







Please enter the answer below before you can view the full text.
9+7=

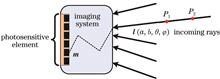
Calibration is the basis of accurate vision measurement in an imaging system, and its purpose is to establish the mapping relationship between object points in three-dimensional space and image points on the sensing plane. Different from the traditional pinhole projective model, a ray model for the calibration and measurement of imaging system is introduced in this paper. The model assumes that each pixel point of the imaging system in focus state corresponds to a virtual primary ray in space. By determining the parameters of ray equations corresponding to all pixels, calibration and imaging characterization can be achieved, thereby avoiding the structural analysis for complex imaging systems and modeling. Complex imaging systems include special imaging systems such as light field camera, large distortion lens, and telecentric lens. This paper reviews the basic principles of the ray model and the development of its calibration methods, and presents some of the progresses made by our team in the 3D measurement with fringe structured light based on the ray model, showing that the ray model can be used for high accuracy measurement of various complex structural imaging systems. It is an effective model for calibrating non-pinhole projective imaging systems.
Pose estimation for objects is employed in rich artificial intelligence fields, such as robotics, unmanned driving, aerospace, and virtual reality. This paper mainly discusses the mainstream measurement systems and methods in term of research status, frontier trends, and hot issues, the differences, advantages and disadvantages of which are compared and analyzed in detailed. In general, virtual-camera-based pose estimation systems have outstanding system integration while providing with high accuracy and low cost. Deep-learning-based methods exhibit excellent performance in adaptability of scenes and objects, which are expected to be widely used in unstructured industrial scenarios. Finally, starting from the perception of scenes and objects, this paper analyzes many severe challenges faced by the current pose estimation technology, and looks forward to the research focus and direction of pose estimation technology.
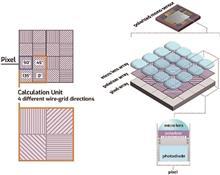
Polarization imaging is a new photoelectric imaging technology that captures more information than traditional imaging technology. It has advantages in measuring transparent, high reflection/radiation, and textureless targets. Polarization imaging is still in the exploratory stage in industries, although it has been widely used in astronomy, remote sensing, and underwater imaging. This paper summarized the development and current status of polarization imaging and industrial detection as well as three-dimensional measurement based on polarization imaging to promote its popularization and application in industries. Further, the key technologies of polarization imaging for industrial vision were analyzed, and the future development direction of the related technologies was explored.
Digital shearing speckle pattern interferometry (DSSPI), also named shearography, is an extensively researched non-contact high-sensitivity optical measurement method. The recent development of shearography, ranging from key technologies to applications is presented in detail within this paper. The new technologies of shearography, such as spatial phase-shifting shear interferometry, multi-directional shear interferometry, and multi-functional multiplex measurement, are described in detail, and their applications in nondestructive testing in aerospace, automobile, machinery, new materials, and other fields are introduced. At the end of the article, the pros and cons of shearography are analyzed, and the potential research content is discussed.
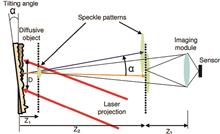
Microvibration sensing technology based on laser speckles has several advantages, including noncontact, system compact, invisibility, high sensibility and long sensing distance, and it can be used in medical treatment, aerospace, civil engineering, security, national defense, etc. In this paper, we reviewed the development of microvibration detection using laser speckles according to the developing sequence and detection scheme. Here, we introduced four detecting schemes, including high-speed area array camera, photodetector, line array camera, and rolling shutter camera. Furthermore, we discussed their advantages and disadvantages and summarized the algorithms for extracting vibration signals. Additionally, we provided an outlook on future development trends in laser speckle-based microvibration detection.
Compared with contact measurement, machine vision inspection, a noncontact measurement, has the advantages of high efficiency, complete information, good stability, and recognizable defects. It has been used increasingly in the field of gear inspection. Many gear inspection instruments based on machine vision technology have been developed in the last 10 years, including video measuring machines, flash measuring machines, CVGM instruments, and online inspection equipments that can perform both comprehensive gear inspection and analytical gear measurement. This paper examines the development processes and characteristics of gear visual inspection instruments; analyzes the research and application progress of algorithms such as edge detection, subpixel positioning, feature extraction, and pattern recognition in gear visual inspection; summarizes the technical development of machine vision in gear accuracy measurement and gear defect inspection; and identifies the future development prospects of gear visual inspection instruments and technology.
Three-dimensional (3D) imaging faces challenges due to machine vision requiring complicated applications and diverse functionalities. Due to its compact structure and reliable performance, 3D imaging using single-camera stereo vision (SSV) offers a considerable approach to object reconstruction and situational awareness under spatially-limited conditions. In this paper, we demonstrated the theoretical basis for SSV-based 3D imaging. Next, we introduced 3D imaging techniques based on known or unknown camera motion, and those using reflective, refractive, or diffractive optical elements based on system setup, basic principle, and implementation methods. Furthermore, we analyzed existing methods based on their strengths and shortcomings in the field of view, spatial resolution, viewpoint flexibility, and dynamic response. Particularly, the calibration methods of misalignment parameters between the camera and optical element are reviewed to enhance 3D reconstruction accuracy. In addition to the technical challenges and potential applications, we discussed the development trends of SSV-based 3D imaging toward a wide field of view, high resolution, high dynamic and real-time capability, and strong environmental adaptability.
With the advancement of deep neural networks, research in visual perception and natural language processing has made significant progress. However, almost all current state-of-the-art deep neural models use static inference graphs, with the inference depth remaining constant throughout the inference stage. Because of this static inference mode, the model cannot adapt its depth to the complexity of the input data. Hence, static models cannot achieve a good trade-off between efficiency and accuracy. Conversely, depth-adaptive dynamic neural networks can decide the inference depth adaptively based on the complexity of the input data, indicating a promising research field for achieving efficient and robust deep models. We comprehensively review the works in this field and summarize the current literatures in three areas: depth-adaptive neural network structure design, data complexity estimation approaches, and depth-adaptive neural network training methods. Finally, we discuss the important future research problems in this field.
In the current intelligent manufacturing process, the requirements for zero scratch quality of precision products and instrument surfaces are constantly improving. The scratch detection method based on machine vision shows important research significance because of its non-destructive and high-precision characteristics. This paper summarizes the development status of scratch detection technology based on machine vision and divides the current mainstream scratch detection methods into manual design features and deep learning methods. The scratch detection methods based on manual design features include gray distribution statistics, transform domain, and high- and low-dimensional space mapping methods. The scratch detection methods based on deep learning include supervised and unsupervised learning methods. The advantages of each method are summarized, disadvantages and application scenarios are described, and development trends of scratch detection technology based on machine vision are expounded.
With the more frequent space launch activities, amount of space debris increase rapidly, which pose a heavy threat to the in-orbit functional spacecraft. Space debris detection is the basis of space debris environment modelling, active debris removal, and collision avoidance maneuver. Therefore, space debris detection plays an important role to maintain the space safety and space sustainability. First, the existed ground-based and space-based space debris detection systems are reviewed, and corresponding key technologies are analyzed. Second, the space debris detection technologies based on optical sensors, radar, and impact detectors are reviewed, respectively, the corresponding difficulties and key technologies are also introduced. At last, the future development trend of space debris detection is discussed.
The development of optical 3D shape measurement has been very mature, and has a wide range of applications in industrial manufacturing, biomedical, cultural relic protection and other fields. But sinusoidal fringe used in traditional fringe projection measurement cannot avoid the Gamma effect of projector and camera, which leads to the increase of measurement error. The nonlinear problem is solved by the appearance of binary fringes from the fringe generation, whose discontinuous gray value avoids the influence of nonlinear errors on the measurement results. At the same time, with the development and maturity of digital projection technology, the binary fringes have an absolute advantage in projection speed, compared with gray stripes. Therefore, defocusing projection technology has been widely studied and applied. Based on the brief introduction of the principle of defocus projection and the characteristics of binary fringe, the binary fringe modulation techniques are summarized, and the characteristics and applicable scenarios of different modulation techniques are analyzed. Finally, the future research direction of binary fringe defocused projection is prospected.
In this paper, we proposed a piecewise step phase coding method to solve the error codes occurring in the three-dimensional (3D) shape measurement method using the phase coding technique in the phase unwrapping for the wrapped phase of high-frequency fringe. The first step codewords were used to encode the order of the second step codewords. After two groups of phase coding fringes were projected for the recovery of two sets of codewords, two extra misaligned Gray code patterns were projected to obtain two codewords shifted by half period from the two sets of codewords, respectively. By taking advantage of the mismatch between the misaligned and original codewords, we selected different codewords for complementary decoding. Therefore, more reliable fringe orders were obtained for 3D reconstruction. Experimental results reveal that the proposed method is robust in decoding codewords and can label more fringe periods than the complementary Gray code method using the same number of projected auxiliary patterns. Furthermore, the proposed method accurately reconstructs 3D shapes of complex objects with denser high-frequency sinusoidal fringes.
In this study, an imaging system combining cameras and rotating Risley prisms is proposed to address the difficulty of considering the field of view and spatial resolution in a target scene’s three-dimensional (3D) reconstruction. The imaging system can form a virtual camera array under different Risley prism rotation angles, adjust the array virtual cameras’ imaging position using rail movement, and realize a subregional multiview image acquisition in a large field of view. A calibration approach of the array virtual camera’s internal and external parameters using a geometrical transformation relationship is proposed, and the subregional 3D point cloud acquisition approach based on the triangulation principle is established, employing the camera projection model and the double-prism refraction model. A prelocalization approach for overlapping regions of multiview pictures is presented on this basis, and a coarse-to-precise subregional point cloud alignment fusion is obtained by integrating the iterative closest neighbor algorithm. The experimental results reveal that the proposed imaging system can achieve largescale and high-resolution 3D target reconstruction and can ensure a 3D reconstruction accuracy due to the coarse-to-precise point cloud alignment approach while enhancing processing efficiency.
As an inverse rendering problem, image-based material editing is essential for augmented reality and interaction design. Herein, we propose a method to edit the object material in a single image and convert it into a series of new materials with widely varying material characteristics. This approach involves specular highlight separation, intrinsic image decomposition, and specular highlight editing. Using a parametric material model, we synthesized a large-scale dataset of objects under various illumination conditions and material shininess parameters. Based on this dataset, we converted the source material into the target material using deep convolutional network. Experiments illustrate that the three parts of the approach are effective on various qualitative and quantitative evaluations, showing the material editing effect on the synthetic image and real test image. This novel material-editing method based on directly editing the specular highlight layer of a single image supports a variety of materials, such as plastic, wood, stone, and metal and efficiently produces realistic results for both synthetic and real pictures.
To simplify the tedious and inefficient manual inspection for connector surface cracks, an intelligent inspection method for connector surface cracks based on machine vision is proposed. To find the region to be examined and the border, the lower boundary of the area to be inspected is first fitted using a fitting approach based on random sampling consistency. Among them, the morphological operation method based on single scale can not effectively extract the crack region. Based on the crack characteristics, this study proposes a crack extraction technique based on multiscale morphological operation, and the comparative experiment demonstrates that this method has a good result and accomplishes the coarse extraction for the fracture region. Then, according to the crack structure characteristics, an adaptive threshold segmentation method is proposed to complete the segmentation for the crack region. Finally, Blob analysis is used to statistically distinguish between genuine and false cracks based on the geographical information of the target connectivity domain and the gray-scale response intensity of the target area. Results show that the proposed method achieves real-time online detection for connector surface fractures with a detection accuracy of 97.1%.
Workpiece recognition is critical for switching painting trajectory in a flexible robotic spray-painting production line. However, due to the wide variety of sprayed workpiece sizes and types, as well as the presence of poor surface texture, multiview dissimilar (MVD) components, and comparable parts, it is difficult to effectively and reliably identify sprayed workpieces in the real production line. In this study, a recognition approach is proposed based on two-dimensional (2D) instance segmentation and three-dimensional feature pairing. Specifically, the high efficiency of the Mask R-CNN learning model was used for 2D workpiece segmentation and coarse recognition based on small sample training; this was followed by the integration of the fast point feature histogram (FPFH) feature for fine recognition, with its strong discrimination of local details for accurately recognizing MVD and similar-topology workpieces. During the fine recognition stage, the intrinsic shape signature method was used as the key point of the workpiece and vectored using the FPFH feature. The extracted feature was then coarsely paired and verified with topological structure consistency and spatial transformation to obtain the paring rate, which was used as the evaluation criterion to recognize the workpiece. In the experiment, more than 1500 workpieces of 34 categories are used for testing, and the recognition accuracy can reach 99.26% with a running time of less than 1500 ms for a single workpiece.
This study proposes a method of landing runway detection based on YOLOv5 network architecture to solve the critical problem of fast and robust runway detection for engineering applications of UAV autonomous landing technology. First, the captured airborne front-view images were enhanced to improve the robustness of the network model based on the YOLOv5 network architecture. Then, features with different scales and different dimensions were fused to improve the precision of the detection network model. Furthermore, the geometric features of the runway were incorporated into the loss function design in the prediction layer to optimize the prediction model. In this study, AirSim was used to simulate visual image landing datasets under complex conditions to validate the effectiveness of the proposed method. The simulation results on these datasets show that the average detection speed of the runway detection algorithm proposed in this study can reach 125 frame/s, and the average detection accuracy is 99%, which outperforms other traditional methods and can meet the fast and accurate requirements of runway detection.
In the machinery manufacturing industry, the measurement results of the size parameters of a workpiece are related to the material use rate and the working performance of the equipment, which has important practical significance. This study proposes a vision measurement method for workpieces based on binocular vision and line-structured light. First, the line-structured light and binocular vision are used to obtain the spatial point cloud of the target surface, and a shortest path search algorithm for the surface distance between any two points based on the spatial point cloud is designed. Then, the geodesic distance measurement results are optimized through surface reconstruction and partial projection. The results reveal that the range of the noncontact measurement is within 100?620 mm, and experiments show that the relative error does not exceed 0.70% compared with manual measurement. This method is expected to be applied to noncontact distance measurements on the surface of a medium-sized workpiece.
Aiming at the issues of camera calibration and orientation in large spatial volumes, a novel joint calibration and orientation method for dual cameras is proposed. In this method, an unmanned aerial vehicle carries a scale ruler to create a spatial virtual calibration field, while two cameras simultaneously take photos of marker points at both ends of the scale ruler. Then, the spatial length of the scale ruler is used as constraint; the self-calibrated bundle adjustment model is developed to calculate the internal azimuth parameters and distortion coefficients of the two cameras and the external azimuth parameters between both cameras. The length of the rebuilt scale ruler is then used to assess the error and accuracy. To validate the proposed method, calibration tests were performed in an outdoor environment with the spatial dimensions of 40 m×10 m×14 m. The results demonstrate that after calibrating the dual cameras using the proposed method, the average length error of the proposed method for reconstructing the scale ruler is 0.193 mm, the root mean square error is 2.316 mm, and the relative accuracy is better than 1/20000. The proposed method can easily and correctly calibrate all the dual-camera system’s parameters in a large measurement volume. Furthermore, the proposed method is simple, costeffective, highly accurate, and has a broad applicability. Moreover, it serves as a reference method and database for the visual assessment of extremely large scale objects.
This paper primarily explores the depth learning method from a single image under the current unsupervised framework. It investigates whether this method can effectively deal with the repetition of the inherent structure and texture of ancient Chinese architectural images and whether it can meet the centimeter-level reconstruction accuracy required by the Chinese architecture documentation standard. Specifically, the accuracy difference of depth learning based on a single image under the image acquisition mode of fixed binocular cameras and the image acquisition mode of a single moving camera is compared using the data obtained by the structured light depth camera as the ground truth by directly comparing the depth map and the three-dimensional (3D) point cloud. The experimental results show that while 3D reconstruction based on multiple images is challenging due to the existence of repeated structures and textures, the impact of the existence on depth learning based on a single image is generally insignificant. In addition, even though depth learning based on a single image has achieved comparable accuracy with laser scanning on many open indoor and outdoor datasets, it is still difficult to achieve the centimeter-level reconstruction accuracy required by the digital documentation standard of ancient Chinese architectural 3D reconstruction. In the future, the shape of prior information will be exploited to improve the reconstruction accuracy.
Image-based space target detection has become one of the crucial requirements to ensure the safety of in-orbit satellites. Existing anchor-free target detection algorithms based on deep learning have achieved outstanding results. However, their detection heads have a simple structure, resulting in insufficient representation ability. To overcome this challenge, we propose a space target detection algorithm based on attention mechanism and dynamic activation. Based on the anchor-free target detection algorithm's general network structure, the channel and spatial aware-based residual attention module is employed in the detection head to improve the network's feature representation ability. Meanwhile, the channel aware-based dynamic activation module is connected in series with the detection head to enhance the network's performance in a specific space target detection task. The experimental findings on the SPARK space target detection dataset demonstrate that the proposed algorithm achieves an AP@IoU=0.50:0.95 of 77.1%, and its detection performance is substantially better than the mainstream algorithms such as Faster R-CNN, YOLOv3, and FCOS. Additionally, to further enhance the detection ability for small targets, the dynamic label assignment approach is adopted in the training process.
Visual target tracking is crucial for an unmanned aerial vehicle (UAV) to conduct a strike, location, and reconnaissance against moving and time-sensitive ground targets; however it is hindered by imaging platform motion, severe occlusion, and target disappearance from the field of vision. A visual ground target tracking approach based on a motion model for UAVs is proposed to enhance the robustness for these challenges. First, a fast optical flow algorithm based on the dense inverse search is used to compute the homography transformation between two consecutive frames, and the target position is mapped from the historical frame to the present reference frame to decouple the motion of the imaging platform. The target motion on the reference frame is then modeled using a linear motion model, which is used to predict the target position when occlusion occurs. Finally, short-term and long-term trackers are combined to solve the tracking drift generated by the false update of the tracker for partially occluded target samples. Based on the discriminative correlation filter, experiments were conducted on the collected UAV videos. The findings reveal that the proposed approach can substantially improve the adaptation to the imaging platform motion and severe occlusion, and can be easily combined with other target tracking approaches.
This paper studies the use of visual guidance system for autonomous landing of fixed-wing unmanned aerial vehicles (UAVs). The research is mainly aimed at improving the speed and accuracy of the visual navigation system to obtain the navigation parameters. The acquisition of parameters by the visual navigation system can be divided into two steps: runway detection and recognition, and relative pose estimation of fixed-wing UAVs. To improve the acquisition speed of navigation system parameters, we mainly improve the detection and recognition efficiency of the time-consuming runway detection and recognition algorithm. In this paper, the spatiotemporal consistency of the runway in the sequence image is used to extract candidate regions, and the invalid candidate regions are reduced without affecting the recall rate. Then the efficiency of runway detection is improved and ultimately the speed of the visual guidance system to obtain guidance parameters is improved. In order to improve the accuracy of the estimated guidance parameters, this paper combines the point and line features on the runway for pose estimation. That improves the pose estimation accuracy by increasing the number of available features. The experimental results show that the proposed method can effectively improve the speed and accuracy of the visual navigation system to obtain the navigation parameters.
Existing deep learning methods handle magnetic resonance (MR) image reconstruction and segmentation as individual task instead of considering their correlations. However, the simple concatenation of the reconstruction and segmentation networks can compromise the performances on both tasks due to the differences in optimization. This paper develops a multi-task deep learning method for the combinatorial reconstruction and segmentation of MR images using an improved teacher forcing network training strategy. The newly designed teacher forcing scheme guides multi-task network training by iteratively using intermediate reconstruction outputs and fully sampled data to avoid error accumulation. We compared the effectiveness of the proposed method with six state-of-the-art methods on an open dataset and an in vivo in-house dataset. The experimental results show that compared to other methods, the proposed method possesses encouraging capabilities to achieve better image reconstruction quality and segmentation accuracy while co-optimizing MR image reconstruction and segmentation simultaneously.
To increase manufacturing efficiency and product quality, robotic arms can replace manual grabbing and other duties. Currently, data-driven algorithms need a significant number of samples to train models, which is less migratory, as well as a specific quantity of processing resources. To address the above issues, this study establishes an efficient robotic arm vision grasping algorithm and system based on RGB-D images. First, we propose a minimum bounding rectangle (MinBRect) target detection algorithm to quickly estimate the target position. Further, the MinBRect is used to calculate the minor axis inclination of the rectangle to estimate the pose for the grasping task, and finally, the UR5 robotic arm is manipulated to perform the actual grasping experiment. In the experiments, the accuracy of the positional estimation of the proposed algorithm for all 10 target objects is above 85.7%, and the average time reaches 0.7677 s. The grasping accuracy and speed of the proposed approach are greatly improved when compared to the two location estimation techniques, indicating that the proposed algorithm has high accuracy and resilience. Furthermore, because no dataset is required, the suggested technique may be used in structured situations with limited computational resources and industrial production, and it has been demonstrated to be portable in power equipment testing. Actual grasping tests are used to validate the effectiveness of the suggested grasping algorithm for the robotic arm system.
The three-dimensional (3D) texture information of asphalt pavement is important information for characterizing its skid resistance. To mitigate the problem of interference to information acquisition due to the high matching error rate in the weak-textured and non-textured areas of the asphalt pavement, this paper proposes a pavement 3D texture information acquisition method using a binocular vision stereo matching algorithm. First, the binocular vision measurement platform is built, and the internal and external parameters of the binocular camera are obtained using Zhang Zhengyou’s checkerboard calibration method. Second, for the digital images collected by the binocular camera, the stereo matching algorithm that introduces the cross-scale cost aggregation model is used to get a better parallax map. Finally, we obtain the 3D model of the pavement texture using reverse reconstruction, and then the pavement texture information is obtained. The experimental results show that the proposed method reconstructs a more accurate 3D model of the road surface with the relative error within 5% and has a high accuracy and a good robustness for obtaining road texture information.
Focusing evaluation algorithms are the core of the superposed large depth of field imaging. Aiming at the experimental requirements of evaluating the performance of the focusing evaluation operator, we proposed a focusing evaluation operator performance evaluation method using image sequence sampling-point focusing evaluation and scatter plot Gaussian fitting. The performance evaluation experiments are performed on the existing focusing evaluation operators. Furthermore, we proposed a gradient-weighted image sharpness operator by modifying the traditional image sharpness index. The performance difference between the new and existing operators is compared using real and simulated images. The research results have certain reference significance for the implementation of stacking measurement.
To address the problem of accurate measurement of relative pose of the target object in machine vision, this paper proposed a method, which applies a depth camera to acquire 3D point cloud data of target object, to achieve its relative pose perception. This method selected homonymous points based on a priori knowledge of spatial structure of the target object and applied a single binocular vision measurement system to obtain the 3D point cloud data of the target object while analyzing and processing the data to achieve homonymous point recognition. Furthermore, this method calculated the coordinate values of three homonymous points of the target object on the object coordinate system and the camera coordinate system, respectively, and solved the relative pose by using singular value decomposition (SVD). This method effectively solved the problem of 3D object pose perception and improved the efficiency of pose perception. The experimental data demonstrate that the relative error of six degrees of freedom measured by the proposed method is within ±0.5° and ±1 mm, which satisfies the application of machine vision pose perception in industrial production.
Multiexposure image fusion is an effective high dynamic range imaging method. The fused high-dynamic-range image contains additional details and information. Currently, most conventional multiexposure image fusion algorithms suffer from detail loss and color distortion, affecting further image observation and processing. To improve the clarity, detail information, and color authenticity of the fused image, a high dynamic range imaging method based on YCbCr spatial fusion is proposed. The red-blue-green (RGB) image is converted to the YCbCr color space, an improved moderate exposure index is proposed to fuse the luminance component with multiresolution weighting, and the chrominance component is fused using the threshold-based weighting method. Experimental results show that the visual effect of the fused image obtained using the proposed method appears more real and exhibits better color expressiveness and the definition is considerably improved, which can well address the problems of color distortion and information loss in conventional high dynamic range imaging methods based on the RGB color space.