







Please enter the answer below before you can view the full text.
9-2=

Surgery and chemotherapy, as the main treatments for liver cancer, require accurate extraction for the liver lesion area. Therefore, to solve the problems of the current segmentation methods for liver tumors, such as the loss of small-sized tumors, fuzzy segmentation of tumor boundaries, and severe missegmentation, a new method for liver tumor segmentation based on the attention mechanism and deformable residual convolution is proposed. U-Net was used as the backbone network, and a residual path with deconvolution and activation function was added at the end of the encoding convolution layer to connect with the upper layer, thereby solving the problem of missing small target segmentation and fuzzy boundaries caused by information loss in pooling and deconvolution operations. Furthermore, a deformable convolution was used to enhance the model for extracting features of tumor boundaries. Several convolution layers were added to the skip connection layer to compensate for the semantic gaps caused by simple skip connections in feature fusion. The model pays more attention to tumor characteristics through the dual-attention mechanism. The mixed loss function was used to address the problem of segmentation performance degradation caused by a class imbalance under the condition of ensuring the stability of training. The experiment was carried out using the Liver Tumor Segmentation Challenge (LITS) dataset. The experimental results show that the Dice coefficient of tumor segmentation of the proposed method reaches 85.2%. Moreover, the proposed method has a better segmentation performance than other comparison networks, meeting the requirements of auxiliary medical diagnosis.
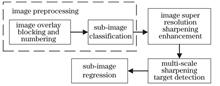
A small target detection algorithm based on super-resolution reconstruction is proposed to solve the problem of low detection accuracy of small targets occupying a few pixels. First, a high-resolution image is segmented via image preprocessing and sub-images containing targets are filtered out. Second, a super-resolution sharpening enhancement module is constructed, and the sharpening image and sharpening loss are introduced to obtain high-resolution sub-images with clearer edges. Subsequently, a multi-scale sharpening target detection module is used to detect the target; it uses an edge-sharpening model to further enhance the image edges of the deep feature layer to compensate for the loss in details due to deep convolution. Finally, the small-target detection results are returned in the original image based on the sub-image number used to complete small target image detection. The proposed detection algorithm is then verified using the PASCAL VOC and COCO 2017 datasets, where the average accuracies (mAP) are 85.3% and 54.0%, respectively. Moreover, the small target detection accuracy of the COCO dataset is 43.5%, which is 9.7 percentage points higher than the suboptimal value. Therefore, the proposed algorithm can effectively reduce the number of times small targets are missed during detection, thus improving the detection accuracy.
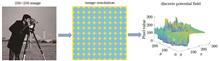
A quantum derived image transformation and threshold denoising algorithm based on the Schr?dinger equation is proposed to make full use of image information and effectively remove Gaussian noise and Poisson noise from the image. In the discrete Schr?dinger equation, the image is regarded as the potential field, and the characteristic function obtained by solving the stationary Schr?dinger equation constitutes the adaptive basis. The image is then projected onto the adaptive basis. Since the noise is mainly represented by the high-order characteristic function corresponding to the high energy, the soft threshold function is used to deal with the projection coefficient in terms of energy to achieve denoising. To reduce the influence of Anderson localization in the quantum system on denoising, the image is preprocessed with a Gaussian filter. The proposed algorithm has a good denoising effect in Gaussian noise and Poisson noise scenes, according to experimental results.
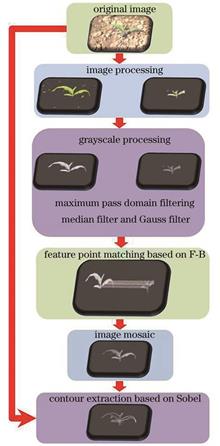
With the continuous progress and development of agricultural robot technology, it has become increasingly important to use robots to collect and process specific crop image information in the agricultural application field. Aiming to address the problem that the corn plant contour extracted using traditional image processing methods is incomplete or even missing, an improved corn plant contour extraction method is proposed. In this method, the HSV color space was used to extract the image of the green leaf part of the corn plant, whereas the RGB channel separation method was used to extract the image of the red root part. After the leaf and root images were obtained, the F-B algorithm was used to select their feature points and describe and match them, whereas the random sampling consistency algorithm was used to remove the wrong matching points. Finally, the weighted fusion method was used to splice the images, and the Sobel operator was selected to extract the plant contour. The experimental results show that, compared with the traditional scale invariant feature transform (SIFT), speed up robust features (SURF), and oriented FAST and rotated BRIEF(ORB) algorithms, the F-B algorithm has improved matching speed and accuracy, with its matching accuracy being more than 80%. The Sobel operator used to extract the plant image contour results in better image clarity and integrity. Thus, this method can achieve the contour extraction of maize plants with high speed and accuracy.
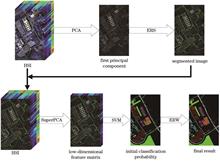
A hyperspectral image classification method based on joint hyperpixel dimension reduction and category posterior probability optimization is proposed to address the issues of inadequate utilization of spatial information and decline in classification accuracy under small- and medium-sized training samples. First, the entropy rate hyperpixel segmentation algorithm, based on the spatial texture structure of hyperspectral images was used to adaptively detect homogeneous hyperpixel regions, and principal component analysis was applied to each region individually to mine the hyperpixel mixture features that can represent the spatial-spectral information of images. Then, the initial category probability vector of each pixel was calculated using the mixed features provided in the support vector machine, and the extended random walk algorithm was used to optimize the initial category using the image space neighborhood information. Finally, the classification result was calculated based on the maximum classification probability of each pixel. Experiments were performed on three general hyperspectral datasets, including Indian Pines, Pavia University, and Salinas, and compared with the other six methods. Even with a small number of training samples, the experimental results show that the proposed method's overall classification accuracy is 98.29%, 97.29%, and 99.72%, respectively, which is superior to the classification results of the comparison methods.
A lightweight network model based on multiscale feature information fusion (MIFNet) is developed in this study owing to the imbalance among the parameter amount, inference speed, and accuracy in many existing semantic segmentation network models. The MIFNet is constructed on the encoding-decoding architecture. In the encoding part, the split strategy and asymmetric convolution are flexibly applied to design lightweight bottleneck structure for feature extraction. The spatial attention mechanism and Laplace edge detection operator are introduced to fuse spatial and edge information to obtain rich feature information. In the decoding part, a new decoder is designed by introducing a channel attention mechanism to recover the size and detail information of the feature map for a complete semantic segmentation task. The MIFNet achieves accuracies of 73.1% and 67.7% on the Cityscapes and CamVid test sets, respectively, with only approximately 0.82 M parameters. Correspondingly, it reaches up to 73.68 frame/s and 85.16 frame/s inference speed, respectively using a single GTX 1080Ti GPU. The results show that the method achieves a good balance in terms of the parameter amount, inference speed, and accuracy, yielding a lightweight, fast, and accurate semantic segmentation.
A target tracking method based on positional perception is proposed to address the issue of low tracking accuracy caused by the absence of target detail information in thermal infrared images. First, semantic characteristics were extracted and thermal infrared objects were robustly characterized using the deep dilated residual network (D-ResNet). Second, a positional perception module was designed to efficiently detect the object position on the feature map and enhance the positioning accuracy of the algorithm. Third, the channel attention module was introduced to suppress interference information and filter feature map data in the channel domain. Then, the region proposal network was implemented to complete border regression and target categorization. Finally, RGBT234 thermal infrared sequences were used to adjust the network to successfully learn the thermal infrared object information. The proposed method is tested on VOT-TIR2019 and GTOT datasets and achieves accuracy of 75.3% and 91.4%, respectively, and a speed of 30 frame/s. Experimental results also demonstrate that the proposed method can realize high tracking accuracy in dealing with common difficulties, such as occlusion, analog interference, and scale change, effectively in the thermal infrared scene.
We propose a novel flame generation algorithm, called fire-GAN, based on the HistoGAN algorithm to solve the issues of low quality and complex color control of flame images produced by a generative adversarial network. First, flame image segmentation is introduced in the image preprocessing link to remove background interference from the network, reduce the flame shape distortion and color distortion. Second, the roundness loss function is suggested to increase the focus of the network during training on the intricacy of the flame contour. Finally, data enhancement is implemented in the generator and discriminator to maintain the network stability during training and prevent gradient explosion. The experimental results demonstrate that the average RGB error between the flame generated by fire-GAN and the target flame is 2.6%, the Fréchet inception distance (FID) is 59.23, and the inception score (IS) is 2.81. The outcomes demonstrate the feasibility of the fire-GAN to produce a flame image with color, definition, and authenticity levels quite comparable to the target flame image.
In a series of applications based on a light field, three-dimensional (3D) reconstruction of objects is a basic and key task. Ordinary light fields can only reconstruct a single perspective; however, they cannot reconstruct a panorama and generate accurate 3D information in areas with scarce texture features. To solve these problems, a panoramic 3D reconstruction method based on a multi-view coding light field is proposed. First, the structured light coding is used to project sine templates to the scene to generate pixel-level phase codewords to enrich the scene features. Then, the light field is collected independently from multiple angles. Furthermore, the depth value is obtained using spatial and angle information in the interior of each light field sampling viewpoint. Finally, 3D information fusion is realized between different light field sampling points under the pose guidance. The experimental results show that the proposed method can effectively restore the panorama information of the object. Moreover, the reconstruction of an area with insufficient texture features of the object is more accurate.
This study proposes an effective method for repairing honeycomb artifacts by analyzing generational mechanisms and the related characteristics of these honeycomb artifacts based on the honeycomb artifacts in images collected using a fiber bundle imaging system. According to the distribution characteristics of honeycomb artifacts in the image, the original image was first divided into several sub-images by a splitting method to reduce the honeycomb artifact's image width. Then, a sliding window with a certain size was used to repair the honeycomb artifacts. Subsequently, the pixels located in the area of honeycomb artifacts were screened out of the sliding window according to the designed adaptive threshold mechanism, after which we calculated the pixel value difference and Euclidean distance between the pixel and another with the largest pixel value in the window to obtain the adaptive compensation coefficient for pixel repair, leading to a transverse of the sliding window and repair of the whole sub-image. Hence, an original image was finally formed with restored sub-images and vice versa. Based on the test results, the proposed method has a better performance, as shown by the objective evaluation index, indicating that it will repair the honeycomb artifacts in images better than the previously established honeycomb artifact restoration algorithms.
An improved helmet detection algorithm for YOLOv4 (SMD-YOLOv4) is proposed to effectively detect whether construction workers are wearing helmets in complex scenes and reduce safety hazards. First, the SE-Net attention module is used to improve the ability of the model backbone network to extract effective features. Next, a dense atrous space pyramid pooling (DenseASPP) is used instead of spatial pyramid pooling (SPP) in the network to reduce information loss and optimize the extraction of global contextual information. Finally, the scale of feature fusion is increased in the PANet part and deep separable convolution is introduced to obtain detailed information about small targets in complex contexts without slowing down the network inference speed. The experimental results show that the mean average precision (mAP) of SMD-YOLOv4 algorithm reaches 97.34% on the self-built experimental dataset, which is 26.41 percentage points, 6.44 percentage points, 3.25 percentage points, 1.49 percentage points, and 3.19 percentage points higher than that of the current representative Faster R-CNN, SSD, YOLOv5, YOLOx, and original YOLOv4 algorithms, respectively, and can meet the real-time detection requirements.
A classification method of hyperspectral images based on dual channel feature enhancement (DCFE) is proposed to solve the problem of how to extract and use the spatial and spectral information of hyperspectral images more fully when the training samples are limited. First, two channels are designed to capture spectral and spatial features, and 3D convolution is used as a feature extractor in each channel. The feature map from the reduced-dimension spectral channel is fused with the feature map of the spatial channel. Finally, the feature map combining spectral and spatial features is input into the attention module, and feature enhancement is achieved by increasing attention to important information while decreasing interference from irrelevant information. The experimental results show that the proposed method has an overall classification accuracy of 96.57%, 98.15%, 98.95%, and 96.83% on four hyperspectral data sets, including Indian Pines (3% training sample), Pavia University (0.5% training sample), Salinas (0.5% training sample), and Botswana (1.2% training sample), respectively. When compared to the other five hyperspectral classification methods, the proposed method has remarkably improved the classification performance.
Conventional Retinex defogging algorithm does not consider the depth-of-field information of fogged images and restores the entire image at the same scale, resulting in local color distortion and loss of image details. An adaptive Retinex image defogging algorithm that uses depth-of-field information to remedy these disadvantages is proposed. As fog concentration and depth of field are closely related, the depth-of-field of foggy images is estimated using the BTS depth learning model. The average gradient of the image is considered the optimal evaluation standard, following which the foggy image is processed in blocks. The Retinex enhancement adopts different Gaussian filtering scales, and the optimal Gaussian filtering scale as well as the corresponding average depth-of-field are estimated. The parameter models of depth-of-field estimation and Gaussian filtering scale are obtained via the gradient descent method and applied to the single-scale Retinex defogging algorithm to process the fogged images in blocks. Finally, by calculating the mean value and mean square deviation, and defining a parameter to control the image dynamics, we can realize adaptive contrast stretching without color deviation. Moreover, bilinear interpolation mapping can also be applied to increase the continuity of the image block edges and obtain an enhanced defogging image. Experimental results show that the standard deviation, average brightness, information entropy, square gradient, and other evaluation indicators after defogging using the proposed algorithm are better than those of the contrast algorithm. In practice, the defogged image has higher contrast, the image details remain intact, and excessive enhancement is suppressed. The adaptive Retinex image defogging algorithm based on depth-of-field information proposed in this paper has a high degree of adaptation and can effectively retain image details with natural color that conforms to the characteristics of human vision, making it superior to the conventional Retinex defogging algorithm.
Addressing the issue that there is no standard evaluation system for the effectiveness of infrared deception jamming against false targets, the visual saliency model is employed to determine the contrast between the real target and the false target under the same background, and quantitatively assess the effectiveness of infrared deception jamming against false targets. The effectiveness of the false target's infrared deception jamming effect increases with decreasing value. The experimental results demonstrate that the evaluation method can not only quantitatively reflect the infrared deception jamming effectiveness of a single false target, but also differentiate the infrared deception jamming effectiveness of various types of false targets, and has strong universality.
Traditional clustering-based band selection methods mostly belong to hard clustering, which are not accurate enough to divide the bands. To solve this problem, this paper proposes an unsupervised band selection method based on fuzzy C-means clustering (FCM). By introducing the firefly algorithm (FA), an FCM-FA is obtained, after which the global search feature of FA is used to solve the problem for which the FCM only obtains a locally optimal solution in certain circumstances. Classification experiments on two public hyperspectral datasets show that the proposed FCM-FA achieves the classification accuracy for all bands in 55.9% of 136 experiments, the optimal classification accuracy is achieved in 77.9% of the cases, the introduction of FA effectively improves the effect of FCM, with the overall accuracy increasing by 3.12 percentage points, and Kappa is increased by 4.26 percentage points at most. Hence, our results verify that FCM-FA can significantly reduce the amount of data while retaining the main information of original data that can be further promoted and studied.
The effective extraction of features for hyperspectral image classification is a challenging research topic in remote sensing. To solve this problem, a spatial-spectral feature framework with an automatic threshold attribute attribute profile is proposed for hyperspectral image classification. The framework includes two stages. The first stage involves conversion of the grayscale value of the hyperspectral image into an attribute morphological profile of the tree structure, filtering the tree using the proposed automatic threshold method to create the final extended multivariate attribute morphological profile, and using the profile to obtain the spatial-spectral feature data. The proposed method does not require the customization of any thresholds and only requires a few filtering operations to obtain the maximum spatial information. Then, in the second stage, the derived spatial-spectral feature data are used to create an effective classifier using a trained spectral angle mapping stackable automatic encoder network to obtain the final classification result. Finally, the effectiveness of the method is verified by applying it to two real hyperspectral image datasets and comparing the results with those of existing methods.
Fast and accurate underwater image super-resolution reconstruction technology can help underwater vehicles better perceive underwater scenes and make navigation decisions. Based on this, a lightweight underwater image super-resolution reconstruction algorithm (SRIDM) based on an information distillation mechanism is proposed. Based on an ordinary residual network, the algorithm presents a global feature fusion structure, information distillation mechanism, and spatial attention module, which further enhances the feature expression ability of the model. The effectiveness of each module was validated through model ablation experiments, and the best module combination and distillation rate were discovered. The experimental results on the USR-248 test set show that the proposed algorithm restores images better than other contrast algorithms in terms of subjective visual effect and objective evaluation quality. When the magnification factor is 4, its peak signal-to-noise ratio and structural similarity reach 27.7640 dB and 0.7640 respectively. Furthermore, the proposed algorithm is also a lightweight algorithm, which significantly reduces the number of model parameters and computational complexity while maintaining performance.
Current ellipse detection algorithms have been designed and implemented for grayscale images. When processing color images, much useful information is discarded, which is inconducive to obtaining higher quality detection results. Therefore, an ellipse detection algorithm for color images is proposed. First, the three color channels and weighted grayscale image of the image are detected for ellipses, and a set of ellipses is obtained by fusing the detection results of multiple channels. Then, the multiple response results of the same ellipse in different image channels are clustered and combined into an ellipse. Finally, an ellipse validity verification technique is proposed. The technology fuses the color information of the image using the DiZenzo operator, extracts the ellipse support line segment to determine the effectiveness of the ellipse, filters invalid ellipses, and obtains the final detection results. Experiments show that compared with existing algorithms, the proposed algorithm fully uses the color information of the image, thereby significantly improving the efficiency of ellipse detection, and the F-score on a standard dataset is significantly better than that of the current detection algorithms.
A template drift suppression method based on sub pixel correction is proposed to address the issue of long-term template drift tracking by the kernel correlation filtering algorithm. First, according to the fast algorithm of kernel correlation filtering commonly used in the tracking process, the tracking error introduced by template updating was analyzed. Second, the influence of sampling error on template drift was analyzed. Then, the sampling error introduced by the template update was corrected by shifting the phase of the template frequency domain. Finally, the inhibition effect of the template sub pixel correction on the long-term tracking template drift was verified through experiments. The experimental results show that under the same tracking conditions, the template drift introduced using the template sub pixel correction method is reduced to only 1/4 of that of the whole pixel template update. Therefore, the template sub pixel correction quite effectively suppresses the template drift with a small amount of computation when used in the correlation filtering and kernel correlation filtering algorithms.
To address the difficulties in object recognition caused by noise, occlusion, and other factors in Bin-Picking by an industrial robot, a three-dimensional (3D) recognition algorithm using curvature point pair features is proposed. Based on the original point pair feature, a curvature difference feature is introduced to make the point pair more descriptive and improve the point cloud registration rate. In the preprocessing stage, a watershed algorithm based on distance transformation is used to segment the scene point cloud, extract candidate targets, and accelerate the algorithm matching. Furthermore, a new weighted voting scheme is proposed for the pose voting stage, and it assigns a larger weight to stronger point pairs based on the curvature difference information and further improves the point cloud registration rate. The experimental results show that the proposed algorithm significantly improves the accuracy and speed compared to the original algorithm, and it can meet the requirements of practical application scenarios.
A moving object detection algorithm based on new background extraction is proposed to rapidly and efficiently detect moving objects in various environments. First, N consecutive images are read from the video. For any pixel position, the corresponding positions of each frame image and other images are subtracted to obtain N groups of difference sequences containing N differences. Next, based on the rectangular radial basis function, the number of differences within the width of the rectangle in each difference sequence is counted. Finally, the pixel value corresponding to the maximum frequency difference sequence is used as the background and the moving target is extracted via background subtraction. The experimental results show that under the condition of a specific amount of data, the structural similarity value of the background established by the proposed method and the real background is 0.162 higher than that of the ViBe algorithm. The precision, recall, F1 measure, and false positive rate indexes of the moving target detection results are better than those of the ViBe and GMM algorithms. Therefore, the proposed algorithm is a moving target detection algorithm with high accuracy and anti-interference ability.
An algorithm for improving low illumination color images that is based on the fusion of full variation and Gamma is proposed to address the issue of low brightness and poor detail. First, the image is divided into illumination and reflection images by using local variation bias and spatial adaptive total variation model (TV), and the weight value is combined with the exponential form of TV to extract better reflection images with texture details. Second, to obtain a better weighted distribution adaptive Gamma correction and an improved brightness corrected image, brightness V is extracted from the original image's HSV space. Finally, weighted fusion of images improved in two different ways yields the final enhancement results. The experimental results demonstrate that the image details processed by the image improvement algorithm are clear, which can effectively address the issue of poor similarity between the enhancement results and the original image brightness structure, and minimize image distortion and artifacts.
This study proposed a differently scaled point cloud registration algorithm based on artificial bee colony optimization that can improve the accuracy and efficiency of differently scaled point cloud registration. The scale scaling factor, together with the three-dimensional rotation and translation parameters, was introduced as the variables to be solved in the registration process, and the artificial bee colony optimization method was used to optimize the solution. Furthermore, the proposed algorithm improved the Euclidean distance objective function based on the normalized scale factor, which eliminated the errors caused by optimizing the scale scaling factor to effectively improve the stability of the registration algorithm. Compared to currently employed methods, the proposed algorithm improves the accuracy and efficiency in different model registrations. The experimental results demonstrate that the proposed algorithm utilizes the excellent global optimization ability of the artificial bee colony optimization method and can therefore effectively realize the high-precision and fast registration for differently scaled point clouds.
Aiming at the problems of low light, low contrast, and high noise caused by shadows, a polarization distance intensity (PDI) model fused with the "hue-saturation-intensity" color space (HSI color space) is proposed based on the theory and algorithm of polarization distance using the biological polarization vision mechanism for reference to improve the detection and recognition accuracy of targets under shadows. The model uses the angle of polarization information as the estimation method to set the threshold range, fuse the polarization distance information and the original light intensity information into a new intensity channel, and fuse with the original hue and saturation information to finally obtain the mapping result of the PDI model. The actual measurement experimental device was set up, and four groups of comparative experiments were conducted. Compared to the other three existing target enhancement algorithms, the proposed algorithm achieves significant improvement in gray contrast, signal-to-clutter ratio, and Fish distance indicators, and could improve the difference between the target and the background under shadow significantly.
A reconstruction model based on convex-nonconvex finite element total variation (CNC-FETV) regularization is proposed to avoid the biased estimation of L1 regularization in diffuse optical tomography. First, the finite element method was used to divide the computational domain into a finite number of triangles, after which a continuous piecewise polynomial function was used to approximate the absorption coefficient value in each triangle. Then, the derived difference matrix was assembled element by element to obtain a representation of the FETV regularization. Subsequently, the CNC-FETV regularization was obtained by the construction method based on convex-nonconvex sparse regularization. Results theoretically proved that the nonconvex regularization term could maintain the overall convexity of the objective function under certain conditions. Finally, the alternating direction multiplier method was used to solve the proposed model. Numerical experiments show that compared with the Tikhonov and FETV regularization models, the proposed CNC-FETV regularization model has superior performances in both numerical criteria and visual effects for diffusion optical tomography reconstructions.
In this study, we propose a depth estimation method for phase-coding light field based on a lightweight convolutional neural network. This method aims to solve the problems of low accuracy for depth values caused by the insufficient texture of a measured object in traditional light field depth value estimation and high computational loads caused by high-dimensional light field data. In addition, a new phase-coding light field dataset is proposed. This novel method exploits the information of horizontal and vertical perspectives in phase-coding light field to extract the features using full convolutional networks and deepening average pooling. Furthermore, the central view is used as a guide to fuse the horizontal and vertical features and acquire the depth map. The experimental results demonstrate that the proposed method can generate high-accuracy depth maps, while number of parameters and computation time in generating such maps are, respectively, 27.4% and 41.2% of those of a typical light field depth estimation network. Thus, the proposed method has a higher efficiency and real-time performance than the traditional approach.
In this study, an angle-related fitting function wherein the fitting coefficient is calculated using the least square fitting polynomial method is established for an active self-built dual-focus terahertz imaging system. In addition, the geometric optical tracking calculation process for the scanning track is successfully simplified into a binary function. The system adopts the same channel image scanning technique using a rotating mirror. Because the fitting independent variable has a significant influence on the terahertz image, two different fitting independent variables are used for calculation, and the advantages and disadvantages of the two are compared through numerical and imaging results analyses. The experimental results show that when the coordinate component of the normal vector of the rotating mirror is used as the fitting independent variable, the calculation time of the scanning trajectory is reduced to 3 s/frame, and the terahertz image is very accurate. Moreover, the system realizes fast and accurate imaging under a spatial resolution of 3 cm and view field of 50 cm × 100 cm when placed at a distance of approximately 8 m. Thus, this study provides a valuable reference for quick scanning in terahertz imaging systems and is of practical significance for real-time terahertz security inspection and non-destructive testing.
Liquid-crystal displays (LCD) based on the mini-light-emitting diode (Mini-LED) backlight have attracted significant attention as a promising highly dynamic contrast display system. A halo effect occurs in Mini-LED backlight LCDs because of backlight partition and LCD light leakage, reducing the image quality. In this study, an accurate optical model of the Mini-LED backlight LCD system was established to precisely replicate the halo effect under different parameters. Based on the proposed model, the visual perception experiment of the system was designed to investigate the perception of the human eye on the halo effect under different Mini-LED backlight block sizes, LCD contrasts, and backlight modulation algorithms. The experimental results show that the Mini-LED backlight block size and modulation algorithm significantly influence the halo effect, whereas the LCD contrast has no significant impact on halo effect perception. With an increase in the block size of the Mini-LED backlight, the halo effect is significantly enhanced. When the backlight block viewing angle is 0.5° or larger, the subject can easily perceive the halo effect. In addition, a high linear correlation exists between the subjective experimental results and the objective evaluation results. This study provides a theoretical reference for designing Mini-LED backlight LCD systems.
A solving spherical target imaging coordinate method based on monocular vision for resolving the deviation between the two-dimensional elliptical image center and the actual spherical center imaging coordinate in the monocular vision measurement system of the spherical auxiliary target is proposed as a result of this non-collinearity of the optical axis and the spherical center. First, the monocular imaging system is calibrated, the factors influencing the deviation between the spherical center imaging coordinate and the corresponding two-dimensional elliptical image center are examined, and the monocular spherical center imaging coordinate solution model is developed. Second, the improved Zernike moment method is used to realize the edge sub-pixel extraction of ellipse images. The simulation results demonstrate that the ellipse center positioning accuracy of the improved Zernike moment method is enhanced by more than 25.00%. Finally, the experimental plan for the monocular measurement of the spherical target distance is created, and the experimental validation is done on spherical targets with various intervals. The findings indicate that the maximum absolute deviation between the spherical target moving distance calculated by the proposed method and the actual value is less than 0.039 mm, which meets the requirements of target positioning accuracy and stability of monocular vision robot system.
Considering the non-effectiveness of traditional convolution neural networks in detecting pattern defects in yarn-dyed fabrics, a defect detection method based on a U-shaped Swin Transformer reconstruction model and residual analysis is proposed. This method uses the Transformer model to improve the extraction of global image features and enhance reconstruction while solving for the small number and unbalanced types of defective samples during the actual production process. First, the training process of the reconstructed model is completed for a certain pattern using the non-defective samples after adding noise. Subsequently, the test image is inputted into the model to obtain the reconstructed image, and its residual image and reconstructed image are calculated. Finally, the defect areas are detected and located via threshold segmentation and mathematical morphology processing. The results indicate that this method can be effectively used for the detection and location of defect areas on multiple yarn-dyed fabric patterns without requiring the marking of the defective samples.
In this study, a multi-workpiece grasping point location method based on collaborative depth learning is proposed to solve the problems of disorderly placement and mutual occlusion of multiple workpieces in industrial production lines, such as missing inspection, wrong inspection, and difficult grasping point location. First, YOLOv5 is used as the basic network, and a data preprocessing module is added at the input end for angle transformation during image enhancement. Subsequently, a feature thinning network is added to the detection layer to realize the recognition and positioning of rotating workpieces via rotating anchor frames, and a lightweight Ghost bottleneck module is used to replace the bottleneckCSP module in the backbone network to eliminate the increased time cost due to the secondary positioning of the rotating anchor frames. Additionally, the fused feature maps are inputted into the attention mechanism module to obtain the key features of the workpiece. Subsequently, the image is clipped based on each workpiece detection frame, and the multi-workpiece detection is approximately transformed into single workpiece detection. Finally, the center of mass of the workpiece is obtained, and the grasping point is determined by combining the rotation angles of the detection frame. The experimental results show that the proposed method effectively solves the problem of locating the grab points of multiple workpieces close to or occluding each other. Furthermore, the method has higher detection speed and accuracy, which guarantees the real-time performance of multi-workpiece detection in industrial scenes.
A target detection algorithm for aerial images based on an improved attention mechanism is suggested to address the issue that the existing object detection network based on horizontal view images has a high false-positive rate and a high miss rate in aerial images. First, a trident channel and spatial attention module that extracts multi-mode and multi-scale characteristic map data of three-branch pooling layers and three-branch dilated convolution layers is added at the output of the Faster R-CNN backbone network so as to compress the data, thereby redistributing the weight of feature channels and spatial pixel regions. Second, a double-head detection mechanism is employed for the classification of the objects and bounding box regression in the aerial image to fully utilize the semantic and spatial location information. The suggested algorithm is further assessed on relevant datasets and contrasted with other object detection algorithms. The results indicate a significant enhancement of the mean average precision of the suggest algorithm, leading to better target detection for unmanned aerial vehicle images in various scenes.
An algorithm for binocular vision measurements based on local information entropy and gradient drift is proposed to solve the low detection efficiency, low matching accuracy, and insufficient binocular vision measurement accuracy of traditional feature detection algorithms. First, the image is divided into several sub-regions, the local information entropy of each sub-region is calculated to screen out the high-entropy regions, and the oriented FAST and rotated BRIEF (ORB) algorithm is used to detect feature points. Second, the circular neighborhood is used to replace the pixel points, and the gradient amplitude of each pixel in the circular neighborhood is improved using two-dimensional Gaussian weighting to improve the rotation invariant local binary patterns (LBP). Next, it is fused with the rotated binary robust independent elemental features (rBRIEF) to generate a new descriptor for feature matching. Finally, the gradient drift method is proposed. The sub-maximum response value of the feature point is introduced as the auxiliary factor. Combined with the maximum response value, the accurate coordinates of the ideal feature point are calculated through the iterative coordinate update, solving the inaccurate feature point coordinates and improving the measurement accuracy. The experimental results show that the average matching accuracy of the proposed algorithm is 37.51% higher than that of the traditional ORB algorithm, and the lowest relative measurement error is 0.365%.
We use Monte Carlo simulation and optical density algorithm to evaluate the detection performance of line-scan imaging system for internal defects of tested samples in this paper. First, a fine division for the irregular tissue boundary of the internal defects is achieved using a three-dimensional voxel segmentation method, as it is difficult to accurately simulate the optical transmission of complex tissues by the traditional Monte Carlo method. Then, the effects of the instrument parameters on the penetration depth of photons in the tissue, the detection depth of the detector, and the diffuse reflectance of surfaces are analyzed, and the optimal parameter configuration is determined. Finally, the optical density algorithm is used to evaluate the detection performance of the system for defects with different sizes and depths. The simulation results show that the line-scan imaging detection system can achieve a good balance between the photon detection depth and the surface reflectivity, under a light source with an incident angle of 15° and a distance of 1 mm between the light source and detector. For large (a=2 mm, b=3 mm, c=1 mm), medium (a=2 mm, b=2 mm, c=1 mm), and small (a=2 mm, b=1.5 mm, c=1 mm) ellipsoid defects, the defect depth detection limits of the system are 3.5 mm, 3 mm, and 2.7 mm, respectively. Hence, the study provides a theoretical basis for parameter optimization and performance evaluation of the line-scan imaging system for detecting the internal defects in agricultural products such as fruits.
The total lateral runout of the direct driver (DD) motor directly affects the positioning accuracy of DD. In real-time production, face runout is measured using dial indicators because of the complex measurement process for total face runout. This method can easily damage the surface of the measured object and is associated with inefficiency and low precision. To address this issue, a method to measure the DD motor end face runout based on point cloud driving is proposed. In this method, the point cloud on the DD motor surface is obtained using a linear laser sensor that incorporates laser triangulation to measure the distance of the object. The Z-axis measurement accuracy is 1.8-3.0 μm, and the repetition accuracy is 0.4 μm. Then, the point cloud is first compressed using a uniform down sampling algorithm and then segmented using a hybrid segmentation algorithm based on curvature and density. The segmentation of the compressed point cloud helps in obtaining the point cloud of the DD motor working face. The outliers in the point cloud of the working face are then analyzed and eliminated using an algorithm based on the Pauta criterion. Finally, the random sampling consistency algorithm is used to fit the point cloud plane to obtain the point cloud plane equation, and the plane is used as the reference to calculate the total end face runout of the DD motor. Our experimental results show that the measurement result of the proposed method exhibits about 12% error at the micrometer level compared to the reference result, indicating the effectiveness of the proposed method and confirming that it also meets the industrial precision requirements. In addition, the DD motor end face runout measurement software is developed based on the point cloud library, Qt, and Visual Studio platforms. The developed software realizes data display, point cloud processing, one-click measurement, data management, and other functions.
Extensive investigations of X-ray films of different lung diseases will help to precisely distinguish and predict various diseases. Herein, an algorithm for chest X-ray disease classification based on an efficient channel attention mechanism is proposed. The high-efficiency channel attention module is added to the basic feature extraction network in a densely connected manner to improve the transmission of effective information in the feature channel while inhibiting the transmission of invalid information. By using asymmetric convolution blocks to improve the ability of network feature extraction, the multilabel loss function is used to address multilabeling and data imbalance. The novel coronavirus pneumonia X-ray film is added to the public dataset, Chest X-ray 14, to form the dataset, Chest X-ray 15. The experimental results on this dataset show that the average area under curve (AUC) value of the proposed chest X-ray-film disease classification algorithm based on the efficient channel attention mechanism reaches 0.8245, and the AUC value for pneumothorax reaches 0.8829. Thus, the proposed algorithm is superior to comparison algorithms.
In this study, we report an improved hand-held full-field optical coherence tomography (FFOCT) system based on a combination of double interferometers. The system uses a Fizeau interferometer for detection and a Michelson interferometer for compensation. The initial system was modified by the addition of a plane mirror to alter its optical path and to make it easier to arrange samples horizontally. The analysis was conducted on how the system's imaging quality and compensation distance were affected by the angle deviation between the mirror and other key components of the system. The obtained results are useful for the design and optimization of the hand-held FFOCT system.
Inverse synthetic aperture LiDAR (ISAL) is a kind of coherent imaging system. It acquires images with speckles that affect target recognition and judgment. In recent years, some scholars proposes a model-based iterative reconstruction (MBIR) algorithm to solve the problem. The algorithm directly estimates the real valued reflectance instead of the complex valued one commonly used by traditional reconstruction methods, making the reconstructed image closer to the optical image. However, the MBIR algorithm faces the problems of complex optimization model, low efficiency, and difficult convergence when the gradient-free line search version is used. To address these problems, this study presents two proposals. First, the Markov relation between the distributions of the complex reflectance and reflectivity, and the measurement signal is obtained from the viewpoint of information transfer. The complex reflectance is assumed as a complete dataset of the reflectivity estimation that simplifies the optimization. Second, the surrogate function of a prior model, whose gradient is easier to obtain, and the logarithm transformation are used to improve the algorithm efficiency in which the original problem is transformed into an unconstrained problem with gradient. The effectiveness and efficiency of the proposed method are verified by simulation and outdoor experimental data from a target 7 km away. The results show that the proposed method can obtain better images within five iterations for echo data with carrier-to-noise ratio of 5 dB, 0 dB, and -5 dB.
Convolutional neural networks (CNNs) have achieved impressive results in hyperspectral image classification. However, because of the limitations of convolution operations, CNNs cannot satisfactorily perform contextual information interaction. In this study, we use the Transformer for hyperspectral classification to address the problem of capturing hyperspectral sequence relationships at extended distances. We propose a multiscale mixed spectral attention model based on Swin Transformer (SMSaNet). The spectral features are modeled using the multiscale spectral enhancement residual fusion module and the spectral attention module in SMSaNet. The spatial features are then extracted using the improved Swin Transformer module, and hyperspectral image classification is realized using a fully connected layer. SMSaNet is compared with five other classification models on two public datasets, that is, the Indian Pines and University of Pavia. The results show that SMSaNet achieves the best classification effect compared to the other models. The overall classification accuracies reach 99.51% and 99.56%, respectively.
This paper proposes a laser-camera fusion Gmapping mapping strategy to resolve problems of incomplete obstacle detection or unsatisfactory mapping effects when carrying lidar or an RGB-D camera on a mobile robot in Gmapping mapping. First, the camera point cloud and laser point cloud are preprocessed, and then point cloud fusion and filtering are performed by the point cloud library (PCL). The point-to-line iterative closest point (PL-ICP) algorithm is used to register the point cloud of adjacent frames to improve the matching accuracy and speed. Second, a visual odometer and a laser odometer are fused by the Kalman filtering algorithm, and the fused data and wheel odometer are dynamically weighted twice to improve the accuracy of odometers. Finally, the proposed method is verified on the built mobile robot. The experimental results show that the proposed method improves the obstacle detection rate by 32.03 percentage points and 19.86 percentage points, respectively, compared to the laser mapping and camera mapping methods, the size error of the map reduces by 0.014 m and 0.141 m, and the angle error decreases by 1° and 3°, respectively. The accuracy of the odometer is increased by 0.12 percentage points compared to the old odometer.
Sudden weather changes can endanger the middle and upper atmosphere lidar in observation. Hence, to ensure the safe operation of the lidar, the weather conditions of stations need to be monitored in real-time. Consequently, this paper develops an automatic weather identification system for a local weather station, using a night-sky image analyzer with digital image processing technology. Investigations reveal that the system can judge in real time whether the current weather conditions meet the lidar's observational conditions, subsequently giving an early warning when it will become bad weather in the next two hours. Furthermore, the continuous observation results of trial operations for one year show that the proposed system can meet the middle and upper atmosphere lidar automatic operation requirements with high stability and practicability.
To enhance the conversion speed of single-slope analog-to-digital converter (SS ADC) for low-noise CMOS image sensors, this study proposes a correlated multiple sampling (CMS) method based on SS ADC, which entails estimating the sampling time based on the input light intensity. Using the differential characteristic of the output signal of a digital-to-analog converter (DAC), the positive/negative ramp was selected according to input voltage. When the input voltage is low, the ramp shape was regulated such that there were four sampling times; when the input voltage is high, the sampling time was set to two. This design is based on 110-nm node CMOS process, and the clock frequency is 400 MHz, line conversion time is 23 μs, resolution is 11 bit, and quantization range is 1 V. The simulation results reveal that the differential nonlinearity (DNL) of this design is +0.6/-0.3LSB (LSB is least significant bit), and the integral nonlinearity (INL) is +0.7/-0.9LSB, with 82 μV being the minimum noise. Compared with conventional CMS method with sampling number of four, the A/D conversion time of the proposed method is saved by 13 μs without increasing noise under low light.
Aiming at the issue of co-frequency interference between shipborne radars in complex battlefield environments, an independent component analysis technique based on an improved crow search algorithm is proposed to separate co-frequency signals. First of all, the optimization performance and convergence speed of the algorithm are enhanced by utilizing the reverse learning method, dynamic perception probability, golden sine operator, and Levy flight. Then, the algorithm is integrated with the independent component analysis technique. Taking kurtosis as the objective function, the optimal separation matrix is determined by implementing the improved crow search algorithm. Finally, the matrix is applied to separate the received mixed signals. The simulation findings demonstrate that the proposed independent component analysis technique based on the improved crow search algorithm effectively separates the radar co-frequency signals and accomplishes the goal of anti-co-frequency interference.
To address the issues of extremely large image size, small target detection, and complex background interference in aircraft detection task of optical remote sensing image, an improved Faster R-CNN aircraft detection algorithm based on the fusion of lightweight feature extraction network and attention mechanism is proposed. The proposed algorithm's ability to detect small targets is significantly enhanced by removing the deep feature layer of small target detection redundancy, which also results in a 38.4% reduction in the number of network parameters, enabling lightweight processing and significantly improving the reasoning speed. To strengthen the feature extraction ability and weaken the background interference, convolutional block attention module is creatively presented only in the backbone of the feature extraction network, which successfully increases the detection ability of the model to aircraft targets. To avoid repeated reasoning and inconsistent prediction results, the midline single frame prediction post-processing mode is used in the test reasoning stage to predict the aircraft target in the overlapping area in a single frame. The experiment demonstrates that the improved algorithm achieves a final mF1 score of 88.97, which is 3.5% higher than the original algorithm on the optical remote sensing dataset.
The traditional angle constraint algorithm to detect lidar disorders can cause excessive cutting when facing the point cloud with a special angle or lack of point clouds. Therefore, an improved angle constraint three-dimensional lidar obstacle detection method is proposed. In this study, the point cloud is converted to a deep map, a new breakpoint detector is used to complete the initial segmentation and construct the chart structure, a point cloud collection is described, and the point cloud set that meets the cluster distance is combined by searching the graph node. Compared with traditional methods, the breakpoint detector enhances segmentation robustness. Also, the graph structure search solves overcutting caused by the lack of point clouds and accelerates clustering speed. Moreover, compared with traditional methods, the average time consumption of the proposed method is reduced by 51.4% while the average positive detection rate is increased by 11.5 percentage points.
The detection of street trees is crucial to the study of the urban ecological environment because they are one of the key components of an urban green space landscape. Given the low applicability and accuracy of the mobile laser scanning point cloud trunk detection method, a method based on multilayer aggregation for identifying the trunk of the street tree point cloud is proposed. On the basis of point cloud filtering and density clustering preprocessing, this method filters point clouds of street trees using multi-feature constraint method according to the variation between urban street trees and other typical features. Then, the bottom-up multilayer clustering and cluster aggregation method is applied to complete the detection and extraction of the trunk point cloud. In this experiment, two groups of roadside tree point clouds with different complexities are carried out to validate the method. The results demonstrate that the proposed method can efficiently complete the extraction of roadside tree trunks with various scene complexities. The accuracy, recall, and F-measure of the extraction results are 93.1%, 94.4%, and 93.7%, respectively. In conclusion, the proposed method can be used to detect the trunk of roadside trees with large density differences and incomplete point clouds.
A rotation remote sensing target detection algorithm based on multi-scale feature extraction is proposed, because high-resolution remote sensing images have large object scale differences, dense small-object arrangements, and strong orientation. In this study, CenterNet was chosen as the benchmark model and redesigned. First, to improve the context information extraction ability, we proposed and applied the receptive field expansion module combined with multi-scale cavity convolution. Second, the extraction ability of the algorithm for multi-scale targets was improved in combination with adaptive feature fusion. Finally, we redesigned the CenterNet detection head and updated the loss function to improve the detection performance of the model for rotating objects. The designed model is named CenterNet for remote sensing images (CenterNet-RS). Experiments were performed on the DOTA dataset, and the mean average precision (mAP) of CenterNet-RS reaches 73.01%, which is 9.45 percentage points higher than the baseline model. Thus, the experimental findings demonstrate that the proposed method can significantly increase the target detection accuracy for remote sensing images.
To address the practical issues of few pixels, limited information, detection difficulties, and misalignment of small objects in remote sensing images, this paper aims to improve the YOLOv5 and proposes a technique of boosting residual connections and cross-layer attention to improve the model's detection capability for small objects in remote sensing images. To effectively improve the detection capability of YOLOv5 for small objects in remote sensing images, the method employs residual linking for feature maps and the addition of detection heads. Furthermore, using cross-layer attention, this paper attaches semantic informations to the features of different network layers, improving the model's ability to suppress complex background informations in remote sensing images. In the experiments on the Detection in Optical Remote (DIOR) remote sensing dataset, the proposed approach achieves a mean accuracy precision (mAP) of 86.4% and a small object detection accuracy evaluation metrics (APs) of 23.4%, which is 5.9 percentage points higher than the benchmark network. The experimental results show that the method proposed in this research performs well in small object detection problems in remote sensing images, and it also confirms that the bottom feature map and attention mechanism in the feature pyramid are critical for improving small object detection performance.
Based on the characteristics of magneto-optical switch, such as fast switching speed, high reliability, and low cross talk, a time division multiplexing solid-state lidar based on a fiber magneto-optical switch is proposed. First, the working principle and properties of the time division multiplexing solid-state lidar based on a fiber magneto-optical switch are discussed and examined, and the performance indexes of the magneto-optical switch related to the performance of lidar are tested, including delay time, switch rising edge time, insertion loss, and return loss. Then, a time division multiplexing solid-state lidar system was constructed based on the 1 × 8 optical fiber magneto-optical switch. A time-of-flight (ToF) ranging technology was used to quickly achieve three-dimensional (3D) imaging of the lidar by switching the optical path to the fiber channel at various locations of the two-dimensional beam array. Finally, the 3D point cloud map of the measured object was built in the experiment to confirm the system's all-solid-state 3D imaging capability. The scanning frequency of 510.3 Hz and angular resolution of 0.36° are achieved, and the angular resolution is increased to 0.18° by the microjitter translation platform. The developed technique has advantages over micro-electro-mechanical system (MEMS) and optical phased array beam imaging technology, including low cost, high energy utilization, and good beam quality.
Based on the principle of chromatic aberration confocal microscopy, the chromatic confocal microscopy (CCM) technology utilizes different focal positions of different wavelengths to achieve effective depth measurement; moreover, CCM employs a confocal setting to filter out defocused and stray light to improve the signal-to-noise ratio. This paper first introduces the basic principles of CCM and different scanning schemes, then reviews the development of CCM, and expounds the research progress of CCM at home and abroad. Considering the key issues such as optical design, signal generation model, spectral data processing, and crosstalk reduction, this paper summarizes relevant research schemes. CCM technology has several advantages such as nondestructive testing, high resolution, high signal-to-noise ratio, and effective tomography. Thus, it can be broadly utilized in various fields, including the biomedical, industrial testing, and other fields.
The traditional optical inspection of physical evidence has some drawbacks, including difficulties in obtaining sample spatial structure, poor pertinence, and cumbersome operation process. Optical coherence tomography (OCT) has the benefits of being in situ, noninvasive, high resolution, high speed, and low cost, which has potential uses in the field of forensic research. Through literature analysis, this study introduces the imaging principle of OCT. This study analyzes the viability of using OCT in the field of material evidence identification to apply this technology in many forensic science research directions, such as fingerprint inspection, forensic science, document inspection, and biological evidence inspection. The research and development ideas, methods, and application prospects of OCT in the field of forensic science have been examined.