








Please enter the answer below before you can view the full text.
9+4=

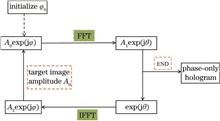
Phase-only holograms are used widely in holographic three-dimensional display owing to their high diffraction efficiency and no conjugate image. An iterative algorithm plays an important role in generating phase-only holograms because of its flexible calculation and high-quality image reconstruction. This study introduced a comparative study on the latest iterative algorithms for generating phase-only holograms. The basic principle of generating phase-only holograms by iterative algorithm was introduced, and representative and innovative algorithms were realized by programming. Experiments were performed to analyze the characteristics, advantages, and disadvantages of various methods by comparing the image reconstruction quality and computation time. The results show that the histogram compensation algorithm can obtain better results for images with large pixel differences, the adaptive weighted Gerchberg-Saxton algorithm can be used for images with high reconstruction quality.
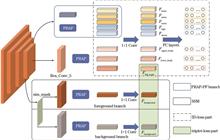
This paper proposes a part aligned multiscale fusion network, based on a human pose estimation algorithm and similarity matrix to address the misalignment problem of local features caused by complex person re-identification scenes and difficulty in extracting invariant person features in cluttered backgrounds. The proposed network introduces pose-estimation algorithms to construct aligned local features and integrates low-level local features and high-level global features through a multibranch structure. In addition, the feature similarity matrix divides the global features into the similarity-guided background and foreground branches and uses the regional-level triplet loss to extract person features robust to complex backgrounds. Extensive experiments are conducted for four datasets (Market-1501, DukeMTMC-ReID, CUHK03, and MSMT17). The proposed method achieves state-of-the-art performance. In particular, it improves the accuracy of first hit accuracy by 1.4 percentage points and mean average precision by 3.4 percentage points on the most challenging MSMT17 dataset.
Large-scale tomb murals are divided into several blocks by narrow passages. Hence, during high-definition collection, certain information around these blocks may be missing. To address this, a digital generation technology for tomb murals based on a multiscale cascade network is proposed, for reconstructing these lost data between mural blocks. In this approach, tomb murals were first generated on a large scale, and the reconstruction results were subsequently input into a deep semantic small-scale generation network to generate fine digital information. A self-attention mechanism was introduced into the small-scale generation network to enhance the correlation between the generation region and the global information and solve the artifact problem of the generation region boundaries. In terms of the feedback loss, the texture loss and the texture fineness of the reconstructed information are improved, and the mural generation effect is also improved. Jump connections were added to the generation network to accelerate the training process and enhance the efficiency of gradient backpropagation. Based on ablation and comparative group experiments, the proposed digital generation technology can improve the texture matching rate of mural block epitaxial information and reduce the influence of artifacts. This proposed method achieves good objective indexes for the peak signal-to-noise ratio and structural similarity.
Xinjiang-25 cm telescope is a small aperture sky survey telescope used to support geostationary earth orbit(GEO) target monitoring tasks. Space object monitoring must rely on fast optical image processing technology and astronomical positioning method to obtain the right ascension and declination measurement information of space objects. The Xinjiang-25 cm telescope has a large pointing error, which significantly affects the success rate of optical image processing. In this study, we analyze the impact of pointing error on star map recognition in astronomical positioning and propose an improved fast star map recognition method based on pointing search that can automatically adapt to the adverse impact of pointing error. This method was tested using the image of the 25-cm telescope at Nanshan station, Xinjiang, and the expected effect was achieved, proving its effectiveness and stability.
Small-target detection from images remains a challenge in the field of computer vision because of the limited size, small appearance and geometric clues, and lack of large-scale small-target datasets. To solve this issue, an adaptive feature-enhanced target detection network called YOLO-AFENet is proposed to improve the accuracy of small-target detection. First, by introducing the feature fusion factor, an improved adaptive bidirectional feature fusion module is designed using feature maps of various scales to improve the network's feature expression ability. Second, combined with the network characteristics, a spatial attention generation module is proposed to improve the network's feature localization ability by identifying the location information of the region of interest in the image. The experimental results of the UAVDT dataset show that YOLO-AFENet has a 6.3 percentage points higher average accuracy compared with YOLOv5 and is better than other target-detection networks.
A lightweight convolutional neural network, AGNet-improved GhostNet-50, is proposed for ship classification using self-made ship datasets while ensuring a desirable classification accuracy with a small model size. First, a Ghost module that integrates asymmetric convolution is proposed to improve the feature extraction capability of the AGNet convolution process. Next, combined with the bottleneck structure, an asymmetric Ghost bottleneck module is designed, further reducing the computational cost while maintaining the expression ability of the model. Finally, a 1×1 convolution layer in GhostNet-50 is removed to reduce the parameter redundancy of the overall model. The proposed method was compared from multiple aspects using evaluation indexes such as classification accuracy, parameters, and computational and inference speeds. Based on the experimental results, the accuracy of the AGNet model in the test set of 33 categories reaches 93.87%, and the number of model parameters is only 0.72×106. Compared with GhostNet-50, the AGNet model is compressed in terms of size by 46.67%, and the accuracy is improved by 2.93 percentage points. The experimental results show that AGNet can achieve better classification performance with a smaller model size and can be better applied to ship classification tasks.
It is difficult to highlight the features of facial expressions in the study of global faces, due to the unique subtleties and complexity of facial expressions. To improve the robustness of expression recognition in natural environments and optimize model parameters, this paper proposes a lightweight facial expression recognition method based on multiregion fusion, which integrates local details and global features to realize a combination of coarse and fine granularity, thus improving the model's efficacy in discriminating subtle changes in expressions. First, local features are extracted from the human face through a branch, which uses eyes and mouth as input. Second, the facial global features are adaptively acquired by another branch, and a mask is generated by key points to assist in adjusting the facial attention map. The facial attention map acts on the global features to highlight the weight of the unmasked parts and describes the overall high-level semantic information. A pruning algorithm is used to perform lightweight optimization for the overall model, using less memory and few computational operations to obtain a more compact network. The recognition accuracy of the proposed method on RAF-DB and AffectNet datasets is determined to be 85.39% and 58.81%, respectively. The experimental results show that the recognition accuracy of the proposed method is higher than other advanced methods and the proposed method significantly reduces the number of parameters, which proves the effectiveness and progressiveness.
A fast image matching method based on the improved accelerate-KAZE (AKAZE) algorithm is proposed to address the issues of low matching rate and weak robustness in UAV image matching. The proposed method first constructs the nonlinear scale space during the feature extraction stage using the AKAZE algorithm, and then efficiently describes the feature points using the fast retina keypoint (FREAK) descriptor. Later, the obtained feature points are prematched using the grid-based motion statistic (GMS) method to distinguish them with high robustness. The matching outcomes are then further screened using the basis of random sample consensus (RANSAC) algorithm. Experiments are conducted on an Oxford standard image dataset and an RSSCN7 remote sensing image dataset to verify the effectiveness of the proposed method. The proposed method is compared with the improved AKAZE, ORB, KAZE, and SIFT+FREAK algorithms. Continuous testing can guarantee that the proposed method can achieve fast image registration while maintaining high accuracy. It can maintain a high robustness under image illumination change, fuzzy transformation, and compression transformation and can meet the needs of UAV image real-time matching.
An improved ResNet-101 network model that fuses tensor synthesis attention (RTSA Net-101) is proposed to solve insufficient feature extraction and the indiscriminate contribution of the extracted features when processing image classification tasks using a convolutional neural network. First, the image features are extracted using a Resnet-101 backbone network and the tensor synthesis attention module is embedded after the convolution structure of the residual network. The features are calculated using a three-tensor product to obtain the attention feature matrix. Next, the Softmax function is used to normalize the attention feature matrix to assign weights to features and distinguish the contribution of features. Finally, the weighted sum of the weights and critical values are calculated as the final features in our proposed method to improve the image classification performance. Comparative experiments are conducted on natural image datasets, CIFAR-10 and CIFAR-100, and street brand dataset, SVHN. The classification accuracy values of the models are 96.12%, 81.60%, and 96.67%, respectively, and the average test running time of the images are 0.0258 s, 0.0260 s, and 0.0262 s, respectively. The experimental results show that compared with the other seven advanced image classification models, the RTSA Net-101 model can achieve higher classification accuracy and shorter test run time, and it can effectively enhance the feature learning ability of the network, thereby render the proposed model innovative and efficient.
A real-time detection algorithm F-YOLO for the feeding behavior of lightweight fish based on the fish swarm's texture, shape, and density characteristics is proposed to realize accurate feeding in fishery breeding based on the traditional detection algorithm. The initial backbone feature extraction network CSPDarkNet53 of the YOLOv4 algorithm is replaced by MobileNetV3, which significantly enhances the real-time detection performance of the network and the detection performance of small fish targets at the cost of a slight reduction in detection accuracy; channel pruning, and knowledge distillation are performed on the convolution layer of the network structure to compress the model and reduce the number of floating-point operations (FLOPs) and the amount of calculation; using optimized K-means clustering and DIoU loss function with global non-maximum suppression to determine the anchor frame, the problem of missing anchor frame caused by mutual occlusion of fish bodies are solved. The experimental results reveal that the model size of the suggested F-YOLO algorithm, the average recognition time of each image, the accuracy, the FLOPs, and detection speed in the embedded device are 13.7 MB, 50 ms, 99.13%, 1.64×1010, and 33 frame/s, respectively, which can provide theoretical guidance for the actual fishery breeding.
As a molecular imaging mode, X-ray fluorescence computed tomography (XFCT) has the problems of long scanning times and large radiation doses. In general, the scanning time and radiation dose of XFCT are reduced by increasing the projection interval and reducing the number of projections. Therefore, to improve the quality of reconstructed images with few projections and iterations, an XFCT reconstruction algorithm based on the L1/2-norm is proposed. The numerical simulation results show that compared with the traditional Maximum Likelihood Expectation Maximization algorithm, the proposed XFCT reconstruction algorithm has a smaller root mean square error and a global image quality index closer to 1 with fewer projections and iterations, achieving the goal of improving the quality of reconstructed images with few projections and iterations.
The problem of retinal blood vessel segmentation, such as limited labeled image data, complex blood vessel structure with different scales, and easy to be disturbed by the lesion area, is a concern for researchers. Thus, to address this problem, the study proposes a multiscale dense attention network for retinal blood vessel segmentation. First, based on U-Net architecture, the concurrent spatial and channel squeeze and channel excitation attention dense block (scSE-DB) is used to replace the traditional convolution layer, strengthening the feature propagation ability, and obtaining a dual calibration for feature information so that the model can better identify blood vessel pixels. Second, a cascade hole convolution module is embedded at the bottom of the network to capture multiscale vascular feature information and improve the network's ability to obtain deep semantic features. Finally, we performed the experiments on three datasets (DRIVE dataset, CHASE_DB1 dataset, and STARE dataset), and the results show that the accuracy of the proposed network is 96.50%, 96.62%, and 96.75%; the sensitivity is 84.17%, 83.34%, and 80.39%, and the specificity is 98.22%, 97.95%, and 98.67%, respectively. Generally, the results show that the segmentation performance of the proposed network outperforms that of other advanced algorithms.
Many complex elements such as poor light and high noise in the underwater environment result in low detection accuracy and high missed detection rate in traditional underwater target detection methods. To address these issues, based on the current general Faster R-CNN algorithm, this study proposes an underwater target detection algorithm based on automatic color level and bidirectional feature fusion. First, the automatic color level was used to enhance a blurred underwater image. Second, the path aggregation feature pyramid network (PAFPN) was introduced for feature fusion to enhance the expression for shallow information. Third, the soft non-maximum suppression (Soft-NMS) algorithm was introduced to modify and generate the candidate target regions before and after training. Finally, the FocalLoss function was used to rectify the issue of an unbalanced distribution of positive and negative samples. The experimental results show that the proposed algorithm can reach a detection accuracy of 59.7% on the URPC2020 dataset and a recall rate of 70.5%, which are 5.5 percentage points and 8.4 percentage points respectively higher than the current general Faster R-CNN algorithm, effectively improving the average accuracy of underwater target detection.
Pedestrian targets in subway scenes pose problems such as varying sizes, different degrees of occlusion, and blurred images caused by dark environments, which adversely affect the accuracy of pedestrian target detection. To address these problems, this study proposes an improved YOLOv5s target detection algorithm to improve the accuracy of pedestrian target detection in subway scene video signals. The pedestrian dataset of a subway scene is constructed, the corresponding labels are marked, and the data preprocessing operation is performed. Moreover, a deep residual shrinkage network is added to the feature extraction module, and the residual network, attention mechanism, and soft thresholding function are combined to enhance the useful feature channel and weaken the redundant feature channel. The fusion features of multiscale and multireceptive fields of the image are obtained using the improved atrous spatial pyramid pooling module without losing image information, and the global context information of the image is effectively captured. The improved non-maximum suppression algorithm is designed to postprocess the target prediction frame and retain the optimal prediction frame of the detection target. The experimental results demonstrate that the improved YOLOv5s algorithm proposed in this study can effectively improve the accuracy of pedestrian target detection in subway scene video signals, particularly for small and dense pedestrian target scenes.
To solve the problems of trajectory missed detection, misdetection, and identity switching in complex multitarget tracking, this paper proposes a multitarget tracking algorithm based on improved YOLOX and BYTE data association methods. First, to enhance YOLOX's target detection capabilities in complex environments, we combine the YOLOX backbone network and Vision Transformer to improve the network's local feature extraction capability and add the α-GIoU loss function to further improve the regression accuracy of the network bounding box. Second, to meet the real-time requirements of the algorithm, we employ the BYTE data association method, abandon the traditional feature rerecognition (Re-ID) network, and further improving the speed of the proposed multitarget tracking algorithm. Finally, to mitigate the tracking problems in complex environments, such as illumination and occlusion, we adopt the extended Kalman filter, which is more adaptive to the nonlinear system, to improve the prediction accuracy of the network for tracking trajectory in complex scenes. The experimental results show that the multiple object tracking accuracy (MOTA) and identity F1-measure (IDF1) of the proposed algorithm on the MOT17 dataset are 73.0% and 70.2%, respectively, compared with the current optimal algorithm ByteTrack, they are improved by 1.3 percentage points and 2.1 percentage points, respectively, whereas number of identity switches (IDSW) is reduced by 3.7%. Meanwhile, the proposed algorithm achieves a tracking speed of 51.2 frames/s, which meets the real-time requirements of the system.
A feature extraction network using global and local features is designed to tackle the issue of retrieving incomplete and fuzzy shoe prints. The global features of the multiscale shoe print are normalized and weighted, and the losses of all their outputs are calculated; moreover, the part-based Conv baseline (PCB) module is used to divide the shoe print feature map into three parts, extract the local features of the three parts, and calculate their losses. During the training phase, all of the global feature branch and local feature branch losses are added to express them collectively. The output of the two branches after splicing is directly flattened as the shoe print descriptor to be retrieved in the test phase, and the cosine distance between it and the descriptor of the sample library shoe print is used as the similarity score. The experimental results show that the proposed method significantly reduces the parameter quantity and calculation cost of the model, and achieves high accuracy on the three shoe print data sets of CSS-200, CS Database, and FID-300. Furthermore, it achieves decent accuracy on the top1% of the CSS-200 and CS Database (Dust) datasets, which are 94.5% and 95.45%, respectively.
Digital holography (DH) is critical for monitoring quantitative three-dimensional information of transparent samples. However, phase aberration compensation and unwrapping are needed in conventional digital holographic reconstruction, which adversely affect its speed and accuracy. We propose an improved residual Unet method that combines dilated convolution and attention mechanism to implement end-to-end phase reconstruction of DH, which simplifies the imaging process and improves the quality of image reconstruction. In addition, the proposed method can further optimize the network model for real-time reconstruction by adjusting residual blocks. The experimental results reveal that the proposed phase reconstruction method based on deep learning can obtain accurate three-dimensional information of samples in real time, which benefits real-time monitoring for dynamic samples.
The noise equivalent temperature difference (NETD) of infrared cameras is a crucial criterion for evaluating the imaging quality. The position and aperture of the blackbody source, target, and entrance pupil (the collimator and the camera to be measured as a whole) in an infrared camera NETD test device should meet the specific mathematical relationship, otherwise the test accuracy will be reduced. Therefore, based on geometrical optics theory and radiology, the spatial distribution of the blackbody source, target, and entrance pupil in the infrared camera testing system is deduced in this study. Additionally, the relationship between the measured temperature at the target hole and the blackbody source temperature at the rear is explored. A mathematical model has been established to guide the test of the infrared camera test system. Combined with a test system, the relative error is verified to be less than 7.4% when the spatial distribution of the test device meets the proposed model requirement; otherwise the test accuracy decreases rapidly. The temperature uniformity and stability at the target hole are analyzed when the target is used.
Adhesive tapes are common criminal tools used at crime scenes, and fingermarks and other physical evidence on tapes are crucial. However, the adhesive tapes found at crime scenes are usually overlapped, stuck to each other, or adhered to other objects; thus, the nondestructive extraction approach of fingermarks on the surface of the adhesive tapes has always been one of the most challenging problems in the field of forensic science. In this study, a new approach based on optical coherence tomography (OCT) is proposed to develop the latent fingermarks on the surface of the adhesive tapes and separate the overlapped fingermarks of many layers of adhesive tapes. A self-built OCT system in the frequency domain was used to detect the latent fingermarks hidden on the adhesive tape's surface under three conditions. Two-dimensional cross-section images, en face transversal images, and three-dimensional (3D) rendering images of fingermarks were obtained using the visual processing approach, which was used to examine their mechanisms. The results revealed that OCT technology could not only quickly and nondestructively develop latent fingermarks on the single-layer adhesive tape surface and separate the overlapped fingermarks on multi-layer adhesive tapes but also eliminate the interference of multi-color background patterns at the same time. The quality of the images was high and the details were clear; the distributed information of the third level characteristic, such as sweat pores, can be observed through 3D rendering as well. This offers a new technique and approach for developing fingermarks.
Speckle structured light has become a research hotspot in recent years owing to its ability to obtain three-dimensional (3D) information by projecting only one image. However, when using speckle structured light to obtain 3D information, problems such as low number of matching speckle feature points and high mismatching rate are encountered. Therefore, the speckle feature-point extraction and matching algorithm is herein studied. Based on the analysis of the gray-distribution rule of speckle region, a method for extracting speckle feature points based on gray-value comparison is proposed. By comparing the gray value of relevant pixels on the window, coarse extraction is performed, and the response function of the feature point is defined to eliminate redundant detection. In terms of matching, speckle feature-point descriptors are established, and a multi-constrained propagation matching method based on descriptor information is proposed. First, the seed points with high matching degree were obtained through multi-constrained conditions, and the seed points were generated into a queue. Next, the unmatched speckle feature points in the descriptor were propagation matched using the descriptor information of the seed points. Experimental results show that the proposed algorithm increases the number of matches by more than 35% and reduces the mismatching rate to 0.12% compared to other algorithms.
Biological speckle technology can non-destructively characterize the microbial activity and has gained significant attention in the field of agricultural product quality control. However, traditional speckle image processing methods do not readily distinguish various bioactive areas, and errors are generated in the quality assessment and classification process. A new image processing and analysis method based on wavelet energy spectrum is proposed to address this issue. First, the image is decomposed based on an orthogonal wavelet. Subsequently, the low-frequency components are extracted to establish an energy spectrum. Finally, the energy intensity distribution of the image is estimated, and the speckle activity is quantitatively analyzed. The results of collision experiments on the usual rock candy core apples in the market show that, compared with the traditional Fujii method, the weighted generalized difference method, the enhanced moment of inertia method, and the wavelet entropy method, the suggested approach can not only show the evolution law of apple biological activity with time; however, it also realize the distinction between the normal area and the collision area on the apple surface through the index with higher contrast and stability. The suggested approach is anticipated to be extensively employed in the field of fruit mechanical damage assessment since it is effective at identifying bruises in apple skin.
In this study, the size, position, optical characteristic, and structure reconstructions of foreign objects in tissue simulators are realized using the scanning technology of an equiangular fan beam, a chaotic laser as a laser source, and a chaotic crosscorrelation signal with delta-like function. Equiangular fan beam scanning systems consist of a collimated chaotic source and two photodetectors. The chaotic laser collimated by the optical collimator passes through the tissue simulator and is received by the photodetector. The time-domain information of the chaotic source at different angles is obtained through the synchronous rotation of the chaotic light source and the photodetector. In the tissue simulator, crosscorrelation operation is performed on the outgoing and reference signals, and the crosscorrelation peak value is extracted to obtain the attenuation information of light. The detection of foreign objects in the tissue simulator is accomplished by comparing the attenuation coefficients of the foreign objects and the simulator. According to the attenuation induced by the scattering and absorption of light in the phantom, the theoretical model of the crosscorrelation peak of chaotic signals as projection data is established, and the filtered back-projection algorithm is used to realize the image reconstruction. The results reveal that the chaotic laser-based scanning imaging method of equiangular fan beams has a high detection accuracy and can distinguish foreign objects with different attenuation coefficients.
The calculation of light intensity distribution for an imaging system based on special-shaped aperture diaphragm has a significant theoretical importance for developing imaging techniques such as the automatic focus and depth-of-field expansion of microscopic systems. The traditional Fresnel diffractive light intensity distribution calculation formula applies only to the problems of an axisymmetric aperture diaphragm and light intensity distribution in the focal plane. We derived the mathematical relationship between the optical field intensity distribution of the image space suitable for the arbitrary aperture shape and arbitrary out-of-focus amount using scalar diffraction theory along with a combination of spectral transformation and orthogonal separation. Furthermore, by using the principle of discrete Fourier transform, we obtained the numerical calculation expression of optical intensity distribution for the imaging space of an optical imaging system with a particular aperture diaphragm. Additionally, we compared the calculation and analysis of the obtained numerical calculation expression with that of the traditional calculation formula, which prove the accuracy of the derived mathematical model calculation at a circular aperture diaphragm and focal plane. For a semicircular aperture diaphragm, under the same system parameters, at the three image positions of 0, 4, and 8 μm, respectively, the results calculated using the obtained mathematical model theory agree with the experimental test results, thereby indicating that the derived mathematical model applies to any shape of the aperture diaphragm.
Terahertz (THz) wave has a potential application prospect in the field of space observation because of its high transmittance and spatial and temporal resolution. Large field-of-view imaging is required for staring optical systems, and compared to scanning imaging, staring imaging has the advantages of high imaging performance, quick speed, and simple structure. As a result, the design of a large field-of-view staring THz optical system has important engineering application value. Zemax and an inverse telephoto structure are used to create a large field-of-view THz optical imaging system with a relative aperture of 1 and a full field-of-view angle of 60°. The system adopts a 4-piece reverse-telephoto coaxial structure, consisting of 2 spherical lenses and 2 aspherical lenses, and the lens material is polymethylpentene (TPX) material. Compactness and lightweight are advantages of the entire system. The modulation transfer function (MTF) value of the full field-of-view at the spatial frequency of 12.5 lp/mm is higher than 0.3, and the optimization results demonstrate that the root mean square radius of the diffuse spot in each field-of-view is smaller than the Airy spot radius, demonstrating the system's high imaging quality. Additionally, the system's robustness is demonstrated by the results of the tolerance analysis, and it is simple to reach the required processing technology level. This design has significant reference value for THz space large field-of-view high-resolution detection.
Detection of the damage to the pipeline insulation layer in a complex environment is challenging because the current automatic damage detection ignores the depth information and only uses the 2D image information. For the orbital robot inspection scene, a damage detection method for the pipeline insulation layer based on line structured light and YOLOv5 is proposed as a solution to this issue. After pre-segmenting the laser domain, the line structured light was added to the video acquisition device, and the laser center line was extracted using the adaptive threshold method. Further, the active ranging was operated in conjunction with the theory of line structured light depth measurement. To address the registration issue between the RGB images and depth information, RGB-D images were automatically created from the video by image stitching. Finally, RGB-D damage detection using the YOLOv5 algorithm with middle-level feature fusion was conducted to identify and classify two types of damages: bulges and dents. Experimental results indicate that the suggested method can extract RGB-D data from the captured video using the orbital robot, and the mean average precision of detection reaches 85.1%, making it possible to detect damage to the thermal insulation layer of the thermal pipeline with high accuracy and efficiency.
To extract a smooth and accurate strain field from a noisy displacement field obtained by digital image correlation method, the moving least-square (MLS) fitting method is often adopted. However, as the MLS fitting method is computationally expensive and unstable when applied to large datasets, the pointwise moving least-square (PMLS) fitting method is proposed herein to improve the computational efficiency and stability. The feasibility and accuracy of the strain field fitted by the PMLS fitting method were explored on simulation experiment under two conditions of continuous displacement field and discontinuous displacement field, and then the strain field of the two groups of measured data images of the continuous displacement field experiment and the crack experiment were obtained. The PMLS fitting method was compared with the classical point-by-point least-square (PLS) method and the MLS fitting method. The results show that the accuracy of the proposed method is effectively improved compared to the PLS method by more than 16% when a large window is used, the computational efficiency increases by more than 27 times compared to the MLS method, and the stability of the MLS method is significantly enhanced. For the discontinuous displacement field, the problem of strain distortion in the discontinuity regions can effectively be addressed, which confirms the applicability of the proposed method to discontinuous displacement fields.
To solve the issue of complex image reconstruction at a small sampling rate due to the high repetition rate and redundancy of cylinder head inner wall thermal field data, a thermal fatigue damage detection method for cylinder head inner wall with a small sample is proposed via fusion of multiple single-scale reconstructed images. The proposed method begins by correlating the thermal scatter pattern of the inner wall with the total radiant energy of its outer wall at various scales to obtain multiple reconstructed images of the cylinder head inner wall. Then, the image fusion technology is used to fuse the reconstructed images of the inner wall at different scales to obtain the fused images of the cylinder head inner wall. The paper demonstrates the advantageous performance of the proposed method in small sampling rate image reconstruction by comparing the results of inner wall image reconstruction at various sampling rates. The effects of different fusion weight coefficients on the fused images are also discussed. The outcomes of the experiments demonstrate that the proposed method may detect the thermal fatigue damage zone of the inner wall at a lower sampling rate. The peak signal-to-noise ratio and contrast ratio of the proposed method are enhanced by 9.62% and 26.13%, respectively, compared with those of the traditional correlation method when the number of samplings is 500. The proposed method also has the distinct benefit of postponing the deterioration of the reconstructed picture quality, thereby resolving the problem of thermal fatigue damage detection caused by insufficient data gathering in real-world applications.
It is highly subjective and has a large error to identify antimony flotation conditions by manually observing the characteristics of antimony flotation foam, which seriously restricts the flotation performance. The recognition method based on computer vision has low cost and good effect. In view of the above problems, a recognition method of antimony flotation conditions based on light-weight convolutional visual Transformer (L-CVT) is proposed. The stack of transformer layers replaces matrix multiplication in standard convolution to learn global information, replaces local modeling in convolution with global modeling, and introduces submodules in the lightweight neural network MobileNetv2 to reduce computational costs. The proposed method solves the problem that convolutional neural network (CNN) ignores the long-distance dependence within flotation images, and makes up for the lack of inductive bias of visual Transformer (VIT). The experimental results show that the accuracy of antimony flotation condition identification based on the proposed method can reach 93.56%, which is significantly higher than VGG16, ResNet18, AlexNet and other mainstream networks. It provides an important reference for antimony flotation data in the field of condition identification.
An optimization method and its derived solution for uniform lighting source of a metal linear test object with high curvature in space are proposed to solve the gray-scale image display problem attributed to the wide variations in brightness on the surface of the metal linear test object caused by uneven illumination in visual inspection. First, the ideal lighting model of any point in the lighting space is established using photometric theory. The mathematical relationship between the surface illuminance, reflectance, spatial coordinate information, and image gray level of the point is then derived, and the simulation is performed using MATLAB. Analyzing the data yielded the primary factors influencing uniform illumination and imaging of the measured object. On this premise, the dome light source is utilized to improve the illumination light source, and the surface uniformity of the metal linear measured object is 92.85%. The experimental findings demonstrate that this technique can effectively improve the surface uniformity of the metal linear object, up to 34.77% higher. Furthermore, it can effectively solve the imaging problem during visual inspection of this type of object.
A vision measurement scheme based on sub-pixel image stitching is proposed to solve the problems of unclear features of transparent optical elements, difficulty in the large field of view, and high-precision dimension measurement by machine vision. Furthermore, the rotation angle between the camera coordinate system and the world coordinate system is calibrated in the proposed scheme to obtain accurate scale factors and image-matching results. The rotation angle of the image coordinate system is less than 0.1° after correction. Additionally, feature matching of transparent components is achieved by adding a grid background. The proposed registration algorithm based on sliding window pre-matching and random sampling consistency to screen the best offset vector increases the image mosaic accuracy to attain 0.05 pixel, which is significantly improved compared with the previous studies. The scheme is applied to the vision inspection system of transparent optical elements. Under the condition that the moving accuracy is only 0.02 mm, the image mosaic result with an average error of 0.12 pixel is obtained, and the large field of view and high-precision size measurement of transparent optical elements are realized.
A two-stage dynamic multi-object positioning and grasping method is proposed to solve the problem of fast and accurate grasping of various types of dynamic objects on a factory assembly line. In the first stage, the proposed multiscale context-aware single-branch fusion semantic segmentation network is used to obtain the mask area of the target object: first, the feature extraction network adopts a single-branch structure, which reduces the number of network parameters while ensuring the extraction of rich spatial information and high-level semantic information; subsequently, the feature fusion network improves the expression ability of spatial data and semantic information through the bilateral guided feature fusion module; finally, the feature enhancement network is designed, and the feature assisted convergence module is embedded in the shallow and deep networks to accelerate the convergence speed of the network. In the second stage, a quick pose estimation strategy based on contour point detection is applied to predict the optimum posture of the grasping point in the mask region. The test results on the self-built dataset and the pipeline platform grab experiments demonstrate that the proposed method can detect and predict the position and posture of the object grab points in real time and accurately complete the object grab. Furthermore, its segmentation accuracy, prediction time, and grab success rate are better than the comparison method.
The use of highways can lead to various cracks on their surface, which can harm the structure. Thus, the research on efficient and accurate crack segmentation algorithms in transportation has attracted significant interest in recent times. Data-driven deep learning technology showed the best applicability among the existing image-based crack segmentation methods. However, crack segmentation models based on neural network generally lack attention to real-time performance. Therefore, this study designs a set of structure hyperparameter selection frameworks and proposes a real-time pavement crack segmentation model (FastCrack-SPOS) to balance the accuracy and speed of the model and to select the appropriate structure hyperparameters. First, we constructed 45 groups of different structural models with various widths (16, 32, 48, 64, 80); depths (D1, D2, D3); and down-sampling ratios (1/4, 1/8, 1/32) and analyzed the effects of each parameter on model performance. Then, we used the neural architecture search technology to search for suitable convolution blocks for each layer and constructed the model. Experimental results reveal that the proposed architecture hyperparameter selection method is highly effective for lightweight crack segmentation model design. Our FastCrack-SPOS has an intersection ratio of 62.88% in the pavement crack dataset, and the number of parameters is only 0.29×106, which is a reduction by 95% compared to existing models. For processing images with size of 1024×1024, the speed attained by the FastCrack-SPOS is 147 frames/s, thereby achieving a balance between speed and accuracy, leading to its high practical application value.
A double watermarking algorithm for medical image tamper detection is proposed to address the imbalance between robustness and transparency caused by embedding watermark information in medical images. First, the Sine-Cubic chaotic map encryption algorithm is used to linearly couple the Sine map and Cubic map, and the obtained chaotic sequence is used to encrypt the copyright image. Second, the carrier image is wavelet transformed, and the low-frequency sub-band is divided into safety regions. The medical image is divided into regions of interest (ROI) and non-interest (NROI) based on the entropy value of the sub-block in the safety region. Simultaneously, a strong zero watermark is created by combining the stable features of the ROI region and the encrypted copyright. Finally, the zero watermark is embedded into the maximum coefficient of the upper triangular matrix of Schur decomposition of the NROI sub-block of the medical image, and the maximum coefficient following the watermark embedding is recorded for tamper detection. The experimental results demonstrate that the proposed watermarking algorithm is imperceptible, robust, and secure, and can accurately locate the tampered watermarked region; when compared to other watermarking algorithms, the proposed double watermarking algorithm is significantly more robust and efficient.
Aiming at the complex anatomical structure of the spine, a YOLOv4-disc algorithm for spinal magnetic resonance imaging image detection is proposed. First, aiming at the problem of small number of real case samples, the adaptive histogram equalization (CLAHE) data enhancement method with limited contrast is used to improve the generalization ability of the model. Second, K-means algorithm is used to cluster the size of real frames in the dataset to obtain the appropriate anchor frame size and determine the number of anchor frames. After that, depth separable convolution is used in CSPDarknet-53 backbone feature extraction network instead of ordinary convolution to reduce network parameters and reduce computation. Finally, the loss function of the native network is improved based on Focal loss to solve the problem that the proportion of positive and negative samples is seriously unbalanced in one-stage target detection. The experimental results show that the mean average precision (mAP) of the proposed YOLOv4-disc algorithm reaches 90.80%, which is 3.51 percentage points higher than that of the native YOLOv4 algorithm.
Based on near-infrared autofluorescence, a rapid identification system for parathyroid glands during surgery is designed, the system is of great value for rapid identification of parathyroid glands during operation. In this research, a ring-shaped adjustable excitation light source and a high-precision adjustable LED constant current source are designed. The near-infrared light source is used to excite tissue fluorescence, and the tissue autofluorescence information is collected by a high-sensitivity CMOS camera. The obtained fluorescence images are processed, accurately identifying parathyroid glands. Simulating tissue fluorescence through gradient concentration of indocyanine green (ICG) solution, the experimentally measured fluorescence intensity is positively correlated with the concentration of ICG, and both the signal-to-noise ratio and signal-to-background ratio meet the requirements for intraoperative discrimination, which verifie the sensitivity and accuracy of the proposed system for different fluorescence intensities. Using this system to test tissue phantoms, the fluorescent phantom can be clearly distinguished from the background. The parathyroid gland and surrounding tissues were tested, and the parathyroid gland is green and clearly distinguished from the surrounding tissues, which preliminarily verifies that the proposed system can be used for the identification and detection of parathyroid glands.
The unique spatial correlation properties of quantum entangled signals can overcome technical barriers, such as those presented by the distance and accuracy, encountered by classical imaging approaches. Therefore, herein, the principle of “ghost imaging” of entangled signals is summarized and is then introduced in the field of navigation. Accordingly, an imaging scheme of hybrid entangled quantum signals generated using a cavity-electric photoelectric light converter is proposed. In contrast to the traditional imaging method, herein, based on theoretical analyses and simulations, the spatial correlation characteristics of entangled microwave signals are completely utilized, and the images that cannot be observed by classical methods are generated in a “nonlocal” manner; correspondingly, the signal-to-noise ratio is higher than that of the classical scheme when weak signals are detected. That is, the imaging quality is better than that of the classical scheme, and it has the ability to resist atmospheric turbulence disturbances unlike the classical scheme.
Compared to discrete-return and full-waveform LiDARs, the photon-counting LiDAR can provide more dense sampling, higher resolution, and better penetrability along the laser ranging. However, the point clouds obtained by the photon-counting LiDAR contain more background and interference noises. Therefore, it is necessary to adopt a suitable noise filtering method to accurately identify the effective photon signal on the target. At present, the main filtering methods include histogram statistics (HS), local distance statistics (LDS), and density-based spatial clustering of applications with noise (DBSCAN). To evaluate the performances of these methods on the mountainous region and the waters, the multiple altimeter beam experimental LiDAR is used for comparing and analyzing the three methods. The results show that the three methods can accurately extract effective photon point clouds. Among them, the HS method is suitable for flat terrains and water areas. LDS and DBSCAN are better suited for undulating terrains and mountainous areas, and DBSCAN achieves the best performance in mountainous areas. The results are quantitatively compared in terms of precision, recall, and F1-score. HS, LDS, and DBSCAN achieve a precision of 0.9342, 0.9524, and 0.9669, respectively, in the mountainous areas and 0.9981, 0.9492, and 0.9349, respectively, in the water areas.
In view of the problems that the traditional neural network model tends to ignore difficult samples due to the unbalanced classification of remote sensing image semantic segmentation data, and the reasoning results are hollow and the segmentation accuracy decreases, a drill-shaped neural network semantic segmentation method is proposed. First, a new bridge module is defined to fuse the shallow and deep feature information, thus more building details can be captured by the network; second, in the deep learning segmentation model training, the multi loss function is used to improve the extraction of difficult sample information; finally, to balance the differences of category training, the feature information is extracted from remote sensing images at multiple levels, and the segmentation accuracy is improved. The experimental results show that the average intersection to union ratio of the proposed method reaches 0.849, the building missing rate and wrong recognition rate are less, and the segmentation accuracy is improved compared with the existing methods.
A remote sensing image segmentation network called AFSM-Net, which combines a feature map segmentation module and an attention mechanism module, is proposed to address the issues of low recognition and low segmentation accuracy of small targets in remote sensing image segmentation using conventional convolutional neural networks. First, the feature map segmentation module is introduced in the coding stage to enlarge each segmented feature map and extract features by sharing parameters; then, the extracted features are fused with the original output image of the network; and finally, the attention mechanism module is introduced into the network model to make it pay more attention to the effective feature information in the image and ignore the irrelevant background information, to improve the feature extraction ability of the model for small target objects. The experimental results show that the average intersection ratio of the proposed method is 86.42%, which is 3.94 percentage points higher than that of the DeepLabV3+ model. The proposed method fully considers the attention of small and medium targets in image segmentation, and improves the segmentation accuracy of remote sensing images.
The improvement in the sensing node used to cover the three-dimensional complex terrains (CTDCT) depends on the research results of two-dimensional coverage of wireless sensor networks and the phenomenon of weak applications in actual three-dimensional space. The node stereo perception model addresses the misjudgment of occlusion and coverage by judging the blind spots of perception in line-of-sight and non-line-of-sight; moreover, it combines the perception quality of nodes in the CTDCT. The algorithm expands the distribution of nodes and reduces redundancy by introducing mapping from the point set to the feasible region of the scene. Furthermore, the nonlinear adjustment of node position in the iteration cycle improves network diversity in the early stages and optimizes the local topology in the later stages. The step length of the designed node is excited by redundant nodes to improve the level of coupling between the network and the existing environment. The simulation results demonstrate that the CTDCT algorithm reduces the coverage misjudgment probability and adjusts the node position. This effectively reduces the node's perception of overlap and blind areas in line-of-sight and non-line-of-sight scenes. Furthermore, it also enhances the regional coverage quality in the CTDCT.
A methane leakage telemetry system based on TDLAS-WMS is proposed in this study to meet the high-precision, non-contact, and long-distance detection requirements of methane leakage. The system adopts a dual core advanced RISC machine (ARM) and field programmable gate arrays (FPGA) and design, where FPGA realizes the digital phase-locked demodulation to extract the first (1f) and second harmonic (2f) signals. Furthermore, ARM receives the 1f and 2f signals demodulated by FPGA in real time through serial peripheral interface (SPI) and relays them to Labview for harmonic signal analysis and methane concentration online demodulation. Using 2f/1f signal processing technology, the influence of change in light intensity and target reflection coefficient on the system measurement results is eliminated. The relationship between harmonic signal and detection distance in the range of 0-90 m under the same experimental conditions are studied. Results reveal that 2f/1f signal processing technology has a considerable effect on noise suppression. The harmonic signals with different integrated concentrations are measured, 2f/1f and gas integrated concentration data are linearly fitted by the least squares method, and system calibration linearity is obtained, which is 0.9966. Moreover, the system error is measured and analyzed experimentally. Within the range of 0-2000×10-6 m, the maximum and minimum relative errors of system measurements are -3.66% and -0.23%, respectively. Using 1500×10-6 m, the detection limit of the second harmonic signal evaluation system for methane concentration is determined to be 70.5×10-6 m. Results indicate that the designed and developed methane leakage telemetry system can be widely used in the monitoring and early warning of sudden gas leakage in urban gas stations and natural gas pipelines.
To ensure the safe and reasonable development of karst caves, it is often necessary to consider the flood situation in the caves. Based on this, a method for determining the safe water level of karst caves based on three-dimensional (3D) geospatial information and flood numerical simulation is proposed. First, the Green-Ampt, soil conservation service unit hydrograph, and dynamic wave methods were used to build a mountain torrent model and verify its reliability. Second, flood hydrograph at the entrance of the karst was calculated using the designed 10-year rainstorm input flood model, and the flood data served as the input parameter for the flood simulation in the cave. Finally, a more efficient 3D turbulence model was selected to simulate the flood in the 3D model of the karst cave, then the safe water-level coordinates of the karst were extracted. Results show that the simulated flood mark is consistent with the observed flood mark. Therefore, the mountain flood model is suitable for flood calculation in the study area, and the 3D simulation results of the flood in the tunnel, based on large eddy simulation, are consistent with the actual water-level change characteristics in the tunnel. Thus, this method can provide more valid reference data on safe water levels for karst cave development.
A high-speed target tracking algorithm with high accuracy and stability is proposed for pulse image sensors. First, the principle of a pulse image sensor is introduced. Second, the traditional visual background extraction (Vibe) algorithm is improved by combining the pulse density characteristics of the sensor to remove the ghost and hole issues in the traditional Vibe algorithm, this further improves the integrity of motion detection. Subsequently, combined with motion detection, the traditional mean shift (MS) tracking algorithm is enhanced to improve the accuracy and stability of target tracking. Finally, scene reconstruction and target tracking are completed via image reconstruction. In the three high-speed scenes experiments, compared with the traditional MS algorithm, which is directly applied to image sequences, the maximum tracking error of the proposed algorithm for high-speed targets reduced from 11.0454 to 2.2361, from 14.1421 to 5.0000, and from 26.1725 to 5.0990, respectively. The position standard deviation of target tracking decreased from 7.9879 to 2.0393, from 12.0790 to 2.7454, and from 14.4591 to 3.5654, respectively. In summary, the proposed algorithm can effectively improve target tracking accuracy and stability and is more suitable for pulse image sensors than the other algorithms.
Remote sensing images have many problems, such as complex background, small targets, and dense arrangement. The target detection method based on depth learning can improve the accuracy of target detection, but there are many problems, such as more model parameters and general detection speed. Aiming at the above problems, a remote sensing image target detection method based on improved YOLOv4 is proposed. First, the lightweight network Mobile NetV3 is used to replace the original feature extraction network of YOLOv4 to improve the detection speed; second, the self-attention mechanism is concatenated in the prediction layer, and the improved non maximum suppression algorithm is used for post-processing; finally, in the image preprocessing, Mosaic method is used to enhance the data, K-means method is used to obtain the candidate frame parameters that better match the remote sensing target, and Complete Intersection Over Union (CIoU) loss function is used in the prediction layer to locate the coordinate frame. The experimental data set consists of two classical remote sensing datasets, NWPUVHR-10 and DOTA, including 10 categories of ships, vehicles, and ports. The results show that when the input size of remote sensing image is 608×608, the detection speed is 54 frame/s, 1.6 times that of YOLOv4, and the average accuracy is 85.60%. The proposed method reduces the parameter amount and improves the detection speed while maintaining a high detection accuracy.
Due to the lack of color information of three-dimensional point cloud and spatial information of optical images, a fusion method based on lidar and camera automatic calibration is proposed in this work. The fused data contains both the spatial information of the point cloud and color texture information of the optical images. First, the planar calibration plate was used to automatically calibrate the lidar and optical camera in steps. Second, the coordinate relationship was established through a collinear equation, and the color texture information of the optical image is given to the point cloud for fusion and visualization. The experimental results show that the fusion accuracy and the level of automation of the proposed method are improved. Compared to the calibration fusion method based on manual matching, the accuracy of the proposed method is improved by 51.7%. Compared to the calibration fusion method based on a trapezoidal checkerboard calibration board, the accuracy of the proposed method is improved by 36.4%. Considering the visualization results from multiple angles, the proposed method can better restore the color and spatial effects of real scenes.
In this paper, we demonstrate a miniaturized nanofiber methane sensor based on tunable diode laser absorption spectroscopy (TDLAS). Based on the Beer-Lambert law, we chose a methane absorption line near 1.6 μm, performed a wavelength modulation on a distributed feedback diode laser (DFB-DL), used a lock-in amplifier to demodulate the second harmonic signal, and established a complete TDLAS system based on nanofiber. The system is used to examine the influence of different incident powers and pressures on the second harmonic signal at room temperature. We obtain the system’s pressure broadening and frequency shift coefficients through experiments. It is found that nanofibers with a smaller diameter can produce stronger absorption for methane. Moreover, the designed nanofiber sensor is a powerful tool for tracing gas measurements under low power conditions and has considerable application potential in gas species and quantitative analyses.
Photonic neural networks (PNNs) are proposed to balance the demands between a substantial increase in computation ability and a decrease in computing power consumption, owing to the superiorities in terms of large bandwidth, low latency, and low power consumption in optical transmission. Hence, in recent years, PNNs have become the research hotspot both in academia and industry. By utilizing photons as the physical media, the basic computing units in artificial neural network algorithms can be built and experimentally demonstrated. In further, PNNs might be adopted as a new computing architecture with high performances and be applied to solve the practical applications. In this paper, the working principle and characteristics of the core optical devices in PNNs are described, along with the system architecture and application scenario. In addition, the present challenges and future development trends of PNNs are discussed, after reviewing the research progress of PNNs at home and aboard.
This study experimentally investigates the maximum measurable particle size of interferometric particle imaging (IPI). The maximum measurable particle size for IPI was examined in relation to the effect of object distance variation brought on by several object planes in the same field of vision. The IPI experimental system irradiated by a single beam was built to measure the polystyrene mixed particle fields with particle diameter of 51 μm and 110 μm, and the maximum measurable particle size in different collection areas in the same field of view was analyzed. The outcomes of the experiment demonstrate that the spatial relationship between the objects in the experimental system has an impact on the maximum quantifiable particle size of IPI technology. The maximum quantifiable particle size of various acquisition areas within the same field of view varies for an experimental system with fixed parameters.
This study introduces a depth auto-encoding network into spectral feature learning and proposes an improved feature extraction method based on a convolution auto-encoding network (1D-BCAE) to address the impacts of high dimension, nonlinearity, and a lot of noise in the near-infrared spectrum on quantitative modeling. The feature extraction method is applied to the quantitative modeling of key indexes of tobacco using near-infrared spectroscopy, which improves the accuracy and robustness of the model. First, this method uses a one-dimensional convolution kernel and a pooling window suitable for spectral data feature extraction. Second, in the coding process, the BasicBlock module and batch normalization (BN) structure are added to optimize the network structure, which reduce the number of parameters and computation, reduces the noise and nonlinear characteristics of the spectrum, and optimizes the training efficiency of the network. By designing a corresponding connected structure, the parameters of each module in the encoder are passed to the corresponding decoder, which reduces the loss of detailed features in the network training process. The effectiveness of the proposed method is verified by comparing the reconstruction error and root mean square error in experiments. The quantitative models about nicotine and total sugar in tobacco leaves are established using the features extracted by the full spectrum segment and principal component analysis (PCA), convolutional auto-encoding (CAE) network, and 1D-BCAE combined with the partial least squares (PLS) method, respectively. The results reveal that 1D-BCAE can effectively learn the internal structure and nonlinear relationships in high-dimensional data, and the established model performs better. The proposed method can effectively extract the spectral information of the components to be measured, which is critical for developing a robust correction model and reducing model complexity.