







Please enter the answer below before you can view the full text.
8+6=
Multimodal image fusion involves the integration of information from different sensors to obtain complementary modal features. Infrared-visible image fusion is a popular topic in multimodal tasks. However, the existing methods face challenges in effectively integrating these different modal features and generating comprehensive feature representations. To address this issue, we propose a dual-branch feature-decomposition (DBDFuse) network. A dual-branch feature extraction structure is introduced, in which the Outlook Attention Transformer (OAT) block is used to extract high-frequency local features, whereas newly designed fold-and-unfold modules in the Stoken Transformer (ST) efficiently capture low-frequency global dependencies. The ST decomposes the original global attention into a product of sparse correlation maps and low-dimensional attention to capture low-frequency global features. Experimental results demonstrate that the DBDFuse network outperforms state-of-the-art (SOTA) methods for infrared-visible image fusion. The fused images exhibit higher clarity and detail retention in visual effects, while also enhancing the complementarity between modalities. In addition, the performance of infrared and visible light fusion images in downstream tasks has been improved, with mean average accuracy of 80.98% in the M3FD object detection task and mean intersection to union ratio of 63.9% in the LLVIP semantic segmentation task.
To address the challenges of restoring details in heavily occluded areas and enhancing network generalization capabilities in occluded polarized image reconstruction tasks, the research proposes a novel occluded image reconstruction model, PolarReconGAN, based on multiscale adversarial network. The proposed model integrates with polarization array imaging technology, aims to reconstruct the polarization information of occluded targets, thereby improving image quality and detail representation. We design a multiscale feature extraction module that employs a random window slicing method to prevent information loss due to image resizing, and utilizes data augmentation to enhance model generalization. Additionally, a loss function based on discrete wavelet transform is employed to further improve the reconstruction effects of image details. The experimental results demonstrate that the proposed method achieves an average structural similarity index (SSIM) of 0.7720 and an average peak signal-to-noise ratio (PSNR) of 25.2494 dB on a multi-view occluded polarization image dataset, indicating superior performance in occluded image reconstruction.
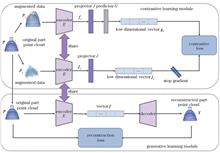
Unsupervised representation learning is a primary method for extracting distinguishable shape information from unlabeled point cloud data. Existing approaches capture global shape features of whole point clouds but often overlook local part-level details and are computationally expensive due to their reliance on whole point clouds and numerous negative samples. Inspired by the human visual mechanism of perceiving whole objects from local shapes, this study proposes an unsupervised part-level learning network, called reconstruction contrastive part (Rc-Part). First, a dataset of 40000 part point clouds is constructed by preprocessing public whole point cloud datasets. Then, Rc-Part employs contrastive learning without negative samples to capture distinguishable semantic information among parts and uses an encoder-decoder architecture to learn part structure information. Joint training with both contrastive and reconstruction tasks is then conducted. Finally, the encoder learned from the point cloud dataset is directly applied to whole-shape classification. Experiments on the PointNet backbone achieve high classification accuracies of 90.2% and 94.0% on the ModelNet40 and ModelNet10 datasets, respectively. Notably, despite containing 10000 fewer samples than the ShapeNet dataset, the part dataset achieves superior classification performance, demonstrating its effectiveness and the feasibility for neural networks to learn global point cloud data from components.