










Please enter the answer below before you can view the full text.
4-2=

Herein, a method of post-processing filtering based on space vector projection is proposed to eliminate the near-ground points that have a considerable impact on the accuracy of digital elevation model (DEM) construction to address the problem of difficulty in generating a high-quality DEM via single progressive morphological filtering for airborne light detection and airborne ranging (LiDAR) data. Initially, the proposed method takes each laser point as starting point and then constructs vectors with the lowest laser point of each of the nine grids closest to it at the end. Thereafter the method accumulates the projection of each of the nine vectors in the Z direction, compares the results to the preset threshold, and identifies as well as classifies the laser point. To validate the effectiveness of the proposed method, this study selects six groups of test data from the international society for photogrammetry and remote sensing (ISPRS) under different terrain conditions and generates 1 m × 1 m resolution DEM using ground points extracted before and after the post-processing filtering as well as performs linear fitting with reference DEM in the same research area. The results show that when compared with a single progressive morphological filtering algorithm, the combined algorithm of progressive morphological filtering and post-processing filtering based on space vector projection can achieve higher precision of point cloud filtering and DEM construction in urban area and rural area with continuous terrain as well as has good applicability and reliability.
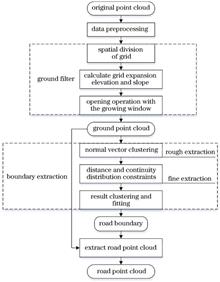
Vehicle-based laser scanning is extensively used for urban three-dimensional data acquisition because of its advantages of fast, high accuracy, and high density. However, it is not easy to accurately and efficiently extract urban road point clouds because of the large amount of data and multiple targets in urban scenarios. Based on the progressive morphological filtering algorithm, this study proposes an algorithm using grid approximation rather than three-dimensional space point operation and adaptive calculation of filtering parameters. As per the spatial distribution characteristics of urban roads, using the driving track information of scanning vehicles, the road boundary points are extracted using normal vector clustering, distance constraint, and continuity distribution constraint methods. Moreover, the accurate road boundary is generated by result clustering and fitting to achieve fast and accurate extraction of the road point cloud. The experimental results demonstrate that the accuracy, integrity, and overall quality of the road boundary extracted using the proposed algorithm are >90%. This shows that the difference between the boundary position and detected value is <3 cm.
To overcome low detection accuracy, false and leak detections for medium- and small-scale targets, rough segmentation for building boundary of traditional semantic segmentation network, we propose a high-resolution remote-sensing image building change detection method based on deep learning. The proposed method adopts the coding-decoding structure. At the coding stage, the residual network is used to extract the image features. The dilated convolution and pyramid pooling module are introduced in the deepest features of the encoder to enlarge the receptive field and extract the multiscale image features. At the decoding stage, the attention module highlights the useful features, and the features with different scales and resolutions are aggregated. We performed experiments on large-scale remote-sensing building change detection datasets. The results show that the proposed method can obtain deep-layer semantic information and pay attention to detailed information. It also has a considerable improvement in precision, recall, and F1 score. Additionally, the proposed method performs better than other semantic segmentation networks in multiscale target detection and building boundary extraction.
A syllable segmentation algorithm with the logarithmic envelope feature of Chinese speech is proposed to improve the segmentation effect of existing continuous Chinese syllable segmentation algorithms in noisy environment. The voice envelope is obtained by curve interpolation, and then the logarithmic time-domain envelope is obtained by filtering and logarithmic operation. Extreme points are obtained with the threshold judgment. Finally, the syllable segmentation boundary is determined according to the distribution of extreme points. The proposed algorithm is more effective than traditional ones for syllable segmentation of Chinese speech without noises, and still has a high segmentation accuracy at low signal-to-noise ratio.
Aiming at the serious safety accidents caused by the defects of positive and negative electrodes of lithium batteries, a defect detection method for the distance between positive and negative electrodes of lithium batteries is proposed. Firstly, the X-ray image of the lithium battery is obtained, the region of interest in the image is intercepted by the watershed algorithm, and the region of interest is rotated and corrected. Secondly, aiming at the problem that it is difficult to segment the negative linear region of the lithium battery, a horizontal gradient template is designed to extract the positive boundary and intercept the negative linear region of the lithium battery. Then, a multi-scale retinal enhancement algorithm and an extended differential template are used to extract the negative line. Finally, the vertical coordinates of the line are obtained by horizontal projection of the extracted negative line, and the coordinates of the positive and negative pole points are obtained according to the positive gradient and the extracted negative line, so as to obtain the positive and negative distances of the lithium battery. The experimental results show that the proposed algorithm has low missing rate and stable operation and meets the industrial requirements.
In this paper, we proposed an improved BSCB model based on the autogenous theory segmentation system to repair defective digital images of Chinese paintings. First, the segmentation model using the sub-channel autogenous theory was used to accurately separate the area to be repaired from the background area, and the Reinhard color migration algorithm was used to specify the color mark to facilitate the automatic recognition by the computer. Finally, the Laplacian smoothing operator in the traditional BSCB algorithm comprehensively considered all neighbors of homogeneous diffusion causing image blur, isoline crossing. Furthermore, the improved BSCB model based on the approximation of smoothing and gradient (ASG) operator was used to repair the marked area to repair the defect on the Chinese painting images, such as damage, color distortion, and loss of details. The research results show that compared with traditional repair algorithms, the proposed algorithm has better repair effects for different defect types of traditional Chinese painting images and has practical application values.
In this paper, we propose a novel crack detection algorithm based on feature enhanced whole nested network to resolve the issue of inaccurate crack segmentation caused by complex background and changeable texture of concrete cracks in natural scenes. First, based on the holistically-nested network (a deep learning edge detection network), the multi-scale supervision mechanism was adopted to integrate the prediction results of concrete cracks of different scales to enhance the expression ability of the network to the linear topology of concrete cracks. Then, we used a convolution-deconvolution feature fusion module to effectively integrate the deconvolution deep semantic features and convolution shallow detail features of concrete cracks. The deep semantic features can reduce the interference of complex backgrounds and improve the feature response of the fuzzy crack area. The shallow features can improve the expression ability of crack details and the quality of crack features. Finally, we proposed a hybrid void convolution boundary thinning module that used residual network and void convolution group to refine the fracture boundary and improve the accuracy of fracture segmentation. Using the Bridge_Crack_Image_Data dataset and Crack Forest Dataset, the accuracy of the proposed algorithm was 92.1% and 91.6% and the F1-score was 80.2% and 91.1%, respectively. The experimental results show that the proposed algorithm obtains stable and accurate segmentation results in complex natural environments and attains strong generalizations.
A multiscale Retinex image enhancement algorithm in HSV space based on illumination compensation is proposed to solve the under exposure of images acquired in low-light conditions. First, in HSV space, the intrinsic protrusion and illumination compensation layers both replace the original luminance component. Then, the intrinsic protrusion layer is processed by improved bilateral kernel function (IBKF), and the reflection layer is obtained according to multiscale Retinex. The illumination compensation layer is processed by optimizing the bilateral Gamma function through sparrow search, and firefly disturbance is introduced in the later stage of sparrow search to make it converge to the global optimum faster. The illumination layer is extracted from the brightness transition layer. Finally, the reflection and illumination layers are fused, and color space conversion is employed to generate the final output image. The experimental results show that the proposed algorithm improves the illumination loss in the process of image enhancement as well as image clarity and obtains better visual perception.
A fabric surface defect classification technique based on spatial attention multiscale feature fusion is designed to address the problem of low-classification accuracy caused by complex texture and varied defect kinds of the fabric surface. The multiscale pyramid pooling module is used to maintain the information integrity of the feature map, and the rich semantic information extracted from the high-level feature map is used as a priori information to guide the low-level features, realizing the fusion of high-level and low-level features; the improved spatial attention module is integrated into a convolutional neural network to enhance the differential expression of features. The improved class activation mapping method is used to obtain the defect classification information and location information. The fabric surface defect image is recognized and detected using data augmentation and transfer learning methods. The experimental results show that the proposed algorithm can effectively increase the accuracy of fabric defect classification and obtain defect location information without manual location labeling.
A fast image defogging method combining dark channel and global estimation is proposed to address the problems of inaccurate estimation of transmittance value, halo effect at the abrupt change in scene depth of field, color distortion in the sky region, and poor real-time performance of the algorithm in the dark channel prior method. Firstly, the minimum intensity values of the R, G, and B color channels of each pixel in the image are obtained. The atmospheric scattering model combined with the global estimation method is used to obtain the transmittance value without block effect using a simple and fast linear model. The transmittance obtained by the dark channel prior method is then linearly fused with it. The transmitted value is then adaptively adjusted according to the characteristics of the foggy image to improve the accuracy of the transmittance estimation. Finally, the defogged image is restored by combining the atmospheric scattering model. The experimental results show that the transmittance value obtained via the proposed method is more accurate, which can effectively restore the details of the image and avoid the halo effect and color distortion. Simultaneously, the algorithm's processing speed is faster, making it easier to meet the requirements of a high-resolution visual system.
Aiming at the problem that the traditional multi-scale feature matching algorithm is difficult to maintain the image local accuracy and edge details in the process of high-speed railway catenary image matching detection, an improved accelerated nonlinear diffusion (AKAZE) algorithm for high-speed railway catenary image feature matching is proposed. Firstly, the method of edge feature and local binary pattern texture feature fusion is used to overcome the shortage of feature points in traditional catenary image. Then, the improved AKAZE algorithm is used to extract the features of catenary image, and the binary robust independent elementary feature (BRIEF) descriptor is proposed to describe the feature points. Next, the false matching points are eliminated by fast similar neighborhood search and random sampling consistent algorithm. Finally, the image difference method is used to realize the matching detection of catenary image. Experimental results show that, compared with the AKAZE feature matching algorithm, the average matching accuracy of the proposed algorithm is improved by 22.16%, and the operation efficiency of the algorithm is also greatly improved.
Graph signal processing is one of the most effective methods to solve irregular data. For this reason, a sparse recovery algorithm based on clustered class graph signals is studied. For complex and irregular array signals, the similar signal atoms are clustered and divided into blocks, the spatial structure of the graph signal is constructed, and the corresponding clustered blocks orthogonal matching pursuit based on graph signal algorithm is designed by using graph filter. In order to verify the effectiveness of the proposed algorithm, a comparative experiment with five algorithms is carried out. Simulation experiments show that the running time of the proposed algorithm is much shorter than other mainstream algorithms under the same sampling rate, and at the same time, the proposed algorithm has a higher peak signal-to-noise ratio at a smaller sampling rate.
This study proposes a depth estimation method based on progressive optimization of a multistage neural network to accurately and robustly estimate the depth of light field. A four-level depth neural network is used to extract features from sub-aperture images in horizontal, vertical, diagonal, and anti-diagonal directions and estimate the depth map of the central viewpoint. In each subnetwork, the encoder-decoder structure having a jump connection is used to extract global and local features. The structure and training strategy of gradual optimization are adopted among subnetworks at all levels, i.e., the depth map generated by the former subnetwork is used as the input of the latter subnetwork to guide its depth estimation. The experimental results demonstrate that the proposed method can generate a high-quality scene depth map, particularly at the object boundary. Moreover, the proposed method has good robustness to input images having different resolutions. It has the advantage of efficient reasoning depth value, which can meet practical application requirements better.
At present, the supervised person re-identification methods focus on the problem of single modality (visible image). However, in addition to visible images, there are a large number of infrared images which lack color and texture information in the 24-hour surveillance system. Therefore, the cross-modality pedestrian retrieval method can effectively improve the practicability of person re-identification technology. The current cross-modality person re-identification methods ignore the unique discriminant features from different modalities, which leads to the performance limitation. This paper proposes a cross-modality person re-identification method based on cross-modality identity mutual prediction learning and fine-grained feature learning. A modal specific identity classifier is designed to improve the discrimination and robustness of modal specific features. A cross learning mechanism is constructed to promote the network to transform the specific features of different modal into modal invariant features, so as to make effective use of the modal specific discriminant information. In addition, fine-grained feature learning further enhances the discrimination of network feature representation from both local and global aspects. Comparisons with the state-of-the-art methods on open datasets SYSU-MM01 and RegDB show the advantages of the proposed method.
Aiming at the problem of image matching model estimation in the condition of high outliers ratio, an algorithm of inliers ratio promotion based on the global topological distribution of matching points is proposed. The algorithm can filter out some outliers only by the topological distribution characteristics of matching points and improve the inliers ratio, which can be applied to all the model estimation algorithms. First, matching types are divided into identical distribution and non-identical distribution based on the geometric topological distribution of inliers, and the matching model is given based on the two matching types. Second, the algorithm of inliers ratio promotion is given. Finally, series of interfaces are given to combine the proposed algorithm with the existing model estimation algorithm. In the experiment, some image matching model estimation algorithms are combined with the proposed algorithm. The experimental results show that the proposed method can significantly improve the inliers ratio and decrease the time consumption of the original model estimation algorithms after the combination with the proposed algorithm.
The alignment system automatically adjusts the beam of a high-power laser driver; thus, it is the main method to ensure high beam quality. It performs feedback control based on the results of alignment image processing, wherein the recognition and extraction for the laser spot and reference center is key. In this paper, the ant colony algorithm is introduced into the extraction of collimating reference contour and spot contour. The image gray gradient is used as the pheromone to improve the edge extraction ability for the reference and spot. At the same time, the ant colony algorithm is optimized according to the collimating image characteristics to enhance the adaptability of the collimating system.
The estimation and correction of lung respiratory motions are crucial for the image-guided radiotherapy of lung cancer, which require motion displacement information obtained using the image registration technology. However, lungs are typical moving organs that involve complex deformations during the breathing cycle, owing to which the three-dimensional computed tomography (CT) image registration of lungs becomes difficult and time-consuming. Currently, the registration of lung CT images remains a challenge that requires urgent attentions. In this study, a nonuniform B-spline image registration method based on the adaptive regularization term is proposed. First, a nonuniform B-spline deformation model is constructed, in which the control point gird is initialized using spatial adaptive sparsity based on the curvature according to the characteristics of the physiological structure of the lung to improve the registration efficiency. Furthermore, by designing the spatial position weights of the pixel points, the smooth regularization and total variation regularization terms of the deformation field are adaptively combined to improve the registration accuracy. The effectiveness of the proposed method is verified via experiments on public data sets and comparison with some other registration methods.
The pulse sequence image sensor is a high-speed bionic image sensor, and its image quality deteriorates because of the influence of noise. Spatial noise is attributed to the mismatch of the comparator and other devices, and the temporal noise arises from random noise and single-code flicker noise under the synchronous readout mechanism. This study establishes a noise model based on noise research and the sensor principle, and simulates and predicts the time error caused by noise under different parameters such as photocurrent and integral voltage drop. Results show that increasing the integral voltage drop will reduce the fluctuation of the time error rate caused by single-code flicker noise and the size of the time error rate caused by other noise sources. Further, increasing the photocurrent will increase the fluctuation of the time error rate caused by single-code flicker noise and increasing the junction capacitance will increase the time error rate caused by temporal noise. Finally, the noise characteristics of a chip are evaluated in the pulse interval reconstruction mode and the aforementioned analysis is validated. The findings of this study have guiding significance for optimizing the design of pulse sequence sensors, handling noise, and reconstructing stable images.
To address the problem of a small field of view of RGB-D data obtained using a single imaging system, where a large field of view is required, an RGB-D data stitching method is proposed based on spatial information clustering. Based on the spatial information present in RGB-D data, the distance between object points is defined to realize spatial information clustering using a simple linear iterative clustering (SLIC) on the RGB-D data. The scene is divided into several planar sub-blocks. Each sub-block shows homography, which can be used to accurately determine the homographic matrix and then realize the accurate splicing and fusion of small-field RGB-D data to generate large-field RGB-D data. Results of a real scene-based experiment shows that the proposed method can decrease the distortion during image warping and reduce the dislocation in overlap regions during stitching. Based on the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) values, the efficiency of RGB-D data stitching based on spatial information clustering is quantitatively shown to improve compared with global stitching.
The intersection of a printed document and stamp-seal determined in a sequence is one important method for confirming the authenticity and relative manufacturing time of document components. The spectral domain optical coherence tomography (OCT) system having a wavelength of 900 nm is used to examine several intersecting line samples made using laser and inkjet printers with oil-based and water-based stamp seals, thus obtaining 2D tomographic and 3D stereo images of the intersection line region to compare the imaging characteristics presented using two types of printers and determine the intersecting line sequence. This study investigated 120 intersecting line samples, including 30 groups made by laser printers and stamp seals and 30 groups obtained using inkjet printers and stamp seals. Each group of samples was repeated multiple times, and multiple areas were selected to repeat the test. The experimental results show that the contrast in the luminance distribution of the transmitted light reflected in the OCT images of the same intersecting line sequence formed by laser and inkjet printers differed. This can provide a reference for discriminating the intersection line sequence of printed documents and stamp seals.
The digital image correlation (DIC) method is a non-contact deformation measurement method, including the subset-DIC method and the global-DIC method. The subset-DIC method cannot consider the deformation compatibility, which leads to some errors in the localized deformation measurement results. The global-DIC method can fully consider the deformation compatibility, but it has a lower measurement efficiency than that of the subset-DIC method. A DIC method is proposed based on a combination of element matching and subset matching for localized deformation measurements. For deformation measurements beyond strain localization, the results of the subset-DIC method are used to determine the computational zones of the global-DIC method, and deformations of these zones are obtained by using the global-DIC method, then the results of the subset-DIC method are updated. A numerical experiment on the formation of a fictitious shear band and physical experiments of clay specimens in biaxial compression are carried out, and the measurement results of the subset-DIC method, the nine-node global-DIC method with subpixel initial values and the proposed method are compared. Results show that the proposed method can ensure the accuracy of localized deformation measurements with a few increases in time for an appropriate size. The maximum value of the maximum shear strain of the proposed method is higher than that of the subset-DIC method at the center of the shear band. Therefore, the proposed method and the nine-node global-DIC method with subpixel initial values are more suitable for deformation measurements beyond strain localization than the subset-DIC method, and the proposed method has more advantages in measurement efficiency than those of the nine-node global-DIC method with subpixel initial values.
Motion measurement system can simultaneously collect three-dimensional (3D) laser point clouds, image texture, and the position and attitude data; however the registration fusion of image photos and laser point cloud is challenging to meet the needs of high efficiency and high overlap. This paper proposes a method to register video images with laser point clouds under motion measurement to solve this problem. The positioning orientation system (POS) sensor’s position and attitude data are used to calculate the initial registration value of keyframes in a video image and a laser point cloud using a collinear equation model. The iterative method for selecting weights based on Robust estimation improves the accuracy of initial registration values and determines the exact values of registration parameters. The stereo-dense matching point cloud is generated from the keyframe of the video image, and the nearest neighbor iterative registration is performed using the 3D laser point cloud. The experimental results show that the registration method of video image and a vehicular laser point cloud is feasible, and the registration accuracy is high, meeting the requirements of 3D reconstruction of urban streets, component acquisition, target extraction, and other measurement applications.
Orthogonal beam splitting imaging system has essential applications in dynamic pose measurement. Fast and effective matching of the feature points' coordinates of the target to be tested is the key to achieving dynamic measurement. Traditional coordinate matching methods have problems, such as slow speed and large dynamic error. Therefore, this study proposes multiple points' coordinate matching algorithm based on the cross-ratio invariability among feature points. According to the imaging feature of the orthogonal beam splitting imaging system, considering the cross-ratio invariabilities and sequence in projective transformation as constraints for coordinate matching, a collinear multi-point cooperative target was designed to complete the matching of image coordinates and object points. The possible overlap of coordinates during pose measurement was also discussed. The experimental results show that the coordinate matching time for per frame of the proposed method is only 3 ms. The error of the rotation matrix of the proposed method combined with optimal solution to the perspective-n-point problem method does not exceed 6°, furthermore, the error of the translation vector does not exceed 1.4%, which can be applied in rapid pose measurement.
This study proposes a semantic map construction method based on object segmentation to solve the problem that maps constructed using the traditional visual simultaneous localization and mapping (SLAM) lack semantic information and cannot understand the scene content to improve the ability of mobile robots to perceive the environment and perform advanced tasks. To begin, the improved semantic segmentation model DeepLab V3+ was used to segment a two-dimensional image to obtain the object's label. Further, the dense map was constructed according to the improved iterative closest point (ICP) point cloud splicing method, and the region growth algorithm was used to segment the three-dimensional point cloud. Finally, the semantic map was constructed by mapping the two-dimensional label to the three-dimensional dense map. Experimental results show that the improved DeepLab V3+ detects objects four times faster than the original method; the improved ICP algorithm is used for point cloud splicing, and the relative trajectory error is reduced by 16.4% when compared to the ORB-SLAM algorithm in the fr/360 sequence of the TUM dataset; finally, compared with the ORB+YOLOv3, ORB+MASK-RCNN, ORB+DeepLab V3+ methods, the proposed method not only reduces the redundant information of semantic map but also builds faster and occupies less storage.
The traditional grating fringe phase-shift method requires at least three grating images to extract the phase, which increases the measurement system's frequency and the image preprocessing workload. The Hilbert transform is used in a two-step phase-shift method to solve these problems. The Hilbert transform has the properties of a 90° phase shift and the ability to filter out the direct-current component. The phase extraction formula is used to calculate the phase after the grating fringe image has been processed by Hilbert transform. The nonlinear effect of the measurement system will distort the fringe images and the calculated phase will be inaccurate, which lead to the low accuracy of the final three-dimensional restoration. In the two-step phase-shift method, the formula of phase error caused by the nonlinear effect of the system is deduced, and the phase is iteratively compensated to weaken the influence of the nonlinear effect. The feasibility of the proposed method is verified via computer simulation, and the proposed method is applied to the three-dimensional surface shape reconstruction of the rail surface, providing an effective method for measuring rail wear and surface defects.
Existing image dehazing algorithms have problems in restoring hazy images with bright areas, such as color distortion, color offset, and brightness reduction. Aiming at the shortcomings of existing methods, a single image dehazing algorithm is proposed based on exponential mapping and adaptive weight energy function. Firstly, according to statistical law of the dark channel prior, the attenuation characteristics of the exponential function are utilized to construct a dark channel mapping model between clear image and hazy image. Subsequentially, the estimated value of the transmission can be calculated based on that of obtained dark channel. Secondly, according to the Markov property of images, a Markov network-based adaptive weight energy function is constructed to optimize the transmission and the down-sampling method is used to reduce the algorithm complexity. Finally, the haze-free image is restored by using the optimized transmission and local atmospheric light. The experimental results show that the restored images of the proposed algorithm have clear visual effects and high color fidelity. And several objective evaluation parameters reach the highest values. The histogram correlation coefficient reaches 0.4521, which is 67.3% higher than those of the average performance of comparison algorithms. In summary, the proposed algorithm can effectively solve the recovery problems of hazy image with bright areas.
The width measurement of cracks by machine vision has problems of offsets in the width direction of the cracks and inaccurate measurements. To this end, taking the cracks of reservoir dams as objects, the method of crack backbone refining and width measurement was studied. Based on image thinning, the proposed method refined the cracks' backbone further. The total number of points in the eight neighborhoods of each backbone's point did not exceed two. Redundant data points were simplified, and the number of neighborhood distribution types was reduced to 16, which enhanced the backbone's ability to describe the crack shape. The backbone's macroscopic and microscopic features were combined as a basis for the width measurement direction to obtain a more accurate measurement direction than a baseline method used for comparison. As a result, the proposed method achieved continuous and accurate visual measurements of the crack width. By adding two evaluation criteria, measurement recall rate and direction error, the proposed method was validated to be more accurate in actual engineering requirements than the baseline method. The proposed method has practical engineering applications and can be a reference for radial vision measurement of other slender and irregular targets.
The present tile defect detection algorithms mainly rely on manual design features and classifier. In addition, they face debugging difficulties and insufficient robustness in practical applications. Therefore, we proposed a texture tile defect detection algorithm using the improved YOLOv3 model. First, a convolutional autoencoder was added in front of the Darknet-53; the reconstructed images with weak defects were fused with original images to get richer input information. Further, the K-means clustering method was used to get new and more suitable anchors. Finally, to solve the problem of insufficient samples, we used the weights of a pre-trained model trained on a common data set to initialize the network to improve convergence performance. Results show that the average accuracy of the improved model increased by 5 percent, besides it kept the prediction speed of the original model and could effectively detect texture tile holes and scratches.
Aiming at the problem of person image style difference caused by cross-camera shooting in the process of person re-identification, this paper proposes a learning framework based on a cyclic vector quantization generative adversarial network (CVQGAN) and a self-calibrated convolution module. First of all, this paper designs a discrete vector quantization module, which is introduced into the process from encoding to decoding of the generator. The discrete vector in the vector quantization space is used to solve the problem that the original generator produces noisy pseudo images, therefore generating higher quality style conversion images. Then, the self-calibration convolution module is integrated into the convolution layer of the Resnet50 backbone network, and the multi-branch network structure is used to perform different convolution operations on each branch, so as to obtain features with stronger characterization ability and further solve the problem of style differences of the same pedestrian under different cameras. The proposed algorithm is validated by experiments on Market1501 and DukeMTMC-reID datasets, and the results show that the proposed algorithm can effectively improve the accuracy and robustness of person re-identification.
This paper proposes a three-dimensional reconstruction method based on speckle and phase hybrid light field modulation. First, based on the principle of binocular stereo vision, 2 frames of speckle and 3 frames of phase-shifted fringe patterns are projected on the surface of the tested object. Then, the collected speckle images are used for stereo matching to obtain a coarse disparity map, and two sets of truncated phases are sequentially analyzed by adjusting the fringe frequency. Finally, two sets of phase-assisted coarse disparity maps are used for precise matching, resulting in the highest-precision three-dimensional reconstruction. The experimental results show that, compared with the traditional method, the reconstruction speed of the method is faster, the accuracy is higher, and the robustness is stronger. In addition, the method does not require phase unwrapping, which solves the problem that the matching point appears near the boundary of the truncated phase period, which may easily lead to incorrect matching.
Aiming at the difficulty of identifying multi-target prohibited item in X-ray security images, a multi-target prohibited item recognition algorithm is proposed in this paper. First, considering practical application requirements, network performance and running speed, the residual network (ResNet50) is used as the backbone network, and a local reinforcement module is added to compensate for the checkerboard phenomenon caused by dilate convolution. Then, the features of different levels are processed by the dilated residual feature enhancement module and the transformable dilated space pyramid pooling respectively, and the multi-scale characteristics of prohibited item are adaptively learned. Finally, the attention mechanism is introduced to strengthen the learning ability of key channels and realize the feature focusing in the spatial dimension, so as to strengthen the detailed representation ability of the prohibited item area. The test results on the security inspection prohibited item image dataset show that compared with other comparison algorithms, the algorithm can achieve better segmentation accuracy on the premise of ensuring real-time performance, the mean intersection-over-union is 82.26%, and the image processing speed is 16.21 frame/s.
Traditional feature descriptors of point cloud data show disadvantages such as insufficient expressiveness, low computational efficiency, and poor robustness. Aiming at the problem that the binary shape context (BSC) feature descriptors, regions with a large curvature distribution cannot be effectively detected and the ambiguity of the local coordinate system suffers. This study proposes a point cloud data registration algorithm based on binary feature descriptors. First, the intrinsic shape signature keypoint detection method and three-dimensional surface patch estimation method are used to address the problem of semantics. Then, the Hamming distance and improved geometric consistency method are used for feature matching. Finally, the random sampling consensus is used to eliminate false matches. Experimental results show that compared with the fast point feature histogram, signature of histogram of orientations, and BSC algorithms, combining the algorithm with the iterative closest point algorithm can considerably improve the registration efficiency and reduce the registration error.
Considering the limited number of training samples of hyperspectral images and the influence of high spectral dimension on classification accuracy, a novel hyperspectral classification algorithm combined dynamic convolution with triplet attention mechanism (TA) is proposed. First, principal component analysis (PCA) is used to remove spectral redundancy. Then, the processed data are input into the modified residual network. Second, dynamic convolution is introduced in the residual network to extract deep and refined features. The TA model is used to interact with cross-dimensional information to focus on the extremely important hyperspectral spatial-spectral features and reduce the impact of useless information. Finally, the Softmax fully connected layer is used to realize the classification of hyperspectral images. The results demonstrate that the classification effect of the proposed algorithm outperforms six other classification algorithms on three public datasets of Pavia University, Kennedy Space Center, and Salinas. Furthermore, the overall classification accuracy of the proposed algorithm reaches 97.49%, 94.21%, and 98.65% on three datasets, respectively.
This study proposes an optimized ERFNet lane detection algorithm to reduce the imbalance between the speed and accuracy of current lane detection algorithms based on semantic segmentation. First, an efficient core module is designed; introducing operations such as channel separation and channel reorganization, the number of model parameters and calculations are greatly reduced. Then, the down-sampling is adjusted to increase the single-branch down-sampling process, which improves the model parallelism while reducing information loss. Finally, a feature fusion module is introduced at the end of the encoder, and the receptive field is expanded using dilated convolution to extract differently-scaled lane features. We compare the proposed algorithm with four lane detection algorithms based on semantic segmentation on the CULane dataset. Results show that the comprehensive F1-measure of the proposed algorithm is 73.9% when the intersection-over-union is 0.5, and the inference time per image can reach 12.2 ms, which is superior to the other four models and achieves a good balance between speed and accuracy.
To enhance the robustness of size estimation for shaft parts in visual measurements, this paper proposes a fast and high-precision vision measurement method for shaft part geometric dimensions based on parallel line fitting. Parallel constraint improves the noise resistance of the proposed method and enhances the adaptability of the industrial measuring device to its environment. First, a region of interest (ROI) was quickly found based on template matching. Then, a parallel line equation was established using the Ransac algorithm for the interior points of the two edge lines of a measured object. Additionally, a nonlinear optimization was performed based on the least square method to obtain the number of pixels occupied by the measured object. In the simulation, the anti-noise performance of the proposed method was verified by comparing it with traditional algorithms. Finally, a telecentric measuring platform was built to measure the shaft neck size for a stepped shaft. The results showed the effectiveness and feasibility of the proposed method.
The effect of different ultrasound intensities from 0 to 0.8 W/cm2 on the permeability and light penetration depth of glycerol solutions in human skin in vivo were investigated. The experiment used optical coherence tomography (OCT) imaging technology to perform quantitative continuous measurements. The results show that ultrasound has the ability to accelerate the penetration of glycerol solution and enhance the penetration of light through the skin with the intensity of pulsed ultrasound ranging from 0 to 0.8 W/cm2, and the optical clearing effect of the skin increases with an increase in ultrasound intensity. The sample that was only applied with glycerol solution was defined as the control group, and the sample with the ultrasound effect and glycerol solution applications was defined as the experimental group. When the results of experimental and control groups were compared, it was observed that the average permeability coefficient of 15% glycerol solution in human skin treated with 0.2, 0.4, 0.6, 0.8 W/cm2 pulsed ultrasound was increased by 2.6%, 9.5%, 14.7%, and 19.8%, respectively, compared to the samples with only 15% glycerol solution application. The average permeability coefficient of 30% glycerol solution treated with pulsed ultrasound in human skin was increased by 3.7%, 12%, 16.7%, and 22.2% respectively, compared to the control group that only used 30% glycerol solution. The conclusions suggested that the average permeability coefficient of glycerol solution increased with increasing pulsed ultrasonic intensity in the range of 0.2‒0.8 W/cm2.
With the rapid advancement of medical imaging technology and the rapid development in artificial intelligence, intelligent medicine has emerged as a prominent focus of medical study. Although ultrasound imaging technology has many therapeutic uses, most vascular extraction techniques are manual or semiautomatic, and the extraction results are highly subjective and error-prone. For preprocessing carotid artery features, this work uses a multiscale Hessian filtering synergistic technique. It then uses medical prior knowledge to extract the region of interest (ROI) of blood vessels, creates a traversal tracking search algorithm to find blood vessels, and automatically extracts the carotid artery vessel wall using pixel grayscale difference grading. The extraction accuracy can reach 89.3%. This study can lessen the load on physicians, reduce the rate of misdiagnosis owing to subjective diagnosis and allow physicians to perform a quantitative and qualitative examination of vascular morphological features, making clinical diagnosis more objective and accurate.
The excitation source for a spectrally focused coherent anti-Stokes Raman scattering (CARS) microscopic imaging system is a single femtosecond laser oscillator. The system uses a glass rod composed of SF10 to introduce a chirp into the femtosecond pulse for an enhanced spectral resolution. For single Raman displacement detection, a melamine sample is used to perform experimental spectrally focused CARS microscopic imaging research. Moreover, a half-wave plate is inserted in the pump and Stokes optical path of the spectral focus CARS microscopic imaging system. By changing the half wave, the polarization direction of the linearly polarized excitation pulse is changed, and the variation trend of the ratio of the resonant signal/nonresonant background with respect to the deflection angle of the half-wave plate is studied. Furthermore, the deflection angle of the half-wave plate is determined using the maximum ratio of the resonant signal/nonresonant background in a specific region of the sample.
As per the requirements of high imaging quality, large relative aperture, lightweight, and wide temperature adaptability of the non-cooling thermal imaging system, based on the structural analysis of the lightweight optical system, the initial power distribution of the system is solved using the principle of optical-passive compensation. Moreover, a lightweight long-wave infrared athermalization optical system is designed using the characteristics of binary diffraction surface different from infrared materials. The focal length of the designed system is 50 mm, and the F-number is 1. It is suitable for a long-wave (8‒12 μm) infrared uncooled detector with a resolution of 640×512 and pixel size of 12 µm. The optical system comprises three lenses having a total mass of 67 g. In the temperature range of -40 °C‒60 °C, the modulation transfer function of each field of view is close to the diffraction limit. The experimental results of room temperature demonstrate that the designed system has a good athermalization effect.
In the design, development, and data inversion of spaceborne lidar, the forward model is critical. This study establishes a forward model for observing clouds and aerosols using spaceborne lidar. It can simulate ice clouds and aerosols, as well as other complex scenes. The model as a whole is made up of 8 sub-modules. The simulation results in the 532-nm channel show that in the deep convection scenarios, the clouds are deep and the signal attenuation is serious, thus, only the distribution of the cloud top can be distinguished. The influence of cloud microphysical characteristics on the effective detection of aerosols must be considered in the ice cloud and aerosol scenes. In terms of parameter sensitivity analysis, the relationship between telescope diameter, satellite orbit altitude, laser single pulse energy, and the signal-to-noise ratio can help with instrument design. The comparison of the attenuation backscattering coefficient calculated by the forward model with the actual detection results of CALIOP/CALIPSO shows a good consistency in the structure of spatial distribution. However, owing to the uncertainty in the CALIPSO inversion algorithm and the difference in parameter settings between the inversion and the forward model, some minor differences at different altitudes when comparing the average of all profiles remain.
Filtering is a key step in the processing of airborne LiDAR point cloud data, and the morphological filtering algorithm has long been considered a classic and effective filtering algorithm for airborne LiDAR point cloud. Because the traditional morphological filtering algorithm retains poor terrain characteristics, which affords poor filtering results, a new morphological filtering algorithm based on thin-plate spline multilevel interpolation was proposed. In this algorithm, the filtering window was considered to reduce continuously during the morphological open-operation process and the thin-plate spline interpolation under different windows was used for processing. This process was iterated from top to bottom until the window size was smaller than the set minimum filter window size. Experiments were conducted using the test data set provided by the International Society of Photogrammetry and Remote Sensing. Results show that the accuracy of the proposed algorithm increases significantly, the filtering effect improves in areas such as buildings or slopes, and topographic features are effectively retained.
The existence of cloud shadows in remote sensing images severely affects image interpretation and application. Therefore, finding an efficient shadow compensation method is essential to recover the shaded information. Because the calculation method for obtaining γ coefficient in the conventional Gamma transformation compensation model relies only on the statistical characteristics of the shadowed area, this method cannot reflect the difference between the pixels within the shadowed area. Therefore, this study proposes a self-adaptive Gamma algorithm using the image information from different levels to compensate for the shaded information automatically in the cloud shadows. First, the cloud shadows were detected using remote sensing images and the feature mean and variance of the shadow regions were calculated. Then, the improved logarithmic transformation γ-factor calculation method was designed. By synthesizing the multi-level mean variance information of the local window of pixels in the shadow area, the shadow area and non shadow area, the weighted solution can reflect the overall characteristics and internal differences of the shadow area. Moreover, this method can realize the pixel-level adaptive compensation. Therefore, each pixel in the cloud shadow area can be reasonably compensated to achieve the same effect as the nonshaded area. The experimental results show that the proposed method can effectively compensate the cloud shadow cast by clouds with different shapes and thicknesses. The brightness and contrast of cloud shadows are considerably improved. Additionally, the details of the regional features in cloud shadows are better recovered.
A large amount of granite is distributed in the Longling area of western Yunnan. Its surface weathering is high, and there is a lot of rain, resulting in a severe erosion of the side slope surface and extremely serious soil and water loss. Therefore, targeted soil and water loss control scheme is urgently required. In this study, the weathered sandy soil in the granite distribution area of Longling County, Yunnan Province was considered as the research object and artificially simulated rainfall experiments were designed for three soil and water conservation measures, including engineering, plant, and engineering + tillage measures, and three surface slopes (10°, 20°, and 40°). Three-dimensional laser scanning technology was employed to monitor the effects of soil and water conservation measures under different slopes with high precision and real time, and the effectiveness of soil and water conservation measures was assessed using the characteristics of sediment yield rate and sediment reduction benefit. The experimental results show that the slope is the most important factor influencing slope erosion under certain rainfall intensity conditions; the steeper the slope, the faster the sediment yield rate. The three types of soil and water conservation measures have different degrees of sediment reduction effect. The effect of soil and water conservation of the two combined measures is far superior to that of a single measure.
Building profile extraction is crucial in three-dimensional urban reconstruction. The traditional Alpha-shapes profile extraction algorithm has strong robustness and easy implementation, but the extracted profile is easily interfered by noise points, making it difficult to obtain an accurate profile edge. This paper proposes an improved Alpha-shapes profile extraction algorithm to solve the abovementioned problem. First, the initial profile points extracted via the Alpha-shapes algorithm are selected by a random sample consensus algorithm. Thereafter, the key profile points are determined using the Douglas-Peucker algorithm. Finally, an accurate profile is extracted through forced orthogonal optimization. Three groups of point clouds with different building shapes are used for experimental analysis. The experimental results demonstrate that the algorithm is superior to the traditional Alpha-shapes algorithm as the improved algorithm can obtain more accurate building edges and effectively overcome the jagged edges of the traditional Alpha-shapes algorithm, and the accuracy, completeness and quality are also better than those of the traditional Alpha-shapes algorithm.
Airborne LiDAR point cloud features are abundant, but their density is uneven. Efficient classification for the airborne LiDAR point cloud is a key task in remote sensing and photogrammetry. Because the density of the point cloud is not uniform, a density-dependent point cloud convolution operator, PointConv, was introduced to perform density weighting on the basis of traditional three-dimensional (3D) convolution. At the same time, the attention mechanism module was proposed to correct the importance of extracted local information and improve the ability of the network for identifying different point cloud instances. The effectiveness of the proposed method is demonstrated by the classification results on the GML_DataSetA urban outdoor scene airborne point cloud dataset and the ISPRS Vaihingen 3D semantic marker reference dataset.
A large number of experiments are conducted at Dunhuang national radiometric correction field every year to provide calibration services for earth-observation satellites at home and abroad. However, over several years, there are only few studies regarding the accuracy of the ground spectral sampling scheme when Dunhuang field obtains pixel-scale surface reflectance. To quantitatively evaluate the accuracy of different ground sampling schemes, the best sampling point locations were determined to obtain the surface reflectance at different pixel scales and realize high-precision and high-efficiency operational measurement of Dunhuang field. The accuracy of surface reflectance sampling methods at different pixel scales was analyzed quantitatively using Dunhuang’s high-resolution unmanned aerial vehicle data and 2 m panchromatic data from the GF-1 satellite. Based on the results, a five-point system sampling scheme is suggested to obtain pixel-scale surface reflectance from Landsat by preliminarily calibrating a 2 m quadrat within the 150 m national field in Dunhuang. For the pixel-scale resolution of meteorological satellites, the five-point-simulated annealing sampling scheme is suggested to determine the position of the 2 m quadrat in the newly selected 3 km site. In both the cases, a spectrometer is used to measure the five-point system sampling method in each 2 m quadrat.
Recently, color index and light detection and ranging (LiDAR) point cloud data have been extensively used in agriculture and forestry remote sensing. However, they bring the characteristics of different objects in the same spectrum and data redundancy. Considering pitaya plants in the Karst Plateau Valley area as an example, the method test area and accuracy verification area were set using UAV visible light images and image matching point cloud data. By fusing the calculation results of four color indexes of visible band difference color index (VDVI), red green blue color index (RGBVI), normalized green blue difference index (NGBDI), normalized green red difference color index (NGRDI) and canopy height model (CHM) data, the identification rules of pitaya single plant that fuse color index and spatial structure of point cloud data were developed for segmentation and extraction. The accuracy evaluation data of real pitaya plant contour was established as a reference. The precision of fusion extraction of four color indexes and point cloud data was compared with a single factor of color index or CHM segmentation. Then, the optimal extraction scheme is selected to confirm the feasibility of the proposed method. The results are as follows. The fusion method of the color index and spatial structure has higher extraction accuracy. The F measures are >91%, and the difference between the matching area and mean values of the real value is ~0.1 m2. The VDVI index fusion results achieved the highest accuracy. The area value per plant was the closest to the true value; the root mean square error (RMSE) was 0.28 m2, and the area value data were concentrated. The F measure in the accuracy verification area was 88.12%, and the RMSE was 0.27 m2. The overall extraction effect of pitaya plants was good; however, low shrubs could affect the accuracy of pitaya plants identification to certain extent. The proposed method of fusion image spectral features and spatial structure of point cloud data can effectively enhance plant recognition features. It has good adaptability for identifying pitaya plants in Karst mountains, which can provide a reference for the extraction potential of a single pitaya plant in Karst mountains..
Imaging ellipsometry is a measurement technology developed using traditional ellipsometry combined with imaging technology to adapt to the small and precise trends of various devices and materials. With the rapid development of nanotechnology, the technology has shown a trend of rapid developments and a wide range of applications in many fields, such as materials science, biology, and semiconductor. In this paper, we introduce the principle, advantages, and disadvantages of this technology. Furthermore, we comb the development history and describe the application progresses of this technology in material science and biomedicine, while discussing developing trends of this technology. This study hopes to serve as a review article on ellipsometric imaging technology and help promote the development of the technology and its application in more fields.
Vegetables are one of the most essential foods in human's daily diet. They not only provide various vitamins required by the human body but also supplement nutrients, such as dietary fiber. Detecting vegetable traits is critical during the growth and development precesses. Hyperspectral imaging technology is a new type of non-destructive testing technology that combines traditional spectroscopy with machine vision technology. It can not only obtain image dimension information but also delve deeper into the spectral dimension information within vegetables and investigate the changes of vegetable traits at the same time, based on the image dimension level and spectral dimension level of vegetable images. This article reviewed the research results of hyperspectral imaging on the non-destructive detection of vegetable traits from three aspects: the internal quality detection of vegetables, nutrient element monitoring, and disease diagnosis. The future development direction is proposed combined with the existing problems.
Detection and imaging technology in a scattering medium is widely used in the biomedical field. However, the current technology still has some problems, such as low efficiency of external excitation or uncertain focus position. Thus, this paper proposed region variance feedback using the wavefront shaping method to realize non-invasive focusing deep in a scattering medium. Here, the region variance of the target speckle was used as the feedback of the wavefront shaping, and the excitation speckle in the scattering medium was focused on a single target by phase modulating with a spatial light modulator. The results show that the region variance method using the wavefront shaping realizes deep focusing on a single target in the scattering medium and selectively focuses on the determined target position according to the region selection. This selective focusing technology provides a new way for multiple targets imaging in biological tissue.
Laser-induced breakdown spectroscopy (LIBS) is applied to detect porphyra yezoensis elements in offshore seawater. The spectrum shows that porphyra yezoensis contains Ca, Mg, Mn, Fe, K, P, Na, Zn, Cu, Sr, Si, O, C, and other elements. To investigate the feasibility of using porphyra yezoensis as a marker of heavy metal pollution in offshore seawater to reflect the degree of pollution, four lead solutions with varying concentrations are prepared to simulate polluted offshore seawater in this experiment, and fresh samples of porphyra yezoensis are immersed in the solutions. The spectra of this contaminated porphyra yezoensis are determined using LIBS. Quantitative analysis is performed using the internal standard method. The correction curve is obtained after fitting. The plasma temperature and electron density are calculated in the experiment to confirm the quantitative work's accuracy as well as the local thermodynamic equilibrium environment is verified. Additionally, CN molecular bands observed in the spectrum of porphyra yezoensis are simulated. Two important parameters of CN molecules are detected: vibrational temperature and rotational temperature. Finally, vibrational temperature, rotational temperature, and plasma temperature are compared and discussed briefly. The results verify the feasibility of applying LIBS to the field of offshore sewage detection.
Wave band selection is an effective means to reduce the dimension and much redundancy of hyperspectral data, and it is an important prerequisite for pixel classification of hyperspectral images. It is a complex combinatorial optimization problem in essence, and it is difficult to get satisfactory solution by traditional search methods. To solve the above problems, a method of hyperspectral band selection based on golden sine and chaotic the spotted hyena optimization algorithm (GSSHO) is proposed. Firstly, chaos strategy is used to initialize the spotted hyena population to improve the randomness and diversity of the population. Secondly, golden sine algorithm is used to improve the original spotted hyena optimization (SHO) algorithm to search individual position update mode to improve the global search ability of the algorithm. Finally, a fitness function combining classification accuracy and band number is designed to evaluate the optimization performance of the algorithm. On hyperspectral remote sensing data sets, this method is compared with other advanced optimization algorithms. The experimental results show that the number of bands selected in this algorithm is close to one tenth of the original band, and the classification accuracy of Pavia Centre data set is up to 99.08%, which is better than those of other comparison methods. It can find the optimal solution with more reasonable convergence direction, and the number of selected bands is less, and the classification accuracy is higher. It is an efficient method for selecting wave band.
Deck paints are important evidence materials in maritime criminal cases. The rapid, accurate, and nondestructive identification of deck paints is crucial in forensic science. Infrared spectra are commonly used for such a fast and nondestructive identification analysis. Pretreatments can eliminate the noise and background interference of the spectra and improve the recognition rate of the dataset. In an experiment, 100 samples from five brands of deck paints were collected. Support vector machine (SVM) and Bayes discriminant analysis (BDA) were used to identify the deck paint spectra after several infrared pretreatment combinations, and the optimal infrared pretreatment method was screened according to the recognition rate. Results show that the effect of BDA is better than that of SVM. The recognition rate of the training dataset of the deck paint spectra processed using Savitzky-Golay second derivative smoothing and Fourier self-deconvolution is 100%, and the recognition rate of the test dataset is 96%. The selected method shows a good classification effect and strong qualitative ability and can be used as a reference for identifying deck paints in forensic science.