







Please enter the answer below before you can view the full text.
8+6=

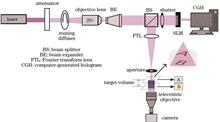
Given the problems of cumbersome steps and low effectiveness of the present double-sided microdevice processing technique, a holographic double-sided photolithography based on the enhanced Gerchberg-Saxton (GS) algorithm is proposed, which employs a single light source to achieve a double-sided pattern produced by single exposure on the upper and lower surfaces of the glass substrate. This approach realizes double-sided pattern reproduction in the target space by determining the combined holograms corresponding to various axial position patterns and loading them onto a spatial light modulator (LCOS-SLM) to regulate the incident light field. The holographic reconstruction of patterns A and B at distances of 2 mm and 4.06 mm from the focal plane, respectively, is calculated and simulated using the modified GS method. The experimental device was set up to achieve the simultaneous exposure of the upper and lower surfaces of the 3-mm thick transparent quartz glass substrate, and the problems of speckle, stray light, and crosstalk in the process of light field generation were examined and solutions were proposed, and finally 60-μm linewidth double-layer pattern exposure was realized, which confirm the feasibility of the proposed method for double-sided lithography. A single hologram and a single light source are used in the technique described in this research to create numerous layers of arbitrary images in the target volume during a single exposure, considerably simplifying the processes involved in producing double-sided pictures.
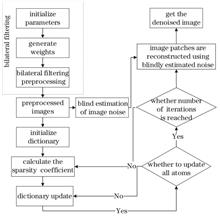
Synthetic aperture radar (SAR) images are contaminated by multiplicative noise during the imaging process because of flaws in SAR's innate imaging mechanism; the image noise makes it difficult to analyze targets and detect changes. Existing denoising algorithms cannot adaptively estimate the noise size, and the edge preservation effect is not ideal. Additionally, it can be difficult to work out how to adaptively analyze images with different noise sizes. As a result, this work proposes a sparse denoising algorithm for SAR images based on bilateral filtering and blind estimation. First, bilateral filtering was employed to obtain preprocessed images with good edge-preserving properties, and then the blind estimation was utilized to determine the global noise level of the images, which acted as a residual threshold in the sparse reconstruction process. To achieve the goal of image denoising, sparse coding and dictionary learning algorithms were employed for representing the image using the least amount of atomic information possible. The experimental findings demonstrate that the sparse reconstruction algorithm combined with blind estimation not only effectively removes image noise and improves the equivalent numbers of looks, but also performs well for peak signal-to-noise ratio and edge-preserving index, effectively preserving the detailed texture information of the original image.
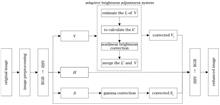
An adaptive enhancement algorithm based on nonlinear global brightness correction is proposed for leaf disease images with uneven illumination. First, the original image is preprocessed by Gaussian filtering and adaptive equalization, and the color space is transferred to HSV. The multi-scale Retinex algorithm is used to estimate the light component of the V component. Combining the optimal segmentation threshold of the bright and dark areas calculated by the maximum between class variance segmentation method (OTSU) and the constructed nonlinear brightness correction function, the brightness of the bright and dark areas is adaptively adjusted, and then the corrected V component is obtained by merging with the original V component. Gamma correction is performed on the S component of HSV space, and the reconstructed image is restored to RGB image. The experimental results show that the algorithm can effectively reduce the impact of uneven lighting on the image, guarantee the adaptive enhancement of bright areas while enhancing dark areas, and improve the image clarity and brightness uniformity. Compared with the contrast limited adaptive histogram equalization algorithm (CLAHE), nonlinear correction algorithm and color restoration multi-scale Retinex algorithm (MSRCR), it has better performance in terms of average gradient, information entropy, peak signal-to-noise ratio, and structure similarity.
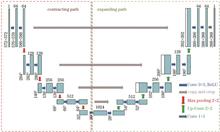
To solve the problem of the phase recovery of a single electronic speckle interferometric fringe pattern, we propose a USS-Net, which combines a subpixel convolution module and a structured feature enhancement module to realize end-to-end phase recovery of a single fringe pattern using U-Net as the basic network. First, the upsampling method of U-Net is improved, and the subpixel convolution module is used to make the proposed network learn more fringe details while reducing the influence of deconvolution zero filling on gradient calculation. Second, in the coding part, the feature fusion method of U-Net is improved, and the structured feature enhancement module is used to fully integrate feature information with different scales. Hence, the proposed method can solve the problem of poor feature extraction caused by uneven fringe density and increase the segmentation accuracy for a single pixel point. The electronic speckle pattern interferometry (ESPI) fringe-phase simulation and experimental datasets are established, and the USS-Net model is tested and analyzed to verify the effectiveness of the proposed method. The proposed method overcomes the shortcomings of traditional phase recovery methods, such as cumbersome processes and high susceptibility to noise disturbance, and effectively increases the accuracy of phase recovery of a single fringe pattern.
Generally, Shannon defined information entropy is used to measure information uncertainty, whereas, Onicescu defined information energy is used to measure information certainty. However, information energy and Shannon entropy display a dual relationship. Furthermore, the cumulative residual entropy is employed to estimate the information uncertainty by replacing the probability distribution function of Shannon entropy with the cumulative distribution function. Based on this, a new method to measure information certainty—cumulative residual information energy—is proposed and applied to image threshold segmentation. To overcome the shortcomings of complex calculation and the low efficiency of accumulated residual information energy, a recursive algorithm is used here to increase the running speed of image threshold segmentation. Our experimental results show that the proposed method outperforms the classical maximum entropy threshold method and other related threshold segmentation methods used for natural images and cell blood smear images.
Identification of fish epidemics by the naked eye depends on the experience of diagnostic personnel. Moreover, the epidemic data has such fine granularity problems as small gaps between categories and low recognition efficiency. Usually, the Transformer requires a large amount of data for training due to the lack of inductive bias in convolutional neural networks (CNN). In addition, the model's classification accuracy is restricted by insufficient global feature extraction and the weak generalization performance of CNN. In this study, based on the global interaction of all pixels in the feature map, an algorithm model is developed, and a fish epidemic recognition model (CViT-FDRM) using the combination of CNN and a Vision Transformer is suggested. First, FishData01, a database of fish epidemics, is set up. Second, CNN is used to extract the fine-grain features of fish images, and the Transformer model self-attention mechanism is used to acquire the global information of images for parallel training. Then, the group normalization layer is utilized to group the sample channels to compute the mean and standard deviation. Finally, 404 fish epidemic images were used for testing, and CViT-FDRM obtained 97.02% recognition accuracy. The experimental results on Oxford Flowers, an open-source database of fine-grained images, reveal that CViT-FDRM has greater classification accuracy than that of the standard fine-grained image classification algorithm, reaching 95.42%, which is 4.84 percentage points higher. Therefore, CViT-FDRM can perform well in fine-grain image recognition.
Hyperspectral images (HSI) are vulnerable to interference from the environment or the equipment during the acquisition process, causing a significant loss of remote sensing data. Therefore, hyperspectral image denoising is a fundamental issue in image preprocessing. In this paper, a denoising algorithm is designed, which divides HSI into local equal blocks and uses low-rank matrix constraints to characterize the local features. Moreover, the designed algorithm uses truncated nuclear norm minimization and global spatial-spectral total variation regularization to separate sparse and high-density noise, while maintaining spatial-spectral smoothness. The combination of the two methods can effectively remove mixed noises, including Gaussian and salt and pepper noises. The proposed optimization algorithm is compared with four recently published denoising algorithms, showing that the average structure similarity and average peak-signal-to-noise ratio are improved by 0.13 and 1.10 dB, respectively. Application of algorithms to a single noise with different intensity demonstrates that the average structure similarity is also improved by 0.10. The proposed method demonstrates a distinct noise removal effect in the amplification and contrast of actual images. Experimental results show that the proposed method is close to the local feature representation of hyperspectral images, which combined with the global regularization method, can facilitate a more obvious denoising effect and eliminate high-density and sparse noises.
Aiming at solving the problems of fogging, blurring and color distortion in underwater images, an underwater image restoration method is proposed based on total variation and color balance. Depending on the complete underwater optical imaging model, the background light is estimated by combining the quadtree subdivision algorithm and the propagation characteristics of light in water, the transmittance is estimated by using the underwater median dark channel prior, and the fuzzy kernel is estimated by using the conjugate gradient and iterative least square method. In order to improve the computational efficiency, the alternating direction multiplier method is introduced to inverserly solve the variational energy equation to obtain a haze-free and deblurred image. In addition, a color balance algorithm is proposed to compensate color channel in YCbCr space for correcting color distortion. Compared with six popular underwater image enhancement and restoration methods, the experimental results show that the proposed method can effectively remove fog and blur, correct color deviation, and restore a clear and true color underwater image.
Existing pedestrian target detection algorithm based on visible light and infrared modal fusion has a high missed detection rate in all-weather environment. In this paper, we propose a novel multi-modal pedestrian target detection algorithm based on illumination perception weight fusion to solve this problem. First, ResNet50, incorporating an efficient channel attention (ECA) mechanism module, was used as a feature extraction network to extract the features of both visible light and infrared modes, respectively. Second, the existing illumination weighted sensing fusion strategy was improved. A new illumination weighted sensing fusion mechanism was designed to attain the corresponding weights of the visible light and infrared modes, and weighted fusion was performed to achieve fusion features to reduce the missed detection rate of the algorithm. Finally, the multi-modal features extracted from the last layer of the feature network and the generated fusion features were fed into the detection network to accomplish the detection of pedestrian targets. Experimental results show that the proposed algorithm has an excellent detection performance on the KAIST dataset, and the missed detection rate for pedestrian targets in all-weather is 11.16%.
Aiming at the problems of insufficient target extraction and loss of details in infrared and visible image fusion algorithm, an infrared and visible image fusion method based on improved region growing method (IRG) and guided filtering is proposed. First, use IRG to extract targets from infrared images, then use NSST for infrared and visible images, and conduct guided filtering for the obtained low-frequency and high-frequency components. The filtered infrared and visible low-frequency components get low-frequency fusion coefficients through IRG based fusion rules, and the enhanced high-frequency components get high-frequency fusion coefficients through dual-channel spiking cortical model (DCSCM). Finally, the fused image is obtained by NSST inverse transform. The fused image is evaluated with subjective evaluation and 6 common objective evaluation indexes. The experimental results show that the proposed algorithm has obvious advantages in subjective and objective evaluation, such as prominent target, clear background information, strong detail retention ability.
A hyperspectral image classification method based on superpixel segmentation and the convolutional neural network (CNN) is proposed to address the issues of low utilization of spatial-spectral features and low classification efficiency of CNN in hyperspectral image classification. First, the first three principal components were filtered after extracting the first 12 image components utilizing the principal component analysis (PCA), and the three filtered bands were then subjected to superpixel segmentation. Sample points were then mapped within the hyperpixels, enabling it to select superpixels rather than pixels as the basic taxon. Finally, the CNN was used for image segmentation. Experiments on two public datasets, WHU-Hi-Longkou and WHU-Hi-HongHu, show improved accuracy obtained by combining spatial-spectral features compared to using only spectral information, with classification accuracy of 99.45% and 97.60%, respectively.
For the inpainting of the images of textile cultural relics at the damaged parts, an improved algorithm is pro-posed based on K-means color segmentation and Criminisi algorithm. Due to the characteristics of textile cultural relics images, RGB images were converted into Lab color model, and K-means classifier was used to segment a* and b * layer data according to their colors to calibrate the edges of the patterns and narrow the search area of matching blocks. The standard deviation of L value was introduced to represent the color dispersion and the priority function and adaptive matching block were improved.The proposed algorithm and the three algorithms reported in the literature were used to repair the image of natural damaged textile relics and man-made damaged textile images, and the restoration results were evaluated. The experimental results show that the image restored by the proposed algorithm has natural texture, reasonable structure, and better peak signal-to-noise ratio, structural similarity, feature similarity, mean square error values.
An infrared and visible image fusion method based on saliency target extraction and Poisson reconstruction is proposed to address the problems of incomplete saliency target, blurred edges, and low contrast in the fusion process of infrared and visible images in a low illumination environment. First, the saliency target was extracted using the correlation of saliency detection, threshold segmentation, and Gamma correction, which is based on the difference in saliency intensity between infrared image pixels, to separate the target from the background in infrared images. Second, the visual saliency features and gradient saliency of the source images were considered, and fused images were reconstructed by solving the Poisson equation in the gradient domain. Finally, the mean and standard deviation of the infrared images were used to optimize the fused images, thereby improving the quality of the results in a low illumination environment. Experimental results show that the proposed method is superior to other comparison methods in terms of subjective and objective evaluation performances. Moreover, the proposed method can better highlight infrared target information, retain rich background information, and have remarkable visual effects.
An innovative image fusion model combining convolutional neural network (CNN) and Transformer is proposed to address the issues of the CNN's inability to model the global semantic relevance within the source image and insufficient use of the image context information in infrared and visible image fusion field. First, to compensate for the shortcomings of CNN in establishing long-range dependencies, a combined CNN and Transformer encoder was proposed to improve the feature extraction of correlation between multiple local regions and improve the model's ability to extract local detailed information of images. Second, a fusion strategy based on the modal maximum disparity was proposed for better adaptive representation of information from various regions of the source image during the fusion process, enhancing the fused image's contrast. Finally, by comparing with multiple contrast methods, the fusion model developed in this research was experimentally confirmed using the TNO public dataset. The experimental results demonstrate that the suggested model has significant advantages over existing fusion approaches in terms of both subjective visual effects and objective evaluation metrics. Additionally, through ablation tests, the efficiency of the suggested combined encoder and fusion technique was examined separately. The findings of the experiments further support the effectiveness of the design concept for the infrared and visible image fusion assignments.
This study aimed to resolve the issue of information missing during the reconstruction of complex objects using existing line structured light. Herein, we have examined the mechanism of information incompleteness caused by occlusion along with the relationship between the parameters of the line structured light system and the occlusion incompleteness quantitatively. Furthermore, a new method for cross-complementary reconstruction of long and short baseline structured light is proposed. Based on the binocular line structured light hardware equipment, three sets of line structured light systems are created, which have a binocular long baseline and left and right monocular short baselines, conducting image acquisition and three-dimensional (3D) reconstruction of objects. The reconstruction result integrates the left-eye and right-eye images and binocular reconstruction findings, accomplishing information filling and resolving the problem of information loss effectively while performing 3D reconstructions for objects with complex surfaces using line structured light. The experimental results demonstrate that compared with the traditional binocular structured light, the reconstruction missing threshold of the proposed binocular line structured light fusion reconstruction technology is reduced from 4.28 mm to 2.14 mm, the information reconstruction integrity rate is enhanced from 88% to 92%. And we collected objects such as chargers, boxes, and development boards, moreover, this study shows that up to 94% of the information can be rebuilt. Thus, the proposed binocular line structured light fusion reconstruction technology increases the integrity of information acquisition and expands the application range without altering the hardware of binocular line structured light.
The complex structure, small projection ratio, and large field-of-view of the catadioptric ultrashort-throw optical projection imaging system are result in slow convergence speed of optimized aberration. Hence, we proposed a design for an ultrashort-throw optical projection imaging system based on catadioptric coupling point herein. The deviation between the ideal and observed coupling points determined by calculating the position of the light coupling point at an aperture as well as the each field-of-view between the refracting lens set and the concave mirror in the proposed optical system is used as an evaluation function to optimize the aberration. Moreover, the forward and reverse designs are combined to effectively increase the optimization efficiency of the proposed optical system. Using this technique, we designed an ultrashort-throw projection lens that can project a 100 inch (2540 mm) size picture at 486 mm, with TV distortion of less 0.2% and modulation transfer function (MTF) of each field-of-view of more 0.5 at 117-lp/mm cutoff frequency.
Due to the non-contact, simple structure, high sampling rate, high security, and high resolution, optical tomography technology has been widely used in the fields of industrial fluid monitoring and medicine and has significant research value in the academic field. Optical tomography concludes scanning stage and image reconstruction stage. In the stage of image reconstruction, the performance of the algorithm determines the performance of image reconstruction. Aiming at the problems of slow reconstruction speed and poor reconstruction quality, this paper proposes the improved Landweber reconstruction algorithm based on preset matrix. In the improved algorithm, the historical iteration information is considered, and preset matrix and acceleration term are introduced in the iteration process. In this paper, five specific distributions in the circular measurement field are used for experimental simulation, and the performance of the proposed improved algorithm is compared with that of the traditional algorithm. The results show that the performance of the proposed algorithm is significantly improved. The reconstruction error of the proposed algorithm is about 5%, which has been reduced by 48%. The quality of the reconstructed image is also significantly improved.
Bonnet polishing is widely used for processing aspherical optical components with nanometer surface roughness and submicrometer shape accuracy. The traditional bonnet tool wear detection method is expensive, time consuming, and has low efficiency. This study proposes a wear detection method for bonnet tools based on a splicing data acquisition platform and an improved iterative closest point (ICP) splicing algorithm. This method calculates the extent of wear in large bonnet tools using point cloud splicing and a bonnet wear detection algorithm. The point cloud preprocessing for mosaic data is conducted using voxel down sampling and radius filtering. A good initial registration transformation matrix is obtained using the splicing detection data acquisition platform. Finally, point cloud precise registration is realized using the bidirectional K-D tree nearest neighbor search combined with the ICP algorithm. Experimental results demonstrate that the stitching algorithm proposed herein can greatly enhance registration efficiency while ensuring registration accuracy. Moreover, it does not affect the accuracy of subsequent bonnet wear detection, which guarantees wear detection of large bonnet tools.
To solve the problems of lack of depth information and poor detection accuracy in conventional monocular three-dimensional (3D) target detection algorithms, an algorithm for multiscale monocular 3D target detection incorporating instance depth is proposed. First, to enhance the processing ability of the model for targets with different scales, a multiscale sensing module based on hole convolution is designed. Then, the depth features containing multiscale information are refined from both spatial and channel directions to remove the inconsistencies among different scale feature maps. Further, the instance depth information is used as an auxiliary learning task to enhance the spatial depth characteristics of 3D objects, and the sparse instance depth is used to monitor the auxiliary task, thereby improving the model's 3D perception. Finally, the proposed algorithm is tested and validated on the KITTI dataset. The experimental results show that the average accuracy of the proposed algorithm in the vehicle category is 5.27% higher than that of the baseline algorithm, indicating that the proposed algorithm effectively improves the detection performance compared with the conventional monocular 3D target detection algorithms.
To resolve the problem of high false alarm rate and low detection rate caused by the failure of existing background suppression algorithms in effectively suppressing complex backgrounds, a small target detection algorithm based on six-direction gradient difference anisotropic Gaussian filter suppression, double-layer orthogonal gray difference and diagonal gray difference target enhancement, and gray index adaptive threshold segmentation is proposed herein. First, a series of background suppression strategies are created using the Gaussian filtering technology and gradient difference concept. Then, the suppressed image is mapped on a double-layer sliding window using orthogonal gray difference and diagonal gray difference to enhance its local contrast as well as improve its target saliency. Finally, the real weak target is detected using the adaptive segmentation algorithm of the pixel gray index. Experimental results show that the background suppression factor index of the algorithm increases to 93%, and it can modify a background suppression model based on the local changes in the background to adaptively suppress prominent targets in complex backgrounds.
To overcome the low efficiency of traditional methods in detecting construction building flatness and the considerable influence of human factors on these detection results, this study proposes a flatness-detection method based on three dimensional (3D) laser scanning. First, a 3D laser scanner was used to collect, process, and stitch the data related to the target building to obtain high-precision 3D point-cloud data. Second, based on the characteristics of the building flatness, a nonuniform thinning method was designed to preserve the concave and convex characteristics of the wall. Third, the random sampling consistency algorithm and the eigenvalue method were used to automatically extract and fit point-cloud data related to the building to obtain the geometric parameters of each wall to be detected. Finally, a flatness-detection method for construction buildings employing 3D laser scanning was designed based on the topological-spatial relationship between a fitting plane and the point cloud data. The results of this study show that the proposed nonuniform thinning method can effectively realize the thinning of point-cloud data. In addition, the data thinning ratio reaches 55.4 % and the concave and convex characteristics of the wall surface can be preserved without loss. Furthermore, the proposed flatness detection method is theoretically feasible, exhibits reliable accuracy, and achieves a detection efficiency that is 23.33% higher compared with that achieved by traditional detection methods.
The original point cloud obtained directly by equipment such as laser scanners is usually affected by noise, which will affect subsequent processing, such as three-dimensional reconstruction and semantic segmentation; as a result, the point cloud denoising algorithm becomes particularly crucial. The majority of currently available point cloud denoising networks use the distance between noise and clean points as the objective function during iterative training, which may cause point cloud aggravation and outliers. To address the above issues, a new denoising network called multiscale score point (MSPoint) based on multiscale point cloud distribution fraction (i.e., the gradient of point-cloud logarithmic probability function) is proposed. The displacement prediction and feature extraction modules make up the majority of the MSPoint network. Input the neighborhood of the point cloud in the feature extraction module and strengthen the antinoise performance of MSPoint by adding multiscale noise disturbance to the data, thereby leading the extracted features to have a stronger expression ability. According to the fraction predicted by the fraction estimation unit, the displacement prediction module iteratively learns the displacement of noise points. MSPoint provides stronger robustness than previous approaches and a superior denoising impact, according to experimental results on public datasets.
Shaft-in-hole assembly is an essential basic problem in the field of industrial manufacturing. Aiming at its issues of narrow space visual challenges, easy collision damage, low manual assembly efficiency, and other problems, this paper suggests a detection scheme based on binocular vision that uses image fusion to expand the monitoring field-of-view and evaluate assembly parameters through the intersection of shaft and hole. Furthermore, the fusion weight of the binocular data at various positions is optimized according to the reprojection error, which reduces the error by about 10% and ensures the measurement accuracy while realizing fast detection. The experimental findings demonstrate that the suggested method is capable of real-time detection during the assembly process of shafts with small clearance holes and small diameters with a gap of 0.25 mm and an average inaccuracy of roughly 0.015 mm. At the same time, the suggested approach has a strong robustness in various camera installation sites and is not sensitive to the camera's tilt angle.
Traditional camera calibration methods with a circular array target typically use the center of the ellipse as the control point coordinate, ignoring distortion from projective effects and introducing systematic errors into the calibration process. Therefore, we propose an accurate camera calibration method based on perspective distortion correction. Herein, first, the camera was coarse calibrated using the center of the ellipse. Second, using the coarse calibration parameters, the projective transformation corresponding to the camera's pure rotation was determined, and the ellipse parameters were directly changed to yield the true projected center of the circle. Finally, we used the obtained center to perform fine camera calibration. According to the simulation and experimental results, the suggested technique significantly reduces the reprojection error and parameter standard deviation of camera calibration; it can meet the simple, high-precision criteria of camera calibration for industrial vision measurement.
The shape and structure of nonspherical objects are complex, and it is easy to mismatch when using point clouds for direct registration. Aiming at this problem, the geodesic distance on the manifold is introduced here along with the actual geometric shape of the object. Additionally, the three-dimensional (3D) point cloud registration problem is converted into a clustering problem, and a multisite cloud registration method based on manifold clustering is proposed. First, the 3D point cloud after rough registration was divided into several clusters. Then, the geodesic distance was used as the basis of cluster division to update the cluster center while updating the rigid transformation simultaneously. The process was repeatedly iterated to obtain the final registration result. Finally, in the registration process, the geodesic distance matrix calculation easily generated a computational consumption, and the thermal gradient method was applied to transform the traversal process of point sets in space into a Poisson equation solution to improve efficiency and complete the multisite cloud registration. Experimental results on Bunny, Dragon, and other point cloud data in the Stanford University public dataset show that the proposed method can effectively improve the registration accuracy of nonspherical objects by 20%-30%.
Multi-frequency-phase-shift structured light illumination scanning along two-direction will achieve higher robustness, but it increases time spending on scanning and computing. This paper proposes an improved coding and decoding strategy for scanning along two-direction by means of epipolar geometry. First, after scanning along vertical direction and getting unwrapped vertical phase, the temporary horizontal phase is obtained according to unwrapped vertical phase and epipolar geometry of system. Then, after scanning along vertical direction and getting wrapped horizontal phase, unwrapped horizontal phase is obtained by using temporary unwrap algorithm. Finally, a line-model is established between the camera and projector. When calculating a 3D point cloud, the intersection point of the camera line of sight and the projector line of sight is calculated, avoiding the traditional matrix inversion method and improving the point cloud calculation speed. The experimental results show that: 1) the root mean square error of final lateral phase is 4.89×10-3; 2) the computation speeds of 3D point cloud after scanning along two-direction and scanning along one-direction are improved by 6.08 times and 4.10 times, respectively; 3) the proposed 3D point cloud reconstruction method for scanning along one-direction is within the error range of 10-11 mm compared with the traditional method.
To improve the current low efficiency process in artificial defect detection on aero-engine surface, a YOLOv5-CE model, based on improved YOLOv5, is proposed. First, the data enhancement strategy search algorithm is integrated into the network to automatically search the best data enhancement strategy for the current dataset to improve the training effect. Second, the coordinate attention mechanism is introduced into the backbone network while the coordinate information is embedded on the basis of channel attention to improve detection of small defect targets. Finally, the location loss function of YOLOv5 is improved to efficient intersection over union loss which can accelerate the model convergence and improve the precision of prediction box regression. Experimental results show that compared with the original YOLOv5s network, the proposed YOLOv5-CE model improves the mean average precision by 1.2 percentage points to 98.5% and can efficiently, as well as intelligently, detect four common types of defects in aero-engines.
Herein, we present a novel keypoint distance learning network, which utilizes geometric invariance information in pose transformation. Distance estimation is added to the network and robust keypoints are determined, which improves the pose estimation accuracy within six degrees of freedom based on deep learning. The proposed method consists of two stages. First, a keypoint distance network is designed, which achieves RGB-D image feature extraction using a backbone network module and a feature fusion structure and predicts the distances of each point relative to the keypoints, semantics, and confidence using a multilayer perceptron. Second, based on the visual point voting method and the four point distance positioning method, keypoint coordinates are calculated using the multi-dimensional information output from the network. Finally, object poses are obtained through the least square fitting algorithm. To prove the effectiveness of the proposed method, we tested it on public datasets LineMOD and YCB-Video. Experimental results show that the network parameters of this method can be reduced by 50% with improved accuracy compared to ResNet in the original PSPNet framework, with accuracy improvements of 1.1 percentage points and 5.8 percentage points on two datasets, respectively.
Multi-view stereo matching is a major hotspot in the field of computer vision. We propose a self-attention-based deep learning network (SA-PatchmatchNet) to address the issues of poor completeness of multi-view stereo reconstruction, inability to process high-resolution images, huge GPU memory consumption, and long running time. First, the feature extraction module extracted the image features and sent them to the learnable Patchmatch module to obtain the depth map, and then the depth map was optimized to generate the final depth map. Moreover, the self-attention mechanism was integrated into the feature extraction module to capture the important information in the deep reasoning task, thereby enhancing the network feature extraction ability. The experimental results show that the reconstruction completeness is improved by 5.8% and the entirety is improved by 2.3% compared with that of the PatchmatchNet when the SA-PatchmatchNet is tested on the Technical University of Denmark (DTU) dataset. The completeness and entirety of the proposed network are significantly improved compared with that of the other state-of-the-art (SOTA) methods.
The process of feeding wolfberry into betel nut still needs to be accomplished manually by workers, which has low production efficiency and food safety issues. To address this problem, betel nut pose recognition and positioning system based on structured light three-dimensional (3D) vision is designed. First, a digital projector projects blue sinusoidal fringe patterns onto betel nuts, and once the deformed fringe images are acquired, the computer performs 3D reconstruction to obtain a high-precision betel nut point cloud. Subsequently, two-dimensional (2D) image and 3D point cloud information are fused, and the proposed feature line method is used to estimate the betel nut pose parameters. Finally, the center of the betel nut cavity is positioned as the feeding point, which is subsequently converted to the base coordinate system of a robot arm according to hand-eye calibration to complete automatic feeding. Experiments on pose recognition and localization were conducted using 500 betel nuts, and both processing time and classification accuracy were evaluated. Results show that the processing time of one betel nut is 0.39-0.59 s. The overall recognition accuracy is 95.6%. The localization error for the feeding point is within 0.25 mm, which is lower than the 0.3 mm required for feeding. This demonstrates that the proposed method can effectively solve the problem of attitude recognition and positioning of freely placed targets within complex shapes and has high positioning accuracy and good stability to meet the actual production requirements.
In this study, a retrieval method based on complex Flex-Bootstrap and multi-convolution neural network (Multi-CNN) and deep neural network (DNN) fusion model is proposed to solve the problems of low efficiency and low accuracy of traditional similarity matching retrieval methods due to single sample and unbalanced data in protein mass spectrometry data retrieval research. Here, we compared our proposed method with the DNN model, CNN, and DNN fusion model. Furthermore, the Flex-Bootstrap method combined with the Multi-CNN and DNN fusion model has achieved promising results when applied in the prediction of protein mass spectrum data types. Experimental results revealed that the test set's accuracy was increased to 98.82%, and the loss function value was reduced to 0.0397. Therefore, this model not only effectively solves the problem of underfitting in data retrieval using the DNN model and CNN and DNN fusion model, but also enhances the accuracy of prediction and the search efficiency of the mass spectrometry database.
Scratches are commonly found defects in optical glasses, which degrade their beam quality, enhance the thermal effect, and reduce resistance to laser damage. Therefore, accurate detection and characterization of scratches is critical during processing. In this study, an optical glass with a scratch depth of 70 nm was selected as the detection sample. The optical glass scratch information was loaded by light waves using an optical interference method. Then the interference fringe image was processed and edge-detected, and finally the actual scratch depth value was obtained. Experimental results show that the relative error observed for the 70 nm scratch depth of optical glass using optical interferometry is less than 1%. Thus, the proposed method provides a detection method for the scratch depth value in the order of tens of nanometers during optical glass processing.
This paper addresses the challenges of high model complexity and low classification accuracy in remote sensing image classification using convolutional neural networks. To overcome these challenges, a modified DeeplabV3+ network is proposed, which replaces the deep feature extractor in the encoder with lightweight networks MobilenetV2 and Xception_65. The decoder structure is also modified to feature fusion layer by layer in order to refine the up-sampling process in the decoding region. In addition, a channel attention module is introduced to strengthen the information association between codecs, and multiscale supervision is used to adapt the receptive field. Four networks with different encoding and decoding structures are constructed and verified on the CCF dataset. The experimental results show that the MS-XDeeplabV3+ network, which uses Xception_65 in the encoder and layer by layer connection, channel attention module, and multiscale supervision in the decoder, has reduced number of model parameters, faster training speed, refined edge information for ground objects, and improved classification accuracy for grassland and linear ground objects such as roads and water bodies. The overall pixel accuracy and Kappa coefficient of the MS-XDeeplabV3+ network reach 0.9122 and 0.8646, respectively, which show the best performance among all networks in remote sensing image classification.
At present, a water extraction technology is good at extracting medium- and low-resolution remote sensing images; however, when applied to high-resolution images in small water bodies, it is prone to the influence of mixed image elements, foreign body common spectrum, and shadow, resulting in misjudgment. In view of the simultaneous problems of large and small water bodies in high-resolution images, to quickly extract large water bodies and effectively avoid the impact of shadows in the extraction of small water bodies, multiscale segmentation and spectral difference segmentation are used to extract large water bodies. Consequently, a novel water extraction method based on the combination of light green ratio (LGR) and object is proposed for the impact of small water body shadows. The effectiveness of the proposed method is validated in comparison with methods such as decision tree, support vector machine, random forest, normalized difference water index + near infrared (NDWI+NIR), and convolution neural network, as a result, the accuracy for extracting water bodies is 94.86%, 88.85%, 87.15%, 88.8%, 91.46%, and 92.42% respectively, indicating its higher extraction accuracy for large and small water bodies in high-resolution images and better extraction efficiency than the comparison methods through segmentation of different scales.
The detection performance of Top-Hat is limited by a fixed single structural element, resulting in poor suppression for complex background. This paper proposes two improved Top-Hat algorithms with a progressive relationship. First, the Top-Hat transform is enhanced according to the gray value difference between small targets and their neighborhoods, and a Top-Hat algorithm with two structural elements is demonstrated. The structural elements are designed for dilation and erosion operations, and the operation sequence of the open operation is adjusted to get better the detection performance for small infrared targets. Based on the upgraded method, a Top-Hat infrared small target detection method with adaptive dual structure based on local contrast is present. The prior information can be obtained, and the size of the dual structure elements can be adaptively changed by calculating the local contrast to obtain the saliency map. The gray value difference between the target region and its neighborhood is used to suppress the background and enhance the target. The results show that the proposed adaptive Top-Hat method based on local contrast performs best in the five evaluation indexes compared with similar and non-similar methods.
Road information extracted from remote sensing images is of great value in urban planning, traffic management, and other fields. However, owing to the complex background, obstacles, and numerous similar nonroad areas, high-quality road information extraction from remote sensing images is still challenging. In this work, we propose HSA-UNet, a road information extraction method based on mixed-scale attention and U-Net, for high-quality remote sensing images. First, an attention residual learning unit, composed of a residual structure and an attention feature fusion mechanism, is used in the coding network to improve the extraction ability of global and local features. Second, owing to roads with the characteristics of large spans, narrowness, and continuous distribution, the attention-enhanced atrous spatial pyramid pooling module is added to the bridge network to enhance the ability of road features extraction at different scales. Experiments were performed on Massachusetts roads dataset, and the results showed that HSA-UNet significantly outperformed D-LinkNet, DeepLabV3+, and other semantic segmentation networks in terms of F1, intersection over union, and other evaluation indicators.
Massive point-cloud data involve considerable difficulties in storage, transmission, and processing. To address the problem that existing algorithms cannot consider the surface area, volume, or reconstruction error of the reconstructed model after feature preservation and simplification, we propose a point-cloud simplification algorithm based on the location features of neighboring points. The algorithm simplifies the target point-cloud according to the weight calculation projection plane, search matrix size, and reduction ratio. To mesh the target point-cloud, we find the vertical direction of the projection plane (positive and negative directions), take the target point as the center, and obtain the points within the search matrix. The weight value is determined according to the position relationship between the point in the search matrix and the target point, and the original point-cloud is reduced according to the reduction ratio set. The proposed algorithm is compared with curvature sampling, uniform grid, and random sampling methods, and is evaluated in terms of feature retention, surface area, and rate of change of volume. Experimental results show that the reductions performed by the proposed algorithm are better than those provided by the uniform grid and the random sampling methods for feature regions,and are consistent with the curvature sampling method. The reduction causes the error, surface product difference, and volume difference of the reconstructed model to be generally superior to those of the curvature sampling method, consistent with the random sampling method, and slightly inferior to those of the uniform grid method. Therefore, the proposed algorithm not only preserves features, but also reduces the variation and error in the surface area and volume of the reconstructed model.
Aiming at the characteristics of a low signal-to-clutter ratio and low false alarm rate in infrared small target detection under different background conditions and focusing on the characteristics of small target energy approaching Gaussian distribution, this paper proposes an infrared small target detection method using improved image local entropy weighted multi-scale based on the image block contrast. First, the mean values of infrared image center blocks and neighborhood blocks were calculated. Thereafter, the mean difference between the center block and the neighborhood block was calculated to highlight small targets and suppress background noise. At the same time, the improved local image entropy of each pixel was calculated to highlight small targets, suppress pseudo targets whose shape is similar to the size of small targets, and suppress corners of large interfering objects. Afterward, the improved image entropy was used to weight the difference between the mean value of the center block and the neighborhood block to obtain a saliency image with a high signal-to-clutter ratio and low false alarm rate. Finally, the adaptive threshold segmentation algorithm was used to obtain the position of the target. The experimental results show that the proposed method is more applicable to a wider range of scenarios than the similar detection methods based on human visual system (HVS), especially in complex backgrounds, and can achieve a lower false alarm rate and higher signal-to-clutter ratio.
Camera calibration is essential in photogrammetry and computer vision. Herein, the application and classification of camera calibration are first introduced. Subsequently, the theoretical basis of calibration is summarized, including spatial coordinate system transformation, geometric imaging model, internal and external parameter calculation methods, and camera calibration methods described based on classical and intelligent aspects. Conventional calibration methods include reference object-based, active vision, and self-calibration methods. Then, a comprehensive analysis of their advantages and disadvantages is provided. Meanwhile, in intelligent calibration, error backpropagation, multilayer perceptrons, and convolution neural networks are involved. The typical indexes used to evaluate camera calibration methods are summarized. Finally, a summary is provided, and the development direction of camera calibration technology is discussed, which can provide a reference for researchers investigating camera calibration.
The development of silicon-based optoelectronics technology can integrate discrete active and passive components in the transmitting module and receiving module of the LiDAR system on the chip, making the LiDAR smaller in size, more stable and lower in cost, and accelerating the application of LiDAR in autonomous driving and other fields. In this paper, the basic concept and principle of LiDAR is first analyzed. Then, according to the different scanning modes, the LiDAR on silicon substrate is divided into four categories: array flash, optical phased array, lens-assisted beam steering, and slow light grating. The technical characteristics and recent progress of these four categories are described respectively. Finally, the development trend of LiDAR on silicon substrate is summarized and prospected.
Optical coherence tomography (OCT) is a new imaging technique widely used in ophthalmic disease diagnosis and other measurement and detection fields. A swept source OCT (SS-OCT), as a main technical path of OCT, has become the research focus in the field of OCT in recent years because of its advantages of fast imaging speed, deep depth, and high resolution. Because the performance of SS-OCT is mainly determined by the performance of the frequency swept laser, the research and development of the frequency swept laser are very important. This paper mainly summarizes the research progress of frequency swept laser. From the aspects of technical means, design ideas, performance indicators, etc., the research progress of frequency swept laser and the research status of the frontier in the field are introduced and summarized in detail.
Infrared detection systems have the characteristics of good concealment, strong anti-jamming ability, etc. and are widely applied in military and civil fields. The detection of small and weak targets is an important part of an infrared detection system and has become an attractive research area. Recently, scholars have made remarkable achievements in the research of infrared dim small target detection algorithms based on the low-rank sparse decomposition. This study focuses on the research status and development of infrared dim small target detection algorithms based on the low-rank sparse decomposition and presents a detailed review on three aspects: background component constraints, target component constraints, and joint time-domain information constraints. First, the constraints of the background component are divided into the low-rank constraint of block image, low-rank constraint of tensor, and full variation constraints. Second, the constraints of the target component are analyzed from two aspects: the sparse representation of targets and the target component weighting strategy of fusing local priors. Then, the joint time-domain information constraint is analyzed. Furthermore, the performances of a typical detection algorithm based on the low-rank sparse decomposition and a single frame detection algorithm are compared. Finally, future research direction in this field is highlighted.
Ancient murals are unique surviving copies and unique in artistic style. However, the effect of reconstructing missing information is poor as reference data are scarce. The key to improving the reconstruction process of murals is producing enough reference samples. In this study, an improved style transfer method is proposed to generate high-quality mural images. First, clustering is performed in the low-dimensional space of the input images to maintain their structural integrity. Second, a residual shrinkage module based on the attention mechanism and soft threshold function is introduced to remove redundant information in the images and effectively retain texture details. Finally, the content and matched style clustering sets are converted into real-time features to obtain migration images of any style. The experimental results show that the proposed method can generate natural and clear mural images as well as achieve better results in terms of peak signal-to-noise ratio and structural similarity than other common style transfer methods. Moreover, in an experiment of mural digitization based on a generative adversarial network, the superiority of the proposed method over the conventional augmentation method is verified.