








Please enter the answer below before you can view the full text.
2-1=

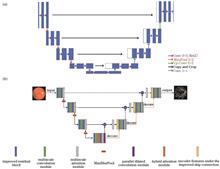
Some existing retinal vessel segmentation methods have been unsuccessful in distinguishing weak blood vessels and have suffered from blood vessel segmentation disconnections at intersections. To solve this problem, a multi-scale U-shaped network based on attention mechanism was proposed in this paper. In the encoding part, the proposed algorithm employed the improved residual block structure to extract the depth features of blood vessels while effectively solving the overfitting problem. In turn, the multi-scale convolution module and multi-scale attention module were used to obtain multi-scale feature information of the depth features. Then, MaxBlurPool was used as the pooling method to reduce dimensions of data and ensure the translation invariance. In addition, hybrid attention module and parallel dilated convolution were presented in the last encoding layer, where the former emphasized the information that needs to be focused from the channel and space dimensions to suppress the interference of the background area and the latter was used to obtain the characteristic information of receptive fields with different sizes while not introducing redundant parameters to cause computational burden. In the decoding part, skip connection was improved to suppress noise and obtain more abundant context information. The proposed algorithm achieved better segmentation effect than other methods on public fundus datasets.
A remote sensing rotating target detection approach based on a sparse Transformer is proposed to address the problem of remote sensing image target detection, which is challenging due to the wide neighborhood sparse, multi-neighborhood aggregation, and multiple orientations characteristics. First, this method uses the K-means clustering algorithm to produce multi-domain aggregation, to better extract the target features in the sparse domain, based on the typical end-to-end Transformer network, and the characteristics of a remote sensing image. Second, to adapt to the basic characteristics of the rotating target, a learning technique based on the target bounding box’s center point and the frame features is proposed in the frame generation stage, to efficiently obtain the target regression oblique frame. Finally, the network’s loss function is further optimized to improve the detection rate of the remote sensing target. The experimental results on DOTA and UCAS-AOD remote sensing datasets show that the average accuracy of this technique is 72.87% and 90.4%, respectively; thus indicating that it can adapt effectively to the shape and distribution characteristics of various rotating targets in remote sensing images.
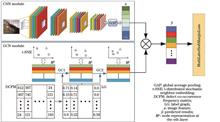
A drainage pipe image contains many defects, such as deformation and leakage. Considering that existing convolutional neural networks (CNNs) ignore the label relationships and make it difficult to accurately detect multilabel pipeline images, graph convolutional networks (GCNs) were introduced to model the relationships between different defect labels and improved label graph GCN (ILG-GCN) model was proposed. First, the ILG-GCN model introduced the GCN module based on the original CNN model. GCN used label graphs to force classifiers with symbiosis to be close to each other and obtain classifiers that maintain semantic topology, thereby improving the probability of predicting symbiotic labels. Second, the label graph used by the GCN module to update node information was improved. The improved label graph calculated the adaptive label symbiosis probability for each defect based on the symbiosis strength of the main related labels and assigned different weights to the main related labels according to their symbiosis strength. The experimental results show that the mean average precision value of the proposed model is 95.6%, suggesting that the model can accurately detect multiple pipeline defects simultaneously.
We proposed an approach to remove the noise in the γ radiation scene image based on the video time-series correlation considering the challenges of patch noise in the scene images generated using the complementary metal-oxide-semiconductor (CMOS) image sensor in a γ radiation environment. First, according to the foreground patch noise’s background-related and transient characteristics in the γ radiation scene video, which are both included in the time series correlation characteristics, the frame difference and statistical analysis approaches are employed to generate the bright and dark patch noise’s location distribution in the γ radiation scene image from the video sequence image’s residual. Then, through the frame number judgment model designed by the cumulative radiation dose borne using the CMOS image sensor, the adjacent frame images required to effectively repair the current frame image are generated. The effective pixel value is set in the adjacent frame with the same position as the current frame image patch noise and is not affected by radiation interference using the adaptive threshold mechanism and location distribution of bright and dark patch noise and transient characteristics of the patch noise, and the effective pixel value’s mean value is employed to recover the noise pixels. Finally, the Laplacian sharpening filter is used for image postprocessing to enhance the image quality. Experimental results demonstrate that the proposed approach has a higher peak signal-to-noise ratio, structured similarity indexing method value, and subjective perception satisfaction than numerous denoising approaches, which indicates that the approach has higher denoising efficiency and rich detail preservation.
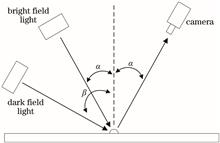
In this study, a defect detection approach for lithium battery electrode coating is proposed, which employs an imaging approach with multiple line-array cameras and double light source stroboscopic illumination, and distributed parallel image processing techniques. Especially, bright and dark light sources are employed for stroboscopic illumination in this approach, and two high-speed line scan cameras take the bright and dark field images alternately at the same position, which enhances not only the resolution for defect detection but also the detection efficiency. The master-slave distributed processing architecture is used in the image processing stage. Two industrial control computers process the image data coming from each camera in parallel, and the defect data obtained are sent to the host computer via TCP/IP for data fusion and defect classification. The experimental findings demonstrate that the lithium battery electrode coating detection system using this approach can achieve online detection and has a high practical value.
This study proposes a real-time layout estimation method based on an improved lightweight network to simplify the network structure of layout estimation and improve the use of output features. A lightweight coding and decoding network was used to obtain the main plane segmentation images of indoor scenes directly end-to-end and realize real-time layout estimation. Aiming at the problem of low feature usage in previous joint learning methods, a simplified joint learning module was introduced and the gradient of the output segmentation graph was used as the output edge. Additionally, the loss of the edge was directly integrated into the output loss of the entire network to improve feature utilization and simplify the joint learning network. Aiming at the imbalance of positive and negative labels of dataset and the imbalance of layout type distribution, to improve the stability of network training, segmentation semantic transfer was used to initialize the network parameters in this paper using the semantic segmentation network parameters trained on the LSUN dataset. The performance of the proposed method was evaluated using two benchmark datasets. The results show that the average pixel error of the proposed method is 7.35% and 8.32% on the LSUN and Hedau datasets, respectively. Ablation experiments prove the effectiveness of hierarchical supervision, simplified joint learning, and semantic transfer mechanism for improving accuracy. Finally, the experimental results show that the proposed method can estimate accurate indoor scene layout in real-time.
In this paper, we proposed an adaptive region fitting non-uniform image segmentation algorithm to solve the low segmentation accuracy of the traditional level set method in segmenting uneven grayscale images. First, we constructed an adaptive region fitting energy term to retain more detailed information in the local region of the image to be segmented, and to achieve accurate image segmentation. Second, we applied a non-convex regular term to smooth the curve and protect the edges of the image. Furthermore, we added an energy penalty term to constrain the level set function and improve the algorithm’s segmentation efficiency. Finally, the synthetic and real images were verified by experiments. Experimental results show that the average Dice similarity coefficient, Jaccard similarity coefficient, and accuracy of the proposed algorithm are 88.62%, 79.86%, and 92.48%, respectively, which are 18.19 percentage points, 16.10 percentage points, and 13 percentage points higher than those of Local Binary Fitting (LBF), Local and Global Intensity Fitting (LGIF), and Local Pre-fitting (LPF) respectively.
To address the problems of uneven illumination, low contrast, and excessive surface interference grinding texture in the image of a magnetic tile, this paper proposes a magnetic tile surface defect detection algorithm based on improved homomorphic filtering and Canny algorithm. First, the magnetic tile images were decomposed into high- and low-frequency images using the improved homomorphic filter transfer function. Moreover, the high-frequency images were enhanced through successive mean quantization transform. Second, the enhanced high- and low-frequency images were fused to obtain a magnetic tile image with uniform illumination and high contrast. Furthermore, the Gaussian filter in the traditional Canny algorithm was replaced by relative total variation to extract the magnetic tile defect structure. To improve edge detection accuracy, the gradient direction template was also employed to obtain the gradient amplitude and direction of image pixels, with the single threshold based on image gray information being used to extract the image edge defect, improving the robustness of the algorithm. Finally, the detected image edge defect was filled by morphological processing, and the interference edge was removed to obtain the defect area of the magnetic tile. Experimental results show that the proposed algorithm is effective in detecting the surface defects of magnetic tiles, the detection accuracy is high, and it is suitable for many types of surface defects of magnetic tiles.
In the field of Terracotta Warriors protection, to reduce the challenge of matching and splicing fragments of the Terracotta Warriors, more computer-aided technology is applied to the core link’s debris classification in the restoration of the broken Terracotta Warriors. The classification accuracy is low because of insufficient characteristic extraction of traditional Terracotta Warriors debris classification approaches and increased difficulty associated with data collection. In this paper, a depth classification model of Terracotta Warriors fragments based on data enhancement is presented. First, the existing dataset of Terracotta Warriors fragments was improved using conditional generative adversarial nets to achieve the dataset’s expansion of Terracotta Warriors. Second, the deep convolutional neural network was employed to automatically and effectively extract the debris feature information and achieve an effective debris classification effect. Third, the double-channel attention mechanism of the convolutional block attention module (CBAM) and the CutMix enhancement strategy were effectively introduced to significantly improve the deep classification model’s performance. Results on the experimental dataset of the Terracotta Warriors reveal that the presented approach is more accurate than the traditional classical debris classification approaches based on geometric, scale-invariant feature transform, and shape features as well as the multifeature fusion. It can effectively reduce the subsequent restoration work’s complexity, such as matching and stitching, and therefore improve the overall efficiency of the Terracotta Warriors’ restoration work.
To reduce the blur phenomenon in real millimeter-wave radiation images, a blind deblurring method of millimeter-wave radiation images based on residual scale recursive network (RSEN) is proposed. RSRN adopted a multi-level residual recursive structure and added cascading residual connections and multi-scale recurrent connections to the encoder-decoder network structure. It completely utilized the multi-scale feature information of millimeter-wave radiation images while improving model performance, thus making the networks training more stable. Finally, the millimeter-wave radiation image was deblurred in an end-to-end manner. The results demonstrate that, when compared with the existing image deblurring methods, this method eliminates the blur better while retaining the detailed information, and provides better qualitative and quantitative results.
For human pose estimation, a high-score representation method is usually adopted for detecting key points; however, this detection is difficult to achieve because of numerous network parameters and complicated calculations. In this study, to realize a closer connection between layers and achieve an enhanced lightweight nature, the densely connected network (DenseNet) is employed and densely connected layers are proposed. The network calculation parameters are reduced while the detection accuracy is maintained, and the network computing speed is optimized. Second, a fusion method that combines upsampling and deconvolution modules in the multiscale fusion stage is proposed, facilitating more abundant output feature information and more accurate detection results more accurate. Finally, the COCO 2017 and MPII datasets are used for validating the proposed method. Experimental results show that compared with other human pose estimation algorithms, the proposed method achieves an average network accuracy of 74.8%, reduces the number of operating parameters by 63.8%, and decreases the network calculation complexity by 8.5% while ensuring the accuracy of real-time effects.
A multi-angle facial expression recognition algorithm combined with dual-channel WGAN-GP is suggested to address the concerns of poor performance of standard algorithms for multi-angle facial expression identification and bad quality of frontal face pictures generated under deflection angles. Traditional models only use profile features to recognize the multi-angle facial expression, which leads to low recognition accuracy due to small differences in characteristics. As a result, the generative adversarial network is used to frontalize the face first, removing the impact of the pose angle. To stabilize the training of the model and improve the quality of face generation, WGAN-GP is used as the baseline and improved into a dual-channel structure, which fuses the facial features and the global features of the face for frontalization. Finally, the lightweight network MobileNetV3 is built to detect the produced frontal facial expression photos, ensuring classification accuracy while drastically reducing parameter calculation. The experimental results demonstrate that the proposed method can well generate the frontal facial expression images at any angle and enhance the recognition rate of multi-angle facial expressions.
In order to fully extract the spectral-spatial features of hyperspectral image (HSI) and to achieve high-precision ground object classification of HSI, an end-to-end multi-scale feature fusion identity (MFFI) block is proposed. This block combines 3D multi-scale convolution, feature fusion and residual connection. Through this block, multi-scale spectral-spatial joint features of HSI can be extracted. Because of the end-to-end feature of the block, the final MFFI network can be obtained by stacking multiple MFFI blocks. The average overall accuracy of 99.73%, average accuracy of 99.84%, and Kappa coefficient of 0.9971 are obtained on three HSI datasets: Salinas, Indian Pines and University of Pavia. The results show that the proposed MFFI block can effectively extract the spectral-spatial features of different types of ground object datasets and achieve satisfactory classification results.
Aiming at the complicated problem of cloud image feature extraction method of all-sky imager, we propose a cloud-type classification model, that is, a dual-path gradient convolutional neural network (DGNet), by combining a double-line dense structure and gradient information to optimize the ability of the network to learn features of cloud images. The classification model is constructed using dual-thread parallel dense modules, and a gradient algorithm is applied to the feature maps. Experimental results show that compared with classic models, the accuracy of the proposed model improves significantly, reaching 67.00%. The main contributions of this study are as follows: the proposed model adopts a multithread and multiscale gradient dense module structure to reduce the loss of feature information; The gradient algorithm is used to fully extract the gradient change features of the cloud image to enhance the model’s accuracy for recognizing cloud species; A new data set of all-sky images is proposed, which contains 10 types of cloud images and 100 images of each type, accounting for 1000 images; Compared with the existing models, the proposed model shows the best accuracy, proving the feasibility of the proposed model.
An adaptive depth image hole inpainting algorithm is proposed herein to address the problem of the depth image being affected by the depth value of external objects during the process of edge inpainting. First, the edges of the depth image and RGB image were extracted, then the false edge caused by holes was removed and the edges were fused. The size of the filter window was then determined using the fused edge information and effective pixel ratio. The weight parameters of spatial distance were set on the basis of the relationship between filter window and spatial distance. The maximum structural similarity between the depth image and RGB image was used as the color weight parameter. Finally, a median filter was used to remove edge hole pixels and discrete noise. The proposed algorithm is tested using the Middle bury dataset and NYU Depth Dataset V2 and compared with other algorithms. The results show that the proposed algorithm can repair holes in the edge area more effectively, maintain clearer object edge contour information, and has high robustness.
In recent years, convolutional neural network (CNN), as a representative of the deep learning method, has gradually become a research hotspot in the field of hyperspectral image (HSI) classification because it does not require complex data preprocessing and feature design. In this paper, a deep CNN model with an attention mechanism is proposed based on an existing neural network model combined with the HSI data characteristics. The model used a residual structure to construct a deep CNN to extract spatial-spectral features and introduced a channel attention mechanism to recalibrate the extracted features. According to different importance levels of features, the attention mechanism assigned different weights to features on different channels, highlighted important features, and controlled unimportant features. Experiments were conducted at Indian Pines and Pavia University to validate the proposed technique. When the spatial size of the dataset was 19 × 19, the Indian Pines and Pavia University datasets were divided into 3∶1∶6 and 1∶1∶8, respectively. Additionally, these datasets have the best classification accuracy. The average overall accuracy, average accuracy, and average Kappa coefficient obtained are 99.55%, 99.31%, and 99.45%, respectively. The experimental results show that deep CNN with residual structure can extract high spatial-spectral features of the HSI. Additionally, the attention mechanism recalibrates the features to strengthen the important features, thereby effectively enhancing the HSI’s classification accuracy.
Computational ghost imaging (CGI) has been widely studied owing to its high resolution and robustness. In contrast with traditional imaging schemes, CGI requires large amount of measurements to be taken for reconstructing a single image; thus, the efficiency of CGI needs to be improved. In this context, wavelet transform has attracted much attention because it can better decorrelate and then significantly compress a signal. By introducing Haar wavelet transform into the CGI scheme, the imaging speed has been significantly improved. However, because of the presence of various types of wavelets with different features, the application of other wavelets in the CGI scheme is scarcely reported. Because many wavelets are unorthogonal, they can only perform continuous wavelet transform, which may bring problems when applying them to the CGI scheme. Thus, a semicontinuous wavelet transform scheme was proposed. A CGI based on Mexihat and Gauss wavelets (both in 1D and 2D) were experimentally realized. The experimental results show that the two continuous wavelet schemes can perform normal imaging and show stronger antiinterference ability than Haar wavelet, which are more suitable for practical applications.
Aiming at the problems that traditional visual simultaneous localization and mapping (vSLAM) systems cannot remove moving objects in dynamic scenes effectively and lack semantic maps for high-level interactive applications, a vSLAM system scheme was proposed. The scheme can remove moving objects effectively and build semantic octree maps representing indoor static environments. First, Fast-SCNN was used as a semantic segmentation network to extract semantic information from images. Meanwhile, a pyramid optical flow method was used to track and match feature points. Then, for step sampling of the feature points, a stepping random sampling consistent algorithm (Multi-stage RANSAC) was used to perform the RANSAC process on different scales several times. Later, the epipolar geometry constraint and semantic information extracted from the Fast-SCNN were combined to remove the dynamic feature points of the visual odometer. Finally, the semantic octree map representing the static indoor environment was built by the point cloud after using voxel filtering to reduce redundancy. Experimental results show that the performance indicators of a camera, including relative displacement, relative rotation, and global trajectory errors in the 8 RGB-D high dynamic sequence of common datasets TUM RGB-D, are improved by more than 94% compared with the ORB-SLAM2 system, and the global trajectory error is only 0.1 m. Compared with a similar DS-SLAM system, the total time for eliminating a moving point is reduced by 21%. After voxel filtering, the semantic point cloud and octree maps occupy 9.6 MB and 685 kB storage space, respectively, in terms of map construction performance. Compared with the original point cloud of 17 MB, the semantic octree map occupies only 4% of the storage space; therefore, it could be used for high-level intelligent interactive applications due to its semantics.
A recognition and tracking network for dense neutrophil cells in the zebrafish tail was designed to address the problems that previous algorithms have low accuracy in recognizing dense cells and wrongly connected spatial trajectories. In this study, the enhanced mask region-based convolutional neural network (Mask R-CNN) was paired with the upgraded three-dimensional DeepSort to identify and track dense neutrophil cells. First, using self-built optical projection tomography (OPT) for image acquisition. Then, in the Mask R-training CNN’s module, we enhanced the Huber mask loss, adjusted the neural network parameters, and increased the gray-level dynamic range in the detection module to optimize the edge detection performance and achieve accurate cell recognition. Finally, the cell trajectory is reconstructed using DeepSort and the improved frame-by-frame correlation notion. Experimental results indicate that this method improves network training efficiency by ~50%, and cell segmentation accuracy reached 98.99% and 97.83% in XZ/YZ plane, respectively, which are significantly higher than the unimproved Mask R-CNN, U-Net, morphology, and watershed segmentation algorithms. Moreover, 75 visual zebrafish neutrophil trajectories were reconstructed. The proposed network can better recognize, segment, and reconstruct the pathway of highly overlapping cells and expand two-dimensional positioning into three-dimensional space than conventional networks. It serves as a guide for identifying and characterizing dense microorganisms and a useful model for cell stress response in pathogenic research.
Herein, we propose a face template protection method based on multifeature fusion to solve the problems of the poor effect of a single feature template protection algorithm and insufficient template protection before storage. In this method, two feature extraction algorithms were employed to extract different face features to achieve multifeature fusion protection. Furthermore, both features were used as masks in the feature transformation stage. The original image was encrypted using the double random phase mask technology. Before storage, we designed an improved scrambled algorithm based on partitioned magic square transformation to obtain the key from the image using the idea of key generation and properties of the adjoint matrix. To verify the performance of the algorithm, two face databases, ORL and EYaleB, were used. The results show that the scrambling degree of the scrambled algorithm can reach 0.0194 and 0.0187 in the ORL and EYaleB databases, respectively, and the recognition rate of the proposed template protection method reaches 97.12% and 96.90%, respectively. The three characteristics of template protection, namely, irreversibility, revocability, and unlinkability, perform well.
Since the volume of point cloud data captured by a three-dimensional laser scanner is large and leads to redundancy, occupying a lot of computer space and time cost in the later data processing. Thus, the point cloud data processing must be simplified. A hierarchical point cloud simplification algorithm is proposed on the premise of retaining the key geometric features for aiming at the scattered point cloud data model. First, the point cloud model's cuboid bounding box was constructed and divided into multiple small cube grids, so that each point was contained in the grid. Further, the weight of each point in each grid was estimated, and whether the point was preserved or not was determined by comparing the weight and weight threshold, to eliminate the noise points and achieve the point cloud's initial simplification. Finally, the simplification algorithm based on curvature classification was employed to achieve the point cloud's fine simplification. Through the simplification experiments of the common and cultural relic point cloud data model, the results demonstrate that, when compared with the random sampling, uniform grid, and normal vector angle approach, the algorithm has better geometric feature preservation performance, and can achieve better point cloud simplification effect that is an effective point cloud simplification algorithm.
The magnetically focused pulse-dilation framing image converter tube is an ultrafast diagnosis device with a temporal resolution within 10 ps and a spatial resolution that closely relates to the imaging magnetic field. In this study, a model of a pulse-dilation framing image converter tube was constructed and the spatial resolution of the point imaging distribution was calculated under the Rayleigh criterion. The imaging magnetic field was applied with emission areas of different radii, and the imaging magnetic field was optimized by finding the optimal on-axis and minimum difference between object points. In the pulse-dilation framing image converter tube with a magnetic lens, the overall spatial resolution was not improved by increasing or decreasing the magnetic field, but was optimized by the magnetic field of the specific emission area. When the lens aperture is 160 mm, the slit width is 4 mm, the axial width is 100 mm, the drift area is 500 mm, and the emission energy is 3 keV, the imaging magnetic field is optimized by setting the emission area radius to 8 mm and the maximum magnetic field along the axis to 37.87 × 10-4 Tesla. As the spatial resolution of the microchannel plate is 55 μm and the imaging is 1∶2, the spatial resolutions are 29.86 μm, 43.08 μm, 87.07 μm, and 276.88 μm at locations of 0 mm, 5 mm, 10 mm, and 15 mm on the object plane, respectively. The simulation results are consistent with the measured data. This work provides a reference method for establishing the relationship between the imaging magnetic field and overall spatial resolution and for optimizing the calculations of the spatial resolution simulation.
The details of cross-sectional images based on Fourier domain optical coherence tomography play an important role that is limited to nonuniform sampling, spectral dispersion, inverse discrete Fourier transform (IDFT), and noise. In this section, we propose a method for emphasizing axial details to the greatest extent possible. After removing spectral dispersion, uniform discretization in the wavenumber domain is performed based on two interferograms via a specified offset in depth, with no spectrum calibration. The sampling number in IDFT is optimized to improve axial sensitivity up to 1.62 dB. The proposed process has the advantage of being based on numerical computation rather than hardware calibration, which benefits cost, accuracy, and efficiency.
Urban drainage system is a crucial part of urban public facilities; thus, the regular inspection and maintenance of drainage pipe is essential for safely operating underground pipe network. The drifting capsule robot developed by the project team is characterized by its convenient operation, high efficiency, and inexpensiveness, which meet the requirements of large-scale survey of underground pipe network. However, the high-efficiency operation mode results in a huge amount of data that needs to be processed. Simultaneously, video data collected by drifting operation contains several unwanted features, such as vibrations and illumination, thus traditional data processing methods are unsuitable. Therefore, there is an urgent need to develop new intelligent disease recognition methods. This study presents a disease identification method based on an improved residual attention network. This method considered video clips as input, used convolutional neural networks to extract the features of each frame, and then fused different layers along specific dimensions for classification and recognition. Experimental results show that the improved method can achieve an accuracy of 89.6%, better than unimproved residual network, and effectively improve the recognition accuracy and efficiency of the drifting capsule robot.
To address the problem of insufficient image feature information and the accumulated error of visual-inertial odometry (VIO) in an outdoor complex environment, this paper proposes a VIO and global navigation satellite system (GNSS) algorithm based on a combination of point and line features. First, the paper designs a minimization strategy using geometric constraints, which performs constraint matching between the front and back frames on the extracted line features. In addition, an improved VIO-GNSS loose coupling model is built, in which the accumulated error in VIO pose estimation is suppressed using the global observation value of the GNSS. The experimental results in the KIITI data set and measured data set show that the proposed algorithm can maintain good accuracy and robustness compared with several similar algorithms in large outdoor complex environments with good/rejected/interrupted GNSS signals and meet the real-time requirements of driving positioning.
In this paper, we proposed an improved YOLOv4 algorithm model to solve the problems of low detection accuracy and slow detection speed of traditional indoor scene object detection methods. First, we constructed an indoor scene object detection dataset. Then, we applied the K-means++ clustering algorithm to optimize the parameters of the priori box and improve the matching degree between the priori box and object. Next, we adjusted the network structure of the original YOLOv4 model and integrated the cross stage partial network architecture into the neck network of the model. This eliminates the gradient information redundancy phenomenon caused by the gradient backpropagation in the feature fusion stage and improves the detection ability for indoor targets. Furthermore, we introduced a depthwise separable convolution module to replace the original 3×3 convolution layer in the model to reduce the model parameters and improve the detection speed. The experimental results show that the improved YOLOv4 algorithm achieves an average accuracy of 83.0% and a detection speed of 72.1 frame/s on the indoor scene target detection dataset, which is 3.2 percentage points and 6 frame/s higher than the original YOLOv4 algorithm, respectively, additionally, the model size is reduced by 36.3%. The improved YOLOv4 algorithm outperforms other indoor scene object detection algorithms based on deep learning.
Most existing crowd counting methods use convolution operations to extract features. However, extracting and transmitting spatial diversity feature information are difficult. In this paper, we propose an Involution-improved single-column deep crowd-counting network to mitigate these problems. Using VGG-16 as the backbone, the proposed network uses an Involution operator combined with residual connection to replace the convolution operation, thereby enhancing the perception and transmission for spatial feature information. The dilated convolution was adopted to expand the receptive field while maintaining resolution to enrich deep semantic features. Additionally, we used the joint loss function to supervise the network training, improving counting accuracy and global information correlation. Compared with the baseline model, the performance of the proposed method across the ShangHaiTech, UCF-QNRF, and UCF_CC_50 datasets considerably is improved, demonstrating that our approach outperforms many current advanced algorithms. Furthermore, results show that the proposed crowd counting method has higher accuracy and better robustness than other methods.
This research proposes a multi-scale attention feature fusion stereo matching algorithm (MGNet) to address the mismatching phenomenon of the current end-to-end stereo matching algorithm in challenging and complex scenes. A lightweight group-related attention module was designed. This module uses group-related fusion units to effectively combine the spatial and channel attention mechanisms while capturing rich global context information and long-distance channel dependencies. The designed multi-scale convolutional global attention module can process local information and global information at multiple scales, add non-local operations in the global feature processing stage. The module captures multi-scale and global contexts simultaneously, providing rich semantic information. In the cost aggregation stage, channel attention was introduced to suppress ambiguous matching information and extract differentiated information. Three datasets were used to analyze the proposed algorithm’s effectiveness. The results indicate that the proposed algorithm performs effectively in morbid areas like thin structures, reflective areas, weak textures, and repeating textures.
A three-dimensional (3D) lidar is the main sensing module of an unmanned surface vehicle (USV). The interference of water clutter will reduce the energy efficiency of target detection and affect autonomous navigation’s obstacle avoidance function. Based on 3D lidar, this study proposes a surface target DBSCAN-VoxelNet joint detection algorithm. The proposed algorithm employs a noise density clustering approach (DBSCAN) to filter surface clutter interference; a depth neural network VoxelNet is employed to divide surface sparse point cloud data into voxels, and the results are input into a Hash table for efficient query; the feature tensor is extracted through the feature learning layer, and the tensor is input into the convolution layer to obtain the global target information, resulting in high-precision target detection. The experimental results reveal that the proposed joint detection algorithm performs well in suppressing clutter in the water area, with a mean average precision (mAP) of 82.4%, which effectively enhances surface target detection accuracy.
This research proposes a saliency detecting approach based on an improved manifold ranking algorithm, aiming at the problem that green citrus has similar color features to the background in the natural environment, making the citrus difficult to be recognized. First, to avoid the increasing difficulty of recognizing caused by the uneven brightness of the green citrus images, the brightness improvement approach based on fuzzy set theory was employed to preprocess the orange images. Second, to resolve the issue that the traditional graph-based manifold ranking saliency detection algorithm relies on the boundary background to obtain the foreground seeds, resulting in the unsatisfactory effect of the saliency map, an approach combining relative total variation and local complexity was employed to extract more accurate foreground seeds. Finally, to sort the manifolds, the extracted foreground seeds were combined with the a priori saliency map of the boundary background without foreground seeds and the final saliency map was obtained. Experimental findings indicate that the proposed algorithm can recognize the green citrus region more effectively, and the segmentation accuracy, false-positive rate, and false-negative rate are 94%, 3.19%, and 1.64%, respectively.
The improper crimping height of the wire harness terminal leads to the wire core being cut off or having a large gap. In manual detecting number of wire cores and judging whether the wire core is broken after terminal crimping, there are many challenges, such as high labor intensity and visual fatigue. In this paper, a wire core detection method based on deep learning in the microscopic image of the wire harness terminal for counting is proposed. K-means multidimensional clustering algorithm was used to cluster the wire core bounding boxes to generate the anchor boxes that conform to the distribution of the core bounding boxes, aiming at the properties of dense and irregular arrangement of terminal wire core microimaging. The gradient equalization mechanism was used to reconstruct the loss function to deal with the extremely uneven category of anchor boxes with different attributes in the terminal image. The results show that the algorithm proposed in this paper achieves a mean average precision of 96.2% while maintaining the real-time performance and the same counting accuracy as the manual, compared with the other object detection algorithms. The proposed algorithm can be used for wire core counting and crimping quality evaluation of wire harness terminals.
Facial expression recognition is a challenging task for neural network applied with pattern recognition. Moreover, feature extraction is particularly important in the process of facial expression recognition. In this paper, a attention-split convolutional residual network was proposed to enhance the feature expression. This network used ResNet18 as the backbone network and replaced the basic block in ResNet18 with the coordinate attention-split convolutional block (CASCBlock), which is also proposed here. In the CASCBlock, two split convolutions were initially used to split and then fuse the features in the channel dimension to reduce redundant feature representations. Then, the coordinate attention mechanism was incorporated after the second split convolution. Finally, a fully connected classifier was developed for expression recognition. The proposed method was tested on the FER2013 and RAF-DB datasets, and the experimental results showed that the recognition accuracy of the proposed method on FER2013 and RAF-DB datasets is 2.897 percentage points and 2.575 percentage points higher than that of ResNet18, and the number of model parameters decreased by ~60% compared with ResNet18.
It is very challenging to reconstruct the 3D structure from a single image and perceive the semantic information of 3D objects. Aiming at the problem that it is difficult to directly generate a 3D reconstruction model from a single image input, a joint optimization network model combining PointNet and 3D-LMNet is proposed for single image 3D reconstruction and semantic segmentation. First, a 3D point cloud is generated by training based on the 3D-LMNet network, and then local segmentation is performed. Meanwhile, the network loss function is jointly optimized to predict the segmented 3D point cloud. Then, the reconstruction effect is improved through the semantics information of segmented point cloud, and a 3D point cloud reconstruction model is generated with semantic segmentation information. Finally, in view of the problem that there is no point-to-point correspondence between the true value point cloud and the predicted point cloud category label during the joint training, the joint optimization loss function is introduced into the joint optimization network to improve the reconstruction and segmentation effect, and the 3D reconstructed model is made. Through verification on the ShapeNet dataset, and comparation with PointNet and 3D-LMNet training, the model in this paper improves mean intersection over union (mIoU) by 4.23%, and reduces chamfer distance (CD) and earth mover’s distance (EMD) by 7.97% and 6.04%, respectively. The joint optimization network significantly improves the reconstruction and segmented point cloud model.
In the recycling process of waste glass, all types of impurities at the front end of the glass are removed manually by sorting. The degree of automation is low. The research background for this study is the manual sorting scene of a glass recycling and processing firm in Shanghai. This paper proposes a method of pipeline impurity glass detection based on the YOLOv4 algorithm. Moreover, typical sample images were collected in the field as the dataset, and the category of thin-tape glass was defined by indirect detection of both ends. Additionally, the Kmeans++ algorithm was used to reset the previous boxes (anchors), and the feature fusion was performed using a high-resolution feature map with a four times down-sampling rate to improve the detection performance for small targets. The results show that the mean average precision (mAP) of the proposed model is 97.88%, and the average precision (AP) for rubber strip glass is 95.47%. Compared to other methods, number of parameters of the proposed model is reduced by 31.11%, the AP for rubber strip glass is increased by 6.70 percentage points, and the detection speed is 42.82 frame/s, which can meet the real-time demand. Therefore, the proposed detection method is suitable for the visual component of the automated task of sorting impurity glass.
Commutative encryption and watermarking (CEW) is an emerging method that combines encryption technology with digital watermarking technology, which has double protection capabilities to achieve secure transmission and copyright tracking. In the field of multimedia data security, this method has been extensively used. However, existing algorithms have not considered the sensitivity and specificity of high-resolution remote sensing (HRRS) images; thus, they cannot completely protect HRRS images. This study proposes a CEW algorithm based on homomorphic encryption to solve this problem. First, partitioning is performed on the original image, and then integer wavelet transform is used to extract low- and high-frequency coefficients. Finally, the Paillier algorithm encrypts the low- and high-frequency coefficients of each sub-block, and the watermark is embedded in the low-frequency coefficient. The experimental results show that the proposed algorithm can achieve commutativity between encryption and watermarking and reconstruct the plaintext and ciphertext data’s watermark. In addition, the proposed algorithm has high encryption security and strong watermark robustness.
This study proposes the YOLOBIRDS algorithm to solve the challenges of several model parameters, high amount of calculation, and a considerable imbalance of positive and negative samples in bird detection tasks in natural scenes. The feature extraction network model was modified, and the standard convolution neural network structure was modified to the depthwise separable residual model. Additionally, the loss function was modified, and the object box size and position loss function were modified from mean square error to generalized intersection over union (CIoU). The confidence loss function includes the positive and negative sample control parameters. The experimental results show that in the Hengshui Lake bird dataset, the mean average precision (mAP) of the YOLOBIRDS algorithm reaches 87.12%, which is 2.71 percentage points higher than that of the original algorithm. Moreover, number of parameters reaches 12425917, which is 79.88% lower than that of the original algorithm. Finally, the speed reaches 32.67 frame/s, which is 19.98% higher than that of the original algorithm. The new model trained by the proposed algorithm has higher accuracy and faster detection speed, which greatly improves the overall recognition rate of bird detection and balances the loss weight of positive and negative samples.
To realize the three-dimensional reconstruction of space objects, the camera parameters need to be calibrated, and the calibration accuracy is the primary concern. Due to the low precision and slow convergence of traditional camera calibration method, an improved particle swarm optimization camera parameter algorithm based on dynamic adjustment and adaptive variation is proposed. The method takes the traditional calibration results as the initial value and dynamically adjusted the inertia weight of the group by defining the individual search ability, avoiding the influence of unreasonable setting of inertia weight on the algorithm search ability. In addition, the optimal particle variation is adjusted adaptively based on the degree of particle falling into local optimal, in order to improve the global search ability of the algorithm. The proposed camera parameter calibration method is compared with other calibration methods, experimental results show that the proposed algorithm has advantages.
The two important techniques for object detection are training samplers and localization refinement. To solve the problem of unreasonable distribution of positive and negative samples, and get better image classification features and localizations, this study presented an accurate and effective single step anchor-free algorithm for object detection. The algorithm consists of three modules: semantic based positioning, adaptive feature enhancement, and efficient localization refinement. Firstly, the positioning module proposes a semantic based sampling method, which distinguishes the front/background regions according to the semantic characteristics of the object, reasonably selects positive samples and negative samples, and preferentially selects the foreground region with large amount of semantic information as the positive samples. Secondly, the feature enhancement module uses the target semantic probability map and detection frame offset to adjust the image classification features pixel by pixel, increases the proportion of foreground features, and adaptively adjusts the feature coding range according to the object size. Finally, the localizations are optimized in parallel, and the classification loss is calculated for the localizations before and after optimization, which improves the positioning performance almost without cost, and ensures the feature alignment and consistency. In the MS COCO dataset, the proposed algorithm achieves 42.8% in average precision, the detection time of a single image reaches 78 ms, realizing the balance between detection accuracy and speed.
Intelligent transportation systems have been playing a major role in vehicle detection technology. Recently, the convolutional neural network (CNN) architecture is a popular method for vehicle detection. However, in complex traffic situations, only fewer pixels for long-distance small targets are available, and CNN’s subsampling mechanism seems to be lacking sufficient context information of some extracted features, which gives small target detection great challenges. A small target vehicle detection algorithm based on a visual Transformer was introduced in this paper to solve the aforesaid problem. By improving the linear embedding module of the Transformer, information on the small targets was supplemented. Additionally, the image was constructed hierarchically, and each layer was only related to the part. Modeling, while expanding, the receptive field, instead of CNN, was conducted to extract more powerful features from small target vehicles to achieve accurate end-to-end detection. Data was verified using the UA-DETRAC vehicle dataset. The experimental results showed that the improved vehicle detection algorithm enhanced the detection performance of small targets at long distances and under severe occlusion conditions and that the detection accuracy reached 99.0%.
A standing tree disparity image is the basis of tree factor measurement and 3D reconstruction. However, one challenge is its difficulty in obtaining high-quality standing tree disparity image due to the complex structure of standing tree images and large illumination interference in the natural environment. Combined with the characteristics of standing tree images, in this paper, we propose a method for generating a standing tree disparity image using improved semi-global matching (SGM) algorithm. To solve the problem of poor disparity image generated using the SGM algorithm when the image texture and illuminations are weak and unstable, respectively, we employ an improved Census transform to replace the Census center pixel value with the median of the surrounding pixels to improve the reliability of the initial cost. Furthermore, the mean shift algorithm is used for image segmentation in the process of cost aggregation to enhance the robustness of the algorithm and effectively reduce the false matching rate for repeated and weak texture regions. Finally, we adopt the adaptive window to fill in invalid values and apply a median filter to eliminate unreliable parallax values, so that the area with discontinuous disparity can also obtain accurate disparity value. The proposed method was verified on the Middlebury public dataset. The results show that the average mismatch rate of the proposed method is approximately 5.23%, compared with the traditional semi-global block matching (SGBM), Boyer-Moore (BM), and SGM algorithms with improvements of 9.47 percentage points, 9.345 percentage points, and 8.96 percentage points, respectively. In the natural environment, the proposed SGM algorithm can be used to generate a standing tree disparity image with higher accuracy.
For the effective use of the valid information contained in the flame image of the tail section of the sintering machine, the random forest algorithm is used to predict the sintering state in a short time. The algorithm is feasible in engineering. To improve the influence of low-importance properties in random forests on classification results, we propose a random forest improvement algorithm using probability decision, making to realize the short-term prediction of the flame state of the sintering machine tail section. First, 300 sintered section flame images were uniformly preprocessed, and geometric features of 10 images were given as input. Second, K-mean and fuzzy C-mean clusterings were performed on the geometric features of the 10 extracted images. Finally, the probability of each category appearing at the leaf node was given according to the accuracy of the clustering results. The experiment proves that the proposed optimized random forest algorithm improves the accuracy for sintering state classification.
Pose estimation is a major concern in machine vision. The iterative speed of the basic overlap pose estimation algorithm is slow. The initial point for iteration is selected as a weak perspective transformation, and the calculation result is easy to fall into the local optimal solution. Given this situation, this study proposes an improves forward overlapping pose estimation algorithm. Kronecker’s product optimizes the objective function of matter square residual, which reduces the complexity of orthogonal iterations and improves the calculation speed while ensuring iteration accuracy. The difference between the reference point and the reprojection point on the image is calculated using the idea of weighting, and different weights are given to the image square residual to reduce the effect of the error points on the results. The simulation and real experiments, when compared with the traditional normal superposition method and linear pose estimation algorithm, show that the algorithm effectively improves the calculation accuracy, speeds up the calculation speed, converges globally, and has higher practicability.
X-ray imaging is a commonly used diagnostic method with important clinical value in chest-disease diagnosis. Exploiting the release of large-scale available datasets, several methods have been proposed for predicting common diseases using chest X-ray images. However, most of the existing predictive models are limited to single-view inputs, ignoring the supportive role of multiview images in clinical diagnosis. Additionally when image features are extracted using a single model, the effective features are incompletely extracted and the accuracy of disease prediction decreases. The present study proposes a new depth-dependent multilevel feature fusion method (DFFM) that combines the visual features of different views extracted via different models to improve the accuracy of disease prediction. DFFM was verified using MIMIC-CXR, the largest available chest X-ray dataset. Experimental results show that the area under the receiver operating characteristic curve was 0.847, 12.6 and 5.3 percentage points higher than the existing single-view and multiview models with simple feature splicing, respectively. These results confirm the effectiveness of the proposed multilevel fusion method.
In this study, we investigated the discernibility of subcutaneous hemorrhage injuries and the time limit of the examination for obsolete subcutaneous hemorrhage using a multiband light source. Different discernibility effects were compared through light irradiation at of 365-, 415-, 450-, CSS, 490-, 510-, 530-, 555-, 570-, 590-, and 610-nm wavelengths using a multiband light source. Moreover, an invisible, obsolete subcutaneous hemorrhage was examined. The effect was relatively ideal under the irradiation of the 365-nm-wavelength light. A subcutaneous hemorrhage mark was detected up to 2 weeks in the invisible state. The proposed method is simple and fast, and it can provide an effective way and scientific basis for the forensic identification of obsolete subcutaneous hemorrhage injuries.
The accurate segmentation of hepatic vessels is critical for the preoperative planning of liver surgeries. However, the vascular trees in the liver are complicated and highly intertwined. The hepatic vessels’ accurate segmentation is a difficult task. Due to too many sampling layers in traditional 3D-UNet model, the detailed information of hepatic blood vessels get lost during network propagation. Thus, reducing number of sampling layers reduces the expression ability of the model. In this study, based on a 3D-UNet model, a recombination recalibration model is introduced to the network to enhance the transmission of detailed information in the channel and space while suppressing the information with poor correlation. Further, attention mechanism is introduced to the model to constrain the feature graph as a whole, enabling the model to focus on the blood vessels. Finally, the sampling layers are adjusted to ensure multiscale semantic information while avoiding the loss of detailed information caused by oversampling. The best Dice Score and Sensitivity of the proposed model are 64.8% and 73.15%, respectively. The experimental results show that the improved model outperforms MPUNet, UMCT, nnU-Net, and C2FNAS-Panc in liver vascular segmentation.
In order to better analyze the changes of vegetation and observe the growth status of forestry crops, point cloud data collected by ground-based LiDAR and hand-held LiDAR were adopted in this study to conduct classification research on vegetation through machine learning. At present, classification of vegetation based on feature combination of point cloud covariance matrix has redundancy in its features, and the classification effect of some features is poor. It is mainly reflected in the classification of the boundary of vegetation. To classify vegetation more accurately, this study investigated the point cloud classification based on covariance matrix feature extraction and Fisher algorithm feature selection, and proposed two features of input parameters of support vector machine (SVM) classifier, namely, area feature and pointing feature. In the data collected by the ground-based LIDAR, the weights of the two features that were calculated by Fisher algorithm were 7.25 and 5.78, respectively. The weight of the area feature ranked second only compared to the feature λ2 with the highest weight of 8.45 (λ2 is the eigenvalue of the point cloud covariance matrix). The overall classification accuracy using the original features is 99.15%; the overall classification accuracy was improved by 0.75 percentage points after the addition of the new features. Moreover, the classification effect of the junction of tree trunk, ground, and shrub was remarkable. The results showed that the proposed new feature combination has a higher weight coefficient, which can effectively improve the accuracy of vegetation classification. The classification effect of the data collected by the hand-held LiDAR was satisfactory. The overall classification accuracy reaches 99.74% after using the new feature, which verified the strong robustness of the classification algorithm.
In remote sensing image feature matching, only using feature descriptor similarity measurements results in a large number of outliers. It is important to remove reliably outliers from the initial matching results for improving the accuracy of feature matching and transformation parameter’s estimation. To solve this problem, a simple and effective outlier removal algorithm for remote sensing image feature matching guided by topology is proposed. The potential topological geometric constraints of matching point pairs were completely exploited, and the local and global outlier filtering strategies were presented. The neighborhood consistency of corresponding matching pairs was used, that is, the neighborhood point pairs of the correct matching pairs satisfied the consistency correspondence, and all outlier pairs not meeting the condition were eliminated through a local filtering. Then, based on the hypothesis verification idea of random sampling, global filtering was performed using spatial order constraints and affine area ratio constraints. The local optimization strategy was used to modify the maximum consistent inliers for accurately estimating geometric transformation parameters and reliably removing outliers. Finally, a spatial meshing method was adopted to refine the estimation model and increase the matching pairs to further improve the matching performance of remote sensing images. Compared with other outlier removal algorithms such as NBCS, LPM, LLT, VFC, GMT, SOCBV, and RANSAC, the proposed algorithm is more stable and achieves better performances particularly under complex conditions, including low inlier ratio, severe scale, and viewpoint change.
In this study, an individual mangrove object detection model called YOLOv5-ECA based on deep learning is proposed to automatically identify and locate individual mangroves with high accuracy aiming at the challenges of small and dense individual mangroves in drone images, resulting in low automation and efficiency for detecting them. First, the open-source software LabelImg is used to mark the target tree on the selected drone image, which is applied to construct the individual mangrove dataset. Then, the YOLOv5 is used as the basic object detection model to maximize and enhance the target tree, and achieving this is based on the characteristics of dense distribution and small size of objects. The efficient channel attention (ECA) mechanism enhances the CSPDarknet53 backbone network to avoid dimensionality reduction while enhancing feature expression capabilities. Furthermore, the enhanced SoftPool pooling operation is introduced into the SPP module to retain more detailed feature information. Finally, the ACON adaptive activation function determines whether the neuron is activated. The results demonstrate that the constructed dataset is used to train the network before and after improvement, and the accuracy, recall, and mean average precision (mAP)@0.5 parameters are compared. The results of different models are slightly different, but they all tend to converge. The proposed YOLOv5-ECA's average detection accuracy is 3.2 percentage points higher than YOLOv5 and 5.19 percentage points higher than YOLOv4, and its training loss is also lower. The deep learning-based YOLOv5-ECA model can quickly, accurately, and automatically detect individual mangroves and significantly enhance the ability to identify and locate them.
The task of detecting 3D objects in complex traffic scenes is crucial and challenging. To address the high-cost problem of high-definition LiDAR and the poor effect of detection algorithms based on the millimeter wave radar and cameras used in mainstream detection algorithms, this study proposes a 3D target detection algorithm using low-definition LiDAR and a camera, which can significantly reduce the hardware cost of autonomous driving. To obtain a depth map, the 64-line LiDAR point cloud is first downsampled to 10% of the original point clouds, resulting in an extremely sparse point cloud, and fed to the depth-completion network with RGB images. Then, a point cloud bird-eye view is generated from the depth map based on the proposed algorithm for calculating the point cloud intensity. Finally, the point cloud bird-eye view is fed into the detection network to obtain the geometric information, heading angle, and category of the target stereo bounding box. The different algorithms are experimentally validated using KITTI dataset. The experimental results demonstrate that the proposed algorithm can outperform some conventional high-definition LiDAR-based detection algorithms in terms of detection accuracy.
In this paper, we proposed a feature extraction and simplification algorithm for three-dimensional (3D) point cloud based on piecewise linear Morse theory to solve problems in difficultly deleting pseudo feature points, and generating noise characteristic lines after simplification of existing 3D point cloud topological feature extraction algorithms based on Morse theory. First, we calculated the function index to extract the feature points. Regarding the triangles comprising each feature points as a collection, we calculated the dot product of the normal vectors of two adjacent triangles in the collection. Herein, the dot product maximum was considered the weight of the point, and the appropriate threshold was set to remove the pseudo feature points. Second, feature lines were produced by connecting feature points to complete the construction of descending Morse complex. Finally, the persistence and the retention index considering the actual retention value of the feature lines were calculated, respectively, by choosing the function index value of different points on the feature lines. With both indexes, the origin persistence method can be improved to attain a new feature line measurement index and the simplification and expression of 3D point cloud topological feature can be accomplished. The results show that, compared with other algorithms, the proposed feature extraction algorithm significantly reduces pseudo feature points. Furthermore, the time efficiency of the proposed algorithm for constructing the descending Morse complex increases by 70.37%, and the point cloud compression rate increases 22.48%. Additionally, the new importance measurement method for feature lines attains more concise, continuous, and structural complete feature lines, and the feature extraction and simplification processes show strong anti-noise performance.
The laser scanner can precisely and efficiently conduct the three-dimensional reconstruction of the building's interior, and data registration of each station can offer complete 3D information. A point cloud registration approach based on curvature threshold is proposed to tackle the difficulty of registration with a large amount of point cloud data and a low coincidence rate. The point cloud's normal vector is employed to estimate the point's curvature. To obtain the input point cloud's characteristic point set, a suitable curvature's threshold is set to simplify the point cloud and take it as the characteristic point set. The point cloud registration algorithm that is based on probability distribution is adopted for coarse registration, to quickly and effectively conduct the point cloud's preliminary registration. For precise registration, the iterative closest point algorithm of KD-Tree acceleration is employed. Through comparison time and precision analysis with classic SAC-IC and other algorithms, the experimental results demonstrate that the registration accuracy is enhanced by more than 35% in scenes with a large amount of point cloud data and low coincidence rate, and registration time is enhanced by more than 30%, and reconstruction efficiency is enhanced by more than 30%.
In double-helix point spread function (DH-PSF) engineering, the PSF of the conventional imaging system is transformed into DH-PSF using a regulation of pupil surface wavefront phase of imaging system to realize large-depth, high-precision nanoscale three-dimensional (3D) imaging. The DH-PSF is widely applied in life-science and material-science research, industrial detection, and other fields. In this study, the basic principle of the DH-PSF and the design and application methods of the DH phase mask are described in detail. Based on these, the applications of the DH-PSF to depth estimation, nanoscale 3D single-particle tracking, super-resolution fluorescence microscopy, and laser scanning fluorescence microscopy are introduced. The advantages of the DH-PSF technology in these application examples are emphasized, providing a useful reference for research in related fields. Finally, the prospects of the development direction of the DH-PSF technology and its application are discussed.
In recent years, bacterial infectious diseases have been occurring, and the frequent use of antibiotics has led to a significant increase in the number of drug-resistant bacteria, and the phenomenon of drug resistance is becoming more and more serious. There is an urgent need for an efficient and accurate detection technology to make a judgment on the pathogenic bacteria. Different species of bacteria have different molecular compositions and structures. Surface-enhanced Raman spectroscopy (SERS) is used to distinguish and reflect the cellular state mainly due to its ability to reflect the unique spectral fingerprint of bacteria. The detection of pathogenic bacteria by SERS is influenced by several factors, and this paper introduces three aspects of SERS detection of pathogenic bacteria and provides a brief review. Firstly, the design of substrates is summarized in terms of different structures and sizes of SERS substrates for pathogenic bacteria. Secondly, the co-culture, in situ reduction and electrostatic binding of pathogenic bacteria for non-labeling detection and labeling detection including external and internal labeling methods for SERS detection of pathogenic bacteria are reviewed. Finally, the identification of pathogenic bacteria is combined with the traditional multivariate statistical analysis method of Raman spectroscopy of pathogenic bacteria and advanced machine learning algorithms, and the application of SERS in pathogenic bacteria detection is summarized and prospected.
The traceability analysis of material evidence has always been a tough area of forensic expertise, which is crucial for criminal investigations. This study proposes a new method for the detection and traceability analysis of human fingernail samples using attenuated total reflection Fourier transformed infrared spectroscopy (ATR-FTIR) combined with machine learning related methods. The ATR-FTIR of fingernails from 195 volunteers were collected. These volunteers came from 18 provinces located in the 7 regions of China. The dimensionality of the original spectral data was reduced via principal component analysis (PCA) and factor analysis (FA) after preprocessing. Multilayer perceptron (MLP), radial basis function (RBF), decision tree (DT), and support vector machine (SVM) models were used for classification and recognition. The experimental results show that in the subsequent modeling analysis, there is little difference between PCA and FA. The classification effect of the MLP is better than that of the RBF. The classification accuracy of the training set and test set of the PCA-DT model based on the CHAID algorithm can reach 91.0% and 92.0%, respectively, which are better than those of the exhaustive CHAID, CRT, and QUEST algorithms. PCA-SVM model based on the polynomial kernel function can fully distinguish fingernail samples from seven regions and five provinces in North China. Its classification accuracy is better than those of RBF, Sigmoid, and linear kernel functions. Therefore, the ATR-FTIR technology combined with the PCA-SVM model can accurately classify the fingernail samples from different regions. This study establishes a new method reference for analyzing the traceability of fingernail evidence.
Wavelength modulation signal (WMS) based on tunable diode laser absorption spectroscopy (TDLAS) is an effective trace gas detection technology. It offers several advantages such as high selectivity, high precision, and high sensitivity, as well as real-time online monitoring. In the field measurement process, background noise and optical fringes significantly reduce the system’s measurement accuracy, affecting the concentration measurement results. To effectively eliminate the effect of these noise on the measurement and improve the signal to noise ratio (SNR) of the system, this study proposes a digital filtering denoising method based on wavelet transform combined with empirical mode decomposition (EMD). The NH3 with low mass concentration was measured experimentally, and the wavelet transform filtering, EMD filtering, and wavelet transform combined with the EMD filtering were used to reduce noise in the obtained harmonic signals. The experimental results show that the wavelet transform combined with the EMD filtering has the best noise reduction effect compared to the other two methods. The SNR of the wavelet transform combined with the EMD filtering increases from 28.4 dB to 446 dB for NH3 with a mass concentration of 11.38 mg/m3. Thus, the proposed method significantly improves the system’s measurement accuracy.
In this study, a pulse-dilation framing camera using double magnetic lenses to correct aberrations is reported. The spatial resolution, field curvature, and astigmatism characteristics of the camera were analyzed. When the imaging ratio is 2:1, the radius of the working area of the framing camera with a single magnetic lens is 15 mm, and the spatial resolution at a 15-mm off-axis distance is 2 lp/mm. When double magnetic lenses are used in this system, some aberrations are corrected, the radius of the working area is 30 mm, and the spatial resolution at a 15-mm off-axis distance is 5 lp/mm. The field curvature of the camera with a single lens and double lenses was measured and simulated. In a single-lens imaging system, the axial distance between the imaging point at 15-mm off-axis of the field surface and the image point on the axis is around 11 cm, while in a double-lens imaging system, it is about 3 cm. The astigmatism of the double-lens system is analyzed. In the experiment, sagittal and tangential image surfaces are fitted, and the sagittal and tangential resolutions can reach 10 lp/mm.