








Please enter the answer below before you can view the full text.
4+4=

To improve the ability of ResNet50 to extract target object features of remote sensing scene images and interpretability of scene classification, a Resnet50-CBAM-FCAM(RCF) network-based method of remote sensing image scene classification is proposed in this paper. This method increases the convolution attention module and full convolution-class activation mapping branch in the ResNet50 network. With the help of an attention mechanism, the branch features are fused with the extracted channel attention features and spatial attention features, respectively, and the class activation maps of various scenes are generated. The experimental results show that the overall classification accuracy of the proposed method in AID and NWPU-REISC45 datasets is more than 96% and 93%, respectively, and the visual results of the class activation maps can focus the target objects of remote sensing scene image accurately.
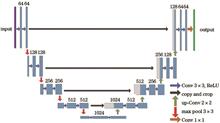
In order to solve the problem that the detection of thin clouds and broken clouds is very difficult due to the changeable cloud shapes in the research of cloud detection in RGB color remote sensing images, a U-shaped network based on multi-scale feature extraction (MS-UNet) is proposed. Firstly, a multi-scale module is proposed in order to obtain a larger receptive field while retaining more semantic information of the image. Secondly, the FReLU (Funnel Rectified Linear Unit) activation function is introduced in the first group of convolutions to obtain more spatial information. Finally, further feature extraction is performed after down-sampling, and in the up-sampling pixel recovery, the missing information is completed by jump layers, and the deep semantic features of the cloud are combined with the shallow detail features to achieve better cloud segmentation. Experimental results show that this method can effectively segment thin clouds and broken clouds. Compared with UNet, MF-CNN, SegNet, DeepLabV3_ResNet50, and DeepLabV3_ResNet101 networks, the overall accuracy is increased by 0.075, 0.065, 0.070, 0.013, and 0.005, respectively.
To ensure the real-time performance of the nonuniformity correction of the complementary metal-oxide-semiconductor (CMOS) image sensor in aerospace remote sensing cameras and reduce the photo response non-uniformity (PRNU) of the image, according to the structural characteristics of the CMOS image sensor, a CMOS image non-uniformity correction method based on an adaptive moving window is proposed in this study. First, from the perspective of engineering applications, a movable variable-step window is used to block the image so that multiple columns of pixels in the same window shared a set of correction parameters. Then, to solve the problem of insufficient linear fitting correction accuracy in existing methods, based on the nonlinear response characteristics of the CMOS sensor, the response curve is second-ordered by the least squares method. Experimental results show that the method can not only improve the quality of CMOS images but also reduce the number of correction parameters of the hardware system. The PRNU of the image corrected by the method is less than 1%. Compared with the linear fitting correction method, the number of correction parameters of the method is reduced by 23.7%.
In this paper, we propose a building environment classification method based on the Adaboost algorithm for autonomous environment perception and mapping of mobile robots in unknown building environments. In the proposed method, laser sensor is used to obtain the raster map of local environment, whose features are extracted. Then, the Adaboost algorithm is used to construct a scene classifier by selecting representative boundary points of different scenarios. We use a boundary-based path planning strategy, in which boundary points determine the navigation path of a mobile robot. Experimental results show that a mobile robot can conduct autonomous inspection in unknown building environments. Simultaneously, the detected local raster maps are spliced into a complete building environment map using built-in simultaneous localization and mapping (SLAM) technology to realize autonomous navigation.
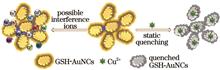
Reducing glutathione (GSH) is used as a stabilizer to synthesize gold nanoclusters (GSH-AuNCs) with good stability and water solubility. The specific static quenching effect of Cu 2+ on GSH-AuNCs fluorescence in aqueous solution is used to establish a rapid and highly sensitive detection method for Cu 2+. GSH-AuNCs emits strong fluorescence at 602 nm under the excitation light of 396 nm wavelength. When Cu 2+ exists in the GSH-AuNCs system, the fluorescence signal is quenched to a certain extent, and the greater the concentration of Cu 2+, the more significant the effect, the linear relationship between the fluorescence emission intensity of GSH-AuNCs and the concentration of Cu 2+ is established based on this, and the quantitative detection of Cu 2+ is realized. Under optimized conditions, the fluorescence emission signal of GSH-AuNCs showes a good linear relationship with Cu 2+concentration between 16.7 and 5000 nmol·L -1, and the detection limit is 7.4 nmol·L -1. At the same time, the recovery rate of the actual water sample is detected, the recovery rate is between 92.9% and 107.9%.
Aiming at the physical evidence of heroin mixtures and methamphetamine mixtures, a spectral identification method for drug mixtures based on the support vector machine-multilayer perceptron(SVM-MLP) fusion model is proposed. In the experiment, 90 sets of spectral data of the mixture of heroin, methamphetamine and other substances were obtained, and the baseline automatic correction and peak area normalization were used to eliminate noise and use principal component analysis extract characteristic wavenumber data spectral data fusion classification model based on SVM and MLP. The result shows that the SVM model based on Gaussian kernel function, linear kernel function, and polynomial kernel function can achieve accurate classification of 97.8%, 97.8%, and 95.6% of heroin mixture samples, respectively. The MLP model can achieve 96.5% for methamphetamine mixture samples accurate classification. The SVM-MLP fusion model is non-destructive, convenient and efficient is helpful for the identification of drug evidence in anti-drug cases and the judicial sentencing of the person involved has a certain universality and reference significance.
To alleviate the problem of the poor imaging quality of conventional color image sensors under low illumination, a low-illumination color image enhancement system based on a single sensor was proposed. The system simultaneously collects visible (VIS) and near infrared (NIR) images and enhances the VIS image using the NIR image. In the system, a series of image processing methods were proposed to handle the mixed light images. These methods involved a VIS separation method combining color subtraction and noise reduction to eliminate the influence of NIR on VIS color, a fusion method combining color space conversion and standardization processing to fuse VIS and NIR images, and a pixel replacement method to solve the contradiction between color discrimination and signal-to-noise ratio. Through the image processing of low illumination using NIR, the system can significantly improve the brightness, information, and signal-to-noise ratio of conventional color image sensors under low illumination.
In this paper, an image denoising network based on a hybrid attention mechanism and dual residual learning is proposed. The network uses a dual residual network learning structure based on different sizes of convolution kernels, which can not only reduce the difficulty of fitting deeper network structures, but also represent the multi-scale structure in the image. In the proposed denoising network, the feature channels are adaptively adjusted through hybrid local and non-local attention modules. Such hybrid attention module ensures that convolutional neural network can not only pay attention to the local features, but also depict the long-range dependencies in image. By comparing with several common deep denoising networks, the experimental results show that the proposed method can effectively suppress noise at different levels, specifically for the high-level noise.
In the process of acquisition of finger vein images, the high attenuation of near-infrared light in biological tissues reduces the contrast between the vein and non-vein areas, resulting in serious noise interference in the collected finger vein images. Accordingly, this paper proposes a stable enhancement method of the venous blood vessel region combining the Weber law and Gabor filtering. Based on the Weber law, the directional Weber differential excitations are established and combined with Gabor filtering organically in this method. Through the multi-scale and multi-directional characteristics of Gabor filtering, the directional excitation capability of WLD (Weber local descriptor) is amplified, and the mutual cooperation between the optimal response of Gabor filtering and the optimal excitation of Weber law is realized. This effectively highlights the venous blood vessel imaging regions and enhances the degraded finger vein images stably. The experimental results show that the method proposed in this paper has a good image enhancement effect and can effectively improve the distinguishability of the finger vein network.
In order to improve the clarity and visibility of underwater images, an algorithm based on the combination of differential channel gain and improved multi-scale Retinex algorithm is proposed to improve the quality of underwater images. First, considering the strong attenuation of red light by the water medium, the improved gray-scale world method is used to gain the red channel separately to make it closer to the uniform lighting scene. Second, in order to eliminate foggy blur and enhance the contrast of details, the improved multi-scale Retinex algorithm processes the image after the difference channel is enhanced, and replaces the logarithmic function in the multi-scale Retinex algorithm with the tanh function to reduce the loss of data and ensure the integrity of the information. Finally, the adaptive gamma technology is used to adjust the brightness of the image distributed. Experimental results show that the image processed by the proposed algorithm is clear, natural in color, and has better visual effects.
To obtain images having a high dynamic range, a multiexposure image fusion method based on an improved exposure evaluation and double pyramids is proposed in this paper. First, the exposure measurement index used for the evaluation of weight quality is optimized, and a weight image is constructed. Then, the Gaussian pyramid for decomposing weight images and the Laplacian pyramid for decomposing the original image are combined, and exposure fusion is implemented at different scales and decomposition layers to preserve more image detail information. Experimental results show that compared with the original image, the exposure-evaluation-based image, and the pyramid-based image, the image detail information fused by the method improve by 23.5%, 3.9% and 0.9%, respectively.
Layout segmentation is an important basic step in the process of document image analysis and recognition. In order to explore a suitable method for layout segmentation and description of Tibetan document images, a research method based on the adaptive run length smoothing algorithm is proposed. Firstly, according to the layout structure of Tibetan document images, K-means clustering analysis is used to get the run length threshold suitable for the layout, smooth the run length, find the connected component, and realize the layout segmentation. Then, according to the external contour characteristics of each layout element, the text area and non-text area are simply distinguished. Finally, the text area is recognized by a Tibetan text recognizer, and then the extensible markup language is used to record layout information and realize layout description. Experiments on Tibetan primary and secondary school teaching materials and stereotyped Tibetan document images show that this method can achieve good layout analysis results.
Text image skew correction is an important preprocessing step in the front-end of character recognition. To overcome the disadvantage in the limited range of tilt angle detection of the existing methods which is only -90--90°, this study transforms the text image skew angle detection problem into a skew angle class detection problem. Several types of skew angle classes of text images are detected using the classification function of deep convolution neural network by selecting the appropriate loss function and designing the detection structures of one-stage two classification and multi-stage multi-classification, and then getting the tilt angle range of the text image. The experimental results show that the tilt angle class’s detection accuracy, recall, and precision rates are all above 0.93. The classical deep learning method is used to recognize the text image after skew correction. Moreover, the recognition accuracy is greatly improved compared to that before the correction.
Rainy day is a common severe weather, in which rain streaks seriously affect the accuracy of algorithms, such as object classification, detection, and segmentation. In a rain image, multiscale rain streaks have similar shape features, which make it possible to exploit such complementary information for the collaborative representation of rain streaks. In this study, we construct a multiscale feature pyramid structure to exploit the similarity features between different rain streaks and design the initial, convolutional long short-term memory network (Conv-LSTM), fusion, and reconstruction modules. In addition, we introduce a lightweight nonlocal mechanism in the fusion module to guide the fine fusion and removal of rain streak features. Extensive experiments were conducted on synthetic and real-world datasets. Compared with four recent deep learning-based single image deraining methods, the peak signal-to-noise ratio(PSNR) and structural similarity (SSIM) of the proposed method significantly improved. Experimental results show that the proposed method can effectively remove rain streaks and avoid image blur, while maintaining the original image information.
According to the characteristics of complex gradient, uneven brightness, subtle defects, and multiple types of car navigation light guide plate image texture background, and according to the optical characteristics of light guide plate, dot arrangement, defect imaging effect, etc., a fast defect detection method combined with lightweight and cascaded deep learning network is proposed. First, based on the characteristics of defect distribution of the light guide plate, by improving the convolutional layer connection and the down-sampling method of the feature map, a lightweight two-classification network was designed to quickly segment the solid line suspected defect area. Second, the improved ResNet network was used to construct a multi-classification network. The lightweight network and the multi-classification network were cascaded and merged, and diversified features were extracted from the segmented suspected defect regions to achieve accurate defect classification. Then, defect region could be located and recognized by predicting images which were from fixed windows sliding on the completed light guide plate. Finally, a self-built dataset of light guide plate images collected from the industrial field was used, and a large number of experiments are carried out on this basis. Experimental results show that the average accuracy of the detection algorithm for light guide plate defects detection is 98.4%, and the single detection time is 1.95 s. The accuracy and real-time performance meet the requirements of industrial detection.
The task of recovering the 3D shape and its surface color from a single image at the same time is extremely challenging. For this reason, an end-to-end network model is proposed to solve this problem, which uses an encoder and decoder structure. Taking a single image as input, first extract the features through the encoder, and then send them to the shape generator and the color generator at the same time to get the shape estimation and the corresponding surface color, and finally through the differentiable rendering framework to generate the fianl color three-dimensional model. In order to ensure the details of the reconstructed 3D model, an attention mechanism is introduced into the network encoder to further improve the reconstruction effect. The experimental results show that compared with the 3D reconstruction network models, the designed model has a 10% and 3% increase in the real 3D model intersection ratio; compared with the open source project, the structural similarity of the designed model is improved by 3%, and the mean square error is reduced by 1.2%.
Aiming at the problem of the poor detection effect of ViBe algorithm under static background and the existence of “ghosting” in the detection target, an improved ViBe algorithm is proposed by combining the knowledge of the Hash algorithm and the two-dimensional information entropy of the image. First, the Hash algorithm is used to perform differential operations on the selected three frames of images, and the target area obtained after the difference is filled in the background to obtain the background image, and then the background image is modeled to eliminate the ghost phenomenon. Then, the adaptive threshold and update rate are obtained according to the complexity of the background, the adaptive threshold is used for foreground detection, and the connected domain information is used for secondary detection to obtain the target image. Finally, the target image is processed and the background is updated. According to the experimental data, after the improved algorithm detects pedestrians and vehicles in static scenes such as grass, leaves, and snow scenes, the F-measure value of the image is above 0.8, which is improved and more stable than the ViBe algorithm and the Gaussian mixture model. Experimental results show that the improved ViBe algorithm can eliminate ghosting, suppress background interference, and better detect target information.
To address the issues of high computational complexity and large memory footprint of the attention map of the self-attention mechanism and to improve the performance of the semantic segmentation network, we propose a lightweight network based on attention coding. The network uses an adaptive positional attention module and global attention upsampling module to encode and decode long-range dependency information, respectively. When calculating the attention map, adaptive positional attention module excludes useless basis sets and context information is obtained. A global attention upsampling module uses global context information to guide low-level features to reconstruct high-resolution images. Experimental results show that the segmentation accuracy of the network on the PASCAL VOC2012 verification set reaches a value of 84.9%. Compared with dual attention network, which has a similar segmentation accuracy, the giga floating-point operations per second and the GPU memory of the network are reduced by 16.9% and 12.9%, respectively.
To address the classification decision problems in synthetic aperture radar (SAR) image target recognition, a new recognition method based on updated classifier is proposed in this paper. The method uses a convolutional neural network and a sparse representation classifier as the basic classifier to classify samples with unknown categories. The decision results of the two methods are fused, and the reliability of the fused decision results is then determined. Subsequently, test samples with reliable categories are added to the original training samples to update the classifier to obtain more reliable recognition results. The experimental results based on the MSTAR data set show that the recognition accuracy of the method is higher than those of the other methods.
In order to improve the quality and output of industrial strip steels and address the problems of traditional manual identification such as identification difficulty, low efficiency and lack of objectivity, we propose a method for identifying strip steel surface defects based on the soft attention mechanism and improve the traditional deep residual network ResNet model. Moreover, we use the pseudo-color image enhancement technique to process images and obtain new training sets. The experimental results show that compared with the traditional models, the improved models of A-ResNet50 and A-ResNet101 can both accurately identify different types of strip steel surface defect images under different signal-to-noise ratios. The accuracies on the test set are 98.61% and 98.05%, and the unit inference time is 0.078 s and 0.130 s, respectively. Thus the feasibility and reliability of these two models in the identification of surface defects on strip steels are confirmed. The proposed method possesses a high identification accuracy, which can be used to realize the intelligent identification of surface defects on strip steels and meet the demands of industrial identification.
To solve the problems of low-illumination image, such as low brightness, low contrast, severe information loss, and color distortion, a low-illumination image enhancement algorithm was proposed based on a parallel residual network. The main function of the network model involved parallelizing the alternating residual module with the local-global residual module, using the improved loss function to calculate the test set loss, constantly adjusting the network parameters, and finally achieving a network model with strong enhancement ability. Experimental results show that the proposed model can effectively improve the brightness and contrast of the image and reduce the loss of edge details. Both synthetic and real image datasets were used in experiments. The subjective vision of our model is more natural, and the objective evaluation index is better than those of other contrast algorithms.
The conventional fuzzy C-means clustering algorithm is weak in terms of noise suppression in remote sensing image water segmentation and requires the manual setting of excessive parameters. To solve this problem, a fuzzy clustering remote sensing image water segmentation method combined with a gravity model was proposed. First, the fuzzy membership matrix obtained using the fuzzy C-means clustering algorithm was used as the initial membership matrix of the algorithm. Then, the ratio of the local standard deviation of the pixel gray value to the local mean was calculated. Furthermore, the normalized ratio was used as a weighting factor to reflect the influence of neighboring pixels on the central pixel. Finally, combined with the spatial attraction model, a tradeoff weighting factor was introduced in the relationship between the local space and fuzzy membership, which could simultaneously consider the spatial distance between the central pixel and its neighboring pixels and the difference in category membership. This factor can adaptively and accurately estimate spatial constraints using the neighboring pixels and fully adapt to the image content. Experimental results show that compared with the conventional fuzzy C-means clustering algorithm and related representative algorithms developed recently, the segmentation performance of the proposed algorithm is optimum. The proposed algorithm exhibits the highest segmentation accuracy, with a maximum of 97.1%, and the false alarm rate is reduced by approximately 15%--30%.
To solve the problem of serious degradation of images captured by imaging equipment in hazy scenes, a single image dehazing algorithm based on feature constraint cycle generative adversarial networks (CycleGAN) is proposed. First, the mapping relationship between the hazy image and the clear image is learned by the CycleGAN, and the discriminator determines whether the reconstructed image conforms to the data distribution of the real sample image. Then, as for network model loss function, the joint function based on cyclic consistent loss and Haze loss is constructed. The frequency information of image is introduced into Haze loss function as a constraint term and the content loss of high-dimensional feature is extracted by the pre-trained VGG-16 model, which can improve dehazing performance of the network and solve the problems of insufficient dehazing and image information loss in CycleGAN model. Finally, the peak signal-to-noise ratio and structural similarity index are used as the evaluation criteria for quantitative analysis between the input hazy image and the output dehazing enhanced image. Experimental results show that the proposed algorithm can effectively reduce the effect of haze on imaging quality, and obtain better subjective visual evaluation and objective quantitative evaluation.
For parity inflection point Gaussian decomposition method in full waveform data processing in the problem of insufficient accuracy, this paper puts forward a full waveform data processing algorithm based on peak effective correction. This method is first used in the process of data preprocessing the data block to estimate the mean and variance of noise, and then used in different signal segment and the matching filter width of Gaussian filtering. Then combined with the noise threshold and filtering after wave peak to extract the effective information. Finally, modify the Gaussian component parameters according to the peak information. Taking Beijing urban area as the experimental research area, the decomposition accuracy is compared with the results of other decomposition algorithms. The results show that the root mean square error between the height estimated by this algorithm and the actual measured value is 1.02, which is better than the results calculated by the even-odd inflection point Gaussian decomposition method and the Gaussian decomposition product GLA14.
An effective solution for data enhancement, video enhancement, and target detection algorithm compression is proposed to address the data deficiency, blurred images, and limited computing power of an embedded system of the unmanned underwater vehicle for searching underwater relics. First, the data augmentation was used to improve the generalization ability of small sample, and knowledge transfer was then implemented through transfer learning to accelerate the convergence of models. Then, key frame images were selected from the captured video based on the structural similarity, and the selected key frames were enhanced using the contrast limited adaptive histogram equalization stretching in real time. Finally, based on the multigranularity pruning strategy, YOLOV4 performed bidirectional compression of the channel and convolutional layer. The experimental results show that the operation complexity (BFLOPS) of the compressed YOLOV4 model is reduced to 10.588. The average detection speed for images with a size of 640 pixel×480 pixel on the Jetson TX2 embedded image processor reaches 18.2 frame/s.
In order to improve the display effect of high dynamic range images, a high dynamic range image tone mapping algorithm based on cross decomposition is proposed. Based on the analysis of image edge filtering, an image decomposition and reconstruction algorithm based on cross decomposition is given, and the reconstruction coefficients are analyzed, and then applied to tone mapping. First, the chromaticity and brightness information are separated in the chromaticity brightness space. Then, the brightness information is filtered by Gaussian filter and bilateral filter respectively to construct a crossover decomposition scheme, a base layer containing large-scale structure information, a detail layer containing texture information, and the edge layer where the brightness varies dramatically are obtained. Finally, by discussing the reconstruction coefficients in detail, the coefficient selection rules in tone mapping are determined, and the brightness range is compressed and reconstructed. The experimental results show that the proposed algorithm can effectively compress the dynamic range of the image while maintaining the color information, enhancing the edge and texture details and other features.
The key issue in improving compressed sensor signal reconstruction accuracy is to design an effective perception matrix. Therefore, this paper presents a transfer learning-based perception matrix optimization method. First, migration learning is used to update the sparse representation coefficients and the fixed sparse basis is converted into a sparse adaptive basis. Then, the Gram matrix is constructed using the product of the sparse basis and measurement matrix. Finally, the nondiagonal elements of the Gram matrix are minimized by eigen decomposition to reduce global coherence of the Gram matrix and achieve accurate reconstruction of the original signal. The experimental results show that the method’s reconstructed image peak signal-to-noise ratio is higher and its complexity is lower compared to the other methods.
Head pose estimation is an important part of gaze tracking but is usually calculated from two-dimensional (2D) images of human faces in most studies. Therefore, a three-dimensional (3D) head pose estimation method of eye tracker based on binocular camera is proposed in this paper. First, the spatial coordinate system and the facial intrinsic coordinate system are established. Then, the facial landmarks of the binocular image are detected by referencing the Dlib and the disparity and 3D coordinates of the corresponding facial landmarks are calculated. Finally, the Euler angle of the 3D head pose is calculated based on the symmetry of the face, and a pitch-angle correction algorithm is applied. To verify the accuracy of the method, a binocular head pose dataset is constructed using model heads and high-precision optical instruments. The experimental results show that the average error of the Euler angle by the method is 1.08° and the root mean square error is 1.25. The accuracy and robustness of the method exceeded those of the OpenFace method based on 2D images.
Indoor layout estimation is one of the important research topics in the field of computer vision, and it is widely used in three-dimensional reconstruction, robot navigation, and virtual reality. The current indoor layout estimation solutions have problems such as poor real-time performance and large calculations. To deal with these problems, this paper proposes a lightweight convolutional network based on multi-task supervision. The network model is based on the encoder-decoder structure and uses indoor edge heatmaps and planar semantic segmentation to achieve multi-task supervised learning. In addition, this paper modifies the convolution module, replaced 1×3 and 3×1 convolution with 1×1 convolution, which improves the real-time performance of the network while ensuring the accuracy of the model. The experimental results conducted on the public dataset LSUN show that the proposed method has good real-time performance and accuracy.
Considering that the existing infrared and visible image fusion methods do not entirely consider the information differences between different modalities and within the same modalities and the fusion image exhibit problems such as loss of detailed texture information and low contrast, this paper proposes an infrared and visible image fusion method based on a dual-channel generative adversarial network. The generation and identification networks are trained through confrontation, and the trained generation network is used as the final image fusion model. The fusion model uses dual-channel to extract features from infrared and visible images to retain more cross-modal information. Furthermore, a self-attention mechanism is introduced to enhance the input features and improve feature-richness in the modal to strengthen the global dependence of feature pixels. The experimental results on the TNO public dataset show that compared with the existing image fusion methods, the fused image obtained by the method has a higher contrast and richer detailed texture than the image obtained using existing image fusion methods. The fused image can efficiently fit human visual perception and performs well across a range of evaluation metrics.
In order to solve the problems of multiple types of road surface diseases, large scale changes in the scale, and small sample data sets in road surface disease detection, a road surface multi-scale disease detecting algorithm based on improved YOLOv4 is proposed. First, the depth separable convolution method is used to replace the ordinary convolution method in the CSPDarknet-53 backbone network, which reduces the amount of network parameter calculations. Then, the loss function of YOLOv4 is improved based on the focal loss, which solves the problem of low detection accuracy caused by the imbalance of positive and negative samples in the process of network training. Finally, the YOLOv4 network is pre-trained with the help of transfer learning ideas, and the data set is expanded using methods such as flipping, cropping, brightness conversion, noise disturbance and other methods, so as to solve the problem of over-fitting of network training caused by insufficient samples of road surface disease. Experimental results show that, compared with original YOLOv4 detection network, the mean average precision of road surface disease detection based on YOLOv4+DC+FL algorithm can reach 93.64%, which increases by 3.25%. The detection time is 35.8 ms per picture, which is reduced by 7.9 ms.
In this article, the PM, Jonswap, and Elfouhaily spectra were used to model the sea surface, and combining them with the measured data from Chinese stations, the radiances of seawater, sky, and atmosphere were calculated. The effects of wind speed and detection angle on the long-wave infrared polarization characteristics of the sea surface under different wave spectra were studied. Simulation results show that the long-wave infrared polarization characteristics of sea surface vary significantly during the day and night. When the detection angle of the PM spectrum is 80°, the average polarization degree of the sea surface reaches the maximum, while the corresponding detection angle for the Jonswap and Elfouhaily spectra is 70°. Under the same conditions, the incident angle distribution of the Jonswap and Elfouhaily spectra is relatively concentrated, and their average degree of polarization is higher than that of the PM spectrum. When the detection angle is 63°, the average degree of polarization of the sea surface modeled by the PM spectrum is unaffected by wind speed. The corresponding detection angle of the Jonswap and Elfouhaily spectra is 56°. When using different wave spectra to model the sea surface, the polarization characteristics of the simulated sea surface will be different. Therefore, the appropriate wave spectrum should be selected according to the characteristics of the sea surface scene to ensure the reliability of simulation results.
Aiming at the problem that the Gamma nonlinear effect of the projector and the camera will cause periodic errors in the unwrapping phase results, a phase error suppression method based on the mean template is proposed. First, Fourier transform is performed on the unwrapping phase to calculate the period value of the phase error. Then, a one-dimensional mean filter template with variable length is designed. The length of the template is related to the period of the phase error. Finally, this template is used to perform mean filtering on the unwrapping phase to eliminate periodic errors. Experimental results show that the proposed method reduces the periodic error of the unwrapping phase by an average of 94%, eliminates the distortion ripples that appear when measuring the depth information of flat objects with structured light, and improves the accuracy of phase measurement and depth information measurement without complex mathematical models and increasing fringe patterns. The proposed method is more suitable for practical applications.
Articulated laser sensor is a new-fashioned non-contact three-dimensional coordinate measuring instrument based on non-orthogonal axis architecture, which requires the intersection accuracy of laser beams from the left and right units. Therefore, the acquisition of high precision laser spot center is the premise and basis for ensuring measurement accuracy. The spot center-positioning error can be divided into random and system errors. For random error, the edge threshold method is used to eliminate them. For system error, a compensation method based on nonlinear least square fitting is proposed. Based on the straightness error evaluation method, the results of the above positioning and compensation method of laser spot center are compared and analyzed. The results show that the positioning accuracy of the centroid method can be improved to 0.12 pixel using the proposed method. Additionally, the proposed method performs better than other existing methods and satisfies the high precision measurement requirements of articulated laser sensor.
Digital image correlation (DIC) method is an indirect method for measuring displacement and strain. It has been widely used in related fields owing to its advantages of simple optical path and good adaptability. In this study, first, typical hollow disk metal parts are taken as the research objects and a self-built thermal deformation device is used to heat and control the temperature of the parts. Then, the DIC method is used to extract the image features of the parts before and after temperature change to calculate the thermal deformation of the outer diameter of the parts. Finally, ANSYS simulation software is used to simulate the thermal deformation of the parts under the same temperature change. Experimental results show that the thermal deformations of the parts measured using the DIC method correspond well with the ANSYS simulation results, which indicates that DIC method can be used to measure the thermal deformation of metal parts.
In digital image correlation calculations, it is usually necessary to manually select a speckle area for limiting the search area. With the development of industrial automation, it is often necessary to obtain the real-time displacement field and strain field of a material surface. It is particularly important to find a fast and accurate speckle area extraction algorithm. There exist the problems that the second-order gradient entropy function takes too much time in the speckle area extraction process and the speckle area cannot be accurately extracted for a complex and variable speckle. In light of these problems and according to the distribution characteristics of speckles, an algorithm for speckle area extraction is proposed, which is based on the weighted entropy of Laplacian pyramid. This algorithm not only reduces the amount of calculation, but also can flexibly and automatically determine the threshold value according to the entropy value distribution histograms of different speckle images. The research results show that in the extraction process of speckle areas, the proposed algorithm can flexibly select the threshold value to complete the automatic extraction of speckle areas, and simultaneously reduces the calculation time by more than 90%. This proposed algorithm is better than the second-order gradient entropy function, which can basically achieve the extraction of speckle areas under complex backgrounds and the extraction speed is significantly improved.
Large optomechanical instruments are difficult to process in short time. In order to verify the correctness of instrument design, the similarity model test was used to replace the prototype research. Based on the similarity theorem, the similarity relationship between the prototype and the scaled model of the collimator system in the Thirty Meter Telescope (TMT) wide field spectrometer was first derived. The finite element models of the prototype and the 1∶3 scaled model were then established, and the modal analysis and the surface analysis were conducted based on these two models. The similarity model test and the analysis for the scaled model object were finally performed. At the scale of 1∶3, the vibration mode similarities of these two models conform to the theoretical analysis results. The root mean square value of surface wavefront errors for the scaled model is 0.065λ(λ is wavelength) in the working environment. The model test results prove that the scaled model of the collimator system can satisfy the requirements of an optical system, which can predict the dynamic responses and surface deformation changes of prototype. The study can provide technical accumulation for the formal research of subsequent projects.
Deep learning stereo matching method based on three-dimensional convolutional neural networks (3DCNN) is fundamental to obtain accurate disparity results. The main concern with this approach is the high demand of computational resources for achieving high accuracy. To perform stereo matching method at a low computational cost, a method based on a gated recurrent unit network is proposed herein. The proposed method performs cost aggregation by replacing the 3D convolution with a gated-loop unit structure and reduces the computational resource requirements of the network based on the characteristics of the loop structure. To ensure high disparity estimation accuracy in images with weak textures and occluded areas, the proposed method includes an encoder-decoder architecture to further enlarge the receptive field in the 3D matching cost space and effectively aggregate contextual information of multiscale matching costs using residual connections. The proposed method was evaluated on the KITTI2015 and Scene Flow datasets. Experimental results demonstrate that the accuracy of the proposed stereo matching method is close to that of 3D convolutional stereo matching method while reducing the video memory consumption by 45% and the running time by 18%, greatly alleviating the calculation burden of stereo matching.
Due to the limited width of high-resolution satellites, earth observation applications involving a large area usually require mosaics of multiple high-resolution images taken at different times or different sensors. The process of mosaicing images usually includes 5 basic steps: sorting, registration, color balance, seam line detection, and overlap area fusion. The existing color balance methods do not make full use of the existing satellite data, and most of the algorithms only pursue visual effects, not the fidelity of the data. For this reason, a new spatio temporal fusion mosaic framework is proposed. The framework introduces the spatio temporal fusion method based on the enhanced deep super-resolution network, and the images of all shooting moments are adjusted to the same time through a global reference image to ensure consistent color styles. The method in this paper carries out mosaic testing in the red, green, and blue bands of LandSat8 images. The experimental results show that the proposed method is more effective than the existing mosaic methods.
This paper presents a visual simultaneous localization and mapping (SLAM) algorithm that combines the point and line features using a grouping strategy. The algorithm aims to improve the poor robustness of line feature extraction and low matching efficiency in the visual SLAM algorithm. First, the line segments grouping strategy merges potential homologous line segments to generate high-quality long line segments using the common junctions to screen the effective line features. Then, these line features are matched according to the affine invariance of point and line features. Finally, the error function of the point and line fusion features is constructed to minimize the reprojection error, thereby improving the estimation accuracy of the camera pose. When experimentally tested on the KITTI, EuRoC, TUM, and YorkUrban datasets, the algorithm effectively improved the robustness of feature extraction, thus improving the accuracy of camera pose estimation and mapping.
Aiming at solving the problems of low accuracy and slow speed in the surface defects detection of aeroengine components using traditional methods, an improved YOLOv4 algorithm is proposed herein. First, an aeroengine component surface defects dataset was developed and the K-means clustering algorithm was suggested to cluster the defect samples for obtaining the priori anchor’s parameters of different sizes. Second, the improved parameter-adjustment algorithm was used to scale the priori anchor’s sizes and increase the difference in sizes to improve the matching rate between priori anchors and feature maps. Finally, convolution layers were added after the different feature layers of the backbone feature extraction network output and spatial pyramid pooling structure to improve the ability of network to extract defect features. Experimental results show that the mean average precision (mAP) value of the improved YOLOv4 algorithm in the test dataset is as high as 82.67%, which is 4.55 percent point greater than that of the original YOLOv4 algorithm. The average detection time of a single image is 0.1240 s, which is basically the same as that of the original algorithm. Moreover, the detection performance is better than Faster R-CNN and YOLOv3.
Herein, a deep learning-based doorplate detection method was proposed to realize the global positioning of mobile robots in indoor environments. First, the target detection algorithm based on MobileNet-SSD was used to detect the doorplate area of the image acquired using a monocular camera. Second, an improved rotating projection method was proposed to correct oblique images. Third, doorplate number recognition was performed using the k-nearest neighbor algorithm. Fourth, the speeded-up robust feature point matching was performed based on the precollected front-view template pictures of each doorplate. Then, the camera pose solution was achieved based on the PnP problem. Finally, the global positioning of the mobile robot was realized according to the coordinate transformation. Experiments using a mobile robot in an office environment show that the average position error of the mobile robot based on the proposed method is about 7 cm. Moreover, the orientation error is 0.1712 rad, which is reduced by about 50% compared with using only the adaptive Monte Carlo method, and the angle error is reduced by about 57%.
In this paper, based on the geometrical optics principle of binocular imaging,we propose a binocular aiming system composed of dual cameras, which realizes the large-range and high-precision aiming of the laser beam on the charging target. By analyzing the positional relationship among the camera, the laser emitting port, and the charging target, large scale horizontal and vertical aiming as well as high-precision aiming has been realized theoretically and experimentally. The theoretical and experimental results show that when the focal length of the camera lens is 20 mm, the aiming error of each point is less than 1.6 mm on the 4 m×4 m plane 3 m away from the laser emission port; when the focal length of the camera lens is 50 mm, for the target 10 m away from the laser emission port in longitudinal area, the aiming error of the target does not exceed 2 mm. The system has the advantages of high aiming accuracy, simple device, and convenient operation, and it is an efficient and convenient aiming method that can be used in laser charging technology.
Aiming at the problem of binocular vision system in three-dimensional coordinate measurement of remote target point. First, this article analyzes the main error sources of camera calibration and three-dimensional positioning process in binocular vision are analyzed based on the principle of binocular vision measurement system. Then, derivative relations between binocular vision three-dimensional positioning measurement system and camera parameters, matching accuracy of feature points, pixel size, focal length, baseline length and measurement distance are derived. Finally, the influence of each parameter on the positioning error of the measurement system is obtained through the simulation experiment. The experimental results show that the error model has a certain guiding significance for the design of binocular vision measurement system.
Although dictionary learning has shown to be a powerful tool for image representation and has achieved satisfactory results in various image recognition tasks. Most traditional dictionary learning algorithms have been restricted to multi-resolution face recognition tasks mainly due to the poor discriminability of the dictionary. To solve this problem, we propose a novel multi-resolution dictionary learning algorithm with discriminative locality constraints (MDLDLC) in this paper. Based on the one-to-one mapping between each dictionary atom and the corresponding profile vector, we design two local constraints on profile vectors, referred to as intra-class and inter-class local constraints, by utilizing the local geometric structure of the dictionary atoms. Meanwhile, the two constraints are formulated into a unified regularization term and incorporated into the objective function of the dictionary learning model to optimize for encoding the discriminative locality of input data jointly. The proposed MDLDLC algorithm encourages high intra-class local consistency and inter-class local separation in the code space of multi-resolution images. Finally, extensive experiments conducted on different multi-resolution face image datasets demonstrate the effectiveness of the proposed MDLDLC algorithm. The results show that the proposed MDLDLC algorithm can learn the multi-resolution dictionaries with discriminative locality, preserving and achieving promising recognition performance compared with other state-of-the-art dictionary learning algorithms.
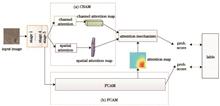
In view of the blurred boundary and low contrast of abdominal organs as well as the different liver and tumor shapes, a feature fusion-based method for automatic segmentation of liver and tumor is proposed in this article. The method is trained in two stages. The first stage uses an improved U-Net for liver segmentation. The second stage generates the area of interest (ROI) with the result of the first stage of liver segmentation, using ROI as input for tumor segmentation, which effectively avoids the effects of non-relevant information. The proposed method is run through two stages in which channel attention is used to obtain high-frequency information between channels, and spatial attention is helpful in using image spatial and contextual information. Then, feature fusion of two output feature images is completed in jump connection section. Finally, their feature information is combined via deeply-supervised net to further improve the segmentation accuracy. In the experiment, DSC, VOE, and RVD are mainly used as the evaluation criteria in which the liver and tumor of DSC are 0.957 and 0.676, respectively, realizing an accurate segmentation of liver tumor.
Breast cancer is one of the most common malignant tumors and poses a serious threat to women’s life and health. Current treatments mainly focus on surgery, chemotherapy, and radiotherapy and have apparent side effects. In the field of cancer treatment, photodynamic therapy (PDT) has been highly favored in tumor treatment in recent years because of its advantages of low invasiveness, high selectivity, and reproducibility of treatment. In this direction, we designed an innovative drug-loaded platform based on a metal-organic framework (MOF) for the ablation of breast cancer cells. MOF material PCN-224 can be used as a photosensitizer and a platform for carrying anticancer drugs, and the designed drug-loaded nanoplatform has a double killing effect on breast cancer cells. First, we loaded the anticancer drug MMAE into PCN-224 to determine the drug-loading capacity. Furthermore, the therapeutic effects of the drug-carrying material PCN@MMAE and the bare PCN-224 material were compared. Results showed that under identical illumination conditions, the drug-loaded platform significantly enhanced the killing effect without any obvious dark toxicity and effectively exhibited a synergistic effect of photodynamic therapy and chemotherapy.
Retinopathy of prematurity infants is an angiogenic disease. It is one of the main causes of neonatal retina damage or blindness. By segmenting and analyzing the structure of fundus vessels, early diagnosis and monitoring of retinopathy of prematurity infants can be performed. Compared with adult retinal vessels, those of prematurity infants have lower contrast and choroid overlap, which leads to low accuracy and sensitivity of retinal vessel segmentation. Therefore, the FDMU-net neonatal retinal segmentation model is proposed under the U-net framework. The model incorporates dense connection layers to improve feature utilization. During encoding and decoding channel stitching, multi-scale convolution kernels are used to fuse features, which improve the receptive field. Finally, the weighted focal loss of the vessel skeleton is used as a loss function to improve the network’s problem of poor segmentation of fuzzy samples. The algorithm proposed in this paper was tested on two public datasets, DRIVE and STARE, with an accuracy of 96.75% and 96.85%, and sensitivity of 81.52% and 84.84%, respectively. Moreover, after performing experiments on the fundus dataset of prematurity infants, compared with the U-net model, the AttentionResU-Net model and the multi-scale feature fusion full convolutional neural network model, the proposed FDMU-net model has higher accuracy and sensitivity. In conclusion, the algorithm proposed in this paper can satisfactorily solve the problems of vessel loss and low sensitivity in vessel segmentation and effectively segment the retinal vessel of prematurity infants.
Spaceborne multibeam photon-counting LiDAR can achieve high repetition frequency detection, effectively improving the spatial resolution of LiDAR on-orbit measurements and meeting application requirements, such as surveying, mapping, and vegetation measurement. Aiming at the characteristics of photon-counting LiDAR point clouds, an adaptive denoising algorithm is proposed in this paper. First, the shape of the search area is optimized and the distribution characteristics of the neighborhood noise point density are analyzed. Then, identification parameters of the noise points are adaptively determined according to the statistical characteristics of the neighborhood noise point density. Experimental results of point cloud data obtained using the airborne prototype show that the measurement accuracy of the algorithm on roof ridge lines can reach 0.13--0.27 m. Experimental results of the multiple altimeter beam experimental LiDAR airborne experimental point cloud show that the recognition rate of the algorithm for typical scenes, such as ice sheet, sea surface, vegetation, and land, is better than 94%, and the accuracy rate is better than 90%. This shows that the algorithm has good adaptability and can be applied to adaptive denoising of large-scale photon-counting LiDAR point clouds.
Large field of view, high resolution, and phase imaging are long-term goals pursued in the field of optical microscopy. Nevertheless, it is difficult to balance these performances in the conventional optical microscopic framework, which largely limits the application scope of conventional optical microscopy. Conventional microscopic imaging methods improve the imaging space-bandwidth product (SBP) or phase-imaging capability at the expense of a significant increase in the system construction cost or decrease in other imaging performances. Fourier ptychographic microscopy (FPM), as a representative computational microscopy imaging technology framework, can achieve large SBP and quantitative phase imaging simultaneously, without requiring precision mechanical scanning devices and interferometric systems. FPM has been widely studied and used in the fields of digital microscopy and life sciences; it has high research value and application prospects. In this article, the related research progress of FPM from the aspects of basic physical model, phase-recovery algorithm, and system-construction method is reviewed. In addition, the theory and application development direction of FPM are analyzed and discussed.
As a fundamental technique, object counting has broad applications, such as crowd counting, cell counting, and vehicle counting. With the information explosion in the internet era, video data has been growing exponentially. How to obtain the number of objects efficiently and accurately is one of the problems that most users care about. By virtue of the great development of computer vision, the counting methods are gradually turned from the traditional machine learning based methods to deep learning based methods, and the accuracy has been improved substantially. First, this paper introduces the background and applications of object counting. Then according to the model task classification, three counting model frameworks are summarized and the computer vision based counting methods in the recent 10 years are introduced from different aspects. Some public datasets in the fields of crowd counting, cell counting, and vehicle counting are introduced and the performance of various models is compared horizontally. Finally, the challenges to be solved and the prospects for future research are summarized.
Clinical detection of soft tissue biomechanics is of great significance for the early diagnosis, progress tracking and treatment evaluation of certain diseases. Optical coherence elastography (OCE) has been developed to visualize and quantify tissue biomechanics based on optical coherence tomography (OCT), in which to observe the static or dynamic mechanical responses of soft tissue organs under load excitation to quantify and reconstruct their biomechanical properties and thus to obtain the pathological information of diseased parts. Due to its advantages of non-invasive 3D imaging mode, real-time imaging treatment performance and high resolution, the OCE technique has the unique advantage and development potential in the clinical biomechanical measurement of soft tissue organs such as eyes. From the aspects of the static/dynamic excitation methods of OCE, the speckle tracking technology and phase sensitive detection technology of OCT, and the analytical and finite element analysis methods for biomechanical property quantification, we introduce the theory and method of OCE, review the development history of OCE, introduce and summarize in detail its newest achievements, and prospect its development trend.
The purpose of this study is to establish a classification method of rubber soles. An X-ray fluorescence spectrometer was used with the settings as follows: voltage 45 kV, current 40 μA, power 1.8 kW, and detection time 60 s. Forty samples of different types and brands of rubber soles were tested. Taking the type of shoes as the explained variable, a multiple linear regression model was established to calculate the score rating. Simultaneously, according to the standardized partial correlation coefficient, the characteristic elements can be screened out. Based on the above results, rubber soles can be classified according to the element content, providing clues and direction for the investigation work.
With the advent of the 5G era, the requirement of structured light 3D imaging technology for the narrowband filter of the invisible light receiving module is significantly increasing. Based on the film design theory of the Fabuli-Boro full-medium type interferometer, Si-H and SiO2 are selected as the high and low refractive index materials. Using the spectral resolution method, the inductively coupled magnetron sputtering technology and DC magnetron sputtering technology are used to alternately form the film to improve its aggregation density. The film's roughness is reduced. Besides, the film-forming temperature influence on the passband spectrum is reduced by the auxiliary anode. The final preparation takes a central wavelength of 945 nm. The average transmittance between 926 nm and 952 nm reaches 98.5%, and the offset of 0°-38° passband is 13 nm.
This paper investigates the effect of the linearization of camera JPG data on the accuracy of spectral reflectance reconstruction based on weighted polynomial regression algorithm and demonstrates whether the JPG data needs to be linearized in the weighted polynomial regression algorithm. This method was trained using the X-Rite Digital ColorChecker Semi Gloss (SG) chart including 140 color and grey patches and tested using the GretagMacbeth ColorChecker chart including 24 color and grey patches, and self-made 44 printed and 48 textile samples. Comparison results based on real camera data have shown that the weighted polynomial regression method with the original JPG data outperformed the weighted polynomial regression method with the linearized JPG data measured in terms of CIEDE2000 color difference and root-mean-square error. Based on the results of this study, linearization of the JPG data does not improve the reconstruction accuracy for reconstructing the reflectance using the weighted polynomial regression method. Without JPG data linearization, higher spectral reconstruction accuracy can also be obtained. The weighted three order polynomial regression method performed the best with original JPG data.
In order to improve the accuracy of local stereo matching, a stereo matching algorithm is proposed, which is based on improved Census transformation and adaptive support region. To solve the problem that the traditional Census transformation algorithm is sensitive to the sampling at a center point and has a high mismatching rate, this paper proposes an improved Census transformation algorithm which is insensitive to sampling by combining the information of the interpolation points at the left and right of a center point. In the stage of matching cost calculation, the improved Census transformation is combined with the color information and gradient information in x and y directions to construct the matching cost. In the stage of cost aggregation, a cross-based approach based on improved guided filtering is proposed to construct adaptive support regions and aggregate costs. Finally, the WTA strategy is used to calculate disparity, and the final disparity map is obtained through a multi-step refinement. The experimental results show that the algorithm proposed here has an average mismatch rate of 4.92% in four sets of standard images on the Middlebury test platform, indicating that it has high accuracy and good adaptability.