





 View fulltext
View fulltext
Journal of Electronic Science and Technology
Co-Editors-in-Chief
Zhiming Wang;Yong Wang

2024
Volume: 22 Issue 3
8 Article(s)

Jiang Wu, Yi Shi, Shun Yan, and Hong-Mei Yan
The estimation of pain intensity is critical for medical diagnosis and treatment of patients. With the development of image monitoring technology and artificial intelligence, automatic pain assessment based on facial expression and behavioral analysis shows a potential value in clinical applications. This paper reports a framework of convolutional neural network with global and local attention mechanism (GLA-CNN) for the effective detection of pain intensity at four-level thresholds using facial expression images. GLA-CNN includes two modules, namely global attention network (GANet) and local attention network (LANet). LANet is responsible for extracting representative local patch features of faces, while GANet extracts whole facial features to compensate for the ignored correlative features between patches. In the end, the global correlational and local subtle features are fused for the final estimation of pain intensity. Experiments under the UNBC-McMaster Shoulder Pain database demonstrate that GLA-CNN outperforms other state-of-the-art methods. Additionally, a visualization analysis is conducted to present the feature map of GLA-CNN, intuitively showing that it can extract not only local pain features but also global correlative facial ones. Our study demonstrates that pain assessment based on facial expression is a non-invasive and feasible method, and can be employed as an auxiliary pain assessment tool in clinical practice.
Sep. 25, 2024Vol. 22 Issue 3 100260 (2024)
Shi-Yuan Zhou, Hong-Yu Luo, Ya-Zhou Wang, and Yong Liu
In this work, we theoretically unlock the potential of Ho3+-doped InF3 fiber for efficient ~3.2 μm laser generation (from the 5F4,5S2→5F5 transition), by employing a novel dual-wavelength pumping scheme at 1150 nm and 980 nm, for the first time. Under clad-coupled 1150 nm pumping of 5 W, ~3.2 μm power of 3.6 W has been predicted with the optical-to-optical efficiency of 14.4%. Further efficient power scaling, however, is blocked by the output saturation with 980 nm pumping. To alleviate this behavior, the cascaded 5I5→5I6 transition, targeting ~3.9 μm, has been activated simultaneously, therefore accelerating the population circulation between the laser upper level 5F4,5S2 and long-lived 5I6 level under 980 nm pumping. As a result, enhanced ~3.2 μm power of 4.68 W has been obtained with optical-to-optical efficiency of 15.6%. Meanwhile the ~3.9 μm laser, yielding power of 2.76 W with optical-to-optical efficiency of 9.2%, is theoretically achievable as well with a moderate heat load, of which the performance is even better than the prior experimentally and theoretically reported Ho3+-doped InF3 fiber lasers emitting at ~3.9 μm alone. This work demonstrates a versatile platform for laser generation at ~3.2 μm and ~3.9 μm, thus providing the new opportunities for many potential applications, e.g., polymer processing, infrared countermeasures, and free-space communications.
Sep. 25, 2024Vol. 22 Issue 3 100261 (2024)

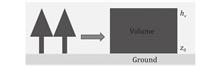
Yin Zhang, and Ding-Feng Duan
We estimate tree heights using polarimetric interferometric synthetic aperture radar (PolInSAR) data constructed by the dual-polarization (dual-pol) SAR data and random volume over the ground (RVoG) model. Considering the Sentinel-1 SAR dual-pol (SVV, vertically transmitted and vertically received and SVH, vertically transmitted and horizontally received) configuration, one notes that SHH, the horizontally transmitted and horizontally received scattering element, is unavailable. The SHH data were constructed using the SVH data, and polarimetric SAR (PolSAR) data were obtained. The proposed approach was first verified in simulation with satisfactory results. It was next applied to construct PolInSAR data by a pair of dual-pol Sentinel-1A data at Duke Forest, North Carolina, USA. According to local observations and forest descriptions, the range of estimated tree heights was overall reasonable. Comparing the heights with the ICESat-2 tree heights at 23 sampling locations, relative errors of 5 points were within ±30%. Errors of 8 points ranged from 30% to 40%, but errors of the remaining 10 points were >40%. The results should be encouraged as error reduction is possible. For instance, the construction of PolSAR data should not be limited to using SVH, and a combination of SVH and SVV should be explored. Also, an ensemble of tree heights derived from multiple PolInSAR data can be considered since tree heights do not vary much with time frame in months or one season.
Sep. 25, 2024Vol. 22 Issue 3 100263 (2024)
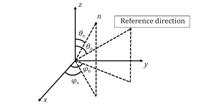
Xiao-Dong Zheng, Sheng-Teng Shi, Jun Ou-Yang, Feng Yang, Qammer Abbasi, and Abubakar Sharif
In this paper, an effective algorithm for optimizing the subarray of conformal arrays is proposed. The method first divides theconformal array into several first-level subarrays. It uses the X algorithm to solve the feasible solution of first-level subarray tiling and employs the particle swarm algorithm to optimize the conformal array subarray tiling scheme with the maximum entropy of the planar mapping as the fitness function. Subsequently, convex optimization is applied to optimize the subarray amplitude phase. Data results verify that the method can effectively find the optimal conformal array tiling scheme.
Sep. 25, 2024Vol. 22 Issue 3 100264 (2024)
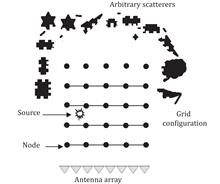
Mahmoud Eissa, and Dmitry Sukhanov
Location awareness in wireless networks is essential for emergency services, navigation, gaming, and many other applications. This article presents a method for source localization based on measuring the amplitude-phase distribution of the field at the base station. The existing scatterers in the target area create unique scattered field interference at each source location. The unique field interference at each source location results in a unique field signature at the base station which is used for source localization. In the proposed method, the target area is divided into a grid with a step of less than half the wavelength. Each grid node is characterized by its field signature at the base station. Field signatures corresponding to all nodes are normalized and stored in the base station as fingerprints for source localization. The normalization of the field signatures avoids the need for time synchronization between the base station and the source. When a source transmits signals, the generated field signature at the base station is normalized and then correlated with the stored fingerprints. The maximum correlation value is given by the node to which the source is the closest. Numerical simulations and results of experiments on ultrasonic waves in the air show that the ultrasonic source is correctly localized using broadband field signatures with one base station and without time synchronization. The proposed method is potentially applicable for indoor localization and navigation of mobile robots.
Sep. 25, 2024Vol. 22 Issue 3 100273 (2024)
Jun-Xian Liu, Yun-Ying Man, Hao Yang, and Peng Yang
This study demonstrates a simple 2-bit phased array operating at 27 GHz that supports one-dimensional beam scanning with left-handed circular polarization (LHCP). The antenna is constructed using a compact four-layer printed circuit board (PCB) structure, consisting of a 90° phase shifter layer with microstrip structures, a ground (GND) layer, a direct current (DC) control layer, and a circularly polarized annular radiation patch layer with 1-bit phase shifting. Based on the proposed unit structure, a 1×8 array with half-wavelength inter-element spacing was designed and validated. Experimental results show that the array achieves a peak gain of 10.23 dBi and is capable of beam scanning within ±50°.
Sep. 25, 2024Vol. 22 Issue 3 100275 (2024)

Designing a sparse array with reduced transmit/receive modules (TRMs) is vital for some applications where the antenna system’s size, weight, allowed operating space, and cost are limited. Sparse arrays exhibit distinct architectures, roughly classified into three categories: Thinned arrays, nonuniformly spaced arrays, and clustered arrays. While numerous advanced synthesis methods have been presented for the three types of sparse arrays in recent years, a comprehensive review of the latest development in sparse array synthesis is lacking. This work aims to fill this gap by thoroughly summarizing these techniques. The study includes synthesis examples to facilitate a comparative analysis of different techniques in terms of both accuracy and efficiency. Thus, this review is intended to assist researchers and engineers in related fields, offering a clear understanding of the development and distinctions among sparse array synthesis techniques.
Sep. 25, 2024Vol. 22 Issue 3 100276 (2024)
Yan Li, Tai-Kang Tian, Meng-Yu Zhuang, and Yu-Ting Sun
Knowledge distillation, as a pivotal technique in the field of model compression, has been widely applied across various domains. However, the problem of student model performance being limited due to inherent biases in the teacher model during the distillation process still persists. To address the inherent biases in knowledge distillation, we propose a de-biased knowledge distillation framework tailored for binary classification tasks. For the pre-trained teacher model, biases in the soft labels are mitigated through knowledge infusion and label de-biasing techniques. Based on this, a de-biased distillation loss is introduced, allowing the de-biased labels to replace the soft labels as the fitting target for the student model. This approach enables the student model to learn from the corrected model information, achieving high-performance deployment on lightweight student models. Experiments conducted on multiple real-world datasets demonstrate that deep learning models compressed under the de-biased knowledge distillation framework significantly outperform traditional response-based and feature-based knowledge distillation models across various evaluation metrics, highlighting the effectiveness and superiority of the de-biased knowledge distillation framework in model compression.
Sep. 25, 2024Vol. 22 Issue 3 100278 (2024)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20