




 View fulltext
View fulltext

2023
Volume: 50 Issue 1
7 Article(s)

Yunyao Li, Jinyu Fan, Tianliang Jiang, Ning Tang, and Guohua Shi
The significance of OCT imaging in ophthalmic surgery has been proved in experiments on animal eyes, human eye models, and clinical cases. In recent years, commercial OCT surgical navigation equipment has already been widely used in ophthalmic clinical surgery. With the progress of image processing technology, image and ophthalmology, OCT surgical navigation equipment will further promote the innovation of ophthalmic surgery, and thus promote the development of the ophthalmology field.During ophthalmic microsurgery, the visualization of internal structures is limited by traditional intraoperative imaging methods due to their lack of depth information. Optical coherence tomography (OCT) is a non-contact tomographic imaging technique that is widely used for intraoperative navigation in ophthalmic surgery because of its ability to provide depth information, non-invasiveness, fast imaging, and high resolution. Typical OCT devices can be divided into handheld OCT and microscope-integrated OCT. This article briefly introduces the mechanism and development of time domain OCT and fourier domain OCT, reviews the development of OCT ophthalmic surgical navigation devices, introduces representative OCT systems in each category, describes and compares their imaging principles, performance, advantages, and disadvantages, and finally concludes with a summary and outlook on the applications of this technology in ophthalmic surgery.
Jan. 25, 2023Vol. 50 Issue 1 220027 (2023)
Jia Lv, Zeyu Wang, and Haocheng Liang
Overview: The state of retinal blood vessels is an important indicator for clinicians in the auxiliary diagnosis of eye diseases and systemic diseases. In particular, the degree of atrophy and pathological conditions of retinal blood vessels are the key indicators for judging the severity of the diseases. Automatic segmentation of retinal blood vessels is an indispensable step to obtain the key information. Good segmentation results are conducive to accurate diagnosis of the eye diseases. Due to the good characteristic of U-Net that can use skip connection to connect multi-scale feature maps, it performs well in segmentation tasks with small data volume, therefore, it could be applied to retinal vascular segmentation. However, U-Net ignores the features of retinal blood vessels in the training process, resulting in the inability to fully extract the feature information of blood vessels, while its segmentation results show that the vessel pixels are missing or the background noise is incorrectly segmented into blood vessels. Researchers have made various improvements on U-Net for the retinal vessel segmentation task, but the methods still ignore the global structure information and boundary information of retinal vessels. To solve the above problems, a boundary attention assisted dynamic graph convolution retinal vessel segmentation model based on U-Net is proposed in this paper, which supplements the model with more sufficient global structure information and blood vessel boundary information, and extracts more blood vessel feature information as much as possible. First, RGB image graying, contrast-limited adaptive histogram equalization, and gamma correction were used to preprocess the retinal images, which can improve the contrast between the vascular pixels and background, and even improve the brightness of some vascular areas. Then, rotation and slice were adopted to enhance the data. The processed images were input into the model to obtain the segmentation result. In the model, dynamic graph convolution was embedded into the decoder of U-Net to form multiscale structures to fuse the structural information of feature maps with different scales. The method not only can enhance the ability of dynamic graph convolution to obtain global structural information but also can reduce the interference degree of the noise and the segmenting incorrectly background on the vascular pixels. At the same time, in order to strengthen the diluted vascular boundary information in the process of up-down sampling, the boundary attention network was utilized to enhance the model’s attention to the boundary information for the sake of improving the segmentation performance. The presented model was tested on the retinal image datasets, DRIVE, CHASEDB1, and STARE. The experimental results show that the AUC of the algorithm on DRIVE, CHASEDB1 and STARE are 0.9851, 0.9856 and 0.9834, respectively. It is proved that the model is effective.Aiming at the problem of missing and disconnected capillary segmentation in the retinal vascular segmentation task, from the perspective of maximizing the use of retinal vascular feature information, by adding the global structure information and retinal blood vessels boundary information, based on the U-shaped network, a dynamic graph convolution for retinal vascular segmentation model assisted by boundary attention is proposed. The dynamic graph convolution is first embedded into the U-shaped network to form a multi-scale structure, which improves the ability of the model to obtain the global structural information, and thus improving the segmentation quality. Then, the boundary attention network is utilized to assist the model to increase the attention to the boundary information, and further improve the segmentation performance. The proposed algorithm is tested on three retinal image datasets, DRIVE, CHASEDB1, and STARE, and good segmentation results are obtained. The experimental results show that the model can better distinguish the noise and capillary, and segment retinal blood vessels with more complete structure, which has generalization and robustness.
Jan. 25, 2023Vol. 50 Issue 1 220116 (2023)

Intravascular ultrasound image segmentation combining polar coordinate modeling and a neural network
Jingyu Liu, Huaiyu Cai, Wenyue Hao, Tingtao Zuo, Zhongwei Jia, Yi Wang, and Xiaodong Chen
Overview: Intravascular ultrasound (IVUS) is an important imaging modality for diagnosing cardiovascular diseases. The annotation of major anatomical structures of blood vessels in IVUS images can provide necessary clinical parameters for lesion severity assessment, which is a necessary step for physicians' diagnosis. However, manual annotation is laborious and inefficient. With the development of deep learning, convolutional neural networks perform well in this task and are able to achieve automatic and accurate segmentation and recognition of the main anatomical structures of blood vessels. Existing IVUS image segmentation networks are mostly based on pixel-by-pixel prediction, which lacks overall constraints on the main structures of blood vessels and cannot guarantee that the topological relationships between main vessel structures conform to medical prior knowledge, which has a negative impact on the calculation of clinical parameters. To solve this problem, this paper proposes an IVUS image segmentation method based on polar coordinate modeling and a dense-distance regression network. First, a prior knowledge-based polar coordinate modeling is designed for encoding the two-dimensional mask of the main structure of blood vessels containing prior knowledge into a one-dimensional distance vector to avoid the topological relationship of the blood vessel structure from generating random changes in the network prediction. A dense-distance regression network consisting of a residual network and a semantic embedding branching module is then constructed for learning the mapping relationship between IVUS images and 1D distance vectors. To effectively constrain the learning direction of the network, a joint loss function is proposed. This loss function takes into account the actual spatial relationship between one-dimensional distance vectors and has a stronger supervisory capability. The network prediction results are finally reconstructed as a two-dimensional mask by spline curve fitting. The proposed method is validated on a 20 MHz IVUS image dataset. The experimental results show that the proposed method achieves 100% topology preservation in the media, lumen, and plaque regions and achieves the Jaccard measure (JM) of 0.89, 0.87, and 0.74, respectively. The advantage of the algorithm in this paper is that it can provide a high accuracy and topologically correct segmentation results of the vessel structures, which is suitable for general IVUS image segmentation. The clinical parameters provided are reliable and can be used as an important reference basis for physicians' diagnosis, reducing physicians' workload and improving diagnostic efficiency, which has a promising future in clinical applications.Aiming at the problem that existing intravascular ultrasound (IVUS) image segmentation networks cannot guarantee that the topological relationships between segmentation results conform to medical prior knowledge, which has a negative impact on clinical parameter calculation, an IVUS image segmentation method based on polar coordinate modeling and dense-distance regression network is proposed. This method converts two-dimensional (2D) masks to one-dimensional (1D) distance vectors to preserve the topology of the vessel structures through polar coordinate modeling with prior knowledge. Then a dense-distance regression network consisting of a residual network and semantic embedding branch is constructed for learning the mapping relationships between IVUS images and 1D distance vectors. A joint loss function is proposed to constrain the network learning direction. The prediction results are finally reconstructed as 2D masks by spline curve fitting. The experimental results show that the proposed method achieves 100% topology preservation in the media, lumen, and plaque regions, and achieves Jaccard measure (JM) of 0.89, 0.87, and 0.74, respectively. The algorithm is suitable for general IVUS image segmentation, with high accuracy, and can provide reliable clinical parameters.
Jan. 25, 2023Vol. 50 Issue 1 220118 (2023)

Xueyuan Wu, Xiaosong Du, Qingxia Liu, Huiling Tai, and Yang Wang
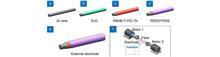
Overview: Organic photodetectors (OPDs) have advantages such as wide material sources, tunable spectrum, solution processing, and low manufacturing cost. They have numerous potential applications in domains of aviation, military, business, medicine, et al. Traditional organic photodetectors owe a planar structure and mostly use indium tin oxide (ITO), silver, aluminum, and other materials as electrodes. The organic photosensitive layer is sandwiched between two asymmetric electrodes to form a "sandwich" structure. However, the rigidity and brittleness of planar substrates constrain their application in flexible and wearable devices. As an inherently flexible and simple-to-weave material, fibers have been widely used in electronic textiles and wearable devices in recent years. For example, there has been substantial research on fibrous solar cells, supercapacitors, light-emitting devices, and physical/chemical sensors. In terms of fiber-based photodetectors. In 2014, Jixun Chen et al used a Ni wire as the core to prepare a NiO-ZnO heterojunction, and a twine Pt wire as the outer electrode to realize ultraviolet detection. In 2018, Xiaojie Xu et al. modified CuZnS: TiO2 array on the Ti wire surface, and wrapped a carbon nanotube fiber (CNT) on the outer layer to realize the collection and transmission of photogenerated carriers. However, most fiber-based photodetectors are based on inorganic photosensitive materials, showing the disadvantages of complicated manufacturing procedures, poor flexibility, and high cost. In this study, a fiber-based organic photodetector (FOPD) was prepared using organic photosensitive material. The electron transport layer (ZnO), organic heterojunction photosensitive layer (PBDB-T:ITICTh), and hole transport layer (PEDOT:PSS) were prepared on the surface of zinc wire by dip-coating method. Silver wire or carbon nanotube fiber (CNT) was wrapped as the external electrode, and two kinds of flexible FOPDs were obtained. Both the two devices showed a typical response in the visible band with remarkable rectification characteristics, and exhibited a specific detection rate of 1011 Jones (300 nm~760 nm) at ?0.5 V bias. Due to the better interface contact between CNT external electrode and photosensitive layer, the CNT-FOPD showed a lower dark current density (9.5×10?8 A cm?2, ?0.5 V) and faster response speed (rise and fall time: 0.88 ms and 6.00 ms). This work is expected to provide new ideas for the development of flexible fibrous devices and wearable electronics.Fiber-based photodetectors are expected to be widely used in the field of wearable electronics due to their properties of flexibility, easy-to-weave, and omnidirectional light detection. Currently reported fiber-based photodetectors mostly use inorganic photosensitive materials, which have drawbacks such as limited mechanical flexibility and complex preparation processes. In this paper, we proposed the fiber-based organic photodetector (FOPD). The electron transport layer (ZnO), organic heterojunction photosensitive layer (PBDB-T:ITIC-Th), and hole transport layer (PEDOT: PSS) were prepared on zinc wire by a solution dip-coating method layer by layer. Finally, silver wire or carbon nanotube fiber (CNT) was wrapped as the external electrode, and two kinds of flexible FOPDs were obtained and showed typical rectification characteristics. They showed a specific detection rate of 1011 Jones (300 nm~760 nm) at ?0.5 V bias. Due to the better interface contact between the CNT external electrode and photosensitive layer, the CNT-based device exhibited lower dark current density (9.5×10?8 A cm?2, ?0.5 V) and faster response speed (rise time of 0.88 ms and fall time of 6.00 ms). The work is expected to provide new ideas for the development of flexible fiber-based devices and wearable electronics.
Jan. 25, 2023Vol. 50 Issue 1 220151 (2023)
Pan Huang, Peng He, Xing Yang, Jiayang Luo, Hualiang Xiao, Sukun Tian, and Peng Feng
Overview: Breast cancer is the most common cancer among women. Tumor grading based on microscopic imaging is important for the diagnosis and prognosis of breast cancer, and the results need to be highly accurate and interpretable. Breast cancer tumor grading relies on pathologists to assess the morphological status of tissues and cells in the microscopic images of tissue sections, such as tissue differentiation, nuclear isotypes, and mitotic counts. A strong statistical correlation between the hematoxylin-Eosin (HE) stained microscopic imaging samples and the progesterone Receptor (ER) immunohistochemically (IHC) stained microscopic imaging samples has been documented, i.e., the ER status is strongly correlated with the tumor tissue grading. Therefore, it is a meaningful task to use deep learning models to research the breast tumor grading in ER IHC pathology images exploratively. At present, the CNN module integrating attention has a strong ability of induction bias but poor interpretability, while the Vision Transformer (ViT) block-based deep network has better interpretability but weaker ability of induction bias. In this paper, we propose an end-to-end deep network with adaptive model fusion by fusing ViT blocks and CNN blocks with integrated attention. Due to the negative fusion phenomenon of the existing model fusion methods, while it is impossible to guarantee that ViT blocks and CNN blocks with integrated attention have good feature representation capability at the same time; in addition, the high similarity and redundant information between the two feature representations lead to a poor model fusion capability. To this end, this paper proposes an adaptive model fusion method that includes multi-objective optimization, adaptive feature representation metric, and adaptive feature fusion, which effectively improves the fusion ability of the model. The accuracy of the model is 95.14%, which is 9.73% better than that of ViT-B/16 and 7.6% better than that of FABNet. The visualization of the model focuses more on the regions of nuclear heterogeneity (e.g., giant nuclei, polymorphic nuclei, multinuclei and dark nuclei), which is more consistent with the regions of interest to pathologists. Overall, the proposed model outperforms the current state-of-the-art model in terms of accuracy and interpretability.Tumor grading based on microscopic imaging is critical for the diagnosis and prognosis of breast cancer, which demands excellent accuracy and interpretability. Deep networks with CNN blocks combined with attention currently offer better induction bias capabilities but low interpretability. In comparison, the deep network based on ViT blocks has stronger interpretability but less induction bias capabilities. To that end, we present an end-to-end adaptive model fusion for deep networks that combine ViT and CNN blocks with integrated attention. However, the existing model fusion methods suffer from negative fusion. Because there is no guarantee that both the ViT blocks and the CNN blocks with integrated attention have acceptable feature representation capabilities, and secondly, the great similarity between the two feature representations results in a lot of redundant information, resulting in a poor model fusion capability. For that purpose, the adaptive model fusion approach suggested in this study consists of multi-objective optimization, an adaptive feature representation metric, and adaptive feature fusion, thereby significantly boosting the model's fusion capabilities. The accuracy of this model is 95.14%, which is 9.73% better than that of ViT-B/16, and 7.6% better than that of FABNet; secondly, the visualization map of our model is more focused on the regions of nuclear heterogeneity (e.g., mega nuclei, polymorphic nuclei, multi-nuclei, and dark nuclei), which is more consistent with the regions of interest to pathologists. Overall, the proposed model outperforms other state-of-the-art models in terms of accuracy and interpretability.
Jan. 25, 2023Vol. 50 Issue 1 220158 (2023)
Hao Peng, Wanqi Wang, Long Chen, Xianrong Peng, Jianlin Zhang, Zhiyong Xu, Yuxing Wei, and Meihui Li
Overview: The success of the deep detection model largely requires a large amount of data for training. Under the condition of fewer training samples, the model is easy to overfit and the detection effect is unsatisfactory. In view of the model that is easy to overfit and cause the target misdetection and missed detection in the absence of training samples, we present the Few-Shot Object Detection via the Online Inferential Calibration (FSOIC) framework by using the Faster R-CNN as detector. Through its excellent detection performance and powerful ability to distinguish the foreground and background, it effectively solves the problem that the single-stage detector cannot locate the target when the training samples are scarce. The bottom-layer features have a larger size and stronger location information, but the lack of global vision leads to weak semantic information, while the top-layer features are the opposite. To make full use of the sample information, the framework is designed to possess a new Attention-FPN network, which selectively the fuses features through modeling the dependencies between the feature channels, and directs the RPN module to extract the correct novel classes of the foreground objects by combined with the hierarchical freezing learning mechanism. The channel attention mechanism compresses the feature map and spreads it into a one-dimensional vector for sigmoid through two fully connected layers. The weight is generated for each feature channel, and the correlation between each channel is established. The weight of the input features is allocated according to the category, and the dependence relationship between each channel is modeled. Due to the closed nature of the neural network, simple feature fusion is uncertain, and it is difficult to fuse the feature map in a satisfactory direction. To the imbalanced sample features, the candidate targets of the new class are scored too low and filtered in the selection of the prediction box, resulting in false detection and missed detection of the detector. We designed the online calibration module that segmentes and encodes the samples, scored the re-weighted the multiple candidate objects, and corrected the misdetected and missed predicted objects. The performance of our detection algorithm performs better than most comparisons. The experimental results in the VOC Novel Set 1 show that the proposed method improves the average nAP50 of the five tasks by 10.16% and performs better than most comparisons.Considering that the model is easy to overfit and cause the target misdetection and missed detection under the condition of few samples, this paper propose the few-shot object detection via the online inferential calibration (FSOIC) based on the two-stage fine-tuning approach (TFA). In this framework, a novel Attention-FPN network is designed to selectively fuse the features by modeling the dependencies between the feature channels, and direct the RPN module to extract the correct novel classes of the foreground objects in combination with the hierarchical freezing learning mechanism. At the same time, the online calibration module is constructed to encode and segment the samples, reweight the scores of multiple candidate objects, and correct misclassifying and missing objects. The experimental results in the VOC Novel Set 1 show that the proposed method improves the average nAP50 of the five tasks by 10.16% and performs better than most comparisons.
Jan. 25, 2023Vol. 50 Issue 1 220180 (2023)

Liming Liang, Xin Dong, Renjie Li, and Anjun He
In IDRID dataset, the sensitivity and specificity were 95.65% and 91.17%, respectively, and the quadratic weighted agreement test coefficient was 90.38%. In the Kaggle competition dataset, the accuracy rate is 84.41%, and the area under the receiver operating characteristic curve was 90.36%. The experimental results show that the algorithm in this paper has certain application value in the field of DR. In view of the shortcomings of the above model, the next key task is to streamline the network model and further improve the model performance as much as possible.Diabetic Retinopathy (DR) is a prevalent acute stage of diabetes mellitus that causes vision-effecting abnormalities on the retina. In view of the difficulty in identifying the lesion area in retinal fundus images and the low grading efficiency, this paper proposes an algorithm based on multi-feature fusion of attention mechanism to diagnose and grade DR. Firstly, morphological preprocessing such as Gaussian filtering is applied to the input image to improve the feature contrast of the fundus image. Secondly, the ResNeSt50 residual network is used as the backbone of the model, and a multi-scale feature enhancement module is introduced to enhance the feature of the lesion area of ??the retinopathy image to improve the classification accuracy. Then, the graphic feature fusion module is used to fuse the enhanced local features of the main output. Finally, a weighted loss function combining center loss and focal loss is used to further improve the classification effect. In the Indian Diabetic Retinopathy (IDRID) dataset, the sensitivity and specificity were 95.65% and 91.17%, respectively, and the quadratic weighted agreement test coefficient was 90.38%. In the Kaggle competition dataset, the accuracy rate is 84.41%, and the area under the receiver operating characteristic curve was 90.36%. Simulation experiments show that the proposed algorithm has certain application value in the grading of diabetic retinopathy.
Jan. 25, 2023Vol. 50 Issue 1 220199 (2023)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20