




 View fulltext
View fulltext

2022
Volume: 49 Issue 5
7 Article(s)

Yinan Ji, Haifeng Li, and Xu Liu
Overview: This paper presents an improved and optimized scheme for a large field of view single lens computational imaging system. In 2018, Peng Y F et al. proposed a single-lens computational imaging system with large field of view. This system solved the problem that the field of view of a single-lens computational imaging system could only be limited to 10 degrees. However, we noticed that after adopting the mixed PSF method of Peng Y F et al., the PSF learned by the network was not actually the accurate PSF of the image. This PSF error would have a bad effect on the final network output, resulting in the degradation of the quality of the restored network image. In order to solve the above-mentioned problem and make the imaging results of wide-field single-lens computational imaging system have better quality for human eyes to see, we proposed a processing method for wide-field PSF and its corresponding image training idea. Firstly, we divided the image into two parts, including the center and edge areas, according to the field of view. The center part corresponds to the field of view within 10 degrees, and the edge part corresponds to the field of view between 10 degrees and 53 degrees. In order to avoid segmentation traces after splicing, we adopted a segmentation method that can leave a gaussian gradient boundary. Then, the segmented images were made into two training sets, which were put into different networks for training. Under this situation, the PSF after the network training would be closer to the real PSF in the picture, which would greatly reduce the influence of PSF error, so that the quality of network training results would be better. After the training, the image to be restored was divided into two parts by the same method, and then the two parts of the image were restored in the corresponding neural network respectively. Finally, the output results of the two networks were spliced into a complete image to obtain the final result. For the same group of different pictures, we used the idea proposed by Peng Y F et al. and our new idea to restore and compared the results of the two methods. From the subjective perception of human eyes, the pictures obtained by using our new idea are more natural, clearer, and better than those obtained by using the methods of Peng Y F and others. In terms of objective evaluation indicators, our method is comparable to the method of Peng Y F et al. in terms of PSNR value. In terms of SSIM value, our method is much better than that of the Peng Y F et al. Therefore, in general, our idea does improve and optimize the large field of view single lens computational imaging system, and makes its imaging results higher quality and more suitable for human eyes.In order to improve the final image quality of a large field single-lens computational imaging system, and to make its output more suitable for human eyes to see, a feasible image training method is proposed in this paper. First, a image was divided into two parts, including the center and edge areas, according to the field of view. In order to avoid leaving segmentation traces after splicing, we adopted a segmentation method that can leave a Gaussian boundary. Then the two parts were put into two datasets respectively. After that, the two datasets were respectively fed into the neural network for training. After training, the test image was divided into the center and edge areas using the same method, and were fed into their own neural networks. Finally, the results of the two networks would be joined together into a complete image to get the final result. After subjective perception and objective index evaluation, the image obtained by using the new idea in this paper has a significant improvement in quality and a better visual perception compared with the image obtained by direct training. Therefore, the improvement and optimization of the large field of view single-lens computational imaging system is successfully realized, and the output images of the system become more suitable for human eyes.
May. 25, 2022Vol. 49 Issue 5 210371 (2022)
Chong Zhang, Yingping Huang, Zhiyang Guo, and Jingyi Yang
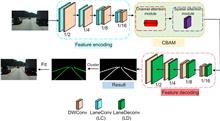
Overview: In recent years, the rapid development of neural network has greatly improved the efficiency of lane detection. However, convolutional neural network has become a new problem restricting the development of lane detection because of its large amount of calculation and high hardware requirements. Lane detection methods based on deep learning can be divided into two categories: detection based methods and segmentation based methods. The method based on detection has the advantages of high speed and strong ability to deal with straight lane. However, when the environment is complex and there are many curves, the detection effect is obviously not as good as the segmentation based method. This paper adopts the segmentation based method, and considers that the performance of lane detection can be improved by establishing global context correlation and enhancing the effective expression of important Lane feature channels. Attention mechanism is a model that can significantly improve network performance. It imitates the human visual processing mechanism, strengthens the attention to important information, so as to reasonably allocate network resources and improve the detection efficiency and accuracy of the network. Therefore, this paper uses the CBAM model. In this model, channel attention and spatial attention are serial to obtain better feature representation ability. Spatial attention learns the positional relationship between lane line pixels, and channel attention learns the importance of different channel features. In addition, in order to solve the problem of complex convolution calculation and slow running speed based on segmentation model, a more efficient convolution structure is proposed to improve the computational efficiency. A new fast down sampling module laneconv and a new fast up sampling module laneconv are introduced, and the depth separable convolution is introduced to further reduce the amount of calculation. They are located in the coding part of the network. The decoding part outputs the binary segmentation result. Then, the results are clustered by DBSCAN to obtain the lane line. After clustering, compared with the complex post-processing in other literature, this paper only uses simple cubic fitting to fit the lane line, which further improves the speed. Therefore, the running speed of the model proposed in this paper is better than most segmentation based methods. Finally, a large number of experiments are carried out on tusimple Lane database. The results show that the method has good robustness under various road conditions, especially in the case of occlusion. Compared with the existing models, it has comprehensive advantages in detection accuracy and speed.Lane line recognition is an important task of automatic driving environment perception. In recent years, the deep learning method based on convolutional neural network has achieved good results in target detection and scene segmentation. Based on the idea of semantic segmentation, this paper designs a lightweight Lane segmentation network based on encoding and decoding structure. Aiming at the problem of large amount of computation of convolution neural network, the deep separable convolution is introduced to replace the ordinary convolution to reduce the amount of convolution computation. Moreover, a more efficient convolution structure of laneconv and lanedeconv is proposed to further improve the computational efficiency. Secondly, in order to obtain better lane line feature representation ability, in the coding stage, a dual attention mechanism module (CBAM) connecting spatial attention and channel attention in series is introduced to improve the accuracy of lane line segmentation. A large number of experiments are carried out on tusimple lane line data set. The results show that this method can significantly improve the lane line segmentation speed, and has a good segmentation effect and robustness under various conditions. Compared with the existing lane line segmentation models, the proposed method is similar or even better in segmentation accuracy, but significantly improved in speed.
May. 25, 2022Vol. 49 Issue 5 210378 (2022)
Ronggui Wang, Hui Lei, Juan Yang, and Lixia Xue
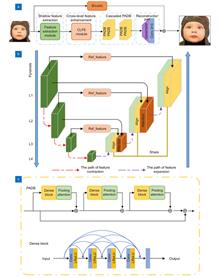
Deep convolutional neural networks (DCNN) recently demonstrated high-quality restoration in the single image super-resolution (SISR). However, most of the existing image super-resolution methods only consider making full use of the inherent static characteristics of the training sets, ignoring the internal self-similarity of low-resolution images. In this paper, a self-similarity enhancement network (SSEN) is proposed to address above-mentioned problems. Specifically, we embedded the deformable convolution into the pyramid structure and combined it with the cross-level co-attention to design a module that can fully mine multi-level self-similarity, namely the cross-level feature enhancement module. In addition, we introduce a pooling attention mechanism into the stacked residual dense blocks, which uses a strip pooling to expand the receptive field of the convolutional neural network and establish remote dependencies within the deep features, so that the patches with high similarity in deep features can complement each other. Extensive experiments on five benchmark datasets have shown that the SSEN has a significant improvement in reconstruction effect compared with the existing methods.
May. 25, 2022Vol. 49 Issue 5 210382 (2022)
Zhihao Wang, Wenxi Zhang, Zhou Wu, Xinxin Kong, Yongbiao Wang, and Yiwei Hao
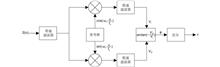
Overview: Laser vibration measurement technology has made great progress in the past decades, and there is still a higher demand in the measurement accuracy and measurement range. Due to the large amount of noise in the measurement process of the laser vibrometer, which leads to a decrease of the vibration measurement precision of the laser vimeter, the filtering of the vibration measurement signal is the key to improving the precision of the laser vimeter. Traditional filters such as the FIR and IIR are time-invariant filters, whose parameters are fixed and invariable. The frequency range of the input signal is required to be known during design, and the filtering performance is inversely proportional to the bandwidth. An adaptive filter is a time-variant filter, it does not need to predict the statistical properties of interference noise, can filter in successive iteration processes of the working state of convergence to adaptively based on the optimal solution under the certain standards, such as minimum mean square error (MMSE) and least-squares criterion, are effective for broadband and narrowband noise suppression. The Least Mean Square (LMS) forward predictor is a kind of the classical adaptive filter, which is based on the MMSE criterion and uses the stochastic gradient descent method to approach the optimal solution under the MMSE criterion by iteration. It has the advantages of simple structure and good robustness. Aiming at the adaptive filtering problem in the laser vibrometer, the Least Mean Square (LMS) forward predictor was used in this paper, and the vibration measurement signal model was established. We simulated and analyzed the parameters of the LMS forward predictor, such as the peak value and frequency of the vibration measurement signal, the order of the filter and the step size coefficient on the filtering performance, and built an experimental system for verification. Simulation and experiments show that the LMS forward predictor can be used as a way to realize adaptive filtering of laser vibrometers, which is suitable for vibration velocity signal filtering in applications such as building vibration detection, mechanical vibration measurement, and material surface micro-damage detection. The filtering effect and convergence speed of the LMS forward predictor are affected by the peak value, order, and step coefficient of the input signal. The filter parameters can be selected and designed according to the requirements of the system for the minimum filtering signal-to-noise ratio and vibration velocity measurement range. This paper provides a theoretical basis for the parameter selection of the LMS forward predictor and provides a technical means for designing an adaptive filter suitable for a laser vibrometer.Aiming at adaptive filtering in the laser vibrograph, we simulated and analyzed the parameters of the Least Mean Square forward predictors, such as the peak value and frequency of the vibration measurement signal, the order of the filter and the step size coefficient on the filtering performance. Then we built an experimental system for verification, and an experimental system was built to verify it. The research results can be used as the theoretical basis for the parameter selection of the minimum mean square error forward predictor and provides a technical means for designing an adaptive filter suitable for laser vibrometer.
May. 25, 2022Vol. 49 Issue 5 210391 (2022)
Junjie Gan, and Lei Li
Overview: As an important device of adaptive optics, Polydimethylsiloxane (PDMS) liquid lens has the advantages of large aperture and high power. By changing the amount of liquid in the cavity, the lens focusing can be realized with the deformation of the membrane. This kind of lens has been studied for more than half a century. However, the development and application of PDMS liquid lens were restricted because of its aberration. PDMS is an excellent optical material, but as a hyper-elastomer, its deformation characteristics are complex. Moreover, the deformable membrane can be susceptible to gravity effects. As a result, the aberration of the PDMS liquid lens is serious. In this paper, a PDMS membrane liquid lens for correcting aberrations is proposed. The proposed liquid lens is composed of a PDMS membrane, liquid material, and compensation substrate. The aberrations caused by the compensatory substrate were opposite to the liquid part and the overall aberrations reduce. The work is divided into three steps. The first step is to measure and fit the surface profile of the PDMS membrane. Firstly, using a three-dimensional profilometer, the surface profile of the liquid lens at different power was scanned by the scanning probe stylus. Then curve fitting for depth data was performed to find the surface characteristics, and the results show that the PDMS membrane has a paraboloid profile during deformation. In the second step, an optical model of the liquid lens was established based on the paraboloid membrane model. Through optimization by Zemax software, the compensatory substrate parameters were determined. The high refractive index liquid (1-Ethyl-3-methylimidazolium trifluoromethanesulfonate) and a compensatory substrate are used for correcting the aberration and improving the optical power. In the third step, the proposed liquid lens is fabricated. Measurement with a focimeter for the relationship between optical power and liquid variation of the proposed liquid lens was conducted. The experimental results show that the effective optical aperture of the liquid lens is 25 mm and the power range is -5 D ~ +6 D. Finally, the optical performance was measured. Photos imaged through the proposed liquid lens were taken by a phone camera. An experimental system was designed for the resolution test, where the resolution target in a collimator was imaged through the liquid lens. What’s more, the transmittance of the liquid in the visible band is more than 90%. Compared with the traditional lens, the proposed liquid lens can improve the image quality, and the resolution is 15 lp/mm at +5D power. The proposed liquid lens has potential applications in large aperture optical imaging systems, such as telescopes, glasses, AR, VR, etc.Polydimethylsiloxane (PDMS) liquid lens has the advantages of large aperture and high power, but its aberration is serious. In this paper, a PDMS membrane liquid lens for correcting aberrations is proposed. The proposed lens is composed of a PDMS membrane, liquid material, and compensation substrate. Based on the paraboloid membrane model, an optical model of the liquid lens is established. The high refractive index liquid (1-Ethyl-3-methylimidazolium trifluoromethanesulfonate) and a compensatory substrate are used for correcting the aberration and improving the optical power. The proposed liquid lens is fabricated and the experimental results show that the effective optical aperture is 25 mm, the power range is -5 D ~ +6 D, and the transmittance in the visible band is more than 90%. Compared with the traditional lenses, the proposed liquid lens can improve the image quality, and the resolution is 15 lp/mm at +5D power. The proposed liquid lens has potential applications in large aperture optical imaging systems, such as telescopes, AR, VR, etc.
May. 25, 2022Vol. 49 Issue 5 210404 (2022)
Solution processed organic light-emitting devices: structure, device physics and fabrication process
Shihao Liu, Letian Zhang, and Wenfa Xie
The industrialization of organic light-emitting devices (OLEDs) in the field of lighting still faces the challenge of high costs, while solution-processed OLEDs can dramatically reduce their manufacturing cost. However, compared with thermally evaporated OLEDs, solution-processed OLEDs encounter difficulty in building multilayer systems. As the relevant reviews on solution-processed OLED from the perspective of material engineering have been proposed, this paper will mainly summarize multilayer structures of solution-processed OLED from the aspects of device physics and preparation processes. First, we will analyze the necessity of each functional layer based on the carrier/exciton dynamics and optical physics. Next, we will introduce the commonly used solution-processing techniques and discuss the problems involved in the preparation of multilayer films. Finally, we will present the future prospects of solution-processed OLEDs.
May. 25, 2022Vol. 49 Issue 5 210407 (2022)

Ayuan Lin, Jinyu Wang, Yuxin Chen, Peiliang Qi, Zhiyun Huang, and Xiaodi Tan
When the Bragg condition is satisfied, although the hologram is illuminated by the reading wave, the power of the reconstructed wave may be zero. The above phenomenon is called null reconstruction in polarization holography. In the reconstructing stage of the conventional holography, as long as the reading wave that satisfies the Bragg condition illuminates the hologram, the reconstructed wave is generated, and the null reconstruction is not possible. In this paper, the light field of the reconstructed waves recorded by the same elliptically polarized waves in polarization holography is deduced, which is based on the tensor polarization holography theory. The conditions for achieving null reconstruction are given. In the recording stage of the experiment, elliptically polarized waves were used, and the recording angle was 136°. In the reconstructing stage, the polarization state of the reading wave is set in advance, and the specific polarized wave was used for reconstruction. The experimental results are in good agreement with the theoretical derivation.
May. 25, 2022Vol. 49 Issue 5 210454 (2022)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20