




 View fulltext
View fulltext

2023
Volume: 31 Issue 2
13 Article(s)

Wenlin WU, Xiaobo LIAO, Junzhong LI, Jun ZHOU, and Jian ZHUANG
Industrial cameras cannot clearly observe targets in real time in overexposed lighting conditions with sudden changes in brightness. An adaptive exposure control method is proposed to address this problem. First, the weighted average gray value of an image of a preset reference area is calculated, and then, the exposure value is calculated for the image. Next, a parameter control optimization method based on an improved "S" curve is designed to optimize and adjust the internal parameters. Finally, the optimal level of clarity is obtained with reference to the preset position. Experimental results show that the proposed method takes approximately 0.08 s to complete the entire camera adjustment process. Compared with those of the automatic exposure algorithm implemented on the camera hardware and an adaptive exposure algorithm based on image histogram features under the same conditions, the average standard deviation of the Laplacian of the images produced by the proposed algorithm is 54.3% and 20.6% greater, respectively. Therefore, the proposed algorithm can effectively enhance the adaptability of the optimized cameras under conditions of sudden changes in brightness and can be implemented in various practical applications.
Jan. 25, 2023Vol. 31 Issue 2 226 (2023)
Jianhua YANG, Hao ZHANG, and Haiyang HUA
Building segmentation in remote sensing images is widely used in urban planning and military fields, and is a current focus of research in the remote sensing field. To solve the problems of large-scale changes between buildings, building occlusion, and similar building shadows and edges in remote sensing images, which result in low building segmentation accuracy, a convolutional neural network with parallel paths and strong attention mechanism was developed. The model was based on the idea of residual connections of a ResNet network, and used ResNet as the basic network to improve the network depth and convolution downsampling to obtain parallel paths to extract multi-scale features of buildings to reduce the influence of scale changes between buildings. A strong attention mechanism was then added to enhance the fusion effect of the multi-scale information and discrimination of different features, and suppress the influence of building occlusion and shadows. Finally, a pyramid space pooling module was added after the multi-scale fusion features to suppress the appearance of holes inside the building in the segmentation result and improve the segmentation accuracy. Experiments were conducted on the WHU and Massachusetts Buildings public datasets, and the segmentation results were quantitatively compared using four indicators, namely MIoU, recall, precision, and F1-score. In the Massachusetts Buildings dataset, MIoU reaches 72.84%, which is 1.46% higher than the MIoU obtained with ResUNet-a. Thus, the model effectively improved the segmentation accuracy of buildings in remote sensing images.
Jan. 25, 2023Vol. 31 Issue 2 234 (2023)
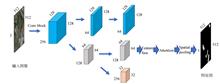
Xiang LI, Rigen TE, Feng YI, and Guocheng XU
As a critical strategic resource, crude oil plays a key role in many fields. In particular, it is important to the Chinese economy and military. In this study, we propose a target detection model called Transformer-CBAM-SIoU YOLO (TCS-YOLO) based on YOLOv5. The proposed model was implemented and trained to identify and classify oil storage tanks using the Jilin-1 dataset of optical remote sensing satellite images. The proposed model includes an additional C3TR layer based on the Transformer architecture to optimize the network, as well as a Convolutional Block Attention Module (CBAM) to add an attention mechanism to the network layers. Moreover, we adopt Scale-Sensitive Intersection over Union (SIoU) loss instead of Complete Intersection over Union (CIoU) as a positioning loss function. Experimental results showed that compared with YOLOv5, TCS-YOLO's model complexity (GFLOPs, Giga Floating Point of Operations) was reduced by an average of 3.13%. Furthermore, the number of parameters was reduced by an average of 0.88% and inference speed was reduced by an average of 0.2 ms, while mean average precision (mAP0.5) increased by 0.2% on average, and mAP0.5:0.95 increased by 1.26% on average. The proposed TCS-YOLO model was compared with the conventional YOLOv3, YOLOv4, YOLOv5, and Swin Transformer models, and TCS-YOLO exhibited more efficient characteristics. The TCS-YOLO model has universal feasibility for the target identification of global oil storage tanks. In combination with techniques to calculate the storage rates of identified oil tanks, this method can provide a technical reference for remote sensing data in the field of energy futures.
Jan. 25, 2023Vol. 31 Issue 2 246 (2023)
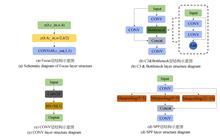
Yi GAO, and Miao HE
Gait recognition algorithms mainly rely on the contour sequence of pedestrian targets for feature extraction and recognition. In practical applications, pedestrians walk together, and the contour is easily occluded and interfered by other pedestrians, which significantly reduces the accuracy of gait recognition algorithm. To improve the robustness of gait recognition algorithm in dense occlusion scene, a deep-learning gait recognition algorithm based on unordered contour sequences is proposed. First, a simulation is conducted based on the Casia-B dataset, and the target contour simulation dataset for dense occlusion scene is established to verify the occlusion robustness of the algorithm. Second, a data augmentation method based on random binary expansion is proposed. However, owing to the limitations of horizontal pyramid pooling (HPP) structure in the area of gait recognition demonstrated through theory and experiment, a degenerated horizontal pyramid pooling (DHPP) structure is proposed. By combining the DHPP structure, CoordConv method, joint training, and pruning method, the perception ability of absolute position information in deep-learning features can be enhanced and the robustness of the algorithm for occlusion scene can be improved. In addition, the feature expression dimension of the target is reduced. The experimental results indicate that the proposed method is effective in improving the robustness of gait recognition algorithm.
Jan. 25, 2023Vol. 31 Issue 2 263 (2023)

Yanan GU, Ruyi CAO, Lishan ZHAO, Bibo LU, and Baishun SU
Recently, wire harnesses are widely used. The harness terminal, an important component of a harness, requires strict quality inspection. Therefore, to improve the accuracy and efficiency of harness terminal quality detection, a real-time semantic segmentation network using multiple receptive field (MRF) attention, called MRF-UNet, is proposed in this study. First, an MRF attention module is used as the basic module for network feature extraction, improving the feature extraction and generalization abilities of the model. Second, feature fusion is used to effect jump connections and reduce the computational load of the model. Finally, deconvolution and convolution are used for feature decoding to reduce the network depth and improve the algorithm's performance. The experimental results demonstrate that the mean intersection over union, mean pixel accuracy and dice coefficient of the MRF-UNet algorithm on the harness terminal test dataset are 97.54%, 98.83%, and 98.31%, respectively, and the reasoning speed of the model is 15 FPS. Compared with BiSeNet, UNet, SegNet, and other mainstream segmentation networks, the proposed MRF-UNet network exhibits more accurate and faster segmentation results for microscopic images of harness terminals, thus providing data support for the subsequent quality detection.
Jan. 25, 2023Vol. 31 Issue 2 277 (2023)
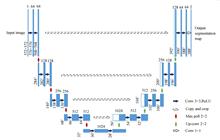
Kun ZHANG, Liting ZHANG, Xiaohong WANG, Yawei ZHUN, and Kunpeng ZHOU
Point cloud fine-grained semantic segmentation, that is, object component segmentation, has important applications in industrial production, such as manipulator control, intelligent assembly, and object detection. However, due to the scattered form of point cloud data, the geometric features at the boundary of object parts are not obvious and the calculation process is difficult, resulting in the low precision of fine-grained segmentation, which makes it difficult to meet the production needs. For point cloud segmentation at the component level, this paper proposes a fine-grained semantic segmentation network to enhance the local saliency of point clouds. In the network, the context information of local data is constructed to improve the precision of fine-grained segmentation. The network establishes an improved farthest-point sampling algorithm using geometric curvature to enhance the feature computing ability of a local data subset of the point cloud and to create a multiscale high-dimensional feature extractor for extracting the high-dimensional features of different scales. In the process of computing the point cloud features, seq2seq was used, the attention mechanism was introduced, and the high-dimensional features of different scales were fused to obtain the context information of fine-grained semantic segmentation. Finally, the fine-grained segmentation accuracy was improved, particularly for the segmentation effect at the boundary.The experimental results show that the overall intersection and merging ratio of this network on the ShapeNet part dataset achieves 85.2%, while the accuracy rate achieves 95.6%. The network also has a certain generalization ability. This method is of great significance in the fine-grained semantic segmentation of three-dimensional objects.
Jan. 25, 2023Vol. 31 Issue 2 288 (2023)

Wei WANG, Tiantian ZHAO, Qiang LIU, Bangcheng HAN, Pingjuan NIU, and Jian SANG
This paper expounds the current research and future development of Mass Transfer (MT) and Motion Positioning Platform (MPP) technology. On the basis of the chip transfer method, the MT scheme can be divided into precision pick-and-release, self-assembly, roller-transfer, and laser lift-off technology. The development process of the MT scheme is discussed based on the chip transfer efficiency and yield. On this basis, the structures and working principles of mechanical, air-supported, magnetic levitation, and hybrid configurations are introduced. Considering the aspects such as motion stroke and positioning accuracy, the advantages and disadvantages of MPPs are discussed. Finally, the development prospects of MT and MPP devices are predicted. Laser lift-off technology based on microporous liquid-gas bimodal media and hybrid-configuration MPP that combines mechanical and magnetic tracks with circumferential small-angle correction and axial micro-height-adjustment capabilities are expected to form the focus of the research on Mini/Micro LED chip-transfer technology.
Jan. 25, 2023Vol. 31 Issue 2 183 (2023)
Zhiyuan YU, Xiaoxia WU, and Fuguo WANG
To ensure that the six-hardpoint positioning system of a 4m silicon carbide (SiC) primary mirror has a sufficiently high natural frequency, the configuration parameters of a six-hardpoint positioning mechanism are optimized. First, dynamic and natural frequency equations of the six-hardpoint positioning system of the primary mirror are derived, and the functional relationship between the configuration parameters of the mechanism, axial stiffness of the hardpoint, mass and inertia of the primary mirror, and natural frequency of the system are established. Next, finite element analysis is used to determine the axial stiffness of the hardpoint used in positioning the mirror. Based on the natural frequency equation and with the goal of maximizing the first-order natural frequency of the mirror system, the configuration parameters of the six-hardpoint positioning mechanism are optimized using a genetic algorithm. Finally, a modal analysis of the mirror system under the optimal configuration is conducted. The axial stiffness of the hardpoint was 33.044 N/μm. Under the optimized configuration parameters, the first-order natural frequency of the 4m SiC primary mirror system reached 30.83 Hz, which is a significant improvement over the initial value. The optimization method can effectively improve the first-order natural frequency of the six-hardpoint positioning system of a primary mirror.
Jan. 25, 2023Vol. 31 Issue 2 200 (2023)
Tongqun REN, Haichuan JIANG, Jiankun ZHANG, Mengjie GUO, and Xiaodong WANG
The loss of system precision owing to machining and installation errors is common in the assembly of micro magnetic parts. To overcome this issue, an automatic calibration and error compensation method is proposed herein. The coordinate systems of different modules are established according to the equipment layout, and all the error parameters affecting the assembly accuracy are extracted. According to the positional relationship of the guide rails, a model for motion transformation between different modules is established, and an error compensation model is then derived to meet the assembly task. The machine vision system in the equipment is used to take measurements, and a special calibration board is designed. The error parameters are measured and identified by observing the coordinate changes in the feature points before and after motion. Furthermore, all parameters are globally optimized via particle swarm optimization. Based on the developed automatic calibration software, calibration and verification experiments are carried out in the assembly operation area. The experimental results show that the open-loop control accuracy of the system is within 6 μm after compensation, meeting the assembly accuracy requirements of the equipment. This method provides an automated, high-precision and high-efficiency calibration scheme for the assembly equipment of micro parts.
Jan. 25, 2023Vol. 31 Issue 2 214 (2023)
Xiaoqian NIU, Pengfei MIAO, Hanlin WANG, Xiaodong WANG, and Bo CHEN
In order to forecast and warn of space weather, the disturbances of solar-terrestrial need to be monitored. Extreme Ultraviolet (EUV) filters can remove unwanted radiation, and they are an important part of the Extreme Ultraviolet Imager. In order to optimize the transmission of EUV filters at 17.1nm, we chosen the material and thickness of EUV filters at 17.1 nm based on the Lambert-Beer law by theoretical calculation and software simulation. First, the release layer and metal thin-film were deposited by thermal evaporation, and EUV filters with nickel-mesh supported were successfully manufactured. After testing, the transmission of the filter whose surface is smooth and flat without obvious pinholes is about 43.81% at 17.1 nm. Next, in order to illustrate the effect of the oxide layer on the transmittance, the filter sample was measured by spectroscopic ellipsometry to obtain the thickness of the oxide layer at different placement times, and the roughness was measured to optimize and simulate the transmission of the filter. The thickness of the oxide layer and the roughness of the sample were fitted by IMD, and the layer thickness was adjusted to achieve the curve closest to the actual measured value. Experimental results indicate an excellent agreement between the measured and simulated values, and the absolute error of the transmittance of the EUV filter is only 1%. This study provides preparation methods and improvement ideas for EUV filters, and has important practical significance in space exploration.
Jan. 25, 2023Vol. 31 Issue 2 141 (2023)
Jun WU, Fengcheng SONG, Zhixiang PAN, Chenping ZHANG, Runxia GUO, and Xiaoyu ZHANG
The temperature field is a common condition-monitoring parameter that is widely used to monitor the condition of large industrial equipment. The schlieren method is an effective flow-field visualization method to measure the spatial temperature field. The traditional schlieren method rebuilds the spatial refractive index field by directly measuring the light deflection angle and then calculating the temperature field. However, the light deflection angle is generally very small, and direct measurements produce large measurement errors. A method that uses interference fringes to amplify the light deflection angle is proposed, effectively improving the measurement accuracy of the schlieren technique. First, interference fringes were formed using a measuring laser that passes through a double slit to replace the random speckle pattern of the traditional schlieren method. When the fringe generated by interference fringes crosses the nonuniform temperature space, the fringe offset was measured by visual measurement, and the light deflection angle was calculated based on the offset. Next, the distribution of the spatial refractive index field was calculated using the Abel inverse transformation method to obtain the spatial temperature field. Finally, the effectiveness and measurement accuracy of the proposed method were verified experimentally using simulation. The experimental results showed that the temperature field reconstruction error induced in our method decreased by approximately 30% compared with the error induced in the traditional schlieren method. The proposed interference fringe schlieren method effectively improves the accuracy of schlieren measurement and expands the application range of schlieren temperature measurement.
Jan. 25, 2023Vol. 31 Issue 2 150 (2023)
Tianliang LI, Zhenzhen SONG, Fayin CHEN, Yifei SU, and Yuegang TAN
Surgical robots can avoid damage to important tissues through preoperative path planning before surgery. As they have high operational accuracy, they are widely used in needle biopsy operations. However, surgical robots cannot currently achieve accurate and real-time acquisition of puncture needle shape information. This problem makes it difficult for them to autonomously avoid obstacles and prevents the needle from precisely reaching its target in order to carry the puncture procedure out. Therefore, studying a shape perception method for needles to provide shape information feedback for autonomous/master-slave punctures by surgical robots, is important for improving the safety and accuracy of puncture surgery. Therefore, a shape self-sensing puncture needle that integrates distributed optical fiber sensing technology and artificial intelligence was developed in this study. A neural network model algorithm was trained using training data comprising the center wavelength data and shape data of the fiber Bragg grating under different bending states, both of which were obtained from a static calibration experiment. Then, the model was used to realize the three-dimensional shape reconstruction of the puncture needle. Experimental results indicate that the maximum error of the needle shape reconstruction is 0.90 mm, and that the maximum error of the bending directional angle is 5.03°. As regards the dynamic experiment, the maximum error of the shape reconstruction is 0.84 mm, and the maximum error of the bending directional angle is 1.02°; the reliability of the model is thus validated. Thus, the proposed shape self-sensing puncture needle can accurately realize real-time acquisition of the shape, and it has broad application prospects in needle shape perception and regulation during autonomous puncture and master-slave operations by surgical robots.
Jan. 25, 2023Vol. 31 Issue 2 160 (2023)
Xu LIU, Bo LIU, and Yunjiang RAO
Distributed optical fiber sensors based on optical time domain reflectometry (OTDR) perform characterization through spatially resolved measurements along a single continuous strand of optical fiber, which has major advantages on the technology and application costs compared with conventional point-type sensors. The conventional OTDR based on analog detection suffers performance limitations on the important parameters of spatial resolution and dynamic range of the system. In contrast, photon-counting OTDR by single photon detection can overcome these performance limitations through digital detection and recoding. This review focuses on the technologies employed and developments in photon-counting OTDR, aims to clarify the advantages and limitations of photon-counting OTDR, explores the future development trends, and promotes the further development of distributed optical fiber sensors based on OTDR.
Jan. 25, 2023Vol. 31 Issue 2 168 (2023)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20