








Please enter the answer below before you can view the full text.
7-1=

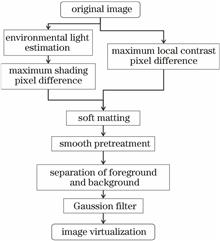
This study proposed an image background blurring algorithm based on color constancy. First, color constancy was used to detect the illumination of the image using which the Lambertian surface model was constructed. Next, the maximum mask pixel difference was compared with the maximum local pixel difference, and the image depth map was obtained using the soft matting algorithm. Furthermore, the image was divided by the gray value to obtain the foreground and background portions. Finally, the image background was blurred using the Gaussian filter. Using the proposed method, the foreground and background of the monocular image can be accurately obtained and the blurring effect is obvious.
Automatic recognition of handwritten Chinese has a wide range of applications in document digitization and handwritten note transcription. A method based on attention mechanism is proposed to recognize the handwritten Chinese characterized by their random writing, complex structure, and large number of features. Based on the traditional convolutional neural network (CNN) model, an attention-CNN (AT-CNN) model is proposed. The information interaction between each layer in the network is realized using attention mechanism, thus the information loss caused by pooling operations reduces. Experiments on the classical handwritten Chinese data set HWDB show that the recognition accuracy of this method can reach 95.05%, which is significantly improved compared with that by other models.
Diffusion-based inpainting is a common method of small-area image tampering, considering the blurring effect introduced by diffusion-based image inpainting, this paper proposes a method of diffusion-based image inpainting forensics via gradient domain guided filtering enhancement. Since the texture of the forged image is clear in the untouched regions, and the blurring effect results in some texture changes in the inpainted regions, gradient domain guided filtering can better preserve the texture structure of the untouched regions and highlight the blurring effect of the inpainted regions. In view of the fact that the tampered information is reflected to different extend in different color channels, the gradient domain guided filtering is applied to enhance each color channel of the input image, which captures the impact of image inpainting from multiple perspectives. Experimental results show that this method can not only detect and locate the diffusion-based image inpainting regions effectively, but also has better detection performance than the existing methods.
In view of the difficulty in detecting the surface cracks of ceramic tile with complex background, this paper presents an algorithm for detecting the surface cracks of ceramic tile based on principal component analysis. First, red channel image converted from the ceramic tile color image was preprocessed. Then, the principal component analysis method was used to reconstruct the image of ceramic tile. The image with crack information was obtained by differential processing between the preprocessed image and the reconstructed image. Finally, binary and morphological processing methods were used to extract the parameter information of cracks. Experiments show that the algorithm can detect the cracks of ceramic tile with three-dimensional morphological structure and complex background interference, faster detection speed with accuracy rate as high as 96% can be achieved compared with other algorithms.
An improved AlexNet structure is proposed to solve the problem of long time and low recognition accuracy of an AlexNet training finger vein recognition system. To address the problem of limited image size and poor adaptability of an AlexNet network model, the network structure of spatial pyramid pooling mode is introduced. To fasten the network’s training speed and reduce the complexity of the network model, the convolution kernel size of AlexNet, network depth, and the full connection layer are adjusted. Results show that the improved network model has a significant improvement on the recognition accuracy and training duration compared with the AlexNet model in both public and private finger vein datasets.
Optical music recognition plays an important role in the field of music information retrieval and computer aided instruction. For traditional frameworks, the processing steps are complicated, and the accuracy is low. Moreover, deep learning algorithm-based model training takes a long time and shows large recognition error for difficult notes. In this work, an improved convolutional recurrent neural network is proposed. First, different noises were added to the original score to expand the score image and improve the robustness of the training model. Then, the multi-scale residual convolutional neural network was used to extract note features to improve the subsequent recognition accuracy. Finally, bi-directional simple recurrent units were adopted to recognize note features and accelerate convergence of the algorithm in the training stage. Experimental results show that the average symbol error rate of the proposed network model has been reduced to 0.3234%. Thanks to the faster converging rate, the training time is about one third of that of traditional convolutional recurrent neural network.
In this study, we propose an improved gradient domain adaptive tone mapping algorithm based on the color correction model to solve the damage of chromaticity information with respect to the process of image brightness compression in a high dynamic range, resulting in severe color gradation in regions having different image brightness and shade after tone mapping. The image brightness can be restored by combining the Gaussian pyramid of the image luminance space and Poisson equation. Subsequently, we introduce the chromaticity space color correction algorithm and apply linear interpolation between the chromatic aberration of the image and the achromatic color. Further, we adjust the color correction factor by calculating the brightness ratio before and after processing to enhance image saturation. Finally, we realize adaptive correction of the image chromaticity information. We also perform a comparison with the typical Larson, Drago, Reinhard, and gradient domain local tone mapping algorithms. The results prove that the image processed using the improved algorithm exhibits good optimization with respect to the information entropy, contrast, and average gradient. The proposed method effectively reduces the color shift because of brightness compression and enhances the overall color perception of the image.
In this study, we propose a method based on improved Faster R-CNN with respect to the influence of light penetration, occlusion, environmental background, and shooting angle on the insulation piercing connectors and bolts on the transmission line. First, we enhanced the acquired datasets via flipping, panning, and angle rotation. Second, we compared the influences of different training sets on the model. Finally, we used a deep residual network (ResNet50) having a considerable network depth and less amount of computation to replace the VGG-16 (Visual Geometry Group 16) network for extracting the image features owing to the small size of the bolt. Further, we analyzed the influences of different models and parameters on the identification accuracy. The result proves that the improved Faster R-CNN model has an mAP value of 92.4%, which is 2.8 percentage higher than that of the unmodified Faster R-CNN model. The deep learning target detection model can be used to appropriately detect and identify the insulation piercing connectors as well as bolts having different resolutions and position angles. Therefore, this model has a high engineering application value.
In this study, we propose an intelligent identity authentication method for an optimized convolutional deep belief network to address the information security problem faced by smart phones. First, the collected raw data is preprocessed and then input into the sparse autoencoder for pretraining. The pretrained weight is used as the convolution kernel of convolutional deep belief networks, and the layer-by-layer greedy algorithm is adopted to formally train the model. Subsequent to the training, the extracted features are integrated with the root mean square layer, and the weight between the root mean square layer and the output layer is adjusted using the supervised learning algorithm. Finally, the classification results are output through the Softmax classifier. The proposed method can directly process high-dimensional gesture data and establish a gesture model for feature extraction. Simulation results show that compared with the hidden Markov algorithm and the deep belief network algorithm, the proposed method can significantly improve the accuracy of identity authentication.
In this study, we propose a hyperspectral image classification algorithm based on multiple features and the improved stacked sparse autoencoder network to solve the problems of insufficient feature utilization and less training samples. The low-dimensional data structures of the hyperspectral images can be obtained using manifold learning, and the local binary pattern (LBP) features with spatial information and extended multi-attribute profiles (EMAP) features can be extracted from the hyperspectral images. Further, Active learning is used to query and label highly characteristic unlabeled samples. Then, the samples fusing space spectrum joint information are used to train the stacked active sparse autoencoder neural network; these samples are subsequently classified using the Softmax classifier. The overall classification accuracy of the Indian pines dataset was 98.14%, whereas the overall classification accuracy of the Pavia U dataset was 97.24%. The experimental results prove that the proposed algorithm has a high classification accuracy and can appropriately classify the boundary points.
To address the inability of traditional crack image segmentation methods to inaccurately extract the crack on the concrete surface, an improved lightweight global convolutional network crack image segmentation model is proposed in this study. Based on the principle of deep convolution network, the large convolution kernel is used to classify and locate crack images. For the characteristics of cracks, a lightweight semantic segmentation model MobileNetv2-GCN is constructed. Experimental results show that the MobileNetv2-GCN model delivers superior performance in three open crack datasets. The central axis skeleton algorithm is used to extract the crack skeleton subsequent to semantic segmentation, and the physical value of the average width of the crack is calculated. The proposed model has high accuracy and can provide reliable data support for road quality detection.
With the rapid development of style migration technology, the global style migration technology has basically taken shape, but in the actual application process, there are problems such as the local style migration of the target area of the picture. Aiming at the above problems, this paper combines the residual network based on the convolutional neural network, and proposes a local style migration method based on residual neural network. Firstly, the mask is used to segment the content map to extract the target region. Secondly, the convolutional neural network extracts the image features and performs feature fusion. Then, the residual network is used to speed up the formation of the graph. Finally, the deconvolution is generated. A picture that only completes the style transition for the target area. In this paper, the several experiments are designed on the Microsoft Coco2014 dataset. The experimental results show that the local style migration network model based on residual neural network has better local style conversion ability and higher execution efficiency.
In order to improve the details of fusion image from infrared and visible image and reduce artifacts and noise, an infrared and visible image fusion algorithm based on ResNet152 deep learning model is proposed. Firstly, the source image is decomposed into the low frequency part and the high frequency part. The low frequency part is fused by the average weighting strategy to put a new low frequency part. The high frequency part is extracted by ResNet152 to obtain multiple feature layers.The L1 regularization, convolution operation, bilinear interpolation upsampling, and maximum selection strategy for the feature layers to obtain the maximum weight layer. Multiplying the maximum weight layer and the high frequency part to obtain a new high frequency part. Finally, the image is reconstructed by the new low frequency part and high frequency part. Experimental results show that the proposed algorithm can get more texture information while retaining the significant features of the image, and effectively reduces artifacts and noise. The subjective evaluation and objective evaluation are better than the comparison algorithm.
The emergence of kernelized correlation filter has pushed the traditional target tracking algorithm to a new height. With its high speed, high precision, and high robustness, it has quickly gained wide recognition and attention from the society. In view of the shortcomings of the kernelized correlation filter in scale change, based on the relative position of the main features of the target when the scale changes and fast moving, the size of the target can be reflected. The block detection method is used to calculate the scale of the target. In respect, the kernelized correlation filter loses the target when dealing with the target with high-speed changes of the feature, and the target template is updated in advance by Kalman filter prediction to solve the problem of template update lag. Experimental results show that the proposed algorithm can improve the tracking accuracy steadily.
To improve the quality of multi-focus image fusion, a fully convolutional neural network multi-focus image fusion algorithm based on supervised learning is proposed. The proposed algorithm aims to use neural networks to learn the complementary relationship between different focus areas of the source image, that is, to select different focus positions of the source image to synthesize a global clear image. In this algorithm, the focus images are constructed as training data, and the dense connection and 1×1 convolution are used in the network to improve the understanding ability and efficiency of the network. The experimental results show that the proposed algorithm is superior to other contrast algorithms in both subjective visual evaluation and objective evaluation, and the quality of image fusion is significantly improved.
Non-uniform suspended particles block the cracks of the underwater culverts. Therefore, we propose a culvert crack defect segmentation algorithm based on enhanced hue features in this study. The color-sensitive hue features can be enhanced using the proposed algorithm; this forms the basis for performing rough image segmentation. The rough segmentation result is considered in the spatial domain to avoid the interference of the culvert wall depression in the image segmentation results. The connected region is used as the local unit, and the region feature is used to filter the interference and complete the segmentation. The experimental results prove that the cracked defects can be effectively segmented using the proposed algorithm.
The ability to correctly divide the ridges into “ridges” and “grooves” is the key to the independent cultivation of agricultural machinery in the ridges. Although the color and texture of the ridge row show diversity depending on the soil and the way of trenching, the scale of the ridge row in the image gradually decreases from near to far. Based on this feature on the ridge scale, this paper proposes a multi-scale segmentation algorithm for ridge row. The method uses the Gaussian difference pyramid structure to construct the multi-scale feature set of ridge rows. Then, according to the distribution of ridge rows in different scales, the image in multi-scale feature set is centralized and saturated with gray value. Finally, each feature image is segmented and weighted respectively to divide the image into “ridge area” and “ditch area”. Experiments on 40 ridge rows show that the proposed algorithm can effectively segment ridge rows in different scales, and effectively suppress the noise generated by local soil characteristics.
Compressive sensing (CS) is proposed as a new signal compressive sampling theory in recent years. At the coding end CS obtains compressed data through projection, which requires more computing resources and higher implementation cost. Different from the standard compressed sensing, this paper proposes an image compression sampling method based on edge information assistance. In other words, some pixels of the image are randomly collected as measurement, and the pixels near the image edge are sampled with a high probability. Finally, the nonlinear optimization method is used to restore the image. The proposed sampling strategy obtains the random measurements and the adaptive measurements respectively through two steps. This paper gives the physical description of the sampling strategy and realizes it through simulation experiment. At the same time, the optimal ratio of edge information in sampling matrix is also discussed. Experimental results show that the proposed algorithm can quickly and effectively recover high quality images.
In order to improve the accuracy of object classification of point cloud data from airborne LiDAR, an object classification method for multi-source fusion point cloud data based on Point-Net is proposed. Point clouds can effectively represent three-dimensional features of objects, and remote-sensing images contain detailed spectral information. Therefore, a registration and fusion method for point cloud data and remote sensing images is designed to comprehensively utilize their advantages. Meanwhile, considering the lack of neighborhood information in Point-Net, a multi-scale Point-Net classification model for fusion point clouds is also proposed to realize effective classification of fusion point cloud data. The proposed algorithm is verified with point cloud data from urban regions and the classification effect is evaluated by analyzing the classification accuracy and time. Results show that, compared with other methods, the proposed method can effectively improve the classification accuracy of point cloud data, and achieve effective classification of point cloud data in urban areas.
Pneumonia detection has important research significance in medical image processing. For the problem that the current classical detection algorithms has low accuracy in detecting pneumonia lesions. This paper presents an algorithm for detecting pneumonia lesions in X-ray images based on multi-scale convolutional neural networks. The feature channel attention module is added to the basic feature extraction network to highlight the channel containing useful information in the feature map, and to suppress the feature channel without lesion information or containing a large amount of useless information to form a high-quality feature map. Then through statistical analysis, a series of candidate frames with different aspect ratios and scaling scales are designed using clustering algorithm to be suitable for pneumonia lesion detection. In this paper, the single-model and multi-model detection experiments are performed on chest X-ray datasets containing pneumonia lesions. The detection accuracy is 82.52% in the case of single model and 89.08% in the case of multi-model fusion. Through comparison experiments and results analysis, the proposed algorithm is superior to other detection algorithms in pneumonia lesion detection and is suitable for pneumonia lesion detection in X-ray images.
For indoor sound source localization algorithm based on microphone arrays, its accuracy is greatly influenced by the reverberation and noise. Traditional sound source localization approaches cannot keep high localization accuracy in strong reverberation and low signal-to-noise ratio environments. To tackle this problem, a novel indoor sound source localization algorithm based on convolutional neural network is proposed. By extracting the phase weighted generalized cross correlation function of the received signals from microphone arrays as training feature, the three-dimensional localization information of target sound source can be obtained. Experiments based on NOIZEUS database demonstrate that the proposed algorithm can be adapted to different acoustic conditions via training. Compared with other learning based indoor sound source localization algorithms, the proposed algorithm has good localization performance and robustness in strong reverberation and low signal-to-noise ratio environment, suggesting high research and application value.
A point set registration algorithm based on symmetric Kullback-Leibler (SKL) divergence is proposed. Each point in the point set is represented as a Gaussian distribution. The Gaussian distribution includes the location information of the point and the influences from surrounding points. The whole point set is modeled as a Gaussian mixture model (GMM). The registration problem of two point sets is thus formulated as the minimum value solution of SKL divergence between two GMMs. The genetic algorithm is used for optimal solution. The experimental results show that the proposed algorithm is robust to noise, outliers, and missing points, and achieves good registration accuracy.
Retinal blood vessel segmentation is one of the key components in the construction of fundus image analysis and computer-aided disease diagnosis systems. In this paper, a method of retinal blood vessel segmentation using Hessian-based orientational adaptive Gabor wavelet is proposed. According to the eigenvector of the Hessian matrix, the orientation of the blood vessel is obtained and set as the direction angle of the Gabor wavelet transform. By extracting the features of the four-scale orientational adaptive Gabor wavelet in combination with the large eigenvector of the Hessian matrix, five-dimensional retinal blood vessel features are constructed. The segmentation of the blood vessels can thus be realized through classifying the pixels of the fundus images with the support vector machine. The proposed method can accurately sense the direction of the blood vessel by only calculating the filtering response of the Gabor wavelet in this direction, which reduces the computational complexity of the feature extraction and achieves good complimentary between the large eigenvalues of the Hessian matrix and Gabor wavelet features. Experiments using the proposed method are performed on the DRIVE database to obtain better segmentation performance. The proposed method shows good performance in the extraction of small blood vessels and in the detection of vascular points at bifurcation and intersection.
In this paper, a LiDAR simultaneous localization and mapping (SLAM) pose optimization algorithm is proposed based on graph optimization theory and global navigation satellite system (GNSS) data. By adding the satellite positioning node into the pose graph, the trajectory error can be effectively controlled within the range of GNSS positioning error when there is no loopback. In long distance loopback, the loopback detection point can be accurately located, which improves the global consistency of the LiDAR SLAM pose graph. The proposed algorithm is tested in the urban environment with better rigidity and in the non-urban environment with weaker rigidity. Experimental results show that the trajectory drift can be controlled to be about 1 m for 300 m straight-line mapping when there is no loopback. In the case of long distance (above 360 m) loopback, the proposed algorithm controls the trajectory drift to be within 0.2 m and about 0.1 m for the primary and the secondary loopback,respectively. These results fully demonstrate the effectiveness of the proposed algorithm.
In this paper, a blind image restoration algorithm based on reweighted graph total variation combined with hyper-Laplacian is proposed. First, the bimodal distribution of the weight of a blurred image is reconstructed using the reweighted graph total variation. Next, the reconstructed image is used to estimate the continuity and sparsity of the point spread function (PSF) and the blurred image is restored by the PSF. These two processes are repeatedly iterated to make the PSF approach the ideal solution continuously. Finally, we combined it with a priori, that is, the hyper-Laplacian cave, which can best fit a natural image gradient distribution to achieve the non-blind restoration of the blurred image. Experimental results show that the proposed algorithm can give a more accurate prediction of the blurred kernel and effectively reduce the ringing effect in images compared with two representative blind restoration algorithms developed in recent years. Moreover, there is an improvement in subjective vision and objective elevation indicators.
In this study, we analyze the changes in the spot morphology of the far field of the subaperture under the influence of gap and decenter of mask and explore the feasibility and applicable conditions of using the ideal circular aperture template library to match the far-field pattern generated by circular templates with gap and decenter for co-phasing. Further, the shape of the far-field is numerically simulated under different gaps and decenters of mask. The usage of ideal template narrow-band co-phasing is numerically simulated, and the co-phase accuracy of different piston errors under different gaps and decenters of mask is analyzed. The results prove that the far-field extension range will increase with the increasing gap. The larger the decenter of mask is, the less obvious the far-field effect modulated by the piston error will be. The ideal co-phase template can be directly adopted when the gap scaling factor or decenter scaling factor does not exceed 0.3. In this study, we expand the application of the narrow-band co-phase algorithm and provide the basis to further study this algorithm.
The relative pose estimation in case of monocular cameras is generally based on point features. However, it would be difficult to obtain ideal results using this method in a scene, where the textures are not obvious and corners are small. Therefore, we combine the measurement data obtained from an inertial measurement unit based on the homography constraint associated with a planar scene and propose a monocular relative pose estimation algorithm by combining the point and line features. The images of the two consecutive frames can be initially rectified to downward view images using the angle information provided by the inertial measurement unit. Subsequently, the point-line features are detected and matched. Finally, the relative pose of the downward view images can be solved by transforming the relative pose of the original images according to the homography constraint associated with the combination of point and line features. The simulation and real experiments prove that the proposed algorithm is effective and that the relative pose for monocular cameras can be effectively measured.
Wavefront restoration based on deep learning is to obtain Zernike coefficients of wavefront aberration directly from the input light intensity image using the trained convolutional neural network (CNN) model. This method has many advantages, such as without iterative calculation, simple and easy to implement, and easy to quickly obtain phase. The training of CNN is carried out by training a large number of light intensity images of distorted far field and their corresponding Zernike wavefront coefficients, automatically extracting the characteristics of light intensity images, and learning the relationship between light intensity and Zernike coefficients. In this paper, a CNN-based wavefront restoration model is established based on the 35-order Zernike-atmospheric turbulence aberration. By analyzing the ability of this method to restore static wavefront distortion, the feasibility and restoring ability of the CNN based wavefront restoration are verified.
This paper proposes a new no-reference quality assessment method for inpainting Thangka image based on multiple features, and combining the structural and color characteristic of Thangka images to solve the problem that a single feature is confined to reflects the difference in the effect of restoration methods. The proposed algorithm not only uses the rich texture of Thangka images but also selects Gaussian difference operator to extract the line drawing of target image, and combining symmetry characteristic of Thangka image to obtain structural features. Secondly, the color features of Thangka images are extracted according to the difference of color entropy between each superpixels after simple linear iterative cluster segmentation. Finally, considering that the multi-scale features are more consistent with the human visual characteristics, the decomposed image features are input into the adaptive neural network for training, and the objective evaluation score of image quality is predicted. The experimental results show that this method can obtain the scores which is consistent with the subjective evaluation by utilizing the structure and color characteristics of Thangka images, and its Spearman correlation coefficient and Pearson correlation coefficient are both above 0.94.
In this study, an efficient Fourier ptychographic microscopy method (FPM) based on an optimized pattern of light emitting diode (LED) angle illumination is proposed. First, a theoretical expandable spectrum range is obtained in the Fourier space based on the relationship among the LED, the aperture, and the sample. Second, image quality assessment methods are utilized to extract differential expressions to describe how an arbitrary LED affects the reconstruction effect. Third, the optimized angle illumination strategy is implemented based on the analysis of the differential expression. Then, a rhombus-based sampling approach is designed to accelerate the FPM process. Finally, the subjective and objective assessments are used to measure the validity of both simulation and actual experiments. Results indicate that our optimized method can effectively improve the efficiency by approximately 3.85 times compared with that of the traditional method.
In the image type ballastless track subgrade settlement monitoring system, vibration and other factors are affected during the operation of the train. The relative deflection of the target surface and camera affects the accuracy of the spot center positioning results. Therefore, a monitoring target attitude measurement system is designed. The deflection angle is obtained by solving the target pose to achieve correction of the spot center positioning results. First of all, combine monocular vision with monitoring targets, establishing a perspective projection model of the camera according to a known geometric constraint relationship between the two-dimensional feature points of the target surface. Then, based on the P5P question, using the HOMO algorithm to solve the linear pose of the target surface linearly. On this basis, the pose optimization solution is obtained by the nonlinear Levenberg-Marqurdt algorithm. The system can perform real-time feature point image processing and pose calculation. An experimental platform for the target surface attitude measurement system in the surface settlement monitoring of ballastless track is constructed based on a high-precision three-dimensional precision rotary table, and mount the target surface vertically on the three-dimensional precision instrument. The data of the target pose measurement is obtained by controlling the rotation angle of the three-dimensional precision instrument. Experimental results show that when the X, Y, and Z axis are respectively rotated at [-5°, 5°],the root mean square error of the three directions of the pose measurement system is 0.048°, 0.052°, 0.056°, respectively. The entire measurement process time is 0.9 s. The time and accuracy of the measurement system meet the measurement requirements of the image-based ballastless roadbed surface settlement monitoring system.
In order to understanding the registration efficiency and registration accuracy of different point cloud registration methods, six different point cloud registration methods (3DSC, PFH, FPFH, NDT, ICP, 4PCS) are selected to perform three-dimentional point cloud data in the coarse registration experiment. The time of point cloud registration and the rotation angle error and translation distance error of point cloud registration on the x, y, and z axis are recorded during the experiment, the registration efficiency and registration accuracy of different point cloud registration methods in the coarse registration experiment are compared by analyzing the data recorded by the experiment. The experimental results show that 3DSC, PFH, and FPFH perform well in the coarse registration experiment, 4PCS has good registration effect but longer time consumption, ICP is not suitable for coarse registration, and NDT performs general in coarse registration experiments. The conclusion of this experiment can provide an effective reference for the selection of point cloud registration methods in different situations.
To address the issue that existing person re-identification (Re-ID) algorithms have low robustness and discriminative capability when extracting pedestrian features with information loss, a novel Re-ID algorithm based on residual neural network is proposed for extracting multi-layer features of pedestrian images. During training phase, the residual network is used to extract the phase features after the four convolutional residual modules, to compensate for the information loss. And the triple loss function is used to supervise training of each feature vector. During the similarity measurement phase, the feature similarity is calculated according to the four feature vectors, the similarity of each stage is calculated by the summation of mapping function, and then the result of the summation is used to perform similarity matching. During the experiment, we validate the proposed algorithm on the Market-1501 and DukeMTMC-ReID datasets. The accuracy (Rank-1) of our algorithm reaches 91.7% and 84.9% and mean average precision (mAP) reaches 86.8% and 80.7%, respectively. Experimental results show that the multi-layer features extracted by our algorithm have considerable robustness and discriminative capability, which improves the accuracy of Re-ID.
The parallax pattern obtained from the ELAS (efficient large-scale stereo matching) algorithm contains obvious fringes and void regions. To address this problem, a stereo matching algorithm that combines matching window characteristics with differentials is proposed in this paper. By enhancing the description of the feature information of points, the similarity measure of the points to be matched is provided with a higher degree of discrimination. First, according to the classical adaptive algorithm of color images, a window descriptor adapted to a gray image was proposed spatially. Next, according to the characteristics of an image signal, a less smooth differential operator was selected at the pixel level. Then the proposed matching window was combined with a differential operator to obtain a description ability of feature information stronger than either of the two. Finally, objective evaluation of standard benchmarks and subjective evaluation of self-collected images show that the proposed algorithm is more robust and has higher matching accuracy, and it obviously improves phenomena related to stripes and void regions in the disparity map.
Traditional length-measurement methods cannot detect pitch. Accordingly, in this work, an optical cable pitch detection method based on machine vision is proposed. This method uses a laser velocimeter for detecting the speed of a production line and generates corresponding pulses to trigger the acquisition information by an industrial camera. A detection system was built by combining low angle with backlight illumination. Furthermore, a preprocessing operation was used to solve the instability of overlapping geometric properties of gray levels. To improve the positioning accuracy, an automatic template construction method is proposed to effectively construct matching templates. A template partition precise-positioning method was used to solve the problem of direct matching misjudgment; then the commutation point was matched and identified and the pitch length was detected. Theoretical analysis and experimental verification reveal that the error between the measured and standard pitch results is within 0.02-0.10 mm, which meets engineering requirements, and the system runs steadily and reliably. The proposed method provides a new way to detect optical cable pitch.
In order to further restrain the non-uniform noise of remote sensing images, we analyze the the causes and noise models of stripe noise in the spatial remote sensing hyperspectral image, and then propose a moment matching algorithm based on the window threshold decision. The window threshold can be estimated based on the flat region and the obviously striped region. Further, moment matching can be achieved with respect to the images containing stripe noise based on the referent mean, standard deviation, and stripe threshold determination. The experimental results denote that compared with the traditional methods, the peak signal-to-noise ratio increases by at least 6.2163 dB, the mean-square error decreases by at least 5.9630, and the structural similarity increases by at least 0.254. When compared with the traditional methods, an improved image variation inverse coefficient can be obtained using the proposed method; further, the lateral gradient and standard deviation of the image decrease, the image stripe noise is effectively removed, and the original image details are preserved.
Lensless digital holographic imaging could support high resolution, large field of view and three-dimensional (3D) imaging, but improving the resolution and quality of the reconstruction is still challenging. In this review paper, the compressive holographic models based on diffraction propagation method are introduced. Compressive sensing are developed based on total variation regularization and two-step iterative shrinkage/thresholding algorithm. The physical mechanism of removing two-order noise and twin image is discussed. A filter layer is designed to improve the signal to noise ratio of 3D reconstruction. A block-wise algorithm based on effective anti-aliasing region is proposed, which can improve computational efficiency of compressive holography. A single-shot compressive holographic model based on two-angle illumination beam is proposed. It effectively improves the axial resolution of 3D imaging. High-resolution 3D reconstruction of multilayer masks and particle flow field are demonstrated by using this algorithm.
Hyperspectral imaging method can obtain two-dimensional images and spectral information of in vivo tissues, which has the advantages of high spatial and spectral resolution, large imaging range, non-invasive nature, and fast speed, providing abundant information for in vivo tissue diagnosis. In recent years, researchers have made great progress in imaging methods, instruments, and applications. In this study, the main advances of hyperspectral imaging methods and applications are reviewed, and the spectral imaging methods, system composition, and characteristics are discussed. This study introduces the research progress in in vivo tissue imaging methods and application in terms of spectral reconstruction, tissue optical parameter measurement, and image processing based on deep learning. Simultaneously, the application progress of hyperspectral imaging in clinical medicine, such as skin trauma and healing process detection, diagnosis of diabetic foot and retinal diseases, intraoperative detection, and microcirculation function evaluation, is also summarized.
Based on the analysis of the relationship between the photon intensity received by the detector under the common energy segment corresponding to different energy spectra, a multi-spectral computed tomography (CT) imaging method using subtraction fusion is proposed herein. From the analysis of the correlation across the X-ray spectrum using different X-ray source parameters, we establish a subtraction fusion model involving various energy polychromatic projection sequences and obtain multiple sequences of the phantom by varying energy. Combined with the subtraction fusion model, the projection is obtained at different energies, the projection information of the common energy segments is removed using subtraction fusion, and the projection information of the approximate narrow spectrum is derived. Finally, the expectation-maximization/total-variation algorithm is used to reconstruct the image, reduce the noise interference, and improve the reconstruction quality. Theoretical analysis and experiments show that the proposed method can obtain approximate narrow-spectrum projection through multi-spectral projection subtraction fusion, which can effectively suppress beam hardening artifacts and improve CT imaging quality.