









Please enter the answer below before you can view the full text.
8-3=

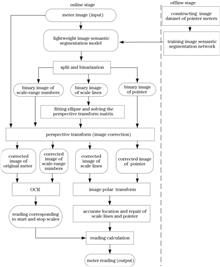
To use the characteristics of pointer meter images without the limitation of existing reading recognition methods, a fully automatic reading recognition method based on a lightweight image semantic segmentation model is proposed. In the proposed method, the lightweight semantic segmentation network CGNet is modified by implementing the channel attention module SENet to enhance and aggregate image features and by deepening classification layers appropriately to predict more accurate semantic pixels of scale lines, pointers, and scale-range numbers. Then, according to the semantic segmentation results, an ellipse is fitted, and perspective transform between the ellipse and a standard circle is performed to correct skewed images. Scale lines and pointers are then extracted from the corrected images by postprocessing operations such as polar transform, image thinning, and vertical projection, and scale-range numbers are recognized using optical character recognition technology. Finally, the meter reading is calculated according to the scale range and relative position of the pointer and scale lines. An image dataset of pointer meters is constructed to validate the proposed method. Experimental results demonstrate that the proposed method realizes significant improvement of image semantic segmentation precision compared to existing lightweight models, and the average relative error of reading recognition for images on the test set is approximately 0.63%, which satisfies the requirements of practical applications.
In this paper, we propose an improved YOLOv4 target detection model combined with an MSRCR image enhancement algorithm to mitigate the poor visual effect, large-scale difference, and unbalanced data category in infrared images of power equipment. First, we constructed a target detection dataset of infrared images of power equipment and applied the MSRCR algorithm to enhance the original infrared images and improve the low contrast and blur pixel of infrared images in rain and fog weather. This improves the detection ability of the model to power equipment in rain and fog weather. Second, a multi-scale convolution module was introduced in the YOLOv4 backbone network to obtain multi-scale features of input images using convolution kernels with different sizes to enhance the initial feature representation. To further improve the detection accuracy, the Focal loss function was used to solve the difficult problem of classification caused by unbalanced infrared image data. The test results show that the average recognition accuracy of the proposed method for eight power equipments is 96.31%, and the detection speed is 71 frame/s. The experimental results verify the effectiveness of the proposed method.
To address the issue that the existing multitarget detection network cannot extract and enhance dynamic flame features, resulting in poor detection results, this paper presents an improved YOLOv3 flame detection algorithm based on dynamic shape feature extraction and enhancement. ResNet50_vd with a small size structure is used as the backbone network of YOLOv3 to reduce the redundancy of feature information. To control the dynamic change of the sampling grid with the shape of the flame target, deformable convolutional neural network modules are added to the backbone network stage 4 and stage 5. The IoU Aware module is introduced to increase the correlation between the confidence score and the positioning accuracy of the IoU, and to enhance the flame feature extraction ability of the network. Simultaneously, the Drop Block module is added to the YOLOv3 Head, and the IoU prediction component is introduced to optimize the loss function, which improves the feature enhancement ability during the model learning process. The ablation experiments were performed to verify the effect of each improvement on the proposed model. The results show that the improved model for flame detection has a detection accuracy of 94.11% and an inference speed of 73.52 frame/s, which can effectively meet the detection requirements of dynamic shape flames.
Traditional methods cannot fully mine image-focus association information, thereby leading to the distortion of fusion details. In this study, a multi-focus image fusion method based on collaborative detection via densely connected convolutional neural networks is proposed to address this issue. Multi-focused source images are integrated to detect focused features collaboratively, and the features of deep dense convolutional networks, such as feature reuse, and the combination of low-level and high-level features are used to enhance the multi-focused image feature representation, which better mine the images' semantic information. By leveraging feature reuse, multi-focus source images are integrated to achieve collaborative focus feature detection. The multi-scale pyramid pooling strategy is used to aggregate the global context information of different focus regions to enhance the ability to distinguish the focused and defocused areas and obtain a rough fusion-probability decision graph. Furthermore, a convolution conditional random field (CRF) is adopted to optimize the decision graph and the refined probabilistic decision graph is obtained. Finally, the fused image is obtained with its details preserved. A pair of multi-focused images are combined into six channels and fed into the network for training, thus ensuring that the focused areas are correlated. The proposed method is evaluated subjectively and objectively using public data sets. The experimental results show that the proposed method produces effective fusion and fully mines the focused association information and retains sufficient image detail.
In view of the low efficiency and poor effect of the traditional mushroom feature extraction method, a lightweight mushroom image classification model is proposed. In view of the small dataset used in the experiment, this classification model initializes the EfficientNetV2 model and modifies the full connection layer in the migration study based on the Imagenet dataset. At the same time, in order to reduce the parameter influence in the network, the original EfficientNetV2 model is streamlined to remove duplicate modules in the network. Finally, the squeeze-and-excitation mechanism in the original MBConv module is replaced with the coordinate attention (CA) attention mechanism with better feature extraction effect, and the new CA-EfficientNetV2 network is obtained. The experimental results show that compared with the classical ResNet50 model and RegNet, the classification accuracy of the proposed EfficientNetV2 is improved by about 10 percentage points and 2 percentage points respectively, and higher generalization performance is obtained; compared with the original EfficientNetV2, the classification accuracy is improved by 3 percentage points. That is, CA-EfficientNetV2 has higher accuracy and classification performance in mushroom classification.
Most cross-modal Hash methods based on deep learning learn unified Hash codes of different-modality data directly through neural networks. However, these methods ignore the factor that different scales of single-modality data contain different semantic information, which affects the data feature representation, and the importance of low-dimensional features in bridging the "heterogeneity" gap. Based on the above problems, we propose a new cross-modal Hash retrieval method (MFPMC) based on multi-scale fusion and projection matching constraint, which obtains low-dimensional features of different-modality data by designing the image multi-scale fusion network and text multi-scale fusion network. Moreover, it introduces the low-dimensional feature projection matching constraint and adversarial training to ensure the distribution consistency of low-dimensional features among different modalities. Simultaneously, low-dimensional features containing rich semantic information are used as inputs for the Hash function. Furthermore, inter-modal Hash code, intra-modal Hash code, quantization, and label-embedding losses are constructed to constrain the learning of Hash function and Hash codes to ensure the generation of discriminative discrete binary Hash codes. Experiments on two benchmark cross-modal retrieval datasets (MIRFlickr-25K and NUS-WIDE) reveal that the proposed method outperforms other methods in terms of retrieval performance.
To achieve accurate detection of items in the warehousing environment, a lightweight warehousing cargo detection method (E-YOLOv4-Lite) is proposed for use in intelligent warehousing robots. This technique builds on YOLOv4 by introducing the MobileNetv3 network to reconstruct the feature extraction network, replacing standard convolution in PANet with deep separable convolution, and reducing the number of model parameters and processing. The improved convolutional block attention module (CBAM) is integrated to improve network detection performance further. In the channel attention module, the improved CBAM replaces the full connection layer with adaptive one-dimensional convolution, and in the spatial attention module, the residual structure with expansive convolution is used to expand the receptive field. Finally, the network training and experimental tests are conducted through the RPC commodity data set, the number of parameters is 11.25 MB, the detection time is 14.4 ms, the frames per second is 69.2, and the mean average precision is 95.43%. The experimental results reveal that the improved E-YOLOv4-Lite model has the advantages of high accuracy, good real-time performance, and lightweight, allowing it to better meet the needs of cargo detection in storage environments.
Aiming at the problem of low detection accuracy and slow detection speed of insulator defects in transmission lines, a defect detection method for transmission line insulators based on multi-scale feature coding and double attention fusion is proposed. First, in order to adapt the detection model to the diversity of characteristic scales of defective insulators, the coding network uses Res2Net50 to extract more fine-grained features, and then embeds the atrous spatial pyramid pooling structure to capture the characteristics of insulators and their defects at multiple scales. Second, in order to reduce the lack of feature information in the decoding network, The different feature layers of the backbone network are connected in series with the efficient channel attention attention module, and they are added to the deconvolution features of the squeeze and excitation attention module to form a double attention fusion. Finally, Experiments show that the mean average precision index of the proposed method reaches about 95.35%, and the frames per second reaches about 65.95, and compared with other algorithms, this method has certain reference value for realizing the accurate detection of insulator defects of unmanned aerial vehicles.
With the development of three-dimensional (3D) measurement technology, how to quickly and accurately measure the 3D shape of large scene objects has become a research hotspot. This study improves the phase measurement profilometry, uses an improved phase calculation method for measuring the 3D information of the object, and combined with the amplitude information, the problem that the phase measurement profilometry can only measure the surface information, but can not accurately measure the position of the object is solved. Our proposed method can suitably measure the 3D information of each object in a large scene. The experimental results show that the proposed method is simple in principle and is good for measuring discontinuous objects. Furthermore, it not only determines object position but also measures the 3D information on the surface of the object.
Field outcrops are affected by natural conditions, and the outcrop surfaces are covered with vegetation and severely weathering, which makes the traditional lithology image recognition methods more challenging to implement. Combining artificial intelligence for rock image recognition lithology in the geological field has become an unavoidable trend with the advent of geological big data and the rising demand for intelligent geology. In this study, we propose SE-DeepLabv3+, an intelligent lithology recognition approach for multimodal clastic rock outcrop images based on an attention mechanism. The SE-DeepLabv3+ achieves more than 90% accuracy in lithology recognition when compared to classical classification methods and semantic segmentation methods, with hand annotation results as a reference, which is greater than other methods. For lithology identification, the SE-DeepLabv3+ was used on certain outcrop sections of the Qingshuihe-Karaza Formation along the southern boundary of the Junggar Basin in Xinjiang, and better identification results were obtained. The study employs UAV 3D image data, combined with artificial intelligence technology to identify the lithology of clastic outcrops, which can significantly enhance the efficiency of lithology identification, transform the conventional operation mode, and advance geological research toward quantification and intelligence.
The existing incomplete text image restoration must identify and fill the Mask region. The Mask region cannot be determined if the residual information of the incomplete text part is too sparse. A blind restoration method of incomplete and sparse text images based on content style transfer is proposed to address this issue. Using a cyclic generative adversarial network to construct the global related pixel information between the text images before and after restoration, the image content style features of the incomplete text were transferred to complete text images for restoration. The selfattention mechanism is added to the network to globally restrict the sparse pixels, thereby resolving the issue of weak dependence between the text sparse pixels far away in the migration process. simultaneously, the maximum pooling is used in the selfattention mechanism to enhance the texture features of the text images after migration and restoration. To improve migration accuracy, the least square loss function is used to replace the sigmoid cross-entropy loss function in the original network model. The proposed algorithm can repair random unknown missing regions in sparse incomplete text images without the assistance of Mask, according to experimental results.
Background removal remains one of the most challenging issues in the phase retrieval from a single frame fringe projection pattern. This study proposes a modified fuzzy c-means (FCM) clustering algorithm to remove background from a single fringe projection pattern. To remove the background part from the fringe projection patterns, a modified FCM algorithm was used to divide the fringes into black and white fringes and optimize the modified FCM objective function to get the background part. The performance of this algorithm was evaluated by applying it to two simulated and one experimental fringe projection pattern. Furthermore, it was compared with the Fourier transform method, morphological operation-based bidimensional empirical mode decomposition method, and variational decomposition TV-Hilbert-L2 model. The experimental results indicate that the proposed algorithm improves the ability of background removal and accuracy of phase extraction.
Medical professionals have started favoring the use of non-contact intravenous injection robots owing to their importance during the COVID-19 outbreak. However, there are currently few studies considering the robot's needle insertion angle, and most of the needle insertion operations are performed at a steep angle. This increases the rate of puncture failure, and sometimes causes significant pain in patients depending on their individual differences. Therefore, the intravenous injection of the dorsal hand is performed in this study to investigate the determination of the robot's needle insertion angle, with a focus on the optimization of the measurement data to ensure accuracy in the calculation of the needle insertion angle. First, the space point cloud of the needle insertion area on the dorsal hand is obtained by combining a monocular camera with the linear structured light scanning method, and the dorsal hand plane is obtained via fitting dorsal hand point clouds using the least squares method. During the calibration process for the linear structured light system, the measurement error is eliminated by formulating an error function and using the optimization method to iteratively solve it. Subsequently, the needle insertion angle is determined based on the obtained needle insertion area plane. Finally, experiments are conducted for the accuracy verification of the proposed method. Based on the experimental results, the average error in the optimized structured light plane position is approximately 0.1 mm, and this serves as a foundation for subsequent automatic injection studies.
This paper proposes and verifies an intelligent photon counting single pixel micro-imaging system. An object is imaged in a digital micromirror device (DMD) under a microscope. After a series of masks are loaded to the DMD for light modulation, modulated light intensity is detected by a space-distinguished single photon detector, and the original image is reconstructed using a deep learning network. The DMD flip and photon counting are implemented based on the exact multi-channel timing control performance of a programmable logic device. Simultaneously, an embedded Arm processor deploys deep learning rebuild networks in real time. Finally, DMD deflection control, photon counting, and a neural network reconstruction function are integrated in a software and hardware collaborative platform to take advantage of the platform's high integration, lightweight and low cost. Experimental results show that the image reconstruction quality of DFC-Net on Zynq is superior to that of the classic TVAL3 reconstruction algorithm at low sampling rates. Although increasing the number of measurements can obtain high quality reconstruction images, each measurement time should be sufficient to inhibit Poisson sculpture noise.
This study develops a transmission line warning device based on multi-source sensing to address the problem of real-time transmission line monitoring against mechanical collision. It also proposes a transmission line warning algorithm based on millimeter wave radar and visual fusion, and the algorithm's effectiveness is verified in a real scene. First, the front transmission lines were detected using a vision recognition algorithm based on standard deviation clustering. Second, a millimeter wave radar ranging algorithm based on an improved robust Kalman filter was used to measure the transmission line distance in real time, while visual detection was used to track the transmission line distance in real time. Finally, real-time warning and judgment for the preset mechanical collision line conditions were conducted based on the above visual detection and millimeter wave radar ranging results. The experimental results show that the visual recognition algorithm based on standard deviation clustering has an effective recognition distance of more than 20 m, a recognition accuracy of 93%, and an output frequency of 1 Hz, whereas the millimeter-wave radar ranging algorithm based on improved robust Kalman filter has a ranging accuracy of ±0.1 m, a ranging error of 2%, and an output frequency of 1 Hz. This device can meet the overall demand for real-time monitoring of transmission lines against mechanical collisions.
More than 230 thousand medical personnel worldwide have been infected with the novel coronavirus since the outbreak of COVID-19. Several medical professionals have praised the nonartificially contacted dorsal hand vein automatic injection method owing to its high isolation. The key for realizing no-contact automatic injection of dorsal hand veins is to realize the detection and segmentation of dorsal hand veins and determine the needlepoint position. In this study, an image processing algorithm based on improved U-Net with guidance and attention mechanism (AT-U-Net) is proposed to detect the dorsal hand vein. The proposed method was validated using a self-built dorsal hand vein database and the results indicate that it performs well with the accuracy of 93.6%. Following the detection of the dorsal hand vein, this study proposes a needle entry point location determination method for dorsal hand veins based on an improved pruning algorithm (PT-Pruning). The trunk line of the dorsal hand vein was extracted via PT-Pruning. The optimal injection point of the dorsal hand vein is determined by considering the vascular cross-sectional area and the bending value of each venous vein injection point area. Compared to the self-built dorsal hand vein injection point database, the detection accuracy of the injection area at the effective injection point is 96.73%, while the detection accuracy of the injection area at the optimal needle entry point is 96.5%. Thus this study lays the groundwork for subsequent mechanical automatic injection.
Traffic sign detection is an essential function of autonomous driving systems, and most modern traffic sign detectors are anchor-based, traversing potential object locations based on anchors. To solve the problems of heavy computing costs and the need to set several hyperparameters in anchor-based models, we propose an anchor-free traffic sign detection algorithm based on an encoder-decoder structure. We introduce a residual augmentation branch in the decoder module in this study to improve feature expression ability during the decoding process. To improve the ability to detect multiscale traffic signs, we propose a multiscale feature fusion subnetwork to effectively extract and use multiscale features. A Ghost lightweight module is adopted by the multiscale feature extraction module, which indistinctively increases the computational cost. On the Tsinghua-Tencent 100 K dataset, our approach achieved a recall of 92.5% and an accuracy of 90.3%, while the model's parameter amount and model size are approximately 1.61×107 and 64.4 Mbit, respectively. The experimental results show that the proposed algorithm outperforms the mainstream object detection algorithms in terms of precision, computing cost, and overall performance.
Model compression can significantly improve the deployment of convolutional neural networks on limited-resource devices. Filter pruning has gradually drawn attention from academia and industry as a research hotspot. The essence of filter pruning is the selection and retention of important filters. Existing research has primarily focused on static and interlayer filter selection, which still has redundancy in the compressed model. We propose an adaptive dynamic filter pruning approach in this paper wherein an activation weight generation module is introduced to generate the activation weight of each filter. The importance of filters in global convolutional layers is dynamically evaluated by embedding the activation weight generation module in various classical networks, and the filters that extract richer information are adaptively selected to reconstruct the pruned networks. Experiments are performed on CIFAR-10 and AUC datasets using different convolutional neural networks, among which the proposed method has better performance than several mainstream pruning methods on CIFAR-10 dataset. The accuracy decreased by 0.3 percentage points when the computation was compressed by ~70% before and after pruning on the AUC dataset. Experiments on various networks demonstrate the proposed method's ability to generalize to different models.
When the target tracking algorithm deals with occlusion, blur, scale transformation, and other challenges, it can easily result in drift and tracking failure; thus, an adaptive correlation filtering tracking algorithm for complex scenes is proposed. First, the proposed multi-feature complementarity method is employed to train the corresponding filters with features, and the fusion weight of features is dynamically adjusted according to the response value of each filter to complete the position estimation for the target. Then, a scale filter is constructed with the center position to estimate the optimal scale of the target. Finally, the multi-scale search region method is integrated, and the tracking model is selectively updated according to the tracking confidence degree, which further enhances the performance and anti-occlusion ability of the tracker. Tests were performed on 74 color datasets of OTB2015 and the proposed algorithm was compared with the advanced correlation filtering algorithms recently. The average distance accuracy of the proposed algorithm is 0.801, the average overlap accuracy is 0.715, and the real-time tracking speed is 39.24 frame/s. Experimental results show that the tracker performs well in a complex environment and has an excellent overall performance.
In this paper, we propose a rotating target detection algorithm using the improved YOLOv5m to solve the problems of low accuracy and poor target direction in the rotating target detection of optical remote sensing images. First, we integrate the attention mechanism module into the network to improve the ability of the model to extract important features. Second, we consider the contribution of the feature fusion at each node in the feature fusion module, with the addition of a skip connection with the same feature scale. Finally, the angles are discretized through densely coded labels due to the angles and boundaries in rotation detection. The experimental results show that this algorithm achieves a detection accuracy of 82.75% for a subset of DOTA data, indicating an improvement of 11.73 percentage points compared with the original YOLOv5m network when the model computation is reduced slightly. Furthermore, we achieved a detection accuracy of 88.89% in the HRSC2016 ship dataset. That is, the algorithm can effectively improve the accuracy of the rotation detection of optical remote sensing images.
Optical fiber is an indispensable transmission medium in modern communication system and quantum secure communication network. In order to solve the problem that the optical fiber end surface defects cause transmission quality decline or even permanent damage to optical transmission system, a fiber end surface detection model YOLOv5_CS based on YOLOv5 algorithm is proposed. Firstly, ShuffleNetV2, a lightweight network, is used as the main feature extraction network. Deep convolution operation and channel random mixing strategy are used to reduce model capacity and enrich feature information. Secondly, the convolutional block attention module (CBAM) is introduced, and features are enhanced in both spatial and channel dimensions to improve network performance. Finally, the number of convolution kernels in the feature fusion layer is reduced to achieve further model compression. The validity of the proposed method is compared and verified by the optical fiber end data set constructed by data augmentation technology. The results show that compared with the YOLOv5 algorithm, the model capacity of the proposed model is reduced by 80%, the detection speed is increased by 31.1 frame/s, and the mean average precision (mAP) is increased by 1.7%, which can accurately and real-time detect optical fiber end surface defects. This work is aimed at the development of portable intelligent detection device, and can also provide technical support for optical fiber end surface defects detection and related visual sensing industry.
Aiming to address the difficulties in the automatic registration of non-homologous laser scanning and photogrammetric point cloud data, a method based on fast point feature histogram (FPFH) point cloud coarse registration and the octree grid iteration improved nearest neighbor (ICP) algorithm is proposed. For coarse registration, a voxel grid is used to desample the point cloud data before applying the FPFH for feature matching. Finally, the sampling consistent initial registration (SAC-IA) algorithm is used to obtain the initial registration transformation matrix. For fine registration, the classical ICP algorithm is used to eliminate the wrong corresponding points by setting the Euclidean distance threshold. Then, the homonymous point pairs with the highest accuracy are selected in each voxel grid, and the final registration transformation matrix is calculated using the singular value decomposition (SVD) method. The experimental results show that the proposed method can be used to solve the registration problem of non-homologous data between laser scanning and photogrammetric point clouds and has certain research and application value.
Considering the narrow space, the design difficulty of the medical endoscope objective lies in performing local optical zoom and distinguishing the imaging view of locally enlarged human tissues. Therefore, the objective lens must meet the requirements of low chromatic aberration, high reliability, and miniaturization. From the analysis of the technical route for an endoscopic optical zoom, this study proposes the application of the Alvarez lens in the endoscope to achieve optical zoom. The proposed structure has the advantages of achieving simple zoom, stable structure, fast, and reliable imaging. First, we have developed the achromatic zoom optical design theory of the endoscope objective using the Alvarez lens based on the Gaussian bracket method and aberration theory. Then, we derived the initial optical design value of the achromatic objective lens system using the aberration theory. Finally, the optical chromatic aberration theory is used to verify the correctness of the theory, which provides an optical design theoretical basis for the further application of the Alvarez lens in the design of an endoscope.
A spectral focusing coherent anti-Stokes Raman scattering (CARS) microimaging system was developed using a femtosecond oscillator as the excitation source. Pump light and Stokes light were obtained by using dichromatic mirrors. Two- and three-dimensional microscopic imaging studies of the spectral focusing CARS imaging in the low-fingerprint region of polystyrene samples were carried out. While changing the delay time of pump-Stokes during two-dimensional imaging, CARS signal intensity spectra that varied with delay time were obtained. The switching of excited Raman vibrations in the process of changing the pump-Stokes delay time was analyzed by comparing it to the polystyrene Raman spectra. Furthermore, the three-dimensional CARS imaging was realized by tomography in the fixed Raman vibration mode for polystyrene samples.
The traditional unsupervised domain adaptive person re-identification algorithm suppressed the noise of pseudo-label poorly and lack inter-domain generalization ability. For the above problems, an unsupervised domain adaptive person re-identification algorithm was proposed which based on soft pseudo-label and multi-scale feature reconstruction. In order to suppress pseudo-label noise, the predicted value of the parallel network is used as the soft tag, and pseudo-label noise is corrected by cross-proofreading methods, which provides a more robust soft false tag for unsupervised domain adaptive tasks. In order to enhance the generalization ability between domains, multi-scale feature reconstruction and Hadamard product feature fusion methods are used to process the deep and shallow feature layer information, realize the style conversion from source domain data to target domain, and solve the problem of poor adaptability of residual network domain with instance normalization and batch normalization network, so as to enhance the generalization ability of the network to source domain and target domain. Experimental results show that the proposed algorithm has achieved good performance in both Market to Duke and Duke to Market unsupervised domain adaptive tasks, which is significantly better than the related algorithms.
For reducing the segmentation error in remote sensing images of vegetation regions and for solving over-segmentation and under-segmentation of targets caused by various factors such as coverage and noise, an adaptive morphology combined with multiscale remote sensing image segmentation method for vegetation regions is proposed. First, general adaptive neighborhood (GAN) is used to construct dilation and corrosion operations, and GAN morphological opening and closing operations are derived. Then, a GAN morphological compound filter is constructed to fill the holes with insufficient vegetation coverage to reduce the interference of noise on the images. Finally, the remote sensing image of the vegetation region is segmented using the multiscale segmentation algorithm. The experimental results show that the proposed method can effectively avoid the phenomenon of under-segmentation and over-segmentation. Moreover, it can effectively segment the remote sensing images of vegetation areas with different coverage. Compared with the traditional multiscale segmentation method and traditional morphological and multiscale combined method, the proposed method has higher segmentation accuracy.
Ascending and descending time series interferometric synthetic aperture radar (InSAR) technology has been used to identify and monitor landslide and deformation of reservoir slopes of a hydropower station on the Jinsha River. It has been found that the landslide areas and deformation trends identified by the approach agree with those of past geological investigation and global position system (GPS) monitoring, which shows that InSAR technology is reliable and useful for landslide monitoring of reservoir slope in mountainous region. Results show that the deformation rate of Xinjian landslide is relatively larger than that of others, with the maximum rate reaching 198.90 mm/a. In the same monitoring period, the root mean square error of the cumulative deformation difference between InSAR and GPS in the line of sight is 39.10 mm, and the maximum difference is 56.65 mm at the XJ17 point. The analysis of the correlation among landslide deformation,daily precipitation and reservoir water level changes shows that the deformation of the Xinjian landslide changes in a periodic step style, which has a lag after heavy rainfall or sudden changes in the reservoir water level. The research can provide a new effective method for landslide monitoring and hazard identification of reservoir slopes in mountainou areas.
Focusing on the problem of poor matching due to nonlinear radiation difference and speckle noise between optical and SAR images, an automatic registration method of coupling phase congruency and mutual information is proposed. First, the stable feature points with uniform distribution are detected from the reference image based on the phase congruency moment feature map. Second, a new similarity measure called maximum index map mutual information is constructed, and it is used to achieve corresponding points by employing a template matching strategy. Finally, the outliers are eliminated by marginalizing sample consensus algorithm and the geometric correction of piecewise linear transformation is used to realize high accuracy registration between images. The proposed method is verified by four sets of medium and high resolution optical and SAR images. The result indicates that the suggested approach has higher registration accuracy than other advanced methods.
A capsule network (CapsNet) is a novel neural network that has been widely used in the classification of hyperspectral remote sensing. However, it is faced with overfitting and gradient vanishing. To solve this problem, this paper proposes a hyperspectral remote sensing classification method using a multi-scale adaptive capsule network (MSCaps). The multi-scale convolution layer was used to extract the spatial and spectral features of the ground object from the input images with different sizes (namely, multi-scale). To solve the overfitting problem caused by the sparseness of the coupling coefficient cij, we applied an adaptive routing algorithm without iteration to further improve the CapsNet structure. To validate the proposed model, we evaluated the classification performances of MSCaps using overall classification accuracy (OA) and model training efficiency on two public hyperspectral remote sensing datasets, namely, the Pavia University (PU) and Salinas-A (SA) datasets. The OA of MSCaps was measured and compared with that of the benchmarks, including support vector machine (SVM), random forest (RF), deep convolutional neural network (CNN), CapsNet, multi-scale capsule network (MCaps), capsule network using adaptive routing algorithm without iteration (ARWI-Caps), and the multi-scale CNN (MSCNN) on original images. Additionally, the OA of MSCaps was compared with that of SVM and RF on images extracted using principal component analysis (PCA). They are named PCA-SVM and PCA-RF, respectively. The training efficiency of MSCaps was compared with that of CNN, CapsNet, and MSCNN. The experimental results show that the OA of CapsNet on the PU and SA datasets is 99.14% and 95.38%, respectively, which is higher than that of the benchmarks. Additionally, the training time of MSCaps is ~1/3 and ~1/4 of that of CapsNet on the PU and SA datasets, respectively. Thus, the training efficiency of MSCaps is significantly higher than that of CapsNet. Therefore, the proposed hyperspectral remote sensing classification method using MSCaps has a good application potential and is an effective alternative for hyperspectral remote sensing classification.
Due to the lack of original spectral information, high-resolution remote sensing images are difficult to effectively distinguish various types of vegetation, and the differences between urban and rural vegetation are often ignored and considering that certain vegetation indices somewhat increase the differences among different vegetation types, this paper proposes a deep learning vegetation classification network based on a vegetation index that combines artificial features and spectral information. Based on a parallel network structure, a dense connection module and atrous spatial pyramid pooling module are introduced to enhance the differences in vegetation feature information and effectively improve classification accuracy. Besides, taking full account of the differences between urban and rural vegetation, this paper verifies and analyzes urban and rural areas, respectively. The overall accuracy of urban vegetation classification and extraction is 96.73%, the F1 score is 80.71%, and the intersection-merge ratio is 69.91%. The overall accuracy in classifying and extracting vegetation in rural areas is 91.35%, the F1 score is 90.28%, and the intersection-merge ratio is 82.41%. Each accuracy index exceeds that of other depth learning methods. The results confirm that this method better distinguishes different vegetation types, is suitable for classifying and extracting vegetation from multi-source remote sensing images, and has a definite value for urban green space planning, rural basic farmland supervision, etc.
Traditional convolutional neural network models fail to fully utilize the rich spatial-spectral information in high-resolution hyperspectral images, and have the problems of high computational cost and low classification accuracy for small sample data. This study proposes a lightweight multiscale pyramid hybrid pooling hybrid convolution model. Based on the hybrid convolution network, the proposed model uses an improved pyramid pooling module to enhance the ability to extract spatial-spectral features, uses fewer convolution layers and depth separable convolution, and uses the global average pooling layer to replace a part of the full connection layer to achieve the transition from the convolution layer to the full connection layer, significantly reducing number of parameters. In this study, the proposed method is tested on three high-resolution hyperspectral datasets and compared with classical hyperspectral image classification methods. The results show that the proposed method can achieve the best classification results under high-resolution conditions, multiple ground object types, and complex boundaries. The overall accuracy of the proposed method on WHU-Hi-LongKou, WHU-Hi-HanChuan, and WHU-Hi-HongHu datasets are 99.12%, 98.43%, and 98.84%, respectively, when only 1%, 2%, and 2% training samples are used, which is superior to that of the traditional convolutional networks. It is proved that the model proposed in this study has a low computational cost, high accuracy for small sample problems, and can be well applied to high-resolution hyperspectral datasets.
In the field of holographic three-dimensional (3D) display, the development of fast algorithms with which to generate computed holograms is an important research task, as the generation of computed holograms is currently time-consuming. The wavefront recording plane (WRP) technique is an effective method to accelerate the generation of holograms based on point clouds. This study analyzes the latest progress in the development and application of the WRP technique for computed holograms. We first introduce the principles of the WRP technique, before going on to analyze the latest research methods for wavefront recording in detail. We summarize and analyze the ways in which these techniques are used to accelerate the generation of the computed hologram and to improve the quality of 3D image reconstruction, and we also review special applications such as surface holographic imaging. We analyze the current utility of the various WRP methods for increasing the speed of computation, improving the quality of image reconstruction, reducing the size of the look-up table in computer memory, increasing the field-of-view angle, and removing aliasing noise. The role of the WRP technique in the creation of real-time, dynamic, high-quality, and large-view holographic 3D displays is also analyzed. Finally, the advantages and disadvantages of various methods are analyzed, and future directions for the development of the WRP technique are proposed.