






Please enter the answer below before you can view the full text.


2025
Volume: 52 Issue 5
10 Article(s)

Ting Mei, Jingwei Zhao, Shanling Lin, Ziyu Xie, Zhixian Lin, and Tailiang Guo
Aiming at the problem that the single-stage YOLACT algorithm based on bounding box detection lacks the location and extraction of the region of interest, and the issue that two bounding boxes overlap and are difficult to distinguish, this paper proposes an anchor-free instance segmentation method based on the improved YOLACTR algorithm. The mask generation is decoupled into feature learning and convolution kernel learning, and the feature aggregation network is used to generate mask features. By adding position information to the feature map, multi-layer transformer and two-way attention are used to obtain dynamic convolution kernels. The experimental results show that this method achieves a mask accuracy (AP) of 35.2% on the MS COCO public dataset. Compared with the YOLACT algorithm, this method improves the mask accuracy by 25.7%, the small target detection accuracy by 37.1%, the medium target detection accuracy by 25.8%, and the large target detection accuracy by 21.9%. Compared with YOLACT, Mask R-CNN, SOLO, and other methods, our algorithm shows significant advantages in segmentation accuracy and edge detail preservation, especially excelling in overlapping object segmentation and small target detection, effectively solving the problem of incorrect segmentation in instance boundary overlap regions that traditional methods face.
May. 30, 2025Vol. 52 Issue 5 240265 (2025)
Qin Bai, Rui Zhang, Peng Xue, Zhibin Wang, and Quanhuizi Kong
To achieve high-precision measurement of the all-Stokes vector, a mutual differential frequency modulation approach for dual photo-elastic modulators (photoelectric modulator, PEM) in all-Stokes vector measurement was proposed. The incident light was differently frequency modulated by two PEMs of different frequencies. The measured polarization vector and the phase delay amplitude of the PEM were simultaneously modulated at different differential frequency components. The phase delay amplitude of the PEM was obtained in real time by dividing the odd differential frequency components, and the Stokes vector of the measured light was accurately obtained by combining different differential frequency components. This method reduced the error introduced by the fluctuation of the phase delay amplitude in the PEM measurement system. Theoretical and experimental analyses were conducted, and the results showed that the variance of the measured Stokes vector was 10?5. This method will provide support for high-precision polarization measurement.
May. 30, 2025Vol. 52 Issue 5 240284 (2025)
Zhenjiu Xiao, Siyu Lai, and Haicheng Qu
To address the challenges of missed detection and false detection caused by complex backgrounds, varying illumination, target occlusion, and scale diversity in UAV images, this paper proposes a multi-level refined object detection algorithm for UAV imagery. First, a CSP-SMSFF (cross-stage partial selective multi-scale feature fusion) module is designed by integrating multi-scale feature extraction and feature fusion enhancement strategies. This module employs incremental convolutional kernels and channel-wise fusion to precisely capture multi-scale target features. Second, an AFGCAttention (adaptive fine-grained channel attention) mechanism is introduced, which optimizes channel feature representations through a dynamic fine-tuning mechanism. This enhances the algorithm’s sensitivity to critical multi-scale sample features, improves discriminative capability, preserves fine-grained mapping information, and suppresses background noise to mitigate missed detection. Third, a SGCE-Head (shared group convolution efficient head) detection head is developed, leveraging EMSPConv (efficient multi-scale convolution) to achieve precise capture of global salient features and local details in spatial-channel dimensions, thereby enhancing localization and recognition of multi-scale features and reducing false positives. Finally, the Inner-Powerful-IoUv2 loss function is proposed, which balances localization weights for samples of varying quality through dynamic gradient weighting and hierarchical IoU optimization, thereby strengthening the model’s capability to detect ambiguous targets. Experimental results on the VisDrone2019 and VisDrone2021 datasets benchmark demonstrate that the proposed method achieves 47.5% and 45.3% in mAP@0.5 under two evaluation settings, surpassing baseline models by 5.7% and 4.7%, respectively, and outperforming existing comparative algorithms.
May. 30, 2025Vol. 52 Issue 5 240287 (2025)
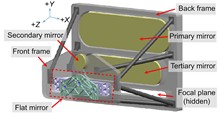
Jian Yuan, Lei Zhang, Siyu Pei, Xiaotao Li, and Guanchen Zhang
The flat mirror with the characteristics of large aspect ratio and high lightweight rate is one difficulty in the opto-mechanical design of a large off-axis three-mirror anastigmat cameras. For a certain flat mirror with a clear aperture of 1220 mm×198 mm, the assembly structure combining a semi-closed mirror blank made of silicon carbide with the three-point back support scheme was proposed, resulting in a total design weight of 30.5 kg. The supporting effect of the mirror was improved through the optimization of support positions. Both the size and position of hinges in the flexure were adjusted, taking into account gravitational deformation, thermal stability, and dynamic characteristics of the assembly. Simulation reveals that, under the condition of gravity during the test, the root mean square (RMS) of the surface accuracy change of the flat mirror is 1.812 nm, together with the tilt of 3.639" for the mirror blank. The measured fundamental frequency of the assembly is 132.5 Hz. After polishing, the tested RMS values of surface accuracy are 0.0203λ, 0.0197λ, and 0.0204λ (λ=632.8 nm), corresponding to the left, middle, and right sub-zones of the flat mirror respectively. The surface accuracy can remain basically unchanged after environmental tests, which meets the requirements of high-performance space cameras.
May. 30, 2025Vol. 52 Issue 5 250006 (2025)
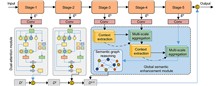
Xiaomin Zhang, and Lingxin Bao
To address the challenge of prolonged acquisition times in magnetic resonance imaging (MRI), data-driven algorithms and the model integration have emerged as crucial approaches for achieving high-quality MRI reconstruction. However, existing methods predominantly focus on visual feature extraction while neglecting deep semantic information critical for robust reconstruction. To bridge this gap, this study proposes a model-driven architecture that synergistically combines hierarchical semantic networks with physical model networks, aiming to enhance reconstruction performance while maintaining computational efficiency. The architecture comprises four core modules: a context extraction module to capture rich contextual features and mitigate background interference; a multi-scale aggregation module integrating multi-scale information to preserve coarse-to-fine anatomical details; a semantic graph reasoning module to model semantic relationships for improved tissue differentiation and artifact suppression; a dual-scale attention module to enhance critical feature representation across different detail levels. This hierarchical and semantic-aware design effectively reduces aliasing artifacts and significantly improves image fidelity. Experimental results demonstrate that the proposed method outperforms state-of-the-art approaches in both quantitative metrics and visual quality across diverse datasets with varying sampling rates. For instance, in 4× radial acceleration experiments on the IXI dataset, our approach achieved a peak signal-to-noise ratio (PSNR) of 48.15 dB, surpassing the latest comparison algorithms by approximately 1.00 dB on average, while enabling higher acceleration rates and maintaining reliable reconstruction outcomes.
May. 30, 2025Vol. 52 Issue 5 250016 (2025)
Xijun Zhao, Bin Fan, and Jun Liao
This paper presents a hybrid multi-order diffractive lens that supports dual-band computational imaging in both visible and mid-wave infrared (MWIR) bands. By applying diffraction structures of varying depths on both sides of the same substrate and optimizing these structural parameters using the end-to-end optimization framework, we successfully developed a diffractive element capable of efficient focusing in the visible light band (640~800 nm) and the MWIR band (3700~4700 nm). Coupled with a specially designed image reconstruction network, this approach realizes a monolithic dual-band computational imaging system with simplicity, lightweight construction, and low cost. Experimental results show that the prototype with a diameter of 40 mm achieves static modulation transfer functions of 50.0% in the visible light band and 4.4% in the MWIR band. Under room temperature conditions, the noise equivalent temperature difference in the infrared band does not exceed 80 mK, confirming the effectiveness and practicality of the proposed design.
May. 30, 2025Vol. 52 Issue 5 250023 (2025)
Haolei Jia, Naiting Gu, and Libo Zhong
Electrostatically driven membrane deformable mirrors correct wavefront aberrations through electrostatic forces, whose correction capability dependent on driving load accuracy. Due to the charge aggregation at the electrode edges, non-uniform deformation occurs due to the nonlinear change of the regional load, which causes inaccurate or incorrect assessment of the calibrated wavefront aberration of electrostatically driven membrane deformable mirrors. Based on this, this work carries out a study on electrostatically driven membrane deformable mirror electrode edge effect and its influence on correction capability assessment, establishes a theoretical model of electrode edge effect, and quantitatively analyzes the influence of electrode edge deformation response and correction capability assessment accuracy based on the model, and the results show that before and after the consideration of the edge effect, the error of correction capability assessment is improved from 25.49% to 6.83% or even lower, and applies to different electrode spacing parameters, which verifies the correctness of the theoretical model proposed in this paper.
May. 30, 2025Vol. 52 Issue 5 250025 (2025)
Yujie Ma, Chuqing Cao, and Jing Zhang
In order to improve the detection capability of small target defects in steel surface inspection, an improved YOLOv8-SOE model is proposed. The model processes the P2 layer features by designing the FSCConv module. By compressing the P2 layer features and deeply fusing them with the P3 layer features, the model's sensitivity to small target features is effectively enhanced, while avoiding the computational burden caused by the introduction of additional detection layers. In order to further optimize the multi-scale feature fusion capability, cross stage partial omni-kernel (CSP-OK) module is used to optimize the multi-scale feature fusion, which improves the integration efficiency of features of different scales. The SIoU loss function is introduced to optimize the bounding box regression, which further improves the positioning accuracy. Experimental results show that the mAP of the YOLOv8-SOE model on the NEU-DET dataset achieves 80.7%, which is 5.4% higher than the baseline model, and has good generalization ability on the VOC2012 dataset. While improving the accuracy of small target detection, the model maintains a high computational efficiency and has good application prospects.
May. 30, 2025Vol. 52 Issue 5 250032 (2025)
Zecan Zheng, Sicong Wang, Jiahao Feng, Zhikai Zhou, Shukang Chen, Shichao Song, Zilan Deng, Fei Qin, Yaoyu Cao, and Xiangping Li
Optical bubble, characterized by a tightly focused three-dimensional dark-field intensity distribution, exhibits significant application value in fields such as optical manipulation and laser processing. In previously reported results, an optical bubble is typically generated through multi-beam interference and superposition, which involves complex optical setups and is not conducive to system integration and practical applications, and has low energy utilization efficiency. In this study, we utilize single-beam vector field modulation technology to generate a tightly focused optical bubble with high intensity uniformity. Furthermore, we achieve the detection of this hollow bubble through polarization conversion of the probe light. By adjusting the energy ratio between azimuthally polarized incident beam and radially polarized incident beam modulated by a 0/π binary phase, we experimentally realize an optical bubble with an edge-to-center dark spot intensity ratio exceeding 10:1 and edge intensity uniformity approaching 90%. This work provides a feasible technical approach for applications in dual-beam super-resolution laser processing, optical data storage, and particle manipulation.
May. 30, 2025Vol. 52 Issue 5 250052 (2025)
Yemei Sun, Xueting Sang, Yan Zhang, Guorui Liu, and Shuaiyu Chen
UAV aerial images have the characteristics of complex background, small and dense targets. Aiming at the problems of low precision and a large number of model parameters in UAV aerial image detection, an efficient multi-scale feature transfer small target detection algorithm based on hypergraph computation is proposed. Firstly, a multi-scale feature pyramid network is designed as a neck network to effectively reduce the problem of information loss caused by lengthy transmission paths by fusing multi-layer features in the middle layer and transmitting them directly to adjacent layers. In addition, the feature fusion process uses hypergraphs to model higher-order features, improving the nonlinear representation ability of the model. Secondly, a lightweight dynamic task-guided detection head is designed to effectively solve the problem of inaccurate detection targets caused by inconsistent classification and positioning task space in the traditional decoupling head with a small number of parameters through sharing mechanism. Finally, the pruning lightweight model based on layer adaptive amplitude is used to further reduce the model volume. The experimental results show that this algorithm has better performance than other architectures on VisDrone2019 dataset, with the accuracy mAP0.5 and parameter number reaching 42.4% and 4.8 M, respectively. Compared with the benchmark YOLOv8, the parameter number is reduced by 54.7%. The model achieves a good balance between detection performance and resource consumption.
May. 30, 2025Vol. 52 Issue 5 250061 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20