








Please enter the answer below before you can view the full text.
8+1=

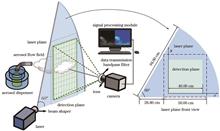
Real-time detection of aerosol flow field using planar laser-induced fluorescence (PLIF) technology is crucial for studying the motion of aerosol. To enhance the visibility of weak signals in real-time PLIF aerosol signal detection, we propose a method of piecewise intensity transformation in this paper. This method sets constraints based on the characteristics of signal intensity, iteratively divides the signal into several intensity ranges, and then replans the signal intensity in each range. The proposed piecewise intensity transformation is applied to the signal processing of PLIF aerosol flow field detection,compared with the processing results of limited contrast adaptive histogram equalization (CLAHE), this method has good results in weak signal enhancement and noise suppression of large dynamic range fluorescent signals, with an improvement of over 20% in the signal-to-background ratio of weak signals. The proposed method achieves real-time detection at 25 frames per second for different stages of aerosol flow field, meeting the requirements for real-time detection of aerosol flow field fluorescence signal.
Problems such as image color distortion, blurred image details, and image artifacts are prone to occur in the current dehazing algorithm. In order to solve the above problems, an image dehazing algorithm with parallel multi scale attention mapping is proposed. The algorithm achieves image defogging through an end-to-end encoder decoder structure. In the encoder stage, the continuous downsampling layer is used to reduce feature dimension and avoid over-fitting. In the feature transformation stage, a parallel multi scale attention mapping block with a parallel branch structure is designed, so that the model can make full use of multi scale features while focusing on important features of the image, and effective collection of image spatial structure information by connecting selective feature fusion block in parallel. In the decoding stage, the upsampling layer is used to reconstruct the image, and through skip connections of up and down sampling to better preserve image edge information. Experimental results show that the algorithm has better dehazing effects on both synthetic hazy datasets and real hazy images. Compared with traditional dehazing methods, this algorithm better preserves image details and has better color retention.
To address the problems of excessive loss of detail information, unclear texture, and low contrast during the fusion of infrared and visible images, this study proposes an infrared and visible image fusion method based on image enhancement and secondary nonsubsampled contourlet transform (NSCT) decomposition. First, an image enhancement algorithm based on guided filtering is used to improve the visibility of visible images. Second, the enhanced visible and infrared images are decomposed by NSCT to obtain low- and high-frequency subbands, and different fusion rules are used in different subbands to obtain the NSCT coefficient of the first fusion image. The NSCT coefficients of the primary fused image are reconstructed and decomposed into low- and high-frequency subbands, which are then fused with the low- and high-frequency subbands of the visible light image, respectively to obtain the NSCT coefficients of the secondary fused image. Finally, the NSCT coefficients of the secondary fused image are reconstructed by inverse transformation to obtain the final fused image. Numerous experiments are conducted with public datasets, using eight evaluation indicators to compare the proposed method with eight fusion methods based on multiple scales. Results show that the proposed method can retain more details of the source image, improve the edge contour definition and overall contrast of the fusion results, and has advantages in terms of subjective vision and the use of evaluation indicators.
Nowadays, micro-video event detection exhibits great potential for various applications. As for event detection, previous studies usually ignore the importance of keyframes and mostly focus on the exploration of explicit attributes of events. They neglect the exploration of latent semantic representations and their relationships. Aiming at the above problems, a deep dynamic semantic correlation method is proposed for micro-video event detection. First, the frame importance evaluation module is designed to obtain more distinguishing scores of keyframes, in which the joint structure of variational autoencoder and generative adversarial network can strengthen the importance of information to the greatest extent. Then, the intrinsic correlations between keyframes and the corresponding features are cooperated through a keyframe-guided self-attention mechanism. Finally, the hidden event attribute correlation module based on dynamic graph convolution is designed to learn latent semantics and the corresponding correlation patterns of events. The obtained latent semantic-aware representations are used for final micro-video event detection. Experiments performed on the public datasets and the newly constructed micro-video event detection dataset demonstrate the effectiveness of the proposed method.
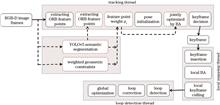
To address the low robustness and positioning accuracy of the traditional visual simultaneous localization and mapping (SLAM) system in a dynamic environment, this study proposed a robust visual SLAM algorithm in an indoor dynamic environment based on the ORB-SLAM2 algorithm framework. First, a semantic segmentation thread uses the improved lightweight semantic segmentation network YOLOv5 to obtain the semantic mask of the dynamic object and selects the ORB feature points through the semantic mask. Simultaneously, the geometric thread detects the motion-state information of the dynamic objects using weighted geometric constraints. Then, an algorithm is proposed to assign weights to semantic static feature points and local bundle adjustment (BA) joint optimization is performed on camera pose and feature point weights, effectively reducing the influence of the dynamic feature points. Finally, experiments are conducted on a TUM dataset and a genuine indoor dynamic environment. Compared with the ORB-SLAM2 algorithm before improvement, the proposed algorithm effectively improves the positioning accuracy of the system on highly dynamic datasets, showing improvements of root mean square error (RMSE) of the absolute and relative trajectory errors by more than 96.10% and 92.06%, respectively.
An integral task in self-service baggage check is the detection of whether pallets are added to the baggage. Pallets loaded with the baggage are mostly obscured; therefore, a fast detection method based on a multi-layer skeleton model registration is proposed to address this issue. A point cloud skeleton model and a point-line model are constructed using a 3D point cloud model to describe the characteristics of the pallet. During online detection, the designed banded feature description is used to capture the border point clouds. Moreover, the proposed point-line potential energy iterative algorithm is utilized to register the point-line model and border points as well as to realize pallet discrimination. An iterative nearest point registration based on random sampling consistency is used to achieve accurate registration and pose calculation as well as to obtain the accurate pose of the pallet. Experimental results show that the algorithm can maintain an accuracy of 94% even when 70% of the pallet point cloud data are missing. In addition, the speed of the proposed algorithm exceeds that of a typical algorithm by more than six times.
The recognition accuracy and efficiency of coal and gangue have a great impact on coal-production capacity but the existing recognition and separation methods of these minerals still have deficiencies in terms of separation equipment, accuracy, and efficiency. Herein, a coal and gangue recognition method is presented based on two-channel pseudocolor lidar images and deep learning. Firstly, a height threshold is set to remove the interference information from the target ore based on the lidar distance channel information. Concurrently, the original point-cloud data are projected in a reduced dimension to quickly obtain the reflection intensity information and surface texture features of coal gangue. The intensity and distance channels after dimensional reduction are then fused to construct the dual-channel pseudocolor image dataset for coal and gangue. On this basis, the DenseNet-121 is optimized for the pseudocolor dataset, and the DenseNet-40 network is used for model training and testing. The results show that the recognition accuracy of coal gangue is 94.56%, which proves that the two-channel pseudo-color image acquired by lidar has scientific and engineering value in the field of ore recognition.
This paper proposes a nondestructive detection method for detecting wall disease by employing multi-spectral imaging based on convolutional neural networks. This method aims to address issues such as low detection efficiency and easy interference by subjective factors that are associated with the use of artificial survey methods in traditional wall disease detection. The minimum noise separation method is used to preprocess the multispectral imaging data of a city wall, which reduces the dimensions of the data while preserving the original data features and reducing data noise. To address the problem of low classification accuracy caused by mixed and diverse pixels of different types of wall damage, a convolution operation is used to extract the features of wall damage, with the most important features retained and irrelevant features removed, resulting in a sparse network model. The extracted features are integrated and sorted through a full connection layer. Two dropout are included to prevent overfitting. Finally, on a wall multispectral dataset, the trained convolution neural network classification model is used to detect wall damage at the pixel level, and the predicted results are displayed visually. Experimental results show that the overall accuracy and Kappa coefficient are 93.28% and 0.91, respectively, demonstrating the effectiveness of the proposed method, which is crucial for enhancing the detection accuracy of wall disease and fully understanding its distribution.
Accurate estimation of the point spread function (PSF) is crucial for restoring blurry images caused by motion blur. This paper proposes a method using window functions to improve the accuracy of PSF parameter estimation and eliminate the interference from the central bright line in the spectrogram on the blurred-angle estimation. To achieve this, two-dimensional discrete Fourier transform and logarithmic operation are performed on the motion-blurred image, followed by the calculation of the power spectrogram. Thereafter, the Hanning window function is added to the spectrogram, and the image is processed using median filtering smoothing and binary transformation processing, in combination with morphological algorithm and Canny operator edge detection. Finally, the fuzzy direction is obtained using the Radon transform. Based on the blurred-direction results, the spectrogram of the motion-blurred image is processed by Radon transform in the direction of the blur angle. The distance between the negative peaks is analyzed to obtain the dark fringe spacing, and the blur length is calculated according to the relation between the dark fringe spacing and the blur length. This completes the estimation of the two point spread function parameters. Comparing the proposed algorithm with existing ones, the results show an improvement in the accuracy of parameter estimation, and a reduction in ringing and artifact phenomena generated during restoration. The proposed method makes full use of image information, and is easy to operate.
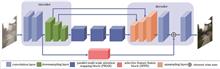
The two common degradations of underwater images are color distortion and blurred detail due to the absorption and dispersion of light by water. We propose an underwater image-enhancement algorithm model based on multi-scale attention and contrast learning to acquire underwater images with bright colors and clear details. The model adopts the encoding-decoding structure as the basic framework. To extract more fine-grained features, a multi-scale channel pixel attention module is designed in the encoder. The module uses three parallel branches to extract features at different levels in the image. In addition, the extracted features by the three branches are fused and introduced to the subsequent encoder and the corresponding decoding layer to improve the ability to extract network features and enhance details. Finally, a contrast-learning training network is introduced to improve the quality of enhanced images. Several experiments prove that the enhanced image by the proposed algorithm has vivid colors and complete detailed information. The average values of the peak signal-to-noise ratio and structural similarity index are up to 25.46 and 0.8946, respectively, and are increased by 4.4% and 2.8%, respectively, compared with the other methods. The average values of the underwater color image quality index and information entropy are 0.5802 and 7.6668, respectively, and are increased by at least 2% compared with the other methods. The number of feature matching points is increased by 24 compared to the original images.
A tone mapping algorithm for high dynamic range (HDR) images based on the improved Laplacian pyramid is proposed to enhance the rendering effect of HDR images on ordinary displays. The algorithm decomposes the preprocessed image into high-frequency and low-frequency layers, which are then fed into two feature extraction sub-networks. The algorithm combines their output images having different features via a fine-tuning network and finally obtains a low dynamic range image with a superior perceptual effect. Furthermore, the algorithm designs an adaptive group convolution module to enhance the ability of the sub-network to extract local and global features. The test results show that, compared to the existing advanced algorithms, the proposed algorithm can compress the brightness of the HDR image better, retain more image details, and achieve superior objective quality and subjective perception.
In recent years, with the development of deep learning, feature extraction methods based on deep learning have shown promising results in hyperspectral data processing. We propose a multi-scale hyperspectral image feature extraction method with an attention mechanism, including two parts that are respectively used to extract spectral features and spatial features. We use a score fusion strategy to combine these features. In the spectral feature extraction network, the attention mechanism is used to alleviate the vanishing gradient problem caused by spectral high-dimension and multi-scale spectral features are extracted. In the spatial feature extraction network, the attention mechanism helps branch networks extract important information by making the network backbone focus on important parts in the neighborhood. Five spectral feature extraction methods, three spatial feature extraction methods and three spatial-spectral joint feature extraction methods are used to perform comparative experiments on three datasets. The experimental results show that the proposed method can steadily and effectively improve the classification accuracy of hyperspectral images.
Visually induced motion sickness has become a serious problem for users of virtual reality technology. Users immersed in a virtual reality environment generally suffer from dizziness, vomiting, and other symptoms. The distortion in stereoscopic image acquisition leads to virtual space distortion in human perception, which may be an important factor inducing and enhancing visually induced motion sickness. To study the effect of the distortion of stereoscopic video acquisition on visually induced motion sickness, a virtual spatial distortion model is constructed based on the theory of stereoscopic video acquisition. In addition, different levels of stereoscopic spatially distorted videos are obtained from lenses with three focal length parameters. Visual perception experiments were conducted to objectively and subjectively evaluate visually induced motion sickness under different spatial aberrations. The results show that when the angle of view of the acquired stereoscopic video does not match the stereoscopic visual angle of human eyes, the distortion of the video significantly affects the visually induced motion sickness, and the distortion of the stereoscopic video acquisition results in a more intense visually induced motion sickness. This paper presents a novel and systematic method to experimentally verify that distortions in virtual space caused by the mismatch between acquisition and perception parameters enhance visually induced motion sickness. The findings of this study can help put forward practical mitigation methods.
It is known that PointNet++ cannot deeply explore the semantic features of Lidar point clouds during feature extraction and loses features due to the use of maximum pooling during feature aggregation. These problems result in a decrease in point cloud segmentation accuracy. To address these problems, this study proposes a point cloud segmentation model based on feature deviation values and attention mechanisms by improving the feature extraction and feature aggregation modules of PointNet++. First, different local neighborhoods are obtained using spherical sampling, and then neighborhood points are selected using the K-nearest neighbor (KNN) method to calculate the feature deviation values of different neighborhoods. This enhances the model's recognition ability for different local neighborhoods and obtains deep semantic information of the point cloud. Second, an attention-based feature aggregation module is used to replace the maximum pooling module in PointNet++ to learn the weights of different features during feature aggregation. This improves the model's ability to filter information from different structures and enhances the segmentation performance of the model. To further optimize the model architecture, a residual module is added to the fully connected layer to avoid parameter redundancy and improve the model performance through weight sharing. Experimental results are validated on the Vaihingen and S3DIS datasets provided by ISPRS and Stanford University, respectively, and are compared with the results of the experiments and mainstream models provided by ISPRS. The overall accuracy (OA) and average F1 score reach 86.69% and 73.97%, respectively, which are 5.49 percentage points and 8.30 percentage points higher than those of PointNet++, respectively. The experimental results on the S3DIS dataset are compared with those of PointNet++, RandLA-Net, and ConvPoint, and show a clear improvement over those of PointNet++. The experiments show that the improved model can fully extract the semantic features of point clouds and effectively improve the segmentation accuracy of the model as compared with the segmentation results of PointNet++.
Digital holographic microscopy allows numerical reconstruction of the complex wavefront of biological samples, but the wavefront of the object has quadratic phase distortion and high-order aberration, which gives the imaging object a certain phase aberration. In this study, a phase distortion compensation algorithm based on a radial basis function (RBF) neural network is proposed. The RBF network is used as the interpolation function to estimate the actual phase of the object by minimizing the loss function. The loss function takes into account the output of the holographic surface and RBF network. In the simulation, the global mean square error is calculated based on the original model. The results using the RBF network, principal component analysis, and the spectrum centroid method are 0.0374, 0.0470, and 0.3303, respectively. We set up a DHM system to observe the imaging amplitude and phase contrast of HL60 cells. The results show that the RBF method can better eliminate carrier frequency and phase distortion. The proposed method has the advantages of not requiring knowledge of the optical parameters and allowing adjustment of the number of sampling points to control the calculation time and interpolation accuracy. It has potential application prospects in the three-dimensional shape measurement of weak scattering objects or micro-nano structures.
Convolutional neural networks have been widely used in the field of image super-resolution, and the expansion of the transformer in such image processing tasks is a milestone in recent years. However, these large networks have excessive parameters and entail a large amount of computation, limiting their deployment and application. Given the above development status, a network based on staggered group convolution and sparse global attention lightweight image super-resolution reconstruction is proposed. A staggered group convolution feature extraction module is introduced in the network and in the transformer to improve attention mechanism optimization, and a sparse global attention mechanism is designed to enhance the feature learning ability. A multiscale feature reconstruction module is put forward to improve the reconstruction effect. The experiments show that compared with several other methods based on deep neural networks,the proposed method performs better in the peak signal to noise ratio (PSNR), structural index similarity (SSIM), parameter quantity, amount of calculation, and other performance indicators. Compared with the Transfomer-based method, the proposed method has an average increase of 0.03 and 0.0002 in PSNR and SSIM, respectively, and an average decrease of 2.66×106、130×109, and 930 ms in parameter quantity, amount of calculation, and running time, respectively.
The problem of coplanar reference points in monocular vision is a fundamental and critical aspect within the field of computer vision. We establish a model for the coplanar Perspective-n-Point problem and present a robust method, which comprises two main components: a direct algorithm and an iterative algorithm. In direct algorithm part, we address the problem of scale inconsistency during the pose estimation process, employ the singular value decomposition method to improve the recovery of the rotation matrix, leading to an estimation of the camera pose. This estimated pose is then used as the initial value for the iterative algorithm. In iterative algorithm part, we introduce an orthogonal iterative algorithm with the object-space collinearity error as the objective function. To enhance the robustness of this algorithm, a weighted orthogonal iterative algorithm is studied. We establish a threshold for determining outliers in the reprojection error and introduce weight information for this algorithm. Experimental results demonstrate that under conditions of limited reference points or minimal outliers, the proposed method exhibits excellent computational accuracy and robustness. It may provide significant practical value.
In this study, we aim to solve the recalibration of the external parameters owing to the changing relative positions of the camera and inertial measurement unit (IMU) in real-time dynamic imaging equipment. Thus, we propose a highly robust Camera-IMU external parameter online calibration method, which automatically estimates the initial value and external parameters when the mechanical configuration is unknown. The global satellite navigation time is used to align the timestamps of the IMU and camera. Then, the singular value decomposition method is used to solve the overdetermined linear equation of rotation. The threshold determination condition and weighting method are modified to reduce degenerate motion in the equation and eliminate the external points, improve system robustness and external parameter accuracy, and obtain constant Camera-IMU rotation external parameters. Then, based on the obtained Camera-IMU rotation external parameters, the sliding window is fixed and the Gaussian-Newton method is used to estimate the Camera-IMU external parameter translation. Compared with the original online calibration method, the calibration accuracy of the rotating external parameter is increased by 15% and the accuracy of the translation external parameters is improved by 35%. Experimental results show the effectiveness of the proposed method.
One-piece annular aperture lenses are being increasingly adopted to meet the requirements of lightweight and miniaturization for space cameras. However, the system presents certain limitations due to its use of a single substrate and compact structure, which result in chromatic aberration and spherical aberration,and the reduction of diffractive efficiency of single-layer diffractive optical element in wide band. To mitigate these issues, diffraction optical elements as well as even-order non-spherical aberration corrections have been introduced. In this paper, we propose an end-to-end optical-digital joint imaging system that optimizes the point spread function, which is the main factor affecting diffraction efficiency. We construct a spatially invariant point spread function model to establish the restoration function for subsequent image restoration, achieving the restoration of degraded images. The proposed optical system operates within the wavelength range of 0.45?1 μm and has the focal length of 185 mm, field of view of 5°, F# of 4, shading ratio of 0.35, and total length of 67.8 mm.
This paper proposes a self-supervised learning-based method for the super-resolution imaging of spatial-domain resolution-limited light-field images. Using deep learning self-encoding, a super-resolution reconstruction of the spatial-domain is performed simultaneously for all light field sub-aperture images. A hybrid loss function based on multi-scale feature structure and total variation regularization is designed to constrain the similarity of the model output image to the original low-resolution image. Numerical experiments show that the newly proposed method has a suppressive effect on noise, and the resultant average super-resolutions for different light field imaging datasets exceed those of the supervised learning-based method for light field spatial domain images.
Zero-order beam interference is generated at the focal plane when the liquid crystal spatial light modulator (LCSLM) is loaded with a computer-generated hologram (CGH) during laser beam splitting. To address this issue, we proposed to load a Dammann grating grayscale map to LCSLM using phase extinction interference, thereby removing zero-order beam interference. Based on the simulated annealing algorithm, the set of phase turning points was solved; simulations were performed in VirtualLab; and a script for generating Dammann grating grayscale maps was written using MATLAB software. Consequently, a verification system was built based on a liquid crystal on silicon spatial light modulator (LCOSSLM), and its modulation effect was tested. The results show that the zero-order beam interference is removed in the CCD field of view by loading the Dammann grating grayscale map for laser beam splitting. Moreover, the actual beam-splitting effect is close to that observed in the simulation results. Furthermore, the beam-splitting uniformity under one-dimensional five-beam splitting reaches 97.190%, which is better than the modulation effect of the grating CGH generated by the GSW algorithm. When the focal distance is large, effects of one-dimensional two- and seven-beam splitting are observed with beam-splitting uniformity levels of 98.453% and 96.820% respectively. The two-dimensional beam splitting is also observed with a measured beam-splitting uniformity of 95.436%. In addition, no zero-order beam is observed in the CCD field of view.
Aberrant amplification of the human epidermal growth factor receptor 2 (HER2) genes can lead to excessive proliferation of cancer cells and tumor progression. When conventional optical microscopy is used to detect the HER2 gene in breast cancer cells with high amplification levels, the fluorescent spots of the fluorescence in situ hybridization (FISH) probe tend to appear as clusters, making accurate counting challenging. In this paper, structured-light illumination super-resolution microscopy is applied to image pathological sections of HER2 gene fluorescence in situ hybridization, in order to resolve fluorescent probes close to each other. Through large field scanning imaging and image stitching, hundreds of cells can be imaged with super-resolution and statistically analyzed. The proposed method allows more accurate enumeration of aggregated fluorescent spots on slides with high-level gene amplification.
This study aims at the lack of automatic analysis and extraction of precise road rut boundaries in road maintenance and management and proposes a method of a three-dimensional (3D) rut-contour extraction based on a point cloud watershed algorithm to address the issue. The method first operated the elevation normalization processing for the laser point cloud data of single-lane pavement to eliminate the influence of the transverse slope. The envelope method was employed to estimate the relative depth of the pavement cross-section and generate the relative depth model of the pavement point cloud. This was further utilized to enhance the sag characteristics of rutting grooves and remove the influence of the longitudinal slope of pavement on the watershed algorithm of the point cloud. Then, the rough boundary line of the rut was obtained by calculating the curvature characteristics of the rut boundary. Besides, the road surface was divided into five regions. The point with the maximum relative depth of each cross-section in the corresponding region was selected as the water-injection point set of the point cloud watershed algorithm. Finally, the longitudinal contour of ruts was precisely obtained according to the principle of waterlogging in the watershed algorithm. An experimental analysis was conducted on the S218 provincial road in Pingdu city, Qingdao to verify the corresponding laser point cloud data of the road ruts. The results show that the proposed method can accurately extract the multitype rut boundary, and the root mean square error of the longitudinal boundary of the rutting contour obtained is less than 5 cm. Simultaneously, the root mean square error of the rut depth obtained based on the rut boundary is less than 1.5 mm, while that estimated using the envelope method is greater than 1.5 mm. This demonstrates the higher accuracy of the proposed method. Therefore, the proposed method provides an effective method to extract the 3D contour of ruts for road maintenance and management.
In this study, the common three-channel spectrometer was improved and optimized to realize the simultaneous detection of ozone and aerosol concentration using differential absorption lidar. First, the initial structure of the spectrometer is determined, followed by the calculation and analysis of the position of the four channels using the raster equation. Then, the four spectral channels are controlled within a reasonable mechanical structure range by adding distance constraints using a spherical mirror and a holographic grating. Finally, a four-channel and low F number spectrometer system is designed. The system uses circular array to linear fiber to improve the reception intensity of the receiving system for atmospheric echo signals and realizes accurate detection for 266, 289, 316, and 532 nm echo signal strength. The results show that the proposed spectrometer system can be connected to a linear fiber with a 0.12 NA. The obtained spectral resolution is better than 0.5 nm and 1 nm at 266, 289, 316 and 532 nm, respectively, thus, meeting the spectral resolution requirements of lidar detection. Moreover, the spectrometer's radius of curvature of the exit slit and the center position of the circle are analyzed. Our findings show that the proposed design can realize the simultaneous detection of aerosol and ozone by lidar and can also simplify the system structure.
Based on fused geometric optical imaging, this thesis proposes a theoretical analysis method considering single Mie scattering theory and the Monte Carlo method to study the influence of turbid water on imaging quality. The proposed method analyzes the imaging characteristics of a point light source with different wavelengths (456 nm, 524 nm, and 620 nm) is transmitted through a turbid water environment with different particle sizes and concentrations. The results show that the point light source with wavelength of 456 nm exhibits the best imaging effect when subjected to polarization imaging transmission in the same water environment and nonscattering environment. In addition, when the 456-nm light passes through turbid water with scattering particle sizes of 1 μm and 2 μm, the imaging effect of linear polarized light is better than that of circular polarized light, which is better than natural light. However, while passing through turbid water with particle sizes of 3 μm, 4 μm, and 5 μm, the natural light and linearly polarized light exhibit the best and the worst imaging effects, respectively. Overall, this paper provides new ideas and methods for underwater polarization imaging technology.
Automated and intelligent optical microscopy necessitates the measurement and correction of the focal plane drift for many biomedical applications, such as long-term observation of living cells and pathological whole slide imaging. In this study, we designed a method to perform focal plane drift measurements based on the detection of the reflected spot position of a nonsymmetric beam. Through simulations using ZEMAX software, the shapes of the reflected spots were simulated on the sample surface at different defocus positions. Furthermore, an integrated focus plane drift measurement module was constructed and tested on a commercial upright microscope. The results reveal that the proposed module exhibits a drift measurement precision of 250 nm and a response time of less than 500 ms for a 60× oil immersion objective, satisfying the demand for long-term and high-resolution imaging.
To address the issue of various types and large-scale differences of surface defects in aluminum profiles, as well as the tendency for small targets to be missed, we suggest an improved detection model for small defects on the surface of aluminum profiles based on YOLOv5s, called KCC-YOLOv5 model. First, the IoU(intersection over union)-K-means++ algorithm is used to cluster anchor frames in place of the K-means algorithm, aiming to obtain the anchor frames that best fit the surface defects of aluminum profiles and improve the quality of small target anchor frames. Second, a global attention module C3C2F is proposed and introduced into the backbone layer to enhance the semantic information and global perception of small targets while reducing the number of parameters. Finally, the neck nearest neighbor interpolation upsampling method is replaced by a lightweight upsampling operator CARAFE(content-aware reassembly of features), which fully retains the small target information of the upsampled feature map. The experimental results show that the mean average precision of the improved KCC-YOLOv5 model is 94.6%, which represents 2.8 percentage points improvement compared to YOLOv5s. Furthermore, the average precision for small targets, such as bubbles and spots, are increased by 5.2 and 12.4 percentage points, respectively. Overall, the KCC-YOLOv5 model significantly enhances the detection accuracy of small targets while maintaining a small improvement in the detection accuracy of large targets.
To address the problems of slow prediction speed and low segmentation accuracy of existing semantic segmentation methods for highway guardrail detection, an UAV highway guardrail detection method based on improved DeepLabV3+ is proposed. First, the MobileNetv2 network was used to replace the backbone of the original model and outputs the middle layer's features to reduce number of parameters while recovering the spatial information lost in the downsampling process; then an atrous spatial pyramid pooling was improved by the densely connected expansive convolution to reduce the phenomenon of missed segmentation; finally, the spatial group-wise enhance (SGE) attention mechanism was introduced in the encoder part to reduce the phenomenon of wrong segmentation. The experimental results show that the average intersection over union, average pixel accuracy, and frames per second transmission of the improved model can reach 79.20%, 87.89%, and 52.59, which are 2.59%, 2.93%, and 56.70% higher than the base model, respectively, and number of parameters is reduced by 78.85%. This method can thus improve the segmentation accuracy for the guardrail while guaranteeing the model's prediction speed.
Phase-shifting profilometry is widely applied in various fields because of its high measurement accuracy and robustness. However, the necessity to project multiple fringe patterns onto the object's surface requires the object to remain stationary during the measurement process. Conversely, overexposure occurs and its position changes with the object's motion during the reconstruction of the highly reflective moving objects, which poses a measurement challenge. Hence, this study proposes an algorithm for measuring highly reflective moving objects. The change in the overexposure position with the object's motion means that not all stripe patterns have overexposure. First, a dual-frequency fringe pattern is projected onto a moving object's surface, and photos are taken. Second, the overexposed areas in all fringe patterns are identified, and the nonoverexposed fringe patterns at each point on the object are recorded. Phase extraction is again performed based on the nonoverexposed fringe patterns with nonequidistant phase shifts to achieve a dual-frequency phase distribution. Finally, motion compensation is applied to the dual-frequency phase distribution, and correct unwrapping is achieved based on the dual-frequency unwrapping algorithm, thereby completing the three-dimensional reconstruction of highly reflective moving objects. The experimental results show that the algorithm effectively reduces measurement errors due to highly reflective moving objects and has a high industrial application value.
Phosphor sedimentation is a key factor affecting the light quality and optical consistency of white light-emitting diodes (LEDs). Herein, a detection method based on optical coherence tomography (OCT) is proposed to realize rapid, nondestructive detection of phosphor sedimentation in white LEDs. For this purpose, a white LED was imaged by an OCT system. Subsequently, the OCT and section images of the LED were compared, and the quantity distribution and sediment morphology of phosphor were analyzed. In addition, an algorithm was developed to extract the area fraction of phosphor from the OCT images based on the relationship between the quantity and area fraction of phosphor and the variations in quantity distribution during sedimentation. Furthermore, the relationship between the area fraction of phosphor and the degree of phosphor sedimentation was studied. The experimental results show that OCT can accurately determine the phosphor sediment morphology in white LEDs and that the area fraction of phosphor observed in the OCT images can quantify the degree of phosphor sedimentation. This method can meet the detection requirements of phosphor sedimentation in white LEDs and can be used for their quality testing and packaging process research.
A real-time particle detection and recognition method based on polarization ratio measurement and support vector machine is proposed. A dual-wavelength semiconductor laser was used as the light source. Additionally, a highly sensitive avalanche photodiode was employed to measure the two polarization components of scattered light, following which the polarization ratio of the scattered light was measured for particle classification. Furthermore, we combined a support vector machine and a neural network model to further increase the accuracy of particle classification and recognition. For the binary and ternary classifications in our study, the classification accuracy increases from 64% and 83% to 100% and 98%, respectively. This method has excellent application prospects in the fields of pharmacy, cosmetics, industrial production control, and detection.
Aiming at the problems of low data registration success rate and insufficient pose control accuracy in traditional assembly methods for workpiece assembly tasks with planar weak geometric contour structures, an assembly method for industrial parts based on planar point cloud registration and relative pose control is proposed. First, the workpiece point cloud information is reconstructed by the binocular structured light sensor, and the obtained results are registered using the RANSAC-ICP algorithm. Then, the relationship between the plane normal vector feature and the maximum distance is corrected to achieve accurate point cloud registration. The relative pose relationship-based manipulator control method is proposed, which omits the calibration of the tool coordinate system and directly controls the manipulator movement by relative pose. Then, it takes the relative pose error as the evaluation standard of the control system error to realize the reliability assembly. Finally, experiments are conducted using a large industrial manipulator in a real test scenario. The results show that the registration success rate of the proposed method is improved by 85 percentage points compared to the traditional assembly method, and the automatic assembly accuracy is better than 0.5 mm, which means that the method can effectively solve the problem of planar workpiece assembly.
To manage the problem regarding inconvenient mobile operations in the field under special conditions, we have designed a mobile robotic arm operation control system based on mixed reality. The system is categorized into three modules: human-computer interaction, mechanical drive, and virtual reality. The human-computer interaction module delivers corresponding operation instructions after recognizing the body gestures of the operator via camera. These operating instructions are then analyzed by the mechanical drive module that provides the working status of the equipment. Furthermore, this feedback information is received by the virtual reality module, which then restores the operation of the equipment in the built virtual scene to realize its real-time monitoring. The test results on a mobile robot platform show that the operator can achieve remote precise control and real-time monitoring of the mobile robot arm through the proposed system, and the system response speed can reach 60?100 ms/frame.
Voxel-based method is usually used in autonomous driving when conducting three-dimensional (3D) object detection based on a point cloud. This method is associated with small computational complexity and small latency. However, the current algorithms used in the industry often result in double information loss. Voxelization can bring information loss of point cloud. In addition, these algorithms do not entirely utilize the point cloud information after voxelization. Thus, this study designs a three-stage network to solve the problem of large information loss. In the first stage, an excellent voxel-based algorithm is used to output the proposal bounding box. In the second stage, the information on the feature map associated with the proposal is used to refine the bounding box, which aims to solve the problem of insufficient information utilization. The third stage uses the precise location of the original points, which make up for the information loss caused by voxelization. On the Waymo Open Dataset, the detection accuracy of the proposed multistage 3D object detection method is better than CenterPoint and other excellent algorithms favored by the industry. Meanwhile, it meets the requirement of latency for autonomous driving.
Neural radiation field (NeRF) exhibits excellent performances in implicit 3D reconstruction compared with traditional 3D reconstruction methods. However, the simple multilayer perceptron (MLP) model lacks local information in the sampling process, resulting in a fuzzy 3D reconstruction scene. To solve this issue, a multifeature joint learning (MFJL) method based on MLP is proposed in this study. First, an MFJL module was constructed between the embedding layer and the sampling layer of NeRF to effectively decode the multiview encoded input and supplement the missing local information of MLP model. Then, a gated channel transformation MLP (GCT-MLP) module was built between the sampling layer and the inference layer of NeRF to learn the interaction relations between higher-order features and control the information flow fed back to the MLP layer for the selection of ambiguous features. The experimental results reveal that the NeRF based on the improved MLP can avoid blurred views and aliasing in 3D reconstruction. The average peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and learned perceptual image patch similarity (LPIPS) values on the Real Forward-Facing dataset are 28.08 dB, 0.887, and 0.061; on the Realistic Synthetic 360° dataset are 32.75 dB, 0.960, and 0.026; and on the DTU dataset are 25.96 dB, 0.807, and 0.208, respectively. Overall, the proposed method has a better view reconstruction performance and can obtain clearer images and detailed texture features in subjective visual effects compared with NeRF.
In order to realize the spatial pose tracking measurement of target particles in a fluidized bed, a pose measurement system based on monocular vision and color texture-coded spheres is developed. For spatial position positioning, a spatial sphere imaging model is established, and based on the pinhole plane imaging model and camera coordinate transformation model, combined with the related theory of spatial analytic geometry, the principle of monocular position measurement is analyzed. Considering that spherical particles cannot measure spatial attitude through their own shape features, the texture feature is introduced, and the measurement of spatial attitude is realized by extracting the texture of the target particle, comparing and establishing its similarity with the known direction image in the synthetic library. According to the above theoretical analysis, an experimental system is built and a series of experiments are carried out. The results show that the comprehensive error rate of position measurement is not more than 0.5%, and the error of attitude measurement is not more than 2°, which verifies the effectiveness and feasibility of the proposed model.
Current detection methods for three dimensional (3D) point cloud data easily identify the local area of low-curvature cylindrical surfaces as planes in a model, but these methods can achieve the fast and accurate identification of only a single element. We propose a fast primitive detection method for point cloud data that can quickly and accurately detect both planar and cylindrical surfaces simultaneously. The proposed method is divided into two stages: coarse recognition and refinement. First, the point cloud is divided into small-grained patches, the patch characteristics are calculated, and the planar and cylindrical patches are roughly identified. Next, according to the filter conditions, the planar patches adjacent to the cylindrical patches are filtered, and then the patches with identical characteristics are combined to obtain the complete planar and cylindrical surfaces. Our experiments show that the proposed method is superior to two popular recognition methods when used to analyze data concerning five mechanical components. Moreover, the proposed method does not exhibit the omission and misidentification errors demonstrated by the other two methods, and the proposed method is more accurate in terms of the surface parameter estimation and segmentation when multiple cylindrical surfaces are connected.
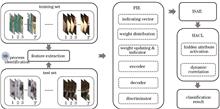
In lateral spine landmark detection, the previous heatmap regression methods have difficulty in distinguishing landmarks on different vertebrae due to the influence of organ occlusion and are prone to landmark and vertebrae matching errors. To solve this problem, we propose a new one-stage lateral spine landmark detection method, which simultaneously predicts the landmark heatmap and landmark matching clue (vertebra center heatmap and landmark offset), and uses the matching clue to match the landmarks with the corresponding vertebra. In order to improve the matching effect, we propose the geometry-aware feature aggregator module, which can extract the landmark features on the vertebra to enhance the feature representation of the vertebra center. We also use a weighted loss function to alleviate the imbalance of positive and negative samples in the landmark and the vertebra center heatmaps. Experimental results show that the average detection error of the proposed method is 8.84, which has 36% improvement in accuracy compared to the method with the second-highest performance.
Chest X-rays are used to diagnose a wide range of chest conditions. However, due to the complicated and diverse features of thoracic diseases, existing disease classification algorithms for chest radiographs have difficulty in learning the complex discriminating features of thoracic diseases and do not fully consider correlation information between different diseases. This study proposes a disease classification algorithm that combines self-attention and convolution to address these problems. This study employs omni-dimensional dynamic convolution to replace the standard convolution of the residual network to enhance the feature extraction capabilities of the network for multi-scale information. In addition, a self-attention module is introduced into the convolutional neural network to provide global receptive fields that capture correlations between multiple diseases. Finally, an efficient double path attention is proposed that allows the network to give greater attention to the focal area and automatic capturing of changes in lesion locations. The proposed model is evaluated on the ChestX-ray14 dataset. Experimental results show that the accuracy of the algorithm and the efficiency of diagnosis for the classification of 14 chest diseases is improved over those of the seven current state-of-the-art algorithms, with an average area under receiver operating characteristic curve (AUC) value of 0.839.
Aspheric mirrors commonly utilize a zero position compensator along with an interferometer for surface shape detection. Therefore, the machining and assembly accuracy of the zero position compensator play a crucial role in determining the reliability of the detection results. This paper introduces a universal compensation error calibration method based on computer generated hologram (CGH). To test the method, a Φ856 mm,f/1.54 hyperboloid mirror is employed as the target aspheric mirror. First, a reflective CGH is designed, and the phase function of the CGH is determined using a ray tracing method. This ensures that the introduced spherical aberration is the same as the normal aberration of the aspheric main mirror to be tested. Subsequently, the correctness of the design is confirmed through ZEMAX simulation calculation, and the primary hologram is processed based on the phase function. Holographic strips are designed and processed on the same glass substrate for adjusting the calibration optical path. The experimental results demonstrate that the CGH calibration achieves a zero position compensator accuracy of λ/80. The proposed method is applicable to concave aspheric mirrors with large apertures and fast focal ratios. Consequently, it can serve as a reliable guide for calibrating zero position compensators in most positive axis aspheric mirrors.
This study proposes an intelligent integration-design method to address the problems of complex structure, numerous parameters, and time-consuming optimization of terahertz frequency selective surface (FSS) cells. The method is based on convolutional neural network (CNN) combined with genetic algorithm, and is applied to the performance optimization design of typical filtered FSS. The FSS periodic cell topology is encoded as a 16×16"0/1"rotationally symmetric sequence, and 26,000 groups of transmission and reflectance spectra in the range of 0.5?3 THz are collected as the dataset. A 19-layer CNN is used to obtain the spectral prediction with an average absolute error as low as 0.06 on the test set. The difference between the predicted and the target spectra is used to give a generalized objective function for the design of various typical FSS cells. Combined with the genetic algorithm, a single-frequency bandpass and bandstop FSSs with a bandwidth of 0.1 THz, a single-frequency bandpass and bandstop FSSs with a bandwidth of 0.5 THz, and a dual-frequency bandpassFSS with a bandwidth of 0.2 THz are designed and implemented, with good polarization stability for all of them. Computational results show that various typical bandpass and bandstop FSS cells can be realized concisely and efficiently by optimizing their topological coding.
The precise positioning of driverless vehicles on unstructured roads extensively relies on LiDAR-based simultaneous localization and mapping (SLAM). However, the problem of localization loss, caused by the failure of pre-built map matching due to environmental changes, has been an industry challenge and a popular research direction. To address the aforementioned problems, this study proposes a long-term robust localization method, online location normal distributions transform (OL-NDT), which uses LiDAR and inertial measurement units to combine real-time local map matching based on NDT localization. OL-NDT inputs the localization information obtained by NDT as measurement information factors into the factor map to optimize the local maps constructed in real time and uses real-time local maps for localization after NDT localization is lost. OL-NDT is tested on the MulRan dataset and achieves a cumulative error percentage of 0.40%, which is 1.06 percentage points lower than the existing traditional localization methods. This effectively improves localization accuracy and enables accurate localization in scenarios with significant changes in the static structure. Moreover, the campus data collected by Beijing Union University is used to verify that the localization trajectory accuracy of OL-NDT precisely matches the known map, even in cases of short-term missing maps.
Aiming at the problem of poor matching effect caused by insufficient discriminative ability of artificial descriptors in multimodal matching tasks, the multimodal image feature matching method is extended from three aspects of feature point extraction (FPE), dominant orientation assignment (DOA) and feature descriptor construction (FDC), based on the constructed cumulative structure feature (CSF) map. In FPE stage, the hybrid points are extracted from CSF maps with different scales, taking into account the repeatability of feature points and positioning accuracy. In DOA stage, the CSF map and its orientation map are utilized to build the local structural feature field to extract the orientations of feature points, so as to alleviate the error-prone problem of dominant orientation estimation of feature points. In FDC stage, L1 distance and root operation are used instead of L2 distance to normalize the CSF descriptor, to improve the discriminative ability of descriptor in the feature matching process. The comparative experimental results of multimodal matching show that the proposed method is significantly superior to LHOPC, RIFT and HAPCG in terms of comprehensive indicators such as the average number of correct matching and average ratio of correct matching; and compared with CSF, the average ratio of correct matching of the proposed method was increased by 6.6%, and the average matching accuracy is increased by 5.8%, illustrating the effectiveness of the proposed method.
Aiming at the problem of low precision of position calculation algorithm and low calculation efficiency in ranging-based wireless positioning technology, a co-location algorithm based on Chan and improved sparrow search algorithm is proposed. The algorithm first applies the Chan algorithm to the time of arrival (TOA) positioning model to estimate the initial value of the position, and then uses the SPM composite chaotic map initialization, golden-sine strategy, adaptive weight factor, Cauchy-t disturbance and ejection boundary processing to improve the sparrow search algorithm, which effectively improves the global search ability and convergence accuracy of the algorithm. Finally, the ISSA algorithm iterative calculation is performed on the initial position value to obtain the final position estimate. The simulation and experimental results show that the algorithm improves the accuracy and speed of wireless positioning.
Building extraction from high-resolution remote sensing imagery is an important research direction for the interpretation of remote sensing imagery. To address the issues of small buildings easily lost and large buildings with blurred boundaries by traditional extraction methods, this paper proposes a multi-module building extraction U-shaped network (MM-Unet) based on Unet. First, Multi-scale feature combination module (MFCM) is introduced in the encoder and decoder sections of the network to obtain and supplement more spatial information. Then, multi-scale feature enhancement module (MFEF) is incorporated at the end of the decoder to enhance the extraction of multi-scale features. After the skip connections, the dual attention module (DAM) is introduced to adaptively learn the feature importance of channel and spatial positions, thereby reducing the differences among features at different depths. In order to validate the effectiveness of the network, experiments are conducted on Massachusetts, WHU, and Vaihingen building datasets with spatial resolutions of 1 m, 0.3 m, and 0.09 m respectively. and the intersection and union ratio of MM-Unet reach 73.42%, 90.11%, and 85.21%, compared to Unet, increased by 2.21 percentage points, 1.25 percentage points, and 1.55 percentage points. These results demonstrate that MM-Unet shows high extraction accuracy and strong generalization ability on buildings of various scales.
High-resolution unmanned aerial vehicle remote sensing images have extremely rich semantic and ground feature features, which are prone to problems such as incomplete target segmentation, missing edge information, and insufficient segmentation accuracy in semantic segmentation. To solve the above problems, based on DeepLabV3_plus model, an improved DeepLabV3_ DHC is proposed. First of all, multiple backbone networks are used for down-sampling to collect low-level and high-level features of the image. Second, the atrous spatial pyramid pooling (ASPP) of the original model is replaced by a depthwise separable hybrid dilated convolution, and an adaptive coefficient is added to weaken the mesh effect. After that, the traditional sampling bilinear interpolation method is abandoned and replaced by the learnable dense upsampling convolution. Finally, cascade attention mechanism in low-level features. In this paper, a variety of backbone networks are selected for the experiment, and some images of Longchang City, Sichuan Province are selected for the dataset. The evaluation index uses the average intersection and combination ratio and the average pixel accuracy of the category as the reference basis. The experimental results show that the method in this paper not only has higher segmentation accuracy, but also reduces the amount of computation and parameters.
Aircraft wake, an inevitable byproduct of aircraft flight, poses a major threat to aviation safety and limits the improvement of aviation efficiency and capacity. Accurate identification of aircraft wake vortex nuclei is a prerequisite for dynamically reducing wake intervals, and coherent Doppler Lidar (CDL) is the main tool for clear-air wake detection. To address the significant errors in identifying and inverting key parameters of aircraft wake turbulence caused by the limitations of CDL spatiotemporal resolution and background wind field effects, this study proposes a wake vortex parameter inversion model based on Bayesian network (BN) and mean squared error (MSE) using CDL detection data. An atmospheric background wind and turbulence environment are built and superimposed onto the simulated wake velocity field to obtain a simulation dataset for training the model. The results show that the proposed model can obtain parameter inversion results with small errors (within 2 meters deviation of the vortex core position and within 5% deviation of the ring volume in the simulated case) at an acceptable computational level. In actual cases, the mean squared error of the inversion velocity field is significantly reduced (more than 50% on average) compared with the conventional algorithm. This research can be used for real-time monitoring of wake vortices at airports and is of great significance for the development of wake interval standards.
Although the existing U-Net provides an ideal solution for remote sensing road extraction, its lack of attention to global information leads to the model's insufficient ability to extract contextual information. In order to further improve the accuracy and completeness of road extraction, context&multilayer features-UNet(CMF-UNet), which utilizes a pyramid feature aggregation module to fuse multi-layer features and introduces a multi-scale contextual information extraction module to enhance the contextual information capture capability, is proposed. Experimental validation is conducted on two datasets, Massachusetts Roads and CHN6-CUG, and the results show that compared with U-Net, CMF-UNet improves recall, F1-score, and intersection over union on the Massachusetts Roads dataset by 5.77 percentage points, 2.02 percentage points, and 2.62 percentage points respectively; on the CHN6-CUG dataset, recall, F1-score, and intersection over union are improved 6.47 percentage points, 1.53 percentage points, and 2.04 percentage points, respectively.
In this paper, a dual-stream convolutional autoencoding network for hyperspectral unmixing with attention mechanism (DSCU-Net) is proposed to address the issue of excessively smooth abundance maps caused by excessive incorporation of spatial correlations during pixel spectra in hyperspectral unmixing using a convolution-based autoencoding network. First, the spatial and spectral features of the hyperspectral images are extracted using a dual-stream convolution network. Second, the extracted spatial features are reweighed using a channel attention mechanism and fused with the spectral features to ensure a balance between the spatial and spectral features. Finally, the fusion features are used to reconstruct the hyperspectral image. Furthermore, these features are sent to the backbone in the unmixing network for hyperspectral unmixing. The entire unmixing network is trained by minimizing the two reconstruction errors. Additionally, experiments were conducted on two real datasets to evaluate the performance of the proposed method. The performance of the methods was also analyzed in complex scenarios. The results show that the proposed DSCU-Net can effectively overcome the fuzziness of abundance details because of the excessive introduction of spatial correlation. Moreover, the proposed method has a better unmixing performance.
Aircraft bunkers are the key aircraft protection fortifications. Therefore, the use of remote sensing images to achieve rapid and accurate detection of aircraft bunkers is of great significance. To develop a method for detecting aircraft bunkers through remote sensing images, we collected information and Google Earth images of 60 airfields with aircraft bunkers and constructed a high-resolution remote-sensing-image dataset of aircraft bunkers. Then, we compared the comprehensive performance of five deep-learning target-detection models, namely, Faster R-CNN, SSD, RetinaNet, YOLOv3, and YOLOX. The research results show that the YOLOX model performs better on the aircraft-bunkers-image dataset with an average precision of 97.7%. However, the results of the horizontal frame cannot obtain a precise boundary and orientation of the aircraft bunkers. Therefore, we propose a new method R-YOLOX, which is an improved version of the YOLOX model, for detecting aircraft bunkers under different orientations. Our method achieves the rotational detection of aircraft bunkers. Compared with the YOLOX model, the rotational prediction frame of our method fits the target contour more closely, and the model accuracy with respect to Kullback-Leibler divergence loss is significantly improved, with an increase of 7.24 percentage points, showing a better detection effect on aircraft bunkers. Further, the accurate detection of aircraft bunkers is achieved from the perspective of horizontal and rotating frames, thereby providing a new idea for the accurate identification of aircraft bunkers in remote sensing images.
Wheel odometry often does not perform as well as expected on complex surfaces, uneven surfaces, and smooth ground. At the same time, the traditional laser scan matching method does not always correctly correlate the relationship between point clouds, and thus is likely to have abnormal point-to-point correlation, which leads to bad localization accuracy. To solve this problem, a laser scanning matching method based on directional endpoints is proposed. First, we extract straight-line endpoints from the environment as the feature points, and then use the feature matching between the endpoints to obtain the relative pose relationships of the mobile robots in adjacent moments. The directional endpoints are used to eliminate the mismatched feature points to further improve the matching accuracy. Hence, the iterative closest point method is used to further optimize the matching results of the directional endpoints to obtain a better localization result of the mobile robot. The experiment results show that the method achieves an average localization error and an average angle error of 0.12 m and 1.18°, respectively, in an indoor environment of 7 m×7 m, which is superior in accuracy compared with the traditional laser scan matching algorithm.
For the single-photon ranging lidar system, the strong background light from both the emitted laser instantaneously and the backscattering of the near field will cause the photomultiplier to generate signal-induced noise (SIN), which seriously affects the detection of subsequent targets. In order to accurately calibrate the SIN at the single-photon level, a complete SIN detection and evaluation platform is built based on a self-developed single-photon ranging echo simulator and a pulsed laser with a fixed width of 10 ns. The induced noise under strong background light of different energy has been measured, and is also fitted using the relevant empirical formulas. According to the actual ranging system, the background light energy received at the detector should be less than 100 pJ in order to meet the signal-to-noise ratio requirement of 100 km-level ranging target inversion. This research provides an important reference for the performance evaluation of the single-photon ranging lidar system.
Optical images obtained through remote sensing are widely used in weather forecasting, environmental monitoring, and marine supervision. However, the images captured by optical sensors are adversely affected by the atmospheric conditions and weather; cloud covering also leads to content loss, contrast reduction, and color distortion of the images. In this paper, a cloud removal algorithm for optical remote sensing images is proposed. The algorithm is based on the mechanism of fusion and refinement and is designed to achieve high quality cloud removal for a single remote sensing image. A cloud removal network, based on the mechanism of fusion and refinement, implements a transform from cloudy images to cloud-free images. A multiscale, cloud feature fusion pyramid with a fusion mechanism extracts and fuses the cloud features from different space scales. A multiscale, cloud-edge feature refinement unit with a refinement mechanism refines the edge features of the cloud and reconstructs the clear, cloud-free image. This paper adopts an adversarial learning strategy. The discriminator network adaptively corrects the features and separates out the cloud features for more accurate discrimination, and makes the network generate realistic cloud removal results. The experiments were conducted on an open-source dataset and the results were compared with those of five competing algorithms. A qualitative analysis of the experimental results shows that the proposed algorithm performs better than the other five and removes the cloud without color distortion and artifacts. Further, structural similarity and peak signal-to-noise ratio of the proposed algorithm exceeds those of the second-placed algorithm by 11.9% and 15.0%, respectively, on a thin cloud test set, and by 9.3% and 9.9%, respectively, on a heavy cloud test set.
The transmission of satellite data is adversely affected by cloud cover; therefore, precise cloud detection plays an important role in recognizing remote sensing image targets and quantitatively inverting parameters. This study addresses the challenges of accurately identifying bright surfaces, thin clouds, broken clouds, and cloud boundaries and the stability of cloud detection accuracy across different scale features. We calculate linear regression on short-term time series datasets, using the slope-change trend of apparent reflectance of front and back time series datasets as the input. To fully leverage information from different scales, we employ the UNet++ model for cloud detection, which boasts a unique dense skip structure and deep supervision structure. Compared with U-Net, SegNet, and UNet++ of the single-temporal dataset, our proposed method can effectively highlight multiscale features and increase the sensitivity for bright surfaces, cloud-boundary contour, and thin-cloud information. Our results demonstrate that the proposed method achieves a high accuracy of 98.21% in cloud detection, and the false detection and missing detection rates are reduced to 1.07% and 3.12%, respectively. Furthermore, our method effectively reduces the interference of bright surfaces on cloud identification, such as barren lands, roads, buildings, ice, and snow, while improving thin-cloud identification accuracy. Therefore, our proposed method is suitable for remote sensing images of different underlying surfaces.
Optical diffraction tomography (ODT) uses refractive index (RI) as endogenous dyes to non-invasively obtain three-dimensional (3D) structural information of biological samples, and is promising to achieve long-term dynamic observation for living samples (such as live cells, etc.), which is of great significance in the fields of biomedical and life sciences. However, ODT relies on weak scattering approximation and interferometric measurement. The former greatly limits the observation performance of this technology on thick samples such as clustered cells and tissues, and the latter significantly increases the complexity of the imaging system. To address these issues, researchers have developed a class of diffraction tomography based on the principle of non-interferometric intensity measurement. First, a basic description of non-interferometric intensity diffraction tomography (IDT) is provided, including its imaging system, imaging metrics, and reconstruction problem; Then, we introduce the research results and latest progresses of non-interferometric IDT from four technical routes: non-interferometric phase retrieval, 3D optical transfer function, multi-layer forward propagation model, and neural network, and compare the above methods; Finally, current problems and challenges as well as future research directions are discussed.
Near infrared spectroscopy and hyperspectral imaging techniques have been widely used in agricultural and forestry products as well as food detection in recent years due to their advantages of high efficiency, nondestructive, and noncontact. These two techniques are applied to obtain spectral and imaging information of samples, and then chemometrics and machine learning modeling methods are combined to detect their quality and safety traits, adulteration issues, physical and chemical indicators, and origin traceability. Currently, they are both well recognized by people worldwide. However, the operating environment of optical instruments and the properties of the tested samples have their own limitations. The optical detection results are susceptible to various factors, which significantly affect the detection accuracy and should be eliminated or weakened. In this manuscript, the basic principles of near infrared spectroscopy and hyperspectral imaging are briefly described, and the influencing factors of these techniques at home and abroad are summarized. Considering the works of domestic and foreign researchers in related areas, the application of related correction methods regarding five aspects including temperature, illumination, moisture, curvature change and humidity is elaborated. Suggestions are finally presented for several existing problems to provide reference for researchers in this field.
Vision-based optical 3D reconstruction method has found wide applications in situations where the detection range is limited, and non-contact methods are preferred, as they offer rich information with minimal scene intervention. This study aims to introduce various methods used for 3D reconstruction, including laser scanning, structured light, moire method, time of flight based on active vision, stereo vision, and structure from motion based on passive vision. In addition, extensive comparisons of these methods are analyzed in detail. Next, the application of optical 3D reconstruction technology in crop information perception research is summarized and discussed. Finally, the study offers future perspectives on optical 3D reconstruction.
Spectral imaging is a method that integrates spectral and imaging techniques to extract spatial information and spectral information of an object to form a three-dimensional hypercube. As a fast and nondestructive optical inspection method, spectral imaging can meet the requirements of forensic science for examining physical evidence. Specifically, it plays a crucial role in the appearance, identification, and classification of trace evidence. In this study, the principle and workflow of spectral imaging are introduced, followed by cutting-edge applications in forensic science, such as examinations of document, blood stain, and fingerprint. Furthermore, the dilemma and future trend of spectral imaging are analyzed to promote further technological development that can serve forensic science.
Single-pixel imaging applies a series of spatial light modulated patterns to subsample the target scene with the assistance of a single-pixel detector, and subsequently reconstructs the object image according to the correlation between patterns and measurements. This indirect image acquisition method ensures reconstruction quality because of the reconstruction algorithm applied, and more crucially, the measurement mask construction. With the introduction of compressed sensing theory, random patterns emerged, but making the measurements blind and lacking specificity. Such patterns fail to facilitate storage and calculation, and thus significantly limit spatial pixel resolution. Recently, Hadamard basis patterns received widespread attention owing to their structured features that enable fast computation and facilitate storage and extraction. Considering this, numerous optimized ordering methods for the Hadamard basis patterns were developed, and proven to significantly reduce the sampling ratios. This study systematically reviews the design frameworks and frontier advances of these methods, and summarizes the future development trends of deterministic pattern construction. Finally, this contribution provides a beneficial reference point including guidance for subsequent research in this specific field.
Wide color gamut technology is one of the hot topics in the direction of image quality enhancement, which can considerably improve the color reproduction ability of video images and improve the visual perception of the human's eyes. The method of expanding the color gamut is divided into three main directions, the transmission of "negative" color light, high-saturation three-primary colors, and multi-primary colors. First, the research significance of wide color gamut technology is briefly described, then the existing standard color gamut and normal wide color gamut standards are introduced, and the imaging and display technology of multi-primary-color wide color gamut is elaborated. Finally, the problems to be solved in this field and the future development trend are discussed.
The comprehensive similarity between the camouflage target and the background can measure the feature difference between the camouflage target and the surrounding background. The higher the comprehensive similarity, the higher the fusion degree between the target and the background, and the higher the camouflage efficiency of the target. In this paper, seven typical features of target and background images, including brightness, color, texture, shape, size, structure, and histogram, are used to represent the camouflage characteristics of the target. The corresponding similarity measurement method is used to obtain the similarity of each feature. The entropy weight method is used to objectively determine the weights of different feature indicators, and the comprehensive similarity between the camouflage target and background is obtained by linear weighting. Thus, the quantitative evaluation results of target camouflage effectiveness can be obtained. Multiple experiments under different backgrounds, different reconnaissance distances and different target attitudes show that the comprehensive similarity between the camouflage target and the background proposed in this paper is consistent with the target discovery probability, consistent with the detection distance, and robust to the background, which proves the correctness and effectiveness of the proposed method. The reliability of the proposed method is proved by comparison experiment.