









Please enter the answer below before you can view the full text.
9-5=

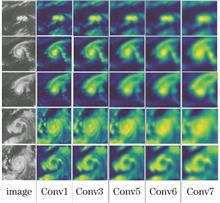
In order to enhance the perception for the multi-scale image variation and improve the scale invariance of convolutional neural networks,this study proposes a typhoon classification model based on multi-scale convolutional feature fusion. A multi-scale perception layer is added to convolutional neural networks; then, convolutional features are multi-scale perceived and cascaded. A multi-scale regularization term is then incorporated into the loss function. The residual error of hidden layer weight is minimized and the feature extraction ability is optimized with backpropagation. Finally, multi-scale high-level semantic features are normalized to the probability value of each category using Softmax. The maximum probability value is used as the final classification result of the image. Infrared satellite cloud images are used as the dataset in our experiments to validate the multi-scale perception ability of the model. Experimental results show that the model can effectively perceive and extract the local features of the typhoon cloud map. The generalization ability of the model is verified using two general datasets, i.e., MNIST and CIFAR-10.
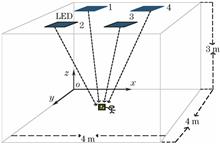
Considering the influences of complex indoor environments on the accuracy of visible light positioning, an indoor positioning method based on the visible light fingerprint is proposed. This method uses a positioning terminal to receive the signal strength information generated by different LEDs in a room to construct features, and the physical coordinates are used as labels. Then, a support vector machine regression (SVR) algorithm learning model is adopted to determine the rough position range of a moving target. Simultaneously, to further optimize the positioning performance, a fingerprint positioning algorithm is used to achieve more accurate positioning with the location range as the limiting condition. The proposed positioning method is tested in a spatial region of 4 m×4 m×3 m. The results show that the probability of achieving a positioning error of less than 1 cm is 67.5%. Compared to the SVR positioning algorithm, the proposed method can improve the average positioning error by 93.98%. Compared to the traditional fingerprint-based localization method, the proposed method can achieve more accurate localization with lower complexity. Both the accuracy of the indoor positioning and the utilization rate of the data are effectively improved by the proposed method.
Spectral unmixing can effectively improve the utilization efficiency of hyperspectral images. Nonnegative matrix factorization is frequently used to find linear representations of nonnegative data, which can effectively solve the problem of mixed pixels. A hyperspectral unmixing algorithm is proposed based on the sparsity of abundance and local invariance of an image. A new objective function is constructed by adopting the sparsity regularization term of abundance and the graph regularization term of the Laplacian matrix. Better unmixing results are obtained after several iterations of the endmembers and abundance. The proposed algorithm is validated using both simulation and real data, and the experimental results demonstrate that the proposed algorithm exhibits good performance.
Herein, to improve the automation and accuracy of the airborne LiDAR point cloud data classification algorithm, a classification algorithm for point clouds based on improved progressive triangulated irregular network densification (IPTD) and a double-layer support vector machine (SVM) was proposed; the classification effect of the algorithm on urban point cloud data was tested as follows. The IPTD filter method was used to extract ground points, and ground points were normalized based on ground points. Then, the effectiveness of point cloud features was evaluated to select eigenvectors, and nearest-neighbor SVM (NN-SVM) was used to classify the ground feature points, realizing the multiple classification of the urban point cloud data. Furthermore, the classification algorithm was verified using point cloud data from urban regions, and the classification effect was evaluated by analyzing the classification accuracy. The experimental results show that this algorithm can effectively improve the classification accuracy and classify point cloud data in urban areas.
Focusing on the instability of concealment and display that occurs when embedding a latent image via a phase modulation technique, a scheme was proposed to obtain good anti-counterfeiting quality by adjusting latent image boundary dots. Weber law was used to analyze the dot arrangement characteristics of a latent image area and the corresponding hidden layer. Results indicate that the inner dots of the latent image did not affect the concealment, whereas the boundary dots had a great impact on its overall concealment. The boundary adjustment method was deduced based on the boundary dot location distribution; thus, the displacement, compensation position, and area adjustment coefficient were determined. Results show that the improved method outperformed the conventional phase modulation method under the premise of ensuring ensuring extracting effect, and provide a new optimization scheme for the grating anti-counterfeiting technology.
This study proposes a new network based on generative adversarial networks to achieve an end-to-end image adaptive fusion, thus solving the difficulties in designing multiscale geometric tools and fusion rules in multimodal image fusion. First, the multimodal source image is synchronously input into the generative network, whose structure is created based on a residual-based convolutional neural network proposed herein. The network can generate the fused image through adaptive learning. Second, the fused and label images are sent to the discriminant network. The generator is gradually optimized through the feature representation and classification identification of the discriminator. The final fused image is obtained in the dynamic balance of the generator and discriminator. In comparison with the existing representative fusion methods, the proposed algorithm obtains more cleaner fusion results and has no artifacts, thereby providing a better visual quality.
We introduced an effective preprocessing method based on Sentinel-1 remote-sensing data to obtain a more accurate dataset and proposed a triangulation-based feature-tracking and pattern-matching algorithm. By establishing a triangular network, the advantages of the two algorithms were effectively combined, which not only improved the efficiency but also enhanced the spatial-distribution uniformity of the sea-ice drift vectors. Additionally, this study investigated the applicability of the algorithm for strong-noise areas of like-polarized (HH) and cross-polarized (HV) data. The experimental results show that sea-ice drift vectors obtained using this algorithm exhibit a high coverage and reduce the root mean square error by ~10%, thereby improving the detection accuracy and robustness against noise. Furthermore, the detection accuracy remains as high as 98%, even in the presence of interference by strip noise. These results demonstrate the effectiveness of this method for effectively monitoring sea-ice drift.
Image denoising using weighted nuclear norm minimization (WNNM) is prone to over-smoothing and cannot distinguish intricate and irregular image structures effectively. Image denoising model using relative total variation (RTV) WNNM is proposed. The proposed denoising method, which utilizes the alternate direction multiplier (ADMM) algorithm to solve the corresponding model iteratively, can obtain a clear image. The ADMM algorithm integrates RTV into WNNM and applies the RTV norm constraint to the low-rank representation model of WNNM. Compared to several state-of-the-art denoising methods based on low-rank matrix approximation, the proposed method improves image denoising performance, maintains image edges effectively, and enhances smoothness, particularly for images with high-density noise. Experimental results demonstrate that the proposed method with RTV norm restores image structure effectively and improves denoising performance.
In the three-dimensional (3D) reconstruction system for fringe projection, we need to unwrap the original phase to obtain the real 3D image. A path correlation algorithm is a type of useful phase unwrapping algorithm that can accurately rebuild the shape and texture of the target object. However, the path correlation algorithm is limited by the phase noise. Resultantly, we will not find the right path to unwrap the phase when encountering a singular point in the region with low image quality. Therefore, we propose an algorithm that can retrieve exact phase, ignore noise, and compensate fault. Based on a theoretical study, we can provide the actual image of the object and the wrapped phase image, and reconstruct the actual phase information based on the proposed algorithm. To verify the practicability and superiority of this algorithm, the phase rewrapping algorithm is adopted as the performance metric of the algorithm.
To ensure safe reactor operation, a variety of detection techniques are required to ensure the qualities of fuel pellets. To address high misdetection rate of cracks due to low contrast and complex background in the detection of surface cracks in fuel pellets, a surface crack detection algorithm based on convolutional neural networks (CNN) and the Beamlet algorithm is proposed. First, images are divided into equal-sized patches, which are used as training samples for the crack recognition model (CrackCNN). Then, the crack-containing region in the image is identified and located by the trained CrackCNN. Finally, a crack in identified region is detected by the Beamlet algorithm. The proposed method, which utilizes both CNNs and Beamlet, can improve detection accuracy and effectively reduce the probability of crack misdetection. Experimental results demonstrate that the F-measure of the proposed algorithm is enhanced by 6.4% and 3.4% compared to using only the Beamlet algorithm and using the double threshold and tensor voting algorithm, respectively.
We considered the residual between an ideal high spatial resolution multi-spectral image and a pansharpened image as generalized noise, and thus proposed a deep residual denoising network (DnCNN)-based quality boosting method for the pansharpened image. We used the DnCNN to learn the patterns of detail loss and spectral distortion of the fixed fusion algorithm, and mapped the input pansharpened image to a residual image. Then, we used the residual image to compensate and repair the pansharpened image. In an experiment using the QuickBird dataset, images pansharpened using different methods were enhanced via the proposed method. The experimental results demonstrate that, using the proposed method, the qualities of all pansharpened images are improved and the best boosting is attained when this method is used in conjunction with the support value transform based method. The proposed method outperforms latest methods.
An improved fusion algorithm based on Bayesian formula is proposed for addressing inaccurate detection and unclear edge problems in existing image saliency detection algorithms. First, compactness prior is used for obtaining the primary saliency map. Then, the secondary saliency map is obtained via multi-kernel learning using primary saliency maps as training samples. Finally, a Bayesian formula is used to integrate the primary saliency map with the secondary saliency map at a certain proportion to obtain an accurate saliency map. Experimental results obtained on two public datasets demonstrate that the proposed algorithm can effectively highlight the target object and remove blurred edges. The proposed algorithm is superior to eight existing algorithms from the viewpoint of accuracy, recall rate, and F-measure value. Furthermore, the running speed of the proposed algorithm is faster, and it demonstrates more accurate experimental results.
The curvature driven diffusion (CDD) inpainting algorithm requires a significant number of iterations and long time for repairing images. In addition, this algorithm cannot repair the damaged points in the image boundary. Herein, an algorithm based on corrosion treatment and multi-parameter factors is proposed to address the limitations of the CDD inpainting algorithm. The main steps of the algorithm can be given as follows. First, the image mask to be repaired is corroded to eliminate the wastage of time because of an oversized mask. Second, a natural logarithmic exponential factor and a linear exponential factor are introduced in the curvature and gradient modulus calculations, respectively. Further, the effect of unreasonable gradient modulus and curvature values on the diffusion rate can be avoided by adjusting the parameters of different exponential factors. In addition, a self-adaptive positive lifting parameter that varies with the number of iterations is introduced to calculate the curvature and gradient modulus, improving the repair of the damaged area. Finally, the corresponding boundary treatment conditions are adopted according to the boundary locations of the images with broken boundaries, avoiding the problem that a broken boundary cannot be repaired. The simulation results demonstrate that the improved CDD inpainting algorithm improves the repairing speed and that images with broken boundaries can also be repaired.
The traditional flame detection algorithm often achieves incomplete contour and poor anti-interference performance in the process of flame foreground extraction. This paper proposes a new flame foreground extraction algorithm, which combines RGB, HSI, and Ostu (maximum between-cluster variance method). The developed algorithm can extract flame contour completely and eliminate the smallest possible interference. Then, static features such as textures and colors in YCbCr are extracted by using a co-occurrence matrix and used for final flame judgment. Finally, an improved probabilistic neural network (PNN) method is developed to adjust the traditional smoothing factor from a single fixed value to a parameter that contains multi-variables, after which the expectation/conditional maximization (ECM) algorithm is used to find the optimal parameters. The extracted features are input in the advanced PNN and used for the training test. Simulation results show that the proposed algorithm can improve the accuracy of flame identification with good anti-interference performance.
Camera pose estimation has a low accuracy and only generates a sparse map in the oriented FAST rotated BRIEF SLAM2 (ORB-SLAM2) system. To compute camera pose and generate a dense map, this study proposes a method that combines the dense direct method and sparse feature-based method adopted by the original ORB-SLAM2 system framework. This method mainly makes three improvements to the ORB-SLAM2 system. First, a new dense constraint unary edge is created in the third-party general graph optimization (g2o) library used in the original system; the photometric error constraint of the dense direct method is added to the g2o library. Second, the rotation transformation between two executive frames is calculated using the dense direct method; then, the improved g2o library is used to simultaneously minimize the re-projection error of the feature-based method and the photometric error of the direct method to compute the 6 degree-of-freedom (DOF) camera pose. Third, a dense reconstruction thread is added in the ORB-SLAM2 system framework and the reconstruction result of the surrounding scene is reported to the user in real time. Experiments conducted on TUM RGB-D and ICL-NUIM datasets reveal that the proposed method considerably improves the accuracy of the camera pose estimation in the ORB-SLAM2 system, produces sparse maps, and reconstructs high-precision dense maps.
This study proposes an ultrasound left ventricular segmentation method. First, the region of the heart with a different echo intensity is divided into independent parts by the three-phase Level Set method. Second, the ventricular wall region is extracted by the binary processing method, and the noise and myocardial wall area are removed and connected, respectively. Third, the left ventricle contour is fitted by the curve fitting method and segmented into a smooth closed segmentation curve. The segmentation results of the proposed algorithm are compared with the doctor's manual segmentation results. The left ventricle is qualitatively segmented. The results are evaluated using three image segmentation evaluation methods, namely, the relative difference degree (RDD), relative overlap degree (ROD), and Dice parameters. The RDD value is 0.051, while the ROD and Dice parameter values are both close to 0.900. The left ventricular segmentation results are quantitatively analyzed. The analysis shows that the algorithm has a good segmentation effect on the heart ventricular wall area, and it is not sensitive to intracardiac noise. A variety of curve fitting methods have a good effect on the left ventricular contour.
To address the problem of backscattering in underwater optical imaging, a method of push-broom underwater ghost imaging computation is studied. A push-broom computation mode for ghost imaging is introduced. Multiple detection lines are combined to form a joint compressive sensing model by exploiting the inter-line correlation. Iterative shrinkage thresholding method is used to solve the model. An experiment setup of underwater ghost imaging computation is established. The proposed method is experimentally compared with traditional plane-array ghost imaging computation methods under different turbidities. Experimental results show that the proposed scheme can reduce the backscattering effectively.
To explore the effect of the anisotropy of different cut directions of Cr4+∶YAG crystals on the polarization characteristics of laser output,the anisotropy of Cr4+∶YAG crystal is studied experimentally using 1064-nm linearly polarized pulsed light as the test light source. In the experiment, the input light power density, initial transmittance, and crystal cutting direction are considered. The experimental results demonstrate that within a certain range of power density, the higher the power density is, the more obvious the anisotropy of Cr4+∶YAG is. The results also show that anisotropy is obvious with low initial transmittance of Cr4+∶YAG. Under the same power density, the saturation transmittance of [110]-cut Cr4+∶YAG is greater than that of [100]-cut Cr4+∶YAG in a certain direction. The [110]-cut and [100]-cut Cr4+∶YAG crystals are used as saturable absorbers for an 808-nm LD pumped passively Q-switched Nd∶YAG/Cr4+∶YAG solid laser, and the experimental results demonstrate that the extinction ratio of the output laser with [110]-cut Cr4+∶YAG is greater than that with [100]-cut Cr4+∶YAG.
A shock wave induced by a nanosecond laser was used to obtain the high shock pressure to explore the relationship between metal failure and metal target thickness. A TC4 titanium mechanical simulation model under the laser-induced shock wave loading was constructed herein based on the calculation results. The damage of the TC4 target was predicted depending on the calculation results. The corresponding laser loading experiment was performed according to the simulation model. The experimental results were analyzed and compared with the simulated results. The results show that when the target thickness is 0.05 mm, the nanosecond laser pulse width is 10 ns, the single pulse energy is 7 J, the frequency is 1 Hz, and the spot diameter is 5 mm. The simulation results also predicts the target damage, and the experimental results are consistent with the simulation results.
The traditional infrared target detection method for missile homing guidance is flawed because of low accuracy and lack of real-time feedback. Therefore, an infrared homing guidance target detection method based on the improved YOLO v3 is proposed,and it involves the optimization of the weight loss by considering the background of infrared homing guidance, improving the accuracy of positioning and classification. Subsequently, the adaptive moment estimation (Adam) and stable stochastic gradient descent (SGD) with momentum are fully exploited. Further, a joint training method predicated on pre-training, which significantly improves the accuracy of detection, is proposed herein. The improved algorithm is ideally trained and tested on the infrared target dataset designed in this work. The best mean average precision is 77.89%, and all the detection rates are greater than 25 frame/s. The false and missing alarm probabilities are effectively reduced.
Considering the incapacity of the traditional network structure to fully extract spatiotemporal information in data, a spatiotemporal pyramid pooling model is proposed. A three-dimensional, densely connected convolutional neural network based on dense computation and fusion of spatiotemporal features is designed. The combination of this model with non-local computation operation of features improves the effectiveness of spatiotemporal-feature extraction from videos. The algorithm is applied to the analysis of teachers' actions in classroom scenes. The experimental results show that the designed network structure produces high recognition accuracy on the teachers' actions dataset.
To address the problems of yarn evenness and hairiness detection, a yarn quality detection system based on machine vision is designed. In addition to hardware, the system core includes a software detection algorithm. The hardware primarily includes an image acquisition unit, a yarn traction device, and a system control device. In terms of software, machine vision and image processing methods were used to detect yarn evenness and yarn hairiness, respectively. Bilateral filtering and Otsu threshold were used to detect the evenness of the yarn, and an EM algorithm and density clustering were used to detect yarn hairiness. The test results and the processed yarn images were displayed in a constructed artificial interaction interface, and the yarn evenness and hairiness were measured and displayed in real time. The experimental results demonstrate that the proposed system delivers effective real-time performance, stability, and high accuracy. In addition to practical applications, the proposed yarn quality detection system is also expected to contribute to academic research in this field.
In complementary learners for real-time tracking known as Staple, the merging coefficients of histogram of oriented gradient feature and color histogram have both a fixed value of 0.3, which can easily cause the problem of losing target when they are merged under different features. To solve this problem, this study proposes an adaptive merging algorithm of complementary learners for real-time visual tracking based on an object probabilistic model known as amStaple, which uses a piecewise function to obtain the adaptive merging coefficient. Experiments on popular object tracker benchmarks including OTB-2013 and OTB-100 verify the effectiveness of the proposed algorithm. Results show that amStaple has better performance than Staple. Compared with Staple in terms of OTB-2013 and OTB-100, amStaple has 6.52% and 3.32% higher precision and 4.89% and 3.11% higher success rates, respectively. Although the proposed algorithm is relatively less innovative, its performance has been obviously improved in various aspects compared with that of a state-of-the-art algorithm from the same period. However, amStaple performs poorly on partial sequence attributes of object tracker benchmarks. To solve this problem, a decision condition is added based on amStaple, which is called amStaple1.
Based on the angio elastography principle, the variation in blood-vessel diameter with pressure is measured by the photoacoustic elastography technique. A characteristic time-domain model for photoacoustic signals is developed to analyze the information of the blood pressure-diameter relation. A series of digital signal-processing methods based on the Hilbert transform are used to obtain spatial distributions of elastic mechanical properties in tissues. Results demonstrate that the pressure and vessel diameter have a monotonously increasing relation with the photoacoustic-signal time interval, which can be used to dynamically and quickly detect changes in the vessel diameter. This method provides a theoretical basis for non-invasive ambulatory blood-pressure measurements by photoacoustic imaging.
To control the light steering direction in three-dimensional space, a liquid prism array system based on electrowetting-on-dielectric (EWOD) is proposed. According to the geometrical optics and EWOD theory, the relationships among the beam steering angle, maximum beam steering angle, EWOD contact angle, interval between adjacent prisms, and liquid refractive index are analyzed and discussed. A theoretical model of an EWOD liquid prism array is constructed in COMSOL. Then, the evolution of the double liquid interface in the liquid prism unit is simulated under different voltages. The beam steering control characteristics of the liquid prism array are simulated. Results demonstrate that the EWOD based liquid prism array can realize continuous beam steering control in a certain range. By selecting a specific combination of liquids, the saturation contact angle can decrease to 45°, and consequently the range of beam steering angle for the liquid prism unit reaches 28° (from -14° to 14°). As the optical axis spacing r is set to 6 mm, the steering region of the liquid prism array system is in a conical region whose apex angle is 28°, and the corresponding vertex of the cone is located at Z=22.58 mm in the Z-axis.
A convolutional neural networks based algorithm is proposed to extract multiple features from a single person. Further, the feature representation of a person using spliced multi-features is also proposed. Initially, the multi-branch structure is constructed using global pooling and multiple convolution; this multi-branch structure is used to offset the information loss. Subsequently, the bottleneck layer is designed to replace the classification layer in the model to reduce overfitting. In the experiment, the proposed algorithm is verified using the Market1501, CUHK03, and DukeMTMC-Reid datasets. In Market1501, the proposed algorithm achieves the first correct prediction probability (Rank1) of 95.2% and mean average precision (mAP) of 86.0%. The experimental results indicate that the proposed algorithm can extract discriminative features. Furthermore, the recognition accuracy of the proposed algorithm is significantly better than that of other advanced algorithms.
A regularized feature extraction algorithm based on the improved Canny algorithm is proposed to address the problems related to applying a feature extraction algorithm to scattered point clouds, i.e., computational burden and lack of regularization. First, scattered point clouds are resampled according to different range resolutions, and the point clouds are rasterized regularly. Second, the gray value of the grid matrix is assigned by the optimized substitution method, and the scattered point clouds are projected into two-dimensional images. Finally, the improved Canny algorithm is used to extract feature regularization from the two-dimensional images. Comparative experimental results demonstrate that the proposed method yields less noise, has strong maneuverability, and can extract features from a straight line boundary or complex curve boundary efficiently. The proposed method will play an important role in the registration of point clouds and images, as well as three-dimensional reconstruction.
The proposed morphological filtering algorithm improves the filtering effect of the radar point cloud greatly. Separation accurate and efficient for the ground points and non-ground points has always been the key problem to the filtering algorithm. Many scholars focus on the determination of the filtering threshold. The contour is an important research content in spatial analysis. Based on the progressive morphology filtering algorithm, the contour is used to obtain the key threshold of the filtering algorithm quickly. Comparing with the traditional manual testing threshold, the contour threshold determination method is more intuitive, and the appropriate threshold can be determined relatively quickly. In order to test the filtering efficiency and accuracy of the contour-morphological filtering algorithm, this paper uses the progressive triangulation filtering algorithm for comparing purpose, and the advantages of the proposed algorithm have been proved.
The traditional ship detection algorithm is difficult to adapt in the complex and varied sea clutter environment, and intelligent ship detection is impossible to realize. This study proposes an improved region-based fully convolutional network (R-FCN) detection method. Aiming at the characteristics of synthetic aperture radar (SAR), the feature extraction network ResNet in R-FCN uses a mixed-scale convolution kernel. The feature extraction network can suppress the influence of the speckle noise and effectively extract the ship features. High-resolution GF-3 and low-resolution Sentinel-1 satellite SAR images are selected for the test. Consequently, good results are obtained, proving the effectiveness of the proposed algorithm.
Cloud detection is prone to error and considerable loss of details because clouds do not have obvious color distribution and texture pattern in RGB color images. Therefore, this study proposes an improved M-Net model called the RM-Net model to achieve end-to-end pixel-level semantic segmentation. An original dataset is enhanced and a corresponding pixel-level label is marked. Multi-scale image features are extracted without losing data via atrous spatial pyramid pooling, and residual units are combined to make the network resistant to degradation. Global context informations of the images are extracted using the encoder module and the left path. The spatial resolutions of the images are restored using the decoder module and the right path. Each pixel's category probability is determined based on fused features, and pixel-level cloud and non-cloud segmentation are performed using the input classifier. When training and testing Landsat8 and GaoFen-1 WFV RGB color images, experimental results show that the proposed method can well detect cloud edge details under various conditions and achieve high-precision cloud shadow detection, thus demonstrating that the proposed method has high generalization and robustness.
Herein, numerical results for stimulated Brillouin scattering (SBS) in a step-index few-mode fiber are discussed based on the theory of wave optics and a mathematical model of SBS in a single-mode fiber. The acousto-optic coupling coefficient is calculated and a series of Brillouin gain spectra and phase shift spectra are presented according to the optical and acoustic mode profiles. Numerical results demonstrate that acoustic modes involved in the SBS process are primarily those with low mode orders. Compared to inter-mode SBS in LP01 and LP11 modes, intra-mode SBS is more critical, wherein the latter can obtain larger Brillouin gain and phase shift. In addition, the Brillouin frequency shift evidently decreases as the optical mode order increases.
Based on nanosecond laser two-beam interference ablation assisted with wet-etching method and finite difference time domain (FDTD) simulation, the formation of structures on silicon is studied experimentally and theoretically. The results show that it is possible for the fabrication of structures with period more than 600 nm by a nanosecond laser with wavelength of 355 nm. The structure depth becomes deeper with the increasing of power or exposure time. The maximum depth is equal to the skin depth of laser, about 50 nm. Further, the period splits into half when the exposure time is more than 5 s, which brings a method to obtain a minimum period of 300 nm. The FDTD simulation confirms that the modulation of formed structures to the interference field is the reason for period splitting. The research shows great potential applications for the fabrication of periodic micro/nanostructures, design of maskless processing facilities, and laser-matter interactions.