







Please enter the answer below before you can view the full text.
8-3=

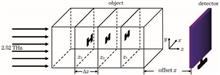
Compressed sensing terahertz digital holography technology is utilized to reconstruct three-dimensional images of a continuous scene. The control parameters affecting the reconstruction results primarily include the numbers of iterations and the sparse limit parameter. First, the holograms of a continuous scene and a discrete scene on three dimensions were reconstructed, simulated and compared. Then, the number of iterations was changed, and the reconstruction results varying with sparse limit parameters was used to find the best control parameters. Simulation results show that the reconstructed image quality is optimal when the number of reconstruction planes is 4, number of iterations is 300, and sparse restriction parameter is not greater than 0.02.
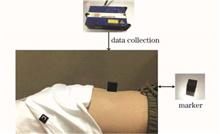
In this study, an object detection and tracking technology based on the Kanade-Lucas-Tomasi (KLT) algorithm is proposed in this work, which is applied to tracking human respiratory motion during radiotherapy. In the experiment, a human body model with adjustable motion parameters is used to simulate different breathing states of human body, and the image information of motion process is collected by the camera. After a series of image preprocessing such as edge detection and edge enhancement performed on the collected image, the region of interest in the first frame of the image is manually marked, and automatic tracking of the region of interest in the remaining frames of the image is realized through a tracking algorithm. Experimental results verify that the proposed algorithm can accurately realize real-time tracking of the human body surface in different breathing states, and the actual normalized displacement error is less than 0.03. The algorithm can be applied to clinical respiratory motion detection, and the obtained image information and parameters can be used to guide precise radiotherapy.
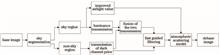
An improved dark channel prior image dehazing algorithm based on the fusion luminance model was proposed to deal with the failure of a dark channel prior in the sky. First, sky and non-sky areas were segmented using a Canny operator. Next, luminance transmission was constructed by simulating the depth of the scene using the luminance, which combined with the transmission of the dark channel to form the transmission of the sky area. A fast-guided filter was used to optimize the transmission map. The value of atmospheric light was selected as the median of the top 0.1% of the pixels with strong anti-interference ability. Finally, the haze-free image was restored using the atmospheric scattering model. Experimental results show that the algorithm could effectively recover the details of the image and suppress the halo phenomenon for the haze image including the sky area with appropriate brightness and natural color.
To overcome the shortcomings of the existing methods in the segmentation of liver medical images, an improved U-Net structure for liver medical image segmentation is proposed in this paper. To reduce information loss, the pooling layer features are copied during upsampling. Moreover, a residual network is introduced to refine the initial segmented image circularly to combine high-level features with low-level features. Using a new boundary-sensitive mixed loss function to refine the image, the network can obtain more accurate segmentation results. The experimental results show that the Dice coefficients of the liver images and liver tumor images are 96.26% and 83.32%, respectively. Compared with the traditional U-Net, the proposed network can obtain more advanced semantic information and improve the segmentation accuracy of liver and liver tumor images.
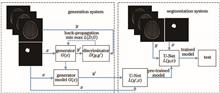
In order to solve the problem that deep learning algorithm has insufficient labeled data in brain tumor segmentation, in this paper, an automatic segmentation method of low-grade gliomas (LGG) magnetic resonance (MR) images based on conditional generative adversarial networks (CGAN) is proposed. First, the original dataset is used to train the CGAN and generate LGG images to expand the original dataset. Then, the generated images are used to pre-train a segment network. Finally, the segmentation model is trained on the basis of the pre-training model. Experimental results show that compared with traditional data augmentation methods, the proposed method improves the Dice coefficient by 4.39% and Jaccard index by 4.42%. The method provides a reference for the development of a computer assisted diagnosis system for LGG segmentation based on MR images.
In view of the different types of speckle noise in the photothermal optical coherence tomography (PT-OCT) three-dimensional image, an improved rotating kernel algorithm is used to suppress them. First, the PT-OCT images are decomposed by wavelet, and four sub-images with different frequency bands are obtained. Then, the foreground and background of the low-frequency approximation sub-images are separated by the maximum between-class variance algorithm, and the segmented enhancement is performed. The improved RKT algorithm is used to filter the high frequency detailed images in horizontal, vertical and diagonal directions respectively. Finally, the low frequency approximate image and the high frequency detail image after three rotating core filtering are linearly enhanced, and then reconstructed to obtain the de-noised image. The proposed algorithm can effectively reduce the speckle noise between vessels in PT-OCT images for angiographic cross section images of brain and other complex tissues and section tomography images at different depths. Compared with the classical RKT algorithm, the square-root mean error is reduced by 27.16 on average, and the average peak signal-to-noise ratio is increased by 3.68dB, which can improve the quality of angiography imaging.
In order to solve the shortcomings of the traditional Criminisi algorithm which the priority value tends to zero quickly and costs much inpainting time, an improved image inpainting algorithm is proposed based on information entropy and gradient factor. Firstly, the information entropy and the gradient factor for the image are fitted as weight factors, and the priority calculation method is optimized to find the optimal inpainting block. Secondly, the information entropy which can measure the complexity of the pixel block is used to adjust the search area of the matching block to establish a dynamic rule of the search area. Then, an adaptive model of the template size for the matching block is established with the help of the gradient factor to improve the optimal matching block search strategy. Finally, the sequential similarity detection algorithm is introduced to select the optimal matching block from the source region to achieve image inpainting. The experimental results show that compared with the traditional Criminisi algorithm, the proposed algorithm is effective both at the objective level and the subjective level. Moreover, the effectiveness of the image inpainting is more real, and the restored image has better visual effects.
Aiming at the problem that the local blur of the image is not easy to measure and the fusion strategy is difficult to designed in traditional multi-focus image fusion, a new phase stretching kernel function is developed, which results in a multi-focus image fusion algorithm based on extended phase stretch transformation. The method promotes the traditional linear or sublinear group delay phase filter to the nonlinear group delay phase filter. It is proved theoretically that the phase of the inverse transformation of the extended phase stretch transformation is approximate to the normalized two-step degree of the original image. The traditional gradient extremum expression of image high-frequency features is transformed into angle or phase expression, and a fusion strategy based on local phase variance measurement of extended phase stretching transform is designed to overcome the shortcomings of current fusion methods by using the good difference between clear and fuzzy images. Many multi focus image data in Lytro dataset are fused using MATLAB software platform. The results are compared with those of traditional fusion algorithms based on discrete wavelet transformation, Laplace Laplacian, super-resolution, guided filtering, and joint convolution self-coding network algorithm. The results show that the fusion image of this algorithm is obviously better than the traditional best fusion algorithm, and the mutual information, information entropy, spatial frequency, average gradient and structural similarity of the fused image are improved by more than 5% compared with other existing methods, which proves the superiority and practicability of the proposed algorithm.
To improve the accuracy of airlight estimation in polarization dehazing methods, a method for haze image reconstruction based on polarization layering and analysis of airlight is proposed. In the polarization space, the gradient prior information of the airlight is used as a constraint condition, and the original polarized hazy image is layered to estimate the polarized image of the airlight. This allows the analysis of the airlight from the polarized images, and the polarization layering and analysis of the airlight can be realized. Finally, by combining the proposed polarization reconstruction model of haze images and the estimation of atmospheric light at infinity in airlight images, a clear haze-free image is reconstructed. The experimental results show that the proposed method improves the accuracy of airlight estimation, provides a clearer reconstructed image, and provides a higher target restoration degree. The proposed method is suitable for haze image reconstruction under different concentrations.
In the air-to-ground environment, the imaging perspective is single, and it is necessary to rely on deep network to provide stronger feature representation capabilities. Aiming at the problems of large amount of calculation and slow convergence speed brought by deep network. Under the framework of densely connected network (DenseNet), a target detection network model expressed by channel differentiation is proposed. First, this article uses DenseNet as a feature extraction network, and uses fewer parameters to deepen the network to improve the ability to extract objects. Second, channel attention mechanism is introduced to make the network pay more attention to the effective feature channels in the feature layer and readjust the feature map. Finally, a comparative experiment is carried out by using the air-to-ground object detection data. The results show that the mean average precision of the improved model is 3.44 percentage points higher than that of single shot multibox detection algorithm based on visual geometry group (VGG16).
Aiming at the problems of blurred edge details and loss of image features in the process of image super-resolution reconstruction, a super-resolution reconstruction algorithm based on dense connection generative adversarial network is proposed. This algorithm consists of a generative network and a discriminative network. In the generative network structure, the original low-resolution image is used as the input of the network. In order to make full use of the features, the features of the shallow network are transferred to each layer of the deep network structure using dense connection, so as to effectively avoid the loss of image features. Sub-pixel convolution is performed at the end, and the image is deconvolved to complete the final super-resolution reconstruction of the image, which greatly reduces the training time. In the discriminative network structure, 6 convolutional modules and a fully connected layer are used to identify true and false images, and the idea of adversarial games is used to improve the quality of reconstructed images. Experimental results show that the proposed algorithm has greatly improved the visual effect assessment, peak signal to noise ratio value, structural similarity value, time-consuming, and indicators. It has restored richer image detail information and achieved better visual effects and comprehensive characteristic.
We propose a microvideo multilabel learning model based on a multiview low-rank representation, which combines the low-rank representation and multilabel learning into a unified framework and uses the consistency in different features to learn an intrinsically robust low-rank representation. Meanwhile, to represent the potential label correlations, our proposed model constructs a label correlation learning term to adaptively capture the labels’ correlation matrix. Furthermore, the supervised information is exploited to further improve the representation ability of our model. Extensive experiments on a large-scale public dataset show the effectiveness of the proposed scheme.
To accurately measure the crack size on the surface of nuclear fuel rods in a complex underwater environment, a method based on linear structured light is proposed. First, a two-dimensional grayscale search is performed on the acquired image to select the area to be processed, and then to further determine the crack area by horizontal projection and first-order differentiation. Then, threshold division of the crack area is performed to reduce the range of this area, and the upper and lower boundaries of crack are determined using the seed point judgment method. Finally, the least squares method is used to fit the centerline of structured light, the intersection point calculated by the centerline equation and the crack boundary point set is used to determine the specific location of crack, and then, the crack boundary point is converted into three-dimensional coordinates for distance sampling to calculate the actual size of the crack. Experiments demonstrate that the proposed method can accurately and quickly measure the crack size of a fuel rod with an error within 0.03mm, making this method appealing and convenient.
Traditional image segmentation algorithms have disadvantages such as single description of image feature information and poor segmentation effect. Therefore, a dual feature Markov random field (MRF) image segmentation method is proposed. First, the spatial information between pixels is used to constrain the prior and posterior probabilities of the Gaussian mixture model (GMM) to establish a grayscale random field. Second, on the basis of non-linearly preserving the edge contours and texture details of the image by the fractional differential operator, a grayscale co-occurrence matrix is used to describe the texture feature information of the image and establish a random field of texture features. Finally, a dual feature Markov random field for image segmentation is designed, and the conditional iterative algorithm is used to optimize the maximum posterior probability of the labeled field to achieve image segmentation. Experiments verify the effectiveness of the segmentation algorithm and the segmentation accuracy is 93.9%. The proposed dual feature random field can improve the robustness and accuracy of the image segmentation algorithm.
In the process of Dunhuang mural restoration, dictionary initialized random selection falls into local optimum easily and only the color Euclidean distance is used as the standard for image block grouping, which leads to the problems such as structure blur and line discontinuity after image restoration. An algorithm for Dunhuang mural inpainting based on Gabor transform and group sparse representation is proposed in this paper. First, the similar structure group is established using mutual information as the criterion of image block grouping, which makes group sparse representation more reasonable. Second, the Gabor wavelet transform is used to extract the feature information of similar structure groups, and the feature dictionary of the structure group is initialized by means of PCA dimension reduction, which can avoid the disadvantage of dictionary initialized random selection. Finally, the SVD decomposition and the split Bregman iteration method are used to learn the structure group dictionary and the sparse coefficients to complete the mural image restoration. The experimental results show that, compared with the other algorithms, the algorithm proposed in this paper has achieved good subjective and objective restoration effects.
There are many algorithms for behavior detection in different datasets, but there is a little lack of algorithms for student behavior detection in classroom. In order to achieve better accuracy and real-time of student behavior detection, this paper improves the network structure based on MTCNN, and proposes a new activation function and a loss function to detect student images and landmark localization. Meanwhile, this paper proposes the strategy of joint classification of student behaviors through the image classification network and the landmark localization classification network. The experimental results show that the proposed improvement actions effectively improve the accuracy of student behavior detection and the final detection accuracy of the model is 78.6%. On the embedded development board of Jetson TX2, the proposed algorithm has the real-time detection accuracy and speed superior to those of the other algorithms such as YOLOv3 and SSD.
Building extraction technology in urban areas has been a hot topic in recent years, but how to accurately distinguish vegetation, buildings, and man-made objects and improve classification accuracy has always been a difficult point. Aiming at the problem of low classification accuracy, we propose a point cloud classification algorithm based on random forest. First, the improved cloth filtering algorithm is used to perform ground filtering on the point cloud data. And a decision tree is constructed and the correlation analysis based on the largest mutual information coefficient is performed to select the decision tree with the smallest correlation coefficient and the highest accuracy to obtain a weakly correlated random forest model. The decision results are processed by weighted voting, and finally a point cloud classification algorithm combining cloth filtering and weighted weakly correlated random forest is obtained. Compared with the traditional random forest classification algorithm, the algorithm is verified by the Vaihingen urban dataset, and the classification accuracy is improved by 4.2%.
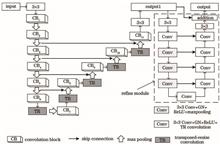
Owing to the continuing decrement in the pixels of the images, the signal output of the digital imaging sensor is increasingly sensitive to photon noise, making the photon noise the main source of noise in the digital image sensor. To address this issue, an image denoising algorithm based on asymmetric convolutional neural networks is proposed herein. To enhance the generalization ability of the model, the network framework is divided into two parts: noise evaluation network and denoising network. To reduce the semantic gap between the network feature mapping in the encoder and the decoder, the skip connection in the denoising network is improved to make the features more similar in semantics to facilitate task optimization. From the qualitative and quantitative aspects of comparative experiments, the experimental results show that the proposed network model exhibits better denoising performance.
In this paper, we propose a method of forgery numeral handwriting detection based on convolution neural network (CNN). It provides an intelligent solution for forgery document detection. The experiment convened 50 volunteers and collected image samples of six types of forged handwritings and normal handwriting with 50 different brand pens, and established a total of more than 7200 sample data. Then, we designed a new CNN for forgery numeral handwriting detection called FNNet by introducing Fire Module structure based on AlexNet. We replaced the partial 3×3 convolution kernel with 1×1 convolution kernel and performed convolution layer assembly to detect forged samples. The experimental results show that the average test accuracy of FNNet in the six types of handwritten forgery numbers is 98.36%, which is 3.01 percentage higher than that of AlexNet. The proposed method is superior to traditional feature classifiers; it provides a new method for forged handwriting detection.
A method to combine nonlinear correlation information entropy (NCIE) and multi-resolution representation is proposed for synthetic aperture radar (SAR) target recognition. NCIE is employed to select the multi-resolution representation of an original SAR image, and several resolutions with strong intrinsic correlation are obtained. Then, the joint sparse representation is used to characterize and classify the selected multi-resolution samples simultaneously. Experiments are conducted in which various operating conditions are employed to test the different methods based on the MSTAR dataset. The experimental results demonstrate the validity of the proposed method.
In this paper, to achieve accurate automatic classification of breast cancer histopathological images, an improved convolutional neural network is proposed, and two different convolutional structures are introduced in order to improve the accuracy of histopathological image recognition by the network. Based on using deep residual network (ResNeXt) as basic network, octave convolution (OctConv) is used to replace the traditional convolutional layer to reduce the redundant features in the feature map during feature extraction stage and improve the effect of detailed feature extraction. Heterogeneous convolution (HetConv) is introduced to replace part of the traditional convolutional layers in the network, reducing model training parameters. To overcome the problem of over-fitting due to the small number of data samples, an effective data enhancement method based on the idea of image block is adopted. The experimental results demonstrate that the accuracy of the network on the four classification tasks of the network at the image level reaches 91.25%, indicating that the designed network model has a higher recognition rate and a better real-time performance.
When background fluctuates in the image, the target tracking process will follow the fluctuation of background with corrected background-weighted histogram (CBWH) algorithm, which will cause fluctuation-errors. In order to improve the tracking effect under fluctuant background and reduce the fluctuation-errors, this paper proposes a background gradient corrected histogram (BGCH) algorithm based on CBWH algorithm. It uses the background gradient information of adjacent frames to perform a second-order correction on the target model, and blocks the fluctuation-following process of the CBWH algorithm in advance. Experimental results show that this method significantly reduces the fluctuation-errors of CBWH algorithm, and also shows better robustness under the condition of target deforming and blurring.
Various forms of cracks can easily occur during the construction and use of concrete structures, leading to many security problems. The traditional manual safety detection method not only consumes financial resources and time but also provides no guarantee of accuracy. To improve the efficiency of crack recognition on a concrete surface, a recognition method based on convolutional neural network combined with clustering segmentation is proposed herein, which achieves accurate recognition of concrete surface crack images under more complex backgrounds. Results show that the proposed method can not only efficiently classify but also identify cracks in more complex backgrounds with high accuracy. In addition, the proposed method provides a certain theoretical basis for the workload reduce of crack recognition on concrete surfaces, as well as the maintenance and safety inspection of concrete structures. Furthermore, the proposed method provides references for future fracture-identification studies under higher accuracy and more complex conditions.
The reconstructed images of biological samples display uneven gray distribution and low contrast, since the synchrotron radiation light source possesses Gaussian distribution characteristics. Moreover, the reconstructed images are also affected by background noise, causing difficulty in observing and analyzing various details of reconstructed images of the biological samples. In order to address this situation, a synchrotron radiation CT image contrast enhancement method, based on image reconstruction, is proposed in this paper. First, the filtered back projection (FBP) reconstruction algorithm and simultaneous algebra reconstruction technique (SART) algorithm are used to reconstruct the image respectively, and the reconstructed numerical range of the two algorithms is obtained; then, the numerical interval reconstructed by the FBP algorithm is mapped to the numerical interval reconstructed by the SART. Finally, the image reconstructed by mapping is combined with a content-adaptive image enhancement algorithm to improve the reconstructed image quality. The experimental results demonstrate that the proposed algorithm can not only effectively eliminate the background noise, but also improve the contrast of the reconstructed image; therefore, allowing for more optimal visualization of the details in the reconstructed samples.
Determination of the sequence of intersecting lines has always been one of the difficult problems in the field of forensic science document inspection. Considering this, we first use a new technology for optical tomography, specifically optical coherence tomography (OCT), to study the sequence of intersecting lines. A frequency-domain OCT system with a center wavelength of 900nm is used to perform imaging and inspection on three different types of intersecting lines samples, to compare the feature differences of 2D tomographic OCT images of the intersecting lines of different types of samples and to analyze the feature differences. Preliminary experimental results show that OCT technology can provide an effective method for the judgment of the sequence of intersecting lines and can lay a foundation for supplementing and enriching the existing ecosystem of measurement techniques.
The memory-effect based speckle deconvolution technique is a method recently proposed to realize imaging through scattering layers. There exist many algorithms used in speckle deconvolution, but there seldom exists specific comparative analysis work so far. A system for memory-effect based imaging through scattering layers is first designed and built. Then the detected speckles are deconvoluted to reconstruct the object image. During the progress of reconstruction, the cross-correlation deconvolution algorithm, the Wiener filtering algorithm, the regularized deconvolution algorithm and the Lucy-Richardson algorithm are respectively used for deconvolution. A number of image quality evaluation indexes are calculated for the images recovered by different algorithms. Considering the image quality and the computation time, it is concluded that the cross-correlation deconvolution algorithm has the greatest advantage in the application of imaging through scattering layers, which is briefly explained in principle.
In order to solve the problem about the loss of detail information of difference maps in the change detection of synthetic aperture radar (SAR) images, a deblurring processing method for the pixel level change detection of SAR images is proposed. Based on the theoretical analysis of the distribution of pixels missed from the difference map, a new method for constructing the difference map is proposed. The difference map generated by this proposed algorithm is fused with the difference map generated by the classical pixel-level change detection algorithm to realize the edge deblurring of the difference map. Taking the average ratio algorithm as an example, the experimental results show that the difference information obtained by the proposed algorithm and that by the neighborhood change detection algorithm are highly complementary. The difference map generated from deblurring by the proposed algorithm is subjectively closer to the change of the real ground object. Objectively, the numbers of the missed points of change detection results are reduced, and the accuracy of change detection is improved.
Fourier ptychographic microscopy (FPM) is a newly developed imaging technology, which is capable of reconstructing images with a wide field of view and high resolution. However, the reconstruction based on traditional reconstruction algorithms has high calculation cost, large amount of image acquisition, and low efficiency. Therefore, we propose a deep learning-based neural network model of FPM that performs end-to-end mapping from low-resolution to high-resolution to effectively improve imaging performance and efficiency. First, the diamond sampling method is used to speed up the process of image acquisition. Second, the combination of residual structure, dense connection, and channel attention mechanism is used to expand the network depth, mine useful features, and enhance the expression and generalization ability of the network model. Then, sub-pixel convolution is used for efficient upsampling and restoring high-resolution images. Finally, subjective and objective evaluation methods are used to evaluate the reconstruction results. The results show that, compared with the traditional reconstruction algorithm, the proposed network model has better reconstruction effect, lower computational complexity, and shorter average reconstruction time. At the same time, the number of low-resolution images is reduced by about half compared with the traditional algorithm.
In this study, a method is proposed to obtain the three-dimensional attitude information of carriers based on the atmospheric polarization pattern to meet the urgent need of obtaining attitude parameters for ensuring the autonomous navigation of unmanned aerial vehicles. Initially, the atmospheric polarization mode is completely analyzed. Then, the K-means clustering algorithm is used to calculate the position of sun in space. Finally, the angle between the magnetic compass and the carrier body is used to obtain the heading information of the carrier. The navigation coordinates are transformed into a reference based on the known heading angle. First, the zenith and sun are observed to be on the same axis; thus, the zenith and sun position vectors are on the same reference and rotate together. Then, the pitch and roll angles are calculated according to the inherent height angle between the zenith and sun. Finally, the roll and pitch angle information are obtained through several conversions and calculations. The experimental results show that effective carrier attitude information can be obtained based on the position of the sun calculated in the atmospheric polarization mode, the accuracy of the simulation can reach 0.01°, whereas that of the field experiment can reach 0.1°.
Aiming at the problem of low recognition accuracy of small faces in classroom scene, this paper proposes a lightweight network structure (Dual-MobileFaceNet) combining channel addition and channel concatenation based on the InsightFace algorithm by integrating the MobileFaceNet and DenseNet structures, so as to improve the recognition speed and the recognition accuracy of small faces. Meanwhile, a double classification algorithm is proposed to improve the identification and classification ability of the InsightFace algorithm. The proposed algorithm achieves an accuracy of 99.46% on LFW dataset. Finally, the proposed algorithm is transplanted to Jetson TX2 embedded development board. In 8- and 18-people classrooms, the recognition accuracy of the proposed algorithm is 96.24% and 94.68%, and the recognition speed of each frame is 0.14 s and 0.29 s, respectively. Compared with other large networks, the proposed network is more realistic and efficient. The proposed algorithm provides an effective concept for the classroom face recognition and non perception attendance system.
In order to realize efficient inspection of laser welding quality, this paper introduces linear array image sensing to address online inspection, and proposes a fast inspection method of weld defect based on deep learning. First, aiming at the laser weld defect, a deep learning network based on Yolo (You only look once) is optimized. Then, an appropriate anchor frame is added to the experimental data set to improve the accuracy of detection frame positioning information, and multi-scale feature fusion technology is used to improve the accuracy of defect recognition, Finally, the data set is made and a data set preprocessing method is proposed to train the network, which improves the recognition effect of defects. Experimental results show that the total recognition rate of single hole, perforation and groove defect is more than 94%, and the detection time of single workpiece image with size of 4096pixel×4000pixel is 0.97s, which is significantly faster than traditional ultrasonic and radiographic image detection methods.
For the shortcoming of the real-time performance of YOLOv3 algorithm in object detection, we propose an improved network structure and a new method for video object detection adapted to real-time object detection. Firstly, the proposed k-means-threshold (k-thresh) method makes up for the problem of its sensitivities to the initial position of the cluster center, and performs cluster analysis on a data set including three categories to select more appropriate anchor boxes. Then, the 4×down-sampling and 8×down-sampling feature maps are stitched together into the third layer detection layer to improve the detection accuracy of the object and increase the the mean average precision of the YOLOv3 algorithm by 2%. Finally, the camera captures the image and the excellent detection data obtained in the previous period to predict the target of the new image and adds a re-detection threshold to improve the smoothness of video detection. The experimental results show that the proposed improved YOLOv3 network improves the detection accuracy and the real-time performance, the maximum frame rate reaches 64.26 frame/s in 30 min of real-time detection, which is 4 times faster than the original YOLOv3 algorithm.
Although the face recognition model based on the deep convolutional neural network can achieve high recognition accuracy, there are massive calculations in the model and a large amount of memory resources are required, which cannot meet the resource constraints and real-time requirements. To solve this problem, two lightweight recursive residual neural networks are designed, which can effectively fuse the information between the layers in the feature map, enrich the semantic information of the feature map and improve the recognition accuracy. First, the MTCNN face detection algorithm is used to face alignment and cropping on the original data set. Then, the ArcFace loss function is used as the supervision signal, this loss function can make the data set aggregation and inter-class dispersion, effectively improve the classification effect of the model. Finally, the model is verified on the LFW, AgeDB and CFP-FP datasets. Experimental results show that the designed network model can achieve high face recognition accuracy while reducing a large number of parameters.
The tracking algorithm based on deep-level siamese network generally lacks the capability to update the target template online; hence, it exhibits poor adaptability in some complex application environments. Aiming to resolve this problem, a target template online-updating algorithm based on optical flow mapping is proposed herein. On the premise of ensuring real-time operation, the proposed algorithm can efficiently improve its adaptability in complex circumstances. First, the optical-flow information between the template frames is calculated in the tracking process. Then, the information of motion change is generated via optical flow mapping and residual calculation. Furthermore, based on singular value decomposition, a method that creates a correction term via the initial frame, which modifies the target-position deviation, is proposed herein. Finally, the proposed algorithm is tested on OTB100 and VOT2016 datasets. The results show that the proposed algorithm can optimize the new target template to enhance the robustness and can achieve the best results compared with existing tracking algorithms.
In order to meet the requirements of measuring high-velocity moving dim small targets, a velocity measurement method based on single-frame multiple local exposures is designed. The influence of key parameters on measurement frequency is analyzed theoretically, and the expression of gray imaging model of laser illuminated target is deduced. Using pulsed laser as local exposure light source and timing base, the target image with time stamp is generated in a single-frame image for many times. A velocity measurement model of single-frame multiple local exposures is established, and the spatial positioning and velocity measurement of small dark targets are realized by using monocular vision and laser ranging data, which breaks the upper limit of the measurement frequency of high-velocity camera and improves the measurement accuracy. Velocity measurement simulation experiment is carried out on a target with a velocity of 1500m/s, and the results showed that the velocity measurement error is less than 0.7%. The prototype experiment proves that the relative velocity error of target is less than 2.5% compared with the velocity of standard velocity target launcher in low velocity conditions, and the system has low cost and good maneuverability, which meets the requirements of engineering precision.
When using simple linear iterative clustering (SLIC) algorithm for super-pixel segmentation of remote sensing images, there are problems of long running time and poor edge fitting. Therefore, a super-pixel segmentation algorithm of remote sensing image based on improved SLIC is proposed in this paper. First, the initialization method of initial seed points is improved to eliminate the influence of random distribution. Second, after each iteration, a filtering operation is introduced to remove pixels in the super-pixel that are significantly different from the clustering center in color space, and the clustering center is updated with the remaining pixel points. Finally, the super-pixel segmentation is realized by iteration with the improved mean value calculation formula. The experimental results in the Python environment show that in the case of the same number of super pixels, compared with classic SLIC algorithm, this algorithm reduces the segmentation error rate by 7.4%, improves the segmentation accuracy by 1.4%. It can effectively improve the fit of the edge contour and reduce the computational complexity of the algorithm.
Tumors are a major disease that seriously threaten the life and health of Chinese residents. Existing tumor diagnosis methods heavily rely on the subjective experience of doctors and include many issues, such as prolonged diagnosis, severe trauma, and high misdiagnosis rate. Therefore, it is crucial to develop a tumor diagnosis technology with intelligent properties to improve the level of diagnosing tumors in China. Raman spectroscopy is a label-free optical technique used for diagnosing benign and malignant tumors, classifying tumor subtypes, pathological diagnosis of biopsy, and in situ near-real-time imaging. Moreover, Raman spectroscopy combined with artificial intelligence has led to an intelligent diagnostic method. In this paper, the research progress of Raman spectroscopy for diagnosing various tumor types over the past three years was reviewed. Furthermore, three main aspects of the conventional Raman spectrum, Raman imaging, and probe diagnoses combined with the spectrum were introduced, and the prospect of Raman spectroscopy in the diagnosis of tumors in the future was discussed.
In the big data era, we have witnessed the explosive growth of deep learning based image and video compression technologies. Such end-to-end learning-based compression frameworks have demonstrated promising efficiency for compact representation of original image data, and attracted a vast attention from both academia and industry. A systematic review of transformation, quantization, entropy coding, and loss function used in end-to-end learning-based image compression framework is introduced in this work. The research progress and key technologies are briefly introduced, as well as the comparative studies of coding performance for existing methods with leading efficiency.
With the continuous improvement of the convenience of image acquisition and transmission and the rapid popularization of image editing tools, a malicious users can easily shoot, spread, edit and modify digital images to achieve the purpose of malicious behavior or crime. It becomes the key evidence for investigation and collection of evidence and judicial proceedings. The illumination response inconsistency (PRNU) causes by the defects of the image sensor manufacturing process and the unevenness of the silicon wafer is unique and stable for each camera, so it can be used as an effective device fingerprint for image source forensics. First, a comprehensive review of digital image forensics technologies including device fingerprint technology is conducted, and the main application scenarios of device fingerprints are introduced. Then, the basic technical principles of device fingerprint extraction in images is introduced, and the development of device fingerprint extraction technology is summarized. Finally, the problems to be solved and the technology development trend of the device fingerprint extraction technology are discussed.
To explore the influences of different spectral preprocessing methods on the terahertz (THz) spectrum, preprocessing methods such as smoothing, multivariate scattering correction, baseline correction and normalization, and combination of multiple scattering correction and normalization are used. In order to optimize the model and reduce the computation amount, principle component analysis is used to compress the THz spectrum to reduce data dimension. The backpropagation neural network (BPNN) and generalized regression neural network (GRNN) detection models are established based on the compressed data. Experimental results show that the effect of the GRNN model with multiple scattering correction and normalization correction is the best. The predicted correlation coefficient is 0.9967 and the predicted root mean square error is 0.0050. This experiment verifies the feasibility of the THz spectrum detection technology for the detection of the melamine in milk powder, and establishes a better GRNN detection model for melamine adulterated milk powder samples. This study is of great significance to promote the healthy development of milk powder industry.