








Please enter the answer below before you can view the full text.
7-5=

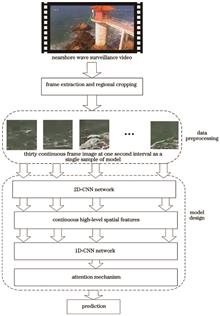
The detection of nearshore wave period is crucial for fine nearshore wave forecast. Thus, we propose a novel method to realize automatic detection of nearshore wave period by learning spatiotemporal features from nearshore wave surveillance videos. The method takes continuous ocean wave video frames as inputs. First, a two-dimensional convolutional neural network (2D-CNN) is used to extract spatial features of the video frame images, and the extracted spatial features are spliced into sequences in the time dimension. Then a one-dimensional convolutional neural network (1D-CNN) is used to extract temporal features. The composite convolutional neural network (CNN-2D1D) can realize the effective fusion of wave space-time information. Finally, the attention mechanism is used to adjust the weight of the fusion features and linearly maps the fusion features to wave period. The method in this paper is compared with the detection method only extracting spatial features based on VGG16 network and the detection method for spatiotemporal feature fusion based on the ConvLSTM and three-dimensional convolutional (C3D) network. The results of experiments show that C3D and CNN-2D1D achieve the best detection results, with an average absolute error of 0.47 s and 0.48 s, respectively, but CNN-2D1D is more stable than C3D, with a lower root-mean-square error (0.66) than C3D (0.81). And CNN-2D1D requires fewer training parameters. These results show that the proposed method is more effective in wave period detection.
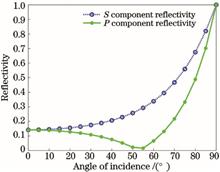
The sun glint on the water surface leads to flares in the optical images and loss of ship target detail information. This paper presents a method of suppressing sun glint on water surface by combining polarization filtering and polynomial fitting. In an imaging optical path, a polarizer is used to filter the glint based on the polarization characteristics of sun glint reflected from the water surface, and the glint areas in the polarization filtering images are estimated through polynomial fitting estimation. The water surface glint polarization imaging experimental device lint is constructed, and the polarization filtered image of the water surface glint is acquired. Polynomial column direction curve, row direction curve, surface, and line-by-line polynomial curve fitting methods based on the least square method are used to process the polarization filtered image. The experimental results show that using a polarization filter in conjunction with a line-by-line polynomial fitting method can effectively remove the sun glint while also making the processed image brightness more natural, not including saturated pixels and highlighting the details of the ship targets.
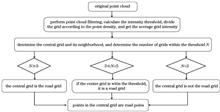
In road network extraction using airborne LiDAR point clouds, the road intensity inconsistency issue results in more points similar to road intensity when using intensity to extract roads, and some real road points are also filtered out. In this paper, we propose a grid segmentation method for extracting road point clouds based on local intensity. The method first uses skewness balance to obtain the road-intensity threshold of the filtered ground points, divides the ground points into a grid, and calculates the grid’s average intensity value. The number of grids for intensity values of the central grid and its neighboring grids within the road-intensity threshold is used to calculate the road point cloud. Experiments conducted with actual data in a complex environment show that the method can effectively reduce the abnormal points around the road while obtaining a more complete road, providing reference for future road network extraction. Data1 in the extracted initial road has a completeness rate of 84.1%, and data2 has a completeness rate of 67.1%, which has obvious benefits compared with the traditional method.
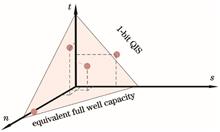
The data redundancy and dynamic range (DR) of quanta image sensor (QIS) are different under different oversampling bit-depth, and the requirements for readout circuit are also different. The reading noise introduced in the imaging process of QIS is studied, and the mathematical model of QIS imaging is optimized. Under the constraints of DR and offset tolerance, the optimal bit-depth of sub-pixel oversampling is obtained. The simulation results show that when the imaging bit-depth of the QIS is 12 bit and the equivalent full well capacity is 4095 electron, the optimal bit-depth of sub-pixel oversampling is 3. In order to ensure that the interval bit error rate is less than one thousandth, the readout circuit offset should be less than 0.22 electron. According to the sampling strategy, a flash low noise readout circuit based on multiplexing structure is designed. Compared with the traditional flash analog-to-digital converter (ADC), the number of ADC comparators is reduced by 4, and the power consumption is reduced by 17.5% when the sampling frequency is 10 MSa/s; when the sampling frequency is 1 MSa/s, the power consumption of ADC is 116 nW and the offset of ADC is 0.196 electron.
The larger the magnification of the microscope, the smaller the field of view. It is usually necessary to obtain a slice image with a large field of vision and high resolution through image stitching. Microscopic images are characterized by rich features, a large amount of information, and contain several similar regions, resulting in high time consumption and low registration accuracy. This study proposes a mosaic algorithm for microscopic images, which can quickly perform registration and fusion. In this study, template matching is used for initial motion estimates and the improved optical flow approach is employed for further matching. After collecting the matching point pairs, the mismatched points are removed using similarity and position restrictions, which increases registration accuracy. Experimental results show that the proposed method can effectively improve registration accuracy while maintaining real-time performance.
With the development of 5G and the emergence of multiple display terminals, image retargeting algorithms have received extensive attention. Most existing algorithms do not consider the aesthetic distribution of the image during retargeting, thus affecting the human visual aesthetic perception. In view of this situation, we propose an image aesthetic evaluation network based on multi-level attention fusion. The aesthetic information is obtained by extracting different fine-grained features and adaptively fusing them according to the attention mechanism. Then, the learned aesthetic information is combined with the saliency map, gradient map, and linear feature map of the image as the importance map to guide the multi-operation image retargeting algorithm. Experimental results show that the generated importance maps can well protect aesthetic information, and the obtained retargeting images has a better visual perception than the state-of-the-art methods.
Aiming at the problems of high dimensionality, weak stability, and poor registration quality of the features to be matched caused by the difference in sensor physical characteristics in heterogeneous image registration, this paper proposes a scale-invariant feature transform (SIFT)-based heterogeneous image registration method. This method combines the phase consistency and improved SIFT algorithm to obtain stable features. Next, it uses the nearest neighbor distance ratio method for initial matching. Then, we propose a joint error and Euclidean distance (JEED) method for rematching. The mode-seeking scale-invariant feature transform (MS-SIFT) method is employed to optimize the matching point pairs to improve the image registration quality. Experimental results show that, compared with the existing methods, the method proposed in this paper can extract reliable and stable features, obtain higher registration quality, and improve the real-time performance of the registration algorithm.
Motion blur is one of the key factors that affect the image quality obtained by liquid crystal display (LCD) systems. The slow response of display systems, the hold type display characteristic, the smooth eye tracking, and the visual integral effect lead to the perceptual blur of dynamic images. In order to study the method for improving the dynamic image quality of LCD, the image motion compensation preprocessing model and LCD dynamic image perception effect simulation model are established based on the theory of smooth eye tracking. At the same time, different adaptive motion compensation preprocessing methods are proposed for binary eight-bit display systems and binary ten-bit display systems. Through visual perception experiments, the research carries out subjective evaluation and statistical analysis on the effect of dynamic image motion compensation. The results show that the compensation method for eight-bit display systems can significantly improve the perception effect of dynamic images, and the improvement rate is 11.11%; while the compensation method for ten-bit display systems can achieve the perception effect close to the original still images, and the improvement rate is 112.75%. The research results can provide a theoretical reference for improving the dynamic image quality of LCD systems.
Focus evaluation is a numerical analysis method that searches and obtains the optimal image point position based on the defocus sequence images. Its resolution directly determines the reconstruction accuracy of the three-dimensional focus shape restoration technology. This paper proposes a high-resolution focus evaluation method that combines the focus evaluation results of the two methods based on the spatial Laplacian operator and frequency domain discrete cosine transform. First, the discrete cosine transform operator was used to perform focus evaluation on the images. Moreover, the result of the symmetric transformation of the Laplacian operator focus evaluation value was used as the weighting factor. The weighting factor was then used to correct the discrete cosine transform evaluation value to increase the response to the image focus feature and suppress the response to the image defocus feature. By analyzing the defocus optical system, the defocus sequence images were generated by method of calculating the defocus point spread function, and the effectiveness of this method was validated by simulation. Finally, an experimental platform for various defocusing scenes was constructed using various imaging lenses and targets. The proposed focus method and the five traditional typical methods were used to compare and analyze the focus of the acquired defocus sequence images. The results show that the proposed focus evaluation method can achieve excellent evaluation results in both small and large defocus images, and the peak sensitivity and steepness are significantly improved. The proposed method has better resolution and response sensitivity of focus evaluation and can effectively improve the accuracy of three-dimensional focus profile restoration.
An image segmentation algorithm based on selective enhancement is proposed to improve the occlusion recognition accuracy of shadows and leaves for photovoltaic (PV) arrays. The proposed algorithm enhances module images in the HSV color space to acquire “moss images”, to realize discoloration of shade and improve the contrast between shaded and unshaded parts. Then, the “moss images” are segmented to acquire the shaded outlines. Experimental results demonstrate that the position and areas of shadows and attached shelters (leaves, etc.) are more accurate after being processed by the proposed algorithm, which gets convenient conditions for the removal of shades and provides a basis for accurate modeling of PV arrays under partial shadow conditions.
In order to solve the problem of quality prediction deviation of multiply-distorted images, a method for no-reference stereoscopic image quality assessment is proposed according to the process of visual information processed by neurons in human primary visual cortex (V1) in the research of visual physiology and psychology. Firstly, Gabor filtering is performed on the distorted stereoscopic image pairs to construct a simulated stimulus model of the V1 layer based on the binocular neuron response. Second, with the discrete cosine transformation (DCT) and the mean subtracted contrast normalization (MSCN), the natural scene statistics features of those distorted stereoscopic image pairs in DCT domain and spatial domain are extracted, respectively. Finally, the support vector regression (SVR) is adopted to build the objective evaluation model for predicting stereoscopic image quality via establishing the mapping relationship between the extracted features and the subjective scores. The proposed model is verified and compared based on the public databases, and the results show that the proposed method can uniformly predict the perceptual quality of singly-distorted and multiply-distorted stereoscopic images with better performance than that of other existing evaluation methods.
When an inspection robot is applied in the outdoor substation, there exists a problem of low accuracy of pointer meter recognition in complex environment. This paper proposes a pointer meter recognition method based on gray-level dynamic adjustment and Blackhat-Otsu algorithm. Aiming at the foggy environment, the Retinex dehazing algorithm based on gray level dynamic adjustment is proposed to process foggy images with different concentrations and the image contrast and clarity are improved. The information entropy of the obtained image is increased by 1.1 dB--2 dB compared with that of other dehazing methods, but the mean square error (MSE) is reduced by 700--800. The fast guided filter layer is introduced in the ResNet network deraining model to remove the rain pattern on the image, and the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are both improved. In order to improve the accuracy of pointer reading, the Blackhat-Otsu pointer separation method is proposed to eliminate the interference of pointer shadow and dial scale. The experimental results show that the proposed method has good robustness to the rain-fog environment in the substation, and improves the accuracies of instrumental detection and reading recognition.
Dunhuang mural images have complex line texture structure and missing contour edges,There are structure propagation errors and block effects when using Criminisi algorithm to inpainting. Therefore, a mural image inpainting algorithm based on edge missing structure reconstruction and improved priority is proposed in this paper. First, the missing edge contour of the damaged mural is reconstructed by adaptive Bézier curve fitting method to enhance the structure of the mural and guide the image restoration. Then, the prior information of local features such as gradient and curvature is introduced to improve the priority function, which makes the calculation of priority more reasonable and avoids the problem of wrong filling caused by the priority frequently tends to 0. Finally, the sequential similarity detection algorithm based on dynamic threshold is used for searching matching blocks, which improves the efficiency of mural repair, and the mural image inpainting is completed iteratively. The experimental results of digital inpainting of real Dunhuang murals show that the algorithm can solve the problems of structure propagation error and block effect of Criminisi algorithm, and the subjective and objective evaluation results of inpainting murals is better than other comparative algorithms.
We propose a real-time detection binary sub network based on two-dimensional (2D) to three-dimensional (3D) skeleton, which can realize 3D estimation of key points of 2D skeleton and human 3D motion recognition based on 2D and 3D skeleton feature fusion. In the detection process, OpenPose framework is used to obtain the 2D key point coordinates of human skeleton in video in real time. In the process of 2D to 3D skeleton estimation, a siamese network with difficult input samples and feedback function is designed. In the process of 3D motion recognition, a two branch siamese network of 2D and 3D skeleton features is designed to complete the task of 3D pose recognition. The 3D skeleton estimation network is trained on the Human3.6M data set, and the skeleton action recognition network is trained on the NTU RGB+D 60 multi view enhancement data set based on Euler transform. Finally, the accuracy of cross subjects and accuracy of cross views are 88.2% and 95.6%. Experimental results show that the method has high prediction accuracy for 3D skeleton and real-time feedback ability, and can be applied to action recognition in real-time monitoring.
Aiming at the problems of single image feature extraction scale and insufficient utilization of middle level features in the existing image super-resolution reconstruction technology based on depth convolution neural network model, a multi-scale residual aggregation feature network model for image super-resolution reconstruction is proposed. First, the proposed network model uses expanded convolutions with different expanded coefficients and residual connection to construct a hybrid expanded convolution residual block (HERB), which can effectively extract multi-scale feature information of an image. Second, a feature aggregation mechanism (AM) is used to solve the problem of insufficient utilization of features among middle levels of the network. Experiments results on five commonly used data sets show that the proposed network model has better performance than other models in subjective visual effect and objective evaluation index.
An infrared polarized thermal image segmentation algorithm based on image gray and information entropy fusion is proposed. First, the local average gray and variance weighted information entropy of the image are used to find out the potential region of multi polarization azimuth thermal image and register it; second, the improved fuzzy C-means (FCM) algorithm is used to segment the thermal image separately, and the result of set operation is used as the label of support vector machine (SVM); then, the data of target region and background region are trained to obtain SVM model and redivide the fuzzy region; finally, the segmented thermal image is achieved by morphological processing synthetically. Experimental results show that compared with the maximum entropy algorithm, OTSU algorithm, and FCM algorithm, the proposed algorithm can get higher segmentation accuracy and effectively improve the phenomenon of wrong segmentation.
To overcome the lack of local features of the deep neural network PointNet and the need for the improvement of segmentation accuracy, the present research introduces a local feature extraction method combined with an improved K-nearest neighbor (KNN) algorithm based on PointNet and a neural network known as KNN-PointNet. First, the local area is divided into k circular neighborhoods, and weights are determined according to the difference in the distribution density of sample data in the local area to calculate the classification of the points to be measured. Second, the local neighborhood features combined with single point global features are used as input for feature extraction by adjusting the network depth to extract local features for enhancing the correlation between points in the local neighborhood. Finally, the improved KNN algorithm is applied to the KNN-PointNet point cloud segmentation network for experimental comparison. Results show that compared with some current advanced segmentation networks, the segmentation network KNN-PointNet with local features extracted by the improved KNN algorithm has higher segmentation accuracy.
The local k-space neighborhood model is a recently proposed k-space low-rank constrained reconstruction model, which uses the linear displacement invariance of the image to map the k-space data of the image to a high-dimensional matrix, which can solve the problem of image reconstruction. In the process of parallel magnetic resonance imaging reconstruction, the use of undersampling technology to increase the imaging speed will cause the quality of the reconstructed image to decrease. For this reason, a local k-space neighborhood modeling algorithm based on Lp-norm joint total variational regular terms is proposed. The proposed algorithm is to experiment with the proposed algorithm and other algorithms on the human brain and knee datasets. The experimental results show that compared with other algorithms, the proposed algorithm can reduce the artifacts of the reconstructed image, retain the edge contour information of the reconstructed image better, and achieve better reconstruction effect.
This paper proposes an improved flame target detection algorithm based on YOLOv3 (You only look once, v3) to solve the causes of reduced detection accuracy caused by fire on small and medium-sized target, multi-target, and fuzzy edge. First, the improved feature pyramid network makes use of local information twice. Then, a large-scale full convolution module is designed to obtain global spatial information of various scales, and an improved channel space attention mechanism is used to improve effective information and suppress useless information. Finally, as loss functions, complete intersection-over-union and Focal Loss are used to improve the detection accuracy of difficult-to-recognise targets and alleviate the problem of data set imbalance. Experimental results in self-made flame data show that this algorithm has higher detection accuracy and faster detection speed. The average accuracy is up to 89.82%, and the detection speed can reach 20.2FPS (Frames per second), enabling it to meet real-time and high-efficiency fire detection requirements.
Factors such as optical noise and electronic device noise can affect the accuracy of the strain field in the digital image correlation method. This paper introduces an algorithm based on single-point redundant strain information. This algorithm suppresses noise in the strain field through weighted summation using a probability density function or constructing an exponential weight function. In the pointwise least squares method, this proposed algorithm is used to identify the strain field of the computed-simulated speckle images test, the tensile test of a plate with one hole, and the bending test of a reinforced concrete column with cracks. The results show that in the case of homogeneous deformation, compared with the classical pointwise least squares algorithm, the accuracy of the strain field calculated by the proposed method has been effectively improved; while both methods achieve the same precision, the calculation speed of the proposed method by more than 65%. Moreover, the proposed method can obtain more reliable strain values in the region near the crack, giving it a broader range of application. Furthermore, compared the regularization-aided finite element strain calculation method, the proposed method has greater accuracy and a faster calculation speed.
Aiming at the problems of complex structure, poor reliability, high cost, and low accuracy in the front shield/support shield pose measurement methods in the existing dual shield tunnel boring machine (TBM) guidance system, this paper proposes a new method for non-contact rapid measurement based on industrial cameras and special-shaped active targets. This method uses technologies such as machine vision, spatial pose transformation, and multi-sensor fusion/calibration to realize the function of stably guiding the dual-shield TBM in the state of strong vibration tunneling. The experimental results show that the proposed method can achieve the high-performance measurement of the six-degree-of-freedom space pose of the front shield/support shield, the measurement frequency is not less than 20 Hz, and the measurement error of the feature point coordinates of the shield machine in a static state is less than 5 mm@(3 m×2 m×6 m), the measurement error under vibration is less than 10 mm@(amplitude is 3 mm, frequency is 20 Hz), which can be used in the double shield TBM guidance system.
With the advancement of DeepFake technology in recent years, the current social platform is full of massive fake videos produced by face-changing technology. Although fake videos can enrich people’s entertainment, they also have disadvantages, such as exposing their personal information. How to accurately detect the fake data generated by DeepFake technology has become an important and difficult task in network security defense. Many researchers have proposed face-changing video detection methods in response to this problem, but the existing detection methods often ignore the incoherence of facial feature crossing video frames. Thus, they are easily countered by optimizing facial synthesizing techniques, resulting in accuracy degradation. Based on this, we propose a novel DeepFake detection method based on long short-term memory (LSTM) network that captures the micro expression changes in terms of the facial features caused by the composite video and uses an encoder to generate features of local visual information. Simultaneously, the attention mechanism is used to achieve the weight distribution of local information. Finally, the LSTM network is used to realize the association information fusion of video frames in temporal space, resulting in the effective detection of DeepFake video data. This paper evaluates a proposed algorithm on the FaceForensics++ dataset, and when compared to existing methods, the experimental results show that the proposed algorithm is superior.
The optical system is divided into four segments in this study, according to the apochromatic and high-resolution requirements of the machine vision lens, and the initial structure of each segment is optimised independently before being merged to obtain the initial structure of the lens segment. The Buchdahl dispersion vector analysis method is employed to perform targeted replacement of some glass materials, and multiple optimisations are applied to provide an apochromatic machine vision optical system that fulfils the criteria of optical performance. The focal length of the system is 60 mm, the half field of view is 11° and the F-number is 5.45. The image field can match a 1″ large target CMOS camera, and each field of view has a modulation transfer function value of 200 lp/mm. At an aperture of 0.707, the system’s residual chromatic aberration is 0.01665 μm, which is within the system’s chromatic aberration tolerance. The secondary spectrum of the system is 0.08385 μm, indicating that the optical system is apochromatic. The Buchdahl dispersion vector is shown to be effective in the experiments. In the process of grouping design and overall optimisation of the lens system, the analysis method can provide greater convenience for the selection of optical glass and the overall optimisation of the system.
The existing matching algorithm has a low registration accuracy of point clouds with low overlap, and is more sensitive to different scales. In order to achieve a better registration effect, it is necessary to preprocess or adjust more parameters to the point cloud. Fast point feature histogram (FPFH) has a low complexity, and retains most of the features of the point cloud. Therefore, we propose an improved registration algorithm based on FPFH of the point cloud. First, extracting key points with multi-scale features based on FPFH to adapt to different scales point cloud datasets, while reducing the number of parameters that require adjustment. Then, the corresponding point relationship after the initial screening of FPFH matching is accurately extracted, the distance constraint condition in the point cloud is added, which reduces sensitivity of the algorithm to overlap and the preliminary transformation matrix of registration is obtained. Finally, the iterative closest point algorithm is subjected to fine-tuning to achieve the purpose of accurate registration. The experimental results show that the algorithm has good registration accuracy on different overlap and different scales of point cloud datasets.
Sea surface temperature (SST) is an important indicator for balancing the surface energy and measuring the sea heat, the high-precision prediction of SST is of great significance to global climate, marine environment, and fisheries. Under extreme climatic conditions, the SST sequence presents obvious non-stationarity, traditional methods are difficult to predict sea surface temperature (SSTP) and have low accuracy. The non-stationarity of the SST subsequence decomposed based on the empirical mode decomposition (EMD) algorithm is significantly reduced, and the gated recurrent unit (GRU) neural network, as a common machine learning prediction model, has fewer parameters and faster convergence speed, so it is not easy to over fit in the training process. Combining the advantages of the EMD model and the GRU model, a SST prediction model based on EMD-GRU is proposed. In order to verify the prediction effect of the proposed model, several groups of comparative experiments were carried out on five SST sequences with different lengths. Experimental results show that the multi-scale complexity of the prediction results of the proposed model is lower in comparison with directing application of recurrent neural network (RNN), long-short term memory (LSTM), and GRU models, and the mean square error (MSE) and mean absolute error (MAE) of the prediction results of the proposed model have been reduced. In order to verify the influence of data sequence length on prediction accuracy, a supplementary experiment is designed. The longer the prediction length, the worse the accuracy effect; after the sequence is processed by EMD algorithm, the effect is improved, and the effect is improved obviously when the prediction length becomes longer.
In order to make full use of the redundant information of the multi-vision system and improve the precision of the system in solving the world coordinates of the homonymous object points, a nonlinear optimization algorithm based on weighted Levenberg-Marquardt (LM) is proposed. The algorithm fully considers the influence of shooting distance on the accuracy of object point calculation. The generalized orthogonal projection method in matrix theory is used to solve the initial position of the object points in world coordinates under the constraint of multiple cameras, and the objective function is weighted with depth information to improve the confidence of the camera in closer distance. Then, the weighted LM algorithm is used to iteratively calculate the object point world coordinates to obtain the optimal solution. Experiments are carried out on four algorithms in an 8 m×6 m×3 m measurement space, experimental results show that the proposed algorithm has different degrees of improvement in accuracy and efficiency compared with the traditional algorithm and the algorithm proposed in recent years, which can offer some references for high precision positioning of the multi-vision system.
In order to solve the problem that the accuracy of defect detection algorithm is not high and it is difficult to meet the actual requirements due to the complex surface texture of aluminum profile and the large difference in defect size, an improved object detection network AM-YOLOv3 (attention-guided multi-scale fusion YOLOv3) is proposed. The attention guide module and four prediction scales are designed to realize the multi-scale feature extraction of aluminum profile surface defects. A bottom-up feature transmission path is constructed, which is combined with the original feature pyramid network to form a twin-towers structure, and the multi-scale feature fusion is realized. K-medians algorithm is used for anchor box clustering, which more accurately characterizes the distribution law of anchor frame size and improves the convergence speed of the network. The performance of the proposed algorithm is verified by experiments on the public aluminum profile dataset. The experimental results show that the mAP (mean average precision) of the proposed algorithm reaches 99.05%, which is 6.8% higher than that of the YOLOv3 model, and the frame rate reaches 43.94 frame/s.
Aiming at the problems of low contrast, weak edges and noise interference of low brightness images,a new image enhancement method based on improved quantum harmony search (QHS) algorithm to optimize fuzzy set transform in nonsubsampled Contourlet transform (NSCT) domain is proposed. First, the low brightness image is subjected to NSCT decomposition to obtain low frequency image and multi-scale high frequency sub-band images. Then, the quantum revolving door updating strategy of QHS algorithm is improved, and the improved QHS algorithm is used to optimize the transformation parameters of the fuzzy sets to realize the adaptive enhancement of low frequency images. Moreover, the Bayesian shrinkage threshold is improved to remove the noise coefficient of the high frequency sub-bands according to the energy distribution, and the edge and texture details are enhanced by the nonlinear gain function. Finally, the enhanced images of various scales are reconstructed by NSCT. Experiments are carried out on low luminance images, medical computed tomography (CT) images and infrared night vision images. The results show that, compared with the existing image enhancement methods, the proposed method not only improves the overall brightness of the image, but also has higher information entropy, contrast and clarity. In addition, the proposed method not only suppresses noise effectively, but also retains more texture details, and is suitable for low brightness image enhancement in different environments.
Aiming at the problem that pedestrian head is susceptible to illumination changes and occlusion, which leads to low target detection accuracy, a pedestrian head detection algorithm based on two-channel single shot multibox detector (SSD) with multi-scale fusion is proposed. First, a deepth channel is added to the SSD network, and the head features with depth information are fused with the features of the SSD network to form a two-channel SSD network. Then, on the basis of the two-channel SSD network, the high-level feature map with rich semantic information is fused with the low-level feature map to achieve more accurate head location. Finally, the prior frame of SSD is re-adjusted to reduce the computational complexity of the SSD network. Experimental results show that in the case of illumination and occlusion, the detection accuracy of the improved algorithm is improved by 12.9 percentage points compared with the traditional SSD target detection algorithm, and it can effectively solve the influence of illumination changes and occlusion on pedestrian head detection.
Appendiceal neuroendocrine neoplasms (ANENs) account for a large proportion of all types of appendiceal malignancies, and one of the important diagnostic criteria is the size of Ki-67 proliferation index. The calculation of the Ki-67 index mainly depends on the experience of pathologists; however, the manual counting process is tedious. Therefore, this study aims to calculate the number of positive and negative cells in the ANEN pathological sections using computer image analysis algorithm and calculate the Ki-67 index to assist the pathologist for conducting a comprehensive evaluation. Aiming to resolve the over-segmentation problem of the traditional watershed algorithm, we used a forced minimum technique to modify the distance and propose an improved watershed algorithm. Then, we segmented, recognized, and counted the positive and negative cells in pathological images, and matched them with the pathologist’s gold standard. Our results show that the average accuracy of the proposed algorithm for the negative cells’ segmentation is 93.4%, while the average over-segmentation rate is 3.3%. Moreover, the average accuracy of the Ki-67 index and average error rate of computer-aided processing ANEN pathological images are 93.2% and 6.8%, respectively. The average time of processing ANENs pathological images decreases artificial time consumption from 57.4 s to 29.5 s, which improves the working efficiency.
Aiming at the problems of missing detection, false detection, and low detection accuracy of the Faster R-CNN target detection network, a soft non-maximum suppression (Soft-NMS) fusion attention mechanism and the Faster R-CNN (Faster Region-Convolutional Neural Network) target detection algorithm is proposed. In order to enhance the global important feature extraction and weaken the irrelevant feature in the feature map by the Faster R-CNN target detection algorithm, an attention mechanism is firstly introduced into the network. Second, aiming at the problem of local information loss caused by the bottleneck structure formed by two fully connected layers in the attention mechanism, a non-dimensional-reduction channel attention and spatial attention series module that can be trained end-to-end with the convolutional neural network is constructed. Then, a Soft-NMS is introduced to replace the traditional non-maximal suppression (NMS) algorithm after the regional suggestion network, which can reduce the target missing detection and improve the location accuracy. Finally, the error detection rate is introduced into the evaluation criteria to further verify the performance of the model. Experimental results show that the Faster R-CNN algorithm based on ResNet-50 can effectively reduce the missed detection and false detection and improve the location accuracy, and the average detection accuracy is significantly improved.
In dynamic scenes, the high-frequency and multi-phase operation of a time-of-flight image sensor will produce motion blur, causing incorrect three-dimensional original data in the motion area, and increasing the difficulty of circuit design. This paper proposes a time-of-flight image sensor model in a dynamic scene to reduce the impact of motion blur. The model can quickly complete the sensor parameter setting through simple parameter settings, which is used to simulate three-dimensional images in dynamic scenes under various conditions to analyze motion errors. The effect of motion error on imaging quality under different motion speeds and frame rates is analyzed using the imaging model, and the difference in imaging quality between the two exposure modes in dynamic scenes is investigated. Finally, the optimal imaging indicators are obtained, with high imaging quality and low circuit design difficulty. The imaging model is evaluated using a Texas Instruments time-of-flight camera, and the verification results show that the model’s simulation data can effectively match the camera’s measured data in both static and dynamic scenes.
Spatial distribution characteristics and seasonal attributes of aerosol optical properties in typical regions around the world are studied through the statistical analysis of multiple aerosol optical parameters using two-level aerosol layer products provided by the cloud-aerosol lidar and infrared pathfinder satellite observation (CALIPSO) satellite remote sensing data from 2009 to 2018. Results show that the monthly averages of the aerosol optical depth (AOD) in Saudi Arabia and India are unimodal, reaching a peak from June to July; the monthly average changes of the AOD in China and Central Africa are bimodal, with the highest values appearing from April to June and from December to January. The regional difference between the particulate depolarization ratio (PDR) and color ratio (CR) is the degree of irregularity of particles, which is the largest in Brazil with a PDR value of 0.5--0.7. In China, India, and Indonesia, fine-mode particles are mainly encountered with a CR value of 0.1--0.2. During the DJF and MAM periods, the nonspherical trend of particles in Saudi Arabia was the strongest, and during the JJA and SON periods, the particles in Saudi Arabia and Central Africa had the largest particle size with a CR value ranging from 0.756 to 0.829. The irregularity of aerosol particles in each region shows an increasing trend, and the variation range of the trend coefficient is 0.01--0.025; the increasing trend is most obvious in Brazil, and the particle size shows a weak downward trend.
The back-end optimization part of the simultaneous localization and mapping (SLAM) algorithm based on graph optimization generally uses a direct nonlinear optimization method. However, the calculation time of the direct nonlinear optimization method increases proportionally with the cube of the graph size, and optimizing large-scale pose graphs has become a crucial bottleneck for mobile robots. Therefore, under the framework of graph optimization, the SLAM algorithm based on sparse pose optimization is used in this work to efficiently calculate the large sparse matrix of the constraint graph through the direct linear sparse matrix solving method. Additionally, it is processed and optimized by using the spanning-tree initialization method. At the same time, experiments are performed on an autonomously built mobile robot platform and the SLAM algorithm based on sparse pose optimization is compared with Gmapping and Hector algorithms in different indoor environments. Results show that the proposed algorithm is superior in mapping accuracy and has a lower CPU load.
The advent of machine learning in recent years has given a hope for modeling in the field of human physical rehabilitation exercises, and the classification recognition based on deep learning has achieved a high recognition rate. The characteristics of the depth model can make the sensor suffer from noise attacks in the recognition rate. Thus here based on the Wasserstein generative adversarial network (WGAN), the generative physical rehabilitation exercise GAN (GPREGAN) framework is proposed, which is improved to disguise aggressive data as normal data. This adversarial data is so highly similar to the original data that the detection algorithms cannot distinguish between them. The generated adversarial data is fed into a deep recognition model based on convolutional neural network (CNN) and long short-term memory (LSTM) network in the experiments, and the detection rate is reduced from 99% to 0 by successfully attacking the network. To evaluate the effectiveness of the generated adversarial samples, the paper uses the sample mean square error for evaluation. It is demonstrated that the GPREGAN framework has the ability to generate time-series data analogous to that in the field of human physical rehabilitation exercises and to increase the diversity of samples in this field.
In order to solve the problems of false detection, missing detection and poor real-time performance caused by uneven density and incomplete segmentation of point cloud in lidar obstacle detection, an improved DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm is proposed to improve the effect of obstacle clustering. Firstly, the k dimensional tree (kD tree) index is established with scattered point cloud data, and the RGF (Ray Ground Filter) algorithm is used to segment the ground points after the raw data is preprocessed. Then, the traditional DBSCAN algorithm is improved to change the clustering radius of obstacles adaptively with scanning distance, and the clustering effect of long-distance obstacle point clouds is improved. The experimental results show that the proposed method can achieve good clustering for obstacles with different distances, its average time consumption is reduced by 1.18 s and its positive detection rate is increased by 19.60 percentage points compared with those of the traditional method.
The present research proposes an efficient scale-adaptive and fully convolutional network based on an encoder-decoder network, which represents a crucial innovation aimed at improving buildings extraction with various scales from remote sensing imagery with high spatial resolution. First, a multiple-input multiple-output structure is proposed to obtain multiscale features fusion and cross-scale aggregation. Then, a residual pyramid pooling module is deployed to learn deep adaptive multiscale features. Finally, the initial aggregated features are further processed using a residual dense-connected aggregated-feature refinement module. Pixel dependencies of different feature maps are investigated to improve the classification accuracy. Experimental results on the WHU aviation and the Massachusetts datasets show that compared with other methods, the method has a better extraction effect on buildings, and the training time and memory usage are moderate, which has high practical value.
Aiming at the problem that the existing deep learning light detection and ranging (LiDAR) point cloud segmentation method ignores the relationship between high-level global single points and low-level local geometric features, which results in low point cloud segmentation accuracy, an enhanced semantic information and multi-channel feature fusion point cloud scene segmentation model is established. First, the point cloud information is supplemented, the normalized elevation, intensity value and spectral information of the point cloud are extracted to construct the multi-channel point cloud features, and the multi-scale neighborhood point cloud enhancement data set is established by using the grid resampling method. By constructing a double attention fusion layer, the feature weighted calibration in the channel dimension and feature focusing in the spatial dimension are realized, the deep information transmission of the convolution network structure is deepened, and the local regional fine-grained features of the point cloud are mined. The proposed algorithm is verified by using the data set provided by the International Association of Photogrammetry and Remote Sensing. Overall accuracy (OA) of accuracy value classification, comprehensive evaluation index (F1),and intersection ratio of the proposed algorithm, the classification results published on the association's website, and mainstream deep learning methods are compared and analyzed. Experimental results show that the proposed algorithm can achieve higher segmentation accuracy, and the average intersection union ratio on Vaihingen data set reaches 52.5%.
Aiming at the problem that the existing hyperspectral image classification algorithm based on ladder network (LN) cannot fully extract the spatial-spectral features of the image, which leads to the reduction of classification accuracy, a hyperspectral semi-supervised classification algorithm based on improved ladder network is proposed. First, the three-dimensional convolutional neural network (3D-CNN) and the long-short-term memory (LSTM) network are combined to propose a new spatial-spectral feature extraction (3D-CNN-LSTM) network, which is used to extract local spatial features step by step. Then, the 3D-CNN-LSTM network is used to improve the encoder and decoder of the ladder network, and a 3D-CNN-LSTM-LN semi-supervised classification algorithm is proposed to enhance the feature extraction ability of the ladder network. Finally, different algorithms are tested on Pavia University and Indian Pines datasets. The experimental results show that the proposed algorithm achieves the best classification effect under the condition of small samples, which verifies the superiority of the proposed algorithm.
To extract high voltage pylons from airborne LiDAR point clouds, a pylon automatic extraction algorithm is proposed. First, the point cloud is preprocessed, and the cloth simulation filtering (CSF) algorithm is used to obtain ground points and non-ground points. Then, spatially regularized grid processing is carried out for non-ground point clouds, rough extraction is performed according to the elevation characteristics of high voltage pylons, and region of interest grids with pylons are obtained. Finally, the improved DBSCAN (density-based spatial clustering of applications with noise) algorithm is used to remove the noise points in ROI grids, and the pylon point cloud is finely extracted. The test results show that the algorithm in this paper can realize the automatic extraction of high voltage pylons from LiDAR point clouds, with a high degree of automation and a high processing efficiency.
Due to the limitation of dynamic range, it needs to control the exposure time and automatic gain for traditional cameras to obtain clear information of the target scene through reducing the influences of pixel saturation and overflow. In order to obtain a clear image simultaneously including dark and bright field information, the dynamic range of the CMOS image sensor must be extended. In this paper, a dynamic range expanding method of CMOS cameras based on binary image superposition is proposed. By superposing a series of binary images with a logarithmic exposure time, the image detection dynamic range of the CMOS camera is improved. As a result, the camera can simultaneously detect strong and weak signals even in the environment with a large brightness variation, and obtain clear gray images of the target scenes. The experimental results show that the relative dynamic range of this binary superposition CMOS camera can be enlarged to more than 8 times that of the traditional counterpart. A comparison of image brightness curves shows that this camera has an effective logarithmic response output. This camera can also effectively reduce the saturation overflow in the bright part and the loss of details in the dark part of the image, and can obtain a complete clear and uniform image in both the highlighted and backlit parts.
Camera calibration is the basis for imaging and computer vision as well as the premise for sensing and vision detection. The camera presents the three-dimensional feature points of space objects in a two-dimensional form on the imaging plane. Each parameter of the camera is determined by the three-dimensional feature points in space and the corresponding two-dimensional image points. This process is called camera calibration, including the calibrations of the internal parameters and the position and pose of the camera in the three-dimensional spatial coordinate system. Based on a brief introduction of the working principle of the area-array camera, this paper summarizes the area-array camera calibration model, calibration methods, rapid calibration methods for large field-of-view cameras, and discusses the latest camera application fields and calibration technologies. Finally, the future research direction of camera calibration is prospected.
Nowadays, cardiovascular diseases have become the No. 1 killer of human health. Developing high-resolution intracavitary imaging technology is conducive to the accurate diagnosis and treatment of cardiovascular diseases. Optical coherence tomography (OCT) has the advantages of non-contact, non-invasive, high-resolution, and fast imaging capabilities, which plays a crucial role in the guidance for the treatments of cardiovascular diseases. In this work, we first described the situation of increasing cases of percutaneous coronary intervention (PCI) in China in recent years, and then the development and application of OCT, endoscopic OCT, and cardiovascular OCT were introduced. We gave a detailed review of the progress of the cardiovascular OCT in academic research and commercial translation. The importance of cardiovascular OCT in clinical diagnosis of coronary plaques and the guidance of stents and prognosis were illustrated. In the end, this article provided the prospect outlook of cardiovascular OCT in future development, and the important research and application values of cardiovascular OCT were summarized.
Brain tumor image segmentation based on convolutional neural network has become a research hotspot in the field of image processing in recent years. Based on this situation, the significance and research status of brain tumor image segmentation, and the specific advantages of applying convolutional neural network to brain tumor image segmentation are described. Then, the research progress of two-dimensional convolutional neural network, three-dimensional convolutional neural network and the classical improved model of convolutional neural network applied to brain tumor image segmentation is reviewed in detail, and the segmentation results of training in the dataset of multi-mode brain tumor segmentation challenge are summarized. Finally, the future development of convolutional neural networks in magnetic resonance imaging segmentation of brain tumors is discussed.
Biological evidence is individual-specific, easily ignored by criminals, stably attached to the crime scene, and difficult to destroy completely. It has a high investigative value. Based on the photoacoustic effect, the photoacoustic spectroscopy realize detection using the mechanism by which the sample absorbs light energy, converts it into heat energy, and generates a sound signal. The photoacoustic spectroscopy provides a sensitive and nondestructive effective method for the research of biological materials, and it has become an essential analysis tool in the field of forensic science. Based on a brief introduction to the photoacoustic effect and the principle of photoacoustic signal generation, this article focuses on the research status of photoacoustic spectroscopy in the identification and analysis of gas, liquid, and biological tissue materials that can be used as forensic biological evidence. The application limitations and development prospects of the technology are summarized and prospected.
The research progress of human pose estimation method based on deep learning is comprehensively summarized. On the basis of comparison and analysis of various single-person pose estimation methods, a variety of multi-person pose estimation algorithms are summarized from the top-down and bottom-up approaches. In the top-down approach, the solutions to local area overlap, articulation point confusion, and difficulty in detecting the articulation point of atypical parts of human body are mainly introduced. In the bottom-up approach, the contribution of clustering method to articulation point detection is emphasized. Representative methods to achieve excellent performance on current public datasets are compared and analyzed. The review enables researchers to understand and familiarize themselves with the existing research results in this field, expand research ideas and methods, and look forward to the possible research directions in the future.
The traditional fluorescence microscopy imaging technique takes fluorescence intensity as imaging contrast, which plays an important role in obtaining the position and concentration information of biomolecules and provides an imaging tool for biomedical research at the molecular level. As another important characteristic of fluorescence, polarization can provide the orientation and structural information of biomolecules in another dimension and has been widely used in the fluorescence polarization microscopy imaging technique. In addition, fluorescence polarization modulation can also be used to obtain the position and orientation information of biomolecules at the super-resolution scale by enhancing the sparsity of fluorescence images and thus enhancing the image contrast. In this paper, as for the different fluorescence polarization modulation imaging techniques based on fluorescence polarization characteristics, their developments in the molecular orientation structure imaging, super-resolution microscopy imaging and the combination of the two aspects are summarized from the physical bases, technical principles, basic implementation devices, and biological applications. Moreover, the future of these techniques is prospected.
Researchers can now identify dynamic activities in living cells at the nanoscale with remarkable temporal and spatial resolution because of the advancement in fluorescent super-resolution imaging. Traditional super-resolution microscopy requires high-power lasers or numerous raw images to rebuild a single super-resolution image, limiting its applications in live cell dynamic imaging. In many ways, deep learning-driven super-resolution imaging approaches break the bottleneck of existing super-resolution imaging technology. In this review, we explain the theory of optical super-resolution imaging systems and discuss their limitations. Furthermore, we outline the most recent advances and applications of deep learning in the field of super-resolution imaging, as well as address challenging difficulties and future possibilities.
Humans observe the world through their eyes and optical instruments, but scattering seriously disrupts light propagation, making focusing and imaging extremely difficult through the scattering medium. By modulating the phase of the input light through feedback optimization, the wavefront distortion caused by scattering can be corrected, allowing light to focus on a specific target in the output light field. Therefore, we propose a memetic algorithm-based method for focusing through a scattering medium. The method combines global search and local search, abstracting focusing through scattering medium into the process of cultural evolution. The simulation and experimental results show that, when compared to focusing methods based on genetic algorithm and particle swarm optimization algorithm, the method has obvious advantages in focusing effect and time consumption, and has good application potential in the field of light field control.
Gabriel pearls are freshwater-nucleated pearls developed in recent years cultured in the mantle of Hyriopsis cumingii. In response to its coloration mechanism, scholars have proposed diversified viewpoints. In our research, both laser Raman spectroscopic and micro-infrared spectroscopic analyses were performed on Gabriel pearls with carotenoid standard samples (β-carotene and astaxanthin) as reference materials for a better understanding of the coloration mechanism, which was expected to provide a scientific theoretical basis for quality evaluation and cultivation technology of these pearls. The results confirmed the strong 1509 and 1126 cm -1 Raman peaks of the nacre of freshwater colored nucleated pearls attributed to ν1(C=C) and ν2(C—C) stretching vibration modes of carotenoid-binding protein, respectively. The presence of a weak peak at 1017 cm -1 was associated with the plane oscillation of CH3 (ν3). Raman spectra in the range of 2100--3800 cm -1 revealed five groups of peaks with varying intensities, which were attributed to frequency multiplication and combined frequency vibration of ν1, ν2, and ν3. Notably, there was a correlation between the number of conjugated double bonds of carotenoid molecules or carotenoid-binding proteins and the color of freshwater-nucleated pearls, indicating one of the reasons for the coloration diversity of pearl color.
Lipstick is considered to be one of the most important physical evidence in forensic science. In order to establish a new method for detecting lipsticks, 50 lipstick samples are tested by using differential Raman spectroscopy combined with chemometrics method. It can be observed from the differential Raman spectrum that the lipstick contains various oils, waxes and oxides. By analyzing the spectrum, lipstick samples of different brands and different series of the same brand can be distinguished according to one or more Raman characteristic peaks, and the discrimination power (DP) value is 100%. All samples are reasonably divided into 10 categories by cluster analysis method, and the DP value is 88.16%. The classification model based on cluster analysis is established by distance discriminant method, the classification accuracy rate can reach 96.00% after cross-validation. The results show that the proposed method can realize non-destructive inspection, and the collected spectra have high signal-to-noise ratio and are not disturbed by fluorescence.
The plasma brightness characteristics derived from the femtosecond laser in the micromachining process can be used as real-time feedback measurement signals. Therefore, it is of great significance to study the brightness characteristics of the spot and construct a high-quality brightness change curve with rich details. In this paper, first, in view of the low signal-to-noise ratio of the spot image and the blurred edge of the target area, the improved wavelet threshold denoising method is used to filter the spot image, and a smooth spot with higher edge contrast can be obtained without changing the brightness level of the spot. Then, the K-means clustering method is used to segment the light spot image, and the halo part that appears as noise is segmented out, and only the area with effective brightness is retained. Finally, the brightness change curve of the light spot sequence image is extracted, and the curve is processed by the method of combining fractal and multi-scale soft threshold filtering, and a high-quality brightness change curve with richly detailed information is obtained. The brightness and fractal dimension are calculated using spot images with different powers. The results show that the brightness of the spot and the complexity of the spot transformation both increase with the increase of the laser processing power.
With the proposal of Industry 4.0 and the rapid development of machine vision in recent years, the realization of an intelligent robot with a vision system has become a reality. The visual system is mainly divided into two-dimensional (2D) vision and three-dimensional (3D) vision. 3D vision has the advantages of high precision, rich degree of freedom, and more application scenes, and is increasingly favored by the market. Compared with traditional 2D vision, 3D vision can obtain more comprehensive 3D data information, and is not affected by illumination. However, the resolution of X and Y directions is low, so the traditional hand-eye calibration algorithm based on checkerboard is not suitable for hand-eye calibration of 3D cameras and robots. Therefore, a hand-eye calibration method for robot and 3D camera based on 3D calibration block is designed. Through the camera calibration of gray information, the use of template matching algorithm segmentation calibration block of each plane, calculate the multiple points in plane in pixel coordinates of the location and the pixel coordinates of depth information at the same time, the fitting of the calibration block multiple plane normal vector information, through multiple plane intersection location feature point out. Random sample consensus algorithm was used to eliminate the wrong feature points, and according to the correct feature points, the transformation relationship between the point cloud data of the calibration block obtained by the robot under different poses was solved. The hand eye calibration results were solved based on the current coordinates of the robots, and the error evaluation model was established to analyze the results. Finally, the comparison between this method and the hand-eye calibration method using calibration plate was carried out by 6 degrees of freedom robot arm of the DENSON and Cognex EA-5000 camera. The results show that this method can complete the calibration more quickly and accurately.
Nowadays, deep learning algorithms used for stereo matching have the problems of complex network structure and high consumption. In order to solve such problems, an end to end stereo matching network structure with only half the parameters of the reference network PSMNet is proposed. In the feature extraction module of the proposed network, the general framework is retained, its redundant convolutional layers are reduced, and meanwhile the spatial attention mechanism and channel attention mechanism are integrated to gather contextual information. In the cost calculation module, the input disparity dimension of the disparity calculation is reduced by increasing the offset, and therefore, the parameter amount and consumption of disparity calculation are greatly reduced. In the disparity calculation, the multi-disparity prediction is performed for the output of the matching cost feature body. And the cross-entropy loss function is added to the L1 loss function, which ensures the matching accuracy when reducing the consumption of the model. The proposed algorithm is tested on the KITTI dataset and SceneFlow dataset. The experimental results show that compared with the benchmark method, the parameter amount of the proposed model is reduced by 58% while the accuracy is increased by 24%.