









Please enter the answer below before you can view the full text.


2024
Volume: 61 Issue 22
44 Article(s)

Yue Ji, Yuhe Liu, Cui Guo, Jinyi Li, and Limei Song
In catastrophic environments such as fires, earthquakes, and explosions, images captured by drone cameras often become blurry because of strong vibrations. These vibrations severely affect the image quality and efficiency of emergency rescue operations. To address this issue, we propose an image deblurring method that uses unmanned aerial vehicle (UAV) inertial sensor data to construct the point spread function (PSF). The proposed method captures the motion information of an airborne camera using an inertial sensor and derives the PSF from this data, effectively overcoming the difficulties associated with traditional methods that consider complex textures, low contrast, or noise. The estimated PSF is combined with the total variation regularization technique to restore the images. By introducing the split Bregman iterative technique into the implemented algorithm, the complex optimization problem is effectively broken down into a series of simple sub-problems. This approach accelerates the calculation speed and yields high-precision image deblurring. Experimental and simulation results show that the proposed method effectively restores image blur caused by UAV vibrations, suppresses artifacts and ringing, and considerably improves the imaging quality of UAV cameras under vibration.
Nov. 25, 2024Vol. 61 Issue 22 2237001 (2024)
Shaiya Wang, Hongzhong Tang, Haifan Luo, Shang Gao, and Yuebing Xu
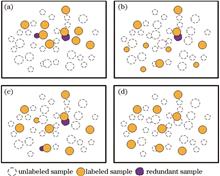
Object detection based on active learning typically utilizes limited labeled data to enhance detection model performance. This method allows learners to select valuable samples from a large pool of unlabeled data for manual labeling and to iteratively train and optimize the model. However, existing object detection methods that use active learning often struggle to effectively balance sample uncertainty and diversity, which results in high redundancy of query samples. To address this issue, we propose an adversarial active learning method guided by uncertainty for object detection. First, we introduce a loss prediction module to evaluate the uncertainty of unlabeled samples. This uncertainty guides the adversarial network training and helps construct a query sample set that includes both uncertainty and diversity. Second, we evaluate sample diversity based on feature similarity to reduce redundancy of query samples. Finally, experimental results on the MS COCO and Pascal VOC datasets using multiple detection frameworks demonstrate that the proposed method can effectively improve object detection accuracy with fewer annotations.
Nov. 25, 2024Vol. 61 Issue 22 2237002 (2024)
Zhe Su, Li Yang, Zai Luo, Wensong Jiang, and Hongmei Fang
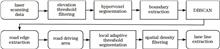
To effectively extract road information from different environments for intelligent vehicles, a road information extraction method based on hypervoxel segmentation is proposed. Road information is mainly divided into road edge and lane line information. First, the non-ground point cloud is filtered according to either the point cloud elevation information or installation location of scanning system. Second, the point cloud is over-segmented using the voxel adaptive hypervoxel segmentation method, allowing the separate segmentation of road edge features. Third, the boundary point extraction algorithm and driving path of scanning system are used to complete the extraction of road edges, subsequently dividing the driving area according to the road edge information. Finally, lane lines are extracted using local adaptive threshold segmentation and spatial density filtering. Experimental results show that the extraction accuracy of the road edge height and road width are 92.6% and 98.4%, deviation degree of lane line is less than 4%, and maximum deviation distance is no more than 0.04 m.
Nov. 25, 2024Vol. 61 Issue 22 2237003 (2024)
Tianjiao Du, Yongsheng Zhang, and Lidong Bao
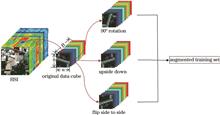
Hyperspectral image classification is a basic operation for understanding and applying hyperspectral images, and its accuracy is a key index for measuring the performance of the algorithm used. A novel two-branch residual network (DSSRN) is proposed that can extract robust features of hyperspectral images and is applicable to hyperspectral image classification for improving classification accuracy. First, the Laplace transform, principal component analysis (PCA), and data-amplification methods are used to preprocess hyperspectral image data, enhance image features, remove redundant information, and increase the number of samples. Subsequently, an attention mechanism and a two-branch residual network are used, where spectral and spatial residual networks are adopted in each branch to extract spectral and spatial information as well as to generate one-dimensional feature vectors. Finally, image-classification results are obtained using the fully connected layer. Experiments are conducted on remote-sensing datasets at the Indian Pine, University of Pavia, and Kennedy Space Center. Compared with the two-branch ACSS-GCN, the classification accuracy of proposed model shows 1.94、0.27、20.85 percentage points improvements on the three abovementioned datasets, respectively.
Nov. 25, 2024Vol. 61 Issue 22 2237004 (2024)
Yang Ou, Jianfeng Huang, and Rong Yuan
Underwater images are an important carrier of marine information. High-quality and clear underwater images are an important guarantee for a series of underwater operations such as marine resource exploration and marine safety monitoring. Underwater images will experience quality degradation due to factors such as selective absorption and scattering of light. In view of this, an underwater image enhancement network model based on deep multi-prior learning is proposed. First, four variants of underwater images are obtained under the prior guidance of the underwater optical imaging physical model, and a separate feature processing module containing five U-Net network structures is used to learn five private feature maps; then,the up-sampling feature maps from each U-Net structure are extracted, and through a joint feature processing module, a public feature map is learned; finally, the feature fusion module is used to uniformly represent the private feature map and the public feature map to generate an enhanced underwater image. Experimental results show that compared with various underwater image enhancement network models, the proposed model is more effective in enhancing underwater image quality. It has achieved excellent performance in multiple quality evaluation indicators.
Nov. 25, 2024Vol. 61 Issue 22 2237005 (2024)
Fenggang Han, Kan Chang, Shucheng Xia, and Xuxin Tai
When the light source is located on the back of the object, the captured image has a dark foreground and a bright background. This non-uniform light distribution significantly affects the overall visual quality of the image. As existing image enhancement methods have difficulty in effectively solving the non-uniform illumination problem of backlit images, this study proposes a backlight image enhancement network guided by an attention mechanism. First, a U-shaped network is used to construct an enhancement subnetwork (EM-Net), to achieve multiscale feature extraction and reconstruction. Second, a condition subnetwork (Cond-Net) is introduced to generate a backlight area attention map to guide the EM-Net to focus on the backlight area in the image. Then, using a dual-branch enhancement block (DEB), the brightness of the backlight area is fully enhanced while maintaining the contrast of the front-light area. In addition, a spatial feature transformation (SFT) layer is introduced in the backlight branch of the DEB, allowing EM-Net to focus on improving the visibility of the backlight area according to the guidance provided by the area attention map. Finally, to strengthen the correlation between the backlight and front-light areas during the enhancement process, a bilateral mutual attention module (BMAM) is proposed to further improve the reconstruction ability of the EM-Net. Experimental results show that the peak signal to noise ratio (PSNR) metric obtained by the proposed algorithm on the backlight data set (BAID) and non-uniform exposure local color distribution prior dataset (LCDP) exceeds that obtained by the latest backlight image enhancement contrastive language-image pretraining (CLIP)-LIT algorithm by 3.15 dB and 4.81 dB, respectively. Compared with other image enhancement algorithms based on deep learning, the proposed algorithm can effectively improve the visual quality of backlit images with higher computing efficiency.
Nov. 25, 2024Vol. 61 Issue 22 2237006 (2024)
Yang Zhang, Qian Shen, Hanwei Liu, Bo Song, and Peng Song
We propose a local stereo matching algorithm that integrates tree segmentation with side window technology to enhance disparity estimation accuracy at edge regions, which is a common issue in existing local stereo matching algorithms. Unlike the traditional fixed window aggregation strategy, the proposed algorithm utilizes a cost aggregation strategy based on side window technology. This approach adaptively selects the optimal side window for cost aggregation, substantially improving the disparity accuracy in edge regions. Moreover, tree segmentation technology is employed during the disparity refinement stage to propagate reliable pixel points through circular searches, thereby enhancing disparity accuracy across edges and complex textured areas. Experimental results from the Middlebury dataset demonstrate that proposed algorithm achieves high accuracy and efficiency in disparity calculation, particularly excelling in challenging areas such as image edges and complex textures.
Nov. 25, 2024Vol. 61 Issue 22 2237007 (2024)
Shule Yan, Runyu Chen, Nian Cai, Shaoqiu Xu, and Jian Chen
Infrared target detection is an important means of remote search and monitoring, and the accuracy of infrared tiny target detection determines the practical application value of this method. A detection framework based on a multi-hop deep network is proposed to improve the performance of tiny target detection in complex backgrounds. First, to deal with the"weak"and"small"shape characteristics of tiny targets, an anchor-free mechanism is used to build feature pyramids as the backbone for extracting feature maps. Then, to realize progressive feature interaction and adaptive feature fusion, a multi-hop fusion block composed of multi-scale dilation convolution groups is designed at the connection level. Finally, to reduce the sensitivity to position perturbations of tiny targets, the Wasserstein distance between the real and predicted targets is used as a similarity measure. The experimental results show that compared to existing methods, the proposed method delivers better detection performance in terms of accuracy and efficiency.
Nov. 25, 2024Vol. 61 Issue 22 2237008 (2024)
Qianqian Zhang, and Weihong Ma
To address the issue of image blurring when the object size exceeds the depth of the field for the imaging system, we propose an image enhancement method based on clear region screening. First, the imaging system employs step capture to obtain multiple images, each focusing on different clear areas of the same target. Second, a combination of bilateral filtering and edge extraction algorithms is employed to weaken low-definition regions of images while retaining strong edge features. The combination of strong edges and regions mitigates the misleading effects of blurred regions near edges. A high-resolution region screening algorithm based on image-variance features is then introduced to select clear images of non-edge regions and match them with strong region-edge maps to obtain the final target images. The experimental results show that, compared to conventional image-enhancement algorithms, the clear regions of the image obtained by the proposed method exhibit minimal change and the blurred regions are effectivly enhanced. Compared with the histogram equalization, adaptive filtering, and Retinex algorithms, the proposed algorithm increases the information entropy, signal-to-noise ratio, structural similarity, and sharpness by an average of 4.1%, 21.3%, 36.0%, and 9.53% , respectively, while decreases the standard error by 23.3% on average.
Nov. 25, 2024Vol. 61 Issue 22 2237009 (2024)
Wenli Zhang, and Wei Song
Fine-grained image classification aims to recognize subcategories within a given superclass accurately; however, it is faced with challenges of large intra-class differences, small inter-class differences, and limited training samples. Most current methods are improved based on Vision Transformer with the goal of enhancing classification performance. However, the following issues occur: ignoring the complementary information of classification tokens from different layers leads to incomplete global feature extraction, inconsistent performance of different heads in multi-head self-attention mechanism leads to inaccurate part localization, and limited training samples are prone to overfitting. In this study, a fine-grained image classification network based on feature fusion and ensemble learning is proposed to address the above issues. The network consists of three modules: the multi-level feature fusion module integrates complementary information to obtain more complete global features, the multi-expert part voting module votes for part tokens through ensemble learning to enhance the representation ability of part features, the attention-guided mixup augmentation module alleviates the overfitting issue and improves the classification accuracy. The classification accuracy on CUB-200-2011, Stanford Dogs, NABirds, and IP102 datasets is 91.92%, 93.10%, 90.98%, and 76.21%, respectively, with improvements of 1.42, 1.50, 1.08, and 2.81 percentage points, respectively, compared to the original Vision Transformer model, performing better than other compared fine-grained image classification methods.
Nov. 25, 2024Vol. 61 Issue 22 2237010 (2024)
Rui Zhou, Shuangjie Meng, Ming Li, and Shuang Qiu
To enhance the reliability of airport surveillance systems during heavy fog, this paper proposes a method to estimate atmospheric light values for airport images dehazing. First, the method estimates the atmospheric transmittance based on the dark channel prior (DCP) and applies a standard atmospheric scattering model to restore the initial dehazed image. Second, the clarity coefficient is introduced to provide feedback on the dehazed image. Based on this feedback, a rule is designed to iteratively update the atmospheric light value, adjusting it until the clarity coefficient peaks. Finally, guided by the updated atmospheric light value, the atmospheric scattering model reconstructs the optimal fog-free image. Experimental results demonstrate that, compared with traditional DCP method, the proposed method achieves more accurate atmospheric light values, resulting in more natural dehazing and outperforming existing objective evaluation indices for image dehazing
Nov. 25, 2024Vol. 61 Issue 22 2237011 (2024)
Yin Tu, Denghua Li, and Yong Ding
This paper proposes a SwinT-MFPN slope scene image classification model designed to balance performance, inference speed, and convergence speed, leveraging the Swin-Transformer and feature pyramid network (FPN). The proposed model overcomes the challenges associated with rapidly increasing computational complexity and slow convergence in high-resolution images. First, the Mish activation function is introduced into the FPN to construct an MFPN structure that extracts features from the original high-resolution image, producing a feature map with reduced dimensions while eliminating redundant low-level feature information to enhance key features. The Swin-Transformer, which is known for its robust deep-level feature extraction capabilities, is then employed as the model's backbone feature extraction network. The original cross-entropy loss function of the Swin-Transformer is replaced by a weighted cross-entropy loss function to mitigate the effects of imbalanced class data on model predictions. In addition, a root mean square error evaluation index for accuracy is proposed. The proposed model's stability is verified using a self-constructed dam slope dataset. Experimental results demonstrate that the proposed model achieves a mean average precision of 95.48%, with a 3.01% improvement in time performance compared to most mainstream models, emphasizing its applicability and effectiveness.
Nov. 25, 2024Vol. 61 Issue 22 2237012 (2024)
Jiachen Kang, and Shaowen Hao
This paper proposes an improvement method for addressing the low reconstructed-image quality and insufficient computational efficiency in three-dimensional hologram calculation for the random phase-mask-extension holographic-display viewing-angle method. The improvement includes two aspects: 1) Introducing the calculation of band-limited angular spectrum diffraction into the Gerchberg-Saxton (GS) phase-iteration process to enhance the reconstructed-phase hologram quality after expanding the viewing angle using an additional random phase mask and effectively suppressing speckle noise in hologram-reconstruction results using the time-averaging method; 2) optimizing the GS phase-iteration process by combining a lookup table design with a multi-compute unified device architecture (CUDA) stream parallel algorithm to significantly improve hologram-generation efficiency. Numerical-simulation results show that the introduction of band-limited angular spectrum diffraction into the GS algorithm combined with the time-averaging method yields higher imaging quality compared with the conventional GS algorithm combined with time-averaging method. Compared with the results of the conventional GS optimization, the proposed method reduces the speckle contrast from 0.41 to 0.2065, increases the peak signal-to-noise ratio (PSNR) from 10.6808 to 18.0546, and improves the structural similarity (SSIM) from 0.2778 to 0.7338 in the reconstructed results. Meanwhile, using the hierarchical hologram acceleration scheme designed in this study, the computation time for a single three-dimensional object hologram is reduced from 1410.53 s to 16.47 s, thus demonstrating the feasibility of the proposed method.
Nov. 25, 2024Vol. 61 Issue 22 2211001 (2024)
Siqi Liu, and Feihong Yu
The automatic exposure algorithm plays an important role in image acquisition and subsequent processing. A self-adaptive damping smooth automatic exposure algorithm for CMOS cameras is proposed to address the shortcomings of current smooth automatic exposure algorithms on mobile platforms. Calculate the average brightness of the region of interest in the image and compare it with the target brightness to determine whether to perform automatic exposure. Calculate new exposure time and simulation gain based on exposure strategy and exposure status. The new exposure time and analog gain are applied after adaptive damping smoothing to complete automatic exposure. The experimental results show that the proposed algorithm can accurately, quickly, and smoothly achieve automatic exposure control in various lighting environments.
Nov. 25, 2024Vol. 61 Issue 22 2211003 (2024)
Xiuhao Wu, Wendong Li, Ya Xiao, Hang Zhao, Jun Ma, and Xiaofeng Shi
To address the clarity degradation caused by scattering in underwater imaging, we propose a self-constructed Mach-Zehnder interference optical path to achieve image refocusing through a cloudy liquid using the transmission matrix method. We investigate the refocusing imaging effect using the intensity averaging method and Gerchberg-Saxton (GS) algorithm. Results indicate that the preset image can be clearly refocused through cloudy media using the four-step phase-shifting transmission matrix method. The cosine similarity ratio between the refocused and original images is determined to be 0.66 using intensity averaging, while this ratio is determined to be 0.91 using the GS algorithm. Combining the transmission matrix method with the GS algorithm effectively reduces the impact of scattering effects on image transmission. This approach has substantial application potential in oceanography, biomedical imaging, underwater communication, and other fields.
Nov. 25, 2024Vol. 61 Issue 22 2211004 (2024)
Yiming Ma, Xin Wang, XianKun Pu, Lei Shi, Han Han, Yao Zha, and Jun Gao
Polarization imaging technology, compared to conventional imaging technology, can enhance contrast and visibility, especially in eliminating reflections or scatter, while also revealing specific properties and details of object surfaces. Multi-view imaging allows capturing scenes from different angles, offering richer scene information and depth perception, thus enhancing the capability to capture image details. However, traditional multi-view object detection focuses solely on ordinary images, neglecting the polarization information contained within the scene. To address this issue, this study employs a self-developed multi-view polarization camera array system to identify and recover occluded targets within a scene. Initially, the system acquires multi-view polarization information of the scene, including data on pure occlusions, ground truth, and occluded scenes across different distances, obstructions, and objects. Subsequently, the acquired polarized images are preprocessed, and polarization images at 0°, 45°, 90°, and 135°are fed into the Polar-ReOccNet network for supervised training, with occluded scene data corresponding to ground truth. Ultimately, by inputting a set of multi-view polarized images, one can obtain the polarized images of the target after removing occlusions, and calculate its degree of polarization, angle of polarization, and a fused image of both degree and angle of polarization. This method achieves the reconstruction of polarization information for occluded targets, effectively retrieving the polarization information inherent in properties such as target texture and materials, thereby facilitating object detection.
Nov. 25, 2024Vol. 61 Issue 22 2211005 (2024)
Xudong Liu, Ying Lu, Huiqin Wang, Ke Wang, Zhan Wang, and Yuan Li
The types of surface diseases on city walls are complex and diverse, with uneven distribution. Spectral data has a low accuracy in identifying diseases with spatial similarity. Aiming at the problem that a single data cannot fully establish the classification and severity characteristics of complex surface diseases on city walls, a multi-data feature fusion method for ancient city wall disease detection is proposed. Independent feature extraction networks are constructed to extract spatial spectral features and texture color features from spectral and true color data sources, and batch normalization layers are introduced after each convolutional layer to accelerate network convergence. By using a feature fusion module to fuse multi-dimensional features of spectral data and color data, advanced feature learning is completed at the fully connected layer. The feature map is mapped to a nonlinear space through a linear rectification function, increasing the model's non-linear expression ability. Construct a joint loss function based on contrastive loss and classification loss to optimize the weights of fused data and improve the discrimination of diseases with similar spatial features. Finally, the Softmax layer is used for pixel by pixel classification to achieve quantitative evaluation and visual analysis of the damage situation of the ancient city wall. The experimental results show that the overall classification accuracy and Kappa coefficient of the proposed method are 96.46% and 94.20%, respectively. Compared with single spectral and true color data, the classification accuracy has been improved by 6.63 percentage points and 12.05 percentage points, respectively. The proposed method is of great significance for the identification of complex disease areas in city walls and the visualization of disease distribution.
Nov. 25, 2024Vol. 61 Issue 22 2212001 (2024)
Mingxing Gao, Zhengfa Jiang, Lin Zhang, and Haoyang Wang
Unmanned aerial vehicle intelligent inspection is a relatively advanced technology in road disease detection. A road crack detection method based on a dual pyramid network is proposed to meet the needs of both accuracy and real-time detection of road cracks under complex backgrounds and noise interference in drone aerial images. Using improved MobileNetv3~~small encoding features to lightweight the network. A stepped feature guidance method is designed for skip connections, combined with a mixed domain attention mechanism to form three different scale feature pyramid fusion networks, efficiently transmitting multi-scale contextual features. Finally, a parallel scale aware pyramid fusion module is designed deep in the network to transmit more detailed encoding features. In addition, the joint constraints of focal loss and dice loss are optimized through weight correction, improving the network's ability to handle imbalanced class data during training. The experimental results on a self-made dataset show that the F1 score and average intersection to union ratio of this double pyramid network reach 87.51% and 79.84%, respectively, which are 2.39 percentage points and 3.47 percentage points higher than CPFNet. The model parameter count is significantly reduced, and the performance and generalization of this method are verified on the CFD public dataset.
Nov. 25, 2024Vol. 61 Issue 22 2212002 (2024)
Bufan Zhang, Jinghu Yu, Xingfei Zhu, Zhaofei Sun, and Yu Lu
To resolve issues of insufficient detection accuracy, false detection, and missing detection in defect detection of coaxial packaged metal bases, this paper proposes an improved model called Metal-YOLO, which builds upon YOLO v5s. By introducing cross-layer feature enhancement connection(CFEC), the model ability to represent complex small object defects is substantially enhanced, effectively reducing the missing detection rate. To further improve the model ability to perceive and discriminate defect features across different scales, an adaptive attention module is integrated into the model, which effectively minimizes background information. Additionally, recognizing the shortcomings of the complete intersection over union (CIoU) loss function in the localization of defect object boxes, the effective intersection over union (EIoU) loss function is adopted. This change remarkably improves the precision of the prediction box positioning. Experimental results demonstrate that Metal-YOLO excels in metal surface defect detection tasks. Furthermore, the proposed model achieves a recall rate and mean average precision values of 74.1% and 78.3%, showing an improvement of 5.0 percentage points and 4.1 percentage points, respectively, compared to the baseline model YOLO v5s, substantially enhancing the effectiveness of metal surface defect detection.
Nov. 25, 2024Vol. 61 Issue 22 2212003 (2024)
Haojie Feng, Jinfang Shi, Rong Qiu, Qiang Zhou, Jianxin Wang, Decheng Guo, and Qing Wang
To enhance the accuracy of identifying and counting bulk damage points in crystals, this paper proposes an improved crystal damage detection (YOLOv8-OCD) algorithm. Initially, to address the nonuniform distribution of bulk damage points in crystals, a convolutional block attention module was introduced into the backbone network; therefore, the model focused on regions with dense bulk damage, improving feature extraction capabilities. Next, to handle the abundant small bulk damage points, a small target detection layer was designed to reduce the false-negative rate. Finally, considering the presence of low-quality instances in the dataset, a Wise-IoU loss function was used. Consequently, the model focused on instances with normal quality, enhancing the detection accuracy. Results demonstrated that compared with the baseline model, the improved model achieved an average precision of approximately 70%, which was an improvement of approximately 3 percentage points. Thus, the improved model balanced the detection accuracy and real-time performance. The effectiveness and advantages of this approach were verified through ablation experiments and comparisons.
Nov. 25, 2024Vol. 61 Issue 22 2212004 (2024)
Boya Yuan, Yao Li, and Qing Ye
A novel algorithm named GER-YOLO for insulator defect detection is proposed to address the issues of large algorithm parameters, complex image backgrounds, and significant insulator-scale changes in the unmanned-aerial-vehicle detection of insulator defects. First, GhostNetV2 is used to construct the C2fGhostV2 module, which significantly reduces the number of parameters and computation while maintaining the algorithm's detection accuracy. Second, an efficient multi-scale attention(EMA) network with cross-spatial-learning ability is introduced, which enables the complete mining of feature information and suppresses meaningless information. Finally, the C2fRFE module is proposed to capture long-range information, learn multiscale features, and improve the detection ability of insulators and their defects at different scales. Experimental results show that compared with the baseline model YOLOv8s, GER-YOLO offers a higher mean average precision (mAP) by 1.1%, reduces the parameter and computational costs by 30.2% and 31.0%, respectively, and can effectively detect insulator defects.
Nov. 25, 2024Vol. 61 Issue 22 2212005 (2024)
Haining Hu, Leiyang Huang, Honggang Yang, and Yunxia Chen
To solve the insufficient detection accuracy of the YOLO model and the numerous parameters required for detecting defects in cylindrical honeycomb ceramic images, a lightweight, cylindrical honeycomb ceramic defect-detection algorithm based on the improved YOLOv8n is proposed. To mitigate fuzzy boundary localization for crack defects, Shape-IoU is used to optimize bounding-box regression and improve the localization accuracy via weight coefficients and shape-loss terms. Meanwhile, to enhance the recognition ability of low-resolution small target cracks, an efficient multiscale attention (EMA) mechanism is introduced to enhance the network's capture and extraction of feature information. The algorithm integrates an improved SCConv module in the backbone to reduce parameter redundancy. Based on this, a space and channel feature fusion pyramid module is designed to achieve a lightweight network model. Compared with the original network, the improved network offers a higher average prediction accuracy by 2.9 percentage points, a lower parameter count by 84.1%, and an increase in the number of frames per second by 9 frames. Additionally, the proposed model is lighter and features a smaller computational load, which is more conducive to actual model deployment and embedded use.
Nov. 25, 2024Vol. 61 Issue 22 2212006 (2024)
Xunhao Tang, and Shaosheng Fan
Small-target images of transmission lines are prone to motion blur owing to factors such as air disturbance, rotor vibration, and relative motion during unmanned-aerial-vehicle inspections. This blurring leads to the loss of texture details, rendering small-target detection difficult. To address this problem, this study proposes a method for detecting small targets in transmission lines based on motion-blurred-image restoration. The proposed method utilizes a conditional vision Transformer-based generative adversarial network (ViT-GAN) to restore motion-blurred images of small targets, thereby enhancing the involved feature-extraction backbone's ability to perceive the global and regional information in images and improving the quality of image restoration for subsequent object detection. The involved YOLOv8 network is enhanced by introducing a multi-head self-attention mechanism, adding a small-target detection layer, and optimizing the boundary-frame-loss function. This helps to achieve good small-target detection in transmission line environments with complex backgrounds and large target-scale variations. Experimental results demonstrate that the proposed method can be used for accurate small-target detection for transmission lines. The average recognition accuracy of six categories of small targets is 92.77%, with an average recall rate of 94.19%, and average F1-score of 94.94%. Overall, the proposed method effectively mitigates the problem of missing and false detection, demonstrating its high accuracy and robustness.
Nov. 25, 2024Vol. 61 Issue 22 2212007 (2024)
Jishuai Liu, Xingdan Jia, Yue Ji, and Qiuhua Wan
To improve the reliability and accuracy of photoelectric angular displacement measuring device and enable proper decoding in the case of contamination, this paper investigates contamination detection and real-time correction methods for contamination-induced error codes in image-based angular displacement measurements. First, the principles of angular displacement measurement and the effects of contamination on this measurement are presented. Then, to detect the code disk contamination and correct the resulting error codes in real-time, the detection-correction-conjecture and area pixel scanning methods are proposed for the rough and precision code areas, respectively, in the course of correction, a new precise coding method is designed. Finally, the proposed contamination detection and real-time error code correction methods are experimentally validated. Results show that the proposed method can detect contamination and correct the resulting error codes in real time. This research is important for improving the reliability and accuracy of angular displacement measurements.
Nov. 25, 2024Vol. 61 Issue 22 2212008 (2024)
Senda Hong, Haojie Cheng, Chunxiao Xu, Zhenxin Chen, Jiajun Wang, and Lingxiao Zhao
To address the challenges of insufficient discrimination and low robustness of feature descriptors in complex scenes, an innovative local subdivision neighborhood feature statistics (LSNFS) descriptor is proposed. The core of LSNFS descriptors is a highly discriminative method called surface neighborhood deviation statistics (SNDS). SNDS comprehensively encodes local spatial information by introducing two types of spatial features. Statistically calculating the weighted neighborhood deviation angle in the subdivided space, combined with specific attribute partitioning strategies, significantly enhances the discriminative ability of descriptors. Linear interpolation and normalization are performed on the generated SNDS histogram to improve the robustness of descriptors to noise and point cloud resolution changes. The LSNFS descriptor encodes local geometric information by computing two angle features, and fuses the generated angle feature histogram with the SNDS histogram to achieve sufficient description of local information. A large number of experimental verifications are conducted on six datasets with different quality and interference types, and the results show that LSNFS performed significantly better than various advanced methods on all datasets, with high descriptive and strong robustness. In addition, applying LSNFS to 3D object registration and real scene registration, the results show that LSNFS not only achieves the best registration performance in 3D object registration, but also can generalize to large-scale real scene data, with good generalization performance.
Nov. 25, 2024Vol. 61 Issue 22 2215001 (2024)
Wang Zheng, Hongfei Yu, and Jin Lü
This paper proposes a external parameter calibration method for lidar and cameras based on line features. First, the image is coarsely segmented using the proportional-integral-derivative network, and the image line features are obtained through fine segmentation via image post-processing operation. Second, a clustering operation is performed on the point cloud data, and the clustered objects are filtered based on intensity, morphology, and other information to retain the line features in the lidar point cloud. Third, a matching consistency function is constructed to determine the degree of matching between the image and lidar line features. Finally, the external parameter between the lidar and the camera is obtained by maximizing the matching consistency function. Experiments on dataset collected by a real vehicle demonstrate that the proposed method has lower calibration errors compared to the benchmark method. Specifically, the proposed method reduces the average calibration error by 0.179° in rotation parameter and by 0.2 cm in translation parameter, meeting the average calibration accuracy requirements for real-world applications.
Nov. 25, 2024Vol. 61 Issue 22 2215002 (2024)
Yuan Zhang, Zepeng Shi, Min Pang, Fengguang Xiong, and Xiaowen Yang
A point-cloud registration method that integrates shape and texture features is proposed to address the issues of unsatisfactory registration performance and low accuracy in existing point-cloud registration algorithms when the geometric features of the point cloud are insignificant. First, keypoints with geometric and texture features change significantly on the surface of a point cloud are extracted, the shape and texture of the keypoints are characterized, and key-point matching is performed based on feature similarity. Subsequently, a random-sampling consensus algorithm is used to eliminate mismatched points and estimate the pose matrix, thus achieving coarse registration and providing favorable initial pose values for the subsequent fine registration. Finally, a color iterative closest point (ICP) registration algorithm is used for fine registration. Experimental results show that this algorithm offers high registration accuracy when used for color point-cloud models with clutter, low overlap rates, and insignificant shape features.
Nov. 25, 2024Vol. 61 Issue 22 2215003 (2024)
Han Gao, Ying Chen, Lizheng Ni, Xiuhan Deng, Kai Zhong, and Chengzhi Yan
To solve the problems of high misdetection rates and the low detection precision of far and small objects with current three-dimensional (3D) object detection algorithms, an improved 3D object detection algorithm based on PointRCNN is proposed. The improved algorithm adopts the spatial autocorrelation algorithm in the preprocessing stage to reduce the dimension of data, effectively removes irrelevant and noisy points, and optimizes the network's ability to extract features and identify key objects. This study also proposes a module called MGSA-PointNet to improve the point cloud encoding network of PointRCNN. The module takes advantage of the manifold self-attention mechanism to extract spatial information in the original point cloud more accurately. It incorporates the grouping self-attention mechanism to reduce the parameter counts in the self-attention weight coding layer while improving the efficiency and generalization ability of the model and enhancing the feature extraction ability of the network. Compared with PointRCNN on the KITTI dataset, the proposed algorithm enhances the accuracy of the 3D detection of cars and cyclists in complex scenes by 2.10 percentage points and 2.14 percentage points, respectively, and improves the average accuracy of 3D pedestrian detection by 5.21 percentage points, thus proving the effectiveness of the algorithm.
Nov. 25, 2024Vol. 61 Issue 22 2215004 (2024)
Yang Zhao, Jialong Miao, Xuefeng Liu, Jincheng Zhao, and Sen Xu
This study proposes a fatigue driving detection model based on image enhancement and facial state recognition to address the issues of low accuracy, large model size, and reduced performance in low-light environments found in existing models. The YOLOv5s model was enhanced for face detection and key point localization under low illumination, incorporating a self-calibrated illumination module to enhance low-illumination images. The downsampling layer was replaced with the StemBlock module to improve feature expression capability, and the backbone network was replaced with ShuffleNetv2 to reduce the model's parameters and computational complexity. Replacing the C3 module with the cbam inverted bottleneck C3 (CIBC3) reduced noise interference in detection and enhanced the model's global perception ability. Furthermore, the wing loss function was added to the total loss function for facial keypoint regression. A fatigue state recognition network was employed to determine the opening and closing statuses of the eyes and mouth located by the face detection model, and evaluation indicators were used to determine the fatigue state. The experimental results obtained on the DARK FACE dataset demonstrate that, compared to the benchmark YOLOv5s model, the improved model reduced parameters and computational complexity by 62.12% and 63.41%, respectively, and improved accuracy by 2.38 percentage points. The proposed fatigue driving detection model achieved accuracies of 96.07% and 94.50% on the YawDD normal lighting and self-built low-lighting datasets, respectively, outperforming other models. The processing time per image was only 27 ms, demonstrating that the proposed model not only ensures detection accuracy in normal and low-light environments but also meets real-time requirements, making it suitable for deployment on edge computing equipment with limited computing power.
Nov. 25, 2024Vol. 61 Issue 22 2215005 (2024)
Tianren Zhao, Qing Zhang, Pengfei Li, and Yaze Wang
In layered construction of offshore oil and gas modules, smooth docking and installation of steel structures on each layer are difficult due to manufacturing errors. This study proposes a method for detecting docking errors based on point clouds. This involves first registering the actual scanned point clouds of adjacent steel structures with their corresponding building information modeling models, and then calculating the alignment errors through feature extraction. This automated approach enables the docking feasibility to be evaluated prior to actual installation, thereby providing references for timely structural adjustments and reducing the possibility of rework. Compared with the traditional manual quality inspection method, our approach can effectively enhance detection efficiency and accuracy. We conducted experiments using two sets of simulated data to validate the accuracy of the proposed method. In addition, considering the characteristics of docking structures, we introduced a coarse registration algorithm based on five-plane sets. Experimental results demonstrate that the proposed coarse registration algorithm significantly enhances alignment accuracy as compared with four other methods.
Nov. 25, 2024Vol. 61 Issue 22 2215006 (2024)
Yue Wang, and Jiale Cao
This paper proposes a task feature decoupling-based autonomous driving visual joint perception (TFDJP) model to address the issues of internal competition and rough edge segmentation in detection tasks. These issues arise because existing autonomous driving visual joint perception algorithms that use coupled decoding networks do not consider the different feature requirements of each subtask. For object detection and decoding, we designed a hierarchical semantic enhancement module and a spatial information refinement module. These modules aggregate features of different semantic levels, separate and encode the gradient flow of classification and localization subtasks, reduce internal conflicts between subtasks, and add an intersection-over-union ratio perception prediction branch to the localization part for strengthening the correlation between subtasks and improving localization accuracy. For drivable area segmentation and lane detection decoding, we constructed a dual-resolution decoupling branch network to model the separation of low-frequency main area and high-frequency boundary pixels of the target. Boundary loss is used to guide the target to complete training and learning from local to global, gradually optimizing the target's main body and edges, thereby improving overall performance. Experimental results on the BDD100K dataset show that, compared to YOLOP, the proposed TFDJP model has an average target detection accuracy improvement of 2.7 percentage points, an average intersection-to-intersection ratio improvement of 1.3 percentage points for drivable area segmentation, and an accuracy improvement of 10.6 percentage points for lane detection. Compared to other multitasking models, the proposed TFDJP model effectively balances accuracy and real-time performance.
Nov. 25, 2024Vol. 61 Issue 22 2215007 (2024)
Jiaxin Dong, Ting Luo, Gen Li, Xing Zhao, and Yunsong Zhao
Addressing the challenges of missed and false detections of prohibited items in X-ray security imaging, this study introduces an enhanced model, termed YOLOv8s-BiOG. This model builds upon the foundational YOLOv8s framework by incorporating dynamic convolution module, weighted bidirectional feature pyramid network (BiFPN), and global attention mechanism. The dynamic convolution modules replace select convolutional components in both the backbone and neck networks, facilitating refined local feature analysis of prohibited items and bolstering feature extraction capabilities. Subsequently, the BiFPN enhances the model's feature fusion network, optimizing its proficiency in managing feature integration across various scales. The adoption of a global attention mechanism aims to mitigate feature loss and amplify the model's performance in detecting prohibited items. Experimental evaluations conducted on the SI2Pxray and OPIXray datasets demonstrate notable improvements in detection accuracy for a range of prohibited items.
Nov. 25, 2024Vol. 61 Issue 22 2215008 (2024)
Heng Wang, Peng Xu, Haitao Lin, Yonglong Li, Jialong Li, Hailan Chen, and Tao Wang
To address the issue of low point-cloud reconstruction accuracy due to poor visibility and light refraction, a laser reconstruction method for underwater targets based on epipolar constraint is proposed. The proposed method uses point correspondence to obtain an affine transformation matrix, which facilitates the affine transformation of underwater images to land images, thereby mitigates the effects of light refraction and enhancing the reconstruction accuracy. The application of the epipolar constraint principle promotes laser feature point extraction and completes point cloud coloring, further increases the reconstruction accuracy. Comparative experimental results indicate that the average measurement error of the proposed method is 0.459 mm, outperforming the existing three-dimensional (3D) reconstruction methods. The proposed method achieves improvements in the accuracy of underwater target reconstruction and the visibility of 3D point clouds.
Nov. 25, 2024Vol. 61 Issue 22 2215009 (2024)
Zhenzhen Wan, Haocheng Li, Ning Shi, Yuwei Liu, and Fang Liu
Tumor calcification refers to the phenomenon of calcium salt deposition in tumor tissues. In pathological sections, the analysis of the proportion of calcified areas is of great significance for the benign and malignant classification of tumors, monitoring of disease progression, tracking of treatment effects, and precision medicine such as surgery and radiotherapy. Compared with traditional pathological sections, fully digital pathological sections have advantages such as high-quality image preservation, remote access and sharing, and multidimensional data analysis. The integration of artificial intelligence algorithms for automated image segmentation, feature extraction, and data computation makes pathological assessment more efficient and accurate. The areas of tumor calcification areas in pathological sections are diverse and distributed discretely. Doctors typically need to manually estimate the proportion of calcified areas, which is time-consuming and imprecise. To address this issue, this study investigated an intelligent assessment system for tumor calcification areas based on fully digital pathological sections. The system utilizes the ECR-UNet network that integrates the attention modules to achieve precise segmentation of calcification areas. Edge detection technology is employed to segment the outer sections of pathological sections. The areas of both regions are then calculated separately to determine the proportion of calcified areas. The improved network demonstrates good segmentation performance on the test set, with the Dice coefficient, accuracy, and precision reaching 89.13%, 98.94%, and 90.81%, respectively. A comparison with the gold standard set by doctors for segmented calcified areas, outer contour areas, and the proportion of calcified areas on pathological sections reveals average accuracies of 92.25%, 99.05%, and 91.76%, respectively. This method provides an effective tool for the intelligent assessment of tumor calcification areas, assisting pathologists in tumor calcification diagnosis.
Nov. 25, 2024Vol. 61 Issue 22 2217001 (2024)
Leiying Zhai, Shengwei Nie, Jingchang Nan, and Yijie Wang
Light detection and ranging (LiDAR) with micro-electro mechanism system (MEMS) micromirrors at the core has the advantages of high resolution, miniaturization, and low price. However, problems still exist, including a small scanning angle and difficult construction of panoramic systems. Therefore, a novel on-chip all-silicon integrated 360° laser radar beam-mixing system is proposed in this study. A flexible beam was designed on top of the conical mirror to form a multidimensional torsion center. A combined traction mechanism of in-plane torsion and two-dimensional scanning driven by a MEMS comb driver was designed at the bottom of the conical mirror. A 360° annular space dynamic beam-mixing system was constructed with the top of the conical mirror as the rotation center and the bottom traction mechanism as the driving force. The kinematic characteristics of the beam-mixing system were analyzed by Coventor finite element software. Results show that under the driving voltage of 50 V, a single quadrangular mirror can obtain in-plane and out-of-plane twist angles of ±29.32° and ±1.8°, respectively, and form circular scanning and longitudinal fields of view covering 360° and 3.6°, respectively. The designed system solves the problem of the small field of view of MEMS LiDAR and realizes panoramic image acquisition. This research has provided a theoretical model of panoramic LiDAR for automatic driving.
Nov. 25, 2024Vol. 61 Issue 22 2222001 (2024)
Mingqiu Yang, Xiaoqing Zuo, and Yan Dong
In response to the problems of low detection accuracy, missed detections, large model size unsuitable for deployment, and low real-time performance of existing algorithms in synthetic aperture radar (SAR) image ship target detection tasks, an improved ship target detection model based on YOLOv8s is proposed for lightweight SAR images. First, a lightweight residual feature enhancement module ACC, which uses adaptive pooling, is proposed to extract different contextual information. The residual enhancement method reduces the loss of feature information at the highest level in the feature pyramid, improves the expression of high-level features, and enhances the network's ability to detect small targets. Subsequently, lightweight dynamic snake-shaped convolution (DSConv) is introduced to replace the standard convolution operation, thereby improving detection performance of the model for small-strip ship targets and reducing missed target detection. Finally, the lightweight BiFormer dynamic sparse attention module is integrated to further optimize the small target detection effect. On the SAR ship detection dataset (SSDD), the algorithm proposed in this paper outperforms the original algorithm in precision, recall, and mAP@0.5, by 5.0, 3.6, and 3.3 percentage points, respectively, and model detection ability for ship targets in SAR images is significantly enhanced. The generalized experimental results of the model on the high-resolution SAR images dataset (HRSID) show better performance than those of other classical algorithms.
Nov. 25, 2024Vol. 61 Issue 22 2228001 (2024)
Haiyu Wang, Xiao Liu, Lili Du, Xiaobing Sun, and Zhiyuan Zhou
Traditional modulation transfer function (MTF) detection method not only relies on artificial targets or typical ground targets, but also suffers from large atmospheric interference and a long detection cycle. Based on the traditional method, an on-orbit MTF detection method based on airport targets is proposed to analyze the characteristics of atmospheric interference in the detection process and to provide the MTF compensation method. The feasibility of rapid on-orbit MTF detection is explored by using large and medium-sized airports distributed in many places around the world as detection targets. Furthermore, a validation test of rapid on-orbit MTF detection is conducted using a total of 12 data sets from nine airports around the world. For example, an average deviation of 0.017 is used from the official MTF detection result in the 560 nm band. Under the condition of thin aerosol optical thickness, the feasibility of on-orbit detection of airport target MTF and validation of the rapid on-orbit detection method of MTF are conducted for four airports using Sentinel-2 multispectral images as test objects and compared with the official Sentinel-2 satellite MTF detection results. Specifically, the average absolute deviation of the two results is less than 0.04. Hence, the method can realize the high-frequency detection of MTF indices in a short period of time. This in turn eliminates the contingency of the results of a single detection and improves the reliability and stability of the detection results.
Nov. 25, 2024Vol. 61 Issue 22 2228002 (2024)
Feilong Wei, Shichun Li, Jiahui Liu, Yingchun Gao, Yuehui Song, Dengxin Hua, and Wenhui Xin
To address the challenges of overlap factor analysis and correction in noncoaxial lidar, we introduce a normalized overlap factor model analysis method. This approach simplifies the traditional five-dimensional geometric area overlap factor model into a four-dimensional structural parameter description. This simplification helps reduce the number of influencing factors and facilitates the identification of key features. The analysis examines the impact of four structural parameters (beam collimation coefficient, transceiver module radius ratio, transceiver module field-of-view ratio, and transceiver module spacing radius ratio) on the overlap factor. Notably, within a specific range of beam collimation coefficient variations, a distinct feature point emerges in the overlap factor curve at a certain detection distance. This feature point serves as a crucial alignment indicator for the biaxial adjustment of the lidar. The validity of our normalized model and its correction method is demonstrated through horizontal experimentation. Experimental results reveal that, compared to traditional methods, the normalized model achieves an average error of 0.016 for the overlap factor within the 0—1 km range. Furthermore, following overlap factor correction, the effective detection distance in the near-field is reduced from 510 m to 107 m. This normalized model offers valuable insights for assessing the parallelism accuracy of noncoaxial lidar adjustments, thereby advancing the practical implementation of automatic lidar product adjustment.
Nov. 25, 2024Vol. 61 Issue 22 2228003 (2024)
Jun Huang, Ying Guo, and Shu Yan
To solve the problems of low detection accuracy caused by small target size, drastic scale changes, target aggregation, and complex backgrounds in remote sensing image target detection tasks, an enhanced algorithm, DF-YOLOv7, based on YOLOv7, was put forward. This algorithm first enhances the information loss strategy caused by excessive downsampling in YOLOv7, improves the detection accuracy of small objects by modifying the layer structure, and lightens the network model. Secondly, the MRELAN module with multi-receptive fields is proposed to replace part of the ELAN to obtain a more robust multi-scale feature representation and to embed the efficient multi-scale attention mechanism, for cross-spatial learning to adapt to complex scenes. Finally, a contextual dynamic feature refinement module was presented, and the redundant features were filtered to highlight the feature differences of low-level small target information and improve the ability to express dense targets. Compared with YOLOv7, the accuracy of the improved algorithm is increased by 3.3 percentage points and 2.3 percentage points, respectively, and the number of parameters is reduced by 50.8%. Compared to YOLOv5s, it achieves 20.1 percentage points higher on VisDrone.
Nov. 25, 2024Vol. 61 Issue 22 2228004 (2024)
Ji Chen, Xin Ye, Yue Wu, Shining Zhu, and Tao Li
Lens arrays, composed of multiple lenses arranged in a specific configuration, are versatile optical components. In contrast to individual lenses, lens arrays have the capability to capture a greater amount of spatial light field information, thereby enabling functionalities such as high-speed motion detection, three-dimensional light field imaging, and parallel information processing. Recently, researchers have developed metalens arrays that preserve the capabilities of traditional microlens arrays while offering advantages such as flexible design and ultra-lightweight features. The unique attributes of metalens arrays endow them with notable prospects for application in the miniaturization, intelligence, and integration of optical devices and systems. This article describes the working principles of lens arrays, successful applications of metalens arrays in imaging and information technology, and presents a prospective outlook on the future development of metalens arrays.
Nov. 25, 2024Vol. 61 Issue 22 2200001 (2024)
Yuhang Wang, Xinyu Wang, Jinghui Zhang, Lujie Bu, and Tao Zhang
Underwater three-dimensional optical imaging can be used to image complex water bodies. Unlike traditional imaging, underwater three-dimensional optical imaging needs to overcome the scattering and absorption effects of water media to reconstruct targets. It has important application value in fields such as ocean engineering, resource exploration, and national defense construction. This article summarizes the research progress of underwater three-dimensional optical imaging technology at home and abroad, and introduces five underwater three-dimensional optical imaging modes in sequence, including underwater distance gating technology, underwater single photon detection technology, underwater structured light three-dimensional point cloud imaging technology, underwater stripe tube laser imaging technology, and underwater multi camera imaging technology. Based on the characteristics and limitations of detection distance, imaging characteristics, and reconstruction environment of various imaging technologies, we analyze and discuss the development trend of underwater three-dimensional optical imaging.
Nov. 25, 2024Vol. 61 Issue 22 2200003 (2024)
Dongdong Shi, Limin Liu, Fuyu Huang, and Xingzhong Wang
Infrared polarization imaging detection technology combines the advantages of infrared detection and polarization detection. This imaging detection technology enriches the information content of targets, greatly improves the recognition ability of target, and provides high-frequency, contrast, and other characteristic information that traditional optical detection cannot provide. It is widely used in military and civilian fields. This article summarizes the basic principles of infrared polarization imaging, analyzes four types of imaging systems and technical details, discusses the main application fields and achievements of infrared polarization imaging detection, and finally provides future development directions and feasible suggestions for infrared polarization imaging detection in response to existing shortcomings.
Nov. 25, 2024Vol. 61 Issue 22 2200004 (2024)
Jingjin Wang, Xin Liu, Zikang Jiang, Chunhui Niu, Xiaoying Li, and Yong Lü
Owing to the development of optoelectronic and digital technology, the optical imaging of surgical microscopes has resulted in continuous innovation and progress in imaging quality, increased functions, and expanded application fields; thus, the related operations have improved. Compared with binocular surgery microscopes, video microscopes can provide multi-user video sharing as well as high-definition and intelligent images of surgery; furthermore, they are more ergonomic, thereby reducing fatigue among doctors. Based on the existing video-based surgical microscope, this paper presents the development and research status of the current video-based surgical-microscope optical imaging. First, the development pertaining to the optical imaging technology of surgical microscopes is introduced. Subsequently, to present the research status of the optical imaging of video hand microscopes, we discuss continuous zoom technology, multimode fusion imaging technology, such as fluorescence, multispectral, polarization, and photoacoustic imaging, and the development of optical imaging, digitization, and intelligentization. Finally, the future development trends are discussed.
Nov. 25, 2024Vol. 61 Issue 22 2200005 (2024)
Yueyuan Zhang, Zhenping Xia, Qishuai Han, and Cheng Cheng
Recent concepts, such as the"metaverse"and"digital twins", indicate a greater necessity for higher perception quality from stereoscopic displays. This can be addressed by applying human factors engineering, which is an advancement in stereoscopic-display technology. Stereoscopic-display technology can be further developed by employing ergonomics to enhance the perception quality of stereoscopic displays. To optimize the perception quality of stereoscopic scenes, herein we propose a method to improve the dynamic range of stereoscopic scenes using the binocular fusion and binocular rivalry mechanisms in the human-eye visual system. This approach is based on the visual characteristics of human eyes when viewing stereoscopic scenes. Results of three progressive visual-perception tests confirm the feasibility of the approach. Stereo images subjected to the proposed method show improved visual-perception quality, and the statistical results show a significant increase in their dynamic ranges, all of which are within the dynamic range of good human-eye perception (0.35μ0.61). Additionally, the approach does not affect depth perception based on stereo images. This technique can offer a theoretical foundation for improving the quality of stereoscopic-scene perception.
Nov. 25, 2024Vol. 61 Issue 22 2233001 (2024)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20