







Please enter the answer below before you can view the full text.
6+2=

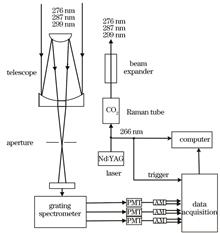
The simultaneous observation of ozone and aerosol in Wangdu County, Hebei Province was conducted using an ultraviolet multi-wavelength lidar to obtain vertical distribution information of ozone and aerosol under combined atmospheric pollution. The results show that atmospheric backscattering causes the largest ozone mass concentration error in the dual-wavelength differential absorption inversion algorithm, with a maximum average mass concentration error of 16 μg/m³. The three-wavelength differential absorption algorithm can reduce the influence of some aerosols. The extinction coefficients of the three lidar wavelengths are eliminated by ozone absorption based on the inversion of ozone mass concentration, and the aerosol extinction coefficients of each wavelength are obtained. Moreover, the aerosol parameter inversion results agree well with the AERONET aerosol optical depth (AOD) data. Finally, UV multi-wavelength lidar inversion results, HYSPLIT backward trajectory analysis, and MERRA-2 reanalysis data were used to examine the typical pollution weather in Wangdu County. By the inversion of ozone mass concentration at 300 m and AOD above 300 m, the changing trend of the two is opposite, and the inhibition effect of AOD on UV radiation is most obvious during midday. During the observation period, air pollution in Wangdu County may be affected by pollutants transported from the northwest.
Aiming at the phenomenon of color attenuation, surface blur, and uneven illumination in underwater optical images, we proposed an underwater optical image enhancement algorithm based on color constancy and multiscale wavelet. First, we adopt the gray world assumption to compensate the attenuation channel and use the color constancy to adaptively adjust the global brightness and contrast of the image to effectively correct the color shift. Second, combined with the characteristics of multiscale wavelet decomposition, we adopt morphological open operation to improve the dark channel transmittance to remove the low-frequency haze phenomenon, and the soft threshold reduces the high-frequency noise. Then, a two-dimensional gamma function is used to adaptively correct the uneven illumination, and sharpening is used to improve the edge detail. Finally, the weight map of the fused input image is defined: gamma correction and sharpening images, and the enhanced image is obtained by multiscale fusion. The experimental results show that the proposed algorithm can effectively balance the chromaticity and brightness of underwater optical images and significantly improve image clarity and detail information. Additionally, application tests show that the algorithm performs well in feature matching, low-light conditions, and edge detection.
The applicability of wind profiler radar products in Chengdu is investigated using L-band sounding radar data from the Wenjiang District Weather Station, Chengdu, from January 2020 to July 2020, based on the wind field and atmospheric refractive index structure constant (Cn2). At all levels, there is a significant positive correlation (p-1 smaller than the L-band sounding radar at the low level (-1 smaller than the L-band sounding radar at the high level (>2.5 km), and the effective sample rate of the horizontal wind speed fluctuates between 70% and 90%. Additionally, the effective sample rate of the horizontal wind direction of the wind profiler radar fluctuates growth with increasing altitude. When the atmosphere is moderately unstable, weakly unstable, neutral, or weakly stable, the Cn2 profiles retrieved by the wind profiler radar and L-band sounding radar agree well with each other at the same time. When the atmosphere is severely unstable or moderately stable, the Cn2 profiles retrieved by the wind profiler radar and L-band sounding radar show a significant positive correlation (p<0.05), but the two profiles have a large value difference. Precipitation is another important factor that affects the accuracy of the wind profile radar inversion, resulting in a significant increase in the horizontal wind speed inaccuracy.
Scattering and an uneven distribution of reflected light owing to the target surface texture are the main issues in extracting the structured light strip center in underwater. Herein, we proposed a new approach for underwater information acquisition. In this method, the targets are scanned using structured light for the convolution process, thereby solving the nonuniform distribution of a backscattered background because of nonuniform illumination. Furthermore, the uncertainty of noise fluctuations is reduced from a statistical viewpoint. A virtual aperture method is proposed to eliminate backscattering using this system. Moreover, a method for improving the accuracy of the center extraction is proposed using the restored image to remove the target surface texture, by using the method, conventional center extraction methods can be applied to the underwater targets containing texture, thus widening their application range. Underwater experiments were performed to verify the feasibility and effectiveness of the proposed method.
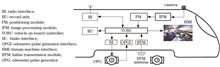
Accurate location information is absolutely vital for communications-based train control (CBTC) systems to ensure safe train running. For the present purposes, a high-precision approach to train positioning is proposed in this paper using optical camera communication and monocular vision measurement, which could present an effective solution to train positioning with high precision, low cost, low maintenance and anti-interference. The images of light emitting diode (LED) lamps are captured by a monocular camera, and the three-dimensional attitude angle of camera is measured by an inertial measurement unit. The coordinates and shape information of LED lamps are obtained by optical camera communication technology. The relative coordinates of the camera and LED lamps are acquired through the imaging principle and geometric relationship to realize the train positioning. According to the real-life line data and train parameters, experimental studies suggest that the maximum error of train positioning in the proposed method is 35.56 cm, the minimum is 1.78 cm, and the average is 12.26 cm, which can meet the requirements of train positioning accuracy for CBTC systems.
Aiming at the problem that digital holography technology measures three-dimensional micro-deformation on the surface of an object, which requires vector information in three different directions, and usually the detection optical path is relatively complicated, a three-dimensional deformation detection method based on multi-camera digital holography is proposed. First, a method is established to accurately reconstruct the phase difference distribution before and after the object. According to the three phase differences that are not coplanar and contain three-dimensional deformation information, the detection of the three-dimensional deformation field on the surface of the object is realized. Then, numerical simulation and experimental verification of the proposed method are carried out, which proves the feasibility and practicability of the method.
In the digital holographic measurement system, the speckle noise introduced during recording severely affects the hologram quality, leading to errors in the three-dimensional (3D) reconstruction results. Phase extraction is instrumental in affecting accuracy in a digital holographic 3D measurement system, and the result of phase unwrapping is crucial in obtaining the correct continuous phase. To suppress the speckle noise in the digital holographic measurement system, this study proposes a suppression method dealing with the wrapped phase. A two-dimensional Gaussian window was used to locally analyze the wrapped phase in the frequency domain. The threshold was selected based on the high correlation between the window Fourier basis function and wrapped phase. According to the threshold, the noise spectrum was discarded to obtain the wrapped phase with low speckle noise. The digital holographic measurement system with effective speckle noise suppression was realized using the microlens array as the test object. Results show that the proposed method protects the 2π jump boundary of the wrapped phase and can effectively improve the 3D reconstruction accuracy of the digital holographic measurement system. Compared with the unfiltered result, the residual error of the proposed method is reduced by 28.35% (peak valley) and 20.23% (root mean square).
Fast and accurate depth estimation using fringe projection patterns plays an important role in the fringe projection three-dimensional measurement approach. Herein, a recurrent residual convolutional neural network based on U-Net (R2U-Net) is introduced to solve the problem of depth estimation with an improved accuracy than single-frame fringe projection patterns, and the corresponding depth estimation method for fringe projection patterns is proposed, which is verified using simulated and experimental data. Results reveal that, for the simulated data, the error in the predicted results of the proposed approach is 1.71×10-6, which is less than the error of 7.98×10-6 corresponding to the U-Net method. For the experimental data, the error between the depth map predicted using the proposed method and the label decreases by 13% than that using the corresponding U-Net approach. Furthermore, compared with the existing U-Net depth map prediction method, the height distribution curve in the depth map obtained using the proposed approach exhibits a greater fitness with the label, which increases the accuracy of the three-dimensional measurement results from single-frame fringe patterns.
To address the problem of low detection accuracy and recall rate in YOLOv4 of weld X-ray flaw detection defect maps, the YOLOv4-cs algorithm is designed. The algorithm improves the convolution mode of YOLOv4 and greatly reduces the model training parameters; further, it improves the accuracy of model detection by removing the down-sampling layer and fusing the feature map obtained by the second residual block in the 52×52 feature layer. Simultaneously, K-means is used to recluster the dataset and modify the priori frame of YOLOv4 model. The experimental results show that the recall rate of YOLOv4-cs in identifying three kinds of X-ray defects within aluminum alloy welded joints significantly improved, its mean average precision (mAP) was 88.52%, which was 2.67 percentage points higher than the original YOLOv4 model, and the detection speed increased from 20.43 frame/s to 24.47 frame/s.
An image defogging algorithm based on attention mechanism and Markov discriminator (PatchGAN) is proposed herein to differentiate features according to the different regional features of foggy images, which cannot be achieved using existing defogging algorithms. Combined with attention mechanism, the proposed algorithm can adaptively assign weights to the features of different regions while using the module with Inception mechanism to predict the globally relevant atmospheric light value more accurately and effectively. The predicted atmospheric light value, transmittance, and foggy image are input into the atmospheric scattering model to obtain the defogged image. Finally, the defogging image is input into PatchGAN to determine whether it is true or false. The experimental results show that the proposed algorithm achieves good defogging effect on indoor and outdoor foggy images and improves the brightness and saturation of defogging images.
Segmentation of human instances is a fundamental problem in human-centered scene understanding and recognition. However, due to the diversity of human body shapes and interactions, spatial relations become complex, posing significant challenges for segmentation tasks. At the moment, most of the mainstream instance segmentation methods rely heavily on the boundary box detection of objects, and thus, are usually unable to effectively separate two highly overlapping objects. In this paper, human skeleton features with complete data annotation are used to provide a priori knowledge for the human instance segmentation task, and a two-stream network structure is proposed to extract skeleton and context features, respectively. The feature fusion module (FFB) then adaptively combines the features from different streams and sends them into the segmentation module, where the final segmentation result is obtained. The proposed algorithm’s average accuracy on the COCOPersons and OCHuman datasets is 59.5% and 56.7%, respectively, which is improved better than other algorithms.
Due to the low efficiency and large error of traditional point cloud registration methods, this paper proposes a point cloud coarse registration method that is transformed in stages along with the vertical and horizontal directions. The proposed method first decentralizes the point clouds P and Q for coinciding the center points of two point clouds, then finds the feature point by traversing the distance from the center of mass, and rotates it to the y axis to complete the vertical alignment. The proposed method then finds the feature point again in the xOz plane by traversing the distance from the center of mass and rotates it around the y axis to align horizontally. Finally, to complete the registration, we use the iterative closest point fine registration algorithm. The proposed method has linear time complexity and constant space complexity, with no iterative computation. The proposed method is compared to three classical methods, and three groups of point clouds with varying numbers and scales are used. The experiment shows that the proposed method has high robustness for various point clouds. The proposed method has a registration time of about 4 s and a small change range; when compared to the three traditional methods, the time consumption is reduced by more than 50%. At the same time, the root mean square error of the proposed method is about 10-8 mm, which maintains a good accuracy.
Because the background information of a remote sensing image is complex, traditional morphology makes it easy to change the position and shape of the road when using fixed structural elements to process the image, which affects the accuracy of image segmentation. Therefore, an adapted morphology-based method of road extraction was proposed. First, the nonlinear structural tensor was used to construct adaptive elliptic structure elements and corresponding adaptive morphological operations were created. A morphological top-to-bottom hat transformation was constructed based on road features to enhance road targets. Further, the road was extracted using the maximum interclass variance method. The shape parameters were then set to identify the targets in the image that were either in a road area or not. Finally, the adaptive morphological filtering method was used to remove the non-road targets that were still attached to the road, and the independent road network was extracted. The experimental results show that this method can completely extract the road from the remote sensing images with complex background information and higher extraction accuracy.
Super-resolution single-image reconstruction is widely used in many fields; however, most existing algorithms extract more feature details by extending the depth and width of the convolutional neural network, which increases the computational complexity as well as number of model parameters. To solve these problems, a lightweight super-resolution network algorithm with adaptive residual attention is proposed herein. This algorithm first generates an attention feature map, which focuses on high-frequency location information by improving the coordinate attention network, and then connecting the improved adaptive residual attention information-extraction module and coordinate attention module in parallel to obtain more image details in the output feature information. The multiscale upsampling method was used to enable the trained network model (single training) to output multiple super-resolution images with different scales at once. Compared with the classical lightweight super-resolution algorithm, the fourfold reconstructed image obtained using the proposed algorithm has an average peak signal-to-noise ratio (PSNR) improvement of 1.06 dB on four common datasets and the number of model parameters is reduced by 59%. Further, the image obtained using the proposed algorithm is clearer and contains more high-frequency details.
To improve the detection speed of the YOLOv3-CS algorithm for remote sensing image target detection, an adaptive sparse factor adjustment algorithm based on the γ parameter of the Batch Normalization (BN) layer is proposed. YOLOv3-CS was pruned to obtain YOLOv3-CSP using γ as the basis for determining the channel importance. The experimental results show that the proposed pruning method reduces the model size by 95.92%, while increasing the detection speed by 173%, when the mean Average Precision (mAP) loss of YOLOv3-CS is 0.22%. The YOLOv3-CSP can be applied to certain occasions requiring high detection accuracy and real-time performance.
Herein, a new semantic segmentation model N-Deeplab v3+ was proposed based on the existing Deeplab v3+ algorithm. The proposed model can be used to address some severe problems of Deeplab v3+ related to the loss of details, such as missing and incorrect segmentations, during image semantic segmentation. The new model designed an atrous spatial pyramid pooling structure with heteroreceptive field splicing to enhance the correlation between different-level data. The feature fusion of multiple crosslayers is performed to improve the characterization of image details. A feature alignment module based on the attention mechanism was developed to guide the alignment of high- and low-level features and enhance the learning process for important channel features in a targeted manner, thus improving the learning ability of the model. Experimental results based on the Cityscapes dataset show that the proposed model can effectively increase the attention for small-scale targets, alleviate the problem of target mis-segmentation, and show improved semantic segmentation accuracy. The generalization capability of the proposed model is further verified on the PASCAL VOC 2012 dataset. The mean intersection over union of N-Deeplab v3+ on the Cityscapes dataset and PASCAL VOC 2012 dataset reaches 76.31% and 81.97%, respectively, showing improvements of 1.69 percentage points and 2.14 percentage points, respectively, compared with the original model.
To enhance the efficiency of astronomical observations, studies on algorithms for recognizing and evaluating the degree of effect of thin clouds on ground-based optical astronomical observations at night are necessary. First, we select images of ground-based wide angle camera array (GWAC), a large field-of-view ground-based optical astronomical equipment, after analyzing the effects of clouds on ground-based optical astronomical observations and traditional ground-based cloud map algorithms. Then, based on the comparison of the GWAC image characteristics, such as gray-scale value distribution, we select the fuzzy C-means clustering (FCM) algorithm to process the GWAC images affected by thin clouds. Next, by repeating multiple sets of experiments, the appropriate key parameters such as the number of clustering layers, the number of iterations, and the smoothing factor are selected using the FCM algorithm. Finally, the FCM algorithm’s results are compared to those of the traditional astronomical star-extinction method. Set the smoothing factor to 1.5 and the number of clustering layers to 5, after 10 cycles of iterative calculations, the FCM algorithm clusters the night sky background into 5 layers.The results of the hierarchical distribution match the cloud thickness distribution estimated via naked eye as well as the results of the accurate traditional astronomical star-extinction method.The FCM algorithm can effectively recognize and analyze the thickness distribution structure of thin clouds in optical astronomical images from large field-of-view ground-based telescopes, allowing it to grade the effect of thin clouds. Using a larger field-of-view fisheye lens and CCD cameras with this FCM algorithm, it is promising to develop an equipment for monitoring the distribution of thin clouds and evaluating the degree of effect in real-time, which would enhance the efficiency of ground-based optical astronomical observations.
In deep learning-based point-cloud semantic classification, PointNet considers the three-dimensional coordinates of the point cloud as a direct input, however, the classification of irregular shape objects is a challenge. In this study, we propose a semantic segmentation network considering the normals of point cloud by adding a normal estimation module on PointNet. We estimate the normals using a principal component analysis method. Compared with the original model, the overall accuracy, mean per-class accuracy, and mean per-class intersection-over-union of the improved model are improved by 2.3 percentage points, 7.1 percentage points, and 3.9 percentage points respectively. Among the 13 semantic classes, the classification accuracy for 10 classes is improved, of which the classification accuracy of sofa and column is improved by 45.6 percentage points and 42.2 percentage points, respectively, and the mean per-class intersection-over-union is improved by 19.8 percentage points and 25.0 percentage points, respectively. Results show that the semantic segmentation network considering normals can improve the overall performance of the network to a certain extent and can significantly improve the classification effect of sofa and column.
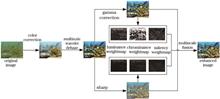
In this paper, we propose an information enhancement method for surface disease images of ancient city walls based on adaptive correction of the illumination component to solve the problems of hidden information of surface disease images of ancient city walls and poor disease feature extraction and recognition due to the interference of sunlight change, occlusion between objects, and shooting angle deviation. The light component was extracted using continuous convolution in a multiscale Gaussian function, and the Gamma parameters were determined according to the nonlinear transformation relationship between the deviation of the light component and the mean value of the pixel. Next, an enhanced two-dimensional (2D)-Gamma function was constructed to adaptively correct the luminance values of the overbright and dark areas of the image to recover the hidden information. At the same time, homomorphic filtering was used to suppress the illumination components of the highlighted areas in the frequency domain in order to solve the problem of weakness of the 2D-Gamma function in characterizing the attenuation of the brightness values of highlighted pixels. This reduces the dynamic range of luminance and enhances the hidden information of highlighted areas of the image. A coefficient factor was used to linearly fuse the brightness-corrected image with the edge details extracted using the Sobel operator to reconstruct an enhanced surface disease image of the ancient city walls with clear details and prominent textures. The experimental results show that the proposed method effectively solves the problem of hidden image information and poor visibility caused by uneven illumination, occlusion, and shadows while retaining the original image details. Moreover, it enhances the surface disease image features of the ancient city walls and improves the accuracy of disease recognition.
YOLOv5 (You only look once,v5) is widely used in real-time target recognition because of its fast detection speed and high accuracy. On X-ray security image detection errors or omissions problems with complex backgrounds, multiple scales, and overlapping. By improving the attention mechanism, a new feature fusion strategy is developed based on the YOLOv5s network structure. This study proposes a YOLOv5s-AFA object detection network with an adaptive feature fusion technique and an attention mechanism. In the shallow layer of the network, an extended receptive field module and an improved spatial attention mechanism are introduced, whereas the improved channel attention mechanism is introduced in the deep layer. The new feature fusion technique can output three feature maps of varying depths at a time and fusing shallow spatial and deep semantic information using adaptive learning weights to improve the network learning. The target results on the X-ray security image dataset show that the false and missed detection rates of the YOLOv5s-AFA network decrease considerably compared with other compared networks.
Semantic segmentation of point cloud data plays an important role for 3D scene understanding and reconstruction, autonomous driving, and robot navigation. In this study, DGPoint, a dynamic graph convolution network based on the PointNet++ architecture, is proposed to address the insufficient segmentation accuracy due to insufficient local feature extraction of point clouds by existing methods. First, the feature aggregation function in edge convolution compensates for loss using a dual-channel pooling operation, which can better retain the fine-grained local characteristics of the point cloud. Then, to accomplish the impact of dynamic graph updates, K-nearest neighbors algorithm is used to determine new local regions prior to edge convolution. Additionally, to ensure the accuracy of edge feature extraction, the designed encoder is repeated multiple times, and the extracted features are concatenated in a jump-connection style before being input to the decoder. Experimental results of the S3DIS data set show that DGPoint effectively solves the shortcomings of the insufficient local feature extraction and improves semantic segmentation accuracy with the mean intersection over union of 68.3% and overall accuracy of 86.2% compared with other methods.
The registration of 2D-3D medical images is crucial in solving radiotherapy positioning verification. A 2D-3D medical image registration approach based on training-inference decoupling architecture is proposed to address the issues of low accuracy and time-consuming processes. The multibranch structure and multiscale convolution were employed in the training phase to enhance feature diversity and improve registration accuracy. During the inference phase, the multibranch structure was reparameterized into a single-channel structure to speed up the registration speed. Additionally, an adaptive activation function, Meta-ACON, was used to increase the network’s nonlinear expression. Two datasets of the chest and pelvis were used for training and testing. The experimental results show that the mean translation error of the proposed method is approximately 0.08 mm, the mean angular error is approximately 0.05°, and the registration time reaches 26 ms. The proposed method significantly improves the accuracy of medical image registration in positioning verification while meeting the real-time requirements of clinical applications.
To demonstrate the feasibility of space-borne applications of single-photon imaging technology, this study analyzes the elimination of the backscattering effect in the optical system, suppression of the single-photon avalanche photoelectric detection noise, and the free running mode. Next, the space-borne single-photon counting imaging system is modeled using a heavy tailed pulse laser function and the Monte Carlo method. The echo photon counting results are simulated for different conditions of orbit altitude, replication number, and gate number. The results show that the echo photon counting waveform is similar to the transmission waveform, as observed in reality. Single-photon imaging is possible within a certain distance threshold. Detections are missed when the replication number is lower than the gate number. The range accuracy can reach 0.09 m when the replication and gate numbers are both set to 2000 at an orbit altitude of 500 km based on the parameter set in this study. The methods in this paper provide technical support for the index allocation and on-orbit parameter adjustment of a space-borne single-photon counting imaging system.
When performing computer vision tasks such as three-dimensional reconstruction and scene understanding, it is a basic task to recover depth information in three-dimensional space from two-dimensional images. When deep learning is currently used to complete this task, methods with higher accuracy often require a huge amount of data, and the acquisition of these data is usually complicated and expensive. In response to this problem, this paper based on transfer learning, and proposes a encoder-decoder network using global self-attention. It takes a single image as input and has a global receptive field at each stage of encoding. After decoding, the depth regression task is transformed into a classification task, greatly reducing the amount of training data required while ensuring the accuracy of the model. The experimental results show that compared with the current state-of-the-art depth estimation networks AdaBins and DPT-Hybrid, the designed model reduces the root mean square error by about 2.2% and 0.3%, and reduces the amount of training data by about 80% and 99.6%.
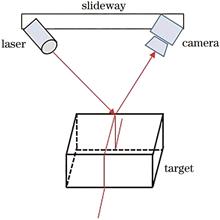
A fundamental way to improve the automation level of pipeline welding in industries is to quickly and accurately identify the weld. To solve this problem, we designed a laser vision-guided seam tracking system for pipeline bus weld. The seam image containing laser stripes was obtained using a CCD industrial camera, and the position of the laser stripes was determined after digitizing the image, threshold segmentation, and region of interest area extraction. Then, we reduced the laser stripes in the images using the improved geometric center algorithm. Furthermore, we obtained the two-dimensional coordinates of the solder points using the curve fitting and feature point recognition algorithm. Finally, we reconstructed the three-dimensional weld feature points using the principle of camera imaging and transformed the coordinates of the weld points from the image coordinate system to the robot base coordinate system to guide the robot to autoweld. The experimental results show that the recognition errors of the solder joints are all within 0.5 mm. Additionally, the recognition efficiency and accuracy of the seam feature point extraction are high, which meet the production requirements of robot automatic welding.
To address the low resolution problem of infrared images in the medical field, we build a distributed array–based infrared imaging system with a simple structure and a real-time performance that achieved an improved image resolution using image algorithm processing. The proposed system is used to obtain four images with pixel-level displacement. One of the images is used as a benchmark, and the other three images are registered. Then, the projection of convex set algorithm is used to reconstruct the images and obtain a high-resolution infrared image. Finally, the reconstruction method of a generative admissible neural network is employed to obtain the infrared super-resolution image. Experimental results show that the infrared imaging system with a distributed array camera can realize real-time super-resolution image reconstruction, and the infrared image resolution can be improved from 400 × 300 to 3200×2400 (an eightfold increment). Compared with the original image, the mean and standard deviation of the super-resolution reconstructed image increase by 1.86% and 8.67%, while the entropy value remains basically unchanged. The proposed image processing algorithm realizes the super-resolution reconstruction for infrared images, which meets the application requirements of infrared super-resolution imaging in the medical field.
Herein, we proposed a hyperspectral image classification method using an edge-preserving filter and deep residual network due to the characteristics of the strong correlation between hyperspectral image bands, high complexity of spectral and spatial structures, and a limited number of training samples. First, we applied joint bilateral filtering to enhance the edge structure of ground objects and extract high-quality spatial features. The extracted spatial features were fused with spectral features to obtain the spatial-spectral features. Furthermore, we constructed a two-dimensional convolutional neural network and improved the model to a deep residual network model by adding a hop layer connection in the convolutional layer. Then, the model was used to extract the deep spatial-spectral features and input them to the Softmax classifier. We compare the experiment with related state-of-the-art methods on two datasets, and the results show that the proposed method alleviates the overfitting phenomenon in the convolutional neural network classification and considers the important role of the edge structure of ground objects, which significantly improves the classification accuracy of the hyperspectral images.
A fast simulation method for obtaining space-based optical observation images of massive space debris is proposed to increase the computational efficiency of space-based optical imaging simulations of massive space debris. First, the imaging principle of the space-based optical observation images was explained. Then, an imaging simulation process was designed and a calculation method for each process was given. It is concluded that the calculation of the visibility of space debris under multiple constraints mainly limits the imaging simulation speed. Thus, an evaluation index of the influence of each constraint on the speed was established for solving the space debris visibility. Finally, based on the established evaluation indicators and the characteristics of actual observation tasks, a strategy for rapidly solving the visibility of massive space debris under multiple constraints was proposed. The simulation results show that the imaging simulation speed of the proposed method is significantly faster than the traditional imaging simulation algorithm while ensuring the fidelity of the simulation images, which is of great significance for developing and effectively evaluating the space-based visible-light observation platform.
The lack of inherent characteristics of infrared small targets, with issues such as high time consumption, prevents applying existing detection methods in complex environments. Herein, we propose an infrared small-target detection algorithm suitable for embedded edge-computing devices which transforms the problem of small-target detection into the problem of semantic segmentation. A lightweight backbone network is used to extract the features, a cross-layer feature fusion method based on context modulation is designed to exchange high-level semantics and low-level details, and dual attention mechanism based on channels and locations is introduced to highlight the small targets in the feature map. Experiments prove that this algorithm outperforms existing state-of-the-art methods in terms of detection effects, false alarms, and time consumption in complex backgrounds. The model is only 100 KB in size and can detect video streams at 20 frame/s in real-time, making it ideal for embedded deployment and practical applications.
To solve the problems of considerable data volume and poor rendering effect in the traditional vertex shading rendering method of three-dimensional (3D) mesh, this study proposes a method to generate clear texture images using the fusion technology of point cloud and multiple-station panoramic images. First, the occlusion from the spatial mapping point of the panoramic texture pixel to the center of the panoramic sphere was calculated. Subsequently, the spatial color domain inverse distance weighted fusion of multiple-station panorama was conducted under texture image pixel point visibility. Additionally, the texture image blank area neighborhood weighted filling was conducted to generate a clear texture image. Finally, panoramic images and laser point clouds were collected as data sources to generate texture images. The experimental results show that the algorithm designed in parallel can quickly generate highly clear textures from multiple-station panoramic images. The overall effect of the model is more realistic and clearer than vertex colored model. The visualization effect of the 3D model of a crime scene is also improved.
The scanning speed and image quality of the digital slide scanner are the two features that users are most concerned about. A real-time focusing configuration centered on a tilted camera is meant to enhance the scanning speed and image quality simultaneously. The device can calculate the defocus distance by taking only one image, and the computation time is only 12.1 ms. Furthermore, based on this, the focal plane can be tracked in real time during the continuous scanning by manipulating the tilted camera and the scanning camera synchronously, which is synchronous focusing and scanning. Synchronous focusing and scanning method saves modeling time and improve the image quality compared with the usual method of modeling first and scanning later.
Line structured laser three-dimensional (3D) imaging technology has been widely used in welding detection. The fast, accurate, and real-time image extraction of the laser stripe center is the key element for online detection of weld quality under splash interference. Aiming at the problem that the traditional method is difficult to effectively solve the interferences of strong arc light and welding slag spatter, a novel robust and fast laser stripe center extraction algorithm is proposed. First, the geometric center of the stripe is extracted in line with the width constraint of the laser stripe. The fast connected region extraction algorithm is used to screen the effective contour, and the breakpoints caused by splashing are linked by the improved local edge linking algorithm. Second, adjacent contours are searched to create ordered pairs and oriented graphs. The path that has the largest projection length is the real stripe center. Finally, the subpixel center is calculated along the normal direction around the roughly extracting the central contour. The experimental results show that the proposed method can effectively resist spatter interference during welding. The centerline of the light strip can be extracted in real-time and accurately regardless of the removal of the baffle plate of the light sensor. The proposed method has a higher running speed and extraction accuracy compared with some traditional algorithms.
Focusing on the problems of complex operation and large error of the light source position calibration method based on specular reflection in photometric stereo vision, this paper proposes a method of light-emitting diode (LED) light source position parameter calibration based on stereo vision. In photometric stereo, the LED light source is photographed using binocular stereo vision system, and the three-dimensional coordinates of the light source are calculated using the least square method based on the stereo vision imaging matrix. Simultaneously, the structural parameters of the light source position calibration system are obtained through the rotation and translation relationships between the cameras in the photometric stereo and binocular stereo vision systems, and the spatial position relationship of the LED light source, which is relative to the camera in the photometric stereo system, is obtained. The experimental result shows that the proposed method can effectively solve the problem of the cumbersome operation of the specular reflection calibration method, and when compared to the method based on specular reflection, the proposed method can obtain more accurate LED light source position calibration parameters using the easy-to-operate stereo vision system. The mean absolute error (MAE) and root mean square error (RMSE) of the light source diagonal distance obtained by the proposed method are lower than those obtained by the specular reflection method.
When the Centernet algorithm in an anchor-free algorithm is used to identify and detect fish, the low-level feature information is easily lost, resulting in a decrease in recognition accuracy and efficiency. Therefore, a fish recognition and detection algorithm based on the Feature fusion Module and Loss function optimization of Centernet (FML-Centernet) algorithm is proposed herein. The feature fusion module is incorporated into the Centernet algorithm’s network structure to fuse the low- and high-level feature information, generate a more complete feature map, and improve the recognition and detection accuracy. By adjusting the loss ratio of positive and negative samples, the loss function of the network model is optimized and the recognition and detection efficiency of the overall model is improved. The effectiveness of the proposed algorithm is verified using the Pascalvoc dataset, and the performance of the network structure is analyzed. The optimized network structure is then compared with different models using a large number of target datasets and labeling dataset information. The experimental results show that the average recognition accuracy (AP50) of the FML-Centernet algorithm can exceed 85% and the average detection time is less than 100 ms. The proposed algorithm not only has high recognition and detection accuracy but also improves the recognition and detection efficiency.
When reconstructing three-dimensional human posture from a single view image, the lack of depth information and postural diversity cause orientation errors and the poor processing of the postural details when mapping two-dimensional to three-dimensional posture. Therefore, combined with the distribution law of bones, vertices of the stereo human model, and optimization model deformation strategy, we propose a three-dimensional pose reconstruction method using multifeature point matching. The core of the proposed method is to match and fit multiple two-dimensional human feature points with the three-dimensional feature points of the human model by optimizing the energy function to realize the reconstruction of three-dimensional posture. Furthermore, we establish orientation constraints using some joint points to reduce the impact of the lack of depth information on the reconstructed posture. Additionally, multiple head feature points are used to adjust the head pose to reduce the impact of pose diversity on the head pose reconstruction. The experimental results on the public pose datasets, MPI-INF-3DHP and LSP, show that the proposed method effectively solves the problems of pose blur and poorly detailed pose processing, as well as accurately reconstructs the three-dimensional human pose under common actions.
In order to realize rapid and accurate identification of rice pests, a rice pest identification method based on transfer learning and convolutional neural network was proposed in this paper. First, the images of rice pests were preprocessed. Pre-processing methods include translation, inversion, rotation, and scaling. According to the characteristics of the pests, the images were divided into six categories, namely, rice leaf roller, rice planthopper, rice plant thopper, rice leaf roller, rice plant thopper, rice plant thopper, rice locust, and rice weevil. Then, based on the transfer learning method, the weight parameters trained by the VGG16 model on the image data set ImageNet were transferred to the recognition of rice pests. The convolution layer and the pooling layer of VGG16 were used as the feature extraction layer. Meanwhile, the top layer was redesigned as the global average pooling layer and a softmax output layer. Part of the convolutional layer is frozen during training. The experimental results show that the average test accuracy of this model is 99.05%, the training time is about 1/2 of the original model, and the model size is only 74.2 MB. The F1 values of six insect pests, namely, rice grasshopper, rice planthopper, rice weevil, striped rice borer, the rice leaf roller, and yellow rice borer, were 0.898, 0.99, 0.99, 0.99, 1.00, 0.99, respectively. The experimental results show that this method has high identification efficiency, good identification effect and strong portability, which can provide a reference for the efficient and rapid diagnosis of crop pests.
In this paper, we propose a two-point light source location technology using a support vector machine (SVM). Here, the transmitter uses a field-programmable gate array to generate position information, encode and load it into the driving circuit of the corresponding light-emitting diode (LED) and the image sensor at the receiver captures two LED images. In the actual positioning, the movement of the positioning point changes the received light power, which affects the exposure degree and time, thereby causing inaccurate extraction of the fringe features. Therefore, our method selects column pixels since SVM is used to realize the classification and accurate recognition of LED and the actual position of the target is obtained using the three-dimensional imaging positioning algorithm of visible light. Finally, we obtained a positioning accuracy of 1-2 cm in the spatial range of 30 cm × 30 cm × 50 cm.
To improve the efficiency of the semi-global matching (SGM) algorithm, a stereo matching algorithm based on better matching cost calculation and a path optimization strategy is proposed. In the cost calculation stage, the local binary patterns (LBP) operator was optimized by taking diagonal points to reduce time complexity and memory usage; in the cost aggregation stage, five directions were selected for scan line optimization according to the aggregation logic, combined with gray-scale similarity and distance constraint conditions to perform adaptive weight assignment; then the initial disparity value was calculated using the winner-takes-all (WTA) strategy, and the aggregation path was further optimized by the disparity map through left and right consistency detection and the quadratic polynomial interpolation algorithm. Finally, the algorithm’s matching efficiency was validated using the Middlebury 2.0 and 3.0 data platforms. The experimental results show that when compared with the SGM algorithm, the proposed algorithm reduces the time used in the cost calculation stage by 63.1% and that in the cost aggregation stage by 39.3%. When the matching accuracy is slightly improved, the overall efficiency of the algorithm is increased by 54.2%, achieving the goal of efficiency improvement.
The rapid development of deep forgery technology has improved the quality of generated pictures and videos to mirror reality. However, it has brought huge security risks to society. In view of the large parameters used in existing detection methods, deep network, complex model structure, etc., this paper first optimizes the classic detection model XceptionNet in the forensics field and proposes a lightweight forensic model Xcep_Block8 that reduces the model parameters while maintaining high detection accuracy. Second, we improve the solution of the unevenness of positive and negative samples by increasing the sampling probability of samples with fewer categories to solve the problem of unbalanced categories. Finally, we employ the hybrid data enhancement method, CutMix, to improve the linear expression between samples. The experimental results show that the test results of the proposed model are about 1.01 percentage points higher than the baseline results. Additionally, it has certain advantages compared with other methods in terms of parameter quantity.
A semiglobal stereo matching algorithm based on fusion cost and adaptive penalty coefficient is proposed to address the low-accuracy problem of semi-global stereo matching algorithms in discontinuous disparity regions. In the cost calculation part, a fusion cost calculation method is proposed introducing the gradient in the y direction of the input image and combining the fusion formula with the gradient in the x direction of the input image, absolute difference, and Census transform to form the cost calculation data item; in the cost aggregation part, a pixel classification mechanism is proposed that classifies each pixel by color and gradient dual thresholds and adaptively adjusts the size of its penalty coefficients; finally, the initial parallax map is processed using a multistep parallax optimization method. Results show that the average error of the proposed algorithm in the discontinuous parallax regions decreases by 1.1 percentage points to 12.8 percentage points, and it also decreases in non-occlusion and all regions. The proposed algorithm exhibits high matching accuracy and robustness.
The shadow of a photovoltaic panel makes the light intensity distribution of the photovoltaic array uneven and reduces the power generation efficiency. It can also produce a hotspot effect, damage photovoltaic cell modules, and cause a system failure. To solve the problems of high target density, large overlap, high cost, and poor real-time performance in the shadow detection of photovoltaic panels, this study proposes a shadow detection algorithm for CRC-RetinaNet photovoltaic panels based on the RetinaNet algorithm. First, cross stage partial structure was used in the feature extraction network to improve the accuracy and detection speed. Second, the feature map was extracted using the recursive feature fusion structure to enhance the feature information of all targets. Third, the activation function of the algorithm was improved to enhance the robustness of the network. Finally, the loss function was changed to CIoU loss to improve the positioning accuracy of the target border regression. The experimental results show that the average detection accuracy of the proposed algorithm is 99.24%, which is improved by 4.02% compared with the original RetinaNet algorithm, and meets the requirements of the real-time detection of photovoltaic panels in the environment.
The existing classification algorithms for benign paroxysmal positional vertigo video nystagmus have the following shortcomings. The features extracted manually are subjective and limited; the feature extraction of axial rotation of eyeballs is difficult; it can only distinguish between normal people and patients or classify simple nystagmus. To overcome the above shortcomings, a video nystagmus classification algorithm based on attention mechanism is proposed. Based on the lightweight model three-dimensional MobileNet V2, a network is used for feature extraction, and the global spatiotemporal attention module is introduced at the lower level of the network with rich global detail features and spatiotemporal information to integrate the spatial information of nystagmus and the temporal information between frames. The attention mechanism of the spatiotemporal channel is introduced to the high-level network to screen high-level semantic features. The cross entropy loss function with category modulation coefficient is used to train the network, which effectively alleviates the problem of imbalance in several categories. Experiments were conducted on 66 types of video nystagmus datasets provided by the Eye and ENT Hospital of Fudan University. The classification accuracy of the proposed algorithm reached 90.08%, and the average accuracy, recall, and F1-score of each category were 90.50%, 92.00%, and 90.40%, respectively, indicating the superiority of the proposed algorithm.
In this paper, an accurate and reliable breast lesion segmentation algorithm is examined to extract tumor regions from mammographic images for the diagnosis of breast diseases. Additionally, a framework incorporating an adversarial network, which is mainly composed of a segmentation network and a discriminant network, is used for the enhancement of the high-order consistency of the segmentation results. Here, an improved U-Net++ network is used as the segmentation network to generate a breast mass segmentation map (a mask), while the discriminant network is used to discriminate between the generated mask and the real mask to further enhance the performance of the segmentation network. The performance of the proposed method is verified on the public dataset (CBIS-DDSM). The experimental results show that the specificity, sensitivity, accuracy, and Dice coefficient of the proposed method are 99.7%, 90.4%, 98%, and 91%, respectively, which are higher than that of the classical algorithms. The deep learning algorithm combined with the improved model (U-Net++) and generated countermeasure network can improve the segmentation performance of breast mass in molybdenum target images.
Polarization-sensitive full-field optical coherence tomography (PS-FFOCT) system can produce the depth-resolved en face images of the birefringence and diattenuation of biological tissue samples. One of the important problems in the birefringence measurement of biological tissue using PS-FFOCT system is the analysis of the effects of relative phase delay error of quarter-wave plate on the measurement accuracy. A PS-FFOCT system was set up in this study. First, the Jones matrix model of the system was derived, and the effects of relative phase delay errors of quarter-wave plate on the measurement accuracy of birefringence were then analyzed. Finally, the results simulated using Matlab software were presented to reveal the specific behaviors. The research results can help the design of PS-FFOCT system and the accurate measurement of birefringence characteristics of biological tissues.
Image registration is widely used in image-guided lung tumor radiotherapy, but the existing algorithms are not effective against large deformation images. Therefore, this paper proposes an algorithm using a multiscale parallel down sampling module to reduce the image size and obtain a multiscale low-resolution feature map, and the pyramid dilated convolution module is used to extract image features to improve the model’s receptive field. The algorithm adjusts the bias of the neural networks on different deformation features through the adaptive channel attention module to solve the problem in which the model is biased and poor for large and small deformation registration, respectively. Simultaneously, a smoothness constraint is added to the loss function to improve the deformed field smoothness. The training set data-augmentation method is also used to improve the model’s stability and generalization. The proposed algorithm has target registration errors of 1.71 mm and 1.50 mm in the DIR-lab and Creatis datasets, respectively, whereas the one-iteration fully convolutional neural network (FCN) has target registration errors (TREs) of 2.83 mm and 2.01 mm in the above datasets, respectively. The experimental results show that the TRE of the algorithm is significantly smaller than that of the FCN algorithm, and the generalization and stability performances of the algorithm are also improved.
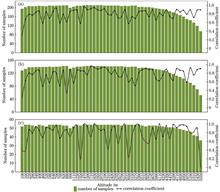
To solve the problem of a low classification accuracy of single classifier in forest classification, a classification model (ACO-SVM) that combines the improved ant colony algorithm (ACO) with support vector machine (SVM) is proposed. In the improved algorithm, a partial finite search was introduced into the ant colony search to avoid local extrema. A time-varying function was introduced into pheromone updating. The dynamic update policy was combined with SVM to optimize the parameters of the radial basis kernel function. The proposed model was verified using an experiment based on the classification of the forest types using UAV visible remote sensing images. In the spectral feature image classification, compared with ABC-SVM, GA-SVM, and conventional SVM models, the proposed ACO-SVM achieved the best forest-type classification performance, with an overall classification accuracy of 81% and a Kappa coefficient of 0.7500. After introducing different textural features, the classification was performed for the Genhe forest area in the Greater Khingan Mountains based on the grayscale co-occurrence matrix feature, and the proposed ACO-SVM showed an overall classification accuracy of 85% and a Kappa coefficient of 0.8063. After introducing the Gabor textural feature, ACO-SVM achieved the overall classification accuracy and Kappa coefficient of 87.5% and 0.8438, respectively.
Object detection in remote sensing images is a fundamental task in image analysis and interpretation. We proposed a Multiscale Dilated Convolution Feature Fusion Detector (MDCF2Det) to achieve precise object detection in remote sensing by addressing the problems of multiscale objects and the complexity of the background. To begin, we improve the original feature pyramid network by replacing the general convolution with the dilated convolution to increase the receptive field. Second, to take full advantage of different levels of semantic and location information, we add a skip connection operation from the input node to the output node. Finally, to suppress the noise and highlight the foreground, we add the multi-dimensional attention model before the regional proposal network, to achieve more accurate object detection in remote sensing images. Experiments are carried out on the DOTA and RSOD datasets, and the proposed algorithm’s mean average precision reaches 92.95% and 73.39% respectively. The results show that the proposed algorithm can significantly improve the object detection accuracy of remote sensing images.
Clustering filtering is a practical method according to the characteristic attributes of the lidar point cloud. However, because of the large data size of the point cloud, direct clustering using three-dimensional point coordinates is time-consuming, produces large filtering error results, and existing filtering algorithms do not perform well in discontinuous terrain. In this paper, we proposed a new point cloud filtering algorithm based on density clustering to solve the direct clustering problem of large-scale point clouds and preserve the overall fluctuation of discontinuous terrain. First, based on the spatial density of lidar point cloud, the characteristic attributes of both ground object and terrain point clouds cluster according to the elevation value density of point cloud, and then screen the plane point cloud, to reduce the number of samples of data. Finally, the original point cloud is divided into noise, nonground, and ground point clouds using density-based spatial clustering of applications with noise algorithm. The experiment is conducted with data samples provided by the international society for photogrammetry and remote sensing. Furthermore, we compared the proposed algorithm with eight other classical filtering algorithms. The quantitative and qualitative results show that the proposed algorithm has good applicability in urban and rural areas, with small filtering error in discontinuous terrain and good adaptability in the mixed area of artificial buildings and vegetation. The proposed algorithm is feasible and can be used in different terrain.
The Dunhuang correction site is the most important radiation correction site in China, and the directional reflection characteristic of the ground target is an important parameter affecting the site calibration accuracy. Until now, there are no clear studies on circumstances that necessitate the ground reflectance correction, and which bidirectional reflectance distribution function (BRDF) is used for correction. Due to the high accuracy of medium-resolution image spectrometer (MODIS), MODIS images are analyzed. First, using six sets of unmanned aerial vehicle multi-angle observation data under different sun zenith angles at the Dunhuang site in September 2020, 36 different BRDF models are established by six different kernel function combinations. For the images under different observation angles, we calculated the apparent reflectance before and after the BRDF correction and compared the relative deviation with the measured apparent reflectance of the satellite. By considering the observation angle of 28° as the boundary, the experimental results show that the relative deviation is greater when the angle is greater than 28°, which is a significant consequence of the BRDF correction. Among the BRDF models established above, the BRDF model established using multi-angle observation data measured close to the time of satellite transit has a better correction effect. Furthermore, the relative deviation between the apparent reflectance calculated by the BRDF model using the kernel function combination of Rossthick-Lidense or RossThick-LiSparseR or Rossthin-LisparseR and the satellite observation value are small.
In this study, a line laser on-machine measurement experimental platform integrating aviation blade detection and processing is designed and built to solve the problems of low efficiency and easy surface damage during the contact measurement of aviation blades. In laser noncontact measurements, point cloud data are prone to errors. Herein, the main influencing factors involved in the measurement process are discussed and analyzed to improve the accuracy of laser in machine measurement. Furthermore, error prediction models based on radial basis function neural network and support vector regression are established and the performances of these two prediction models are compared. The error compensation strategy of free-form surface detection is used to complete the compensation and correction of point cloud data. Finally, taking a certain type of aviation blade as an example, the experimental results show that the proposed method can improve the accuracy of point cloud data by 39.86% and verify the feasibility of the error compensation model and compensation strategy.
Subsidence of the Sino-Myanmar oil and gas pipelines leads to pipeline bending, deformation, and even rupture. Therefore, pipeline settlement monitoring is of great significance for pipeline construction and maintenance. The persistent scatterer interferometric synthetic aperture radar (PS-InSAR) technology has the advantages of all-day use, all-weather use, wide monitoring range, and high precision. Taking the 3-km buffer zone on both sides of the Ruokai mountain section of the Sino-Myanmar natural gas pipeline as the study area, the abnormal deformation area is obtained by the PS-InSAR method. Further, combined with multisource data such as slope, slope direction, vegetation, and soil types in the study area, a risk assessment model is established to evaluate the landslide risk for the Sino-Myanmar oil and gas pipelines and determine the risk level of pipeline subsidence. The main conclusions are as follows: The PS-InSAR method based on the fusion of ascending and descending orbits is used for deformation monitoring, and a total of 90 areas with large deformation are obtained. The average variation is between -25 mm and +25 mm, and most areas are stable. Based on slope, aspect, and other multisource data, the landslide risk level and pipeline operation safety level are determined. The results show that there are 13 first-level landslide risk areas, 18 second-level landslide risk areas, and 59 third-level landslide risk areas, and there are 10 first-level pipeline risk areas, 14 second-level pipeline risk areas, and 66 third-level pipeline risk areas.
Owing to the fault and leak detection problems caused by complex scenes and diverse scales in remote sensing image ship detection, a lightweight ship classification detection method based on improved YOLOv5s is proposed herein to realize real-time rapid ship classification and detection despite limited equipment computing capability. This method applies a lightweight and efficient channel attention technique to the backbone feature extraction network to obtain a novel feature extraction network with an improved ability to identify ships in complex remote sensing images. The feature maps with different levels obtained from the feature extraction network were input into the weighted bidirectional feature pyramid structure to optimize the fusion of high and low stage features of the backbone network, and experiments were conducted on the ship dataset of remote sensing images. The results show that the mean average precision of the improved network model has increased from 83.9% to 89.2% and the average precision for detecting aircraft carriers, warships, civil ships, and submarines has increased by 1.6 percentage points, 0.9 percentage points, 8.8 percentage points, and 9.5 percentage points, respectively. Additionally, the average detection speed and network complexity are considerably better than the other algorithms.
Three-dimensional (3D) stereoscopic display is a promising direction of display technology development, and color asymmetry of left and right eye views is a common phenomenon in stereoscopic 3D displays, which can cause visual discomfort. Under the 3D display, the study of binocular fusion of asymmetric colors is an extension and supplement of traditional color vision research, which has a certain scientific significance to understanding the process and mechanism of visual information processing in the human visual system as well as has application value to solve the problem of visual discomfort in existing stereoscopic display technology. In this study, the relevant literature on binocular color fusion was sorted, and the research status of binocular color fusion was summarized from three aspects: binocular color fusion, the interaction between color and stereo fusions, and the influence of binocular color fusion on the visual comfort of 3D displays. We highlight that the interaction mechanism of binocular color fusion and stereo fusion is still uncleart, and the research results stay on the phenomenon description, lacking quantitative experimental data to establish a color fusion model. We infer that binocular color asymmetry affects the visual comfort of 3D displays. In addition, 3D display-based image enhancement may become a research hotspot in the future.
Terahertz time-domain spectroscopy utilizes the absorption of a substance in a specific frequency range to acquire optical parameters such as refractive index, absorption coefficient, and the reflection coefficient of a substance. It has made significant contributions in the fields of food, drugs, and environment recently due to its benefits such as fingerprint, low energy, strong penetration, and coherence. This study focuses on the current research status of terahertz time‐domain spectroscopy in food, drugs, and environment based on an introduction to the principle of terahertz time-domain spectroscopy and method of acquiring optical parameters. Furthermore, for the future application of terahertz time‐domain spectroscopy in the fields of food, drugs, and environment, we summarize and assess its limits in practical work and its development possibilities.
In criminal technology, identifying bloodstain species is essential in determining the nature of a case and investigation direction. This study explores spectral nondestructive species identification method. Using CRI Nuance spectral imager to carry MISytem 3.0 spectral image analysis software, in the spectrum range of 450 nm?950 nm, 180 groups of objects including human blood trace samples, animal blood trace samples, and mixed human and animal blood trace samples on 30 carriers were analyzed by spectral image analysis. Results were analyzed using the slope difference between the samples’ two substances. The hyperspectral imaging revealed that the three types of bloodstains could be distinguished on most carriers, with discrimination rate exceeding 70%. This study supplements the bloodstains species identification method and serves as a reference for an optical nondestructive bloodstain examination.
The strong scattering of light transported through nanoporous ceramic media can be used to form a miniature gas sensing absorption chamber by adopting the tunable diode laser absorption spectroscopy (TDLAS). To explore the effect of the physical parameters of ceramics on the optical pathlength enhancement, TDLAS was utilized to measure the spectral absorption characteristics of oxygen inside the ceramics and to study the effect of the thickness and porosity of ceramics on the pathlength enhancement coefficient. The experimental results show that the pathlength enhancement coefficient is linearly correlated to thickness and exponentially correlated to porosity, which provides experimental explanation for the pathlength enhancement mechanism. In conclusion, the physical parameters of ceramics can be optimized to improve the pathlength enhancement coefficient and form a miniature gas cell suitable for in-situ TDLAS applications.
The skin colors of humans vary considerably based on which race they belong to and where they live. First, a seven layer neonatal skin model was established herein according to the skin structure and optical characteristics. Subsequently, the Monte Carlo method was used to simulate the propagation of light under different skin color conditions by varying the volume fraction of epidermal melanin. Simulation results show that the difference in the neonatal skin color greatly affects the propagation characteristics of light through the skin. This difference interferes with the key wavelength of noninvasive detection of neonatal jaundice, thus affecting the accuracy of such detection.
The rapid, non-destructive, and quasi-deterministic analysis for drugs is a critical issue in the field of drug prevention and control. The experiment sorted the spectral and chromatographic data from 159 cannabis oil samples representing four types. We establish classification models for different data sets using the supervised pattern recognition methods of Fisher discriminant analysis and K-nearest neighbor analysis, and then compare the effects of single and fusion models on the analysis results. According to the results, in the process of identification and classification of four types of cannabis oil, the fusion model based on spectral and chromatographic data sets has a higher classification effect than other data sets, and the fusion model based on K-nearest neighbor analysis has achieved the best classification effect, with an overall classification accuracy of 1. This research enables the rapid and accurate qualitative analysis of different types of cannabis oil, as well as providing evidence and clues for accurately identifying the source of seized drugs and trying upstream and downstream drug crime cases related to facts.
To help the reconnaissance organs obtain more clues during the case investigation process, the material evidence of plastic and steel windows commonly used in the work was identified using efficient and data-based nondestructive identification. To analyze and identify the material evidence, principal component analysis (PCA) preprocessing was performed in conjunction with Fisher discriminant analysis (FDA)-optimal parameter combination support vector machine (SVM). The two-dimensional characterization and recognition of"brand-batch"were accomplished based on the theoretical and experimental analyses of 126 sets of Fourier transform infrared spectrum data extracted from 6 brands, such as"Jinpeng"and"Conch".Based on the PCA results of three spectral segments, namely, the complete spectrum, functional group, and fingerprint segments, a data classification model based on Fisher discriminant analysis was created. The classification accuracy of the entire spectrum segment was determined to be the highest at 66.7%. The SVM classification model was built using the eigenvalues of the entire spectrum. The effects of the penalty factor C and radial basis function (RBF) gamma value σ on the classification accuracy of the SVM classification model were investigated, and the SVM classification model based on the optimal parameter combination (C = 10, σ = 2.5) was obtained. The best classification model was used to distinguish the different batches of"Conch"brand plastic steel window samples, and the classification accuracy reached 100%. The classification results of this method are ideal as they can fulfill the needs of the rapid classification of plastic steel window cases and are expected to provide some reference for its application in the field of forensic science research.
Stereo matching algorithms used currently are ineffective at matching weak textures, shadows, and other pathological regions. To make full use of scene context information to improve disparity matching accuracy, this study proposes an effective multiple attention stereo matching algorithm (MAnet). At the feature extraction stage, according to multiple attention mechanisms, such as location channel attention and multiheads crisscross attention (MCA), we adjust the feature channels and selectively aggregate contextual information in any range to provide more discriminative features for matching cost calculation. Extending MCA to 3D convolution expands the network perceptual region to accumulate more precise matching cost. The learning ability of challenging regions is enhanced for the networks’ loss function by weighting the loss outside the error threshold. The algorithms are experimentally validated on the KITTI dataset, and the error of MAnet for the KITTI2015 test set is 2.06%. The experimental findings demonstrate that compared to the benchmark algorithm, the MAnet enhances disparity accuracy and improves the matching performance in the pathological region.