep learning technology, 3D reconstruction has achieved significant breakthroughs, becoming a pivotal research direction in computer vision. This paper reviews the applications and recent advancements of deep learning in 3D reconstruction and provides an in-depth discussion of various techniques and emerging trends in the field. Deep learning enables the automatic extraction of features from images through the training of large-scale datasets, facilitating precise reconstruction of 3D shapes. The paper explores 3D reconstruction approaches based on deep learning, focusing on two primary representation types: explicit and implicit. In addition, it introduces classical 3D reconstruction datasets, which provide valuable data resources for training and validating deep learning models. Finally, the paper concludes with a summary and an outlook on future directions in 3D reconstruction research.
May. 25, 2025Vol. 62 Issue 10 1000003 (2025)
Dongdong Shi, Jun Zou, Limin Liu, Fuyu Huang, and Li Li
With the continuous advancement of optoelectronic technology, the demand for wide-area detection systems has become increasingly urgent. Super-large field-of-view infrared imaging technology has emerged as a research hotspot for institutions and military organizations owing to its strong spatial capacity, high real-time time domain performance, accurate target recognition, and excellent adaptability to various environments. This article elucidates the three primary imaging methods of super-large field-of-view infrared imaging technology, analyzing the technical details and characteristics of various imaging systems. Further, the application value of this technology is explored across multiple fields including military reconnaissance, intelligent driving, omnidirectional warning, target tracking, and camouflage recognition. The research progress of critical technologies such as corner detection, system calibration, and image registration is also discussed. Finally, considering the limitations and challenges of current technology, future development directions are proposed. These include the optimization of the lens structure and algorithms of imaging systems, improvement of imaging quality, and enhancement of stitching accuracy. Such advancements aim to promote continuous innovation and development of ultra-large field-of-view infrared imaging technology.
May. 25, 2025Vol. 62 Issue 10 1000004 (2025)
Shuai Zhong, and Liping Wang
In recent years, unmanned aerial vehicles (UAVs) have become pivotal across various fields due to their remarkable flexibility, maneuverability, and precise target perception capabilities. Integrating deep learning-based object detection methods with UAV systems has become a major focus of contemporary research and applications. However, during practical deployment and detection, UAV systems often face limitations such as restricted computational resources, interference from complex backgrounds, and low image resolution, which can degrade model performance and hinder the efficiency and accuracy of detection tasks. This study systematically describes the difficulties and challenges associated with object detection in UAV aerial image. It then reviews existing deep-learning methods and optimization strategies aimed at overcoming these issues. Additionally, the study gives a detailed overview of the existing aerial image datasets, to provide data support for further research. Finally, the study summarizes future research directions and development trends, emphasizing critical issues that demand further exploration. This study aims to serve as a valuable reference and guide for advancing future studies.
May. 25, 2025Vol. 62 Issue 10 1000005 (2025)
Yue Wang, Yanhong Jing, Haifeng Zhang, Zeyu He, Fengying Yue, Sen Dong, and Weining Chen
Image measurement, as a noncontact pose-measurement technology, has been widely applied in various space exploration and measurement tasks in the aerospace industry. It captures spatial targets through visual imaging devices, combines the three-dimensional (3D) spatial features of the targets and their two-dimensional projections in the image, and calculates the pose parameters of the targets. This paper introduces the current development status of a rocket-borne image-measurement device and summarizes the problems it encounters and the corresponding solutions. Based on two specific applications, namely the separation of the rocket body and the measurement of the rocket-nozzle attitude, the principles and development of key technologies for rocket-borne image measurement in the aerospace field are summarized. Finally, based on the current research status and key technology analysis, the main challenges of rocket-borne image-measurement technology are discussed and recommendations for future development are provided.
May. 25, 2025Vol. 62 Issue 10 1000006 (2025)
Yuyang Xing, Huiqin Wang, Ke Wang, Zhan Wang, and Yuan Li
Drones equipped with hyperspectral imaging devices can efficiently collect surface information from city walls for disease detection. However, the mounted devices can only capture five-channel spectral data, which results in insufficient spectral information and low detection accuracy. To address these issues, a spatial-spectral joint learning network for spectral information expansion is proposed to improve the detection accuracy of city wall disease detection. The proposed network employs a 2D spatial feature extraction module and a 3D spatial-spectral feature expansion module to extract shallow spatial features and spatial-spectral joint features at different depths, respectively. The spectral information dimension is progressively increased by splicing processing. Finally, multi-band spectral images are generated via fusion processing. The mean squared error and spectral angle mapper are used as a combined loss function to significantly reduce the error between the expanded and real spectral information. The disease detection accuracy for city walls using the expanded spectral images is 94.88%, which represents a 14.77 percentage points improvement over that of using five-channel spectral images. The experimental results demonstrate that the proposed method confers benefits in city wall disease detection tasks in sparse-channel scenarios.
May. 25, 2025Vol. 62 Issue 10 1030001 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20