







Please enter the answer below before you can view the full text.
3+1=

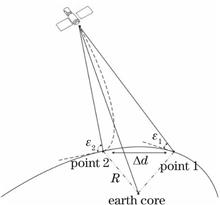
An atmospheric delay correction model based on a ray-tracing algorithm and a surface pressure model are proposed in this paper. As atmospheric parameters for the models, atmospheric data from the National Centers for Environmental Prediction (NCEP) are introduced in the models for the numerical simulations of atmospheric delay corrections of satellite-borne laser altimeters. The result shows that the atmospheric correction along the zenith direction is approximately 2.30 m. By applying sensitivity factors, such as the temperature, precipitable water, station height, and altitude angle, to analyze the sensitivity of the atmospheric delay correction, it is found that the atmospheric delay effect has a low sensitivity to the temperature and precipitable water, while has a strong sensitivity to the satellite altitude angle and station height. The results of this work can be used as a reference for determining the operable conditions for subsequent satellite-borne laser ranging research.
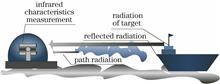
The measurement of infrared radiation characteristics of ship and coastal targets is among the most important components of target infrared radiation characteristic measurements. The traditional ground model corrects only the atmospheric transmittance, so the measurement error of the target cannot meet the measurement requirements of infrared radiation characteristics. This study proposes a method that measures the target radiation characteristics based on reference sources to maximize the measurement accuracy. Experiments for infrared radiation characteristic measurements are conducted near the coast by using a long-wavelength infrared radiation characteristic measurement system with an aperture of 600 mm. Experimental results confirm that the proposed method reduces the radiation measurement error to 4.31%, which is higher than the inversion accuracy of the traditional method.
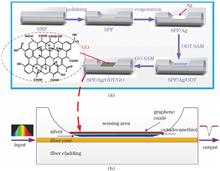
This paper proposes a graphene-oxide-enhanced surface plasmon resonance (SPR) sensor based on side-polished fiber. A silver film is deposited to excite the surface plasmon wave. Seldom graphene oxide nano-films are then decorated on the silver surface of the sensor, where self-assembly octadecanethiol films serve as a link between graphene oxide and silver. The decorated composite films protect the silver film from degradation and enhance the sensor's stability. Compared with the same SPR sensor without graphene-oxide decoration, the average sensitivity of the proposed SPR sensor is 2252.5 nm/RIU in the test range of 1.32-1.34 RIU (RIU is refractive index unit), which is enhanced by 1.48 times, and the figure of merit is comparable with the former without any significant decrease due to the increase of film layers. The proposed fiber sensor is a promising candidate in applications such as antibody antigen immunoassays with high immobilization ability.
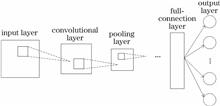
This paper uses a convolutional neural network to automatically classify microscopic images of hair evidence with the aim of enhancing the automation of microscopic technology and providing technical reference for test efficiency. Six kinds of microscopic hair images are collected via Leica DVM6 microscope and are magnified 1400 times to form the sample image dataset which contains 60000 images. The network model Hair-Net based on the convolutional neural network is used to conduct sample training and testing using different parameters. Experimental results show that the classification accuracy of improved Hair-Net can reach 97.82% after parameter testing and optimization, demonstrating that this method can realize automatic classification of microscopic hair images and enhance the robustness.
To meet the requirements of real-time and robust image stitching of unmanned aerial vehicle (UAV) aerial photography, this paper proposes an aerial image stitching algorithm for UAVs based on an improved fast feature-point extraction and description (ORB) algorithm combined with a progressive sample consensu (PROSAC) algorithm. First, the feature points are detected by the speeded up robust feature (SURF) algorithm and described by the rotation-aware binary robust independent elementary features (rBRIEF) algorithm with rotation characteristics. Next, the bidirectional matching algorithm and nearest-neighbor distance ratio algorithm are used to implement feature point coarse matching; subsequently, the PROSAC algorithm is used to eliminate mismatches. Then, the global homography transformation model is used for image registration. Finally, the gradual-in and gradual-out image blending method is used to seamlessly blend the images. The experimental results indicate that the algorithm achieves excellent balance between accuracy and speed, and realizes fast and good image stitching.
In the image deformation process of the moving least squares based algorithm, the coefficient matrix of the solved linear equations is irreversible and unstable. In this study, we apply a constraint term to the coefficient matrix to obtain the exact solution and avoid the formation of ill-conditioned equations by introducing Tikhonov regularization and using the L-curve method to solve the regular parameters. To overcome the limitation of a large number of manually localized feature points and an insufficient number of feature points in the process of image deformation, the Dlib library is employed to automatically extract 68 feature points covering facial features and contours. Simulation results demonstrate that, compared to the original algorithm, the proposed algorithm can produce clear and accurate image deformation.
The Laplace operator introduced in the BSCB model during the transmission process uses four adjacent points around a certain pixel, limiting the pixel representation and then resulting in blurred edges after restoration. In this study, an improved BSCB (Bertalmio, Sapiro, Caselles, Ballester) algorithm is proposed based on rough data deduction to optimize this problem. The improved BSCB algorithm uses the rough data deduction space to formulate rules related to a certain pixel for mining the approximation, derivation, and expansion relations between pixels and adopting points that exhibit the greatest correlation with a certain pixel, avoiding the locality of pixel representation. The experimental results denote that the points adopted during the transmission process of the improved BSCB algorithm can better reflect the image structure, and the proposed algorithm can obtain a better visual effect when compared with the classical BSCB algorithm. The peak signal-to-noise ratio also confirms the improvement of the restoration effect based on the data level.
Aiming at the problems of low classification accuracy and less classification types in the classification for aircraft targets by using conventional methods and neural networks, the feasibility of deep convolutional neural network (DCNN) models is studied. To match model capacity, avoid overfitting, and improve classification performance, a nine-layer DCNN model is designed and optimized with stochastic gradient descent optimizer. Six representative types of aircrafts are selected in the dataset, and two regularization cascade methods are proposed to prevent overfitting and speed up the model convergence. Finally, an aircraft classification accuracy of 99.1% is achieved, which demonstrates the effectiveness of the DCNN model in aircraft target classification. By analyzing the classification results of the normalized confusion matrix, the accuracy of the self-classification of each type of aircraft is given. In addition, a group of comparative experiments are designed to test the same dataset with the classic AlexNet. The results show that the proposed DCNN model is superior to the AlexNet classification algorithm with an accuracy improvement of 95.5%. This model effectively solves the problem of low accuracy in aircraft target classification at present and proves that the DCNN model has certain reference values and application prospects in the classification research of military and civil aviation aircraft targets.
To ensure detection speed and further improve object detection accuracy, a new model RF-YOLOv2 is proposed on the basis of the YOLOv2 model. In this new model, the KITTI data set is first clustered to select the most suitable number and size of candidate boxes. Next, a residual block structure is used to increase the number of convolutional layers in the training part of the network structure. This increase helps the model to extract more strong features to better describe objects. Finally, a feature pyramid network is introduced in the detection part of the network structure, fusing the feature graphs with different sizes. This network allows even low-level feature graphs to capture rich semantic information. Experimental results show that the RF-YOLOv2 model can gain the deeper information about features and can integrate more object size information. These improvements alleviate significant problems in current models that lead to low detection rates when actual road scenes are complex or when objects vary in shape or structure. The proposed model also improves object detection accuracy in real time detection and achieves better results for large object detection.
In this study, an object detection algorithm is designed based on an improved feature extraction network to solve the shortcomings of low object detection accuracy and inaccurate object position detection. Initially, the training set is enhanced; subsequently, a two-path network is designed for usage in feature extraction of the Faster R-CNN algorithm; finally, the non-maximum suppression mechanism is improved in the prediction part of the algorithm, and the weighted averaging method is adopted for obtaining the positions of multiple similar prediction boxes. The experiments conducted using the VOC 2007 and VOC 2012 databases denote that the proposed algorithm outperforms the classical object detection algorithm, with an accuracy rate of 79.1% and an improvement of 3%-4%. Thus, the effectiveness of the algorithm is verified.
Herein, we investigate solutions to address various problems, including the low detection precision and leak detection of the traffic signs, associated with the major detection algorithms under conditions of low illumination or intense variation of lighting. We propose an improved integrated Adaboost algorithm based on multicomponent transformation of the characteristics of key points of image to reduce the sensitivity of a sample image to illumination variation. The proposed algorithm extracts the key points of image and builds a weak classifier to reinforce the anti-disturbance ability of the algorithm under conditions of noise and partial obscurity. Meanwhile, the multi-scale feature fusion algorithm is used to classify and recognize the traffic signs. Furthermore, the German traffic sign datasets (the GTSDB and GTSRB datasets, respectively) and the self-built dataset are used to verify the performance of the proposed algorithm. The results denote that the proposed algorithm exhibits the highest detection and recognition rates when compared to other existing algorithms based on these three datasets. For the images of traffic signs under low illumination, the detection accuracy of proposed algorithm is 94.96%, indicating good robustness in complicated lighting environments.
In this study, we propose a dual discriminator super-resolution reconstruction network (DDSRRN) that can improve the super-resolution reconstruction quality of images. By adding a discriminator based on generative adversarial networks, the DDSRRN combines the Kullback-Leibler (KL) divergence and reverse KL divergence into a unified objective function for training two discriminators. Thus, the complementary statistical properties obtained from these divergences can be exploited to effectively diversify the pre-estimated density under multiple modes. Additionally, model collapse is effectively avoided during the reconstruction process, and the model training stability is improved. The model loss function can be designed based on the Charbonnier loss function to estimate the content loss. Furthermore, the intermediate features of the network are used to design the perceptual loss and style loss. Finally, a deconvolution layer is designed to reconstruct the super-resolution images, thereby reducing the image reconstruction time. The proposed method is experimentally demonstrated to provide abundant details. Thus, the proposed method exhibits good generalization ability and obtains improved subjective visual evaluation and objective quantitative evaluation.
In this study, we report a novel method based on swept-source optical coherence tomography that involves the reconstruction of the three-dimensional structure of the human subcutaneous microvasculature. A handheld optical coherence tomography system that has been developed in our laboratory is employed as the human skin microvascular scanner in the proposed method. Further, the differential standard deviation observed in the logarithmic-intensity blood flow images in case of multi-frame B-scan is calculated, and the in vivo cross-section and en-face images of human skin are obtained. The experimental results denote that the proposed algorithm can generate image information of hemorrhagic flow better when compared with the existing differential standard deviation algorithm based on logarithmic intensity. Furthermore, the blood flow details that cannot be seen in the processed results obtained from the original algorithm can be clearly observed from the reconstructed image obtained by the proposed algorithm, which is useful for ensuring the practical application of the optical coherence tomography system in medical diagnosis of diseases,such as cancer, diabetes, and wine stains.
In this study, we propose an improved cavern capacity calculation model to address the defects of existing point cloud methods. First, the cavern preprocessed point cloud is sectioned into several point cloud slices from the bottom to the top along the height direction. For each slice, the contour points of two cross sections are extracted using the presented hierarchical projection method,and the section contour polygon is constructed correctly by using the improved ordering algorithm for section contour points. Subsequently, the area of each cross section is calculated using the coordinate analytic method. Given the structures of the caverns, the cell volumes of the lower side wall and upper arch of caverns are calculated by using models of cylinder and trustum of a pyramid, respectively. Finally, the capacity table of the caverns can be acquired based on the volume of every polyhedron from the bottom to the top. The performance of the proposed method is evaluated using three representative point cloud fragments from a cavern. The results denote that the accuracy of the output capacity table obtained by experiments is an order of magnitude higher than that demanded by the standard requirement. The proposed approach shows good adaptability with respect to the complex structure of caverns.
To realize the horizontal positioning of a reticle stage with three degrees of freedom and high accuracy, it needs to establish an accurate multi-degree of freedom decoupling measurement model in the reticle-stage-measurement system. In this study, a two-dimensional diffraction planar grating is used to establish a reticle stage degree-of-freedom position measurement system, and the main reasons for the deviation in the position of the reticle stage are analyzed in terms of the multiple installation errors that are caused by the planar grating and read head. Firstly, the displacement model of the three degrees of freedom of the reticle stage is designed according to the installation layout; then, the installation errors of the planar grating and read head are combined to analyze the cause of the Abbe and cosine errors generated by the position of the reticle stage. A compensation algorithm is designed to reduce the position error of the reticle stage and then the model is simulated using MATLAB software, observing the convergence of coupling coefficient. Finally, a calibration error method is proposed. Using the dual-frequency laser interferometer measurement system as the benchmark and using the least squares method, the coupling coefficient of the degree of freedom of the planar grating position model is determined. Experimental results show that the proposed algorithm can effectively compensate the Abbe and cosine errors of the reticle stage; thus, the uncertainty in the measurement system reaches 5 nm.
Crystal waveguides prepared by adhesive-free bonding techniques demonstrate strong mode-limiting effects. In this paper, the crystal waveguide's single transverse mode condition is calculated in the context of mode competition. The single transverse mode thickness range of the core and inner cladding is obtained when the core material is Yb∶YAG with atomic number fraction of 1% and the inner cladding material is Er:YAG with atomic number fraction of 0.5%. Results from these calculations show that the maximum core thickness can be increased to approximately 1.79 times of the traditional calculation results obtained without mode competition. This finding provides theoretical support for the possibility of simultaneous large-mode area and single transverse mode output. A large-core Yb∶YAG crystal waveguide with a core size of 320 μm×400 μm is prepared in the experiment. The crystal waveguide is used as a gain medium to build a crystal waveguide laser that could output a 1030-nm laser. The laser's maximum output power is 26 W, with a slope efficiency of 31.5% and beam quality factors of Mx2=1.22 and My2=1.05. These experimental results demonstrate that the crystal waveguide can achieve an output that approaches the diffraction limit. The introduction of mode competition is a reliable design method for achieving single transverse mode output in a large-core crystal waveguide.
To study the laser cleaning process and optimize process parameters, a nanosecond pulse laser was used to perform laser cleaning experiments on the acrylic resin paint on the surface of a 304 stainless steel substrate. The surface morphology and elemental composition after paint removal were analyzed by using the scanning electron microscopy and X-ray energy dispersive spectroscopy, and the surface roughness was measured by using a laser confocal microscope. Based on the response surface methodology, a Design-Expert software was used to analyze the effects of laser power, number of scans, and spot overlap rate on the surface morphology, elemental composition, and surface roughness after laser paint removal, and the paint removal process parameters were optimized. The results denote that the spot overlap rate considerably affects the surface composition and that the laser power considerably affects the surface roughness. The optimization results denote that the optimal laser paint removal results can be achieved when the laser power is 19.18 W, the spot overlap rate is 46%, and the number of scans is 3. The experiments show that improved cleaning results can be obtained by selecting suitable process parameters.
Herein, the stress distribution state of laser phase transformation hardening vermicular graphite cast iron RuT300 is studied based on beam discretization using a constructed elastic-plastic constitutive model of the discrete laser phase transformation hardening RuT300. Additionally, the model considers the effect of temperature on thermal stress and residual stress. The results demonstrate that the large thermal stress on the material's surface corresponds to a two-dimensional discrete lattice spot. Since rapid laser heating causes each part of the material to experience a different temperature, the thermal stress distribution is wavy along the X-axis path of the model. The maximum thermal stress in the X and Y directions of the discrete spot loading region is found to be -635 MPa, which is 1.8 times that found in the Z direction. In each section of the model, the thermal stress decreases gradually with an increase in the depth; the residual stress value in the laser loading region on the surface of the material is larger than that in the nonloading region. The residual tensile stresses in the X and Y directions of the model constitute the primary residual stress, with a value of approximately 200 MPa. The residual stress in the X direction along the X-axis path is the largest among the three directions. As the laser power increases, the peak residual stress value increases, and the area of the material affected by large residual stresses increases. However, when the laser heating time is prolonged, the change in the peak residual stress value in the loading region is within the range of 2.4 MPa.
Herein, laser milling of Al2O3 ceramics is conducted using nanosecond pulsed laser. The relationship among milling process parameters, surface roughness, and milling depth is investigated using response surface second-order regression model. In addition, the key process parameters affecting surface roughness and milling depth are identified using sensitivity analysis. A genetic algorithm is used to determine the optimal process parameters that minimize the surface roughness and maximize the milling depth. These parameters are then experimentally verified. Results indicate a strong predictive ability of the mathematical model based on the response surface method. The number of milling times and overlap rate have the most significant effect on the surface roughness and milling depth. Under optimized parameters, the predicted surface roughness and milling depth are found to be 10.471 μm and 120.526 μm, respectively, while their corresponding experimental values are 10.835 μm and 131.277 μm, respectively. Therefore, the relative errors in case of surface roughness and milling depth are only 3.36% and 8.19%, respectively.
To address the problem of poor wine quality caused by wine seal ring defects and improve defect detection efficiency, an online detection method for wine seal ring defects is developed. According to the structure and position of the wine seal rings and the inner diameter and depth of the bottle caps, an online detection system based on machine vision dual-field and dual-station collaboration methods is proposed. Given that it is difficult to extract the contour defects of wine seal rings from two-dimensional information, we transform the two-dimensional information of a wine seal ring contour into an one-dimensional vector. Then, the one-dimensional vector theory is applied to analyze and deal with the defects, and the wavelet modulus maxima method is used to extract and determine them. The experimental results show that the system can effectively detect defects at any position of a wine ring and that its detection accuracy is 99.89%. The efficiency of the method described in this paper is six times higher than that of manual inspection. It meets the requirements of production and expected R&D, and provides a new technique for the non-destructive online detection of wine seal ring defects.
This paper proposes a multitask convolutional neural network (MTCNN) based on fine-grained images and multi-attribute fusion. The network mainly includes the following key links. First, the label input layer is added to the network; the input multiple labels are copied and separated, and then matched to multiple tasks with a fully connected layer. The Softmax loss function corresponding to the number of labels is added to backpropagate multiple tasks. Then, a fine-grained image in the original image is extracted by the combination of saliency detection and corner detection, and used as the input of MTCNN. The target features extracted by the neural network are more unique and distinguishable. Finally, the MTCNN uses the nonlinear activation function PReLu to further improve the classification accuracy of the network. This paper uses the MTCNN to perform multi-task parallel training in the Car Dataset and achieves a 10% improvement in the classification accuracy over the traditional single task. The results show that the MTCNN has high generalization performance and the accuracy of image classification is obviously improved.
This study proposes a filter tracking algorithm based on the direction gradient histogram using time regularization and background-aware to overcome the problem of target background of the correlation filter (CF) having no optimal performance without time modeling. The training samples are firstly extracted from the real background, and classification ability of the filter is enhanced by adding the training samples. Subsequently, time regularization is introduced to construct the target relocation module under occlusion. In addition, the alternating direction multiplier method is used to optimize the solution target and reduce the computational complexity. Finally, a linear interpolation strategy is used to update the target location and scale. The proposed algorithm uses 100 video sequences and evaluation criteria in object tracking benchmark (OTB-2015) dataset for performance testing. Experimental results show that the accuracy score of filter tracking algorithm using time regularization and background-aware reaches 0.801 and success rate score is 0.762, which are 20% and 46.8% higher, respectively, compared to those of the kernelized correlation filter (KCF) algorithm. The proposed algorithm can solve the visual-tracking problem of off-plane rotation, occlusion, and background ambiguity, which has wide application prospects and use value.
The accuracy of binocular stereo vision calibration obtained using the mean of total residuals of left and right images is unsatisfactory. To overcome this limitation, this study proposes a method for evaluating the accuracy of binocular stereo vision calibration based on the epipolar constraint. The proposed method considers the constraint relationship between left and right image features in binocular stereo vision and global characteristics of camera calibration parameters. Based on the principle of minimum matching cost, a stereo feature matching method based on scale-invariant feature transform is used for corner detection and matching. The accuracy of binocular stereo vision calibration is evaluated based on the matching degree of measured corner points on the left and right image planes with their corresponding epipolar lines on the relative image plane. This proposed algorithm is added to the calibration algorithm to realize real-time evaluation of camera calibration accuracy during the calibration experiment. Experiments demonstrate that the proposed method is more accurate than the method using the mean of residuals, with accuracy increased by up to 54.0%.
In this study, we propose an adaptive band selection method based on the spectral measurement data, considering the interference of background radiation and instrument noise on target detection. Further, an acousto-optic tunable filter imaging spectrometer is used to collect the spectral data with a spectral scanning band of 400-1000 nm. An unmanned aerial vehicle target and a static object are detected against a sky background and a wall background, respectively. The integrated signal-to-noise ratio of each wavelength is calculated to be 0.7 times the maximum value and is set as the threshold for selecting an appropriate working band. The band selection result is in accordance with the actual situation. The experimental results demonstrate that the proposed method can effectively select optimal detection bands for different targets.
In this paper, numerical simulation and experimental verification methods are presented to investigate the influence of nonparallel slot and double-prism ridge in observing clear interference fringes. This result is essentially in the Fresnel double prism interference experiment using a line source. Initially, the interference intensity distribution formula of the Fresnel double prism on the observation screen is theoretically obtained. This is accomplished using geometrical optics and the principle of interference. In addition, the visibility of the interference fringe as a function of the angle between the slot and the ridge is obtained using numerical simulation. Theoretical analysis shows that as the angle increases, the interference visibility falls, then rises, and then falls again. Finally, an attempt to experimentally verify the theoretical results is also presented. The experimental results seem to be consistent with the numerical simulation results.
The classical one-time-pad communication method exhibits the disadvantage of key loss and the shortcoming that the key will be quickly exhausted when a large amount of data is transmitted, making it unsuitable for classical big data communication. Further, it is difficult to distinguish the four Bell states in quantum teleportation. This study considers quantum teleportation as a quantum channel that transmits classical information sequences because quantum channels not only transmit quantum information but also classical information. The transmitted data 0 and 1 are encoded as quantum states |0> and |1>, respectively. The proposed scheme can continuously ensure security and generate keys, which is suitable for big data communication. Furthermore, this scheme only needs to distinguish between two kinds of Bell states, which can be easily implemented.
The influences of light-field distribution parameters, atomic relative detuning, maximum photon number, light-field probability parameters, and initial atomic states on quantum entanglement characteristics of a system comprising a Pólya-state light field interacting with a Λ-type three-level atom are analyzed based on the quantum entropy theory. The results denote that when the Λ-type three-level atom interacts with the Pólya-state light field and the initial state is a two-lower-level energy-equal superposition state, a stable and periodically oscillating entangled state with a relatively small maximum entanglement degree can be obtained for appropriate parameter values. However, if the initial state is an excited state or a three-level equal-weight superposition state, a stable and periodically oscillating entangled state with a maximum entanglement degree of 1.1 can be obtained for appropriate parameter values.
Colloidal crystals are materials that exhibit an ordered structure formed by dispersed micron or submicron colloidal particles. The self-assembly technology is a commonly used method to manufacture colloidal crystals. The basic concepts of colloidal crystals and the related self-assembly processes are outlined in this review. Furthermore, the applications of self-assembled colloidal crystals in case of micro-nano optics are presented in detail. Subsequently, other applications of self-assembled colloidal crystals, such as color printing, holograms, anti-reflective coatings, and optical devices, are presented and the roles of colloidal crystals in those applications are summarized. The unique periodic structure of colloidal crystals ensures its broad application prospects. Therefore, improving the quality of colloidal crystals using various self-assembly techniques is of considerable importance.
The focusing methods of solar concentrators are mainly classified into three categories. This study introduces the structural designs and operating principles of various solar concentrators, analyses their focusing performance, and summaries the latest research status at home and abroad. First, we consider a refractive concentrator, which involves the usage of Fresnel lens with varying shapes as the main optical element and exhibits a high design freedom, but the lens is sensitive to the spectrum and easy to produce dispersion. Second, we consider a reflective concentrator, which exhibits a simple structure, has natural advantages with respect to the solar spectrum, and covers a larger area, but its concentration ratio is generally low and its concentration efficiency is related to the refractive index of the coating on the reflector and other factors. Finally, we consider a hybrid concentrator, which can be obtained by combining concentrators under different operating principles to achieve maximum utilization of the solar energy and generate a uniform spot at the exit. With respect to the hybrid concentrator, the planar concentrator has attracted increasing attention because of its dynamic concentration ratio and high concentration efficiency; however, the manufacturing and coupling errors associated with the planar concentrator still need to be considered. Regardless, the solar concentrator is one of the key components of a concentrating photovoltaic system, and its research demonstrates considerable futuristic applications. From the development perspective, the optical concentrator designs exhibit considerable potentials because of their high efficiency, uniformity with respect to the focusing spot on the receiving surface, and advanced compact system structure. With the continuous development of the processing technology, the concentrator will become increasingly efficient and lightweight, thereby reducing its cost.
The design of novel light beams and investigation of their propagation properties are important topics in optics, particularly for beams that are nondiffracting, self-accelerating, or self-repairing. The evolution of these beams in either free-space or a waveguide and their applications have attracted a significant amount of research. Although wave optics has been developed as a rigorous and self-consistent framework, it does not offer intuitive processes for solving optical wave propagation. However, geometrical optics, also known as ray optics, can provide an intuitive and understandable method for analyzing light beam propagation and constructing targeted beam shapes in addition to designing optical systems. With the development of modern geometrical optics, rays have extended their physical meaning and are widely used to characterize optical wave propagation. Furthermore, ray characterization can explain nondiffracting, self-accelerating, and self-repairing properties. In this work, beginning with the fundamental theory of geometrical optics, we review the development, applications, and recent advances of significance of ray in modern ray optics. Meanwhile, some typical beams, such as fundamental-mode Gaussian, non-diffraction, and Airy beams, as well as beams with spiral wavefronts and structured Gaussian beams, have been characterized and designed using rays. Lastly, some challenging problems and future research directions of geometrical optics are discussed.
The terahertz waves exhibit spectral fingerprint characteristics and penetrability for nonpolar substances, which have huge potential applications in the identification of hazardous substances hidden in mail. Currently, the commonly used terahertz optical-constant-extraction algorithms have the disadvantages of being complicated and requiring lengthy computations as well as samples with known thicknesses. In this study, we propose a method of directly calculating the characteristic absorption frequencies based on the amplitudes of the terahertz transmission coefficients to alleviate the shortcomings associated with the conventional algorithms and satisfy the rapid-processing requirement of real-time mail detection. The calculation procedure is considerably simplified by using the proposed method because the calculation only needs to be conducted once. To further improve the processing speed, we propose data processing methods that use abnormal data filtering and low-pass filtering instead of requiring multiple measurements and average filtering. Therefore, all the data measurements can be completed once. Furthermore, the characteristic absorption frequencies of the sucrose and benzophenone samples obtained using the proposed method are consistent with those obtained using the conventional method.
The mid-infrared spectroscopy detection can be used to the determination of methanol content in methanol gasoline. The mid-infrared spectra are susceptible to external interference and yield a large amount of data. To simplify the calculation and improve the accuracy of the model, the methods of uninformative variable elimination (UVE), competitive adaptive re-weighted sampling (CARS), and genetic algorithm (GA) are used to select effective spectral bands; then, a corresponding partial least squares (PLS) model is established. Finally, the PLS, UVE-PLS, GA-PLS, and CARS-PLS models are established to explore the optimal methanol content detection model for methanol gasoline. Results show that the CARS-PLS model performs the best, with the predicted correlation coefficient and root mean square error are 0.978 and 1.177, respectively. The CARS algorithm is a very effective wavelength extraction method for the methanol content in methanol gasoline, and detection technology utilizing the mid-infrared spectrum can be applied to determining the methanol content in methanol gasoline, which can effectively simplify calculations and improve the accuracy of the model detection.