








Please enter the answer below before you can view the full text.
5-3=

The convolutional neural network (CNN) has made immense progress in the classification of coronavirus disease (COVID-19) X-ray images; however, the convolution structure can only learn the context information of the adjacent spatial positions of the feature map. Hence, to realize a better combination of the global information of chest X-ray images, we propose a network that pays more attention to the interaction of the global and local information by designing the backbone network, ConvNeXt, a convergent attention module, and a long short-term memory network while improving the CNN depth as well. Herein, this experiment classified the images of the COVID-19 Radiography Database dataset, which can be publicly accessed. Compared with the basic model of ConvNeXt, the proposed network displays an improvement in the accuracy, accuracy, and recall by 1.60, 1.23, and 1.76 percentage points, respectively, in the three classification experiments, and it is superior to Vision Transformer and Swin-Transformer in many experimental indicators, with the accuracy, accuracy, recall, and specificity increased to 95.6%, 96.03%, 95.76%, and 97.53%, respectively. Furthermore, the Chest X-ray dataset was selected to further verify the proposed network generalization capability, and the score-CAM algorithm was used to verify its effectiveness. The experimental results show that the proposed network has a high potential for application in the classification of COVID-19 X-ray images.
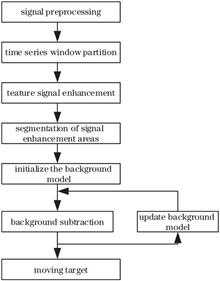
Airport bird detection requires a precise and reliable detection method for small and weakly moving targets because bird strikes are the primary accident sources affecting airport safety. The airport bird detection was realized under a wide field of view and against a complex background after completing experiments under various lighting conditions. The light field fluctuations were used to enhance the low signal-to-noise ratio of the bird motion characteristic signal, and the local Gaussian mixture model was used to segment the foreground of the image enhancement area. The experimental findings demonstrate the effectiveness of the proposed algorithm in increasing the detection rate of dim small targets with long distances, a wide field of view, and low signal-to-noise ratios while having better optical stability.
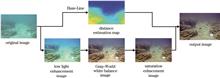
Owing to the effects of absorption, scattering, and attenuation during underwater light propagation, images acquired from an underwater scene degenerate significantly, i.e., they exhibit low contrast and undesirable blue-green bias. Therefore, an underwater image enhancement algorithm based on image segmentation and color adaptation transformation for white balance is proposed. The color adaptation transformation is introduced for underwater color correction, and a low illumination enhancement method based on three-channel inversion defogging is applied to improve underwater images. Further, a white balance strategy based on image segmentation is proposed, and the proposed algorithm is compared with classical algorithms. Experimental results show that the average values of the underwater color image quality evaluation metric (UCIQE), underwater image quality measures (UIQM), and neutral color angle error of the image processed by the proposed algorithm are 0.5839, 1.3689, and 5.0972 respectively, which are higher than those of two classical algorithms. The proposed algorithm presents certain advantages in terms of color correction and sharpness improvement.
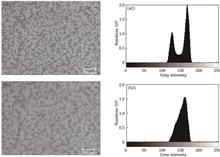
As a direct and effective non-contact full-field optical measurement method, the digital image correlation method has been widely used in 2D/3D displacement and strain measurements of materials and structures in various fields. Combined with advanced speckle preparation technology, in situ loading experiments are conducted under a microscope, which can realize the displacement and strain measurements of micro-scale digital image correlation. Out-of-plane displacement inevitably occurs in the loading process of specimens at the micro scale. Because of the limitations of the depth of field of optical microscopes, small out-of-plane displacement leads to defocus blurring of speckle images, which generates a corresponding error in deformation measurements. To reduce the error caused by out-of-focus blur, the blind deconvolution method is used to blur the speckle image, and the Gaussian filtering method is used to denoise the speckle image to address noise problems. The effects of image restoration on the digital image correlation measurement accuracy are analyzed quantitatively, and a stretching experiment of an indium tin oxide (ITO) film is conducted. Experimental results show that the error in elastic modulus measurement after image restoration is reduced by 13.91%, and the accuracy and stability of the strain measurement results are higher.
This work presents a method based on contrast and structure extraction to overcome the the difficulties of low contrast and unclear edge contour in the fusion of infrared and visible images caused by existing multi-scale transformation methods. First, the visible image is adaptively improved and the infrared image is linearly normalized. Then, the local contrast and salient structure of the image are extracted using dense SIFT descriptors and local gradient energy operators, respectively, and the weight map is obtained by combining the weights of the local contrast and salient structure. The weight map eliminates discontinuities and noise with a rapid guidance filter. Finally, the weight map after thinning and the source image after enhancement and linear normalization are fused by the pyramid decomposition technique. Moreover, this research conducted a large number of experiments on publicly available datasets using six evaluation indicators to quantitatively examine the experimental outcomes, and qualitatively compared the proposed method with 10 mainstream image fusion algorithms. The experimental findings show that the suggested method can effectively preserve the contrast, edge contour, and detail information of the source image while achieving the best fusion effect in visual perception and quantitative indicators.
Semantic segmentation network classifies images at the pixel level, which has more advantages for accurate target location than target identification, thus playing an essential role in infrared small target detection. According to the characteristics of an infrared small target, a novel infrared small target detection network based on real-time semantic segmentation is proposed. A good compromise between the speed and impact of infrared tiny target segmentation is achieved by the network, based on the dual branch feature extraction structure, using the progressive feature fusion module and enhanced Dice loss function. The experimental results demonstrate that the algorithm achieves high accuracy compared with five algorithms, namely FCN, ICNet, BiSeNet V2, STDCNet, and TopFormer for small parameters and calculation. The proposed algorithem is advantageous for the practical application of semantic segmentation in infrared small target detection because its reasoning frame rate on the actual collected infrared small target dataset is 44% higher than that of traditional FCN, reaching 117 frame/s, and the intersection and merging of infrared small targets are 49% higher than that of TopFormer with the similar reasoning frame rate.
In recent years, cross-modal pedestrian re-identification has gradually become one of the hotspots in the field of computer vision. However, it is crucial to effectively extract pedestrian features, further realize the interactive fusion of photos, and mine any potential relationships between pedestrian images while performing cross-modal pedestrian re-identification. To address this issue, a dual stream network based on channel grouping reorganization and attention mechanisms is proposed to extract more stable and rich features between the two modes. Specifically, to extract the shared characteristics of cross-modal images and to achieve the interactive fusion of modal information, the intra-modal feature channel grouping rearrangement module (ICGR) was inserted in the backbone network. Furthermore, to extract additional distinct local features, the possible association between pedestrian images captured using various modes was mined using the aggregated feature attention mechanism and cross-modal adaptive graph structure. A large number of experimental results on mainstream datasets such as SYSU-MM01 and RegDB demonstrate that the proposed algorithm has good generalization ability on multiple datasets. The cross-modal pedestrian re-identification algorithm achieves higher accuracy compared with the existing main algorithms.
To address the issue of difficulty in accurately diagnosing children's pneumonia images, a classification and recognition method based on improved Inception-ResNet-v2 is proposed to improve the recognition accuracy of various types of children's pneumonia images. A multiscale channel attention module based on Inception-ResNet-v2 is introduced to promote network recognition and detection of targets under extreme scale changes. The size of the network stem layer's convolution kernel and the effective receptive field are increased at the start of the model. To avoid overfitting the model, the activation function is reduced in size, and the SiLU activation function is used instead of the ReLU activation function. To address the issue of less amount of data in the Chest X-ray dataset, the input image is rotated at a specific angle and flipped horizontally at random to improve the original data. The experimental results show that the proposed method has a 97.9% accuracy in the second classification of children's pneumonia data and an 85.8% accuracy in the third classification, demonstrating that the method can effectively improve the recognition accuracy of children's pneumonia.
A weak-light environment leads to low contrast, dark brightness, missing details, and other problems with pictures captured by image acquisition equipment. Therefore, a low illumination image-enhancement algorithm based on homomorphic frequency division aggregation is proposed. First, the transfer function of homomorphic filtering is improved, the original image is decomposed into high- and low-frequency components, and some dark-area details are enhanced without the loss of bright-area details. The improved homomorphic-filtering transfer function has fewer parameters than the original and is easy to adjust. Next, the two components are enhanced. That is, the detail enhancement network is designed to improve the detailed information of the high-frequency part, and the low-light image enhancement via illumination map estimation (LIME) algorithm is used to enhance the brightness of the low-frequency part. Finally, a local adaptive network is designed to jointly fine-tune the high- and low-frequency components of the image to correct the distortion during fusion. The experimental results from the subjective vision and objective evaluation indicators show that the proposed algorithm can effectively balance the enhancement effect of smooth regions and texture components of the image and improve the image visual quality.
A lightweight attention-guided super-resolution network (LAGNet) is proposed to address issues such as excessive computation and long training time caused by the redundant structure and increased parameters of image super-resolution reconstruction networks. First, the LAGNet introduces randomly initialized adaptive weights into the deep residual network structure to maximize the use of shallow feature information. Second, an attention guidance (AG) module uses the parallel structure of the efficient channel attention (ECA) model and the spatial group-wise enhance (SGE) model, combines the relationship between channels and the spatial location information characteristics, and employs the attention-guide layer to dynamically adjust the weight proportion of the two branches to obtain high-efficiency channel feature information. Finally, the global cascade connection is used to reduce network parameters and speed up information flow. The L1 loss function is used to accelerate convergence speed and prevent gradient explosion. The test results on the three benchmark datasets show that on average the peak signal-to-noise ratio of the LAGNet is increased by 0.39 dB, the model parameters are reduced by 24%, and the addition and multiplication operations are reduced by 62% compared with other networks; the overall visual effect of the image is clear and the detail texture is more natural.
An efficient point cloud small-scale noise filtering and smoothing algorithm is proposed to address the issues of noise points and acquisition errors in the point cloud model of the key components of the train acquired by 3D laser scanning equipment. First, a K-D tree was used to construct the geometric relationship between points, set the center point, and query the neighborhood information using the K nearest neighbor algorithm. Then, it was assumed that there was a linear relationship between the input point cloud and the filtered output point cloud. Finally, the linear parameters were determined by solving the cost function's minimum value, and the smoothed point cloud model was obtained. To adjust the linear model's parameters dynamically, the weight was adaptively adjusted based on the ratio of the Euclidean distance variance of the point and its K nearest neighbor to the overall Euclidean distance variance during the construction of the cost function. The experimental results reveal that the proposed algorithm can quickly correct small-scale noise, smooth the boundary contour, improve the quality, and thereby lay the groundwork for future tasks such as point cloud recognition and reconstruction.
To overcome the problems of poor generalizability and an inability to adapt to complex real scenes of traditional low-light image enhancement algorithms, a new method based on multi-scale concat convolutional neural network is proposed here. This method achieves low-light image enhancement by learning the mapping relationship between low-light and normal images. Taking the low-light image as input, the shallow layer information of the image is extracted through the preprocessing module. Then, Selective Kernel Network (SKNet) is fused to the local path to form a feature extraction network. Finally, the global feature is fused with the local feature, which is obtained by weight learning of the feature map with a channel attention module. Bilateral guided upsampling is used to restore the image size and obtain the mapping function of the low-light image, after which the image enhancement is completed. Based on the MIT-Adobe 5K dataset, a comparative experiment with nine other advanced methods showed that the proposed method can effectively improve the brightness and details of low-light images. Hence, the proposed method is superior to other contrast algorithms in terms of visual effects and quantitative evaluation.
A super-resolution method based on matching extraction and a cross-scale feature fusion network is proposed to address the problem that the spatial resolution of the FY-4 satellite image's near-infrared and short-wave infrared bands is far lower than the corresponding visible band. The high-resolution band image is used as the reference image to assist in the reconstruction of the low-resolution visible and near-infrared bands. First, using the similarity between the high-resolution image and the low-resolution image, the matching extraction module is used to fuse the fine texture information of the high-resolution image into the low-resolution image. The cross-scale feature fusion method is then used to combine the reference image feature map and the low-resolution feature map, which still differ in brightness, color, structure, and so on. Finally, by combining the total spatial spectral variation loss and the L1 loss, the spatial and spectral reliability of the reconstruction results is ensured. Experimental results demonstrate that the proposed method achieves good results in spatial and spectral reliability. This method achieves the best quality evaluation index and can effectively improve the spatial resolution of FY-4 satellite images compared with Bicubic, RDN, RCAN, EDSR, Dsen2, and other methods.
Aiming at the problem that noise will be generated during micro-CT scanning in the laboratory, resulting in the decline of CT image quality after reconstruction, this paper proposes a deep multi-residual encoding-decoding convolutional denoising network. This method is based on the original residual encoding-decoding convolutional network. First, we increased the number of convolutional layers and introduced the multiple residuals to realize effective learning of noise distribution characteristics in lab-level micro-CT images. Second, a special mix-loss function was designed to strengthen the network's ability to retain image details. Experimental results show that the proposed method has a significant effect on noise suppression and can greatly preserve the structure and feature information of CT images.
To address the issue of cell segmentation challenges caused by weak edges, uneven backgrounds, and irregular cell shape in brightfield microscopic images, we suggest a cell segmentation method for brightfield microscopic images based on fluorescent nucleus guidance. First, the fluorescent nuclear centroid determines the local microscopic image of a single cell in the brightfield, the double Gaussian filtering reduces the impact of nonuniform background, the top-hat transform enhances the contrast of the images, and the two-dimensional maximum interclass variance segmentation method enhances the antinoise performance of the algorithm. Second, the complete brightfield microscopic cell image is preprocessed using double filtering and top-hat transformation. This is followed by global segmentation using the two-dimensional maximum interclass variance method to enhance the lost cell contour information in local segmentation, which is beneficial to solve the inaccurate segmentation problem caused by irregular cell shape. To increase the segmentation accuracy of sticky cells when local and global findings are combined, the watershed transformation is then employed for secondary segmentation. Through the verification experiment on the Hela cell image set, the accuracy, recall rate, and F value of the brightfield cell segmentation are 0.960, 0.984, and 0.971, respectively, which are better than the existing algorithms; the results confirm the high accuracy and robustness of the proposed method.
Multispectral remote sensing images (MSIs) provide a substantial amount of ground object information spread over various spectral bands of the image. The quantity of information contained in different bands or different spatial locations within the same band varies significantly. How to capture useful information from MSIs is a challenging task in semantic segmentation of remote sensing images. An end-to-end semantic segmentation network (BLASeNet) based on band-location adaptive selection is proposed here. The proposed network adopts an encoder-decoder structure. In the coding phase, a band-location adaptive selection mechanism is proposed to adaptively learn the weights of different bands and different spatial locations within the same band, enhancing the effective features expression. The spectral-spatial features of 3D residual block-coded images are further proposed to make use of the band correlation of MSIs. During the decoding phase, an adaptive feature fusion module is proposed to adaptively adjust the fusion ratio of low-level detail features and high-level semantic features via network learning, as well as investigate the impact of three fusion strategies, namely, addition (BLASeNet-A), element multiplication (BLASeNet-M), and concatenation (BLASeNet-C), on the model's performance gain. Furthermore, channel attention is extended to 3D data, and the fused feature map is recalibrated on the channel dimension to produce a more accurate multi-level interactive feature map. The effectiveness of BLASeNet has been demonstrated by experimental results on ISPRS Potsdam, Qinghai and Tibet Plateau datasets.
Light field images contain rich spatial and angle information and are, therefore, widely used in three-dimensional reconstruction and virtual reality; however, the limited spatial resolution of light field pictures, notably the blurring of the image edge area, prevents their application and development due to the inherent constraints of light field cameras. A light field image super-resolution network based on feature interactive fusion and attention is proposed here because the spatial information in a light field subaperture image contains rich texture and high-frequency details and the angle information corresponds to the correlation between different views. Here, the feature extraction and feature interactive fusion modules completely fuse the spatial and angle information of the light field; the feature channel attention module refines high-frequency aspects of the images by adaptively learning effective information and suppressing redundant information; and the optical field structure consistency module preserves the parallax structure between optical field pictures. The performance of the proposed network is typically superior to that of the compared super-resolution network, according to the experimental results from five light field datasets.
For infrared and visible image fusion based on generation countermeasure networks, a deep fusion method based on adaptive feature enhancement and generator path interaction is proposed to solve problems, such as edge blurring between different objects in the fusion result, insufficient extraction of source image information, and imbalance of fusion information. First, the adaptive enhancement block sharpens the edge information of different objects in the source image according to the weight map. After the adaptive feature enhancement loss, intensity loss, and gradient loss are jointly constrained, the contrast and texture details of the fused image can be enhanced simultaneously. Second, the generator path interaction structure can fully extract the source image information by adding an interactive convolution layer between the two main paths, and the transmission of the feature map can be enhanced using a densely connected convolution network. In addition, a content loss function, designed based on the primary, secondary, and dual discriminator introduced in the network structure, ensures the balance between contrast and texture details in the fusion results. Experimental results show that the proposed method has very competitive results in both subjective visual and objective quantitative evaluations and is faster than the other methods.
Classification methods of remote sensing scene images are mostly based on traditional machine learning or convolutional neural networks. The feature extraction capability of such methods is extremely limited, particularly for optical remote sensing images with large interclass similarity, complex spatial information, and various geometric structures, there are problems such as loss of feature information and low classification accuracy. To overcome these problems, we propose a high-resolution remote sensing scene image classification method that combines dictionary learning and Vision Transformer (ViT). This method can not only mine the long-distance dependencies inside the images but can also use dictionary learning to capture the deep nonlinear structural information of images to improve classification accuracy. Through extensive experiments performed on the RSSCN7, NWPU-RESISC45, and Aerial Image Data Set (AID) public remote sensing image datasets trained from scratch on the PyTorch deep learning framework, the effectiveness of the proposed method is verified; the results show that the classification accuracy of the proposed method for the mentioned datasets is 1.763 percentage points, 1.321 percentage points, and 3.704 percentage points higher than that of the original visual converter model, respectively. Moreover, the proposed method outperforms other advanced scene classification methods.
Presently, an electronic laryngoscope image is used to assess the severity of laryngopharyngeal reflux disease based on the reflux finding score (RFS) scale. This quantitative evaluation method increases the screening diagnosis objectivity. However, its misdiagnosis rate is high, and screening efficiency is moderate. An anti-flow-aided evaluation of the throat region based on RFS can be implemented using a deep learning algorithm. We propose a semantic segmentation algorithm for diagnosing laryngopharyngeal reflux disease based on existing knowledge of the RFS scale to segment the throat multi-region semantics in an electronic laryngoscope image. This algorithm resolves the problems of unbalanced sample categories and small target detection in the dataset used for this study. The intersection over union ratio for the dataset increased by 6.38 percentage points. Moreover, detection rates for small targets, such as voice-band groove, granuloma, and mucus, increased by 4 percentage points, 18 percentage points, and 75 percentage points, respectively. Furthermore, SE-ResNet and target area segmentation are used to quantify and evaluate the subjective items in the RFS scale. Thus, the auxiliary evaluation results aid in rapid and effective diagnosis of laryngopharyngeal reflux. The diagnostic accuracy of the proposed method is 94.40%. This study provides an innovative computer-aided assessment method for throat regurgitation that can be used for diagnostic reference based on the RFS scale. Hence, this study lays foundation for further research into throat regurgitation-related diseases.
To improve the anti-interference ability and robustness of the reconstruction algorithm, this paper proposes a global method based on the gradient descent and Newton methods and then proposes two types of variable step-size update strategies based on optimization theory, namely, the dichotomy and Newton methods, so that the iterative process can independently pick the best update step-size. To fully exploit the respective benefits of the sequential and global methods, the termination judgment criterion is designed to combine the two. The proposed algorithm's anti-interference ability is demonstrated through simulation and experimental data to be superior to each sequential method. Especially when the noise of image devices is high, it is uniquely proposed to use dark field image information to calculate each gradient value, to minimize the impact of noise. Furthermore, the above methods only require additional 3-5 rounds of an iterative process to achieve satisfactory results, and the time cost is only a few seconds.
Background light affects an image and degrades its quality. Laser lock-in imaging is an outstanding technology for reducing the impacts of the background light by a sine auxiliary modulation. However, the technology is expensive and not safe enough, and it requires that the frame rate of the image sensor is high enough to meet the modulation speed. In this study, the technology is extended theoretically to investigate the feasibility of a non-sine auxiliary-modulated light and mechanism of the background light elimination. We used an LED as the auxiliary light and the control mode of optimizing image acquisition to reduce the requirement for the frame rate of the image sensor. According to our findings, the modulation signal of the auxiliary light of the locked imaging technology can be extended to any waveform signal with zero integration in a period. Experiments using sine, square, triangular, and sawtooth signals to modulate an LED light show that in a modulation cycle the proposed technology uses four modulation waveforms to achieve a good background light elimination effect at different sampling rates. The proposed technology has low requirements for auxiliary light sources and frame rates of image sensors, providing theoretical feasibility.
A huge number of bone swabs are unearthed from the Chang'an city site of the Han dynasty, and the automatic measurement method of bone swab size based on digital image technology can improve the work efficiency at such sites. An approach for measuring the size of a bone swab image based on an adaptive threshold Zernike moment in various places is proposed to address the issue of low measurement accuracy brought on by variable bone swab textures and low edge contrast. First, the Canny operator is used for pixel-level localization. Then, the effective edge of each sub-region is fixed symmetrically; the weighted gray value of each sub-region pixel point and center point is calculated with Euclidean distance as the proportion coefficient; and the judgment threshold of the Zernike moment extraction edge of each region is used to extract the subpixel edge of the bone swab. Finally, to remove the invalid texture, the edge contour discrimination condition is added, and the precise contour of the bone swab picture is obtained; the size of the bone swab is estimated using camera calibration, and the irregular contour is obtained using the minimum circumscribed rectangle algorithm. The experimental results demonstrate that the root mean square error of the length and width of the bone swab measured by this method decreases by 1.3 mm and 1.2 mm, the average relative error decreases by 3% and 6.3%, and the average absolute error decreases by 1.23 mm and 1.08 mm, respectively, compared with other methods. Thus, the method can effectively enhance the measurement accuracy of the size of the bone swab with complex edge profiles.
A structured light 3D measurement system architecture consisting of three heterogeneous cores is proposed based on phase-shift profilometry to achieve an embedded 3D measurement system for efficiency, integration, versatility, and flexibility. The multi-core heterogeneous architecture has a clear hierarchy, flexible structure, and strong universality and can work with optical devices (cameras, projectors, etc.) possessing a variety of universal interfaces. A full process-structured light 3D measurement system covering phase demodulation, unwrapping, and phase depth mapping modules is designed and constructed based on this architecture along with the parallel pipelining optimization approach of the field-programmable gate array. The experimental findings demonstrate that the proposed approach significantly enhances the measurement efficiency, it only takes 12 ms to process 13 images of 1280×800 resolution when the measurement accuracy is equivalent, which is 11 times that of similar algorithms on standard PC platforms.
This paper obtains image datasets through electroluminescence imaging and uses deep learning image detection algorithms to identify defects in solar cells. We improve the YOLOv4 target detection algorithm by replacing the backbone network of the original algorithm with DenseNet121 and connecting the feature image information through the dense blocks in DenseNet121 to increase the detection accuracy and speed. We also enhance the nonmaximum suppression (NMS) of the original algorithm with Softer-NMS to improve the positioning accuracy of the bounding box and reduce number of false and missed detections. The results indicate that the model's detection accuracy has increased by 5.94 percentage points due to the use of the improved algorithm. Moreover, ablation experiments are set to verify the impact of the proposed improved algorithm on the model performance. In the parameter performance comparison with other related algorithms, the parameter indicators perform well, proving the effectiveness and feasibility of the proposed algorithm.
This paper proposes a lightweight neural network method based on UNet to accurately detect and localize high-density, low signal-to-noise ratio (SNR) sub-diffraction fluorescence spots in high-throughput fluorescence microscopy imaging. This method combines a squeeze and excitation channel-wise attention mechanism with a residual module to optimize feature information. A density map and offset multioutput architecture are also constructed for direct detection and subpixel localization. The proposed method has been verified on public and simulated datasets, and outperforms current algorithms for low SNR and high-density fluorescent spot detection. Notably, the detection performance of the proposed method is excellent for high-density fluorescent spot that reaches the diffraction limit, such as in images with a resolution of 128 × 128 pixels having 1200 fluorescent spots. The spot detection accuracy (F1 score) of the proposed algorithm exceeds 97.6%, and the localization error is 0.115 pixel. Compared with the latest deepBlink method, the F1 of the proposed algorithm has improved by 16.2 percentage points, and the localization error has been reduced by 0.63 pixel.
An improved algorithm for estimating the plane-fitting optical flow is proposed to further improve the accuracy of event sensor optical flow estimation and solve the fitting model error of the plane-fitting algorithm. The algorithm adopts the principle of the Prim greedy algorithm to extract effective events from the event flow and obtain the optimal local adjacent event set, laying the foundation for subsequent optical flow estimation. In addition, the eigenvalue algorithm is used to replace the traditional least square method, and the data ranking of the event set under the greedy algorithm is combined to optimize the plane-fitting model and improve the accuracy of the optical flow estimation algorithm. The experimental results show that compared with the existing estimation algorithm for event sensor optical flow based on plane-fitting, the algorithm improves the average endpoint error and average angle error by 20% and 11%, respectively. This study demonstrates effective improvement of the accuracy of the event sensor optical flow estimation algorithm.
Aiming at the low absolute positioning accuracy of industrial robots, a method for identifying kinematic parameters based on binocular vision is proposed. First, a modified Denavit-Hartenberg set of parameters was used to construct the robot's kinematic model. Next, the robot's end was designed to travel in a multi-space sphere. A binocular vision system was used to estimate the actual distance between various endpoints and the sphere's center; moreover, comparison of the measured distance with the theoretical distance generated the relative distance error function. The sine cosine strategy and trust region optimization were used to optimize the particle swarm optimization algorithm and reduce its possibility of falling into local optimization. Then, the kinematic parameter error was addressed iteratively using the particle swarm optimization algorithm. Finally, the kinematic parameters were compensated and validated by comparison. The experimental results demonstrate that the average distance error is reduced from 1.1601 mm to 0.2260 mm, improving accuracy by 80.52%. Moreover, the standard deviation is reduced from 0.6582 mm to 0.1412 mm, an accuracy improvement of 78.55%, demonstrating the efficiency and practicability of the proposed method.
A point cloud classification method based on graph convolution and multilayer feature fusion is proposed to solve the problem that the existing deep learning point cloud classification methods are insufficient for local feature mining and to improve the quality of feature fusion at different levels. First, the K-neighborhood graph is constructed, the improved edge function is used to extract more fine-grained edge features, and the aggregation method based on attention mechanism is used to obtain more representative local features. Next, the multilayer feature fusion module adjusts the channel weight of the intermediate features, introduces residual connection to fuse the features of different levels, and deepens the information transmission between the network layers. The experimental results using the standard public dataset ModelNet40 show that the proposed method exhibits better classification performance than other point cloud classification methods. The proposed method is robust and has an overall classification accuracy of 93.2%.
Position detection of connecting PIN on printed circuit board (PCB) is a vital link to ensure the electrical reliability of PCB, which mainly detects missing, collinearity, and height of PIN. In this study, a method for determining the position of the connecting PIN based on binocular vision is proposed to meet the actual needs of production. First, the intrinsic and extrinsic parameters of the cameras are obtained by binocular calibration, and the stereo rectification of images is achieved. Second, the relevant grid is constructed according to the previously provided arrangement information and relative orientation, followed by PIN missing detection using a change of the grid's gray threshold. Next, to achieve the collinearity detection of PIN arrangement, the feature corner points corresponding to the PIN in two camera fields of view are extracted separately. Furthermore, the three-dimensional coordinates of the pinpoint are determined based on the disparity principle. Finally, a feature extraction-based PIN relative height detection approach is suggested to implement the relative height detection for PINs. The experimental findings support the effectiveness of the proposed method; the average elapsed time of PIN relative height detection is 125.4 ms, the accuracy is 99.535%, and the repeatable accuracy is within ±0.05 mm.
The current automatic optical detection technology is challenged by the following two aspects: it is difficult to obtain enough defect samples, and the types are extremely unbalanced; the appearance defects are diverse and complex. The above problems seriously affect the detection accuracy and efficiency of the appearance defects of polarizers. Considering these issues, a new depth antagonism method of anomaly detection without real defect samples is proposed. An encoder is used to capture the regular characteristics of the stripe-structured light defect image and a decoder is used to reconstruct the defect-free image. An encoder module is then used to form an unsupervised countermeasure network. Finally, the abnormal score is calculated according to the difference between the reconstructed image and the sample image. In the training phase, synthetic defects are added, and the target potential loss function is improved to further increase the detection accuracy. The experimental results for a polarizer appearance defect data set-considering factors such as light imbalance, noise, and camera distortion-show that the area under curve of the test results of the proposed method reaches 97.9%, the average detection time of a single image is 19.2 ms, and the detection accuracy is 94.6%, which is superior to other methods such as GANomaly. The effectiveness and robustness of the proposed method are verified.
Diabetic retinopathy is a serious and common complication of diabetes. Herein, we propose a new feature fusion network model to improve the accuracy of the diagnosis for the severity of diabetic retinopathy and provide a basis for its precise drug treatment. A lightweight network, EfficientNet-B0, was used to extract layer information from fundus images, and high-level elements were combined with three dilated convolutions with various dilation rates to obtain multiscale features. The multiscale channel attention module (MS-CAM) was introduced to weigh high- and bottom-level features, which were then fused to form final feature representations and thereby complete the classification of the diabetic retinopathy. Experimental results show the classification accuracy of the proposed model is 85.25%; hence, the network is appropriate for practical applications. Furthermore, the model can play an auxiliary role for clinical diagnosis and can effectively prevent further deterioration in diabetic retinopathy.
Due to the high sensitivity of photon counting LiDAR, there is a lot of noise in the collected echo data. Signal identification and removal of relevant noise are the prerequisites for the subsequent application of three-dimensional point cloud data. As a result, a quick extraction of the signal photons is extremely important in practice. Shanghai Institute of Technical Physics independently developed multichannel photon counting LiDAR to collect data near sea surface. In this experiment, after preprocessing, we first enhanced the local distance statistical denoising technique. The enhanced algorithm was then compared with the original algorithm and two classical clustering-based algorithms. The findings demonstrate that the proposed algorithm has a noise removal accuracy of 97.80% and running time of 0.46 s, which are superior to that of the original algorithm and two clustering-based algorithms; it, thus, meets the practical requirements for the fast extraction of multichannel photon counting LiDAR information.
A high-precision three-dimensional (3D) imaging method using four-sided tower mirror scanning is proposed, herein, with the aim of solving the problems of low scanning efficiency and small angle of view of unmanned aerial vehicle (UAV) airborne lidar in the current 45° mirror scanning mode. First, a four-sided tower mirror structure for unmanned airborne LiDAR scanning was designed. Second, the scanning imaging model of this tower mirror was established, and its scanning coordinate equation was thus derived. Third, the track characteristics and influencing factors of the tower mirror were analyzed and compared with the scanning track of the 45° mirror. Finally, the qualities of the 3D laser point clouds obtained by the four-sided tower mirror and 45° mirror scanning UAV airborne laser radar were compared through experiments; the results indicate that the scanning efficiency of the former is more than three times that of the latter at the same speed. Additionally, the scanning point cloud has high density, small thickness, and good penetrability; it has broad application prospects in high-precision topographic mapping.
Herein, the lidar echo coherence was examined to investigate a reliable lidar echo processing technique and research the impact of the atmosphere on the echo phase. By creating an experimental system and developing a time domain model of the lidar, the experimental and simulated atmospheric echoes were first obtained. Moreover, the phase of the experimental echo was retrieved and aligned between pulses to remove system-error interference. Then, the correlation coefficients of the simulated echo and aligned experimental echo were evaluated based on the normalized covariance function; it is discovered that the echo pulses are incoherent. According to the evidence of the high eigencoherence of the outgoing pulse, the interpulse accumulation of the hard target echo can increase the eigenfrequency; whereas, the effect of accumulating the aligned wind field echoes among pulses is significantly worse than the incoherent average, demonstrating that the diffuse reflection of the hard target can maintain the eigensignal coherence, while the coherence of the soft target echo, such as the wind field, is seriously destroyed.
To address the issue that traditional cloud detection algorithms are complex to differentiate thin from thick clouds and enhance the accuracy of remote sensing image cloud detection, a remote sensing image cloud detection algorithm with a dual attention mechanism is proposed. First, a dual attention model is constructed using the DenseNet structure, and dense connection modules are added to minimize the number of feature channels. Second, the global context module is introduced to obtain the global context information and further improve the system's performance. Finally, the cascading cavity convolution module is introduced to increase the receptive field and obtain more global image information. The experimental findings demonstrate that the proposed approach outperforms F-CNN, self-contrast, RF, SVM, and Fmask in both thin and thick cloud detection. As cloud pixels have a comprehensive detection accuracy of 0.9340, a low error rate of 0.0385, and a low false positive rate of 0.0693, over detection may be successfully avoided.
A semi-supervised target detection algorithm for infrared images based on CenterNet and OMix enhancement (IRCC-OMix) is proposed to improve target detection accuracy. The prior information of the anchor frame in the infrared image is difficult to determine. Therefore, CenterNet is used as the backbone model to detect the target in the infrared image through key points. A semi-supervised learning method based on teacher-student-network mutual learning is introduced owing to the high cost of infrared image annotation, and a semi-supervised infrared image target detection (IRCC) model based on CenterNet and consistency is designed. The random erasure enhancement in the IRCC model may lead to the disappearance of small targets in the infrared image, which affects the detection performance of the model. Therefore, an object-based image mixing enhancement method is adopted to improve the detection ability of the algorithm for small targets. The experimental results on the public dataset, FLIR, show that the average precision mean (mAP) of the IRCC model reaches 55.3%, which is 1.9 percentage points higher than that of the training using only labeled data. This indicates that the model can fully utilize unlabeled data and improve its robustness. The mAP of the OMix-enhanced IRCC model is 56.8%, which is 1.5 percentage points higher than that of the cutout-enhanced IRCC model and achieves good detection performance.
To address the problems of visual feature loss, radar closed-loop trajectory vector drift, and elevation pose deviation in vision and laser coupled simultaneous localization and mapping (SLAM), a close coupled vision and lidar SLAM method based on scanning context loop detection is proposed. A visual odometer based on SIFT and the ORB feature point detector is used to solve the problem of feature point loss and matching failure. A radar odometer eliminates the distortion and large drift of the radar point cloud by fusing the inter-frame estimation of the visual odometer. Loopback detection is performed by scanning context, and the vector drift of the odometer is optimized by introducing the factor graph to eliminate loopback detection failure. The proposed algorithm is verified on several KITTI datasets and compared with classical algorithms. The experimental results show that the algorithm exhibits high stability, strong robustness, low drift, and high accuracy.
To address the issue of high-speed camera calibration in shooting range for field-wide field measurement, a calibration technique based on airborne identification targets is proposed. To obtain the known point set, an airborne precise positioning identification target is used, and a method based on simulated annealing sparrow search is used to solve the internal and external parameters of high-speed cameras. The airborne identification target is intended to be easily identified from a long distance. The dynamic difference after the event is used for precise positioning, and the precise measurement of the spatial position of the identification target is obtained through position correction. Based on the simulated annealing sparrow search calibration method, the internal and external parameters of the high-speed camera are calculated and calibrated. In the verification experiment created, the reprojection error of the proposed method for addressing the internal and external parameters of the high-speed camera is 0.43 pixel, and the average intersection error is 2.5 cm. The calibration effect and intersection accuracy are superior to Tsai's two-step calibration method, which improves the high-speed camera's remote calibration accuracy and intersection measurement accuracy while also resolving the calibration problem during aerial measurement.
The classic iterative closest point algorithm is sensitive to the initial position and may fall into a local optimal solution. However, if coarse registration is carried out first to adjust the position and pose, it will take a long time to calculate. Thus, an efficient point cloud registration algorithm based on principal component analysis (PCA) is proposed. First, PCA was used to identify the principal axis directions between the two point clouds. Subsequently, the coordinate system was transformed based on the relationship between two principal axes. Finally, the distance between the contour points on the axes was used for correction to avoid spindle reverse. Compared with the typical error correction method, this approach greatly reduces calculation time. The experimental results show that the improved PCA registration algorithm reduces the running time by 80% on average, and the computational efficiency is significantly improved for point clouds containing more than 20000 points. Further, the algorithm addresses poor initial position and realizes the rapid registration of the two point clouds under any pose. Moreover, the algorithm can be applied to the 3D point cloud registration of train components to improve registration efficiency.
A fast removal algorithm for road ground point clouds is proposed to solve the problems of poor removal effect and long running time caused by too few ground point clouds and different plane parameters of multiple roads. This algorithm improves the traditional random sampling consistency (RANSAC) algorithm by iteratively calculating the lowest point of elevation and extracting a specific range of point clouds based on this point, thereby increasing the proportion of ground point clouds and significantly shortening the time for obtaining ground parameters. The improved algorithm can quickly remove multiple road ground point clouds while retaining nonground points. The experimental results show that the proposed algorithm can achieve a good ground removal effect for different scenes of highway ground. For the single road scene, the improved algorithm takes 8 ms, which is 118 ms less than the RANSAC algorithm. For multiroad scenes, the improved algorithm takes 57 ms, 180 ms less than the RANSAC algorithm.
Non-line-of-sight imaging can reconstruct images of scenes outside the line-of-sight. Different from traditional imaging, it imports the indirect signal returned from the hidden scene into the reconstruction algorithm to realize the reconstruction of the target scene, which is important in the fields of national defense, biomedicine, automatic driving, aerospace, and post-disaster search and rescue. This paper summarizes the research progresses of non-line-of-sight imaging technology, and introduces three non-line-of-sight imaging modes, including non-line-of-sight imaging based on time-of-flight, and non-line-of-sight imaging based on coherent information (including speckle pattern and spatial coherence methods), and non-line-of-sight imaging based on intensity information. Focusing on the characteristics and limitations of hardware parameters, reconstruction algorithms, reconstruction time, and image resolution of coherent information and intensity information imaging modes, the development trend of non-line-of-sight imaging is analyzed and discussed.