




 View fulltext
View fulltext

2024
Volume: 32 Issue 4
13 Article(s)

Qiao GU, Yao LIU, Yang HE, and Xinjie ZHANG
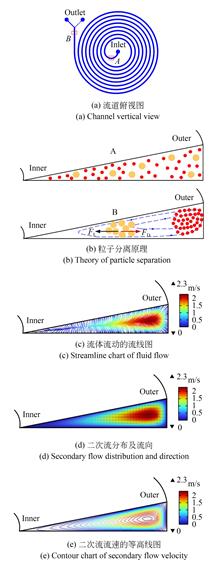
In order to separate microparticles of different sizes, an inertial microfluidic chip with the microchannel of triangular cross-section was proposed, and the characterization of particles focusing and separation in the microchannel was studied. Firstly, a spiral channel with right-angled triangle cross-section was designed. Then, micro-milling was used to cut the microchannel in an aluminum mold, and casting and plasma cleaning were used to fabricate the microfluidic chip. Next, sample suspensions of three different fluorescent particles (6 μm, 10 μm and 15 μm) were prepared. The trajectories of particles in the channel were captured by a high-speed camera and a fluorescent microscope, and the focusing effect of particles under the different suspension flow rates was observed. Finally, the images of particle focusing were stacked and analyzed, and the inertial focusing and separation behavior of particles were studied. The results show that with the increase of the flow rate of particle suspension, the 6 μm particles gradually focus and migrate towards the outer wall of the channel, while the focusing streams of 10 μm and 15 μm particles migrate towards the central channel. When the flow rate is set to 1.5 mL/min, the mixed suspension of 10 μm and 15 μm particles can be separated with the efficiency of 100%. This study demonstrates that the spiral microchannel of triangular cross-section produces strongly skewed secondary flow, which can be applied for the high-efficiency and precise separation of microparticles of different sizes. The research findings will provide new insights for accurate cell manipulation.
Feb. 25, 2024Vol. 32 Issue 4 504 (2024)
Xiangqiang ZHONG, Lingling ZOU, and Sailong FENG
In order to improve the output amplitude of conventional ultrasonic consolidation vibration devices and meet the requirements of stable consolidation of metal sheets, a double-head ultrasonic consolidation vibration device with single-side double-transducer structure was proposed. Based on the resonant system design theory, the size parameters are designed, and the modal analysis and optimization of the device were carried out. The optimal longitudinal vibration frequency was 20 247 Hz. Based on the equivalent four-terminal network method, the ultrasonic consolidation vibration device with two vibration heads was modeled and simulated, and the maximum output amplitude could reach 36 μm. Finally, a prototype was made to test the amplitude and explore the relationship between the output amplitude and the excitation voltage. The experimental results show that the output amplitude is linearly correlated with the excitation voltage. The maximum output amplitude of the device is 34.4 μm, and the error rate of the simulation results is less than 5%. The rationality of the structure is verified, the output amplitude of the device is improved effectively, and the application of ultrasonic consolidation technology in related fields is promoted.
Feb. 25, 2024Vol. 32 Issue 4 514 (2024)
Junfeng LI, Xiangbo XU, Shao CHEN, Xianzhang WANG, Lei FU, and Yahui ZHU
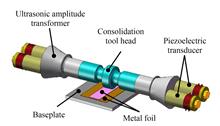
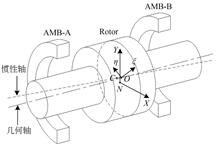
Harmonic vibrations caused by rotor mass imbalance and sensor runout, the main disturbances in magnetically suspended rotor systems. To suppress these disturbances, a compound control method based on repetitive control and variable phase adaptive notch filter feedback was proposed. Firstly, by establishing a model of the magnetic suspended rotor system, the generation mechanism of different disturbing vibration forces was analyzed. Then, taking the X-direction as an example for analysis, an inserted repetitive controller was designed to suppress the harmonic vibration caused by sensor runout. An adaptive notch filter was used to extract the synchronous signal online to adaptively compensate imbalance. The stability of the system was maintained by varying the phase angle at different frequencies, and to compensate the same-frequency displacement stiffness, so that the system can effectively suppress the harmonic vibration. Finally, the proposed control method was verified by simulation and experiment. The experimental results show that the first, third and fifth harmonic vibrations are reduced by 94.4%, 90.4% and 85.9%, respectively. The harmonic vibrations can be effectively suppressed using the proposed composite control method, whose effectiveness well verified.
Feb. 25, 2024Vol. 32 Issue 4 524 (2024)
Jun LI, Binbin FAN, Qingjie ZENG, Jiarui ZHANG, Tian MA, Xiaowei ZHAI, Le HAO, Anshan XIAO, He ZHANG, and Zhen WANG
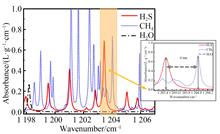
The research of hydrogen sulfide (H2S) and methane (CH4) concentration measurement technology is of great significance to petroleum and petrochemical industry.In this paper, a Quantum Cascade Laser (QCL) with a center wavelength of 8.309 μm was selected as the detection light source based on Tunable Diode Laser Absorption Spectroscopy (TDLAS) technology. A 30 m long distance sensing system was established by using Wavelength Modulated Spectroscopy (WMS) technology to measure the mixture of H2S and CH4 gases. The experiment mixed H2S with 5% volume fraction of water vapor for measurement, and it showed excellent absorption characteristics in this band, with less cross-interference. Through sensing experiments, the impact of different sensing distances of 15 m and 30 m on the detection signal was analyzed. By increasing integration time and calculating the signal-to-noise ratio, a minimum sensing limit of 128.75 ×10-9 m was achieved. Finally, Allan variance calculations revealed that when integration time was 183 s and 142 s, the lowest detection limits for H2S and CH4 were 0.593×10-9 and 1.160×10-9, respectively. The results provide an effective method for remote measurement of highly sensitive H2S and CH4 multi-component gases and ensure safe operation in a variety of industrial environments.
Feb. 25, 2024Vol. 32 Issue 4 467 (2024)
Zhanfei ZHANG, Jie HUANG, Qiang SONG, Fei FENG, and Jianwen DING
In order to obtain stable and high-quality sequential images under transient condition and different object distances, a four-channel sequential front light high-speed imaging system was designed. The system used image space parallel light splitting, taking the imaging principle as the starting point to analyze the key design elements of system. Based on the theoretical calculation parameters, the sub-lens groups (objective lens group, field mirror and collimating lens group, converging lens group) was designed and aberrations were independently corrected. Adding field mirror to reduce the size and weight of system and improve light energy utilization. The transmission effect of beam was improved by accurate connection of field of view and pupil. On this basis, the sub lens groups were integrated and optimized, and beam splitters were added to form the final four-channel sequential front light imaging system. The object distance adjustable optical path was designed, and the image quality of system at the object distance of 0.5 m~∞ was guaranteed by adjusting the handwheel of objective lens group in use, while keeping the position of primary image plane unchanged, enhancing the stability of system performance stability and reducing the difficulty of installation and adjustment. The receiving part of system can be replaced according to actual needs, and the system can be expanded to eight-channel system after adding splitters in the beam splitting region. The installed and adjusted sequential front-light imaging system is used for laboratory testing and field tests, and main optical performance is good. the resolution of each channel can reach 72 lp/mm, and imaging consistency is greater than 98%. Field test results show that the optical system can meet the requirements for shooting sequence images under transient condition.
Feb. 25, 2024Vol. 32 Issue 4 478 (2024)
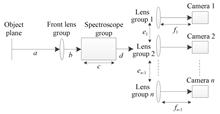
Yue ZHANG, Ning ZHANG, Xiping XU, Yu ZHANG, Kailin ZHANG, and Xu ZHU
The field of view of UAVs varies greatly during large maneuvering movements, and visual features are easily lost in weak texture environments, which greatly reduces the accuracy of visual ranging. To address this problem, this paper combined a catadioptric omnidirectional camera with structured light, and further proposed a catadioptric omnidirectional monocular visual ranging method with fused structured light. In this study, in order to improve the accuracy of the ranging method as well as the processing speed, the region of interest (ROI) of the structured light was first extracted and the median filter was applied to denoise the laser streak image, and then the improved Steger algorithm was used for the extraction of the center coordinate of the structured light streak at the sub-pixel level. Second, the least squares principle was applied to curve-fit the extracted sub-pixel points to obtain the curve equation of the structured light. Finally, the spatial plane parameters were derived through theoretical derivation to establish the ranging objective function to further obtain the distance information.In different scenarios, the ranging accuracy of the proposed ranging method is within 3%, which proves the effectiveness of the method.It meets the demand for stable and reliable ranging of UAVs under large maneuvering conditions and weak texture scenes, and further improves the ability of UAVs to perceive the environment.
Feb. 25, 2024Vol. 32 Issue 4 490 (2024)

Huiyou ZHAO, Xuequn WU, and Yonghua XIA
In view of the position deviation of vehicle laser scanning to obtain urban scenes in different periods, the Traditional point cloud registration methods still have the limitations of low efficiency and low robustness, and an improved point cloud registration method using rods and lane lines was proposed in this paper. Firstly, the filtered point cloud was voxel grid down-sampled, and then the cloth model was used to filter the ground points, and then the K-means unsupervised classification of non-ground point clouds was used, and then the rods were extracted as the target features, and the point cloud grayscale map and spatial density segmentation method were proposed according to the reflection intensity of the point cloud. Then, the improved iterative closest point (ICP) algorithm and normal constraint were used to use rods and lane lines as registration primitives, geometric consistency algorithms were used to eliminate wrong point pairs, and bidirectional KD-trees were used to quickly correspond to the relationship of feature points, so as to accelerate the registration speed and improve accuracy. Experiments show that it takes less than 20 s in urban point cloud scenarios with low overlap, and only 20 iterations, and the accuracy can reach 1.987 7×10-5 meters, which can realize the efficient and accurate registration of laser point clouds in urban road scenes.
Feb. 25, 2024Vol. 32 Issue 4 535 (2024)
Jiajun ZHANG, Jing LIAN, Jizhao LIU, Zilong DONG, and Huaikun ZHANG
Using image structure features for image inpainting is a new method that has emerged in recent years with the widespread application of deep learning techniques. This method can generate plausible content within missing areas, but the restoration results heavily rely on the extracted content of image structures. In practical training, errors can propagate and accumulate, directly impacting the quality of the generated image when there is noise or distortion in the image structure. This method is still in the exploratory phase and faces challenges such as difficulty in network training, poor robustness, and inconsistent semantic context in generated images.To address these issues, this paper proposed a parallel network structure for image inpainting guided by smooth image structures. The generated content of the smooth image structure was not directly used as input for the next-level network but served as guidance information for the decoding layer of network. Additionally, to better match and balance the feature relationship between the structure and the image, this paper combined transformer and introduces a multi-scale feature guidence module. This module utilized the powerful modeling capability of transformers to establish connections between global features, matching and balancing features between structure and image textures.Experimental results demonstrate that the proposed method effectively restores missing content in images on three commonly used datasets and can be used as an image editing tool for object removal.
Feb. 25, 2024Vol. 32 Issue 4 549 (2024)
Jianli SONG, Xiaoqi LÜ, and Yu GU
The automatic segmentation method for brain tumors based on a U-shaped network structure often suffers from information loss due to multiple convolution and sampling operations, resulting in suboptimal segmentation results. To address this issue, this study proposed a feature alignment unit that utilizes semantic information flow to guide the up-sampling feature recovery and design designed a lightweight Dual Attention Feature Alignment Network (DAFANet) based on this unit.Firstly, to validate its effectiveness and generalization, the feature alignment unit was introduced separately into three classic networks, namely 3D UNet, DMFNet, and HDCNet. Secondly, a lightweight dual-attention feature alignment network named DAFANet was proposed based on DMFNet. The feature alignment unit enhanced feature restoration in the up-sampling process, and a 3D Expectation-Maximization attention mechanism was applied to both the feature alignment path and cascade path to capture the full contextual dependency. The generalized Dice loss function was also used to improve segmentation accuracy in the case of data imbalance and accelerate model convergence.Finally, the proposed algorithm is validated on the BraTS2018 and BraTS2019 public datasets, achieving segmentation accuracies of 80.44%, 90.07%, 84.57% and 78.11%, 90.10%, 82.21% in the ET, WT, and TC regions, respectively.Compared to current popular segmentation networks, the proposed algorithm demonstrates better segmentation performance in enhancing tumor regions and is more adept at handling details and edge information.
Feb. 25, 2024Vol. 32 Issue 4 565 (2024)
Ning WANG, Wenxing BAO, Kewen QU, and Wei FENG
Due to different lighting conditions, complex atmospheric conditions and other factors, the spectral signatures of the same endmembers show visible differences at different locations in the image, a phenomenon known as spectral variability of endmembers. In fairly large scenarios, the variability can be large, but within moderately localised homogeneous regions, the variability tends to be small. The perturbed linear mixing model (PLMM) can mitigate the adverse effects caused by endmember variability during the unmixing process, but is less capable of handling the variability caused by scaling utility. For this reason, this paper improved the perturbed linear mixing model by introducing scaling factors to deal with the variability caused by the scaling utility, and used a super-pixel segmentation algorithm to delineate locally homogeneous regions, and then designed an algorithm of Shared Endmember Variability in Unmixing (SEVU). Compared with algorithms such as perturbed linear mixing model, extended linear mixing model (ELMM), and other algorithms. The proposed SEVU algorithm was optimal in terms of mean Endmember Spectral Angular Distance (mSAD) and abundance Root Mean Square Error (aRMSE) on the synthetic dataset with 0.085 5 and 0.056 2, respectively. mSAD is optimal on the Jasper Ridge and Cuprite real datasets with 0.060 3 and 0.100 3, respectively. Experimental results on a synthetic dataset and two real datasets verify the effectiveness of the SEVU algorithm.
Feb. 25, 2024Vol. 32 Issue 4 578 (2024)
Qifeng DONG, Mei YU, Zhidi JIANG, Ziang LU, and Gangyi JIANG
Visually induced motion sickness (VIMS) in immersive virtual reality experience is an important problem that impedes the development and applications of virtual reality systems. Most of the existing assessment methods based on visual content are not comprehensive enough, and the extracted features of motion information are relatively simple, and the influence of abrupt changes in time domain on motion sickness is rarely considered. To solve these problems, a spatio-temporal multi-feature assessment model for VIMS in virtual reality was proposed. The spatial and temporal information of stereoscopic panoramic video was used to design the assessment model of VIMS. The weighted motion features more in line with human perception were adopted, and the feature extraction method was designed considering the temporal mutation information of stereoscopic panoramic video. The proposed model was divided into preprocessing module, feature extraction module and time domain aggregation and regression module. The preprocessing module was used to extract the viewport images and estimate the optical flow map, disparity map and saliency map. The feature extraction module included foreground-background weighted motion feature extraction, disparity feature extraction based on transform domain, spatial feature extraction and time domain abrupt change feature extraction. VIMS evaluation scores were finally obtained through time domain aggregation and support vector regression. The experimental results show that the PLCC, SROCC and RMSE of the proposed model are 0.821, 0.790 and 0.489, respectively when tested on the stereoscopic panoramic video database SPVCD. The model achieves excellent prediction performance which verifies the effectiveness of the proposed feature extraction module.
Feb. 25, 2024Vol. 32 Issue 4 595 (2024)
Daxiang LI, Fujie YANG, Ying LIU, and Yao TANG
Owing to the limitations of convolutional operations, existing skin lesion image segmentation networks are unable to model the global contextual information in images, resulting in their inability to effectively capture the target structural information of images. In this paper, a U-shaped hybrid network with cross-self-attention coding was designed for skin lesion image segmentation. Firstly, the designed multi-head gated position cross self-attention encoder was introduced in the last two layers of the U-shaped network to enable it to learn the long-term dependencies of semantic information in images and to compensate for the lack of global modelling capability of the convolutional operation; Secondly, a novel position channel attention mechanism was implemented in the skip connection part to encode the channel information of the fused features and retain the positional information to improve the network's ability to capture the target structure; finally, a regularised dice loss function was designed to enable the network to trade off between false positives and false negatives to improve the network's segmentation results. Experimental results on ISBI2017 and ISIC2018 datasets show that the network presented in this paper achieves Dice score of 91.48% and 91.30%, and IoU of 84.42% and 84.12%, respectively. The network outperforms other networks in terms of segmentation accuracy with fewer parameters and lower computational complexity. Therefore, it can efficiently segment the target region of skin lesion images and aid in the adjunctive diagnosis of skin diseases.
Feb. 25, 2024Vol. 32 Issue 4 609 (2024)
Lili ZHANG, Zikun CHEN, Tianpeng PAN, and Lele QU
Unlike ordinary image compression, multispectral image compression needs to remove spatial redundancy as well as inter-spectral redundancy. Recent studies show that the end-to-end convolutional neural network model has a very good performance in image compression, but for multispectral image compression, its codecs cannot effectively solve the problem of efficiently extracting spatial and inter-spectral features of multispectral images at the same time, and it neglects the localized feature information of the image. The localized feature information of the image is also neglected. To address the above problems, this paper proposed a multispectral image compression method that incorporates a convolutional neural network with multiscale features. The proposed network embeds that can extract spatial and inter-spectral feature information at different scales, and an inter-spectral spatial asymmetric convolution module that can be used to capture local spatial and spectral information. Experiments show that the Peak Signal to Noise Ratio(PSNR) metrics of the proposed model are 1-2 dB higher than those of the traditional algorithms such as JPEG2000 and 3D-SPIHT as well as the deep learning methods on the 7-band of Landsat-8 and 8-band of Sentinel-2 datasets. Regarding the Mean Spectral Angle(MSA) metrics, the proposed model is more effective on the Landsat-8 dataset and outperforms the traditional algorithm by about 8×10-3 rad. The proposed model outperforms the traditional algorithm by about 2×10-3 rad on the Sentinel-2 dataset. The requirements of multispectral image compression for spatial and inter-spectral feature extraction as well as localized feature extraction are satisfied.
Feb. 25, 2024Vol. 32 Issue 4 622 (2024)
© Copyright 2018-2021 | Chinese Laser Press.
All Rights Reserved 沪ICP备15018463号-20