







Please enter the answer below before you can view the full text.
8+3=

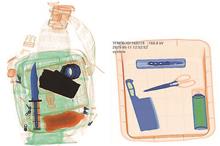
In the automatic X-ray imaging systems used to identify knives in security check, using the original single shot multibox detector (SSD) algorithm, the shallow feature maps are poorly represented, features of small targets gradually disappear during the training stage, leading to low detection accuracy and poor real-time performance, and the small targets such as the controlled knives in security check are missing and checked out by mistake. To solve this problem, the original SSD was improved in two ways. On the one hand, the SSD-Resnet34 network model was constructed by replacing the basic network VGG16 in the SSD using a ResNet34 network with stronger anti-degradation performance, and the last three layers of the basic network were convolved and a new low-level feature map was created by lightweight network fusion. Part of the extended layer of the network was deconvolved to form a new high-level feature map. On the other hand, jumping connection was adopted to achieve multi-scale feature fusion between the high-level feature map and the low-level feature map. Analysis of test data shows that the improved algorithm demonstrates improved detection speed and detection accuracy of small targets, such as the X-ray image controlled knives. And the algorithm demonstrates improved robustness and high real-time performance. Using the VOC2007+2012 general dataset, the detection accuracy of the improved SSD algorithm is 1.7% higher than that of the SSD algorithm, reaching 80.5%.
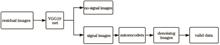
Satellite laser ranging is one of the important technical means to obtain the high-precision distance of space targets. Before the measured data is used in scientific research, a series of pre-treatments of original data are required. Geneal methods for signal extraction include Graz automatic recognition, Poisson filtering, and manual recognition. In recent years, some scholars have adopted deep learning in the field of astronomy to solve some problems and achieved relatively satisfactory results. In this paper, a new algorithm for extracting target signals using deep learning is proposed, and the recognition results of the measured data show that this algorithm has certain reliability, versatility and feasibility. This research has a positive effect on the intelligent development of satellite laser ranging systems.
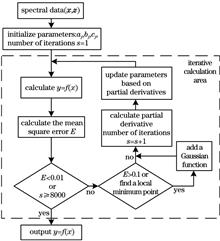
In order to fit the spectral overlapping peaks and terahertz time-domain curves, a Gaussian fitting algorithm that dynamically increases the Gaussian function is designed in this paper. First, use the first derivative of the denoising spectral data to roughly search the position of each Gaussian peak, and then initialize the multi-Gaussian function according to the position of the Gaussian peak. Then, the mean square error between the spectral data and the multi-Gaussian function is used as the loss function, and the gradient descent method is used to find the multi-Gaussian function when the loss function is the smallest. Finally, for the spectral overlapping peaks without obvious peaks and the terahertz time-domain curves with negative values, the dynamic multi-Gaussian function model is used to analyze overlapping Gaussian peaks or fitting curves. Calculation results show that the algorithm can dynamically add multi-Gaussian functions according to the requirements of fitting accuracy, and automatically search for the position of Gaussian peaks, and the effect of fitting spectral overlapping peaks and terahertz time-domain curves is better.
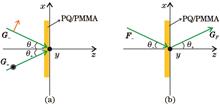
In this paper, we investigate the orthogonal reconstruction in orthogonal linear polarization holography. Orthogonal reproduction means that the polarization of the diffracted light is orthogonal to the polarization of the recorded signal light. Based on the newly developed polarization holography theory with the tensor method, we analyzed the prerequisite for orthogonal reconstruction and verified it experimentally by constructing an experimental platform. Through quantitative analysis and multiple experiments, the power of the diffracted light was related to the interference angle between the recorded signal light and reference light during the recording process when the diffracted light was subjected to orthogonal reconstruction. The experimental results are in good agreement with the results obtained via theoretical analysis. Thus, our knowledge related to polarization holography may be improved through orthogonal reconstruction.
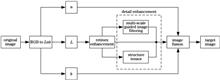
To solve the problems of low brightness and unclear details of images collected by visible light imaging equipment under low-illumination conditions, a low-illumination image processing algorithm based on brightness channel detail enhancement is proposed. First, the image is converted from RGB to the Lab color model, the brightness channel in the Lab model is corrected to an illumination component by an exponential derivative function, and then the Retinex enhancement is performed to obtain a preliminary enhanced image. Then, the structure tensor and multi-scale guided image filtering are used to extract the details of the preliminary enhanced image, and the details extracted by the two methods are fused. Finally, the detail image and the preliminary enhanced image are merged to get the target image. Experimental results subjectively obtain the enhanced image with appropriate brightness and clear details, objectively have good and stable performance in brightness distortion, information entropy, and energy gradient, which shows that the proposed algorithm can effectively improve the brightness and detail information of the image, and maintain the natural color and lighting effect.
Aiming at the problem that image edges and contours cannot be accurately reconstructed, a multi-scale block-based compressed sensing algorithm based on gray-level co-occurrence matrix is proposed in this paper. The algorithm uses three-level discrete wavelet transform to decompose the image into high-frequency part and low-frequency part. The entropy of the gray-level co-occurrence matrix is used to analyze the texture complexity of the high-frequency part of the image block, and the image block texture is subdivided and the sampling rate is adaptively allocated. The smooth projection Landweber algorithm is utilized to reconstruct the image and eliminate the blocking effect caused by the block. Compression and reconstruction simulation of various images are conducted. Experimental results show that when there is no observation noise and the sampling rate is 0.1, the peak signal-to-noise ratio (PSNR) obtained by the algorithm on Mandrill images is 25.37 dB, which is 2.51 dB higher than the existing non-uniform block algorithm. Under different noise levels, the PSNR of the algorithm is only 0.41-2.05 dB lower than that of no noise. For the image with high texture complexity, the reconstruction effect of the algorithm is obviously better than that of non-uniform block algorithm, and has good robustness to noise.
Decision information for process monitoring and management can be obtained by analyzing and predicting the event log of the business process. The existing research methods are mostly targeted at specific single-task prediction, and the portability between different task prediction methods is not high. Through multitask prediction, information can be shared among multiple tasks, improving the single-task prediction accuracy. However, the multitask prediction effect of existing research on repetitive activities must be improved. Based on the aforementioned problems, we propose a depth neural network model combining the attention mechanism and bidirectional long-short term memory, achieving multitask prediction for repetitive activities and time associated with the business process. The proposed prediction model can share the learned feature representation of different tasks and achieve multitask parallel training. Comparison is performed by applying different methods on datasets. The obtained results demonstrate that the proposed method improves the prediction efficiency and accuracy, especially in case of repetitive activities.
To address the problems of poor visualization of restored images and the insufficient image details obtained using dark channel prior algorithms in the processing of large areas of sky, we propose an adaptive image defogging algorithm based on multi-scale Retinex and dark channels. A Canny operator is used to detect the edge of the brightness component and a multi-scale Retinex algorithm is used to eliminate the brightness component. To optimize the prior theory of the dark channel and obtain a rough estimate of the transmittance, we use a cross-bilateral filter. We use the quadtree subspace search method to select the global atmospheric light value. To eliminate the overall darkness of the restored image and enable the display of detailed image information, a 2D gamma function is used to correct the brightness value and restore the defogged image. The experimental results show that the proposed algorithm can effectively restore detailed information in a foggy image to obtain images that feature thorough dehazing, overall smoothness, better color brightness, and a clear and natural appearance.
The traditional ray-casting algorithm demonstrates a range of drawbacks, such as large consumption of computing resources and a low draw speed, when drawing vast smoke data in a three-dimensional (3D) scene. Thus, a visualization method of indoor smoke based on the improved ray-casting algorithm is proposed. First, the 3D data field is divided into uniform blocks of data according to the uniform size, neutral positions of the incident and emission points are calculated when the ray travels through the blocks, and the sampling frequency is adjusted with the help of the distance ratio between the point of sight and midpoint to spot the resampling point. For sampling points at different levels, different interpolation strategies are followed by classifying the resampling points in the rays. Finally, a picture-synthesis algorithm is adopted to complete the mapping of the sampling sight data in each ray, realizing the rendering effect of indoor smoke. Experimental results show that the method is workable and effective. Compared with the existing ray-casting algorithm, the improved one considerably reduces the computing effort of resampling and linear interpolation in the rendering process on the premise of guaranteeing the authenticity and stability of the images. Moreover, the frame rate can stably maintain 75 frame·s -1, which can satisfy the real-time rendering requirements of smoke in different indoor scenes.
Aiming at the problems of incomplete foreground extraction, low accuracy, and high false detection rate of the existing video image flame detection algorithms, a video flame detection algorithm based on improved Gaussian mixture model (GMM) and multi-feature fusion was proposed. Firstly, for background modeling, an improved GMM method with adaptive Gaussian distribution number and learning rate was proposed to improve the foreground extraction effect and algorithm real-time performance. Then the flame color characteristics were used to filter out the suspected flame regions, and local binary pattern texture and edge similarity features were used for flame detection. Based on support vector machine, a flame fusion feature classifier was designed and compared. Experimental results on the public datasets show that the algorithm proposed in this paper effectively improved the background modeling effect. The flame detection accuracy reached 92.26%, and the false detection rate was as low as 2.43%.
This study aimed to address issues of difficult diagnosis of benign and malignant masses in breast mammogram. For medical imaging, this study proposed a classification method of benign and malignant masses in breast mammogram based on attention mechanism and transfer learning. First, a new network model was built by combining convolutional block attention module (CBAM) and the residual network ResNet50 to improve the ability of the network to extract the features of the mass lesions and enhance specific semantic feature representation. Then, a new transfer learning method was proposed; instead of traditional method using the ImageNet as the transfer learning source domain, the patch data were used as the transfer learning source domain to complete the domain adaptive learning from local mass patch images to global breast mammogram, which can improve the ability of the network to capture pathological features. The experimental results show that the proposed method achieves an area under the receiver operating characteristics curve (AUC) value of 0.8607 in the local breast mass patch dataset and an AUC value of 0.8081 in the global breast mammogram dataset. The results confirm the effectiveness of the proposed classification method.
Aiming at the problem that periodic texture background affects the fabric defect detection, a fabric defect detection method based on coarseness measurement and color distance is proposed. Firstly, the detected image is transformed from RGB color space to HSV color space, and homomorphic filtering is carried out for three channels respectively to improve the contrast between defect and background. Fabric images are classified by coarseness measurement, the same categories of fabric images are divided into the same size and non-overlapping image blocks, and the color distances of each image block and its eight-neighbor image blocks are estimated respectively, so as the implementation of the rough localization of the defects can be done. Finally, the saliency and binary processing are performed on the rough location image blocks, which can effectively reduce the influence of the periodic texture background on the detection results. The experimental results show that compared with four methods proposed recently, the proposed method shows a better detection effect on the periodic texture fabric image, and the detection accuracy is higher.
In order to solve the problem of model drift in complex scenes such as occlusion and scale variation, this paper proposes a long-term target tracking algorithm based on TLD framework, which integrates GMS detection and confidence discrimination. First, in tracking module, the fast discriminating scale space correlation filter (fDSST) is used as the tracker, and the position filter and scale filter are used to distinguish the position and scale of the target in the previous frame. According to the independence of the tracking module and the detection module in the TLD algorithm, the results of the tracking module are input into the detection module, and the average peak-to-correlation energy (APCE) is used to determine the template update to judge the confidence. In the detection module, GMS grid motion statistics is used as the detector to make the ORB algorithm with fast rotation invariance feature to match the target in the previous frame, and then the grid motion statistics is used to filter the matching results to achieve the rough positioning of the target position, and the target detection area is reduced dynamically according to the prediction position. Finally, the cascaded classifier is used to locate the target accurately. The results show that the tracking method proposed in this paper can greatly improve the tracking speed of the algorithm while effectively preventing model drift, and has better accuracy and robustness to challenging environments such as target occlusion, scale variation and rotation.
The scale-invariant feature transform (SIFT) algorithm is widely used in image matching. To reduce its computational complexity, a fast SIFT image matching algorithm based on mask search is proposed. First, the texture information of the image is analyzed, and the corner response function (CRF) of the Harris algorithm is used to divide the image. The regions with higher texture complexity are used as a Mask to generate a Mask pyramid ,therefore reducing the search space of the feature points; then, a seven-zone circular descriptor is established in the polar coordinate system and its dimension is reduced. Finally, the same kind matching is carried out according to the extreme value category of feature points to reduce the matching complexity. Experimental results show that the method using Mask feature searching can improve the overall speed of the algorithm at the cost of low matching quality, and it can further improve the speed of the algorithm combined with the improved descriptor and extreme value classification algorithm. Therefore, the proposed algorithm has the potential value in the application of high matching efficiency requirements.
In order to solve the problem that traditional photogrammetric coded point location depends on multiple relationship criteria, complex judgment, and unstable recognition, a localization method is proposed, which uses the target detection network based on improved YOLO v3 to segment the coding points, and uses distance sorting to identify the center mark points. First, the feature extraction network is improved according to the characteristics of the coded mark points, and the coded points are quickly identified from the complex background. Then, image processing is carried out in the prediction frame to calculate the distance from the centroid of the contour to the center, and then the circular mark points of the positioning center are sorted. Finally, the scale coding point data set is constructed for network training and testing. The experimental results show that the recognition accuracy of the target detection network for coded points reaches 94.91%, which is less affected by the environment and noise, and the distance criterion has high accuracy. The location method has the advantages of good adaptability and high robustness.
In this paper, a method of generating corresponding images based on scene description text is studied, and a generative adversarial network model combined with scene description is proposed to solve the object overlapping and missing problems in the generated images. Initially, a mask generation network is used to preprocess the dataset to provide objects in the dataset with segmentation mask vectors. These vectors are used as constraints to train a layout prediction network by text description to obtain the specific location and size of each object in the scene layout. Then, the results are sent to the cascaded refinement network model to complete image generation. Finally, the scene layout and images are introduced to a layout discriminator to bridge the gap between them for obtaining a more realistic scene layout. The experimental results demonstrate that the proposed model can generate more natural images that better match the text description, effectively improving the authenticity and diversity of generated images.
It is difficult to fully recover the image details using the existing image super-resolution reconstruction methods. Furthermore, the reconstructed images lack a hierarchy. To address these problems, an image super-resolution reconstruction method based on self-attention deep networks is proposed herein. This method, which is based on deep neural networks, reconstructs a high-resolution image using the features extracted from a corresponding low-resolution image. It nonlinearly maps the features of a low-resolution image to those of a high-resolution image. In the process of nonlinear mapping, the self-attention mechanism is utilized to obtain the dependence among all the pixels in the images, and the global features of the images are used to reconstruct the corresponding high-resolution image, which promotes image hierarchy. During the deep neural network training, a loss function comprising a pixel-wise loss and a perceptual loss is utilized to improve the image-detail reconstruction ability of the neural network. Experiments on three open datasets show that the proposed method outperforms the existing methods in terms of image-detail reconstruction. Furthermore, the visual impression of the reconstructed image is better than that of the images reconstructed using other existing methods.
In order to accurately evaluate the types and number of yarn defects, an algorithm of yarn defects detection based on spatial fuzzy C-means (FCM) clustering is proposed in this paper. First, the spatial FCM clustering algorithm is used to extract the yarn strips. Then, morphological opening operation is performed on the yarn strips to obtain accurate yarn strips, and the number of pixels between the upper and lower edges of the yarn is used to calculate the measured diameter and average diameter of the yarn. Finally, the type and number of yarn defects are determined according to the standard of yarn defects. In order to verify the validity and accuracy of the algorithm, a variety of pure cotton yarns with different linear densities are tested, and experimental results are compared with the capacitive yarn defects classifier. The results show that the algorithm is in good agreement with the result of capacitance detection, and it is cheap and not easy to be affected by environmental temperature, humidity and other factors.
Dataset is an important part of semantic segmentation technology based on deep learning. In order to apply semantic segmentation technology to the field battlefield environment, it is very important to construct a dataset that conforms to the actual combat scene. In this work, aiming at the operational support requirements for the detection and identification of camouflage targets, the characteristics of the field battlefield environment and battlefield reconnaissance images are analyzed, the construction process and method of the specific scene dataset are designed, and the semantic segmentation dataset CSS with refined semantic annotation is constructed. The effectiveness of the dataset on semantic segmentation tasks is verified by experiments.
Aiming at the problem that the small number of samples in the dataset will affect the effect of deep learning detection, a strip defect classification method based on improved generative adversarial networks and MobileNetV3 is proposed in this paper. First, a generative adversarial network is introduced, and the generator and discriminator are improved to solve the problem of category confusion and realize the expansion of the strip defect data set. Then, the lightweight image classification network MobileNetV3 is improved. Finally, it is trained on the expanded data set to realize the classification of strip defects. Experimental results show that the improved generative adversarial network can generate more real strip steel defect images and solve the problem of insufficient samples in deep learning. And the parameter amount of the improved MobileNetV3 is about 1/14 of that before improvement, and the accuracy is 94.67%, which is 2.62 percentage points higher than that before improvement. It can be used for accurate and real-time classification of strip steel defects in industrial field.
In order to solve the problem of lack of detailed information and low definition of low illuminance images, the fusion algorithm of non-undersampled shear wave transform (NSST) and Retinex theory is used to process low illuminance images in the color space of HSV (Hue, Saturation, Value). First, the V component of the HSV space is decomposed to obtain multiple high pass subbands and a low pass subband. The high pass subbands with the improved adaptive threshold algorithm based on Bayesian shrinkage denoising, the low pass subbands with the improved adaptive local color mapping algorithm improve the contrast. Then, the NSST inverse transformation is applied to the two subbands to obtain the new V components and white balance treatment is performed on them. Finally, the processed image is reversed to the RGB (Red, Green, Blue) space to get the result image. Experimental results show that the proposed algorithm can improve the quality of low illuminance images, and improve the definition and contrast.
The digital image correlation (DIC) method is used to measure the surface deformation of the object, and the true change of the measured object is studied through the deformation of the speckle field. The evaluation method of speckle quality is researched in order to determine the influence of speckle used on measurement accuracy before measurement. According to the specific requirements of the DIC method for speckle images, a speckle quality evaluation method based on gray level co-occurrence matrix (GLCM) is proposed. Perform sub-pixel rigid body translation simulation simulation on the actual speckle image, compare the energy, entropy, contrast, and correlation indicators in GLCM with the measurement results of the DIC method for comparison and analysis, and perform comparison experiments with the average gray second derivative and Shannon entropy. By changing the overall brightness level and brightness distribution of the speckle image, the influence of different lighting conditions on the accuracy of the experimental results is explored. The experimental results show that GLCM is effective in evaluating the quality of speckle images.
It is difficult to quickly and accurately identify wheelset tread defects using traditional image processing algorithms. We propose an algorithm to accomplish this using a dual deep neural network. The dual network is divided into a tread-extraction network and a defect-identification network. Based on the characteristics of the treads as a big target, we analyze and test the SSD network, and apply this network to extract the tread area from wheelset images. To improve the efficiency of tread defect recognition, after the tread image is extracted, we optimize the YOLOv3 network structure to obtain M-YOLOv3 for the characteristics of medium and small tread defect targets. The experimental results show that when extracting tread areas, the average precision (AP) of the SSD algorithm is the highest (99.8%). When identifying tread defects, the AP of the M-YOLOv3 network reaches 89.9%. Compared with the original YOLOv3, the image computing time of the M-YOLOv3 network is reduced by 7.1%, with the AP showing only a 0.6% loss. The results demonstrate the proposed algorithm’s high detection accuracy.
In this study, a color image encryption algorithm is proposed based on the symmetry of Fourier transform and random multiresolution singular value decomposition (R-MRSVD). First, the average value of normalized plaintext images is considered to be the initial value of logistic-exponent-sine mapping. Thus, a random matrix and position index are generated. Then, a two-dimensional discrete Fourier transform is applied to each color channel. Because of the conjugate symmetry property of Fourier transforms, only half of the Fourier transform spectrum coefficients are preserved. Further, a real matrix is constructed by extracting the real and imaginary parts. Finally, R-MRSVD is performed, and the ciphertext image is obtained using Josephus scrambling operation. The pixel characteristic of the plaintext image is considered to be the initial value of the chaotic sequence; thus, the high sensitivity and security of the algorithm can be ensured. The real-valued ciphertext image is convenient for storage and transmission. The quality of the decrypted image, statistical characteristic, key sensitivity, chosen-plaintext attack, and robustness of the algorithms are verified. The simulation results demonstrate the feasibility and security of the proposed color image encryption algorithm.
In view of the problems of deep network depth and lack of context information in medical image segmentation, which leads to the reduction of segmentation accuracy, an improved U-Net-based magnetic resonance imaging (MRI) brain tumor image segmentation algorithm is proposed in this paper. The algorithm forms a deep supervised network model by nesting residual block and dense skip connections. Change the skip connection in U-Net to multiple types of dense skip connection to reduce the semantic gap between the encoding path and the decoding path feature map; add a residual block to solve the degradation problem caused by too deep network to prevent the network gradient from disappearing. Experimental results show that the Dice coefficients of the algorithm for segmenting the whole tumor, tumor core, and enhanced tumor are 0.88, 0.84, and 0.80, respectively, which meets the needs of clinical applications.
Smoke image detection is an important means for early detection of fires. Aiming at the problems of low robustness and low detection rate of traditional LBP (Local Binary Patterns) feature and Gabor feature fusion algorithms, a TDFF (Triple Multi Feature Local Binary Patterns and Derivative Gabor Feature Fusion) smoke detection algorithm is proposed. First, the T-MFLBP(Triple Multi Feature Local Binary Patterns) algorithm is used to encode and calculate the different grayscale differences between pixels and the pixels at special positions in the non-uniform mode, which can capture clearer texture features. Second, the first-order partial derivative of the Gaussian kernel function is used to extract Gabor features, so as to optimize the performance of extracting image edge gray information. Finally, the fusion features can be trained to improve the accuracy of the final classification. The experimental results show that the TDFF algorithm has strong robustness, and the detection rate of smoke images is also significantly better than the unimproved traditional algorithm.
The traditional image rain removal algorithms do not consider multiscale rain streaks and often result in loss of detailed information after the image is derained. To solve these problems, an image rain removal algorithm based on a multiflow expansion residual dense network is proposed in this study. In this algorithm, a guided filter is used for decomposing an image into a base layer and a detail layer. The mapping range can be considerably reduced by training the network with the residuals present between the rain and rainless image detail layers. Three dilated convolutions with different expansion factors are used to perform multiscale feature extraction on the detail layer to obtain more context information and extract complex and multidirectional rainline features. Further, the expanded residual dense block, which is the parameter layer of the network, is applied to enhance the propagation of features and expand the acceptance domain. The experiments conducted on synthetic and real pictures show that the proposed algorithm can effectively remove rain streaks with different densities and restore the detailed information present in an image. When compared with other algorithms, the proposed algorithm is better in terms of subjective effects and objective indicators.
In order to improve the accuracy of pedestrian attribute recognition, a multi-scale attention network for pedestrian attribute recognition algorithm is proposed in this paper. In order to improve the ability of feature expression and attribute recognition of the algorithm, first, the top-down feature pyramid and attention module are added to the residual network ResNet50. A top-down feature pyramid is constructed from the visual features extracted from the bottom-up. Then, the features of different scales in the feature pyramid are fused to give different weights to the channel attention of each layer of features. Finally, the model loss function is improved to weaken the impact of data imbalance on the attribute recognition rate. Experimental results on the RAP and PA-100K data sets show that compared with existing algorithms, the algorithm has better performance in terms of average accuracy, accuracy, and F1 for pedestrian attribute recognition.
Through arranging coded markers on the blade surface of a wind turbine, and based on binocular stereo imaging principle and image feature matching and tracking method, the spatial motion information of coded markers can be obtained dynamically and in real time. Aiming at the problem of noise pollution affecting modal identification, a singular value decomposition (SVD) and Cadzow algorithm was used to construct a Hankel matrix without noise pollution, which effectively reduces false modals caused by noise. In order to solve the problem that false modes are easy to appear in the process of modal order determination, an improved eigensystem realization algorithm (ERA) is proposed. Compared with the traditional ERA, the proposed method improves the accuracy of natural frequency identification by 3.6% and obtains a clearer stabilization diagram.
Due to the limitation of traditional methods for the depth detection of material surface defects, a laser pulsed thermography technique in transmission mode is proposed in this paper. A laser source is selected as the excitation source to heat the defect surface of the measured material. The excitation point is selected directly below the surface defect. The laser power is selected as 50 W, and the heating time is selected as 1 s. During the heating process, the temperature field on the back of the material produces temperature difference due to the influence of heat flow in the conduction process of surface defects. Infrared thermal imaging camera records the temperature field changes on the back of the material, and point A without defect is used as a reference point, and point B at a defect is used as an experimental point. By analyzing the temperature changes at points A and B, the depth of surface defect is extracted. Experimental verification shows that this method can detect the depth of defects on the material surface under certain conditions. When the temperature of point A is constant, the best fitting relationship between the temperature of point B and the depth of the defect becomes an exponential relationship. The temperature of point B on the back also decreases. The research results lay a foundation for the subsequent accurate quantification of defect depth.
When robots conduct simultaneous localization and mapping (SLAM) tasks in large-scale scenes, there is serious mismatching or missed matching in loop-closure detection. Focused on this problem, this study proposes a new closed-loop detection algorithm based on a residual network (ResNet) to extract features of image sequences. The global features of an input image are extracted using a pretrained ResNet. The features of the frame image and previous image sequenced with a certain length are stitched by the down sampling method, and the results are taken as the features of the current frame image to ensure the richness and accuracy of the image features. Then, a double-layered query method is designed to obtain the most similar image frame, and the consistency of the most similar image is checked to ensure the accuracy of the loop-closure. The proposed algorithm can achieve an 83% recall rate under 100% accuracy and an 85% recall rate under 99% accuracy in the loop-closure detection mainstream public datasets of New College and City Centre, which is significantly improved compared with the traditional bag of words method and VGG16 method.
Recently, visual odometry has been widely used in robotics and autonomous driving. Traditional methods for addressing visual odometry are based on complex processes such as feature extraction, feature matching, and camera calibration. Moreover, each module must be integrated to achieve improved results, and the algorithm is high complexity. The interference of environmental noise and the accuracy of the sensor affect the feature extraction accuracy of the traditional algorithm, thereby affecting the estimation accuracy of the visual odometer. In this context, a visual mileage calculation method based on deep learning and fusion attention mechanism is proposed. The proposed method can eliminate the complicated operation process of traditional algorithms. Experimental results show that the proposed algorithm can estimate the camera odometer in real time achieves improved accuracy and stability and reduced network complexity.
Aiming at the problems that moving object detection in video sequence is easily interfered by environmental noise and the object contour is difficult to extract, this paper proposes a multi-moving object detection algorithm based on the improved model of edge multi-channel gradient. First, the Canny operator is used to obtain the edge information of the object in the video sequence, and a multi-channel gradient model of time, space and color is established on the object edge according to the constant characteristics of human visual color; Then the model is used to obtain the motion state description information of the object edge pixel and achieve the separation of the background edge and the edge of the moving object; Finally, the discontinuity edge pixels are associated with the motion state of their neighboring points to connect the discontinuity edges of the object, which achieve the complete extraction of the contour of the moving object; The connected contour is morphologically processed to segment the object. Experimental results show that, compared with similar algorithms, the algorithm has superior real-time performance, accuracy, and robustness in moving object detection.
This study proposes an efficient algorithm for an implicit reconstruction of point cloud data. First, the algorithm quickly interpolates the point cloud data with low resolution and low precision on the basis of the traditional radial basis function implicit surface reconstruction algorithm and then interpolates the point cloud data with high resolution and low precision using trilinear interpolation. Finally, the proposed algorithm determines the area near the zero level set of the point cloud data according to the Euclidean distance, and only for the points within the area, the point cloud date are denoised by statistical filtering algorithm. Compared with the traditional method, this algorithm can not only ensure the accuracy of surface reconstruction but also reduce the calculation time. This algorithm achieves the similar accuracy to that of the traditional method and a reduction in the operation time by 63.21% in the surface reconstruction experiment of the head point cloud data.
A siamese network visual tracking algorithm based on fusion multitask differentiated homogeneous models is proposed to improve the accuracy of the algorithm. First, the siamese network visual tracking and target segmentation models are fused in the decision-making layer. Then, they are combined with multiscale search area, contextual features, and multilearning rate model updating strategy to track. Different algorithms are evaluated using standard datasets, namely, VOT, OTB, LaSOT, and UAV123. Experimental results show that the proposed algorithm can stably track the object under the interference of occlusion, fast motion, and illumination change, among others.
To address the problem of ship target detection in optical remote sensing images under complex sea surface landform and cloud background conditions, an unsupervised ship target detection algorithm that combines the visual salient features of spatial and frequency domains is proposed. First, based on the RGB color space and the ITTI model of the images, image features are constructed using a combination of image brightness feature map, color feature map, and one-step brightness feature. Moreover, the regional difference in the image is calculated using the covariance matrix of the image region and the entire image. Further, the spatial-domain salient feature map is constructed using the generalized eigenvalue of the covariance matrix, and the frequency-domain salient feature map of the phase spectrum of quaternion Fourier transform (PQFT) model is added. Finally, the spatial- and frequency-domain salient features are combined using cellular automata. The experimental results show that the proposed algorithm is superior to other visual salient algorithms commonly used for ship target detection.
Aiming at the problems of few labeled samples and low quality of feature fusion in visible and near infrared dual-band scene classification, a dual-band scene classification method based on convolutional neural network (CNN) feature extraction and naive Bayes decision fusion is proposed in this paper. First, the CNN model based on pre training is used as the feature extractor of dual-band image to avoid the over fitting problem caused by few labeled samples. Second, the calculation speed of support vector machine and the classification performance of each band are improved by the dimensionality reduction of principal component analysis and feature normalization method. Finally, using the dual band posterior probability as the naive Bayes prior probability, a decision fusion model is constructed to achieve scene fusion classification. Experimental results on the public dataset show that compared with single-band classification and dual-band feature cascade fusion classification methods, the recognition rate of the method is significantly improved, reaching 94.3%; it is 6.4 percentage points higher than the best method based on traditional features. The recognition rate is similar to the CNN-based method, and the execution is simple and efficient.
In the traditional three-dimensional (3D) point cloud registration process, there are some problems such as high registration error, large amount of calculation and time-consuming. Aiming at these problems, a registration and optimization algorithm of key points in 3D point cloud is proposed in this paper. In the key point selection stage, the edge point detection algorithm is proposed to eliminate the edge points, improve the comprehensiveness and repeatability of the feature description of key points, and reduce the registration error of 3D point cloud. In the 3D point cloud registration stage, K-dimensional tree (KD-tree) accelerated nearest neighbor algorithm and iterative nearest point algorithm are used to eliminate key misregistration points in the coarse registration results, reduce the registration errors, and improve the speed and accuracy of 3D point cloud registration. Experimental results show that the algorithm can obtain good registration results under different cloud data. Compared with the traditional 3D point cloud registration algorithm, the average registration rate and the average registration accuracy of the algorithm are improved by 68.725% and 49.65%, respectively.
To improve the feature extraction capability and recognition capability of models for vehicle images in crossing environments, a vehicle classification method based on an improved residual network is proposed. First, the residual network is used as the basic model, the position of the activation function on the residual block is improved, and the normal convolution in the residual block is replaced with a group convolution. An attention mechanism is then added in the residual block. Finally, the focal loss function replaces the cross-entropy loss function. In the experiment, the Stanford Cars public dataset is used for pretraining and a self-built crossing vehicle dataset is used for migration learning. The results show that the classification accuracy of the proposed model is better than several classical deep learning models in both datasets.
The introduction of auxiliary task information is helpful for the stereo matching model to understand the related knowledge, but the complexity of model training increases. In order to solve the problem of dependence on extra label data during model training, we proposed an algorithm based on multi-task learning for stereo matching by using the autocorrelation of binocular images. This algorithm introduces the edge and feature consistency information in the multi-level progressive refinement process and updates the disparity map in a cyclic and iterative manner. According to the local smoothness of disparity and the consistency of left and right features of binocular images, a loss function is constructed to guide the model to learn the edge and feature consistency information without relying on additional label data. A spatial pyramid pooling with scale attention is proposed to enable the model to determine the importance of different scale features based on the local image features in different areas. The experimental results show that the introduction of auxiliary tasks not only improves the accuracy of disparity maps, but also provides a significant basis for the trusted regions of disparity maps. It can also be used to determine the single-view visible areas in unsupervised learning. The proposed algorithm has certain competitiveness in terms of accuracy and operating efficiency on the KITTI2015 test dataset.
A three-dimensional face acquisition system consisting of two infrared cameras and a compact speckle structure light projector is designed. The speckle projection system can be configured to project speckles according to the acquisition accuracy and efficiency. The speckle template is fixed on a gear that is perpendicular to the optical axis of the projector, and a gear mechanism is used to drive the speckle template for rotation. The speckle is illuminated by an LED with a wavelength of 735 nm to form a temporally and spatially uncorrelated speckle-encoded structured light pattern in the measurement space, and a spatial-temporal correlation stereo matching algorithm is used to achieve three-dimensional face reconstruction. Through theoretical analysis and experiments, the influence of the rotation angle of the speckle template on the measurement accuracy is verified, and the best rotation angle is determined. The German ATOS high-precision industrial three-dimensional scanner is used to obtain the three-dimensional data of the face mask and use it as the true value, while testing the three-dimensional acquisition effect of the real face. The experimental results show that when the number of projected speckles is 5, the average error of three-dimensional reconstruction is 0.063 mm, and the standard deviation of error is 0.111 mm.
In order to realize accurate neural network modeling for the dual notch ultra-wideband(UWB)antenna, a modeling method using the improved fruit fly algorithm (FOA) to optimize the generalized regression neural network (GRNN) is proposed. This method achieves the improvement of the fruit fly algorithm by expanding the search range of fruit flies, introducing adjustment items into the taste judgment formula, and using the improved fruit fly algorithm to optimize the smoothing factor of GRNN. In this way, the fruit fly algorithm can be prevented from falling into local optimum and the model prediction accuracy can be improved. This method is used in the establishment of the dual notch UWB antenna model, and the antenna S11 parameters and voltage standing wave ratio VVSWR parameters are predicted. Experimental results show that, compared with the FOA-GRNN modeling method and the GRNN modeling method, the maximum relative error of the S11 parameter is reduced by 91.08% and 99.14%, respectively, and the maximum relative error of the VVSWR parameter is reduced by 98.36% and 99.18%, respectively. The accuracy of UWB antenna modeling is improved, and the method feasibility is verified.
Aiming at the problem of insufficient segmentation and over-segmentation of 3D lidar in multi-type scene, a lidar ground segmentation method based on the combined features of point cloud clusters is proposed. First, the three-dimensional point cloud is projected into a fan-shaped grid to cluster the connected domains, and the grids with small gradients are clustered into one category. Then, according to the characteristics of the pavement point cloud conforming to the geometric characteristics of the plane and the straight line, the eigenvalue of each cluster is calculated to select the candidate clusters of the pavement grid cluster, and then the gradient in the radial direction is checked to eliminate the misjudged grid. Finally, the cubic B-spline curve is used for smooth fitting to realize the division of ground points and non-ground points. The proposed method is verified in different road conditions. The experimental results show that the accuracy of the proposed method on roads with multiple obstacles is 97.50%, and the calculation time is 27 ms, indicating that the proposed method has higher ground extraction accuracy and stronger road adaptability.
Satellite dynamic imaging mode can realize satellite imaging in a large-angle fast maneuvering process, meeting the diversified, customized and refined requirements of remote sensing observation. In this work, the basic principle of ground experimental system for dynamic imaging is analyzed, and a set of ground experimental verification system for dynamic imaging mode is built in the laboratory. The system uses a high-precision, high-stability dynamic air flotation target and a camera integration time adjustment method based on an external trigger signal. The relationship between the image quality and light intensity, the relationship between the image quality and the integral series of the camera detector and the maneuvering velocity of the satellite are studied. A dynamic imaging experiment with a custom motion curve is carried out. The results show that in the linear region of the camera detector, the range of the image dynamic modulation transfer function (MTF) value obtained with different maneuvering angular velocities and detector integration series is 0.0918-0.1054, which meets the requirements of engineering applications (near 0.1), and the MTF value has nothing to do with maneuvering angular velocity and detector series. In the dynamic imaging experiment, the system runs stably, and the dynamic MTF value is between 0.1015±0.0098.
Since the urban extraction based on the visible light red band and the urban index method based on the visible light green band are easily confused with the water body and bare land, we propose a method to consider the yellow band of the new extraction index (NBAEI) in urban areas. The function of the extraction index is to use the positive and negative characteristics of the reflection difference between the yellow and red wavelengths in an urban area, distinguish the urban area from the water body, and widen the difference between the bare land and the urban area while extracting the urban area. Baoji city, Rizhao city, and Baoding city are used as study areas, and three types of indicators are analyzed: overall accuracy, misclassification accuracy, and omission accuracy. Experimental results show that the overall classification accuracy of the NBAEI method is higher than the other two methods. The accuracy of misclassification and omission is lower than the other two methods, indicating that the proposed method is very accurate, effective, and suitable for extraction. The urban area is extracted from the GF-6 satellite.
Multispectral imaging (MSI) combines spectroscopy and imaging technology and can acquire the spectral feature and spatial information of the detected target simultaneously. Due to the non-invasive imaging manner, this technology has many important applications in the biomedical field. The basic principle and technical development of MSI are introduced, and its applications are briefly reviewed from three aspects: pathological research, surgical guidance, and biological recognition.
At present, the commonly used auto focusing methods for digital microscopes are divided into active auto focusing and passive auto focusing. Active auto focusing relies on a specific sensor or a distance measuring device, which automatically emits light and receives reflected light to determine the distance from the object to the focusing device and achieve focusing. Passive auto focusing can determine the focus direction and focus position by analyzing the image information of each position, therefore realizing focusing. Passive auto focusing is the most commonly used auto focusing method for digital microscopes due to its low structure requirements and low cost. This paper mainly introduces the auto focusing algorithm for digital microscopes, briefly describes the principle and development direction of active and passive auto focusing methods, focuses on the depth from focus method of passive auto focusing methods, and analyzes two key technologies of the depth from focus method, that is, the sharpness evaluation function and its focus search algorithm.
The smoke detection technology plays an important role in preventing early fire spread. An accurate and fast smoke detection algorithm has very important practical application value. In recent years, with the rapid development of machine vision and image processing technology, smoke detection algorithms for video-oriented images have attracted extensive attention due to their non-contact and strong robustness. The smoke detection algorithm based on video images can effectively overcome the deficiency of traditional smoke detectors working close to fire sources. However, the smoke detection algorithm based on video images still faces great challenges due to the complexity of scenes and the uncertainty of environmental factors. First, the basic process of the smoke detection technology is briefly introduced, including pretreatment, feature extraction, and classification recognition. Second, the preprocessing method based on color and motion segmentation is introduced, and the visual characteristics and movement characteristics of smoke are further analyzed and the related smoke extraction algorithms are introduced. Third, some of the current commonly used smoke detection classifiers and the deep learning network models are discussed and summarized. Finally, the deficiencies of the smoke detection algorithm are mainly introduced and the future of the smoke detection algorithm is prospected.
The hyperspectral image contains rich spectral and spatial features, which are essential for the classification of surface materials. However, the spatial resolution of hyperspectral images is relatively low, resulting in a large number of mixed pixels in the image, which severely restricts the accuracy of substance classification. Affected by factors such as observation noise, target area size, and endmember variability, hyperspectral image classification still faces many challenges. With the continuous progress of artificial intelligence and information processing technology, hyperspectral image classification has become a hot issue in the field of remote sensing. First, the literature on hyperspectral image classification based on feature fusion is systematically reviewed, and several classification strategies are analyzed and compared. Then, the development status of hyperspectral image classification and the corresponding problems are introduced. Finally, some suggestions can improve the classification performance are proposed, which provide guidance and assistance for the technical research of the subject.
In recent years, synthetic aperture radar imaging technology (SAR) has played an important role in the real-time monitoring and control of the ocean due to its all-time and all-weather target sensing capabilities. In particular, the detection of ship targets in high-resolution SAR images has become current one of the research hotspots. First, the process of ship target detection based on deep learning in SAR images is analyzed, and the key steps such as the construction of sample training datasets are summarized, the extraction of target features and the design of target frame selection. Then, the influence of each part of the detection process on the detection accuracy and speed of the ship target in the SAR image is compared and analyzed. Finally, according to the current research status, the problems of deep learning algorithms in the application of ship detection are deeply analyzed, and the further research direction of ship target detection based on deep learning in SAR images is discussed.
Radix Salviae miltiorrhizae powder contains dozens of chemical constituents and is a typical multicomponent substance that is difficult to analyze quantitatively using traditional two-dimensional fluorescence spectroscopy. In this study, three-dimensional synchronous fluorescence combined with parallel factor algorithm, the split half method, and sum of squared error analysis were used to study the fluorescence characteristics of multicomponent Radix Salviae miltiorrhizae powder. The parallel factor model of a Radix Salviae miltiorrhizae powder solution was identified as four components. The corresponding component fluorescence characteristics were as follows. The first component synchronous fluorescence peak in this region was λEx = 470--480 nm, λEm = 520--530 nm, and the second component synchronous fluorescence peak in this region was λEx = 400--410 nm, λEm = 490--500 nm. The third component synchronous fluorescence peak in this region was λEx = 370--380 nm, λEm = 460--470 nm, and the fourth component synchronous fluorescence peak in this region was λEx = 560--570 nm, λEm = 620--630 nm. The fluorescence characteristic of the second component may be the fluorescence of salvianolic acid B. Experimental results demonstrate that the three-dimensional synchronous fluorescence method combined with the parallel factor algorithm has a distinct advantage for fluorescence spectroscopic analysis, especially for a complex multicomponent substance coupled with a more interfering substance. This study can provide a reference for the analysis of multicomponent of Chinese patent medicine.