






 View fulltext
View fulltext
Advanced Imaging
Co-Editors-in-Chief
Xiaopeng Shao, Sylvain Gigan, Feihu Xu

2025
Volume: 2 Issue 5
6 Article(s)

Jitao Zhang
Sep. 23, 2025Vol. 2 Issue 5 053001 (2025)
Chenyu Xu, Zhouyu Jin, Chengkang Shen, Hao Zhu, Zhan Ma, Bo Xiong, You Zhou, Xun Cao, and Ning Gu
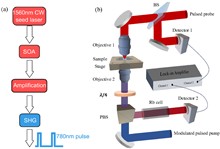
Compared to light-field microscopy (LFM), which enables high-speed volumetric imaging but suffers from non-uniform spatial sampling, Fourier light-field microscopy (FLFM) introduces sub-aperture division at the pupil plane, thereby ensuring spatially invariant sampling and enhancing spatial resolution. Conventional FLFM reconstruction methods, such as Richardson–Lucy (RL) deconvolution, may face challenges in achieving optimal axial resolution and preserving signal quality due to the inherently ill-posed nature of the inverse problem. While data-driven approaches enhance spatial resolution by leveraging high-quality paired datasets or imposing structural priors, physics-informed self-supervised learning has emerged as a compelling precedent for overcoming these limitations. In this work, we propose 3D Gaussian adaptive tomography (3DGAT) for FLFM, a 3D Gaussian splatting-based self-supervised learning framework that significantly improves the volumetric reconstruction quality of FLFM while maintaining computational efficiency. Experimental results indicate that our approach achieves higher resolution and improved reconstruction accuracy, highlighting its potential to advance FLFM imaging and broaden its applications in 3D optical microscopy.
Sep. 23, 2025Vol. 2 Issue 5 055001 (2025)
Zhengyu Qiao, Yong Huang, Lizhi Sun, Dan Zhang, and Qun Hao
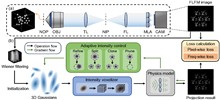
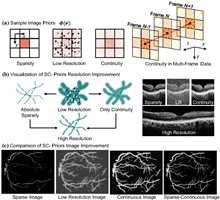
Optical coherence refractive tomography (OCRT) addresses the anisotropic resolution in conventional optical coherence tomography (OCT) imaging, effectively reducing detail loss caused by resolution non-uniformity, and demonstrates strong potential across a range of biomedical applications. Full-range OCRT technique eliminates conjugate image artifacts and further extends the imaging field, enabling large-scale isotropic reconstruction. However, the isotropic resolution achieved through OCRT remains inherently limited by the maximum resolution of the acquired input data, both in the axial and lateral dimensions. Enhancing the resolution of the original images is therefore critical for achieving higher-isotropic reconstruction. Existing OCT super-resolution methods often exacerbate imaging noise during iterative processing, resulting in reconstructions dominated by noise artifacts. In this work, we present sparse continuous full-range optical coherence refractive tomography (SC-FROCRT), which integrates deconvolution-based super-resolution techniques with the full-range OCRT framework to achieve higher resolution, expanded field-of-view, and isotropic image reconstruction. By incorporating the inherent sparsity and continuity priors of biological samples, we iteratively refine the initially acquired low-resolution OCT images, enhancing their resolution. This model is integrated into the previously established full-range OCRT framework to enable isotropic super-resolution with expanded field-of-view. In addition, the FROCRT technique leverages multi-angle Fourier synthesis to effectively mitigate reconstruction artifacts that may arise from over-enhancement by the super-resolution model. We applied SC-FROCRT to phantom samples, sparse plant tissues, and cleared biological tissues, achieving the Fourier ring correlation (FRC) metric improved by an average of 1.41 times over FROCRT. We anticipate that SC-FROCRT will broaden the scope of OCT applications, enhancing its utility for both diagnostic and research purposes.
Aug. 25, 2025Vol. 2 Issue 5 051001 (2025)
Xinyuan Zhang, Leqi Shan, Jiajie Fang, Rui Guo, Shilong Xu, Yicheng Wang, Yulin Guo, Xing Yang, Fei Han, and Yihua Hu
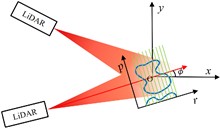
Overcoming the diffraction barrier in long-range optical imaging is recognized as a critical challenge for space situational awareness and terrestrial remote sensing. This study presents a super-resolution imaging method based on reflective tomography LiDAR (RTL), breaking through the traditional optical diffraction limit to achieve 2 cm resolution imaging at a distance of 10.38 km. Aiming at challenges such as atmospheric turbulence, diffraction limits, and data sparsity in long-range complex target imaging, the study proposes the applicable methods of the nonlocal means (NLM) algorithm, combined with a self-developed RTL system to solve the problem of high-precision reconstruction of multi-angle projection data. Experimental results show that the system achieves a reconstruction resolution for complex targets (NUDT WordArt model) that is better than 2 cm, which is 2.5 times higher than the 5 cm diffraction limit of the traditional 1064 nm laser optical system. In sparse data scenarios, the NLM algorithm outperforms traditional algorithms in metrics such as information entropy (IE) and structural similarity (SSIM) by suppressing artifacts and maintaining structural integrity. This study presents the first demonstration of centimeter-level tomographic imaging for complex targets at near-ground distances exceeding 10 km, providing a new paradigm for fields such as space debris monitoring and remote target recognition.
Aug. 29, 2025Vol. 2 Issue 5 051002 (2025)
Xiaojing Feng, Juanzi He, Xingyu Liu, Xiaoshu Zhu, Yifan Zhou, Xinyang Feng, and Shuming Wang
Phase contrast microscopy is essential in optical imaging, but traditional systems are bulky and limited by single-phase modulation, hindering visualization of complex specimens. Metasurfaces, with their subwavelength structures, offer compact integration and versatile light field control. Quantum imaging further enhances performance by leveraging nonclassical photon correlations to suppress classical noise, improve contrast, and enable multifunctional processing. Here, we report, a dual-mode bright–dark phase contrast imaging scheme enabled by quantum metasurface synergy. By combining polarization entanglement from quantum light sources with metasurface phase modulation, our method achieves high-contrast, adaptive bright–dark phase contrast imaging of transparent samples with arbitrary phase distributions under low-light conditions. Compared to classical weak light imaging, quantum illumination suppresses environmental noise at equivalent photon flux, improving the contrast from 0.22 to 0.81. Moreover, quantum polarization entanglement enables remote switching to ensure high-contrast imaging in at least one mode, supporting dynamic observation of biological cells with complex phase structures. This capability is especially valuable in scenarios where physical intervention is difficult, such as in miniaturized systems, in vivo platforms, or extreme environments. Overall, the proposed scheme offers an efficient non-invasive solution for biomedical imaging with strong potential in life science applications.
Sep. 23, 2025Vol. 2 Issue 5 051003 (2025)
DWS-Net: a depth-wise separable convolutional neural network for robust phase-only hologram encoding
Shu-Feng Lin, Jingwei Chen, Dayong Wang, Jie Zhao, Lu Rong, Yunxin Wang, Yu Zhao, and Chao Ping Chen
Neural-network-based computer-generated hologram (CGH) methods have greatly improved computational efficiency and reconstruction quality. However, they will no longer be suitable when the CGH parameters change. A common phase-only hologram (POH) encoding strategy based on a neural network is presented to encode POHs from complex amplitude holograms for different parameters in a single training. The neural network is built up by introducing depth-wise separable convolution, residual modules, and complex-value channel adaptive modules, and it is randomly trained with traditional training input image datasets, a built wavelength pool, and a reconstructed distance pool. The average peak signal-to-noise ratio/structural similarity index measure (PSNR/SSIM) for the proposed network encoded POHs can reach 29.19 dB/0.83, which shows 117.35% and 144.12% improvement compared with the double-phase encoding strategy. The variances of the PSNR and SSIM in different reconstructed distances and different wavelengths are increased by 86.83% and 80.65%, respectively, compared with traditional networks in this strategy. Such a method makes it possible to encode multiple complex amplitude holograms of arbitrary wavelength and arbitrary reconstructed distance without the need for retraining, which is friendly to digital filtering or other operations within the CGH generation process for CGH designing and CGH debugging.
Sep. 22, 2025Vol. 2 Issue 5 051004 (2025)

© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20