








Please enter the answer below before you can view the full text.


2025
Volume: 62 Issue 12
46 Article(s)

Huiyan Han, Wanning Li, Jiaqi Wang, Liqun Kuang, and Xie Han
Aiming to solve problems of low-accuracy and slow grasp detection in unstructured environments, a grasp detection algorithm alter-attention pyramid network (APNet) is proposed. Generative residual convolutional neural network (GR-ConvNet) was selected as the backbone network, adaptive kernel convolution was used to replace standard convolution, and the SiLU activation function was replaced with the Hardswish activation function. A lightweight feature extraction network was developed, and efficient multiscale attention was introduced to increase focus on important grasping regions. Pyramid convolution was integrated into the residual network to effectively fuse multiscale features. The experimental results demonstrate that APNet achieves 99.3% and 95.8% detection accuracies on the Cornell and Jacquard datasets, with an average time required for single-object detection of 9 ms and 10 ms, respectively. Compared with existing algorithms, APNet demonstrated improved detection performance. In particular, APNet demonstrates an average success rate of 92% on a homemade multi-target dataset for a grasping experiment implemented in a CoppeliaSim simulation environment.
Jun. 25, 2025Vol. 62 Issue 12 1237001 (2025)
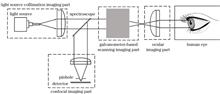
Duo Xu, Fuxin Cai, Tao Peng, Ming Li, Lei Wang, and Xinjian Chen
The confocal fundus camera is a high-frame-rate scanning imaging system used for capturing detailed images of the fundus. However, during image acquisition, its fast-scanning mirror causes misalignment between odd and even scan lines in the reconstructed images. This misalignment happens due to a delay between the mirror's motion signals and the scanning rate signals. To resolve this issue, the study analyzed the relationship between the scanning time and the sampling time of the actual image height scanned by the galvanometer. By using an image similarity function based on normalized squared error, along with the Levenberg-Marquardt nonlinear least squares fitting algorithm, an effective correction of the odd-even row misalignment in the reconstructed image was developed. Additionally, this study introduces a new method for quantitatively assessing the degree of odd-even line misalignment in images. Experimental results demonstrate that the proposed correction algorithm can effectively prevent calibration failures caused by inaccurate feature extraction in traditional methods. This new correction method is versatile, working not only for confocal fundus cameras but also for other high-speed imaging systems. Moreover, the proposed evaluation method can sensitively reflect the degree of odd-even line misalignment in images. Images processed with the algorithm showed a 78.7234% improvement in horizontal resolution and a noticeable enhancement in overall clarity compared to uncorrected images.
Jun. 25, 2025Vol. 62 Issue 12 1237002 (2025)
Xicheng Sun, Fu Lü, and Yongan Feng
To solve the problems of insufficient feature extraction, loss of detail texture information, and large number of model parameters in the current infrared and visible image fusion algorithms, a cross-scale pooling embedding image fusion algorithm with long- and short-distance attention collaboration is proposed. First, the depth separable convolution is used to design channel attention to enhance the expression of key channels and suppress redundant information. Second, based on group shuffle (GS) convolution, a multi-scale dense channel enhancement module is proposed, which enhances the multi-scale information interaction ability and reuses features by superimposing small convolution kernels and introducing dense connections to prevent information loss. Then, on the basis of the cross-scale embedding layer, a cross-scale pooling fusion embedding layer is proposed, and the features of some four stages are extracted using the fusion features of the pooling layer at different scales, so as to make full use of the features of each stage and reduce the computational complexity. Finally, the dual-path design is used to fuse long- and short-distance attention and design a convolutional feedforward network, so as to capture the dependence of long- and short-distance between features and reduce the amount of network parameters. Experimental results on the TNO and Roadscene public datasets of proposed algorithm and other seven algorithms show that, the outline of the fusion results by proposed algorithm is clear, and the entropy, average gradient, and structural content difference of proposed algorithm are improved compared with other algorithms, and the standard deviation of proposed algorithm is better on the Roadscence dataset. In addition, the detection performance comparison experiment of fused images on the M3FD dataset is carried out, and the experimental results show that the proposed algorithm performs well.
Jun. 25, 2025Vol. 62 Issue 12 1237003 (2025)
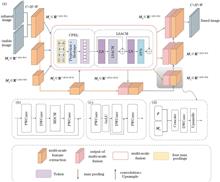
Yunpeng Wang, Jincao Yao, Dong Xu, and Xiang Hao
With the widespread application of deep learning techniques in medical image processing, precise thyroid segmentation is becoming increasingly important for disease diagnosis and treatment. This study proposes a SwinTransCAD model that integrates the Swin Transformer and a multi-scale attention decoding mechanism, effectively capturing the details of the thyroid to achieve precise segmentation. The study first outlines the clinical need for thyroid disease diagnosis and the limitations of traditional segmentation methods. Then the technical features of Swin Transformer and its potential applications in medical image processing are analyzed. Finally, it provides a detailed introduction to the structure of the SwinTransCAD model and the multi-scale attention decoding mechanism. Through comparative experiments, the generalizability of the model across different datasets and its advantages in various evaluation metrics are validated. Experimental results show that the proposed method outperforms existing technologies, providing technical support for the pre-diagnosis and auxiliary treatment of thyroid diseases.
Jun. 25, 2025Vol. 62 Issue 12 1237004 (2025)
Xiaowei Xu, Jianyu Li, Qinghua Qi, and Mingxing Deng
This study develops a model called RA-CRPN for detecting small targets in road vehicle vision. The method addresses the challenges of low detection precision and reliability for small objects detection in road scenes. These objects occupy a small number of pixels and their feature representation information is often insufficient. First, based on the Faster R-CNN framework, the RO-ResNet is integrated into the ResNet50 backbone network, which enabled the output feature blocks to capture contextual information. Second, the RA-ResNet module is added after the backbone network to provide new feature information for each ResNet stage by fusing context information with object features. Then, the improved coarse-to-fine RPN (CRPN) module is utilized to enhance feature alignment and proposal box correction during the two-stage transition, providing high-quality feature information for the region proposal network (RPN) stage. Finally, the SODA-D public small object dataset is employed to validate and analyze the model by comparing it with other methods. The overall average precision (AP), average precision of extremely small (APes) and average precision of relative small (APrs) of the proposed method are 3.9, 2.4, and 3.4 percentage points , respectively, better than the Faster R-CNN baseline model, indicating improved overall detection precision. Additionally, road object detection tests are conducted using a custom vehicle driving dataset. The results show that the mAP@50 (mean average precision at 50% intersection over union) of the model is 5.8 percentage points higher than that of the Faster R-CNN baseline model, further verifying the precision and robustness of the proposed model.
Jun. 25, 2025Vol. 62 Issue 12 1237005 (2025)
Yihui Zhu, Xiaoya Guo, Zhengmeng Jin, and Qinxia Wang
To recover more valuable image details such as texture and brightness in low-contrast images, a new color image enhancement model is proposed based on the saturation-value total variation histogram equalization (SV-TV-HE) algorithm and combined with saturation-value total generalized variation (SV-TGV) and adaptive brightness function. A numerical algorithm is further designed for the proposed model using the alternating direction multipliers method to improve local brightness and contrast and maintain local details. Image enhancement experiments have been carried out for synthetic and real images. Experimental results show that the proposed model can effectively avoid the staircase effect in the process of image restoration, thereby achieving better image enhancement effect than existing methods in restoring image contrast, brightness, and other details.
Jun. 25, 2025Vol. 62 Issue 12 1237006 (2025)
Guangye Wu, Fang Liu, Honggang Qu, Lingyu Lei, and Qian Ren
In nighttime-driving scenes, the image quality deteriorates significantly owing to insufficient light and haze, which poses severe challenges to the driver and automatic drive system. Hence, a novel image-dehazing algorithm for nighttime-driving scenes is proposed. Instead of relying on the classical a priori theory, the algorithm considers the nighttime haze image as a superposition of haze and background layers from the reconstruction perspective, and a lightweight super-resolution reconstruction dehazing network is proposed without using a physical imaging model. By introducing a haze feature-extraction network based on dilated convolution and an attention-mechanism module that uses the haze feature graph as supervisory information, the dehazing network efficiently removes the haze layer while preserving the image details and generating clear and high-contrast images. Comparison experiments with five state-of-the-art dehazing methods are conducted on two nighttime fog map datasets. The experiments show that the super-resolution reconstruction dehazing network performs better than all other nighttime dehazing models. The results of ablation experiments show that the attention module based on the supervision of haze features significantly improves the dehazing capability of the network. This study provides new ideas and methods for solving the image-quality problem in nighttime-driving scenarios, thus facilitating improvements to the driving safety and reliability of automatic driving systems.
Jun. 25, 2025Vol. 62 Issue 12 1237007 (2025)
Xianglong Luo, Wenxin Lü, Zhenyue Shi, and Ruochen Liu
To address the problems of detection accuracy degradation in small traffic sign targets and excessive model complexity in complex scenes, this study proposes a lightweight traffic sign detection method using an improved YOLOv8n. An omni-dimensional dynamic convolution and efficient multi-scale attention (EMA) mechanism are introduced into the backbone network of YOLOv8n to accurately acquire sign features and context information. A small target detection layer of 160 pixel×160 pixel is added to effectively combine features with different scales, preserve more detailed information, and improve the precision of small target detection. GhostBottleneckv2 is introduced for lightweight processing, and the GSConv module is designed to reduce model complexity and accelerate convergence speed. The WIoU v3 loss function is used to enhance the ability of the model to locate the targets. The experimental results show that the proposed algorithm improves the mean average precision by 7.6 percentage points and 2.4 percentage points and decreases the parameter number by 7.6% and 7.9% on the TT100K and CCTSDB2021 datasets, respectively. Hence, the proposed algorithm not only maintains the lightness characteristics of the YOLOv8n model, but also exhibits better detection performance.
Jun. 25, 2025Vol. 62 Issue 12 1237008 (2025)
Zhaojin Wu, Jun Wang, and Zhaoliang Cao
The accurate identification and localization of tilted droplets is a key preprocessing link for achieving a high-precision measurement of the dynamic contact angle. For the problems of low detection accuracy of traditional algorithms and excessive hardware occupancy of deep learning-based target detection algorithms, this paper proposes Light-YOLOv8OBB, a lightweight tilted droplet detection and localization model based on the improved YOLOv8 algorithm. First, this paper designs a C2f-light convolutional structure to lighten and improve the backbone network. Second, the Slim-Neck design paradigm is introduced into the neck network to further lighten the network model. The convolutional attention mechanism module is added to strengthen the model's ability to detect small target objects. Experiments on a homemade droplet dataset and analysis of the results reveal that our algorithm can balance model performance and detection efficiency well. The mean average precision (mAP@0.5:0.95) value of proposed algorithm reaches 76.7%, an improvement of 7.5 percentage points compared with the base model, whereas the number of parameters and computation decrease by 38.7% and 34.9%, respectively, compared with the base model, and the inference time is only 16.1 ms on NVIDIA GeForce MX250.
Jun. 25, 2025Vol. 62 Issue 12 1237009 (2025)
Xiaodi Zhang, and Shijie Jia
To address the issues of inferior image quality, uneven lighting, and blurred details in low-light environments that result in low detection accuracy, this study proposes a night-time detection model named LowLight-YOLOv8n, which is an improved version of YOLOv8n. First, a low-light image enhancement network named Retinexformer is introduced before convolutional feature extraction in the Backbone network, thus improving the visibility and contrast of low-light images. Second, conventional convolution operations are replaced with RFCAConv in both Backbone and Neck networks, where convolution kernel weights are adjusted adaptively to solve the issue of shared parameters in conventional convolutions, thus further enhancing the model's feature extraction and downsampling capabilities. Subsequently, a new C2f~~UniRepLKNetBlock structure is formed by combining the large convolution kernel architecture of UniRepLKNet with the C2f module of the Neck network, thereby achieving a larger receptive field that encompasses more areas of the image with fewer convolution operations, thus allowing a broader range of contextual information to be aggregated, and more potential target information to be captured in low-light images. Finally, a new bounding-box regression loss function named Focaler-CIoU is adopted, which focuses on the detection of difficult samples. Experimental results on the ExDark dataset show that, compared with the baseline model YOLOv8n, LowLight-YOLOv8n improves the mAP@0.5 and mAP@0.5∶0.95 metrics by 6.8% and 5.8%, respectively, and reduces the number of parameters by 0.09×106.
Jun. 25, 2025Vol. 62 Issue 12 1237010 (2025)
Bohao Gao, Hao Li, and Peng Zhu
During the photovoltaic inspection of drones, it is necessary to obtain the position information of the photovoltaic panels in the image to determine the fault location of photovoltaic modules. The accuracy of the position and orientation system (POS) data transmitted by small drones is low because of their technical limitations, making it difficult to use them for photovoltaic panel positioning in small drone images. This paper proposes an automatic positioning method for photovoltaic panels in drone images to address this issue. Based on the drone images and the geographical coordinates of the photovoltaic panels within the inspection area, the actual location of the photovoltaic panels within the image is determined, providing accurate location information for troubleshooting. First, the proposed method establishes a coordinate transformation model and its unknown parameters based on the projection relationship between the object and image. It determines the parameter range based on the shooting conditions, selects multiple sets of parameters to determine the geographical coordinates of the photovoltaic panels within the image, and compares these with the mean square error of the back-projection difference of the photovoltaic panels within the area as a loss value. Next, it optimizes the parameters by comparing multiple sets of loss values and verifies them using overlapping images. Finally, based on the optimal parameters, coordinate conversion is performed to achieve automatic positioning of the photovoltaic panel image. In two experiments using more than 14,000 fault boards, the positioning accuracy of the proposed method reaches 97.78% and 98.54%, which increases by 13.06 percentage points and 12.96 percentage points, respectively, compared to the positioning method based on POS data. It also overcomes the influence of changes in the shooting conditions, thereby verifying the accuracy and robustness of the proposed method.
Jun. 25, 2025Vol. 62 Issue 12 1237011 (2025)
Jiale Chen, Xiaobin Li, and Haiyan Sun
To address the inefficiency of manual color difference classification, this study proposes a multi-strategy improved black-winged kite optimized extreme learning machine (MBKA-ELM) model for dyeing fabric color difference classification. First, as the random initialization of hidden layer weights and biases in extreme learning machine (ELM) algorithms can lead to uneven model training and algorithm instability, the black?‐?winged kite (BKA) optimization algorithm is employed to optimize these key parameters. Second, the incorporation of mirror reverse learning, BKA circumnavigation foraging, and longitudinal and transverse crossover strategies enhances both the convergence speed and global optimization ability of the algorithm. Finally, the MBKA-ELM model is constructed for dyeing fabric color difference classification, achieving an accuracy rate of 98.8% and confirming the feasibility of using this model compared to conventional color difference calculation formulas for detection. Comparative experiments demonstrate the stabilization of the MBKA-ELM model after 10 iterations with a higher classification accuracy than comparable models. Compared with the traditional ELM and optimized models—black-winged kite optimized ELM, spotted emerald optimized ELM, Guanhao pig optimized ELM, cougar optimized ELM, and snake optimized ELM—the classification accuracy improves by 13%, 3.4%, 1.4%, 5%, 4.2%, and 3%, respectively. The proposed model demonstrates superior convergence speed and classification accuracy.
Jun. 25, 2025Vol. 62 Issue 12 1237012 (2025)
Zixuan Li, Yunlan Guan, Zhongjun Yang, and Sheng Zeng
Solidago canadensis L. is a priority invasive species under strict management in China. Effective detection, identification, and localization are essential for its control. To rapidly and accurately identify Solidago canadensis L. in complex natural environments, a lightweight detection model, YOLOv8-SGND, is proposed as an improvement over the YOLOv8 model to address issues of large parameter size and high computational complexity. Based on the YOLOv8 model's head, the new model designs a lightweight network structure and introduces a shared group normalization detection (SGND) head to enhance both localization and classification performance while significantly reducing the parameter count. First, batch normalization is replaced with group normalization in the convolutional blocks. Second, convolution parameters are shared between two convolutional blocks after feature aggregation to reduce the parameter volume and computational complexity. To improve the model's robustness and optimize the balance of errors in the bounding-box coordinates, the original complete intersection over union (CIoU) is replaced by wise IoU (WIoU) v3 as the bounding-box loss function. Finally, while using shared convolution, the Scale layer is applied to adjust the bounding-box predictions, thus ensuring consistency with the input image dimensions and feature-map sizes across different detection layers. Detection experiments on real-world data show that the proposed YOLOv8-SGND model achieves mAP@0.50 and mAP@0.50∶0.95 of 98.8% and 79.6% (mAP is mean average precision), respectively, which represent improvements of 2.8 and 6.0 percentage points over the original YOLOv8 model, respectively. Additionally, the model parameters and floating-point operations are reduced by approximately 21.4% and 1.6 Gbit, respectively. Compared with mainstream object-detection algorithms such as YOLOX, Faster R-CNN, Cascade R-CNN, TOOD, and RTMDet, YOLOv8-SGND outperforms them in all precision evaluation metrics. The proposed method offers high detection accuracy and inference speed, thus can provide technical support for the lightweight and intelligent recognition of invasive species.
Jun. 25, 2025Vol. 62 Issue 12 1237013 (2025)
Shanshan Chen, Qiwen Jin, Zhiming Lin, and Xuecheng Wu
Considering the extensive application potential of digital holography in three-dimensional particle field measurement, this study designs and implements a particle holographic image reconstruction algorithm based on a field-programmable gate array (FPGA). A novel design architecture and implementation scheme are proposed to address challenges encountered in scenarios requiring high real-time performance, large and variable hologram sizes, and multiple reconstructed cross sections under limited hardware resources. The overall architecture exhibits independence in three dimensions, maintaining a hierarchical and structured approach. The specific design incorporates strategies to mitigate fixed-point overflow and accuracy loss, real-time generation of phase shift functions without delay, and optimized data loading and storage solutions, thereby effectively resolving the aforementioned challenges. Experimental results demonstrate that the structural similarity between the FPGA-based particle holographic reconstruction results and the reference values reaches 99.8%, confirming high accuracy. For hologram sizes of 256×256, 512×512, 1024×1024, and 2048×2048, the reconstruction time is reduced by up to 47.6%, 49.3%, 20.9%, and 84.6%, respectively, compared to existing studies. Furthermore, the computational performance is significantly improved.
Jun. 25, 2025Vol. 62 Issue 12 1209001 (2025)
High-Resolution Reconstruction for Off-Axis Digital Holography Based on Fusion of Derivative Spectra
Mingguang Shan, Qiqiang Jin, Na Meng, Jianxin Yin, Zhi Zhong, Lijing Wang, and Lei Liu
This study proposes a high-resolution reconstruction algorithm for off-axis digital holography based on Kronecker convolution-derived spectrum fusion to address the issue of severe interference from zero-order spectra during phase recovery. In this process, first, Kronecker convolution was performed on the off-axis digital hologram and a 2×2 constant matrix. Thereafter, two-dimensional Fourier transform was applied to the convolved hologram, producing a spectrogram containing the original and derived spectra. Depending on the interference level of the zero-order spectrum, bandpass filters of varying sizes were employed to select multilevel-derived spectra, followed by numerical reconstruction. Finally, image fusion technology was used to combine the multiple reconstruction results to produce high-resolution images. Compared with existing off-axis digital holographic reconstruction algorithms, the proposed algorithm reduces interference caused by zero-order spectra. It achieves this without increasing the complexity of off-axis digital holographic structures. This facilitates the retrieval of more object information and allows for high-resolution phase reconstruction. Experimental results show that the proposed algorithm simplifies calculations, significantly diminishes the influence of zero-order spectra on effective spectral information, and achieves high-resolution reconstruction in off-axis digital holography.
Jun. 25, 2025Vol. 62 Issue 12 1209002 (2025)
Changxiang Zhong, Yeyao Chen, Zhongjie Zhu, Mei Yu, and Gangyi Jiang
Owing to the limitation of the optical structure, images captured by light field cameras suffer from the problem of narrow field of view (FOV). This study proposes an unsupervised large FOV light field content generation method based on depth perception to address this problem. First, the proposed method adopts a light field sub-aperture array center warping approach, which is combined with a convolutional neural network to estimate the depth information of the light field image. The light field sub-aperture images are aligned to the center using the depth information, thereby enhancing the correlation among sub-aperture images and effectively reducing angular redundancy. Second, a homography estimation network is developed to extract multi-scale feature pyramids. Deep features are used to predict global homography, and shallow features are used to perform grid-level adjustments to refine image registration. Additionally, a depth-aware loss function is designed to assist the estimation of the homography matrix. Finally, a synthetic mask is leveraged to guide the registered views to achieve natural fusion, and the previously estimated depth information is then used for angular restoration to generate the final large-FOV light field image. Experimental results show that the proposed method achieves high-precision registration while ensuring the angular consistency of the stitched light field image. Moreover, the performance of the proposed method is satisfactory in both subjective and objective indicators on the self-built dataset.
Jun. 25, 2025Vol. 62 Issue 12 1211001 (2025)
Online Detection Method for Cross-Section Size of Irregular Crystal Rod Grown via Czochralski Method
Yang Du, Songhang Chen, Senlin Wang, and Hao Chen
In producing crystals via the Czochralski method, achieving equal-diameter growth is essential for ensuring crystal quality. To address the issues of subjectivity and precision limitations associated with manual visual estimation, an online method for detecting the cross-section size of irregular crystal rod grown via the Czochralski method is proposed. First, the crystal growth monitoring video data collected in real time are converted into a continuous sequence of images and preprocessed for denoising and contrast improvement. Subsequently, using weighted pixel values and gradients to determine the crystal rod edges, the similarity of the radius sequence recorded in different directional rays is used as the fitness of the undetermined center, combined with the gray wolf optimization algorithm to search for the cross-sectional center. Finally, the shape of the cross-section is plotted, and the pixel size is converted to physical size combined with camera calibration to estimate the crystal cross-section size. Experiments using Nd∶YVO4 crystal indicate average errors of 0.30 and 0.10 mm for the major and minor axes, respectively, and an average detection time of 1.07 s, which can facilitate or replace the time-consuming and labor-intensive manual monitoring of crystal growth.
Jun. 25, 2025Vol. 62 Issue 12 1212001 (2025)
Hybrid Algorithm for Particle Image Velocimetry Based on Cross-Correlation with Optical Flow Pyramid
Xiuxia Liang, Chong Liu, Yueyang He, Shuai Wang, and Tao Liang
We propose a hybrid algorithm that combines cross-correlation with optical flow pyramid to address the lack of accuracy and insufficient adaptability in particle image velocimetry (PIV) hybrid algorithms. The traditional cross-correlation response is optimized to enhance the signal strength, while the optical flow pyramid structure, integrated with image warping operations, improves the initial flow estimation accuracy. The combination of these two methods greatly enhances the overall performance of the hybrid algorithm in complex flow fields. A simulation experiment is conducted to reconstruct the direct numerical simulation turbulent velocity fields, revealing that the root mean square error (RMSE) and average angle error (AAE) of the proposed hybrid algorithm are reduced by at least 33.68% and 47.22%, respectively, compared to traditional algorithms. Furthermore, compared to previous hybrid algorithm Hybrid-Liu, the RMSE and AAE are reduced by 24.93% and 33.99%, respectively, while the efficiency is improved by 20.10%. Additionally, a simulated analysis of a double-vortex structure is performed to assess the impact of different particle sizes and displacement conditions on the accuracy and adaptability to fluid scenarios of the proposed algorithm. Furthermore, the experimental measurements are used to analyze real flow fields, demonstrating that the proposed hybrid algorithm can produce velocity field results that are consistent with those obtained using common algorithms, while improving the extraction of vortex structures.
Jun. 25, 2025Vol. 62 Issue 12 1212002 (2025)
Yujie Zhao, Yiran Shi, Xuanming Liang, Deshun Li, Yongqiang Chen, Yu Fang, Xingzhi Wu, Quanying Wu, and Yinglin Song
This study proposes modification to f-scan using a liquid-crystal spatial light modulator (SLM). By programmatically controlling the phase of the incident light beam, continuous variation of the focal point along an arbitrary direction is realized, and thus achieve f-scan. A subfocus phenomenon occurs because of the discontinuous phase-modulation depth in the liquid-crystal SLM. Therefore, the intensity of the incident light is corrected based on theoretical analysis. Subsequently, experimental validation is performed using ZnSe materials. Theoretical and experimental studies suggest that the arrangement of this method is simple, and that no beam-collimation issue is caused by sample movement, unlike the Z-scan technique. Furthermore, this method overcomes the stringent precision requirements of coaxial optical systems and mitigates the constraints associated with minimal variations in the focal length of the f-scan technique. Consequently, this approach simplifies the experiment while enabling effective measurements of third-order optical nonlinearity in materials.
Jun. 25, 2025Vol. 62 Issue 12 1212003 (2025)
Feikuai Fang, Changwei Li, and Min Lai
A high-precision phase recovery technique suitable for Shack-Hartmann wavefront sensors is proposed to tackle the issue of slow convergence in phase recovery. This technique leverages the wavefront reconstruction algorithm of the Shack-Hartmann wavefront sensor. First, the distorted wavefront is reconstructed, and the reconstructed wavefront is then used as the starting point for the improved adaptive stochastic parallel gradient descent (ASPGD) algorithm. This iterative optimization process achieves high-precision phase recovery. By combining the modal method with the ASPGD optimization algorithm, this technique significantly enhances the accuracy of phase recovery and accelerates its convergence speed. The numerical simulation results demonstrate that this technology improves the phase recovery accuracy by three times, achieving a precision of 2‰λ. Compared with the original stochastic parallel gradient descent algorithm, the proposed ASPGD algorithm exhibits lower sensitivity to random perturbation coefficients, a larger dynamic range, and greater practicality. In addition, when addressing noise-induced modal coupling issues, the ASPGD algorithm exhibits superior noise resistance and higher phase recovery accuracy.
Jun. 25, 2025Vol. 62 Issue 12 1212004 (2025)
Xuancai Lu, and Jinsong Wang
In an automatic lensometer based on Hartmann's method, the spot position received by the photoelectric detector is key for measuring diopter. Inaccurate extraction of the spot center can lead to large errors in diopter measurement. This study analyzes the impact of spot offset on diopter error and examines the correlation between spot offset and diopter error, to propose a random circle detection and fitness evaluation method for spot localization based on random sample consensus (RANSAC). First, the spot is preprocessed, including bicubic interpolation, binarization, and Canny edge detection, which improves the accuracy and completeness of the integrity of edge information. Then, using the radial scanning method, starting from the center of the rough localization circle of the spot, edge points are uniformly collected, and three points are randomly selected to generate candidate circles. The circle with the highest fitness is output as the center of the spot. Compared with four traditional methods such as the least squares circle detection method, the proposed method can quickly and accurately locate the center of the spot, with a measurement accuracy of 0.242 pixel, which can effectively improve the accuracy of the refraction measurement by the automatic lensometer.
Jun. 25, 2025Vol. 62 Issue 12 1212005 (2025)
Dongdong Wei, Yang Li, and Chengzong Yuan
Surface-mount technology (SMT) production lines involve a broad range of mounted components and exhibit inconsistent charging tray specifications. To address issues such as error-prone chip positioning and orientation, as well as difficulty in recognizing chip characters during production, this study designs and implements a component detection system for SMT production lines based on improved YOLOv5s. A high-precision line-scan camera is used to rapidly capture images of the charging trays on the production line, and improving the YOLOv5s object detection algorithm through enhancements such as adding an attention mechanism and a P2 small object detection layer, the system achieves improved position and orientation detection, as well as improved information recognition, for all chips in the images of the charging trays with varying specifications. Practical testing verifies that the system enables accurate component detection under various working conditions, significantly enhancing the quality and efficiency of component inspection in SMT production lines.
Jun. 25, 2025Vol. 62 Issue 12 1212006 (2025)
Jiaming Zhang, Yuhui Peng, Gan Zhang, Baozhe Sun, and Shenyang Lin
To improve the efficiency and accuracy of attention mask prediction for panoptic segmentation on point clouds, an end-to-end point cloud panoptic segmentation network model guided by multi-modal bird's eye view (BEV) features is proposed. First, object queries are generated from BEV features decoded by the Transformer, and feature enhancement is achieved through confidence ranking and positional encoding embedding. Second, a cross-attention mechanism module is constructed to fuse object queries with learnable query features and the query features of fused object instance information are used to improve the accuracy of attention mask prediction. Finally, the dimensionality of the input features to the masked attention mechanism network is reduced to enhance detection speed. Experimental results based on the nuScenes dataset indicate that, compared with the baseline method, BEVGuide-PS improves panoptic segmentation metrics PQ, PQ?, RQ, and SQ by 17.7%, 17.0%, 18.3%, and 20.9%, respectively, reduces inference time by 58.4%, and significantly enhances training efficiency.
Jun. 25, 2025Vol. 62 Issue 12 1215001 (2025)
Bo Yang, Mingfeng Li, Ding Tan, and Guangyun Zhang
The accuracy of point cloud registration (PCR) algorithm based on feature matching is often affected by noise and repeated local structures in point clouds. In this paper,an L1,P sparse constraint model-based point cloud registration algorithm is proposed to address these issues. First, geometric or learned point cloud feature descriptors are extracted to construct compatibility graphs using topological relationships, and the spectral matching method is employed to select seed points with higher confidence scores. Second, the discrete constraint of graph matching is relaxed into L1,P sparse constraints to obtain optimal matching results for the fully connected attribute-weighted graph model constructed from the seed points. Finally, a PCR method based on maximal clique hypothesis testing is realized by searching for maximal cliques within the matching results and scoring them, and then selecting the highest-scoring transformation pose as the precise registration pose. Experimental results demonstrate that the proposed algorithm achieves a maximum accuracy improvement of 72.12% and 75.86% on indoor and outdoor point cloud datasets, respectively, compared to typical registration algorithms. In addition, under different parameters settings and Gaussian noise interference, the proposed algorithm demonstrates superior registration accuracy and robustness compared to other registration algorithms.
Jun. 25, 2025Vol. 62 Issue 12 1215002 (2025)
Jian Zuo, Ran Liu, Lin Guo, Heng Ning, Feng Xu, and Yufeng Xiao
Traditional laser-based localization methods face target identification strangeness due to the lack of semantic information from LiDAR. To address this issue, this paper proposes a target localization method that integrates ultra-wideband (UWB) ranging with laser scanning information. First, the collected laser data is clustered, and the minimum Euclidean distance between clusters at adjacent time steps is used as the association criterion. The nearest neighbor data association algorithm is then employed to construct laser cluster trajectories, which are further matched with UWB ranging sequences to achieve motion target identification and tracking. Then, depending on whether the target is within the robot's field of view, the particle weights are updated during the particle filter update stage using either the similarity matching results or the UWB ranging, leading to the estimation of the target's position. The feasibility of the algorithm is validated in a 12 m×12 m indoor environment, showing that the proposed method can achieve a localization accuracy of 0.16 m while meeting real-time requirement.
Jun. 25, 2025Vol. 62 Issue 12 1215003 (2025)
Zhengpeng Zhang, Jianhua Liu, Xinyu Xie, Lijing Bu, and Yan Cheng
The current registration method based on point features is susceptible to the quality of point clouds, involving large amounts of computation and having low efficiency. Meanwhile, the line feature methods have a single feature description and are limited to two-dimensional transformations, making it difficult to adapt to complex three-dimensional scenarios. This study proposes a point cloud registration method based on 3D linear multi-feature description and matching. Firstly, it uses the multi-scale curvature feature to extract key points of the point cloud and adopts a two-stage fitting method to obtain the key point lines. Then, it performs multi-feature expression based on angle and distance for the fitted lines, constructing a multi-feature descriptor and matching similar lines. Finally, the gradient descent method integrated with the random sample consensus (RANSAC) idea is used to calculate the optimal spatial transformation parameters between matching lines and the spatial transformation is carried out to complete the registration. Using the Stanford 3D point cloud database as experimental data and comparing the proposed method with existing registration methods, the results show that the registration accuracy of the proposed method can reach up to 10-8 m. In addition, the registration efficiency and registration effect of this method in extreme positions are significantly better than those of other comparison methods.
Jun. 25, 2025Vol. 62 Issue 12 1215004 (2025)
Daixian Zhu, Jiaxin Wei, and Shulin Liu
To address the challenges of poor robustness and a high rate of mismatches of the ORB algorithm in complex lighting environments, we propose an adaptive ORB feature matching algorithm. The algorithm enhances the selection probability of feature points using an adaptive threshold approach that filters pixels iteratively. In addition, a quadtree uniform distribution of feature points is applied to increase the number of feature points in low-light or high-exposure regions. The MAGSAC++ algorithm is subsequently employed to eliminate erroneous matches, and a novel stopping criterion is introduced to reduce data resampling, which improves both the efficiency and accuracy of feature matching. Experimental results demonstrate that for datasets with significant lighting variations, the proposed algorithm substantially increases the number of extracted features, reduces feature matching time by 61.9% and enhances the matching rate by 35 percentage points compared to traditional ORB. It can efficiently complete feature matching under complex scene variations. Finally, localization experiments were conducted by the proposed algorithm. The results reveal that the proposed algorithm achieves higher localization accuracy compared to other advanced visual SLAM (simultaneous localization and mapping) algorithms and it has certain application value.
Jun. 25, 2025Vol. 62 Issue 12 1215005 (2025)
Shuai Zhang, and Meiju Liu
Feature-embedding-based memory bank methods have proven effective in the task of image anomaly detection. However, they face challenges due to domain bias from pre-trained networks, insufficient representativeness of the memory bank, and feature space bias, which ultimately degrade detection performance. To address these issues, this study proposes a bias-reduced coupled-hypersphere model for image anomaly detection. First, an anomaly generation method to create a self-supervised learning task for model fine-tuning is proposed, which mitigates domain bias. Second, core-set sampling is employed to establish a more representative memory bank of normal features. Then, coupled hyperspheres are identified within the memory bank to differentiate between normal and abnormal features through model training. During the inference stage, local density K-nearest neighbor (KNN) is applied to minimize the effects of feature space bias in the memory bank. Experimental results on the public MVTec AD industrial dataset show that the proposed method achieves image- and pixel-level area under the receiver operating characteristic curve (AUROC) scores of 99.5% and 98.4%, respectively, outperforming most existing approaches.
Jun. 25, 2025Vol. 62 Issue 12 1215006 (2025)
Qi Sun, Lintao Huo, Haifei Xia, Yutu Yang, Bin Wu, Sheng Xu, and Ying Liu
The surface flatness inspection of rail vehicles is key to improving the level of painting engineering and is directly related to aesthetics, anticorrosion, and traffic safety. An adaptive flatness inspection algorithm based on point cloud data is proposed to solve the problems of low accuracy and poor efficiency in detecting the flatness of sidewall panels of rail vehicles. The data to run the algorithm originates from an in-house-designed front-end data-scanning device, which is used to three-dimensionally scan the surfaces of the sidewall panels by sliding multiple laser scanners to obtain point cloud data. Subsequently, an improved guided-filtering algorithm is used to calculate the spatial geometric feature weights of the point cloud by integrating the distance, curvature, and normal vector to smoothen the single-frame point cloud, thus improving the point cloud quality. Next, on the basis of the contour-matching algorithm, the Hough straight-line detection algorithm is improved to segment the contour region of the point cloud, thus realizing the adaptive effect. Finally, the defective areas on the surfaces of the sidewall panels are extracted and localized, and quantification is performed. The results show that the algorithm can identify all the defective regions and ensure that the measurement depth error is within 0.3 mm, the measurement length and width error are within 1 mm, and operation speed satisfies the requirements of real-time detection of 30 mm/s.
Jun. 25, 2025Vol. 62 Issue 12 1215007 (2025)
Tieqiang Sun, Hongjian Yu, Can Zhang, Yidong Yuan, and Aoran Sun
The complete outline of printed circuit board (PCB) defects is difficult to define and is easily affected by the background of the board, resulting in difficulty in separating the shape and size of image defects. Therefore, this study proposes a method based on improved MobileSAMv2 to efficiently extract the defect morphology in defective boards. First, the YOLO object detection technology is introduced to provide accurate mask information of the model, solve the ambiguity problem, and then optimize the segmentation performance. Second, feature fusion technology is used to construct a feature converter network Vision Transformer (ViT) called ICT-ViT, which fuses the inputs of local convolutional neural network and global ViT and adapts to the characteristics of hardware acceleration by sacrificing part of the parameters in exchange for the improvement of overall performance. Finally, the decoding speed and accuracy are further improved by fine-tuning the parameters of the mask decoder. The experimental results show that the accuracy of the model decreases obviously when the tuning interval exceeds 40%. On the PKU-Market-PCB dataset, the optimized model achieves millisecond-level inference speed while maintaining an mean intersection over union of 0.976 and average recall score (mScore) of 0.889. In addition, it shows good performance in small-target defect contour segmentation, which not only meets the need for high efficiency, but also ensures the accuracy of the processing results.
Jun. 25, 2025Vol. 62 Issue 12 1215008 (2025)
Yue Ji, Hai Zhang, Jinyi Li, Limei Song, and Jiuzhi Dong
Fiber tension is a key constraint that affects carbon fiber product quality, and the accuracy of carbon fiber tow microtension measurement by machine vision inspection methods is limited due to model measurement limits. In this study, based on the existing machine vision tension measurement model, a method for the classification and detection of carbon fiber tow microtension through machine vision by introducing a neural network is proposed, whereby the ResNet18 model is improved according to fiber image features. The fiber image is classified into vibration and sag images. By combining the image classification results with image processing algorithms, the lower limit of the measurement of the lateral vibration model is obtained. The sagging string model is further introduced to estimate the fiber microtension of the fiber tow. The experimental results on the dataset show that compared with the support vector machine (SVM), traditional convolutional neural network (CNN), and ResNet18 model, the proposed method improves accuracy by 14.2, 9.2, and 10.5 percentage points, respectively, and the image recognition time is 3.5 ms. The method of determining segmented fiber tension using image classification extends the measurement lower limit of a single transverse vibration model. It reduces the relative error between the machine vision and tension sensor measurements to ±10% within the microtension interval of 1.5?3.0 cN, with a goodness-of-fit of 0.964 between the sag height of the carbon fiber tow and the actual tension. This method effectively improves the detection accuracy of microtension in carbon fiber tows.
Jun. 25, 2025Vol. 62 Issue 12 1215009 (2025)
Taizhe Tan, Mengrou Li, Zhuo Yang, and Zhiyuan Gong
Existing cross-modal pedestrian re-identification methods disregard noise interference and valuable information for pedestrian identification in modal specific features. Hence, a cross-modal pedestrian re-identification network combining frequency-domain attention and modal co-feature optimization is proposed to effectively suppress noise interference in different modal spaces and deeply mine and utilize the implicit identity-discrimination informations in modal specific features. First, a two-stream network integrated with a frequency-domain attention mechanism is used to effectively filter noise and extract modal shared and specific features. Second, the extracted modal specific features are purified and restored to reduce modal-style differences, while identity-discrimination informations are extracted and strengthened independent of modalities. Thereafter, this implicit discrimination informations are used to guide modal shared features to enhance the model's recognizability. Finally, variance aggregation loss is introduced to minimize the modal differences among the enhanced modal shared features. Based on extensive experimental results, the proposed method demonstrates significant performance improvement on three public datasets. In particular, its Rank-1 accuracy and mean average precision are 82.14% and 81.59%, respectively, in the all-search mode on the SYSU-MM01 dataset.
Jun. 25, 2025Vol. 62 Issue 12 1215010 (2025)
Hanwen Zhang, and Yanyang Wang
A camera-radar odometry fusion localization algorithm based on self-supervised learning is proposed to address the limitations of radar positioning accuracy and the degraded performance of visual odometry in rainy weather. This algorithm leverages the rich information from camera data while benefiting from resilience of a radar to adverse weather conditions. First, a dilated convolutional network is incorporated into deep learning-based visual odometry to enhance the local features of the image. A self-attention mechanism is then employed to extract global contextual information from the image to improve depth prediction performance. Second, for radar odometry data, view reconstruction technology is used as a self-supervised signal to train the network for artifact removal, thereby ensuring the authenticity of radar data. To address discrepancies in sampling frequencies and timestamp misalignment between camera and radar data, time soft alignment is performed by matching the timestamps of adjacent radar point cloud maps with the closest camera image pair. To achieve precise alignment between visual and radar odometry, a Smooth L1 loss function is designed to constrain their pose estimations, thereby ensuring effective fusion of visual and radar data. Experiments conducted on the Oxford Radar RobotCar dataset demonstrate that, compared with the baseline algorithm, the proposed algorithm considerably improves pose estimation accuracy in daytime and rainy conditions and validates its effectiveness.
Jun. 25, 2025Vol. 62 Issue 12 1215011 (2025)
Yaochang Tan, Junwei Yang, Kunyang Li, and Lixin Tang
To overcome the issues of high memory consumption, long computation time, and limited accuracy in point cloud registration algorithms for graph space maximal clique (MAC) analysis, a registration algorithm based on angle constraints and MACs is proposed. First, existing algorithms are used to obtain initial matching point pairs from the point cloud, and a first-order spatial compatibility graph is constructed using distance constraints between points. Thereafter, a second-order spatial compatibility graph is constructed under the constraint of three-point spatial angles. Next, MACs are searched for in the second-order graph and sorted and filtered using a priority queue. Finally, weighted singular value decomposition is used to calculate and evaluate the optimal rotation-translation transformation for the largest cliques in the priority queue. The proposed algorithm effectively eliminates incorrect matching point pairs by introducing spatial three-point angle constraints and a MAC priority queue, thereby reducing computation time, optimizing memory consumption, and improving registration accuracy. The registration experiments conducted on the KITTI, 3DMatch, and 3DLoMatch open-source datasets demonstrate that the proposed algorithm achieves excellent registration accuracy compared with other typical point-based registration algorithms. Moreover, the proposed algorithm outperforms the MAC algorithm based on graph space analysis with respect to registration time and memory consumption. In addition, the effectiveness of spatial three-point angle constraints for improving registration accuracy and reducing map size is further verified through ablation experiments.
Jun. 25, 2025Vol. 62 Issue 12 1215012 (2025)
Sidong Cui, Lei Zhang, Haifeng Zhang, Fengying Yue, Zhichao Yue, Yue Wang, and Wenhao Li
This study addresses the challenges of stereo matching algorithms in planetary surface environments, characterized by unstable lighting conditions, high noise interference, and limited ground scene diversity. Traditional algorithms often perform poorly in regions with weak texture and parallax discontinuity. To overcome these limitations, this study introduces a noise-resistant stereo matching algorithm featuring an improved adaptive weighting AD-Census transform. The algorithm implements a Gaussian-weighted circular matching template within the Census transform to establish distance relationships between neighborhood pixels and the center pixel, fusing this with Canny gradient information to generate an improved Census cost. The algorithm combines this improved Census transform with AD transform, utilizing adaptive synthesis weights. Additionally, the crosshatch domain adaptive window is improved by incorporating elevated threshold conditions for pixel grayscale differences, enabling better distinction between weak texture regions and edge regions. Experimental results demonstrate that the improved AD-Census algorithm achieves an 8.7% average mismatching rate on the Middlebury test image set, reduces average processing time by 30%, and exhibits improved robustness to lighting variations and noise. The algorithm's effectiveness is further validated through simulation analysis in a simulated planetary surface environment.
Jun. 25, 2025Vol. 62 Issue 12 1215013 (2025)
Zijun He, Yinchuan Feng, Songfeng Kou, Meimei Kong, Zhongcheng Liang, Jun Dai, Ju Ren, Yang Wang, and Rui Zhao
A zoom optical system based on liquid lens is designed to solve the problems of security mechanical zoom system, such as large volume, complex structure, and easy wear. Under the Gaussian bracket theory, ZEMAX and MATLAB software are employed for the optimal design of the optical zoom system and to evaluate its imaging quality. The results show that the optical system achieves the continuous zoom function within the range of 20?80 mm, with a corresponding zoom ratio of 4. The total length of the system is 108 mm, F number ranges from 2.5 to 8, and the field of view ranges from 10° to 24°. When spatial frequency is 80 lp/mm, its modulation transfer function across the entire field exceeds 0.35, and the distortion levels remain below 2%. This optical system has the advantages of fast response speed, no mechanical parts, and strong zoom ability, promising significant upgrades and enhancements to intelligent security monitoring systems.
Jun. 25, 2025Vol. 62 Issue 12 1222001 (2025)
Man Deng, Youming Guo, and Zhengdai Li
Traditional wavefront-detection-based deconvolution methods depend on time synchronization, where far-field images are captured simultaneously with wavefront measurements using a Shack-Hartmann wavefront sensor. This synchronization facilitates far-field image restoration via deconvolution. However, in practical applications, most adaptive optics systems lack time synchronization, which makes accurate motion blur kernel estimation challenging. To address this problem, we propose a multiscale optimal blur kernel estimation method. The proposed method effectively estimates motion blur kernels without requiring time synchronization. This method was applied to wavefront-detection-based deconvolution techniques and conducted simulations using two sets of extended targets. The results demonstrate that the proposed method effectively estimates motion blur kernels, offering a novel solution for image restoration in non-time-synchronized adaptive optics systems.
Jun. 25, 2025Vol. 62 Issue 12 1228001 (2025)
Tingxu Wei, Ying Chen, Chenghao Li, and Wenhao Ma
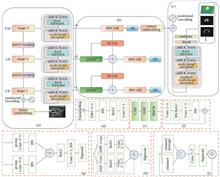
Aiming at the problems of low accuracy and efficiency of existing mainstream registration models due to the high resolution and large variation of target scale in remote sensing images, this paper proposes a registration model based on dynamic mix attention and multi-scale features. First, the ConvNeXt V2 network is introduced in the feature extraction stage, which enhances the ability to dynamically link the global context and local details by embedding dynamic mix attention. Next, a multi-scale feature calibration module is proposed to aggregate low-level texture information with high-level semantic information in multiple receptive fields to improve the registration accuracy. Then, a bi-directional matching method based on prediction matrix weighting is used in the matching stage to compute the dense correspondence to obtain the bi-directional parameters, and finally the image registration is completed by affine transformation. Experimental results on three datasets such as Aerial Image show that, the registration accuracy reaches 0.409, 0.864, and 0.953 with normalized distance thresholds of 0.01, 0.03, and 0.05, and the average registration time is 0.87 s. The results prove that the model effectively improves the accuracy and efficiency of remote sensing image registration.
Jun. 25, 2025Vol. 62 Issue 12 1228002 (2025)
Feng Sun, Yufeng Xiao, Haiyang Wang, Hongsen He, Ran Liu, and Liqiong Yang
This study addresses the situational awareness requirements for unmanned surface vehicles (USVs) operating in nearshore environments by proposing a dual solid-state LiDAR-based method for detecting water surface targets. The proposed method achieves high-resolution detection at a relatively low cost. First, a joint calibration model for the two solid-state LiDARs is developed utilizing the least squares method to determine the extrinsic parameters of the LiDAR scanning system. This calibration broadens the horizontal field of view while maintaining a 144-line scanning resolution. Second, a joint calibration between the LiDAR scanning system and the inertial measurement unit is performed, which reduces point cloud distortion through pose calibration and corrects scanning errors caused by the vessel's motion. In the detection algorithm, adaptive kernel convolution and hierarchical attention mechanisms are integratedinto the CenterPoint network, resulting in significant improvements in both inference speed and detection accuracy. A dedicated dataset for nearshore situational awareness is created, and experimental validation is conducted. Results show that the proposed algorithm improves overall average precision for bird's eye view (BEV AP) and 3D AP by 6.14 percentage points and 4.66 percentage points, respectively, and increases inference speed by more than 40% as compared with the baseline algorithm.
Jun. 25, 2025Vol. 62 Issue 12 1228003 (2025)
Chengzhuo Yin, Xiaohong Gao, Qi Song, and Yanjun Huang
Soil organic carbon (SOC) plays a critical role in the global carbon cycle and is a key indicator of soil health, with significant implications for global carbon cycling and long-term agricultural productivity. Timely acquisition of farmland SOC spatial distribution maps can facilitate carbon cycle research and the formulation of optimal fertilization strategies. This study takes the southern bank of the midstream for the Huangshui River Basin, Qinghai Province, which has representative farmland soils, as the study area. Surface (0?20 cm) SOC content is analyzed using both field and laboratory-measured spectral data, along with Sentinel-2 satellite imagery and 111 field soil samples. Four spectral transformation methods are employed to process the original full-spectrum bands. Three SOC estimation models—extreme gradient boosting (XGBoost), random forest (RF), and partial least squares regression (PLSR)—are constructed to identify the optimal model combination for estimating SOC content based on Sentinel-2 satellite imagery in the study area. Subsequently, correlation analysis (P<0.01) is employed to select characteristic bands for modeling, comparing the effect of these bands on the accuracy of field and laboratory spectral data-based models. The results indicate that the following: 1) Models built using characteristic bands selected from both field and laboratory spectra exhibit higher accuracy than those based on full-spectrum bands. 2) Sentinel-2 imagery combined with the optimal model [XGBoost+first derivative (FD)] proves effective in estimating and mapping SOC content in the study area, achieving a coefficient of determination (R2) for the training set of 0.707, an R2 for the validation set of 0.658, and a residual predictive deviation for the validation set of 2.069. 3) The mapping results reveal that SOC mass fraction in the study area ranges from 0.69 g/kg to 15.93 g/kg, with spatial distribution showing an increasing trend from northwest to southeast, northeast to southwest, and north to south, corresponding to increasing elevation. These findings provide data support for SOC content estimation and digital soil mapping, offering a basis for decision-making in carbon cycle research, precision agriculture, and farmland ecosystem conservation.
Jun. 25, 2025Vol. 62 Issue 12 1228004 (2025)
Guolong Li, Zhen Zhang, Jing Ding, Wanli Wang, Heling Sun, and Chao Deng
The precise segmentation of greenhouses using remote sensing images is crucial for the advancement of large-scale precision agriculture. However, existing segmentation methods often face challenges such as overfitting caused by redundant features and insufficient robustness to seasonal variations in spectral features. To address these issues, we propose the RLUNet model, which combines the ReliefF algorithm with a U-Net structure to optimize feature selection. The proposed model accurately identifies greenhouses by capturing multiscale seasonal variation features and integrating shallow spectral information with deep semantic data. The experimental results demonstrate that the proposed RLUNet model outperforms the baseline model in terms of segmentation accuracy, edge contour clarity, and gap pixel recognition. Specifically, overall accuracy improves by 0.06 to 1.11 percentage points, the intersection-over-union ratio increases by 5.63 to 13.41 percentage points, and the F1 score increases by 3.05 to 10.23 percentage points, effectively addressing feature redundancy issues. Furthermore, cross-validation with different images confirms the model’s robustness against seasonal spectral variations. This approach offers a reliable solution for greenhouse segmentation and holds substantial potential for applications in precision agriculture.
Jun. 25, 2025Vol. 62 Issue 12 1228005 (2025)
Zhengwei Yang, Junwei Huang, Chao Feng, Xia Li, and Zelong Zhang
Owing to the different imaging mechanisms between sensors, significant nonlinear radiometric differences exist among multimodal remote-sensing images, thus rendering image registration challenging. Hence, a dual-stage multimodal image-registration method based on structural information is proposed. In the coarse registration stage, the RIFT algorithm is combined with log-Gabor filters to extract the structural information of the images and construct a maximum index map. FREAK descriptors are constructed to describe key features, thus eliminating differences in feature descriptions under different sensor imaging conditions. In the fine registration stage, a dense three-dimensional template-structure feature representation is designed based on log-Gabor convolution image information, and a three-dimensional phase-correlation matching strategy is adopted for feature correspondence, thereby further improving the registration accuracy and efficiency. Experimental validation on six multimodal remote sensing datasets, including optical-optical, optical-infrared, optical-depth, optical-map, optical-SAR, and day-night, shows that this method outperforms the SAR-SIFT, RIFT, and SRIF algorithms across all metrics. The number of correct matches are 123.91 times, 4.09 times, and 2.82 times higher than the above algorithms, respectively, thus demonstrating the significant advantages and robustness of the proposed algorithm.
Jun. 25, 2025Vol. 62 Issue 12 1228006 (2025)
Chiming Zhang, Ji Qi, Zhong Wen, Qing Yang, and Xu Liu
Multimode fibers (MMFs), capable of supporting thousands of optical modes within a hundred-micrometer-scale diameter, exhibit unique advantages in imaging applications, including compact size, high resolution, and exceptional flexibility. Particularly in medical endoscopy, MMF-based endoscopes can access narrow cavities to realize submicron-resolution in vivo imaging with minimal tissue damage, demonstrating significant potential in brain science research and disease diagnosis. Light field modulation technologies combined with methodologies such as digital phase conjugation, transmission matrix analysis, compressed sensing, and deep learning effectively address the highly disordered light fields caused by mode dispersion and mode coupling during MMF transmission. To address the critical challenge of bending-induced mode distortion, researchers have proposed a series of MMF bending correction techniques. In this paper, we systematically review the advancements of MMF imaging across diverse fields, including in vivo endoscopic imaging, nonlinear optical effects, and multimodal integrated imaging. Finally, we summarize the challenges facing multimode fiber imaging technology and provide an outlook on future directions.
Jun. 25, 2025Vol. 62 Issue 12 1200001 (2025)
Zhaorong Zhang, Wenjuan Chen, Ting Zhi, Feifan Xu, Rongrong Dou, Zili Xie, Zhe Zhuang, Tao Tao, and Bin Liu
Motion sickness caused by prolonged augmented reality/virtual reality (AR/VR) displays is a short-term dysfunction triggered by allostatic stimuli. In particular, when the resolution and image response rate of AR devices are insufficient, severe motion sickness is one of the key factors affecting user experience. This paper first explains the pathogenesis and performance of motion sickness, analyzing the disorders caused by image stimulation and motion sickness. Second, the composition and classification of AR equipment are summarized, and the sources and management modes of delays are introduced. Subsequently, solutions are discussed to improve motion sickness and optimize the user experience from various technical perspectives. Finally, future development avenues for AR/VR display systems are presented.
Jun. 25, 2025Vol. 62 Issue 12 1200002 (2025)
Qishuai Han, Zhenping Xia, Cheng Cheng, Minming Gu, and Fuyuan Hu
As the core entrance to human-computer interaction, the design of the display system has a crucial impact on the user's immersive experience. This paper focuses on the influence of field of view size on immersion in the virtual reality display system, and constructs six virtual scenes with different field of view sizes based on virtual reality near-eye display technology. The subjects complete the perceptual interaction task in the scene, and the EEG device is used to record their EEG activity data in real time during the experiment to quantify the objective immersion. At the same time, the test subjects reporte their subjective immersion status through the immersion questionnaire after each task is completed. The experimental results show that the field of view has a very significant effect on the quantification results of subjective and objective immersion (p<0.001). Within the diagonal field of view (from 60° to 110°) of the experimental design, the larger the field of view, the greater the immersion. Based on the influence mechanism of field of view size on immersion, this paper constructs a model of the influence of field of view size on immersion, and the coefficient of determination of the model reaches 0.8488. The research content is expected to provide a reference for the design of immersive display systems for the metaverse and the optimization of user perception effects.
Jun. 25, 2025Vol. 62 Issue 12 1233001 (2025)
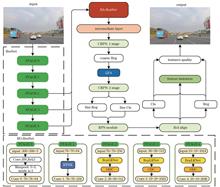
Zhengheng Li, and Chenyin Ni
In industrial microfocus cone-beam CT, when the number of scanning angles is sufficiently large, the images reconstructed using analytical algorithms exhibit high quality. Conversely, when the number of scanning angles is insufficient, the reconstructed images exhibit severe strip-like artifacts during sparse-angle scanning. To address strip-like artifacts caused by sparse-view scanning, deep-learning techniques are applied to assist in reconstruction. This approach reduces the number of scans and thus shortens the scanning time, while ensuring that the reconstruction quality is maintained. Specifically, the input image is first subjected to a discrete wavelet transform. Subsequently, a denoising diffusion probabilistic model (DDPM) is employed to learn the corresponding coefficients for the low-frequency components of the original image and the sparse-view reconstructed image after wavelet transformation. For the high-frequency components, a high-frequency recovery module based on a depthwise separable convolution is used for training. Finally, the image is synthesized via inverse wavelet transform. Experimental results show that the wavelet-based DDPM outperforms several other reconstruction methods on a custom-developed ball grid array dataset. By reducing the number of scans from 1024 to 180, the scanning time is 17.58% of the original. Meanwhile, the method effectively suppresses artifacts, preserves high-frequency details, and achieves superior performance in both qualitative and quantitative evaluations compared with other approaches.
Jun. 25, 2025Vol. 62 Issue 12 1234001 (2025)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20