








Please enter the answer below before you can view the full text.
9-8=

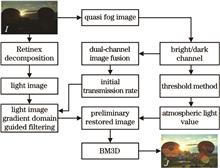
Aiming at the problems of halo artifacts, edge details loss and noise amplification in the low-illumination image enhancement process, an image enhancement algorithm was proposed based on dual-channel prior and illumination map guided filtering. As the traditional fog-degradation model only uses dark-channel prior for image enhancement, local areas have different depths of field, which thus results in the problems such as image overexposure and halo artifacts. As for these problems, the bright and dark dual-channel integration method is adopted to calculate the atmospheric optical value and transmittance. As for the problem that edge information is easy to be lost, the illumination map gradient domain guided filtering is adopted to improve and refine transmittance. As for the problem of noise amplification in the enhancement process, the BM3D filtering is adopted for denoising. The experimental results indicate that, in different low-illumination images, the proposed algorithm shows an obvious improvement in denoising, halo eliminating, brightness adjustment and edge preservation if compared with other low illumination enhancement algorithms.
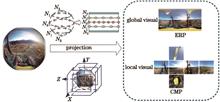
A three-dimensional (3D) panorama provides a 360° perspective for users, giving them a strong 3D sense of reality. Although researchers have developed a large number of algorithms to detect salient areas in two-dimensional and 3D images in recent years, there are few studies on the saliency detection of stereoscopic panoramic images. All available context information in an equirectangular projection (ERP) image which is used as the global information is used, the cubic projection (CMP) image is used as local information, and global and local visual saliency maps are integrated, taking into account the projection characteristics of the panoramic image and the CMP image which helps to eliminate the distortion and frame effect caused by the top and bottom. In this work, the proposed stereo panoramic saliency detection model is composed of two parts, i.e., color similarity and regional contrast methods. First, multi-scale linear iterative clustering superpixel segmentation is carried out on the images, and the color contrast feature map is obtained according to the color difference of pixel blocks. Then, the regional contrast is calculated according to the compactness of spatial distribution. The saliency map is obtained based on feature maps of color contrast and regional contrast. The final stereoscopic panoramic saliency map is obtained by combining equatorial migration and fusing depth information. Finally, the results obtained are compared and verified in the public stereo panoramic image database ODI. Experimental results show that the saliency maps obtained by the proposed method have high precision, recall rate, and F-measure value, and the comprehensive performance of the proposed method is better than that of the six classical saliency prediction algorithms. The proposed model not only makes full use of the image information, but also effectively suppresses the complex background area, so as to obtain the saliency map that is more consistent with the visual perception.
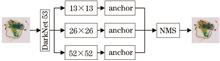
To detect prohibited items in X-ray images, this study proposed a one-stage dual-network object detection algorithm based on deep learning. Based on the one-stage object detection algorithm Yolov3 and combined with the idea of a composite backbone network, a Yolo-C object detection network is developed. The backbone of Yolo-C (DarkNet-C) consists of an assistant backbone network (Darknet-A) and a lead backbone network (Darknet-L). Each feature layer of the DarkNet-A is cascaded by feature with the upper feature level corresponding to DarkNet-L and then propagated to the next feature level. Finally, a feature map representing image information is obtained. The feature enhancement block (FAB) is introduced to improve detection performance of small object. Feature fusion is performed on the cascaded feature maps to enhance the nonlinear expression ability of features and achieve the purpose of feature smoothing. Besides, transfer learning and data enhancement was adopted to train the network and improve its robustness. The mAP in the SIXray_OD dataset is 73.68%, and detection speed is 40 frame·s -1. In the X-ray image detection field, Yolo-C has effectively improved the detection accuracy of different prohibited items and met the real-time requirements of detection.
The traditional image stitching method has low processing speed, is inefficient, and unable to meet the requirements for fast and accurate stitching of high-resolution images. This paper proposes an improved algorithm of high-resolution image stitching based on Oriented FAST and Rotated BRIEF (ORB) features. First, based on the ORB feature point extraction, the Hamming distance is used for fast rough matching. Then, the matching point pair is optimized based on the progressive sampling consistency (PROSAC) algorithm. Next, after removing the mismatch point pair, the image transformation matrix is solved. Finally, the weighted fusion algorithm is used to fuse the overlapping areas of the image to remove the stitching traces. Experimental results show that the proposed algorithm not only has more advantages in processing speed but also has a higher matching accuracy compared to traditional algorithms. In addition, it can realize fast and accurate stitching of high-resolution images.
Aiming at the problem that the existing pixel loss-based super-resolution image reconstruction algorithms have poor reconstruction effect on high-frequency details, such as textures, an image reconstruction algorithm based on an improved super-resolution generative adversarial network (SRGAN) is proposed in this paper. First, remove the batch normalization layers in the generator, combine the multi-level residual network and dense connections, and use the residual-in-residual dense blocks to improve the network’s ability for feature extraction. Then, the mean square error and perceptual loss are combined as the loss function to guide the generator training, which preserves the image’s high-frequency details and avoids the artifacts’ appearance. Finally, the last Sigmoid layer of the discriminator is removed to better converge the training process, and the relativistic loss function is used to guide the discriminator training. The experimental results on the COCO dataset show that compared with the original SRGAN algorithm, the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) of the algorithm in the Set5 data set are increased by 0.86 dB and 0.0123, respectively, in the Set14 data set, the PSNR and SSIM of the algorithm are improved by 0.69 dB and 0.0090, respectively. The mean opinion index and visual effect of the algorithm are far better than other algorithms.
In view of the poor clustering effect of the fuzzy C mean (FCM) clustering algorithm under the data set, and the similarity measure based on Euclidean distance only considers the local consistency between data points. This paper presents a weighted FCM clustering algorithm based on Jeffrey divergence similarity measure (JW-FCM), and introduces the similarity measure derived from Jeffery divergence. First, perform feature weighting on the FCM algorithm, assign appropriate weights to different feature values of the data, and then combine the Jeffery divergence with the weighted FCM algorithm to obtain the JW-FCM algorithm. The JW-FCM algorithm is compared with several related algorithms on the artificial data set and UCI data set. Through experimental analysis and comparison, it is proved that the JW-FCM algorithm has better convergence, robustness, and accuracy. The experimental results show that the improved algorithm shows better clustering effect.
In this study, MSTAR data were selected as a sample set to solve the problem of the high noise of the synthetic aperture radar (SAR) images leading to a low target recognition rate. First, the necessity of adding an attention mechanism to the network was analyzed. Subsequently, the residual shrinkage piece was introduced in the residual attention network. An experimental analysis was performed from the perspective of the recognition rate and number of parameters. Model S was obtained by improving the first stage and the output stage of the residual attention network. Consequently, the recognition rate of model S was found to be 99.6%, and the number of parameters was reduced by nearly 1/2. Image occlusion and noise processing were conducted to test the robustness of model S. Results show that model S has a strong robustness under the conditions of image occlusion, salt and pepper noise.
Because a single feature cannot represent all of the information contained in an inscription image, a method for evaluating bronze inscription images using multi-measurement similarity is proposed in this study. This method is based on the global Hu moment as well as local term frequency-inverse document frequency (TF-IDF) and K-means speeded-up robust features (SURF), referred to as cluster weighted SURF (TF-KSURF). By extracting the Hu moment feature descriptor and the SURF matrix, the global and local features of the inscription image are obtained simultaneously. In addition, the K-means algorithm and weighting strategy are used to cluster and weight the local SURF to construct the TF-KSURF vector. The weights of the two measures are set to form a multi-measure similarity function, which is applied to image retrieval of bronze inscriptions. The experimental results show that compared with the single feature measure, the proposed multi-measure similarity method can be used to accurately analyze the overall characteristics of the inscriptions and to improve the retrieval performance.
Aiming at the problem that the classification accuracy of hyperspectral images is not ideal when the amount of training samples of three-dimensional convolutional network is limited, an efficient classification model based on multi-feature fusion and hybrid convolutional neural networks is proposed in this paper. First, after the dimensionality reduction processing is performed on hyperspectral images, the three-dimensional convolutional layer is used to extract deep hierarchical spatial-spectral joint features. Then, the residual connection is introduced to perform multi-feature fusion through feature map concatenation and pixel-wise addition to realize feature reuse and enhance information transmission. Finally, a two-dimensional convolutional layer is used to enhance the spatial information of the extracted features and realize image classification. The experimental results show that in the three publicly available hyperspectral data sets Indian Pines, Salinas and University of Pavia, 5%, 1% and 1% of the labeled samples are used as training data, respectively, the classification accuracy of the model is 97.09%, 99.30% and 97.60%, respectively, which can effectively improve the classification accuracy of hyperspectral images for under small sample condition.
Sudden mass gatherings are detrimental to people's safety. Therefore, it is paramount to conduct effective crowd counting in high-risk areas. Aiming at the problems of multicolumn neural network structure is bloated, redundant information and time consuming, we proposed a crowd counting model based on a single-column deep spatiotemporal convolutional neural network and modified it for video image counting. First, a fully convolutional network (FCN) is added to the feature fusion of dilated convolution and level jump connection to improve the ability of the network to extract features. Then, to reduce the influence of the angle distortion generated by the video surveillance on the counting results, a spatial transformation module is added to the long short-term memory (LSTM) network structure. Further, the residual connection method is used to connect and improve the FCN and associated timing LSTM network to improve the accuracy of the network counting results. Finally, tests are performed on UCSD, Mall, and self-built population data sets. Results show that the crowd counting accuracy and robustness of the model are better compared with other models.
Existing target detection algorithms have low accuracy in detecting smaller-sized dangerous goods in X-ray security inspection images. Therefore, a multi-scale feature fusion detection network called MFFNet (Multi-scale Feature Fusion Network) is proposed, which is based on the SSD detection model and uses a deeper feature extraction network, namely ResNet-101. The high-level semantic rich features of the network are merged with the low-level edge detailed features through the jump connection method, and contextual information is added for the detection of small-scale dangerous goods, which can effectively improve the identification and positioning accuracy of small scale targets. The new feature layer obtained by fusion and the SSD extended convolution layer are sent into detection together. Experimental results show that MFFNet can greatly improve the detection accuracy of dangerous goods in X-ray security inspection images, especially those of smaller sizes, while maintaining a relatively fast detection speed to meet the requirements of modern security inspection.
Aiming at the problems of color distortion and visual blur in underwater images, an underwater image restoration algorithm based on light attenuation prior and background light fusion is proposed. First, the background light 1 is calculated by the maximum intensity a priori, and the background light 2 is estimated by the image quadtree method. The two local background lights are fused according to the brightness and darkness of the underwater image illumination to determine the global background light. Secondly, the relative depth of the scene is estimated a priori according to the light attenuation, and then the transmittance of the three channels is calculated. Then the underwater optical imaging model is solved inverse to eliminate backscattering. Finally, the adaptive histogram equalization algorithm with limited contrast is combined to better correct the color distortion of the underwater image, and finally the restored underwater image is obtained. Conduct subjective and objective evaluation comparison experiments with four representative underwater image restoration methods. The experimental results show that the proposed algorithm can effectively remove the visual blur of underwater images, and the visual effect is closer to the images in natural scenes.
Aiming at the problem of high difficulty and low precision of two point cloud registration with low overlap rate, a point cloud registration method combining clustering region partitioning with convex optimization problem is proposed. First, the curvature feature of point cloud is used to establish multi-scale descriptor to ensure the integrity of point cloud data and minimize redundant data. Second, the angle difference of multi-scale descriptor is used to cluster and block the corresponding relationship to obtain the overlap area of the source point cloud and the target point cloud. Finally, the point clouds in the overlap area and their corresponding relations are substituted into the convex optimization problem to remove outliers and optimize the corresponding relations to achieve the coarse registration, and then the iterative closest point algorithm is used to refine. Experimental results show that the proposed algorithm can narrow the useful search range of point cloud registration, reduce the amount of registration computation, and provide more advantageous registration accuracy and time efficiency for point cloud data with low initial overlap.
Existing decoding algorithms encounter difficulties in recognizing quick response (QR) codes with complex three-dimensional (3D) distortions (e.g., cylindrical distortion), resulting in the inability to extract data. In this paper, we propose a low-cost and efficient restoration algorithm for 3D cylindrically distorted QR codes. The proposed algorithm is composed of three stages. First, it restores a cylindrically distorted QR code in 3D real-world coordinates by inverse perspective transformation; then the distorted QR code is flattened in 3D real-world coordinates. Finally, the restored QR code is obtained by perspective transformation with the same hyperparameters as those in the first stage. The experimental results demonstrate that the proposed algorithm can handle different cylindrically distorted QR codes and work with only a small number of hyperparameters based on the camera’s internal parameters.
A simulation method is used to optimize the residence time distribution and modification process. The beam shape of the ion beam is changed by adding an diaphragm at the light exit of the ion source. Ion beams with different apertures are simulated on MATLAB software and the ion beam is modified according to different stacking intervals. In the simulation process, we introduce a correction method to obtain the residence time distribution and residual distribution of the surface shape remaining after the removal of material. We analyze the removal rules to determine the best aperture size, stacking interval, and residencetime distribution. The initial peak and valley value of the fused silica plane is 1079.59 nm, the root mean square value is 304.95 nm, and the diameter is 120 mm. The shape is modified on the basis of simulation. We modify the surface shape on the basis of the simulations. After 13 h of modification, the peak-to-valley accuracy of the surface profile is improved to 95.62 nm, RMS value is improved to 8.99 nm, and RMS value of the convergence ratio of the surface profile is 33.92.
In this paper, aiming at the problem of limited image acquisition location and poor reconstruction of weak texture objects in small indoor scenes, a three-dimensional reconstruction algorithm that only needs a mobile phone to acquire images is proposed. First, an active selective image matching policy is employed to reduce the number of images of pairwise matching in the original structure from motion algorithm. Then, the scale-invariant feature transform (SIFT) algorithm is improved to the Harris-SIFT algorithm to enhance real-time performance of the algorithm. Next, the predicted depth is obtained from the full consolidation neural network and fused with a multi-view stereo match algorithm to obtain more dense clouds. Finally, the reconstruction of the object is completed with a Poisson surface reconstruction algorithm. The experiment results show that the algorithm can not only effectively restore the detailed features of the object under the indoor scenes, but also has a better reconstruction effect on the surface of the weak texture objects. Compared with the original reconstruction algorithm, the time used by the algorithm is reduced by 21.07%.
High accuracy results of semantic segmentation often rely on rich spatial semantic information and detailed information, but both incurring high computational costs. In order to solve this problem, we propose a real-time semantic segmentation network based on regional self-attention by observing the similarity of local pixels in the image. The network can calculate the regional correlation of feature information and channel attention information through a regional self-attention module and a local interactive channel attention module. Then, it obtains rich attention information with less calculation. The experimental results on the Cityscapes dataset show that the segmentation accuracy and speed of the network are higher than the existing real-time segmentation network.
Under normalized epidemic prevention and control, mask-wearing detection can promptly remind people to wear masks correctly, thus reducing the risk of cross-infection of people in public places. Aiming at the difficulty of detecting obscured and small targets in the mask-wearing detection task, a YOLO-Mask algorithm is proposed. The proposed algorithm is based on YOLOv3. It introduces an attention mechanism into the feature extraction network to enhance the model's ability to express salient features. Moreover, it uses feature pyramid and path aggregation strategies for feature fusion to enhance detailed feature information and utilize different levels of feature information. The loss function is optimized. The experimental results show that the average accuracy of the YOLO-Mask algorithm is 93.33% for mask-wearing detection targets in different scenarios, which is 7.62% higher than that of the existing YOLOv3 algorithm. The proposed algorithm has better detection results and robustness compared with other mainstream algorithms.
We proposed a deep learning approach for automatic segmentation of three-dimensional gliomas magnetic resonance images(MRI). First, we used a three-stage cascaded strategy to sequentially segment the subregions of gliomas. Second, to further improve the segmentation accuracy, we used intraslice and interslice convolutions, introduced additional multi-levels feature fusing, and implemented dilated convolution. Third, to produce a fine-grained output, conditional random fields as recurrent neural network were adopted as a part of network structure. Finally, we combined two types of loss functions in the training procedure to further improve the segmentation accuracy. We applied our method on the BraTS 2018 dataset and achieved a Dice score of 0.9093, 0.8254, and 0.7855 and the Hausdorff distance of 3.8188, 7.8487, and 4.3264 for the whole tumor, tumor core, and enhanced tumor, respectively. The proposed methods achieved better performance than most brain tumor segmentation methods.
To overcome the edge blurring and the difficulty in edge detection of noisy images, a method for edge detection of noisy images in nonsubsampled contourlet transform (NSCT) domain is proposed based on fractional differentiation. This method first decomposes the image by NSCT, and then extracts the contours of the low-frequency sub-bands. Second, for the high-frequency sub-bands in various directions with more edge details and noise, the proposed method uses the multi-scale product of the NSCT domain and the direction fractional differential matrix to perform threshold denoising and enhance information on high-frequency coefficients. Finally, the scale images of each frequency domain and direction in the NSCT domain are fused to obtain a complete edge image. Experiments are carried out on different types of original and noisy images, and the average continuous edge pixel ratio obtained by the proposed method is 0.931 and 0.861, respectively. Compared with Canny operator, fractional differential detection method, and existing multiscale domain edge detection methods, this method has better edge detection effect. With the increase of the image noise level, we can obtain a high average continuous edge pixel ratio, strong anti-noise, and accurate, complete and continuous edges by the proposed method.
To solve the problem that the detection accuracy of remote sensing image targets is affected by convolution neural network overfitting under the condition of small samples, a data augmentation method based on generative adversarial networks is proposed. The discrimination model is used to provide local and global decisions for the generation model to improve the quality of the image generated by the generative model. The new samples are obtained by fusing the generated target and the training set image, and the new samples do not need to be labeled manually. Experimental results show that: the accuracy of detection and recognition is improved after adding the generated data to the original data; this method can be superimposed with the data augmentation method based on image affine transformation to further improve the effect of data augmentation.
Due to the uneven distribution of wild mushrooms in China, the diversity of species, and the difficulty for the general population to distinguish whether wild mushrooms are edible, there occur positioning accidents from time to time and thus it is urgent to propose an efficient method to identify wild mushroom species. Here, a new type of wild mushroom specie image recognition model (Dis-Xception-CBAM) is proposed, which takes the Xception structure as a benchmark, combines the transfer learning method with network weights for feature learning, adds the attention mechanism to further extract the explicit features of wild mushrooms, and introduces the feature map distortion structure to increase the model's generalization performance. A dataset of 33 kinds of wild mushroom images is constructed based on the common wild mushrooms in China and the corresponding experiments are conducted. When the initial learning rate is 0.001 and the number of training iterations is 300, the Top 1 reaches 96.32% and the Top 5 reaches 99.61%. Compared with the traditional image recognition model, the proposed model obtains a better result, which provides a theoretical basis for wild mushroom recognition research.
The two-step phase-shifting method is an important method to balance high speed and high precision in fringe projection profilometry. However, the current solution algorithm has low accuracy or high algorithm complexity. This paper presents a two-step phase-shifting solution method based on variable grouping optimization. In this method, the original iterative variables are divided into linear group variables and nonlinear group variables. For the determined nonlinear group variables, the explicit optimal solution of linear group variables can be obtained by the least square method. By optimizing the parameters of the nonlinear group, the global optimal solution is obtained. The method in this paper is verified by the numerical simulation and experiment. The results show that the method in this paper effectively reduces the possibility of falling into the local optimum of the phase value obtained by the multivariate nonlinear optimization and reduces the complexity of the algorithm.
Mismatched points are inevitable when matching the feature points in target recognition and image registration. The proper elimination of mismatched points improves the accuracy of recognition and registration, therefore, has become a focus of this research field. The currently mature elimination algorithms, such as random sample consensus (RANSAC) and M-estimator sample consensus (MSAC), often eliminate some of the correctly matched points. To overcome this shortcoming, this study proposes a mismatched-point elimination algorithm with double constraints on length and included angle based on the Pearson correlation coefficient. First, the mismatched points with larger error are roughly eliminated, and the mismatched points with smaller error are then precisely eliminated by iteration. In comparative experiments on several images, the proposed algorithm retained most of the correctly matched points while eliminating all of the wrong matched points. This performance was not matched by the comparative algorithms RANSAC and MSAC. Therefore, the proposed algorithm greatly reduces the error elimination rate and can significantly improve the accuracy of image matching.
In this study, photometric stereo imaging is used to reconstruct the stereo morphology of signature handwriting. Based on gray data quantitative analysis of the sample image, two characteristic indicators of the regional gray difference D and the gray average change trend V' of adjacent regions gray levels are proposed to examine the correlation between three-dimensional (3D) morphological images of the signature handwriting and the signer’s writing characteristics. In the experiment, 1000 signatures from five volunteers are collected to form 2600 single-character sample sets, and 500 copied signatures are collected to form 1300 single-character sample sets. Based on the Lib-SVM classifier, the Canny operator is used to extract edge features, and image processing, such as dilation and corrosion, is performed. The method locates the feature region and uses the LBP(Local Binary Pattern) operator to extract the texture information of the feature region as a feature vector for classification. The experimental results show that a binary classification model of the feature area processed using image processing technology can effectively differentiate the 3D morphology of the real and copied signature handwriting. The proposed method has a higher accuracy rate than the unprocessed sample in the characteristic area, proving that the method is scientific and feasible. It can provide technical support for signature-handwriting examination.
Aiming at the poor detection effect of SSD and other algorithms on small ship targets in synthetic aperture radar (SAR) images and complex scenes, this paper proposes a method of ship detection based on a multiply connected feature pyramid network. First, according to the characteristics of small target ships in the image, a new feature extraction network I-VGGNet is constructed to solve the problem of the loss of feature information of small ships. Second, the multi-connection feature pyramid network module is added to strengthen the fusion of high-level semantic features of ships and low-level positioning features so as to improve the detection performance of the network for small and medium-sized ships. Finally, in order to solve the interference of complex scenes on ship target detection, this paper constructs a new loss function based on generalized intersection over union loss and focus loss to reduce the sensitivity of the network to the ship scale and accelerates the convergence of the model. The proposed method is tested in related experiments on the Chinese Academy of Sciences SAR image ship target data set. Experimental results show that the average accuracy reaches 94.79%, which is better than the existing mainstream detection algorithms. The frame rate reaches 22 frame/s, which meets the real-time detection requirements, the proposed method shows good adaptability to the detection of ship targets of different sizes in complex scenarios.
The standard spherical lens mounted in the Fizeau laser interferometer can usually be used only at a specific wavelength. This paper presents a method to change the working length of the standard spherical lens by adjusting the lens interval inside it, and two types of wavelength-variable standard spherical lenses are designed by using this method, in which the caliber is 19.05 mm and the aperture coefficients are 5.6 and 8, respectively. The reference wavefront quality of the standard spherical lens at each target wavelength meets the design requirements. The tolerance is analyzed to ensure that the standard spherical lens possesses practical machinability. The mechanical structure is designed according to the assembly and working principle of the wavelength-variable standard spherical lens and an experimental standard spherical lens with aperture coefficient of 8 is developed. The peak-valley(PV) value of the transmitted wavefront under a standard 632.8 nm laser interferometer is less than λ/10(λ, incident wavelength) and the actual processing error of the lens is within the tolerance range. The multi-wavelength laser interference device and the experimental standard spherical lens are used to measure the surface shape of the same spherical element. The measurement results under five wavelengths are basically the same. The experimental results show that the wavelength-variable standard spherical lens can be used for actual detection. The research and development of this kind of wavelength-variable standard spherical lens can save inspection costs, improve the utilization rate of standard lenses in laser interferometry, and it has high engineering application value.
Aiming at the problems of low accuracy of indoor positioning technology and computational complexity, an indoor fingerprint location algorithm based on optimized convolutional autoencoder-self organizing map (OCAE-SOM) is proposed. In the offline stage, first, we use the amplitude and phase-preprocessing matrix of a channel state information as the original input data and adjust it to the RGB format to train the convolutional autoencoder (CAE) algorithm so that it can deeply mine the fingerprint features of a reference point. The Adam algorithm is employed to optimize the parameters of the CAE algorithm, which not only reduces the data dimension but also improves training efficiency. Then, we use the OCAE-SOM algorithm for model training. It can shorten the time to train the model separately. Finally, we use the Adam algorithm to optimize the weight of the self-organizing map, which can be better retain the correlation between output features to avoid the local optimization of weight parameters. In the online stage, the adjusted test data are input into the OCAE-SOM algorithm, and the output location point is obtained after matching. The experimental results show that the OCAE-SOM algorithm is significantly better than existing algorithms in terms of positioning time and accuracy, and it has certain application values.
To accurately obtain the center point of interference fringes, a method based on interval curve fitting was established. According to the gray value distribution of the interference fringe pattern, we first obtain the R value graph of the interference fringe and perform Gaussian low-pass filtering; then, we remove various noises while retaining the original fringe information. Thereafter, we consider the filtered image as a list of pixel values in the normal direction to obtain a gray distribution curve. Finally, we intercept the image near the peak to perform segmental curve fitting in the increasing interval and the decreasing interval and obtain the intersection point of the two curve fitting functions, which is the center point of the interference fringe. Experimental results show satisfactory curve fitting effect. Compared with the Steger algorithm, the speed of the proposed method is increased nearly ten times. The proposed method can be used to effectively obtain the center point of interference fringes according to the gray distribution law of interference fringes with a simple operation, high precision, and anti-interference characteristics.
In view of some problems of the traditional rust removal process in bridge maintenance, the laser intelligent rust removal process and equipment are studied in this work. To realize intelligent identification of rust on surfaces of workpieces and rust removal, first, the Python and OpenCV visual library are used to identify the rust on the 16Mn surface. A series of image processing algorithms are used to recognize the rust area, and the position information, rust grade, and size information of the rust area are obtained. Then a 100 W laser rust removal system is used to remove the identified rust, and the derusted workpiece is recognized and detected again. After applying the machine vision-assisted laser rust removal system, the contents of C and O elements on the surface of 16Mn fall below 5%. The laser intelligent rust removal assisted by machine vision can quickly and efficiently identify the rust on the surface of the workpiece. The visual algorithm and process database are used to quickly match the corresponding processing parameters, so as to improve the processing efficiency and reduce the labor cost.
One of the common faults in grate system is side plate offset, and when the side plate offset occurs, it will cause serious accidents and economic losses. Aiming at the problems of time-consuming, laborious, and low intelligent in the side plate offset detection method based on manual observation and inspection, a side plate offset detection method based on line segment detector (LSD) algorithm is proposed. The whole detection scheme including hardware equipment construction and data processing method is designed. The image information of the side plate of the grate trolley is collected by camera. According to the actual running condition of the grate trolley, the offset detection rules of the side plate of the grate trolley are set. Through region of interest capture and region division of the collected video frame images, LSD algorithm is used to detect the straight-line segment information in image, and the straight-line segment information of the trolley’s side plate obtained from the detection is processed by straight-line fusion and breakpoint difference calculation. According to the judgment rules, the offset fault of the trolley’s side plate is detected online and the alarm is given automatically. By testing the video image of trolley side plate collected in sintering plant of Baotou Steel, the program error detection rate is 1%, and the average detection and judgment time is less than 0.1 s, which can effectively replace the manual observation detection method to detect the offset fault of trolley side plate, and provide technical support for the offset detection of chain grate trolley side plate.
To address the difficulty associated with identifying the edge area in aluminum plate defect eddy current inspection images, in which background noise is typically problematic, an image segmentation method for aluminum plate defect eddy current detection based on improved generative adversarial network is proposed. The proposed method is based on the generative adversarial network image segmentation model. The generator partly adopts the idea of the U-Net model. Prior to the fusion of high- and low-level features, an attention module is used to adjust the weight of both low- and high-level features. This weight adjustment improves the utilization of image feature information, enhances the target features, and suppresses background features. The discriminator network is used to distinguish the results generated by the network and actual manually labeled results. The proposed method uses Precision, Recall, and F1 as evaluation indicators. Compared with the traditional image segmentation methods, the proposed method achieves a better segmentation effect for aluminum plate defect eddy current inspection images.
Insulators are an essential part of overhead transmission lines in distribution networks. Accurate identification of insulator images by drone aerial photography is an important prerequisite for defect detection and fault diagnosis. Aiming at the problem of small insulator targets and complex backgrounds in images, an algorithm for insulators identification on overhead transmission lines in distribution networks based on multi-scale dense networks is proposed in this paper. First, use the K-means algorithm to analyze the target frame of the dataset to obtain a suitable anchor frame. Second, replace the residual module in the basic network with a dense connection module to enhance the multiplexing and fusion of network feature information. At the same time, add a spatial pyramid pooling module and optimize multi-scale feature fusion to predict insulators. Finally, replace the original loss function with a loss function that combines the cross-entropy function and the Focal loss function to construct an aerial inspection image data set and perform experiments. The experimental results showed that the algorithm accuracy is improved by about 12 percentage points and has a stronger robustness than the original algorithm, which meets the requirements of the grid inspection for insulator identification.
Correlation filters have demonsrtated excellent performance in real-time and accurate tracking of video signals in recent years, which have attracted the attention of many scholars. However, when the appearance of complex scenes changes greatly, the tracking effect of the filter is easy to be unstable, and the ability to estimate scale changes needs improvement. The model update process easily introduces untrustworthy samples, which is not conducive to track the target accurately. Therefore, a combination of a color histogram model and correlation filtering-discrimination model is used to track objects accurately, and then scale samples are extracted from the predicted position to train the kernel scale correlator. Considering the problem of interference information getting introduced in the model update process, the model is updated when the response confidence attains a certain threshold. The proposed algorithm in the tracking data set (OTB-2015) performed well with a success rate and a precision score of 0.694 and 0.794, respectively.
The radar target detector is an important part of the radar receiver. The purpose of target detection is to maximize the detection efficiency of the target under the constraint of constant false alarm probability. Aiming at the traditional cell averaging-constant false alarm rate (CA-CFAR) in the vehicle-mounted millimeter-wave radar target detection process tends to be obscured under the condition of adjacent multiple targets, we improves a new one-dimensional CA-CFAR detection algorithm. First, the left and right reference units are divided equally, and the average value of each sub-reference unit after the division is obtained. Then, the average value of the sub-reference unit is compared with the average value of the reference unit. Finally, the average value greater than the reference unit is processed to obtain a new detection threshold. Simulation and experimental results show that the improved CA-CFAR algorithm has better detection performance in linear frequency modulation continuous wave radar multi-target detection compared to traditional CA-CFAR, which demonstrates the effectiveness of the proposed algorithm.
In this work, we designed a visual size-measurement system for micro-miniature optical components. We proposed a dark-field scattering illumination scheme combining dome light and coaxial light to highlight the surface features of the element and used the brightness difference between the subregion and the full image for illumination compensation to eliminate edge ghosting. For the excessively high and uneven local edge brightness, we used a region segmentation-based Otsu algorithm to extract edges. In addition, we used the least square method for the component edge-fitting to calculate the size. Experiment results show that the region segmentation-based Otsu algorithm has an average error of 1.5 and 4.1 μm for measuring length and width, respectively, which reduced by more than 10 μm compared to the Canny edge detection algorithm-based measurement results. The measurement uncertainties of the region segmentation-based Otsu algorithm are 0.5 and 1.1 μm for length and width, respectively. The system is less affected by light, and the accuracy and robustness are higher than the algorithm before improvement.
Vehicle driving environment perception is a key and difficult problem of automatic driving field, among which lane detection is the foundation of vehicle driving environment perception. In view of the difficulty in distinguishing different lane instances, the high time complexity of existing distinguishing algorithms, and the need to manually adjust hyperparameters in different driving scenes, a three-branch lane instance segmentation algorithm is proposed in this paper, and the segmentation results are adaptively clustered to fit lanes of different instances. Considering the unbalanced characteristic of the image data obtained by the vehicle-mounted camera, a convolutional neural network is trained on the basis of the Tversky Loss function of the three-section field of view method. In view of the large curvature radius of the lane, the weight of the higher-order term is used as the regular term of a least square method to fit lanes. The test results on the TuSimple dataset show that the accuracy of the algorithm in identifying the lane of the considered example is 96.23%. Compared with LaneNet, the time complexity of the algorithm is reduced by 23.67%. Additionally, it has a good detection effect for various vehicle driving scenes.
In the scenes of dynamic background or measurement noise, the movement background or noise is easily regarded as a part of the foreground. Simultaneously, it is separated by the background modeling algorithm via decomposition of low-rank and sparsity based on the nuclear norm. This algorithm has poor performance in modeling capability of complex backgrounds. To tackle this issue, a video foreground-background separation algorithm via decomposition of weighted Schatten-p norm and structured sparsity is proposed. First, the background matrix is constrained by the weighted Schatten-p norm, which has a better performance for restraining measurement noise than the nuclear norm. Second, the foreground matrix is constrained by the structured sparsity, which uses a structured prior knowledge that the foreground changes continuously in space, and a video background separation model is established. Finally, a decomposition algorithm of the weighted Schatten-p norm and structured sparsity is designed using an augmented Lagrangian method and a generalized soft-thresholding algorithm. The numerical experiment results show that, compared with five other main algorithms, the proposed algorithm can separate objectives more accurately in the scenes of dynamic background.
Existing deep learning methods only use deep layer features for recognizing cancer and ignore the spatial information stored in the output of the surface network, yielding unsatisfactory recognition accuracy. To further promote clinical applications and aid doctors improve the consistency and efficiency of breast cancer pathological diagnosis, an improved Inception-v3 image classification optimization algorithm is proposed. This algorithm optimizes the network model through model improvement and transfer learning. Breast cancer was classified based on the pathological images of a large open database. The improved model of the proposed algorithm is superior to the traditional deep learning method, with an accuracy rate of 96%, which effectively improves the performance of the deep learning model for breast cancer diagnosis. Moreover, the proposed algorithm lays a theoretical and practical foundation for further clinical applications.
In view of the difficulty in detecting the high reflective surface defects in the bottom of a large metal barrel, an endoscopic illumination scheme is proposed. Comprehensively considering the structural and surface characteristics of the metal barrel, a simulation study on the non-forward illumination scheme of the barrel bottom is conducted based on the bidirectional scattering distribution function (BSDF). The results show that the illuminance at the bottom of the barrel presents a good uniformity under theoretical conditions. The corresponding experimental verification results indicate that the actual illumination conditions are basically the same as the simulation results. The proposed scheme can obtain better image quality than the general illumination scheme.
One method used for modeling a miniaturized nonlinear all-optical diffraction deep neural network based on 10.6 μm wavelength is proposed. First, a carbon dioxide (CO2) laser light source with a wavelength of 10.6 μm is used, and the corresponding physical size of the neural network is 1 mm×1 mm. Second, the model framework of the nonlinear all-optical diffraction deep neural network based on 10.6 μm wavelength is constructed according to the characteristics of relevant optical physical parameters. Finally, the grid search method is used to determine the hyper-parameters of the optimal neural network model, and the cross entropy loss function and the Adam optimizer are selected to optimize the neural network. The proposed method is tested on the MNIST handwritten digital dataset and the Fashion-MNIST dataset, respectively, and the classification results reach 0.9630 and 0.8743, respectively. The proposed method provides theoretical reference for the preparation of miniaturized all-optical diffraction gratings.
Point cloud registration and georeferencing are essential steps in point cloud data processing. Georeferencing is the basis of point cloud data integration with other geospatial data. In the georeferencing of static ground laser scanning point clouds, there are few studies on the georeferencing of point clouds based on the least fixed control primitives. Therefore, we propose a fixed control primitives method consisting of 1 point primitive, 1 line primitive and 1 surface primitive, which can be used to calculate the point cloud georeferencing parameters. The experiment results show that the method has high georeferencing accuracy, can quickly and directly calculate geography parameters, and provide initial values for fine georeferencing.
Chlorophyll-a concentration is an essential indicator for estimating phytoplankton biomass, and continuous wavelet transforms is an essential multi-scale spectral analysis method. In this study, taking western Guangdong and Pearl River Estuary as the study area, ten mother wavelet functions are selected based on the water surface hyperspectral and measured chlorophyll-a concentration data to perform continuous wavelet transformation on hyperspectral reflectance data. The partial least square regression (PLSR) method was used to develop the chlorophyll-a concentration inversion model. Besides, the influence of different wavelet transformation coefficients on the modeling results was analyzed and compared. The results showed that the correlation between wavelet coefficients after various wavelet transformations and measured chlorophyll-a concentration is higher than that between the original spectrum and measured chlorophyll-a concentration. Besides, the results showed that the inversion accuracy varies greatly with models based on different wavelet coefficients. The partial least squares regression(PLSR) model based on sym6 wavelet coefficients has the best accuracy (determination coefficient R2 is 0.732, root-mean-square error is 6.457 μg/L, relative percent deviation is 2.600). Compared with the traditional inversion method based on spectral characteristics, it performs better and provides a wavelet-based optimization selection in the construction of the chlorophyll-a concentration model of case Ⅱ water in the future.
Aiming at the problem of coverage path planning of bridge laser scanning inspection, a general model of large-scale bridge inspection coverage path planning based on point cloud slices is proposed in this work, which provides a new idea for bridge coverage path planning by multi-UAV systems. First, we add supplementary viewpoints to the point cloud slice modeling method to solve the problem of incomplete coverage of the point cloud slice model, then we convert the convex hull set and supplementary viewpoints into three-dimensional arc sets, and we use arcs as the minimum optimization object to solve the problem of huge search space for large-scale building traversal. Second, we combine the SC-CBBA (split and combine-consensus based bundle algorithm) and CRSOM (clustering characteristic of cluster growing ring self-organizing map) algorithm to realize the assignment of multi-UAV tasks and check the arc sequence planning of inspection path. Finally, simulations verify that this method can effectively solve the problem of bridge coverage path planning.
In recent years, the demand for three-dimensional (3D) information of the objective world and scene has increased sharply and drives the rapid development of 3D measurement techniques based on structured light illumination. The 3D imaging technique based on fringe projection and phase-shift fringe analysis has high accuracy and robustness, standing out among many techniques, and is widely used in industrial inspection, digitalization of antique, biomedicine detection, and so on. In the application scenarios with timeliness requirements such as human-computer interaction, virtual reality, online detection, and remote surgery, realizing real-time 3D measurement is of great significance and obvious value. In this paper, the basic theory of 3D imaging technique based on phase-shift fringe analysis was introduced. Several optimization directions for real-time 3D imaging were discussed, and different methods in various optimization directions were reviewed. Finally, the challenges and potential research directions of real-time 3D imaging technique based on phase-shift fringe analysis were summarized.
Through the early screening of diseases, the development of targeted treatment programs of precision medicine has been essential to medical development. Medical imaging detection is an important foundation for precision medicine. There is no obvious characterization in the early stage of the disease, thus, the conventional detection method has certain limitations, but the body will show abnormal temperature distribution, and infrared thermography can detect the change of temperature sensitively. So, its application in early disease detection has attracted significant attention. In this study, the advantages and disadvantages of X-ray examination, ultrasound, magnetic resonance imaging, and other medical imaging detection methods, especially the mechanism of infrared thermography applied to disease detection, are introduced. Then, it systematically expounds on the domestic and foreign current situation of infrared thermography and advanced image recognition technology in early disease detection and recognition. It analyzes the advantages and disadvantages of infrared thermography in early disease detection, with the advantages of lossless, fast, and high accuracy and disadvantages such as the need for a large amount of data and poor performance of image processing algorithm. It suggested that the combination of infrared thermography and deep learning will be the main research direction in the future.
Persistent luminescence nanoparticles (PLNPs) can realize nondestructive imaging, detection, diagnosis and treatment without background interference due to their unique and outstanding luminescence phenomena. In addition, the emission wavelength of PLNPs is determined by their luminescence center. Thus, Cr 3+-doped PLNPs (Cr-PLNPs) have attracted much attention in the biomedical field due to their near-infrared (NIR) light emission, good tissue penetrability, and ultra-strong persistent luminescence (PL) excited by NIR light. In this paper, we discussed the application of Cr-PLNPs to biological detection, imaging, and therapy, analyzed their problems, and pointed out their future research directions.
Accurate monitoring of the chlorophyll content of tea leaves is of great significance to the nutritional status and growth of tea trees. Thus, a method for rapid and nondestructive detection of chlorophyll content of leaves is proposed on the basis chlorophyll fluorescence spectroscopy technology. The chlorophyll fluorescence collection device is used to collect the spectrum of tea leaves and measure the relative chlorophyll content. The Savitzky-Golay (S-G) smoothing method is used to preprocess the spectrum, which can eliminate a large number of noise signals. The proposed method is compared with the traditional method. Experimental results show that the proposed method can effectively eliminate irrelevant variables, and the optimization of the model can achieve better results. The partial least square model established after simplifying the variables has a correlation coefficient of 0.96 on the prediction set, and a root mean square error of 0.87. The correlation coefficient on the model set is 0.96, and the root mean square error is 0.95. The fluorescence spectroscopy and chemometric methods can provide a quick and easy analysis method for the quantitative analysis of tea leaf chlorophyll content.
Identification of aging grain seeds has attracted significant attention in agricultural production and food safety. Therefore, this study combines infrared spectroscopy and multivariate statistical analysis to investigate artificially aging wheat seeds. The experimental results show that the original spectra of wheat seeds with different aging degrees are similar. In the second derivative infrared spectrum, the peak intensity and shape of the wheat seeds showed differences in the range of 1800--800 cm -1. In the range of 1800--800 cm -1, the number and intensity of automatic peaks of the two-dimensional correlation infrared spectrum of wheat seeds will change significantly with the increase of aging time. The study results show that infrared spectroscopy with principal component analysis and hierarchical cluster analysis can quickly and conveniently distinguish artificially aging wheat seeds. It is expected to develop into a new method for identifying aging seeds.
Using differential Raman spectroscopy and decision tree model, a classification model for identifying common shoe sole materials is established. This is a new method for identifying shoe sole materials. After preprocessing the pre-spectrum, the samples are classified according to the main components of the shoe sole, and then principal component and hierarchical clustering analyses are used to verify the classification results. Based on the classification results, a classification tree model is established, and finally 51 samples are recognized and classified with overall classification accuracy of 98.0% and the accuracy is 84.3% after cross-validation. These results show that using differential Raman spectroscopy and decision tree model can realize a more accurate identification and classification of shoe sole sample spectrum, providing a certain reference for the differentiation and identification of other physical evidence.