









Please enter the answer below before you can view the full text.
8-5=

In this study, we attempt to use deep learning and object-oriented methods to deal with very-high-resolution visible images obtained from an unmanned aerial vehicle (UAV) for achieving high-precision classification of the forest tree species. First, we use the optimal-scale object-oriented method to segment the images obtained from the UAV. The random forest (RF) method is used to classify the tree species for extracting the feature variables. In addition, the classification variables are sorted based on their importance and significance. Further, the most important feature variables with respect to the classification, including the visible light difference vegetation index (VDVI) and the over-green to over-red reduction index (ExG-ExR), are selected. Subsequently, new data are generated by combining two characteristic variables and the original RGB band of the UAV images. Based on the new data and the original RGB band data are both used to classify tree species by the full convolutional neural network (FCN) method based on the Res-U-Net model. Then, the classification result accuracies in the aforementioned cases are evaluated and compared. Finally, the object-oriented segmentation method is used to correct the optimal tree species classification results. The experimental results denote that FCN with respect to VDVI and ExG-ExR exhibits the best classification effect in case of the original images of the tree species obtained via UAVs. The total accuracy is 97.8%, and the Kappa coefficient is 0.970. RF methoed can effectively screen out the classification feature variables. The addition of characteristic variables to the original image can effectively improve the classification accuracy of the FCN method. Finally, the best classification result is obtained using object-oriented segmentation, resulting in the elimination of the salt and pepper phenomenon and the attenuation of the edge effect. The total accuracy improves by 0.9 percentage points and the Kappa coefficient increases by 0.013.
To satisfactorily detect the defects and topography of the inner wall of a cylindrical workpiece, this paper proposes a panoramic imaging method based on depth learning and machine vision. Through zoom imaging, this method obtains a multi-focus image sequence of the inner wall of a cylindrical workpiece, and uses a multi-focus image fusion algorithm based on convolution neural network to fuse the inner wall image sequences collected at different depths of field to get a fully focused panoramic view of inner wall. Based on perspective transformation principle of visual imaging, the inverse mapping panoramic mapping is used to improve the inner wall topography reconstruction method and obtain the inner wall topography image of the cylindrical workpiece under a cylindrical coordinate system. Experimental results show that the proposed topography reconstruction method can effectively detect the state of the inner wall, and the imaging quality is optimal.
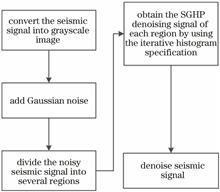
Random noise may accompany the acquisition of seismic signals, and some denoising algorithms can smoothen some of the details in seismic signals, which will result in reduction in seismic data accuracy. In this study, a seismic signal denoising algorithm based on region segmentation gradient histogram preservation (SGHP) is proposed. The proposed algorithm first divides the seismic noise signal into several regions, then estimates the reference gradient histogram for each region. Finally, each region is denoised using gradient histogram preservation so that the gradient distribution of the denoised seismic signal is as close as possible to that of the original signal, achieving the purpose of protecting the details of the seismic signal. SGHP is used to denoise the synthesized seismic signals and post-stack land seismic signals, and is compared with non-local mean filtering (NLM), block matching 3D (BM3D) cooperative filtering, and clustering sparse representation (CSR) algorithms for denoising effect through evaluation indicators such as peak signal to noise ratio and structural similarities. Results show that SGHP has an optimal denoising effect.
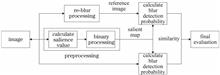
To solve the problem of lack of human visual characteristics in the non-reference blur image quality assessment. This paper proposes a blur image quality assessment method based on blur detection probability variation. This algorithm firstly preprocesses the image, uses the improved adaptive method to calculate the specific salient threshold of blurred image and binarizes the image with a specific threshold to obtain the final salient region of the image. Then, the image quality is described by the blur detection probability variation of the salient regions of the two images after re-blurring. The larger the change, the clearer the image quality. Experimental results show that the proposed algorithm achieves better experimental results in the LIVE data set and has better evaluation performance than the existing traditional algorithms. At the same time, the proposed algorithm can also be used in the field of wisdom mine and so on.
For the stitching of quantum images, the Harris algorithm needs to artificially set the threshold and the local similarity of the image is high, which leads to the high mismatch rate. The quantum image stitching algorithm based on improved Harris and the quadratic normalized cross correlation (NCC) is proposed. In terms of threshold setting, based on the fact that the image repeatability is high, the number of quantum dots or rings of the statistical image sub-region is determined by binarization and threshold reduction to determine the Harris threshold,and as a full-image threshold. In terms of mismatching, the NCC matching is first performed in a small window, and the corner points are initially screened. Then the second NCC is performed on the result with a large window to reduce the mismatch rate. Experimental results show that the proposed algorithm has better accuracy and speed in quantum dot or ring counting. In terms of threshold setting, the proposed algorithm controls the number of corner points within a reasonable range. In the matching stage, the quadratic NCC method reduces the mismatch rate to 4.82%-27.27%. Therefore, the proposed algorithm optimizes the reliability and time overhead of quantum image stitching, and has potential application value in quantum image stitching.
This paper proposes a human body detection method based on deep learning and depth of field information. The deep learning method is used for target detection and the depth of field information of the depth map is used to determine the position of the human body, and then the two works are combined to accurately locate the human body. In this method, the RGB image and the corresponding depth map are acquired by the depth camera, and the RGB image is detected by the darknet-yolo-v3. The obtained target bounding box is preprocessed and transmitted to the corresponding depth map of the RGB image, which processes the depth of field information adopting the active contour without edges model and get the aim of combing deep learning with high rate of recognition and depth of field information to accurately locate the target. The experimental results show that this method can accurately find a target positioning point that is not affected by the logo box, effectively improve the problem of increasing the mark box error caused by the different attitude and action amplitude of the human body, improve the accuracy of the detection of human body, and provide a guarantee for further study of pedestrian accurate tracking.
Aiming at the problems that non-rigid registration of layered B-spline exists local extremum and the level set segmentation method is not suitable for noisy image segmentation, a joint segmentation and registration of medical image based on locally updated hierarchical B-spline bidirectional transformation and level set method is proposed. The proposed method adds a registration transformation to the segmentation algorithm, and the structure information of image segmentation is incorporated into the registration. The B-spline level set function is used to smooth the transformed and segmented image, and a two-way transformation is introduced in the registration to improve the accuracy and smoothness of the registration. Based on the level set method, the bi-directional layered B-spline transform is introduced to construct the joint energy functional of segmentation and registration, and the gradient descent method is used to minimize the energy functional to optimize the objective function. Experimental results show that the Dice metric is always above 99% and the mean square error is reduced by 30% compared with the single image segmentation method. The proposed method improves the registration accuracy and has better robustness in noise image segmentation.
The development of convolutional neural networks has greatly promoted the advancement of facial expression recognition technology. In order to solve the problem that the accuracy of image recognition in practical applications is limited by image pixels, the expression recognition of low pixel face image is studied from three aspects. First, according to the characteristics of low pixels and complex features of the research object, an improved convolutional neural network is proposed. Second, after performing basic pre-processing on the image, image enhancement processing is added as an input to improve the convolutional neural network mode. Finally, the output results of the model are subjected to decision fusion to obtain the final recognition result. Experimental results show that this method has achieved good results on the CK+ source dataset, and has high recognition accuracy, stable results, and strong generalization ability.
Aiming at the problem of the low accuracy of the Faster R-CNN algorithm in object detection, the data is enhanced first. Then, the extracted feature map is trimmed, and bilinear interpolation is used to replace the region of interest pooling operation. Soft-non-maximum suppression (Soft-NMS) algorithm is used for classification. Experimental results show that the accuracy of the algorithm is 76.40% and 81.20% in PASCAL VOC2007 and PASCAL VOC07+12 datasets, which is 6.50 percentage points and 8.00 percentage points higher than that of the Fast R-CNN algorithm, respectively. Without data enhancement, the accuracy on the COCO 2014 dataset is improved by 2.40 percentage points compared with that of the Faster R-CNN algorithm.
Based on the YOLOv2 algorithm, the YOLOv2-voc network structure is improved according to the actual road-scene change. The classification training model is obtained based on ImageNet data and fine-tuning technology and in accordance with the analysis of the training results and target vehicle characteristics. Consequently, the improved vehicle identification classification network structure YOLOv2-voc_mul is obtained. Using samples from simple and complex backgrounds, experiments are conducted to verify the validity of the detection method. Further, the proposed model is compared with the YOLOv2, YOLOv2-voc, and YOLOv3 models after 70000 iterations. Results show that under simple background, the improved YOLOv2-voc_mul model has an accuracy of 99.20% and the mean average precision of different models achieves 89.03%. Under complex background, the improved YOLOv2-voc_mul model has average accuracies of 92.21% and 89.44% for the single- and multi-target detection of four different models, respectively. The proposed model shows excellent accuracy, small false detection rate, and good robustness.
Herein, a face recognition algorithm based on an adaptive weighted Curvelet gradient direction histogram is proposed. First, the Curvelet transform based Wrapping is used to extract facial features with multi-orientations, and the coding method is exploited to fuse the original Curvelet features that have the same scale. Second, the fused image is divided into numerous equal-sized non-overlapping rectangular blocks. The face image is then described using the histogram sequence extracted from all the blocks using the HOG operator, and the adaptive weighting of histograms with each scale is separately performed. Finally, the extracted features are fed into the nearest neighbor-based classifier. Results of the simulation experiments conducted using the ORL, YALE, and CAS-PEAL face databases show that the proposed algorithm has a high face recognition rate and good robustness under the influence of interference factors such as face occlusion, gesture transformation, expression transformation, and illumination transformation.
To achieve automatic inspection and reading capabilities of pointer-type meters in robot as the traditional method extracting the position of start and end lines on the pointer meter is not sufficiently accurate, this study proposes a new type of meter reading algorithm, solving the problem for the need of the start and end lines to be preset in advance. The traditional Hough line recognition algorithm deviates from the center line of the pointer, thereby improving the accuracy of system reading. As the reliability of the reading result cannot be assessed using the existing method, this study establishes an instrument for a reliable reading estimation model based on consistent significance. A clustering algorithm is used to achieve a consistent and significant correlation constraint detection of instrument features, which can estimate the reliability of meter readings. The experimental results show that the accuracy of the proposed instrument reading algorithm is high and that the estimated model created is stable and reliable.
Aiming at classification of carbon fiber reinforced polymer (CFRP) defect types, an ultrasonic one-dimensional convolutional neural network (U-1DCNN) is proposed and the Bayesian optimization algorithm is used to optimize hyperparameters. By automatically extracting the features of ultrasonic A-Scan signals, three defect types, i.e., delamination, gas cavity, and non-defect, are automatically distinguished. First, a dataset is constructed by collecting ultrasonic A-Scan signals. Then, multi-convolutional blocks are used to simultaneously extract as well as enhance the diversity of extracted features. Subsequently, one-dimensional residual units are stacked and connected, simplifying the training of the network while further extracting the features. The learning rate and momentum parameter of stochastic gradient descent of the network are optimized by Bayesian optimization algorithm. Finally, nonlinear mapping of the A-Scan signals and defects is realized. Experiment results show that U-1DCNN can recognize CFRP defects by automatically extracting features, with the accuracy reaching 99.50%.The recognition speed of U-1DCNN is faster than the two-dimensional CNN method, which is advantageous for defect detection.
Herein, a classification method based on an improved deep convolutional neural network is proposed to address the problem that the artificial classification of bobbins is time-consuming, labor-intensive, and not sufficiently intelligent in the actual production of textile mills. First, the original network structure was improved based on the AlexNet neural network model framework. All convolutional layers used 3×3 size convolution kernels and multiple convolution kernels in series to extract more abstract features of objects. Next, we reintegrated the sliding average, conduct L2 regularization, and used other tricks to improve the generalization ability. Moreover, the L_ReLU activation function was used to avoid the “death” phenomenon of some neurons. Consequently, the test samples were input into the trained neural network to achieve the classification of bobbins. Experimental results show that the recognition rate of the method is 88.2%, which is approximately 15 percentage points higher than that by the traditional classification method. Compared with other neural network models, the proposed method demonstrates the advantages of high recognition rate and short time, which complies with the actual industrial requirements.
A flame image detection method is proposed based on convolutional neural network using serial feature fusion model with maximal relevance and minimal redundancy (MRMR) to address the issue that the flame recognition model based on shallow features is susceptible to environmental changes and has low robustness. First, to obtain more global features from the finite sample set training convolutional neural network, the pre-training method was used to extract the deep features from the flame image for serial fusion. Then, to solve the problem of high dimensions of fusion feature, large redundancy, and lack of dynamic features after fusion, the MRMR feature-selection algorithm was used to remove features with low relevance to the flame, obtain highly relevant serial features, and merge with dynamic features to obtain a superior subset of the reconstructed feature vector. Finally, the flame target was detected using the support vector machine classifier. Experimental results show that the proposed method has good generalization ability and flame detection capability.
We propose an improved Poisson reconstruction algorithm based on a vector field and an isosurface to improve the precision and accuracy associated with point cloud surface reconstruction. The proposed algorithm intends to solve the following problems: the Poisson reconstruction algorithm misconnects the empty regions and different normal directions cause the deviation of the reconstruction results. Initially, a statistical filter was used to denoise the noisy point cloud data. Subsequently, the weighted principal component analysis method was used to estimate the normal direction, and the moving least squares (MLS) method was used to calculate and optimize the measurement error associated with the point cloud normal. Further, OpenMP was used for accelerating the proposed method. Finally, the improved dual contouring algorithm was used for extracting the isosurface to eliminate the problems of surface empty regions and misconnected surface features. The experimental results demonstrate that the improved Poisson algorithm can effectively eliminate the possible empty regions and pseudo-enclosed surfaces in the model and improve the accuracy as well as efficiency of the surface reconstruction.
Remote sensing images have a large number of semantic objects, and the visual differences of the same semantic objects are large. Aiming at the problem that the global features extracted by convolutional neural network (CNN) cannot accurately describe the image content, a remote sensing image retrieval method based on regional attention mechanism is proposed. First, the fully connected layer of the CNN is removed, and the deep features are used as the input of regional attention network. Then, the CNN and regional attention network are trained respectively on remote sensing image dataset. After that, local image features with attention can be extracted. Finally, a multi-distance similarity metric matrix is constructed, and extended query is used to improve retrieval performance. Experimental results show that, compared with remote sensing image retrieval method based on global features, this method can effectively suppress the background of remote sensing images and unrelated image regions, and the retrieval performance is better on the two large remote sensing experimental data sets.
An improved image matching algorithm is proposed to solve the problems of high computational complexity and inaccurate target positioning of best-buddies similarity (BBS) image matching algorithm. According to the size of the template image, the size of image blocks is correspondingly selected to reduce the number of points in the matching point set, and then to reduce the computation of the BBS algorithm. The sub blocks are rearranged according to their gray values, and thus the BBS confidence map of is obtained. The possible location of the target is screened out from the confidence map, and the true BBS score of the possible position of the target is recalculated. The BBS score obtained by bilinear interpolation is replaced by the real BBS score of the recalculated possible location of the target. The location with the highest BBS score among the possible locations is taken as the matching result. Experimental results show that the algorithm improves the accuracy of the target positioning while reducing the running time of the BBS algorithm.
In this study, we propose a complex prior saliency target detection method to solve the problems associated with the saliency maps. These problems are as follows: the saliency maps generated via the existing saliency target detection method under single prior knowledge exhibit incomplete background suppression, isolated background block interference, and lack of foreground area. First, the superpixel segmentation algorithm was applied to extract the edge superpixels, and the primary background set was constructed. Subsequently, the background set was optimized in accordance with the significance of the boundary and the four corners. Then, we proposed the feature difference method with respect to the characteristics of the background superpixels exhibiting a low gradient. Second, a convex hull, which roughly surrounds the foreground area, was constructed and set as the center position of its centroid. Finally, three prior saliency maps were adaptively weighted to obtain the final saliency map. The proposed method was used to perform experiments on the maps obtained using the MSRA and ESSCD datasets. The obtained results prove that the proposed method can solve the aforementioned problems by fusing three types of prior knowledges. It can simultaneously reduce background suppression and obtain a saliency map with the foreground area integrity of a significant degree.
This study proposes an alternative non-local stereo matching algorithm based on color and edge information to reduce the large matching error in the texture-rich regions of the traditional non-local stereo matching algorithm. In the cost computation stage, the gray and gradient information are combined to obtain the matching cost of pixels. In the cost aggregation stage, to reduce the mismatch rate for regions with a similar background, the minimum spanning tree is used for cost aggregation, and the weight function is redefined through combination of color and edge information. Then, the winner-take-all (WTA) strategy is implemented to obtain optimal disparity, and the disparity map is refined through post-processing operations such as left-right consistency checking and median filtering. Finally, the feasibility of the proposed algorithm is verified using the Middlebury data platform. Experimental results show that compared with the traditional algorithm, the proposed algorithm reduces the average mismatch rate of the image from 6.02% to 5.10%.
The airport area has great significance to both civilian and military use because of its particularity. At the same time, the airport area detection method based on machine self-identification is the current mainstream detection method. Aiming at the problem of insufficient robustness of traditional detection algorithms to the detection of multiple categories, multiple scales, multiple perspectives, and complex backgrounds in airport remote sensing images,an improved regional convolutional neural network detection algorithm is proposed. Firstly, compared with the traditional data set, a typical target data set of 7 types of airport areas under more conditions such as scales, perspectives, categories, and complex backgrounds is constructed and optimized, which lays a foundation for the supervised training and adjustment of model algorithms. Then, according to the characteristics of the detected target and the limitations of the network, the difference value method is used to generate the anchor, the complex negative sample screening, and the prior decision network are added to optimize and simulate the original network. Finally, the optimized network model is tested and compared. Experimental results show that the proposed algorithm has higher average accuracy than the original algorithm on the basis of increasing only a small amount of detection time, and achieves better results for various types of targets.
Automatic detection of ceramic tilt surface defects is an urgent problem in the upgrading of the industry. The surface of the ceramic tile has a three-dimensional morphological structure and there are a lot of patterns, which will result in uneven illumination on the surface of the ceramic tile and cause many interferences to automatic defect detection. Therefore, this paper proposes a surface crack detection method for the ceramic tile based on multi-scale Hessian matrix filtering. First, band-pass filtering is used to suppress the background and noise of ceramic tile image and highlight the crack characteristics of the ceramic tile. Then, using the eigenvalues of the Hessian matrix, the crack similarity function of ceramic tile is constructed to enhance the crack characteristics of ceramic tile. Finally, the binarization and morphological processing methods are used to extract the crack parameter information. Experimental results show that the algorithm can effectively remove the interference from complex background, extract the complete surface cracks of the ceramic tile, and has high calculation efficiency with an accuracy rate as high as 95%.
Aiming at the influence of hardware noise and sea background clutter in the infrared images of marine targets, we analyze the noise of offshore infrared target tracking working systems based on the background of an offshore unmanned vehicle video navigation obstacle avoidance system, and design a related denoising algorithm. This algorithm completes the system modeling and improves the parameters. Then, the infrared video at sea is sampled frame by frame, and the sampled infrared image sequence is filtered. The tracking position before and after filtering is compared with the central coordinate of the target real position. Finally, the processing result of this algorithm is compared with other similar algorithms. Experimental results show that using the proposed algorithm, the tracking position after filtering basically coincides with the real position, the capture rate is higher than 98%, and the tracking error is less than 1 mrad. Compared with similar filtering algorithms, the signal-to-noise ratio is improved by 10 dB.
To solve the problems of low matching accuracy and slow convergence speed in point cloud registration, a point cloud registration algorithm based on two-dimensional (2D) image features and singular value decomposition (SVD) is proposed. First, a three-dimensional (3D) point cloud was transformed into a 2D bearing angle (BA) image and the BA image was registered using the internal-distance shape context (IDSC) algorithm. Then, using the one-to-one mapping relationship between the 3D point cloud and the 2D pixel, the rigid body transformation of the 3D point cloud was calculated to achieve the rough registration of the two point clouds. Finally, the iterative closest point (ICP) algorithm based on SVD was used to accurately register the two point clouds. In the experiment, the proposed registration algorithm was validated using public point cloud, skull point cloud, and cultural relics point cloud data. Results show that the proposed algorithm is a fast and high-precision point cloud registration algorithm.
Owing to the poor performance of the existing blind image forensics method in multiple mirror tamper, we propose an image tampering detection algorithm based on approximate nearest neighbor (ANN) search in this study. The binary robust invariant scalable keypoints (BRISK) feature descriptor is extracted to obtain a binary feature vector of an image. The PatchMatch is used to calculate the offset and optimize the search for similar image blocks through conduction strategy, which can achieve the preliminary detection results of tampering region. The least mean square linear model is used to calculate the fitting error, which can eliminate the mismatched points and accurately locate the tampering area. Experiments are performed on CASIA V2.0 and Columbia University datasets, and the results show that the proposed algorithm can accurately and efficiently detect the tampering region with complex geometric deformations, proving to be more accurate in multiple-mirror tampering.
Aiming at the requirement of vibration measurement of thin-walled parts, the binocular vision is combined with the matching and tracking of features to realize a more accurate method for measuring the vibration of thin-walled parts. First, the vibration images of thin-walled parts were continuously collected using a binocular camera, and image pre-processing operations, such as filtration and binarization, were performed. Second, the first frame image captured using the left and right cameras was selected, and the feature points on the image were stereo-matched according to the principle of epipolar constraint. Then, the improved optical flow method was used to track the feature points of the first frame image to obtain accurate pixel coordinates of the feature points from the second to the last frame images. Finally, the three-dimensional vibration displacement information of the object was obtained based on the binocular vision measurement principle. Experimental research and analysis show that the proposed method can accurately extract the vibration displacement information of thin-walled parts, thereby providing a new technical reference for further research on vibration characteristic analysis, vibration-damping optimization design, and structural damage identification.
In visual positioning system, the accuracy of image matching directly affects the accuracy of the whole positioning system. In this paper, an image matching algorithm based on multi-level FAST (MFAST) and random sampling consistency (RANSAC) algorithm with optimized sampling is proposed for solving the problem of high mismatch rate in image matching. First, the MFAST algorithm is used to extract the corner points, and the speeded up robust feature (SURF) algorithm is used to determine the main direction to generate feature descriptors. Then, in the framework based on RANSAC algorithm, improved weighted K-nearest neighbor (PTM-DWKNN) classification method is utilized to calculate the best model parameters by selecting a new sample set, thereby eliminating the mismatch points. Simulation results confirm the superiority of the proposed method in comparison with the classic ones in real-world scenarios. The proposed algorithm can effectively eliminate mismatched points, improve the matching accuracy of the image, and meet the real-time requirements.
In this study, we propose a compressive computational ghost imaging method based on region segmentation to solve imaging quality problems in local micro-regions of reconstructed images. First, a rough-contour region of interest (ROI) on the surface of a complex object is obtained and a threshold segmentation method is used to perform an edge detection to extract the no-region of interest (N-ROI) in an image and generate random speckle patterns of the corresponding size based on the recognition area. Then, compressed subimages are restored by combining a compressed sensing technology and the second-order computational ghost imaging algorithm. Finally, an image stitching technique is adopted to restore the image. Experimental results show that when the number of samples is 3000, the peak signal-to-noise ratio of the proposed method is improved by more than 9 dB compared with that by traditional computational ghost imaging methods, and it is increased by approximately 49.57% compared with that when the number of samples is 500. The proposed method can solve local micro-region imaging quality problems in reconstructed images, which can not only greatly reduce the number of samples and the spatial intensity calculation of the target region but can also significantly improve the imaging quality of the local micro-region of an image, providing a new solution for correlation imaging.
Due to the limitation of manufacturing technology, the sub-pixels of RGB-Delta structure active-matrix organic light emitting diode (AMOLED) are arranged irregularly, the trichrome sub-pixels are distributed as triangle, and each pixel unit is composed of two sub-pixels, so the RGB image cannot be displayed normally. In order to solve this problem, by analyzing the arrangement characteristics of sub-pixels in RGB-Delta structure AMOLED, this paper proposes the sharing principle and method of the sub-pixels in rendering unit, and calculates the gray-scale difference between a sub-pixel and a shared sub-pixel in the original image. A method based on threshold comparison is proposed to calculate the optimal rendering weight coefficient, and the virtual pixel grayscale value is obtained by summing the pixel gray-scale value weights of the original image. Random image tests show that the mean square error of the processed image and original image is 4.68×10 -5, and the mean peak signal-to-noise ratio is 40.45 dB. At the same time, the algorithm is verified by point screen display, including high-frequency images such as text and line. The proposed algorithm can restore the image information without distortion and effectively control the color edge influence.
In industrial aluminum defect detection, sparse defect samples always lead to the training overfit and poor generalization. This study describes a defect detection model based on multi-task deep learning. Based on Faster RCNN, a multi-task deep network model is designed, including the aluminum area segmentation, defect multi-label classification, and defect target detection. Then the multi-task loss layer is designed, and the weights are balanced by using adaptive weights to solve the problem of uneven convergence in multi-task training. Experiment results show that with the support of a limited dataset, the proposed method can improve the accuracy of multi-label classification and defect target detection while maintaining the optimal mean intersection over union (MIoU) index of the segmentation task, compared to single-task learning. The method solves the problem of low detection accuracy caused by fewer samples of aluminum defect detection. For multi-tasking application scenarios, the model can simultaneously complete three tasks, while reducing the inference time and improving the detection efficiency.
A new algorithm based on optimized match pursuit (MP) sparse decomposition using adaptive particle swarm optimization (PSO) is proposed to address the recognition problem of sound events in public environment. Based on MP sparse decomposition analysis, the fitness function was used to improve the adaptive setting of parameters related to PSO algorithm; then, the objective function and signal reconstruction function were constructed for optimizing sparse decomposition, thus realizing adaptive PSO algorithm optimized MP sparse decomposition. Moreover, the continuous Gabor super complete set was used to improve the matching degree of the optimal atom, which enhanced the sound signal and improved the classification performance of the feature. Finally, optimized support vector machine (SVM) and composite features were used to achieve accurate recognition of sound events in public environments. Experimental results show that the proposed algorithm significantly reduces computational complexity, achieves optimal recognition rate, and demonstrates better robustness compared with existing algorithms.
In order to improve the accuracy and efficiency of the robot when cutting cylindrical workpieces, an algorithm based on binocular vision and laser target reconstruction point to generate robot cutting path is proposed through joint vision reconstruction and robot motion. First, the CCD camera vision environment and the dot laser measuring device are set up to form a dynamic trajectory by traversing the surface of the work-piece. Then the trajectory points are reconstructed and fitted into a continuous cutting path, and the robot processing trajectory with the adaptive multiple discrete difference algorithm is planned. Finally, through the closed-loop chain of the coordinate system of the robotic hand-eye system, the attitude trajectory is converted into the robot joint motion angle, and a complete set of automatic processing scheme from the three-dimensional reconstruction curve to the robot trajectory attitude planning is formed. Simulation results show that the algorithm can accurately extract the three-dimensional coordinates of the work-piece contour, generate the processing trajectory of the robot space curve, and complete the cutting task.
In order to solve the problem that the distribution of line structured light is not uniform and it is easy to be affected by the environment, a method for extracting the centerline of line structured light based on quadratic smoothing algorithm is proposed. First, the region of interest of the collected image is cropped to reduce the calculation amount of the laser stripe centerline extracting. Then the gray center of gravity method is used to extract the initial value of the laser stripe centerline, and mean value method is used to smooth the big bulge and burr at the initial position of the laser stripe centerline. Finally, Savitzky-Golay filtering algorithm is used to smooth the small bulge and burr of the laser stripe centerline twice. Experiment results show that, compared with the gray center of gravity method, it is slightly faster than about 0.10 s when using this method to extract the centerline of the laser fringe of the image with a resolution of 1280 pixel×720 pixel, and the accuracy is improved by 19.15% to 44.87%. The impact from the change of light intensity is small. Therefore, the method meets the requirements of good real-time, high precision, and good stability.
Based on photogrammetry, this study aims to determine a highly accurate, efficient, and flexible approach for obtaining three-dimensional shape and color information of large-scale objects using a total station and a common digital camera. An ordinary digital camera was rigidly connected to the telescope of a total station to build a combined measurement system, and the camera's posture was recorded at all times using the angle reading of the total station. To weaken the parameter coupling while calibrating a camera with a narrow field of view, the principal distance parameter was first directly calibrated based on the physical characteristics of the camera. The other intrinsic parameters of the camera and pose parameters of the telescope associated with the camera were determined by establishing a control field. The station was freely transformed using two common points to achieve the three-dimensional measurement of large-scale objects. Experiments show that the relative error of the length achieved using this method does not exceed ±1/100, and the angle error does not exceed ±0.6°, implying that this method can currently realize three-dimensional measurement of large-scale objects with medium accuracy.
Resultsshow that the proposed method can sequentially distinguish the components of the mixture, and is a reliable method to identify the terahertz broadband spectral characteristics for these components.
Aiming at the problem of low real-time performance of original YOLOV3 target detection algorithm in vehicle detection tasks, this paper proposes an improved vehicle detection model. In order to reduce the number of parameters, reduce the computational complexity, and solve the problem of gradient disappearance and gradient explosion, the model uses the inverted residual network as the basic feature extraction layer. In addition, group normalization is used to reduce the impact of batch size on the accuracy of the model. At the same time, softening non maximum suppression is used to reduce the rate of missed detection. Finally, the Focal-loss is used to improve the loss function so that the model focuses on the difficult-to-classify samples in the process of training. The parameter amount of the improved model is 36.23% of YOLOV3 model. The detection time per frame is reduced by 13.8 ms compared with YOLOV3, and the average category accuracy is improved by 1.15%. The results show that the proposed algorithm ensures both real-time performance and accuracy, and providing a reference for real-time detection of vehicles.
Convolutional neural network has been successfully applied to face recognition, but the extracted features ignore the local features of the face. In order to extract more comprehensive facial features, a convolutional neural network based on feature fusion for face recognition is proposed. This method takes the low frequency coefficients of the face images obtained by performing discrete cosine transform as global feature of the face. Besides, extracting local binary pattern features of original face images as local features of the face. Likewise, the image obtained by weighted fusion of global and local features is fed into the convolutional neural network for training. Experimental results in ORL and CAS-PEAL database show that the proposed method can improve the accuracy of face recognition.
Image feature matching plays an essential role in the field of image information processing, which has been commonly used in image mosaic, three-dimensional reconstruction, visual motion calculation, and other related fields. In order to increase the matching accuracy of image feature matching, an image feature point matching method based on inertial navigation is proposed to be better adapted to the cases of dynamic scene and repeated texture. To begin with, the ORB(Oriented FAST and Rotated BRIEF) features is extracted from the first and second frames. After that, the data of the inertial measurement unit is used to decide the motion of the camera and also to locate where the feature points in the first frame may appear in the second frame. Finally, the matching result of the first two frames is obtained by matching the corresponding feature points in the first and second frames. The experimental results demonstrate that the matching accuracy of this method can reach up to 92%, which has significantly improve the accuracy of image feature matching.
In order to further improve the recognition and classification accuracy of large-scale multi-category point cloud model, a K-nearest neighbor convolutional neural network is proposed. First, the point cloud model is uniformly sampled with the farthest point sampling algorithm. Second, the K-nearest neighbor algorithm is used to construct the local neighborhood of each point for the sampled point cloud model. In order to prevent the non-local diffusion of information, a local neighborhood is constructed for each feature extracted from the convolution layer. Then, all local features are aggregated to obtain the global feature representation of the point cloud model through the max pooling. Finally, the probabilities corresponding to each category are calculated and classified using the fully connected layer and Softmax function. Experimental results show that the recognition accuracy of this algorithm on the ModelNet40 dataset is 92%. Compared with the current point cloud model recognition and classification algorithms, the proposed algorithm can more effectively fuse local structure features and improve the accuracy of point cloud model recognition and classification.
In order to achieve the goal of quantitative application, high-precision cloud detection has become one of the key steps in remote sensing data preprocessing. However, traditional cloud detection methods have the disadvantages of complex features, multiple algorithm steps, poor robustness, inability to combine high-level features with low-level features, and ordinary detection performance. In view of the above problems, this paper proposes a high-precision cloud detection method based on deep residual fully convolutional network, which can achieve the target pixel level segmentation of cloud layer in remote sensing images. First, the encoder extracts the deep features of the image through continuous down-sampling of the residual module. Then, the bilinear interpolation is used for sampling, and the decoding is completed by combining the image features after multilevel coding. Finally, the decoded feature map is fused with the input image and convolution is performed again to achieve end-to-end cloud detection. Experimental results show that, in terms of the Landsat 8 cloud detection data set, the pixel accuracy of the proposed method reaches 93.33%, which is 2.29% higher than that of the original U-Net, and 7.78% higher than that of the traditional Otsu method. This method can provide useful reference for research on intelligent detection of cloud targets.
With the development of biomedical research, more advanced and comprehensive optical microscopy are required to enhance the imaging performances such as the spatial resolution, the imaging speed, the multi-dimensional information, the imaging quality, etc. Light-sheet fluorescence microscopy (LSFM), illuminating the specimen with a thin light sheet from the side and obtaining the optical sectioned image orthogonally, provides an ideal tool for long-term observation of live biological specimens due to its unique features of fast volumetric imaging speed and low photobleaching and phototoxicity to samples. In this paper, we first give an introduction to the principle and properties of LSFM. Then we address the key issues existing in LSFM and the solutions based on new principles, ideas and techniques. Some applications of LSFM in cell biology, developmental biology and neurosciences are exampled, and the development trends and prospect of LSFM are discussed. The purpose of the paper is to help researchers systematically understand the principle, the state-of-the-art techniques, and the potential applications of LSFM, and provide some references for research in this field.
Holding advantages including high accuracy, non-contact measurement, and full-filed measurement, single-wavelength digital holographic systems are generally used for the measurement of micro-scale objects with continuous morphology. Developed from dual-wavelength interferometry techniques, multi-wavelength digital holographic systems can measure objects with complex shapes and larger scales, which extends the application range of digital holographic metrology. In recent years, there are two main research topics in multi-wavelength digital holography area. First, many types of measurement methods and/or optical setup according to realistic requirements are proposed; in addition, enhancement are achieved in image processing techniques such as noise reduction algorithm, numerical reconstruction and phase aberration compensation to improve the computational efficiency and result accuracy.