





1. Background
The semantic description of dynamic scenes represents a highly challenging multimodal task within the field of machine vision. Traditional video captioning follows a "sensing–compression–decoding–description" pipeline (Fig. 1a), which, however, suffers from several significant limitations: 1) high-resolution videos lead to redundant storage and computation; 2) information loss occurs during the video encoding and decoding processes; and 3) the multi-stage processing pipeline results in low efficiency.
Snapshot Compressive Sensing technology, on the other hand, compresses multiple video frames into a single measurement matrix through physical encoding, thereby effectively reducing bandwidth requirements (for instance, typical physical encoding systems such as CACTI require only 5% of the bandwidth needed by conventional cameras). Nevertheless, existing methods still rely on a two-stage "reconstruction–description" process (Fig. 1b), which continues to face computational redundancy and efficiency bottlenecks, with the quality of scene descriptions being highly dependent on the quality of the reconstructed video (Fig. 1a and 1b). Therefore, a key issue is how to directly extract essential semantic information and generate textual descriptions from compressed measurement data, thereby enhancing the efficiency of semantic understanding of dynamic scenes.
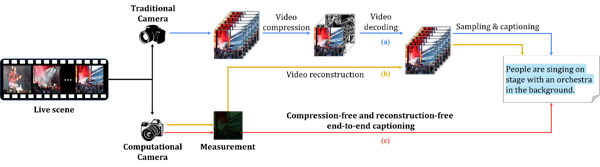
Figure 1 Different approaches to scene understanding: (a) the traditional multi-stage text generation process; (b) the computational imaging-based "reconstruction-to-text generation" process; (c) the end-to-end text generation process proposed in this study.
2. Research Content
Recently, Professor Chen Bo's and Professor Hao Zhang's research group at Xidian University in collaboration with Professor Yuan Xin's research group at Westlake University, published a paper titled "SnapCap: Efficient Snapshot Compressive Scene Captioning" in the Advanced Imaging. This study introduces the first end-to-end snapshot compressive captioning framework—SnapCap (Figure 1 c)—that bypasses video reconstruction. By integrating knowledge distillation with cross-modal representation learning, the framework achieves a direct mapping from compressed measurements to textual descriptions, resulting in over a threefold improvement in processing efficiency compared to conventional methods.

Figure 2 A typical Snapshot Compressive Imaging System
Figure 2 illustrates a typical video snapshot compressive imaging system, where dynamic encoding compresses high-speed video frames into a single measurement image, thereby enabling direct scene compression.
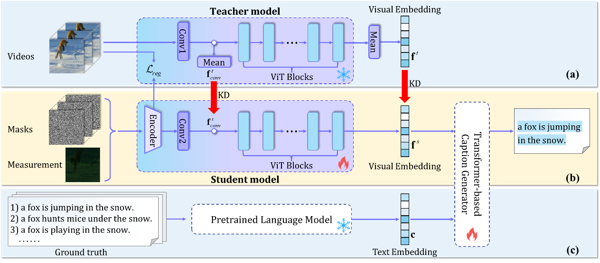
Figure 3 An overview of SnapCap, where (a) – (c) are about training and only (b) is involved during inference.
3. Technical Breakthroughs and Innovations
The highlights of the paper are summarized in the following three aspects:
(1) Knowledge Transfer and Semantic Extraction Mechanism for Heterogeneous Data from the Same Source
Due to the inherently sparse semantics and high dynamics present in both video signals and measurement matrices, performing semantic extraction and text generation in the compressed domain often yields unsatisfactory results. To address this challenge, the authors introduce the multi-modal pre-trained large model CLIP into the compressive sensing domain to extract semantic features from video signals. By aligning both the feature spaces ( and ) and the semantic embeddings ( and ), their approach simultaneously achieves knowledge transfer from video signals to compressed-domain signals and from the pre-trained teacher model to the student model (Figure 2 b and c).
(2) End-to-End Efficient Generation Architecture
Instead of following the traditional "reconstruction-then-description" two-stage process—which requires first reconstructing the original video signal before generating a text description—the study proposes a method that directly integrates text description with feature extraction. Specifically, as illustrated in Fig. 3(b), once the visual embedding representation of the compressed measurement matrix is obtained, it is directly fed into a Transformer-based text decoder, thereby enabling a direct, end-to-end mapping.
(3) Robust Text Description across Compression Ratios
Considering that hardware encoding ratios can vary between devices, posing optimization challenges, the authors propose a strategy that uses the video signal as a regularization mechanism ( as shown in Figure 3) to further align the feature representations of the measurement matrix with those of the original video. This approach ensures robust feature extraction across different compression ratios. Experimental results on the simulation dataset MSRVTT (Figure 4) demonstrate that, while traditional "reconstruction-to-description" methods suffer from decreased text description accuracy as the compression ratio increases—due to degraded video reconstruction quality, the proposed network exhibits strong robustness.
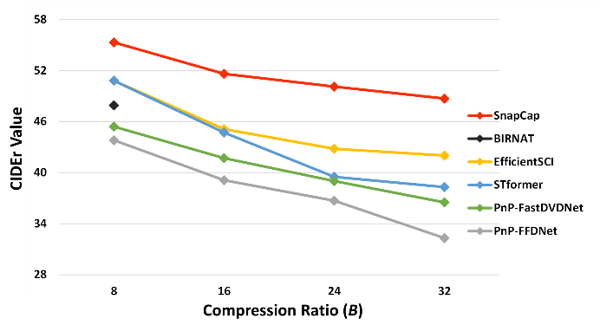
Figure 4. Performance comparison of the proposed method with "reconstruction-then-caption" methods at different compression ratios.
4. Applications
To validate the effectiveness and feasibility of the proposed method, the research team applied it to both simulated video data and real-world video data. The simulated data include the synthesized MSRVTT and MSVD datasets, which are standard benchmarks for video captioning tasks, while the real-world data consist of compressed measurement matrices recorded using the CACTI system. For the simulated data, the authors compared SnapCap with video-based text description methods, as shown in Table 1. In addition, results on the real-world data are presented in Figure 5, along with videos obtained via reconstruction (more results can be found in the original paper). These findings demonstrate that the proposed method can effectively extract semantic features and generate textual descriptions of scenes.
Table 1 A comparison of different methods on MSRVTT and MSVD datasets.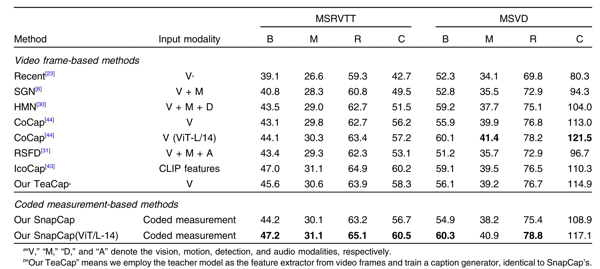
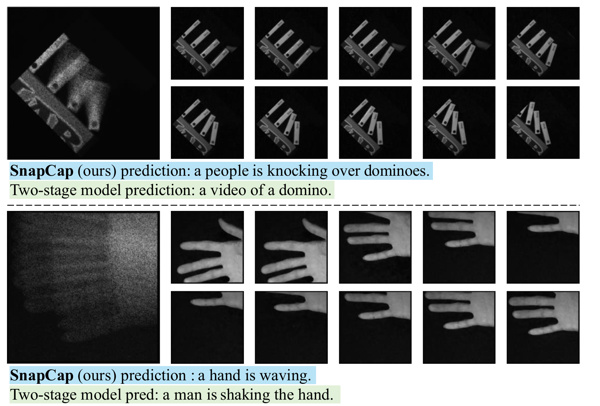
Figure 5 An illustration of language descriptions on real snapshot compressive imaging data.
5. Conclusions and Future Perspectives
This study introduces a novel cross-modal learning paradigm that integrates compressive sensing with semantic understanding, thereby demonstrating the feasibility of directly extracting semantic features from physically encoded data. In the future, by incorporating emerging computational imaging technologies such as single-pixel imaging, the approach could be further extended to applications in low-light environments and long-term observations. These findings offer a new solution for real-time dynamic analysis scenarios, including geological inspection and autonomous driving.