









Please enter the answer below before you can view the full text.
1-1=

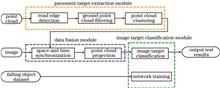
Road falling objects are an important factor affecting driving safety and causing traffic jams. It is crucial to promptly detect and clean up road litter. By summarizing and analyzing the characteristics of falling objects, using the characteristics of high positioning accuracy of point cloud processing and high classification accuracy of image processing, a highway falling object detection algorithm based on image and point cloud fusion is proposed. The proposed algorithm includes the following three steps: road object extraction, point cloud and image information fusion, and falling object classification. First, the laser radar point cloud is used to detect the road edge, filter the ground point cloud, and cluster the point cloud to extract the target point cloud clusters on the road; second, the target point cloud cluster is projected into the time and space-aligned visual image to obtain the corresponding image region of interest; finally, the optimized ResNet-50 is used for target classification. The average detection accuracy rate of the proposed algorithm is 94.84%, and the recall rate is 91.92%, which has a good detection effect.
To address the problems of sparse distribution of small targets in infrared images is sparse, the proportion of pixels is small, and existing infrared small-target detection algorithms are vulnerable to strong noise interference, which significantly impact their accuracy and generalization, an infrared small-target detection algorithm based on context information fusion and visual saliency is proposed. First, the backbone network is constructed by an encoding-decoding method, in which the encoding layer is a full convolutional neural network stacked by hole convolution, and the input features are extracted. Then, feature fusion between different layers is realized through layer-by-layer skip splicing with the decoding layer, and feature information with strong semantics and strong location is extracted. Finally, the extracted features are input into the mixed domain module, and the channel attention and spatial attention mechanisms are used to improve the feature weight of small targets to enhance the background suppression. Through hole convolution combined with cross-layer fusion and visual saliency provided by the hybrid domain module, the proposed algorithm is demonstrated to be superior to the current typical algorithm for complex backgrounds. Compared with the comprehensive optimal algorithm, F_measure is improved by 10% on average, operation efficiency is increased by 40%, and detection and false alarm rate indicators are improved significantly.
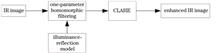
To solve the problems of unclear edge details and low overall contrast of infrared images, an adaptive histogram equalization algorithm combining single parameter homomorphic filtering and limited contrast is proposed. First, the image is processed based on homomorphic filtering with single parameter, and a transfer function with single parameter is studied to make the homomorphic filtering algorithm parameters controllable and independent of experimental experience, while significantly enhancing the details of infrared images. Then, the adaptive histogram equalization with limited contrast is used to adjust the dynamic range of the infrared image to improve the contrast of the infrared image. The simulation results show that the algorithm can significantly enhance the image details, improve the image contrast, and make the infrared image more conducive to subsequent observation.
Current hyperspectral classification algorithms cannot satisfy the requirements of high accuracy and low energy consumption of on-board classification simultaneously. A hyperspectral on-board classification algorithm based on multiscale spatial feature extraction is proposed to solve this problem. The proposed algorithm can significantly reduce the computational costs of the algorithm while maintaining high classification accuracy. Local maximum filtering is used to extract the texture features of hyperspectral images. The multiscale filtering results are combined with the spatial correlation of remote-sensing images to obtain joint local-global spatial features. After the spatial and spectral features are fused, the random forest is used for classification. The algorithm only includes integer comparison and addition operations and does not use high overhead operations, such as multiplication and exponentiation, in mainstream hyperspectral classification algorithms. Experimental results on Indian Pines, Pavia University, and HyRANK image datasets show that the algorithm's classification accuracy loss is within 2.4% compared with the highest-level classification algorithm. In addition, the proposed algorithm achieves high classification accuracy in cross-scene classification. The energy consumed in the classification process is reduced to less than 1/10000 compared with the on-board classification algorithm. Compared with existing algorithms, this algorithm is more suitable for on-board classification tasks and can effectively reduce the computational overhead and energy consumption during the on-board classification process while maintaining high classification accuracy.
A fog simulation method based on depth estimation is proposed, aiming at the lack of foggy image datasets. The brightness and saturation are adjusted adaptively to preprocess the clear original image, self-supervised monocular depth mining network is used to generate the depth map and which is optimized by guided filtering. Transmittance map is obtained with setting the visibility of the simulated image, the dark channel map is used to distinguish sky area to estimate the atmospheric light value, and simulated foggy image with visibility is generated through the atmospheric scattering model. According to the experimental data, the problems of unclear targets in simulated images and sharpening of fog edges are improved effectively. The effect is stable when simulated foggy visibility is below 2000 m, which average error rate of feature evaluation index between simulated foggy image and real foggy image is 6.28%, which shows that the proposed method is feasible. It can simulate clear images in natural environment to solve the problems of lack of foggy image dataset and visibility data.
The fingerprint identification system has been challenged and questioned following the erroneous fingerprint individualization in the Madrid train bombings case. Therefore, the quantitative identification technology based on the statistical law of fingerprint secondary features is now a prevalent research topic, for which the automatic detection and classification of fingerprint second-order minutiae serve as foundations. In this paper, a YOLOv5 based fingerprint second-order minutiae detection method was proposed. First, a fingerprint second-order minutiae dataset was established, which contained 4000 fingerprint images with annotations. The structure of the YOLOv5 network was improved based on the characteristics of small size and dense distribution of fingerprint second-order minutiae. More specifically, the original feature detection layer of 32 times down-sampled large target was deleted, and a new micro-scale detection layer was added. Feature Pyramid Networks (FPN),Pyramid Attention Network (PAN),and Spatial Pyramid Pooling (SPP) structures were used to extract local and global features through multi-scale fusion. Finally, the Squeeze-and-Excitation(SE) channel attentional mechanism was added to effectively enhance the robustness of the model and the detection ability of dense small targets. The experimental results reveal that compared with the original model, the mean average precision(mAP0.5) value of the improved YOLOv5s_FI model increases from 93.0% to 97.4% under the condition that the detection speed is basically unchanged, and the weight of the improved YOLOv5s_FI model is reduced by three quarters.
Given that existing face liveness detection algorithms perform well in a single data set but have poor generalization ability in cross multiple data sets; therefore, this study proposes a liveness detection method centering on real faces. During the data input stage, each round of training will input the real faces of multiple source domains into the network, while only randomly input false faces of one source domain. During the feature learning stage, Resnet18 serves as the backbone network to weight fuse the output features of different residual blocks based on the attention mechanism. Triple loss and adversarial loss are used to aggregate the fused real face features within each domain and cross domains, while triplet loss is used to aggregate the fused fake face features within each domain. During the classification stage, cross-entropy loss is used to classify real and false faces in all source domains. The proposed method was tested on four live face detection data sets, and the experimental results reveal that the proposed method has a lower recognition error rate and higher robustness than other methods.
Traditional image fusion algorithm has limitations, such as indistinct target, unclear or missing edge and texture details, and reduced contrast. An infrared and visible image fusion algorithm based on a guided filter (GF) and dual-tree complex wavelet transform (DTCWT) is proposed. First, GF enhancement is performed on visible and high-frequency infrared image components before and after DTCWT decomposition, respectively, according to the characteristics of infrared and visible images. Then, according to the characteristics of different frequency band coefficients, an algorithm based on saliency adaptive weighting rules is proposed to fuse infrared and visible low-frequency subband components; further, a rule based on Laplace energy sum (SML) and gradient value vector is used to fuse high-frequency subbands at different scales and directions. Finally, the fused high- and low-frequency coefficients are inverted using DTCWT to obtain the final reconstructed image. The proposed algorithm is compared with six efficient fusion algorithms. The experimental results demonstrate the improved performance of the proposed algorithm across four objective evaluation indicators with significant target features in different scenes, clear background texture and edge details, and appropriate overall contrast.
Accurate automatic detection of typhoon eye position can provide a priori information for typhoon forecast and monitoring research to reduce disaster loss. Due to the variability of typhoon morphology, it is still difficult to locate typhoon center automatically. In this paper, a R-CNN method for typhoon eye detection based on multi-scale mosaic is proposed with typhoon satellite cloud images. More than 5000 typhoon satellite cloud images released by Japan Meteorological Agency from 1981 to 2017 are collected. The typhoon eye in the image based on the contour curves of the eye wall and the clear brightness difference between the inside and outside of the typhoon eye is segmented. The original image is divided into multi-scale typhoon cloud images by multi-scale estimation algorithm of typhoon eye radius, and the training set and test set are integrated. With the help of multi-scale image mosaic, hyperparameter selection and multi-condition test analysis, the overall algorithm framework of detecting and segmental typhoon eye using multi-scale Mask R-CNN model is constructed, and multi-scale comparison experiments are carried out. In the self-built calibration dataset, the identification accuracy of typhoon eye is from 88.36% up to 92.63%. The average detection time of each image is at least 0.043 s, the minimum mean square error is 2154,and the maximum average crossover ratio is 0.9454. The experimental results show that the proposed multi-scale mosaic data augmentation method has the best effect in large and medium scale scale fusion, but is poor in small and medium scale fusion. Compared with the existing main data augmentation methods, it can improve the accuracy of neural network more effectively. The comprehensive efficiency of the whole detection model in typhoon center location is better than other deep learning localization methods.
Garbage recycling offers many benefits, e.g., protection of water and soil resources, quality improvement of the living environment of residents, and accelerated development of green circular economy. However, traditional garbage recycling methods incur excessive labor and resource costs. In this work, we propose a lighter YOLOv5s improved model in which ShuffleNet v2 and deep separable convolution methods are combined to better solve the problems in garbage recycling by classifying and locating recyclable garbage more efficiently. Experimental results show that number of parameters of the improved model is only 38.98% of that of the original model. When the input resolution is 640 × 640, the mean average precision (mAP) of the improved model is 94.01%, which is 1.91 percentage points higher than the original YOLOv5s. With regard to the computing speed, the forward propagation time of the improved model is 11.5% greater than that of the original YOLOv5s by deploying on hardware of Jetson Nano. Moreover, compared with the current mainstream target detection models, the improved model has a good ability to express the characteristics of recyclable garbage.
Skull identification is an important subject in forensic medicine. To solve the insufficient representation of skull and facial features in previous skull identification research, a skull identification method is proposed based on the fusion of view and shape features to fully use the effective recognition information of the skull and facial model and improve the skull recognition ability. First, a multi-view neural network is used to learn the multi-view features of skull and facial skin, the LS-MDS algorithm based on double harmonic distance is used to calculate the standard shape of skull and facial skin, and the pooling fusion method is used to aggregate multiple features to reduce the information loss in the view pooling stage. Then, to solve the problem of wave core features being sensitive to scale transformation, the scale invariant wave core features of skull and facial skin are extracted using feature value normalization. Finally, the view and wave core features are fused using kernel canonical correlation analysis to obtain the final feature vector of skull and facial skin. Skull identification is realized by calculating the correlation coefficient of the skull and facial skin feature vectors. Experiments show that the recognition accuracy of the proposed method is 95.4%, which is superior to other methods, thereby proving the effectiveness of the proposed skull identification method.
In order to solve the problem of recognition results of similar behaviors not being ideal owing to insufficient extraction of spatio-temporal features, a large amount of network computing, and low computing efficiency in human skeleton behavior recognition, a skeleton behavior recognition algorithm based on dense residual shift bitmap convolution network is proposed. The pose estimation algorithm is used to extract human skeleton information, and the joint, skeleton, and motion information of the skeleton are calculated by coordinate vector, and input into the network respectively. The dense residual structure is introduced between the shift graph convolution modules to improve the network performance and efficiency of extracting spatio-temporal features. The proposed algorithm can be applied to daily behavior, such as walking, sitting, standing up, undressing, dressing, throwing, and falling. The recognition accuracy on the self-made dataset is 81.7%, and under the two evaluation criteria of NTU60 RGB+D dataset, the accuracy is 88.1% and 95.3%, respectively, thus validating that the algorithm has excellent recognition accuracy.
Pedestrian trajectory prediction can effectively reduce the collision risk caused by sudden changes in pedestrian trajectory, which has been widely used in intelligent transportation and monitoring systems. At present, most of the existing researches use undirected graph convolution network to model the social interaction between pedestrians. This method lacks the consideration of the relevance of the hidden state of pedestrians, and is prone to generate redundant interactions between pedestrians. To solve this problem, a pedestrian trajectory prediction model based on attention mechanism and sparse graph convolution (DASGCN) is proposed. By constructing a deep attention mechanism, the association of motion hiding states among pedestrians is captured, and the pedestrian motion state features are accurately extracted. Self-adjusting sparse method is further proposed to reduce the motion trajectory deviation caused by redundant information and solve the problem of dense and undirected pedestrian interaction. The proposed model was verified on ETH and UCY datasets, and the average displacement error (ADE) and final displacement error (FDE) reached 0.36 and 0.63 respectively. The experimental results show that DASGCN is superior to traditional algorithms in predicting pedestrian trajectory.
Effectively monitoring marine fish is necessary to protect and utilize marine fish resources. However, the complexity of marine environment leads to low accuracy in marine fish identification and detection. Therefore, this study proposes an improved algorithm for detecting marine fish based on RetinaNet. First, DenseNet-121 was used to replace the original backbone network of RetinaNet, thereby reducing the number of parameters and retaining more fish image features. To guide the neural network to extract image features more pertinently, the convolution attention module was introduced into the backbone network. Second, a new convolution layer was introduced in the original FPN such that the improved PFPN network can fuse more image features with more scales. Finally, soft-NMS was introduced in the classification and regression network to effectively address the detection-missing problem owing to close proximity and mutual occlusion of the same fish species. The experimental results indicate that the average accuracy of the proposed algorithm is 92.12%. This value is significantly improved compared with SSD and other existing algorithms and is 4.71% higher than that of the original algorithm. Thus, the proposed algorithm efficiently identifies and detects marine fish.
Addressing the low matching accuracy of existing stereo matching algorithms in weak texture and depth discontinuous regions, a stereo matching algorithm based on adaptive region division is proposed. First, the cross domain algorithm is used to obtain the arm length of a pixel and calculate the pixel change rate to complete the region division. Then, the absolute difference algorithm, the improved Census transform, and the adaptive weighted gradient operator are used to calculate the initial cost volume which is aggregated by cross domain. The aggregated images are optimized by the improved guidance map filtering and the winner take all strategy is used to filter the optimal disparity. Finally, the final disparity map is obtained by using left and right consistency detection, iterative region voting, disparity filling optimization, and median filtering. The test results based on the Middlebury test platform show that the average error rate of the proposed algorithm is 4.21%, which is an effective matching accuracy improvement in terms of the weak texture and depth-discontinuous regions.
This study proposes a new multi-image asymmetric polarization optical encryption method based on the full-vector light field control and Fourier transform frequency shifting. First, multiple images to be encrypted are coherently superimposed to form a complex amplitude optical image after the random phase modulation, Fourier transforms, and frequency shifting phase modulation. Next, the distribution of the image is the interference of two pure phase masks, and is encoded and loaded into the full-vector light field control system based on the 4F system. Finally, the all-optical control vector light field outputs amplitude type encrypted images and keys after passing through the polarizer, which are received by CCD to realize parallel encryption of multiple images. Multiple decrypted images can be obtained during decryption by solving the relationship between the control light field distribution (full vector distribution) and the encrypted image under the condition of the correct key. Any rotation angle of the polarizer and the phase only image obtained by interference decomposition are used as the key, which greatly improves the security of the optical image encryption system. The encryption of multiple images into a single amplitude-type encrypted image is convenient for storage and transmission, which improves encryption efficiency. A simulation study has verified the effectiveness and feasibility of the proposed multi-image encryption scheme, and the experimental results show that the proposed method has high security, noise resistance, shear resistance, and chosen-plaintext attack resistance, which has specific application prospects.
A single-image super-resolution reconstruction method based on aggregated residual attention network is proposed to solve the problems for insufficient feature information mining, high algorithm complexity, and unstable training in the super-resolution reconstruction for a single image in existing generative countermeasure networks. First, the aggregated residual module is used as the basic residual block to construct a generator, to reduce computational complexity. In each residual block, an attention module with a three-dimensional weight is introduced as the main channel to capture additional high-frequency information without other parameters. Second, the discriminator network parameters are limited via spectral normalization to stabilize the training process. Finally, the Swish activation function with improved fitting is used to improve the feature extraction ability of the network. The Charbonnier loss function with enhanced robustness is used as the pixel loss, and the regularization loss is added to suppress image noise to improve spatial smoothness. The experimental results show that the average value of the peak signal-to-noise ratio and structural similarity of images reconstructed using the proposed method on Set5, Set14, and BSD100 public datasets increase by 1.54 dB and 0.0457, respectively. Therefore, the reconstructed images have a better resolution and richer high-frequency detail than the original image.
Brain tumor segmentation is significant in the development of medical image processing and human health. Owing to the high complexity and sophisticated requirements for the hardware equipment of 3D convolutional neural networks, this paper proposes a lightweight multi-view convolutional brain tumor segmentation algorithm. First, a multiplexer module is used to effectively fuse the information between each channel, and the extraction ability for nonlinear features is added to the model. Second, pseudo 3D convolution is used to perform convolution from axial, sagittal, and coronal positions, and group convolution is added to save computing resources and reduce device memory usage. Finally, trainable parameters are used to weigh the importance of features extracted from different views to improve the segmentation accuracy of the model. In addition, the distributed data parallel method is used to train the model to improve the graphics processing unit (GPU) usage. Experiments on the public dataset of the 2019 Brain Tumor Segmentation competition demonstrate that the average Dice similarity coefficient of the proposed algorithm is only 2.52 percentage points lower than that of the first-place algorithm, however, number of parameters and floating-point operations are reduced by 84.83% and 96.67% respectively, and the average Dice similarity coefficient is 0.05% higher than that of the runner-up algorithm. A comparative experimental analysis verifies the accuracy and lightness of the proposed algorithm, indicating the possibility for wide applicability of brain tumor segmentation models.
The change in the facial features with age is a crucial factor affecting the performance of face recognition systems. Therefore, this paper proposes a cross-age face recognition method based on a Transformer. First, the improved T2T-ViT model was used to extract mixed features considering the age and identity. The extracted age and identity features were obtained through residual factor decomposition. Subsequently, the correlation between the age and identity features was removed using a decorrelated adversarial learning algorithm with linear feature decomposition to achieve age-invariant face recognition. Compared with the convolutional neural network-based DAL and MTLFace methods, the improved model significantly reduces the number of model parameters, multiply-add operations (MACs), and calculation time. Finally, the effectiveness of the proposed method is verified using the recognition results on benchmark datasets, AgeDB-30, CACD_VS, CALFW, and LFW, and the accuracy of the proposed method is comparable to that of the DAL and MTLFace methods for age-invariant face recognition.
Synchrotron radiation facilities generate ultra-high-speed diffraction image data streams, which require data screening to reduce the pressure on data transmission and storage. However, competing research groups are reluctant to share such data, and existing deep learning-based screening methods cannot easily achieve effective training under privacy protection. Therefore, for the first time, this study applies the federated learning technology to the screening of radiation source diffraction images, and training data augmentation under privacy protection is realized by separating the data and the model. The Federated Kullback-Leibler (FedKL) screening method is also proposed to improve the global model update based on Kullback-Leibler divergence and data volume weights, thus reducing the complexity of the algorithm while obtaining high accuracy; further, this satisfies the high-precision processing requirements for high-speed data streams. To address the difficulties encountered in data synchronization training for multiple centers of remote light sources, this paper also proposes a hybrid training method that combines the synchronous and asynchronous approaches; this significantly improves the training speed of the model without reducing the recognition accuracy. Experiments on the light source CXIDB-76 public dataset reveal that FedKL can improve the accuracy and F1 score by 25.2 percentage points and 0.419, respectively, compared with FedAvg.
Aiming at the problem of wide-range occlusion of target pedestrians in video pedestrian re-identification, a pedestrian re-identification algorithm based on spatio-temporal trajectory fusion is proposed by combining pedestrian trajectory prediction with pedestrian re-identification, which is time-related and not affected by occlusion. First, from the time and space domains, accurate pedestrian trajectory coordinate prediction in line with social attributes is realized. Second, the spatiotemporal trajectory fusion feature is constructed to effectively combine the apparent visual features in the video sequence with the coordinate data in the pedestrian trajectory, which effectively alleviates the impact of centralized occlusion on the re-identification performance. Finally, a trajectory fusion dataset MARS_traj suitable for the proposed algorithm is constructed, and experiments show that the proposed algorithm can effectively improve the performance of the occlusion video re-identification.
This article discusses how to improve image processing for autonomous far-field laser beam alignment for the main amplifier in a sizable laser facility. The image process mainly includes two parts, far-field reference computation and far-field center computation. To further enhance the computation stability and the computation efficacy for image processing, the image regions chosen in far-field reference computation and the far-field center computation are all constrained to a particular region. In far-field reference computation, two process flows are shown for the transport spatial filter (TSF) image and cavity spatial filter (CSF) image respectively. In far-field center computation, one process flow is compatible for both the TSF image and CSF image, and the clustering approach is adopted in computing the center of the far-fields. Experimental results demonstrate the effectiveness of the proposed image processing method.
Esophageal squamous cell carcinoma (ESCC) is one of the most common malignant digestive tract tumors in China. Clinically, narrowband imaging combined with magnifying endoscopy (NBI-ME) can be used to investigate the morphological changes of microvessels in the esophageal mucosa and serves as an important means of diagnosing ESCC. To solve the ESCC recognition model's difficulty in considering both the recognition accuracy and reasoning efficiency, a lightweight residual network (CALite-ResNet) with an integrated attention mechanism is proposed to classify esophageal NBI-ME images. The dataset for this study comprises 11468 NBI-ME images of 206 patients collected from multiple hospitals. The experimental results show that the accuracy and sensitivity of the ESCC recognition is 96.39% and 95.70% at the image level, and 95.70% and 94.62% at the patient level, respectively, and the average prediction time of a single esophageal image is 16.42 ms. Therefore, the CALite-ResNet model has a higher recognition accuracy and faster reasoning efficiency for ESCC recognition, and a certain clinical significance and application value, thereby making it effective for use in the auxiliary clinical diagnosis of ESCC.
Scoliosis is a common spinal disease in the current society. Therefore, it is important for doctors to diagnose the degree of spinal curvature to quickly and accurately locate the spinal bone corners on X-ray images and calculate their Cobb angles. In light of the occlusion of other organs and complex background interference in orthopaedic X-ray images, a neural network model based on the embedded attention mechanism, vector loss module, and vertebra-focused landmark detection (VFLD) network is proposed. The rotary attention mechanism module is embedded between the encoder and decoder to enhance the network's extraction of the deep and high-dimensional features of the spine bone, inhibit the interference of other organs, and allow the use of the vector similarity loss function to train the network. The experimental results show that the accuracy of the symmetrical mean absolute percentage error of the proposed model in the MICCAI 2019 open spine challenge dataset is as high as 9.31, and can effectively improve the ability of the original model to detect vertebral corners. Compared with many existing models, the proposed model has a higher accuracy and robustness.
As an important part of an aircraft, aircraft skin is directly related to the occurrence of aircraft accidents, so the detection of aircraft skin damage is of great significance for the effective prevention of aviation safety accidents. In this paper, an improved rotated object detection method based on box boundary-aware vectors (BBAVectors) is proposed. First, for the problem of large variation of damage scale, the feature fusion network (FFN) is used to improve the multi-scale detection effect. Second, for the problem of lots of background noise in aircraft skin images, coordinate attention (CA) mechanism is introduced to enhance the object feature information. Finally, for the problem of arbitrary skin damage distribution direction, the damage position of arbitrary angle is represented by the BBAVectors to improve the accuracy of object localization. The experimental results show that the improved rotated object detection method improves the mean average precision by 5.7 percentage points compared with the original model, and the detection performance is better than the horizontal object detection method. On the basis of effectively solving the effect of aircraft skin damage detection in arbitrary directions, it provides better technical support for the improvement of aircraft damage detection methods.
This study proposes a high-speed image rotation estimation algorithm based on correlation filtering (GPCF) to estimate the camera rotation caused by carrier pose variations. The proposed algorithm uses correlation filtering rather than the correlation operation used in the gray projection method for rotation estimation. The accuracy and robustness of the algorithm are greatly enhanced by introducing a circular shift matrix to increase the number of negative samples. Additionally, a noise-to-signal ratio formula is established to quantify the impact of noise on the rotation estimation. Compared to the gray projection method, both theoretical analysis and experiments reveal that the GPCF can estimate the rotation of image sequences in real time with greater accuracy and reliability.
The existing aerial photography image object detection algorithms have several problems, such as complicated models, too many hyperparameters, and poor detection accuracy. Therefore, this paper proposes a lightweight multiscale feature fusion network for object detection in aerial photography images. The proposed network employs the idea of Anchor-Free and reduces the hyperparameters related to Anchor through pixel-by-pixel prediction. First, MobileNetV3 is adopted as the backbone network for feature extraction, and the Ghost bottleneck module is used as the base block for multiscale feature fusion to reduce number of parameters and computational costs. Then, deformable convolution is introduced to construct a deformable receptive field block to improve the robustness of the detector to the deformation of aerial photography objects. Furthermore, the label assignment strategy SimOTA is employed for dynamic sample matching, which alleviates the problems of dense distribution and heavy occlusion of aerial photography objects. The proposed network is evaluated on VisDrone2019-DET and NWPU VHR-10 datasets. The detection accuracy AP50 of the proposed network reaches 26.6% and 94.4%, and the detection speed reaches 59.9 and 79.6 frame/s, respectively. Compared with other mainstream object detection networks, the proposed network has fewer parameters and computational costs while maintaining high detection accuracy and speed, making it more suitable for airborne computing devices.
The concept and form of a space-based laser local oscillator in an infrared radio telescope with a 6.5 m diffractive synthetic aperture are proposed to satisfy astronomical observation and deep space exploration requirements. The form of laser local oscillator array detector is established, and the structure of the synthetic aperture infrared radio telescope based on a diffractive optical system is designed. The telescope uses the signal processing method for aperture transition compensation to expand the spectral range, exhibiting low complexity, small size, and light weight in the optical system. The main parameters of the system and the imaging simulation results are presented. When the central wavelength is 1.55 μm, the angular resolution is approximately 0.24 μrad, the maximum unambiguous field of view angle is approximately 1.55 mrad, and the spectral range is 0.2 μm. Its detection sensitivity is two times higher than that of the traditional 6.5-m-aperture telescope, and the observable limit magnitude is higher than 21.
Because the sensing band of the infrared detector is different from the visible light, it does not depend on the reflection and propagation of atmospheric light, but depends on the radiation intensity emitted by the object itself in the environment, so it often has better target detection effect than the visible light under the conditions of low visibility such as haze and night. Aiming at the problems of low accuracy and poor practicality of target detection in infrared scene, an infrared target detection method based on attention mechanism is proposed. First, a lightweight network structure is designed; second, attention mechanism is used to improve the ability of network feature extraction; then, the iterative feature pyramid structure is improved to improve the detection ability of targets with different scales; finally, complete intersection over union (CIoU) loss function and gradient equilibrium mechanism (GHM) loss function are introduced in the training process to improve the imbalance of positive and negative samples. Compared with other algorithms, the experimental results show that the detection accuracy and speed of the proposed algorithm are significantly improved.
To recover the identification code information of damaged characters of mechanical equipment, this paper proposes a magneto-optical imaging restoration method for damaged characters with orthogonal excitation. Based on the study of the influence mechanism of steel matrix characters on magnetic field conduction, a ring electromagnet model with time-sharing orthogonal excitation is developed, and the effectiveness of the model is verified through simulation analysis. First, to enhance the magneto-optical images of characters obtained by orthogonal excitation, we employ the local histogram equalization method to highlight the stroke features of characters. Then, we design the fusion algorithm of pixel-level significant value weighted average to fuse the images. The experimental system was designed to obtain magneto-optical images with orthogonal directional excitation, and the effectiveness of the proposed algorithm was evaluated through experiments. The results show that the magneto-optical images enhanced by local histogram equalization have large contrast of character strokes and high resolution, verifying the effectiveness of the proposed algorithm. Furthermore, the pixel-level salient value weighted fusion algorithm can comprehensively and efficiently extract all directional features of the character images when fusing the magneto-optical images of damaged characters, and the fused images have high definition. Therefore, the proposed magneto-optical imaging restoration method for damaged characters with orthogonal excitation can effectively recover severely damaged characters with complex strokes.
Single photon lidar is widely used to obtain depth and intensity information of 3D scenes. In a complex scene, there are multiple targets with different depths and different reflectivity. In the case of few return photons and high background noise, traditional methods cannot make targeted treatment for these targets. As a result, a single photon lidar depth estimation technique for complex scenes is proposed. The method makes full use of the time-domain correlation of the echo signal to conduct global multi-depth windowing on the lidar 3D point cloud data in the time domain. Additionally, the weighted filling of vacant pixels uses spatial correlation. Under the optimization framework, a Poisson distribution model is established based on the pre-processed lidar 3D point cloud data. To acquire an accurate depth measurement, the minimum of the cost function is finally found using the alternating direction multiplier approach. Experimental results demonstrate that the proposed method enhances the reconstruction signal-to-noise ratio of the estimated depth image by at least 15% compared with other methods. Compared with other methods under complicated sceneries from a distance, it successfully raises the estimated quality of depth images and increases the robustness to a low photon level.
Short-wave infrared (SWIR) band has excellent potential for imaging. Owing to the focal plane detection arrays, SWIR plays an increasingly important role in modern society. Aiming to solve the defocus problem of SWIR imaging and improve its applicability, a wavefront coding system is introduced into the SWIR band. For light and small SWIR imaging, a cubic phase mask is placed at the pupil to extend the depth of field. The phase mask parameter is converted into radial coordinate coefficient, which is optimized by the consistency of the modulation transfer function and image recoverability. Leveraging 640 pixel×512 pixel SWIR images to simulate the wavefront coding system, and the blurred images are restored through the classic Lucy-Richardson algorithm. The optical design and simulation results show that the wavefront coding system effectively reduces the sensitivity of SWIR imaging to defocus within at least ±20 times the depth of field, and the peak signal-to-noise ratio of the restored image reaches 38.5038 dB.
In many civil and military fields such as medical diagnosis, target early warning, and non-destructive testing, the non-contact real-time microwave imaging technology is of great significance. Though the inverse scattering imaging theory based non-iterative inversion method has natural real-time computing ability, its imaging results are poor and difficult to be practically utilized. To improve the inversion image quality, a sparse induction current real-time microwave imaging method is proposed. This method uses sparse prior information and a compressed sensing algorithm to solve the induced current in the imaging area, then combines the traditional non-interative inversion framework to achieve real-time imaging. Full-wave simulation results and microwave imaging system experiments verify the effectiveness of the proposed method. Compared with the traditional non-iterative inversion results, the proposed method has significant improvement in imaging quality and imaging speed for potential application in real-time monitoring and rapid imaging.
Deepfake techniques have dramatically improved the realism of synthetic faces in recent years. And the fake videos it generates are more difficult to distinguish than traditional forgery methods. Based on the characteristic that visual artifacts of depth forgery images often exist in the high frequency components of shallow features in feature extraction network, a detection algorithm for depth forgery images oriented to the high frequency components of shallow features is designed. First, a high-frequency residual extraction module based on Laplace's pyramid with better filtering performance is designed to address high-pass filters' shortcomings. Second, the Convolutional Block Attention Module (CBAM) is used to increase the weights of key regions of the feature map and key feature channels to improve the spatial and channel correlation of the feature map in the enhancement module. Then, an image gradient loss is designed to prevent the loss of high-frequency information as the network deepens to address the problem of low learning priority of high-frequency components in deep networks. Finally, gradient-centralization is introduced into the AdamW optimizer to solve the problems of long training time and poor generalization of deep forgery detection models. Two models proposed outperform mainstream algorithms in terms of accuracy when validated on the FaceForensics++ and Celeb-DF datasets, demonstrating the algorithms' effectiveness and generalization.
To determine the pose relationship between a linear structured light vision sensor and the flange center of an industrial robot, a planar target with only a single circle and its calibration method are designed. The robot's attitude is adjusted such that the laser line passes through the center of the solid circle on the plane target. Through image processing, the pixel coordinates of the center are obtained. After conversion, the coordinates of the center in the sensor coordinate system are obtained. The attitude is adjusted many times, yielding multiple sets of images and the center coordinates of multiple groups of sensors in the sensor coordinate system. The hand-eye matrix is directly solved using the least-squares method based on the corresponding robot pose relationship. The experimental results show that the standard deviation of the three-dimensional coordinates obtained by the proposed method is reduced from 0.3893 mm to 0.2145 mm compared with the hand-eye calibration method using the standard ball as the target, and the root mean square error is effectively reduced with different distances of the same target as the measurement object. This method improves calibration accuracy, does not require expensive targets, and is suitable for field calibration.
As complex battlefield environment requires rapid and accurate positioning of sky-wave radar, a positioning model based on multi-strategy improved sparrow search algorithm is proposed. First, cubic chaotic mapping, dynamic adjustment of step factor, reverse learning, and mixed mutation operator are used to invent an improved sparrow search algorithm. Then, the improved sparrow search algorithm is used to find the best-fit kernel function parameters and weight coefficient of mixed kernel of hybrid kernel extreme learning machine (HKELM). Finally, the optimized HKELM is used to locate the target detected by the skywave radar. The results show that the accuracy and stability of improved sparrow search algorithm are not only superior to the HKELM location model which is optimized by the basic sparrow search algorithm, but also stronger than the extreme learning machine (ELM) location model. In other words, the effectiveness of the method is proved.
Mountainous areas have rough terrain and substantial elevation changes. The topography effect of remote sensing images significantly interferes with the spectral characteristics of ground objects and may lead to the misclassification for remote sensing images, which is not conducive to remote sensing information extraction. Based on the principle of radiative transfer, an atmospheric correction algorithm for mountainous areas is developed using Python. The proposed algorithm considers the influence of direct solar, sky scattered, and adjacent surface reflected radiations on the target radiance at the satellite entrance pupil and can effectively eliminate the terrain shadow influence. We conducted the atmospheric correction of the CCD sensor for mountain area data of HJ-2AB (a small satellite for environmental and disaster monitoring and prediction made in China) using the proposed algorithm and digital elevation model (DEM). The analysis results show that the terrain effect of the corrected image is weak and that the image quality improves significantly. The surface reflectance obtained by inversion agrees with the spectral data of the ground objects measured in the field, which provides a data quality guarantee for further quantitative remote sensing research.
Deep learning plays an important role in solving the problem of remote sensing image scene classification. However, in certain remote sensing scene classification problems, samples with labels that can be trained are severely lacking (number of single-class samples less than 10), resulting in unsatisfactory classification using existing traditional depth models. In this paper, to solve these problems, a small-sample-size remote sensing scene classification method is proposed, and a model called ResNet14 Attention-ProtoNet (RA-ProtoNet) based on a meta-learning training strategy is constructed. First,in the feature embedding module, the pre-trained depth residual network, ResNet14, is used to extract the depth features of remote sensing images. Second, in the class-level expression module, the problem that the features of similar samples are unremarkable and interfere in class-level expressions is solved. For this purpose, an attention mechanism based on bidirectional long short-term memory (Bi-LSTM) is used to strengthen the sample information within a class and generate class-level feature expressions of samples. Finally, the Euclidean distance is used to measure the distances between the samples to be classified and the class-level features for classification prediction. On three remote sensing image datasets, including UCMERCED, AID-30 and NWPU-RESISC45, the proposed method is compared with remote sensing scene classification methods based on migration learning and existing meta-learning methods. Under the five-way five-shot condition, the overall scene classification accuracies of the proposed method reach 81.30%, 83.29%, and 81.22%, respectively. The experimental results show that the proposed method can effectively mine the sample information within a class and obtain higher classification accuracy of remote sensing image scenes under the condition of minimal samples than the other methods.
Remote sensing image fusion, an effective method that integrates information contained in multispectral and panchromatic images, has become a powerful application technology in fields such as territorial spatial planning and disaster detection. A new method of remote sensing image fusion in non-subsampling shearlet transform (NSST) domain is proposed on the basis of research on fusion strategy in the NSST domain. First, the source image is NSST decomposed into low-frequency coefficients and multi-directional high-frequency subbands. Subsequently, to solve the problems of energy conservation and detail extraction, an image feature weighting mechanism based on the mean spectral radius weights the energy attribute and the improved Laplacian energy sum and applies these to low-frequency coefficient fusion. Next, an improved dual-channel pulse coupled neural network is developed to fuse the high-frequency subbands by combining the weighted adaptive method with the direction information to determine the weight. Finally, the fused low-frequency coefficients and high-frequency subbands are used for reconstruction to obtain the fused image. The effectiveness of this method is verified by 48 sets of satellite images with three different resolutions, namely, GF-2, GeoEye, and WorldView-3. The comparison experiment with five fusion methods shows this new method can achieve good results in visual perception and quantitative evaluation indicators.
To solve the problems of insufficient estimation ability for the center of gravity of a vehicle and difficulty in vehicle reidentification in large bridge vehicle moving load monitoring, a fast fusion method of color image and point cloud based on point cloud grayscale image is proposed to improve the spatial positioning ability for vehicles and recognition ability for targets. The stereo calibration target was used to calibrate the position and attitude of cameras and point cloud collection devices with different viewing angles to obtain their relative positions and attitudes. Then, the calibration results to splice the point clouds collected from different perspectives were used to obtain a complete vehicle point cloud. The complete point cloud was converted to the color camera coordinate system and projected, extracting the point cloud grayscale image and realizing the registration of the color image and point cloud grayscale image. We adjusted the attitude to be consistent with the position and attitude of the vehicle entity in the color camera coordinate system. The mapping relationship between color pixels and 3D point cloud was established. The color information was associated with the point cloud to fuse the color images and point clouds. Using the fused color point cloud and camera imaging model, the virtual image of the vehicle in the color camera coordinate system can be obtained, providing a basis for vehicle recognition. The results demonstrate that compared with the sampling consistency algorithm, the proposed registration algorithm requires approximately 74.1% less time. Experiments reveal that the color point cloud generated by the proposed algorithm after data fusion has a high degree of restoration, proving the feasibility of the proposed algorithm. The proposed algorithm provides new ideas and methods for solving similar problems.
Traditional nonnegative matrix factorization (NMF) applied to hyper-spectral unmixing is susceptible to the interference of pretzel noise, resulting in unmixing failure. Previous sparse unmixing requires determining the optimal feature subset in a spatial domain involving more dispersed information and susceptibility to noise. The weighted sparse Cauchy-nonnegative matrix factorization (SSCNMF) algorithm based on the spatial-spectral constraints is proposed to solve these problems. First, the Cauchy loss-function-based NMF model, which exhibits excellent robustness in suppressing extreme outliers, is applied. Second, an adaptive sparse weighting factor is introduced to improve the sparsity of the abundance matrix. A spatial-spectral constraint term is added, in which the spectral factor is used to measure the sparsity of abundance among different spectra. The spatial factor exploits the smoothness of the spatial domain of abundance to improve the extraction efficiency of data features. Simulation experiments were conducted on simulated and actual datasets. The effectiveness and excellent anti-noise performance of the SSCNMF algorithm are verified by comparing it with some classical hyper-spectral unmixing algorithms.
Using the Landsat-8 OLI multispectral satellite remote sensing images covering typical islands and collected water depth data, this study comprehensively invert the water depth of the target sea area using the traditional multiple linear regression model, back propagation neural network model and random forest model in machine learning. The inversion accuracy of the three methods is evaluated. The results show that compared with the multiple linear regression model, machine learning methods have higher water depth inversion accuracy. The water depth inversion accuracy of the random forest model is the highest with a mean absolute error of 1.94 m and a mean absolute percentage error of 18.29%, and the robustness of the model is better, and the overall accuracy is significantly improved compared with that of the multiple linear regression model. This study compares the performance of shallow water bathymetric models built using the three methods, providing reference value for subsequent research on obtaining high-precision shallow water bathymetric information more efficiently.
The visual simultaneous localization and mapping algorithm is easy to be interfered under occlusion, which leads to large positioning error and low closed-loop detection accuracy. In this paper, a visual simultaneous localization and mapping algorithm based on mixed attention instance segmentation is proposed, which can dynamically adjust the recognition weight of the occluded object and improve the feature extraction and recognition ability of the occluded object in the case of occlusion. At the same time, a probabilistic mismatching removal algorithm is used to remove the wrong matching point pairs and increase the accuracy of pose solution and key frame selection. In this way, the robot pose can be better corrected and the accuracy of system composition can be improved. The proposed algorithm is tested through KITTI open dataset and real scenes, and the results show that the closed-loop accuracy of the proposed algorithm is about 10.7% higher than ORB-SLAM2 algorithm, and the translation error is about 27.6% lower, reflecting good composition ability.
Achieving rapid and accurate crop yield estimation on a large regional scale is significant for China's food security, crop planting structure adjustment, and import and export trade. Oilseed rape is one such commodity in high demand for both national and global consumptions. The development of remote sensing technology has brought new innovations to agricultural yield estimation. Research on oilseed rape in Hubei province sought effective, practical use of limited ground observation data to estimate its yield in a large area. By combining remote sensing data and meteorological data, changes in leaf area index (LAI) during growth and key growth periods are simulated through WOFOST model. The results were used to build a large regional rape yield estimation algorithm based on GF-1 WFV data. The study found that the comprehensive LAI of rape bud moss stage and flowering stage can achieve early, accurate prediction of rape yield. In the bud moss stage, the SR vegetation index showed the best correlation with LAI whereas in the flowering stage, the visible light atmospheric impedance (VARIgreen) vegetation index has the best correlation with LAI. The yield estimation algorithm was then tested in Yangxin county to verify its effectiveness and robustness. Results show the yield estimation error is <6% in contrast to the yield data in the statistical yearbook, indicating that the proposed algorithm has potential usability in large regional scale rape yield estimation.
A generation countermeasure network (GAN) remote-sensing image super-resolution reconstruction algorithm, integrating a multiscale receptive field module is proposed to obtain remote-sensing reconstructed images containing more high-frequency perceptual information and texture details. The GAN algorithm should also be able to solve the problems of training super-resolution reconstruction algorithms and missing reconstructed image details. First, a multiscale convolution cascade is used to enhance the global feature acquisition, remove the normalization layer from the generated countermeasure network, improve network training efficiency, remove artifacts, and reduce computational complexity. Then, the multiscale receptive field and dense residual module are used as the detail feature extraction modules to improve the quality of network reconstruction and obtain more detailed texture information. Finally, the Charbonnier and total variation loss functions are combined to improve the stability of network training and accelerate convergence. Consequently, experimental results show that the average detection outcomes of the proposed algorithm on the Kaggle, WHU-RS19, and AID datasets are higher than those of the super-resolution GAN in terms of peak signal-to-noise ratio, structural similarity, and feature similarity, respectively, by about 1.65 dB, 0.040 (5.2%), and 0.010 (1.1%).
The performance of optical gas sensors is greatly affected by the gas chamber structure. However, there are few researches aimed at improving the optical gas sensor by improving the structure of the gas chamber. Improving the utilization of chips is crucial to alleviate the global shortage of semiconductor chips and low-carbon environmental protection. In this study, a three-ellipsoidal gas chamber optical sensor with non-dispersive infrared technology is designed to improve chip utilization and satisfy the high performance detection requirements. The proposed sensor can simultaneously detect CO2, SO2, and CO. Furthermore, the optical performance of the gas chamber is studied. The results of the optical path, finite element, and Monte Carlo simulations clearly show that 91% of the energy is concentrated on 23% of the receiving surfaces, which effectively overcomes the problems of short optical path of the direct structure gas chamber and low luminous flux on the photosensitive surface (the optical path length increases by 25%, and the luminous flux increases by 40 times). Moreover, the problem of low luminous flux of the multi reflection structure (approximately 117 times) is mitigated. The signal-to-noise ratio distribution is 10-100 times that of the multireflection and direct reflection. Therefore, the proposed three-ellipsoidal gas chamber structure is of great significance for manufacturing high-end multicomponent combined gas sensors.
Aiming at the problems of inaccurate recognition results and large deviation of target orientation detection when 3D target detection is carried out by laser radar during auto driving, a 3D target detection method of laser radar based on improved PointPillars is proposed. First of all, based on Swin Transformer's improved two-dimensional convolution downsampling module of PointPillars, the self attention mechanism can be used in the network feature extraction phase to enrich context semantics and obtain global features, and enhance the feature extraction ability of the algorithm. Second, the ground part of the point cloud is removed by using the characteristics of the point cloud column to reduce the impact of redundant point clouds, so as to improve the recognition accuracy of 3D object detection. The experimental results on the public dataset KITTI show that the proposed method has higher detection accuracy. Compared with the original PointPillars, its average detection accuracy is increased by 1.3 percentage points, which verifies the effectiveness of the proposed method.
The photon counting lidar earth observation means denoted by ICESat-2 have the features of small ground footprints, high repetition frequency, and multibeams. The plane accuracy and flight direction data density of acquired point cloud have been greatly improved. As a result, it can be applied as a novel three-dimensional control condition to enhance the precision of satellite image location. To address the application problem of photon point clouds without synchronous image recording plane position, the research suggests a technique to enhance the positional accuracy of satellite images supported by spaceborne photon counting laser point clouds. First, the three-dimensional terrain profile matching approach is used to achieve precise registration between photon point cloud data and digital surface model (DSM) for the automatic generation of satellite stereo images. Then, terrain feature points are retrieved from the photon profile point cloud based on slope change, and the common terrain feature control points are produced by combining several terrain features of DSM. Finally, the terrain feature points as planimetric and elevation control conditions are added into the satellite image block adjustment with additional parameters to further improve positioning accuracy. Experimental results on the ZY-3 satellite images and ATLAS ATL03 data in Shaanxi Province demonstrate that the proposed method can efficiently improve the accuracy of the ZY-3 image plane and elevation positioning compared to completely uncontrolled positioning method and shuttle radar topography mission (SRTM) data-assisted positioning method. The proposed method's efficacy and viability are confirmed by the fact that the increasing rates of plane accuracy and elevation positioning accuracy over SRTM data can reach 60% and 34%, respectively.
Microspheres can modulate the light field and focus the incident beam into an extremely narrow area on the back of the microsphere, so that the incident beam's full width at half maxima is smaller than the optical diffraction limit, and the focused intensity is considerably higher than the incident one. In addition, the microspheres have high numerical aperture characteristics, which can improve the collection efficiency of detection signals. Based on these benefits, microspheres offer a novel concept and method for realizing optical super-resolution imaging and fluorescence enhancement. Super-resolution imaging and fluorescence enhancement technologies based on optical microspheres are simpler, more direct, and easier to implement than traditional technologies. Their imaging and enhancement effects are comparable to those of traditional technologies. They have significant research value and application prospects in biological imaging and medical detection. Although the studies on microsphere-modulated light field to achieve fluorescence enhancement has made significant progress in recent years, review papers focusing on this topic are still limited. A systematic summary of microsphere-enhanced fluorescence and microsphere-modulated light field is critical for future studies and developments in this field. First, microsphere-based optical super-resolution imaging, including bright field super-resolution imaging and fluorescence super resolution imaging, is introduced. Subsequently, the microspheres-based fluorescence enhancement research is described, including phenomenon research, mechanism exploration, and discussion of influencing factors. Finally, the progress and applications of microsphere-based super-resolution imaging and fluorescence enhancement are summarized, and the future development challenges and trends in this field are discussed and prospected.
Fundus disease is a major cause of blindness. Early detection and timely treatment of fundus diseases can be achieved using optical coherence tomography (OCT), which is an effective approach for preventing blindness. Computer-aided diagnostic techniques are gaining attention as they relieve the pressure on physicians to read films. However, researchers studying computer-aided technology cannot access fundus OCT data owing to privacy concerns. To address this issue, in this study, we searched and combed eight free publicly available fundus OCT databases, interpreted the OCT image features of typical fundus diseases, screened 64 papers based on these computer-assisted algorithm data, and categorized the contributions of these studies. To facilitate the clinical application of computer-aided technology in the early diagnosis of fundus diseases, future efforts can be made in three aspects: improving the stability, repeatability, and generalization of high-precision classification for fundus OCT images; improving the segmentation ability for fundus OCT images; and improving the interpretability of computer-aided algorithms.
The ionospheric space environment is complicated, and the ultraviolet-band light energy is feeble. Therefore, an important part of the study of the far ultraviolet ionization layer hyperspectral load is understanding how to suppress the stray light of a far ultraviolet hyperspectral imager. As per the system technical requirements, this paper presents a stray-light suppression method for a single toroidal grating hyperspectral imager. To evaluate the stray-light suppression effect, we first examined the main sources and propagation paths of stray light, then designed a structure for stray-light elimination using the UG software, and finally used the LightTools software to simulate the energy response of the receiving surface under various fields of view and grating diffraction levels. The results demonstrate that the difference between the stray light energy out of the field of view and the light energy in the field of view is 10-5-10-7, and the difference between the non-working diffraction level light energy of the grating and the working level light energy is 10-6-10-8, and the spectral stray-light coefficient at the central wavelength is 0.9975%, indicating that the proposed method meets the requirements of far ultraviolet hyperspectral remote sensing in space.
Deep learning-based filtering hyperspectral imaging technique can reconstruct hyperspectral images, which only requires deep learning and a few filters for spectral sampling. The filters are also directly integrated with the image sensor, resulting in a simple structure and quick imaging compared to typical snapshot hyperspectral imaging technology. However, most existing studies directly use the images taken by the original hyperspectral imager as the dataset without preprocessing, ignoring the impact of the original hyperspectral imager on the dataset. In this study, the dataset was preprocessed by examining the imaging mechanism of the original hyperspectral camera, which means that the hyperspectral image was converted into a radiative power spectrum to remove the effect of the original hyperspectral camera, resulting in a more robust model than in previous studies. Furthermore, because the spectral response function has poor smoothness, the filters are difficult to produce; thus, the smoothness constraint is incorporated into the error function to create a smooth and easy-to-produce filter.
To prevent criminals from using various delivery channels to transport weight loss drugs doped with toxic and harmful non-food raw materials, a pattern recognition method for weight loss drugs based on terahertz time-domain spectroscopy is proposed in this study. Compared with traditional methods, terahertz spectrum has a high signal-to-noise ratio in time-domain, which is fast, time-saving, and lossless. In this study, seven weight loss drug types were selected as experimental samples. The terahertz time-domain spectra of the samples were collected; accordingly, three characteristic frequency intervals of 0-0.19 THz, 1.75-2.14 THz, and 2.23-2.5 THz were detected by the automatic peak finder. The characteristic frequency intervals were processed using the Hilbert transform, Butterworth low-pass filter, fast Fourier transform low-pass filter, and first derivative after standard normal transform. Subsequently, the obtained feature data was fused with the original spectrum. The original data and the data fused by the four methods were classified and recognized using particle swarm optimization least squares support vector machine and random forest models. The experimental results demonstrate that the particle swarm optimization least squares support vector machine model has the best recognition effect on the spectral feature fusion data after Hilbert transform, whose accuracy can reach 100%. This approach can be used as a reference for the identification of weight loss drugs in forensic science.