








Please enter the answer below before you can view the full text.


2024
Volume: 61 Issue 16
20 Article(s)

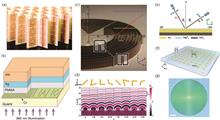
Shiyu Zheng, Yiwan Yu, Xuxi Zhou, Boyan Fu, Shuming Wang, Zhenlin Wang, and Shining Zhu
Optical metasurface technology, a novel planar optical technology, has made great progress in recent years, opening up broad application prospects for optical imaging. Metasurfaces offer several advantages, such as multifunctionality, easy integration, lightweight design, and compactness, while precisely controlling the wavefront. These innovative benefits provide new possibilities for multidimensional light field imaging technology and metasurface-based computational imaging. Metasurfaces can also be used in cutting-edge applications, such as augmented reality (AR), virtual reality (VR), optical fibers, and optical waveguides. They are also instrumental in innovative imaging technologies like super-resolution and quantum imaging. In the future, metasurfaces are expected to exhibit greater flexibility and adaptability, meeting the needs of various complex application scenarios and playing an increasingly important role in the field of optical imaging.
Aug. 25, 2024Vol. 61 Issue 16 1611001 (2024)
Xinyi Lu, Yu Huang, Zitong Zhang, Tianxiao Wu, Hongjun Wu, Yongtao Liu, Zhong Fang, Chao Zuo, and Qian Chen
Super-resolution microscopy imaging technology surpasses the diffraction limit of traditional microscopes, thereby offering unprecedented detail and allowing observation of the microscopic world below this limit. This advancement remarkably promotes developments in various fields such as biomedical, cytology, and neuroscience. However, existing super-resolution microscopy techniques have certain drawbacks, such as slow imaging speed, artifacts in reconstructed images, considerable light damage to biological samples, and low axial resolution. Recently, with advancements in artificial intelligence, deep learning has been applied to address these issues, overcoming the limitations of super-resolution microscopy imaging technology. This study examines the shortcomings of mainstream super-resolution microscopy imaging technology, summarizes how deep learning optimizes this technology, and evaluates the effectiveness of various networks based on the principles of super-resolution microscopy. Moreover, it analyzes the challenges of applying deep learning to this technology and explores future development prospects.
Aug. 25, 2024Vol. 61 Issue 16 1611002 (2024)
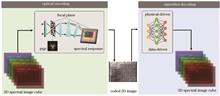
Jiaqi Guo, Benxuan Fan, Xin Liu, Yuhui Liu, Xuquan Wang, Yujie Xing, Zhanshan Wang, Xiong Dun, Yifan Peng, and Xinbin Cheng
Spectral imaging aims to obtain three-dimensional spatial-spectral data cubes of target scenes that substantially improves the recognition and classification capabilities of targets. It has been widely used in various fields, including military and civilian applications. Traditional spectral imaging techniques are mostly based on the Nyquist sampling theory. However, these techniques face challenges in balancing spatial, spectral, and temporal resolutions due to limitations posed by two-dimensional sensor arrays when capturing three-dimensional data cubes. The computational spectral imaging is based on the compressed sensing theory system. First, the optical system is used to encode and compress the projection of the three-dimensional data cube. Then, a spectral reconstruction algorithm is used to decode the three-dimensional data cube, which can balance spatial, spectral, and temporal resolutions. Starting from the unified theory of computational spectral imaging, this paper systematically summarizes three methods of optical field encoding: image plane, point spread function, and spectral response encoding. Additionally, it explores two types of algorithmic decoding: one is based on physical models and prior knowledge, while the other is based on deep learning for end-to-end reconstruction. Furthermore, this paper discusses the differences and connections between these methods, analyzing their respective advantages and disadvantages. Finally, it explores future development trends and research directions of computational spectral imaging technology.
Aug. 25, 2024Vol. 61 Issue 16 1611003 (2024)
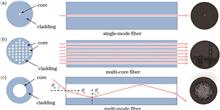
Jiawei Sun, Zhaoqing Chen, Bin Zhao, and Xuelong Li
Fiber optic imaging technology can achieve high-resolution imaging in narrow areas due to the small size and flexibility of optical fibers. Fiber optic imaging can also be employed in biomedical research and industrial inspections. However, there are bottleneck problems in multi-core and multi-mode fiber imaging systems, limiting their resolution and accuracy. This paper briefly introduces representative research on the applications of deep learning to address these bottleneck problems in various fiber imaging modalities such as fluorescence imaging, quantitative phase imaging, speckle imaging, and multispectral imaging. Existing bottleneck in this interdisciplinary research field involving deep learning and fiber optic imaging are also discussed. Additionally, we envision the broad application prospects of intelligent fiber optic imaging systems.
Aug. 25, 2024Vol. 61 Issue 16 1611004 (2024)
Yumeng Li, Yifan Zhang, Guang Yang, and Hui Li
The light-sheet flow imaging system (LS-FIS) enables high-resolution, high-throughput three-dimensional imaging of miniature model organisms like zebrafish. This capability presents potentially broad application prospects in the fields of developmental biology and drug screening. To study correlations between zebrafish structures, this study expanded on the original monochromatic LS-FIS to enable dual-color fluorescence imaging. To calibrate the resolution of the dual fluorescent channels, fluorescent microspheres were employed. Registration of dual-channel images and reconstruction of three-dimensional volumes were achieved using scale-invariant feature transform (SIFT) in combination with the random sample consensus (RANSAC) algorithm. Subsequently, this system was used to perform simultaneous imaging of zebrafish vasculatures and erythrocytes. Three-dimensional images were obtained and analyzed, revealing the distribution of vasculatures and erythrocytes in zebrafish larvae at 4 and 9 days post-fertilization.
Aug. 25, 2024Vol. 61 Issue 16 1611005 (2024)
Ruixue Wang, Xue Wang, Guoqing Zhou, Zhaolin Xiao, and Qing Wang
In response to snapshot compressive imaging (SCI) in dynamic light field temporal domain, a method called dynamic light field deep equilibrium (DLFDEQ) was proposed to reconstruct high-quality dynamic light field image frames (5D data) from known encoding patterns and acquired snapshot compressed measurements (4D data). First, based on compressive sensing, the same compression encoding for each viewpoint of dynamic light field image frames in the temporal domain was adopted. Second, the reconstruction process of compressive measurements was modeled as an inverse problem with an implicit regularization term. Finally, the inverse problem was solved through a deep equilibrium model based on gradient descent (DEQ-GD). The DEQ-GD model allows for the stable reconstruction of the required dynamic light field image frames from snapshot compressive measurements. Experimental results demonstrate that proposed method can recover a 5×5 viewpoints dynamic light field composed of 4 frames of images from a single snapshot light field measurement of a 5×5 viewpoints. Compared with the current state-of-the-art methods, proposed method demonstrates stronger robustness and preserves more accurate details in the reconstructed dynamic light field image frames. By repeatedly capturing and recovering these compressive measurement values, the temporal frame rate of reconstructed image is 4 times of the original camera frame rate.
Aug. 25, 2024Vol. 61 Issue 16 1611006 (2024)
Xin Jin, Zhenwei Long, and Yunhui Zeng
Light field imaging, with its rapid ability to record the direction and depth of light for volumetric imaging, holds significant scientific value and application potential in fields such as life observation and industrial inspection. Metasurface light field imaging, which synergistically combines metasurface technology with light field imaging, offers innovative approaches and methods for achieving higher performance, more compact, and diversified light field modulation and sensing. This paper provides a concise review of the development of metasurface light field imaging technology. Based on the differences in functional implementation and parameters design methods of metasurfaces, existing works are categorized into three types: physics derivation-based, inverse design-based, and end-to-end design-based. Based on the optimized light field imaging performance, the physics derivation-based approach is further subdivided into performance breakthroughs in resolution optimization, field of view expansion, depth of field extension, and depth perception. Through experimental comparisons of end-to-end design with various physics derivation-based schemes in color imaging considering depth of field, the advantages and potential of end-to-end design are demonstrated. The paper concludes by discussing the technical challenges for metasurface light field imaging in end-to-end design methods, high-performance light field capture, and miniaturized and integrated systems, and the development trend of metasurface light field imaging is forecasted.
Aug. 25, 2024Vol. 61 Issue 16 1611007 (2024)
Huijie Hao, Xinwei Wang, Jian Liu, and Xumin Ding
Metasurface, composed of subwavelength nanostructures, represents a disruptive and emerging technology that enables independent control of optical field characteristics, such as phase, amplitude, polarization, and dispersion. It is of significant importance for wavefront control elements, integrated imaging systems, and wearable optoelectronic devices. Metasurfaces allow for complex simulation calculations of input wave signals at the speed of light, providing a novel approach for constructing ultra-thin, ultra-fast, high-throughput, and highly integrated low-power optical imaging platforms. This article summarizes the recent advancements in optical simulation calculations and advanced imaging based on metasurfaces, discussing the fundamental connection between the two fields. The detailed overview of metasurface applications in these fields is provided, including image processing, edge detection, phase imaging, and integrated imaging systems. Finally, the current challenges facing metasurface optical computing are highlighted, and future directions for development are outlined.
Aug. 25, 2024Vol. 61 Issue 16 1611008 (2024)
Yu Meng, Manchao Bao, Tao Yue, and Xuemei Hu
Capturing the light field data of dynamical scenes has been widely adopted in virtual reality, microscopic observations, industrial inspections, and other important observation applications. The significant amount of data from current light-field imaging systems complicates their acquisition, transmission, and processing. In this study, inspired by the compound-eye optical structure of insects and the visual-neural work mechanism of fast fusion perception, we propose a novel dynamic light-field imaging paradigm for a meta-light-field event imaging system to capture meta-light-field events with high-dimensional light-field time-varying attributes, which can significantly enhance the light-field perception and characterization of a scene. By fully leveraging the spatiotemporal correlation between events under the light-field structure, we further propose a spatiotemporal-correlated event packaging algorithm, which affords efficient and robust extraction of meta-light-field events. To demonstrate the effectiveness of our proposed meta-light-field event imaging system, we construct a prototype system and test various experimental applications in different computer vision tasks, such as scene reconstruction, denoising, and trajectory reconstruction. Both simulation and experiments can fully demonstrate the high efficiency and robustness of our proposed meta-light-field event camera in capturing dynamic light-field information.
Aug. 25, 2024Vol. 61 Issue 16 1611009 (2024)
Jian Gao, Linzhuo Chen, Qiu Shen, Xun Cao, and Yao Yao
Recently, the advent of three-dimensional Gaussian splatting (3DGS) technology has brought revolutionary changes to the development of differentiable rendering techniques. Although neural radiance field (NeRF) has been a milestone in differentiable rendering, achieving breakthroughs in high-fidelity novel view synthesis, it still suffers from issues such as implicit expression and low training efficiency. In contrast, 3DGS technology addresses the pain points of NeRF by employing an explicit point cloud representation and a highly parallelizable differentiable rasterization pipeline. Compared to NeRF, 3DGS improves training speed and rendering efficiency while offering greater scene control. 3DGS technology propels differentiable rendering to a new height with remarkable achievements in areas such as novel view synthesis and dynamic scene reconstruction. 3DGS has been demonstrated to have broad application prospects and tremendous potential. This study aims to showcase the latest developments in 3DGS technology to inspire in-depth exploration of differentiable rendering techniques, with the hope of providing insights for technological advancements in the future.
Aug. 25, 2024Vol. 61 Issue 16 1611010 (2024)
Shujun Xing, Zihan Nie, Shuang Zhang, Xunbo Yu, Xin Gao, Xinzhu Sang, and Binbin Yan
Glasses-free three-dimensional (3D) display technology enables viewers to see stereoscopic images without visual aids, which is a focus of 3D display research. At present, the lack of image quality assessment methods for 3D display seriously restricts the development of light field display and content generation. In this study, objective evaluation metrics for crosstalk of glasses-free 3D display are proposed, considering the information reuse caused by the similar color values between adjacent pixels. The experimental results show that the correlation coefficient between the proposed metrics and subjective evaluation values is higher than 88%, indicating that the proposed metrics can detect the crosstalk perceived by the human eye.
Aug. 25, 2024Vol. 61 Issue 16 1611011 (2024)
Meng Zhang, Haiyan Jin, Zhaolin Xiao, and Fengyuan Zuo
The existing image feature matching methods still have significant limitations in dealing with complex scenes such as lighting changes and geometric deformations, due to the lack of depth information and global constraints in the measurement of feature matching. A method for measuring light field feature matching guided by disparity information is proposed to address this issue. Applying Fourier disparity layer decomposition to light field data to construct a scale disparity space, in order to extract light field features containing disparity information. A feature matching metric model that relies on depth cues of light fields was constructed based on projection transformation relationship models of light field features from different perspectives. The method of using artificial neural networks to learn the parameters of the projection transformation model aims to minimize the reprojection error as the objective function, and uses iterative optimization to achieve high-precision solution of the optimal projection transformation model, ultimately achieving the accuracy of feature point matching. The experimental results on the light field feature matching dataset show that compared to existing mainstream feature matching methods, the proposed disparity-guided light field feature matching metric model achieves better matching accuracy and robustness for scenes with lighting changes, geometric deformations, non Lambertian reflective surfaces, repetitive textures, and significant depth changes.
Aug. 25, 2024Vol. 61 Issue 16 1611012 (2024)
Chenming Han, and Gaochang Wu
To address the issues associated with 3D perception in endoscopic surgery, such as uncertainty in depth estimation and occlusions from a single-view image, this paper proposes a novel single-view multi-plane image (MPI) representation-based method. This method uses a fusion of a vision transformer and a conditional diffusion model designed for light field reconstruction in endoscopic operations. Initially, the method employs a vision transformer to tokenize the single-view input image, decomposing it into multiple image patches and extracting locally and globally associative features through a multi-head attention mechanism. Then, the image block features are reassembled and fused from coarse to fine using a multi-scale convolutional decoder to generate an initial MPI. Finally, to address the occlusion problem between tissues in single-view endoscopic surgery, a background prediction module based on a conditional diffusion model is introduced. This module uses the initial MPI to obtain an occlusion mask, and conditioned on this mask and the input viewpoint, it predicts the distribution of the occluded areas. This approach effectively addresses the problem of incoherent viewing angles in the light field caused by single-view input. The proposed method combines the initial MPI, decomposed by the vision transformer, with the background area predicted by the diffusion model to produce an optimized MPI, thus rendering the sub-view images within the endoscopic surgical light field. Experiment results on a real endoscopic surgical dataset from the Da Vinci surgical robot demonstrate that the proposed method outperforms existing single-view light field reconstruction methods in terms of both visual and objective evaluation metrics.
Aug. 25, 2024Vol. 61 Issue 16 1611013 (2024)
Peng Zhang, Lifen Shi, Ziyang Chen, and Jixiong Pu
Infrared small target detection technology holds important application value across key fields, such as autonomous navigation and security monitoring. This technology specializes in identifying small targets that are challenging to detect with the naked eyes, especially in low-light or obstructed environments. This functionality is of utmost importance for detecting potential threats and enhancing remote sensing capabilities. However, accurately detecting small infrared targets in infrared images presents substantial challenges due to their minimal pixel coverage and lack of shape and texture details. To address these challenges, we propose a deep learning model that integrates a multi-layer convolutional fusion module and a multi-receptive field fusion module. The proposed model aims to effectively represent small targets by extracting features at multiple levels and fusing features from different receptive fields. The model is tested using infrared images captured in a laboratory setting. The experimental results demonstrat that the proposed model performed well across multiple evaluation indicators, achieving a pixel-level intersection-over-union ratio of 0.814 and a sample-level intersection-over-union ratio of 0.845. These results confirm the high accuracy and reliability of the model for small object detection tasks. Furthermore, ablation experiments are conducted to evaluate the influence of different modules on model performance. These experiments confirm that both the multilayer convolutional fusion and multireceptive field fusion modules play crucial roles in improving model performance.
Aug. 25, 2024Vol. 61 Issue 16 1611014 (2024)
Zeyu Xiao, Zhiwei Xiong, Lizhi Wang, and Hua Huang
Light fields can completely capture light information in three-dimensional space, thus enabling the intensity of light at different positions and directions to be recorded. Consequently, complex dynamic environments can be perceived accurately, thus offering significant research value and application potential in fields such as life sciences, industrial inspection, and virtual reality. During the capture, processing, and transmission of light fields, limitations in equipment and external factors, such as object motion, noise, low lighting, and adverse weather conditions, can distort and degrade light-field images. This significantly compromises the quality of the images and restricts their further applications. Hence, researchers have proposed restoration and enhancement algorithms for various types of light-field degradations to improve the quality of light-field images. Classical light-field image restoration and enhancement algorithms rely on manually designed priors and exhibit disadvantages of high complexity, low efficiency, and subpar generalizability. Owing to the advancement of deep-learning technologies, significant development has been achieved in algorithms for light-field image restoration and enhancement, thus significantly improving their performance and efficiency. In this survey, we introduce the research background and representation of light fields as well as discuss the typical algorithms used for addressing different light-field degradations, with emphasis on spatial and angular dimension super-resolution, denoising, deblurring, occlusion removal, rain/haze/snow removal, reflection removal, and low-light enhancement. We conclude this survey by summarizing the future challenges and trends in the development of light-field image restoration and enhancement algorithms.
Aug. 25, 2024Vol. 61 Issue 16 1611015 (2024)
Mingzhi Cao, Bowen Wang, Jingya Qi, Fujie Wu, Yingjun Sang, Sheng Li, Lin Li, Yuzhen Zhang, Qian Chen, and Chao Zuo
In optoelectronic imaging systems, the use of multi-camera/multi-aperture computational imaging technology is increasingly recognized as an essential method for achieving wide-field and high-resolution image reconstruction. This technology seeks to overcome the spatial bandwidth product limitations inherent in single imaging systems. However, multi-aperture image synthesis typically involves complex processes such as feature point extraction, descriptor matching, and alignment between sub-eye images, which substantially increases the computational complexity and poses challenges for real-time performance. This is particularly problematic in scenes with moving objects, where the reconstructed images often suffer from ghosting phenomena such as artifacts and misalignment, thereby degrading the imaging quality. To address these issues, this paper introduces a dynamic panoramic image synthesis technology using a multi-aperture compound eye camera array. The technology leverages compute unified device architecture (CUDA) to enhance and accelerate the registration algorithm based on speeded up robust features (SURF). Furthermore, it incorporates a frame difference method to minimize redundant information in the multi-frame registration process, enhancing the registration accuracy of the synthesized image by 15.91% and reducing the registration time by 91.23%. Additionally, the visual background extraction (VIBE) algorithm is integrated into the energy function of the seam line, with established update criteria for the seam line, facilitating the synthesis of panoramic images from multi-frame motion images without misalignment and artifacts. A 5×5 multi-aperture compound eye camera array imaging system was developed to achieve a horizontal 90° field of view synthesis. Compared with traditional stitching algorithms, this approach demonstrates improvements of 1.96 and 1.85 on the reference-free image space quality evaluation index (BRISQUE) and the perception-based image quality evaluation index (PIQE), respectively. Moreover, the system can complete the stitching, reconstruction, and synthesis of 25 sub images at interactive frame rate of 13 frame/s, reducing the reconstruction time by 99.7% compared to non-CUDA accelerated stitching algorithms.
Aug. 25, 2024Vol. 61 Issue 16 1611016 (2024)
Changji Dong, Hedong Liu, Xiaobo Li, Zhenzhou Cheng, Tiegen Liu, Jingsheng Zhai, Ruitao Zhang, and Haofeng Hu
To address the high sensitivity of polarization images to noise and the difficulty of conventional polarization image denoising techniques in ensuring accurate restoration of polarization information while eliminating noise, a 4D block-matching (PBM4D) polarization image denoising algorithm based on polarization constraints is proposed. Initially, the algorithm leverages Stokes relationships to enhance the polarization image and transform it into 3D data across the polarization dimension. Subsequently, 4D block matching is employed based on the similarity of polarization information to ensure fidelity in preserving polarization details. Additionally, the algorithm capitalizes on the physical correlation between distinct polarization channels. Finally, collaborative filtering in the 4D transform domain is applied to suppress noise effectively. Comparative analysis demonstrates the superior noise reduction capabilities of PBM4D across various signal-to-noise ratios, particularly evident in linear polarization degree and polarization angle images. Importantly, PBM4D retains the physical correlation and inherent properties of polarization images, facilitating robust recovery of polarization information from objects exhibiting diverse polarization characteristics.
Aug. 25, 2024Vol. 61 Issue 16 1611017 (2024)
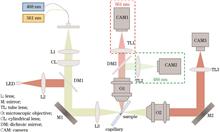
Xinyu Li, Fei Feng, Haoran Meng, Xu Cui, Lu Shi, Xuan Yang, and Haigui Yang
To achieve simultaneous analysis of the three-dimensional spatial structure and spectral information of a target sample, a multi-spectral Gabor in-line digital holographic microscopy imaging system is proposed. Specifically, an adjustable multi-wavelength LED illumination source is introduced into the Gabor coaxial digital holographic imaging system. Holographic images of a target sample at different wavelengths are acquired, and the reconstructed images of the target sample at various wavelengths are obtained through angular spectrum autofocusing and twin-image suppression algorithms. This allows the estimation of the sample's transmission spectra and realizes pixel-level image registration. The imaging performance of the system is tested using the United States air force (USAF) resolution chart, and multispectral experiments are conducted considering different biological tissue samples and liquids with different properties. The results demonstrate that the system can achieve an imaging resolution of up to 7.81 μm. Furthermore, the proposed imaging technique not only achieves color holographic microscopy imaging with good color reproduction, but also qualitatively distinguish liquids with different properties, which has potential application prospects in the imaging and detection of unlabeled biological samples.
Aug. 25, 2024Vol. 61 Issue 16 1611018 (2024)
Sen Qiu, Kai Zhang, Yan Wang, Bingbing Zhang, and Ye Tao
To enhance the accuracy and applicability of a three-dimensional (3D) phase retrieval algorithm in X-ray in-line phase-contrast computed tomography (CT) imaging, this study introduces a constraint-based optimization algorithm for the 3D contrast transfer function. The algorithm imposes constraints associated with sample information in 3D space and uses an iterative optimization method to improve the quality of 3D phase reconstruction. Simulation findings indicate that the constraint-based algorithm demonstrates improved accuracy in phase reconstruction, robust noise resistance, and a broader range of applicability compared with the traditional 3D contrast transfer function algorithm. The algorithm is expected to facilitate the application of X-ray in-line phase contrast CT imaging in various fields, including materials science and biomedical research.
Aug. 25, 2024Vol. 61 Issue 16 1611019 (2024)
Yi Zhang, Baoqiong Wang, Yueqiang Zhang, Biao Hu, Wenjun Chen, Xiaolin Liu, and Qifeng Yu
Camera calibration based on 3D/2D correspondences is of high significance in various applications. Herein, considering 3D/2D correspondences, the perspective-n-points-focal-radial (PnPfr) method aims to estimate the camera pose, focal length, and radial distortion. Therefore, this study proposed a novel solution to its minimal problem, such as the P4Pfr problem. First, four pseudo-depth factors are defined based on the pinhole and radial distortion models. Then, the translation vector is eliminated by decentralizing the 3D points, yielding a robust P4Pfr model. Finally, the rotation matrix is parameterized with respect to this model and solved by rotation constraints. Within this framework, ordinary and planar configurations are handled separately, with the former solved by Gröebner basis and the latter simplified to a six-degree univariate equation. The accuracy, robustness, and efficiency of the proposed algorithm are evaluated using a numerical simulation and dataset. The results reveal that the ordinary solver provides the highest robustness. Moreover, the robustness of the planar solver is comparable to that of the state-of-the-arts applications. Both the two solvers achieve the fastest solving speed to date.
Aug. 25, 2024Vol. 61 Issue 16 1611020 (2024)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20