










Please enter the answer below before you can view the full text.
8+8=

Common fuzzy clustering algorithms can easily cause segmentation failure when an image exhibits unequal cluster sizes. Therefore, a fuzzy C-means clustering algorithm that is insensitive to cluster size is proposed. Firstly, the size of each cluster is integrated into the objective function of the fuzzy C-means algorithm with neighborhood information (FCM_S), which makes the cluster size play a role in the objective function. This improvement can balance the relative contribution from larger and smaller clusters to the objective function and weaken the sensitivity of the algorithm to unequal cluster sizes. Then, a new membership function and clustering center are deduced. Secondly, we design a new expression called “compactness” to represent the pixel distribution of each cluster, which is then introduced into the iterative clustering process. Finally, nondestructive testing images exhibiting unequal cluster sizes are used to verify the availability of the proposed algorithm. The segmentation results not only show improved visual segmentation effects but also show improved performances compared with those of other fuzzy clustering algorithms, as measured by two indices, i.e., segmentation accuracy and adjusted Rand index, thus demonstrating the anti-noise and size-insensitive capabilities of the proposed algorithm.
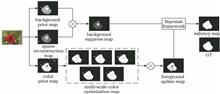
To address the poor background suppression and low foreground resolution in existing saliency detection methods, we propose a saliency detection algorithm based on background suppressing and foreground updating. First, the manifold ranking (MR) algorithm is used to calculate the background prior map, and the super-pixel segmentation algorithm for extracting edge super-pixels is used to construct a background template and calculate a sparse reconstruction map. Next, we obtain the high-quality suppressed background map through point multiplication. Subsequently, we use a Gaussian mixture model to calculate the color prior map, a CA (Cellular Automata) model to calculate the multiscale color optimization map, and point multiplication to obtain the high-precision updated foreground map. Finally, under the Bayesian framework, the suppressed background map and updated foreground map are fused to obtain the final saliency map that meets the requirements of the human eye. Experimental results on two public datasets show that the proposed algorithm can obtain a saliency map with good background suppression and high foreground resolution. Moreover, it provides improved precision, F-measure, mean absolute error, and other indicators relative to eight other algorithms used for comparison.
In the field of optical coherence tomography, reducing the speckle noise while protecting the textural features of image edge is difficult mainly because of the speckle residue and textural blur of edge in the speckle denoising process. To solve this problem, this study proposes a shearlet-transform-based improved total variation speckle denoising method. By combining the shearlet transform with the traditional total variation model, as well as a targeted denoising strategy applied on different image regions, the proposed method reduces the speckle noise without disturbing the texture in the image, and further improves the speckle-noise suppression in the original optical coherence tomography image. The proposed method is tested on many retinal optical coherence tomography images under different physiological and pathological conditions. Results show that the regional targeted strategy in the proposed method improves the ability of speckle-noise suppression, while the shearlet transform improves the ability of the edge texture protection, resulting in simultaneous speckle reduction and texture protection. The effectiveness of the proposed method is also confirmed in comparison with other common speckle denoising methods.
This paper improves a global and local feature-based method to overcome problems of the histogram of oriented gradients (HOG), such as the features only characterizing the global gradient feature of motion, lacking local detail information, and having poor performance on occlusion, in the human behavior recognition. The proposed algorithm first uses the background difference method to obtain the human motion region; then, a steerable filter can effectively describe the motion edge features to improve HOG features,therefore enhancing edge details. At the same time, k-means clustering is conducted on speeded up robust features (SURF) to obtain the bag-of-words model. Finally, the merged behavior features are input into a support vector machine (SVM) for classification and recognition. Simulation experiments perform on the KTH, UCF Sports, and SBU Kinect Interaction datasets, showing improved algorithm recognition accuracies of 96.7%, 94.2%, and 90.8%, respectively.
Aiming at image registration scenes with inconspicuous feature points, we proposed a registration algorithm based on spectral and spatial feature matching to ensure that the overlapping area of two adjacent images to be registered exceeds 80%. Based on the invariance of the rotation center of the Fourier spectrogram, the rotation angle of the two images in the spatial domain around any point was converted into the rotation angle around the center of the spectrogram in the frequency domain. Using the transformation relationship between the polar and Cartesian coordinate systems, the degree of rotation around the center of the spectrogram was converted into a one-dimensional translation, and the rotation angle was obtained using the SAD (Sum of Absolute Difference) algorithm. The SAD algorithm was then applied to determining the translation matrix. The proposed registration algorithm proposed would be suitable for image registration scenes with both inconspicuous and obvious feature points. Moreover, it was characterized by a high speed and registration accuracy.
For multi-person pose estimation in images and videos, it is necessary to address the inaccurate positioning of the human-bounding box and improve the detection accuracy of hard keypoints. This paper designs a real-time multi-person pose-estimation model based on a top-down framework. First, depth-separable convolution is added to the target-detection algorithm to improve the running speed of the human detector; then, by combining the feature pyramid network with context-semantic information, the online hard-example mining algorithm is used to solve the problem of low detection accuracy at hard keypoints. Finally, combining the spatial-transformation network and pose-similarity calculation, the redundant pose is eliminated and the accuracy of the bounding-box positioning is improved. In this paper, the average detection precision of the proposed model on the 2017MS COCO Test-dev dataset is 14.84% higher than that of the Mask R-CNN model, and 2.43% higher than that of the RMPE model. The frame frequency is 22 frame·s -1.
The ViBe algorithm has been widely used for moving target detection owing to advantages such as ease of realization and high operational efficiency. However, the algorithm has weaknesses concerning ghosts, shadows, and incomplete moving targets. Therefore, an improved ViBe algorithm combined with the average background method is proposed, which aims to address the ghost phenomenon existing in the foreground detection of the ViBe algorithm, and the difficulty regarding its long-term elimination. First, the improved average background method was used to obtain and initialize the true background. Then, the ViBe algorithm was used for both foreground detection and background updating, to eliminate the ghosts in subsequent frame detection. Finally, morphological knowledge was used to make the target more complete by eliminating holes and interference targets. The experimental results indicate that this algorithm can more effectively eliminate ghosts and improve the detection accuracy compared with the traditional ViBe algorithm.
Herein, we propose a target-tacking algorithm based on adaptive updating of multilayer convolutional features to address the insufficiency of traditional manual feature expression and the error accumulation of filter models. First, the algorithm uses a layered convolutional neural network to extract the image features, and fuses multi-convolution features through linear weighting to predict the target position. Then, the multiscale target convolution features are used to determine the target optimal scale. Finally, the average peak correlation energy is used to evaluate the confidence of the target response. We evaluate the motion condition of the target according to the frame differential mean and displacement of the two adjacent frames of the target image, and adjust the learning rate of the filter model according to the predicted position credibility and the appearance of the target image. The performance of the algorithm is verified using the OTB-2013 public test set and compared with the existing mainstream moving target tracking algorithm based on correlation filtering. Experimental results show that the proposed algorithm provides higher accuracy and success rate, and is more robust in complex cases.
A multitask recognition model based on convolutional neural network is proposed to avoid single task recognition ignoring supervision information of related tasks. The proposed model introduces an attention mechanism to perform feature recalibration of the task shared layer and combines the multiscale structure for feature fusion. Finally, multi-task recognition is performed on the task-specific layers. Center loss and mean square error loss functions are employed together with the traditional cross entropy loss function to solve the generalization degradation problem caused by uncompact class distribution in the shared feature space. Experimental results on 6 human activities and 15 identities show that the model can achieve the maximum recognition accuracies of 100% and 99.93% on each task, respectively, and the multitask accuracy is up to 99.93%. The results are better than those obtained by the single task models. This shows that the model can simultaneously perform human activity and identity recognition more effectively.
The existing license plate recognition system is unable to locate accurately in the cases of complex background and license plate tilting. To solve this issue, this study proposes an end-to-end license plate location algorithm based on a convolutional neural network to accurately calculate the license plate coordinates. The information is extracted based on the input vehicle picture using Faster R-CNN to obtain the feature mapping of the candidate area. Further, the license plate coordinates are precisely obtained using feature mapping. The experimental results denote that the recognition accuracy of the proposed algorithm is 99% with respect to the functional assessment database of the OpenITS database and 85% with respect to the performance evaluation database.
In this study, we propose a real-time semantic segmentation algorithm based on the feature fusion technology to satisfy the requirements of autopilot, human-computer interaction, and other tasks with respect to accuracy and real-time capability . Here, we use a convolutional neural network to automatically learn deep features of the image. We design a shallow and wide spatial information network to output low-level spatial information for ensuring the integrity of the original spatial information and generating high-resolution features. Furthermore, we design a context information network to output deep-level high-level context information. Then, we introduce an attention optimization mechanism to replace upsampling for optimizing the network output. Finally, we fuse the two output feature maps on multiple scales and perform upsampling to obtain a segmented image with a size equal to the original input size. Subsequently, we perform a simulation using two-way network parallel computing to improve the real-time performance of the proposed algorithm. The network framework achieves 68.43% mean intersection over union (MIOU) on the Cityscapes dataset. In case of an image input of 640 × 480, the speed obtained using an NVIDIA 1050T graphics card is 14.14 frame/s. Furthermore, the accuracy considerably exceeds that of the existing real-time segmentation algorithm, satisfying the real-time requirements of the human-computer interaction tasks.
This study proposes an unsupervised monocular depth estimation model for autonomous drone flight to overcome the limitations of high cost and large size in binocular depth estimation and a large number of depth maps required for training in supervised learning. The model first processes the input image into a pyramid shape to reduce the impact of different target sizes on the depth estimation. In addition, the neural network of the automatic encoder used for image reconstruction is designed based on ResNet-50, which is capable of feature extraction. The corresponding right or left pyramid images are subsequently reconstructed by the bilinear sampling method based on the left or right input images, and corresponding pyramid disparity map is generated. Finally, the training loss could be assessed as the combination of the disparity smoothness loss, image reconstruction loss based on the structural similarity, and the loss of disparity consistency. Experimental results indicate that the model is more accurate and timely on KITTI and Make3D compared with other monocular depth estimation methods. When trained on KITTI, the model essentially meets the accuracy requirements and real-time necessities for autonomous drone flight depth estimation.
A hyperspectral image classification method is proposed based on a Gaussian linear process and multi-neighborhood optimization to overcome the poor classification accuracy of a classification algorithm based on spectral information. First, Gaussian filtering and linear discriminant dimension reduction are performed on the original sample data; then, the data are classified using a multivariate logistic regression model to obtain their initial prediction labels. Finally, the spatial position information of the local pixels is combined to determine the confidence of these prediction labels, which are corrected by the 3-layer tandem neighborhood optimization to obtain the final classification results. The proposed algorithm is compared with other algorithms on the Indian Pines, Pavia University, and Salinas hyperspectral remote sensing databases, demonstrating the enhanced performance in terms of classification accuracy and time efficiency of the proposed method.
To resolve the fuzzy problem caused by the lack of high-frequency information in the super-resolution reconstruction of medical images, this study proposes a medical-image super-resolution reconstruction method based on a residual channel attention network. The proposed method removes the batch normalization layer from the basic unit of the residual network (ResNet) to stabilize its training. Furthermore, it removes the scaling layer and adds a channel-attention block that focuses the ResNet on channels with abundant high-frequency details. The feature maps are subsampled using a sub-pixel convolution layer,obtaining the final high-resolution images. Experimental results show that the proposed method significantly improves objective evaluation indexes such as the peak signal-to-noise ratio and structural similarity index compared with mainstream image super-resolution methods. The obtained medical images are sufficiently detailed with high visual quality.
To address the problem of low recognition rate of QR (Quick Response) codes under changes in illumination, pollution, and damage, a QR-code recognition algorithm based on multiblock local binary patterns (MB-LBP) combined with an improved grey wolf optimization (GWO) algorithm for optimizing a support vector machine (SVM) is proposed. Firstly, the lifting wavelet transform is used to separate the high- and low-frequency components of the image, while the second-level low-frequency and horizontal high-frequency components are divided into nonoverlapping sub-blocks. The MB-LBP features of each sub-block are separately extracted and fused. Then, principal component analysis is applied to reducing the dimension of the sample set. Finally, the classification model of the QR-code data is established using the SVM algorithm. To further improve the classification accuracy, the nonlinear convergence factor based on a logarithmic function is introduced to improve the optimization performance based on the standard GWO; the improved GWO is used to optimize the SVM model. The recognition performance is tested according to different combination modes of high and low frequencies and the SVM optimization algorithm. The experimental results show that the proposed algorithm significantly improves the recognition rate and classification accuracy, and it is highly robust.
This study proposes a computational ghost imaging method based on Tikhonov regularization to solve the problem of poor ghost image quality caused by data perturbation and few sampling times during ghost imaging sampling. The proposed method uses a constraint term that characterizes the noise intensity to transform the computational ghost imaging problem into a mathematical problem for minimizing the signal error and noise intensity. Subsequently, the ghost image of the unknown object is reconstructed by selecting appropriate regular parameters using the generalized cross-validation method. The experimental results denote that the proposed algorithm is superior to traditional, differential, and pseudo-reverse ghost imaging methods when interference is present and that it exhibits considerable stability. Furthermore, in the absence of interference, the proposed method is superior to traditional and differential ghost imaging methods and exhibits similar performance when compared with that exhibited by pseudo-reverse ghost imaging at the same time.
In lightweight networks, the speed of semantic segmentation is high but the accuracy is low. On the basis of lightweight networks, a real-time semantic segmentation method based on dilated convolution smoothing and lightweight up-sampling is proposed. To improve segmentation speed, a lightweight network, ResNeXt-18, with structured knowledge distillation is used as feature extraction network. To improve the segmentation accuracy, a dilated convolution smoothing module and a lightweight up-sampling module are designed. To verify the effectiveness of the proposed method, the evaluations are carried out using the Cityscapes and CamVid datasets, obtaining the speed of 40.2 frame/s and the segmentation accuracy of 76.8%, with a parameter count of 1.18×10 7. The experimental results demonstrate that the proposed method can obtain high segmentation accuracy while maintaining its high-speed real-time performance; as such, it has certain practical value.
With traditional ghost imaging methods, the detection of the edge resulting from a poorly recovered image is difficult; therefore, this paper proposes an improved high-pass-filter-based ghost imaging method. Randomly generated grayscale images are subjected to a high-pass filter before being input into a spatial light modulator. The high-frequency components in different directions of the unknown object are recovered by the correlation operation. Subsequently, the edge image is restored by the corresponding reconstruction method according to the filtering method used and edge detection of the unknown object without pre-known object information is realized. The Kirsch filter and nonsubsampled contourlet transform (NSCT) are considered as examples to show the performance of the algorithm. Compared with traditional edge-detection ghost imaging methods, the edge image obtained using the proposed algorithm has subjectively better smoothness and higher definition. The edge signal-to-noise ratio and mean square error are optimized.
The original Poisson surface reconstruction algorithm can easily produce an unclosed surface at the edge, resulting in the surface of the final object being rough with holes. This paper proposes an improved three-dimensional algorithm for reconstructing surfaces from point clouds. First, the method employs a statistical filter to simplify the denoising of the considered point clouds and eliminates the jagged phenomenon of the reconstructed surface. Then, a topological structure of point clouds is established, and the point-cloud normal vector is normally redirected to reduce the ambiguity of the normal direction. Finally, the point cloud with the disk topological structure is mapped to the plane, the two-dimensional triangulation method is applied to the plane parameterization, the triangle connectivity is provided to the two-dimensional points, and the two-dimensional points are transmitted back to the three-dimensional point cloud to form a mesh surface. The experimental results demonstrate that the method can effectively remove noise points, construct a more regular triangle mesh, and effectively remove the pseudo-enclosed surface. The surface point-cloud reconstruction effect with holes is clearly improved, and the reconstruction time is reduced.
Existing wavefront reconstruction methods generally have low resolution when we examine wavefront distortion caused by turbulence in the atmosphere. They are also limited by the structures of sensors and deformable mirrors. In this paper, a method based on wavelet fractal-difference wavefront correction is proposed. A wavefront reconstruction method based on wavelet fractal interpolation is also proposed, and it is applied after performing self-similarity analysis of wavefront distortion caused by atmospheric turbulence. The multi-resolution analysis of the wavefront phase spectrum is performed by the fast wavelet decomposition method and soft threshold denoising is performed in this process. Subsequently, the fractal interpolation method is used to increase the resolution of the estimated wavefront phase. Finally, the recovery of the wavefront phase is achieved by applying the fast wavelet reconstruction method. Experimental results show that the fast wavelet reconstruction is capable of recovering the wavefront phase. Compared with the minimum variance estimation (MVE) method, the proposed method improves the light intensity value and residual wavefront root-mean-square value, thereby effectively reducing noise interference. A higher imaging quality is obtained and the corrected spot shape is reliable and stable.
Traditional inspection and focusing methods have high complexity and poor stability. This paper presents a self-collimation inspection and focusing method based on image processing. The combination of the self-collimation focusing method and image processing method can improve system applicability and inspection and focusing accuracy. An increase in system defocusing distance leads to a decrease in imaging resolution. Radial targets continuously changing in three-dimensional space are designed to avoid the problem of a small change in contrast after defocusing. In the simulation, the evaluation function operator is selected to calculate the characteristic value curves of defocusing sequence graphs of different targets. The results show that the sensitivity, unbiasedness, and unimodality of the characteristic value curves of radial targets are better than those of Lena graphs and raster targets. The self-collimation inspection and focusing method based on image processing improves the precision of the original self-collimation inspection and focusing method by approximately 19.6%, and the required amount of the tolerant defocus is satisfied.
Latent fingerprint is an important evidence in criminal investigation. In order to study the nondestructive detection of latent fingerprint based on ultraviolet (UV) polarization imaging technology, the back-illuminated sCMOS detector is used to study the UV polarization imaging scheme. The basic working principle of UV polarization imaging is analyzed, and the time-division UV polarization imaging detection system consisting of double-glued lens optical system, asynchronous rotating mechanical structure and automatic tuning electronics system is designed. The experiment verifies the function and performance of the system. The results show that the system can realize the non-destructive detection of weak feature targets such as latent fingerprints. Compared with the traditional intensity information detection method, the polarization information obtained by the method improves the contrast between the target and the background, highlights the details of the target, and provides experimental basis for the application of polarization imaging detection in latent fingerprint nondestructive detection.
Lidar motion compensation is a crucial step in detection of dynamic background targets in smart cars. Herein,a motion compensation algorithm is proposed based on lidar. Firstly, the pose change matrix of the vehicle body between the previous and the current scan periods is solved using quaternion method. Secondly, according to the characteristics of the static scene and the data packets generated by the historical lidar data frame, the Gaussian mixture model is used to model the background over time coordinate system. The Gaussian mixture model is prone to failure in dynamic scenes, therefore, in this study, the dynamic background is first converted into a static background by motion compensation. Then, the Gaussian mixture model is used to deal with all historical frames in the time list, and feature points of the original point of the moving target are found at T moment. The alignment of feature points with the points in the current frame is used to further refine the new position of matching points in the current frame. Experimental results show that the proposed method can successfully estimate and compensate for the background motion and is suitable for real-time detection of moving targets in 3D environments.
We propose a mine ground point cloud extraction algorithm that combines statistical filtering and density clustering to effectively extract ground point clouds and improve the operational efficiency. First, we improve the statistical features based on an efficient KD-tree index algorithm and statistical features, and analyze the spatial distribution characteristics of non-ground points. We then cluster the density space and extract the ground points based on the distribution characteristics of two-dimensional characteristic density space. Lastly, the effective ground points are obtained by intersecting the extracted results of each density space, and the algorithm complexity is observed to be o(n2). Experiments demonstrate that the proposed algorithm has high extraction accuracy and efficiency. The test indicates that when the neighborhood point value is 36, the effect is the best, with a total error of 0.00770 and a mean square error of 0.019633. Meanwhile, the extraction and calculation time of 510519 points are less than 27 s, which is approximately 1/7 of the time required by traditional methods. In addition, we select a large-area mine point cloud to verify the universality of the algorithm.
Existing high precision object detection algorithms mostly rely on super deep backbone networks, such as ResNet and Inception, making it difficult to meet real-time detection requirements. On the contrary, some lightweight backbone networks, such as VGG-16 and MobileNet, fulfill real-time processing but their accuracies are often criticized, especially when the targets are small. In this study, we explore an alternative to build a fast and accurate detector by strengthening the feature extraction ability of lightweight backbone networks, using a new receptive field block based on a single shot multi-box detector (SSD). Simultaneously, to make full use of the semantic information extracted from deep networks, a feature fusion module is designed and added, thereby improving the overall accuracy and enhancing the detection effect of the model for small targets, while still achieving real-time detection. To further verify the validity of introducing new modules, we have tested our model on the PASCAL VOC2007 data set and achieved an accuracy of 80.5% which is 3.3 percentage points higher than that of the original SSD model. In addition, the detection speed of the proposed model reaches 75 frame/s, and its overall performance is better than that of most of the current models.
A text feature-based recognition registration method is proposed to address the problems that the accuracy of the augmented reality recognition registration is prone to be affected by textures and that there is lack of text-based recognition targets. In template imaging processing, two sampling methods,i.e., downsampling and 2 power-based sampling,are combined to construct a multi-scale pyramid, achieving scale invariance. The text feature points are extracted based on an improved algorithm that uses fast retina keypoint (FREAK). Finally, the augmented reality system based on text features is realized. The experimental results show that the proposed algorithm can extract text feature points accurately and reduce the effect of the texture on accuracy, and it is applicable to the recognition registration for text images. Further, the augmented reality system based on the improved method can realize recognition registration in the situation that the target is partially obscured under different scales.
Herein, an improved phase correction method is proposed to address insufficient correction when a monotone method is applied to phase noise in the shadow area of binocular vision systems. The absolute phase information on the workpiece surface is solved using a four-step phase shift and multi-frequency heterodyne, and the phase noise is corrected using a monotone nonreduction method. We then analyze the characteristics of phase noise with insufficient correction of multiple sets of different experimental objects. Discrete phase noise is corrected based on the frequency at which non-zero phase occurs over a fixed interval calculated by the phase frequency matrix, and the continuous phase is corrected using the difference between the actual and predicted phases of the adjacent discontinuous points. The integrity of workpiece information is ensured by calculating and judging the slope between the discontinuous points and the fitting slope of the non-zero phase on both sides, and using the linear method to compensate the partial phase that is set to zero because of the random noise. Experiments are also given to demonstrate that the proposed method effectively corrects phase noise in the shadow area and can be applied to different experimental objects. The cylindrical wooden workpiece has an average measurement error of 0.0859 mm, which meets the accuracy requirements of pose estimation for target grabbing.
Solving the camera external parameters with single image space resection algorithm is a fundamental problem in the fields of photogrammetry and machine vision. Based on the previous work, a new robust algorithm is presented in this paper. A temporary coordinate system is created by three control points. Due to part of the coordinate component of these control points in the temporary coordinate system being zero, the resection solving is transformed to the solution of ternary quadratic equations, the initialize solutions for the nonlinear equations can be acquired by the image coordinates of the three points, which makes the solving process more reliable. In the experiment, 120 images of the control field are taken by the commercial industrial photogrammetry system and the external parameters are calculated with the proposed resection algorithm and the pyramid algorithm. Experimental results illustrate that the parameters calculated by the proposed resection algorithm are correct, and the convergence is good, showing that the proposed algorithm is suitable for solving external parameters of cameras with arbitrary rotation angles.
A single expression based overall fitting method for scattered points of blade contours is proposed to address the large measurement errors of the existing tool measurement instruments when measuring severely worn tools based on machine vision and piecewise fitting. An algorithm of k-cosine curvature is used to extract the corners of the blade contour and the least square method is used for piecewise fitting. Based on this, a single expression of the blade contour used for object function fitting is determined and the nonlinear overall fitting is performed using Levenberg-Marquardt iteration. Finally, experimental results indicate that the overall fitting method can ensure the continuity of the fitting curve and improve the accuracy by more than 20% when measuring severely worn tools, drastically improving the measurement accuracy and robustness of the algorithm.
Digital image correlation (DIC) method has been widely used in displacement and strain measurements because of its simple optical path and good adaptability. It is particularly important for improving the speed of DIC matching in large displacement measurements. This paper proposes an improved climbing algorithm that corrects the shortcomings that result in the traditional climbing algorithm easily approaching the local extremum. Furthermore, the proposed algorithm improves the search speed, making it suitable for large displacement measurements. It is tested and compared with simulated-speckle patterns. The results show that the overall search speed and precision of this method are better than those of traditional climbing algorithms. When the step-size change coefficient is appropriate, the algorithm can quickly obtain the accurate result.
In infrared image detection and segmentation tasks, the color information is lost, the features are fuzzy with noise, the target number is large, and the traditional extraction method is slow. Therefore, we propose an optimized YOLO detection and segmentation network model for far-infrared images. The two proposed optimization points are as follows. We use the K-means++ clustering algorithm to determine the multi-scale prediction anchor size after the analysis of two far-infrared databases. We also perform pixel-level instance segmentation of detection targets using localized adaptive threshold segmentation. The experimental results show that the proposed algorithm performs pedestrian detection at detection speeds of 29 frame/s and 28 frame/s on the FLIR dataset and the dataset used in this paper, respectively, ensuring the requirement of real-time output. The pedestrian detection accuracies in these datasets reach 75.3% and 77.6%. Moreover, the average intersection over the union of the segmentation results is 70%--90%. In summary, the algorithm performs well with respect to robustness and universality. The algorithm provides a valuable reference method for pedestrian detection and segmentation in far-infrared fields.
The purpose of this study is to develop a method for automatically identifying weeds in a rapeseed field. We propose a weed-recognition method based on a Faster R-CNN (region-convolution neural network) deep network and use the deep network model of the COCO dataset for migration training. First, by obtaining images of rapeseed and weed samples under natural environment, the Faster R-CNN deep network model is utilized to share the convolution characteristics and the results of three feature extraction networks: VGG-16, ResNet-50, and ResNet-101, are compared. At the same time, the method is also compared with a single shot multibox detector (SSD) deep network model, which includes the three identical feature extraction networks. The results show that the Faster R-CNN deep network model based on VGG-16 has obvious advantages in rapeseed and weed target recognition. The accuracy of target recognition and recall rate of the rapeseed and weeds are 83.90% and 78.86%, respectively, whereas the F1 value is 81.30%. The proposed deep learning method can effectively and rapidly identity rapeseed and weed targets, providing a reference for further research into multi-type weed target recognition.
We propose a coding and decoding algorithm for stripe boundaries using binary space based on the binocular structured light system. First, the binary space is defined. Second, the projected patterns are layered in the order of projection; subsequently, the initial binary space for the first layer of the stripe image is constructed. Third, based on the sequence of black and white stripes in the initial binary space, the boundary lines of the second layer of the stripe image are extracted in two subspaces. By repeating the aforementioned operation, the next sets of boundaries of each layer are obtained from the binary subspace constructed using the previous layer. During this process, the boundaries are decoded according to the extraction order by considering the consistency of the state of the binary space in the left and right views. Moreover, broken boundaries are connected according to the direction of the binary space. Finally, by linearly fitting the forward and inverse stripe boundaries, we observe the sub-pixel edge points from the intersection of two lines. The experimental results indicate that the entire boundary line can be accurately obtained using the proposed algorithm. Furthermore, the decoding accuracy is up to 100%, and the reconstruction result for the plane has an error of 0.0993 mm. Furthermore, the proposed algorithm has a strong anti-interference for the stripe of a complex scene.
This study aims at resolving the tracking failure caused by the coexistence of similar targets and the significant change in the appearance of a target based on the full convolution siamese (SiamFC) network algorithm. An online adaptive siamese network tracking algorithm (AAM-Siam) based on attention mechanism is proposed to enhance the discriminative ability of the network model and achieve the online learning target appearance change and suppress background. Firstly, the results obtained by tracking the previous frame are added into the template branch and the search branch respectively to compensate for the shortcomings of the network by responding to the changes in the appearance of the target. Secondly, the spatial attention module and the channel attention module are employed into the siamese network to achieve the feature fusion among various frames, learn the target deformation online and suppress background, as well as enhancing the model''s ability to express features. Finally, detailed experiments are conducted on the online tracking benchmark (OTB) and visual object tracking 2016 (VOT2016) benchmark. The experimental results indicate that the accuracy and average success rate of the proposed algorithm on the OTB50 dataset are 4.3 and 3.6 percentage points higher than those obtained using the basic SiamFC network algorithm, respectively.
The contours of buildings extracted using the image classification method are commonly irregular and involve serration issues that are primarily caused by incorrect recognition. Therefore, this paper proposes a building contour optimization method that combines Hausdorff distance and a suitable circumscribed rectangle that conforms to the contour and axial direction of buildings. Firstly, initial results of buildings are extracted using the shifted shadow segmentation and classification principle. For each building, a corresponding fitting polygon is acquired by applying a fitting principle to its building edge. Subsequently, the building axis is assessed using the minimum circumscribed rectangle of the building polygon-fitting result. Based on the axis, a suitable circumscribed rectangle is selected. Furthermore, the building contour and its suitable circumscribed rectangle are respectively divided into equal segments. Meanwhile, the Hausdorff distance between two kinds of segmentations is calculated. If the distance satisfies the substitution rules, building contour segments are replaced with circumscribed rectangular edge segmentation to optimize building regularization. Thus, the proposed method helps in improving the accuracy of building boundary and in promoting building extraction precision. It is tested on several remote sensing images. Compared with other building extraction methods, the results show that the overall accuracy of the proposed method is better than that of the other two reference methods. Moreover, the accuracy and regularization of building contours and the overall precision of building extraction results have been effectively improved. As a result, building shape is more accurately reflected.
Computational imaging technology (CIT) refers to a novel imaging method that is different from the “what you see is what you get” information acquisition and processing methods of traditional optical imaging. With the development of new optoelectronic devices and the improvement of hardware computing capabilities, it has shown a booming trend in the field of optoelectronic imaging. By using CIT to obtain and calculate the information of light field, the information utilization and interpretation capability can be superior to traditional imaging, which can realize the requirements of “higher (resolution), farther (detection range), and larger (optical field of view)” of photoelectric imaging. We start from the description of information acquisition and loss process of the imaging chain, and further analyze the acquisition and interpretation of multi-physical information of light field through several typical computational imaging methods, such as scattering imaging, polarization imaging, and bionic imaging, and the principles of them are discussed in detail. According to the trend of imaging technology, we put forward prospectively the design idea of computational optical system based super large-aperture telescopes. Since CIT has significant advantages in improving imaging resolution, increasing detection distance, expanding imaging field of view, and reducing the size and power consumption of optical systems, it is expected to realize the imaging through the fog with longer distance and through biological tissues at a larger depth.