









Please enter the answer below before you can view the full text.
9-7=

In the aspherical surface zero position interference detection, there is a projection distortion between the measurement error distribution and the actual error distribution of the surface to be measured. Aiming at the problems of complex calculation and poor generality of current projection distortion correction methods, a correction method based on a convolutional neural network (CNN) is proposed. In this method, an intersecting parallels flexible occlude is added to the surface, and the interference image is synthesized according to the range of projected distortion coefficient as the data set of CNN. Then the appropriate network structure to train the network based on the data set is selected. Finally, the actual interference image is input into the network to predict the distortion coefficient, and to realize the calibration and correction of the projection distortion. Experimental results show that the theoretical correction error of this method is less than 1 pixel, and the actual error correction accuracy is better than that of the traditional marker method, which proves that the method is efficient and feasible.
A self-adaptive underwater image enhancement algorithm is proposed to address the issues of color distortion, decreased contrast, and blurring caused by the imaging environment in underwater images. First, based on the local and global color biases in the Lab color space, color compensation is applied to attenuated colors, and thereafter the grayscale world algorithm is used to restore the color balance of underwater images. Second, automatic color scale and gamma correction methods are used to adjust the information of each channel to obtain images with high dynamic range and high illumination. Finally, high-frequency information is obtained through the antisharpening mask method, and image details are enhanced to obtain clear underwater images. The proposed algorithm utilizes statistical information, such as the color deviation and mean square deviation of the image, to achieve adaptive processing. The experimental results show that the proposed algorithm can effectively remove color deviation from underwater images, improve image contrast and clarity, and enhance visual effects. Compared with other algorithms, it has advantages in processing efficiency and time.
Pulmonary nodule computed tomography (CT) images have diverse details and interclass similarity. To address this problem, a dual-path cross-fusion network combining the advantages of convolutional neural network (CNN) and Transformer is constructed to classify pulmonary nodules more accurately. First, based on windows multi-head self-attention and shifted windows multi-head self-attention, a global feature block is constructed to capture the morphological features of nodules; then, a local feature block is constructed based on large kernel attention, which is used to extract internal features such as the texture and density of nodules. A feature fusion block is designed to fuse local and global features of the previous stage so that each path can collect more comprehensive discriminative information. Subsequently, Kullback-Leibler (KL) divergence is introduced to increase the distribution difference between features of different scales and optimize network performance. Finally, a decision-level fusion method is used to obtain the classification results. Experiments are conducted on the LIDC-IDRI dataset, and the network achieves a classification accuracy, recall, precision, specificity, and area under curve (AUC) of 94.16%, 93.93%, 93.03%, 92.54%, and 97.02%, respectively. Experimental results show that this method can classify benign and malignant pulmonary nodules effectively.
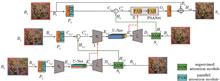
We propose a multi-stage underwater image enhancement model that can simultaneously fuse spatial details and contextual information. The model is structured in three stages: the first two stages utilize encoder-decoder configurations, and the third entails a parallel attention subnet. This design enables the model to concurrently learn spatial nuances and contextual data. A supervised attention module is incorporated for enhanced feature learning. Furthermore, a cross-stage feature fusion mechanism is designed is used to consolidate the intermediate features from preceding and succeeding subnets. Comparative tests with other underwater enhancement models demonstrate that the proposed model outperforms most extant algorithms in subjective visual quality and objective evaluation metrics. Specifically, on the Test-1 dataset, the proposed model realizes a peak signal-to-noise ratio of 26.2962 dB and structural similarity index of 0.8267.
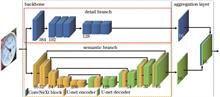
Aiming at the characteristics of small target image segmentation of pointer meter and the limitations of existing methods, a bilateral deep learning backbone network called BiUnet is proposed for pointer meter image segmentation, which combines spatial details and semantic features. Starting from BiSeNet V2 algorithm, the semantic branch, detail branch and bilateral fusion layer are redesigned in this network. First, the ConvNeXt convolution block is used to adjust and optimize the detail branch to improve the feature extraction ability of the algorithm for pointer and scale line boundary details. Second, the semantic branch is redesigned based on the advantages of the U-shape structure of encoder and decoder to integrate different scales of semantic information, which improves the special segmentation ability of the semantic branch for small objects such as pointer and scale. Finally, a bilateral-guide splicing aggregation layer is proposed to fuse the detail branch and the semantic branch features. The ablation experiments on the self-made instrument image segmentation dataset confirm the validity and feasibility of the proposed network design scheme. Comparative experiments with different backbone networks are carried out on the instrument dataset, the experimental results show that the mIoU (mean intersection of union) of BiUnet's instrument segmentation accuracy reaches 88.66%, which is 8.64 percentage points higher than the BiSeNet V2 network (80.02%). Both of them have better segmentation accuracy than common backbone networks based on Transformer and pure convolution.
Image segmentation is an important research direction in computer vision. Fuzzy clustering methods have been widely applied in image segmentation due to their unsupervised nature. However, traditional fuzzy clustering methods often fail to segment images with high-intensity noise and complex shapes. To solve this problem, a weighted factor is proposed based on saliency detection to construct a weighted filter and a pixel correlation model, which improves the noise resistance of the algorithm. The proposed weighted filter outperforms the optimal results of the traditional filter in terms of structural similarity by 0.1. Moreover, a kernel metric is introduced to accommodate the segmentation needs of complex images. Extensive experimental results on synthetic, natural, remote sensing and medical images demonstrate that the proposed algorithm outperforms the traditional methods in visual effects and improves the segmentation accuracy by 2% compared with the optimal results of traditional methods.
Single target tracking algorithm based on Siamese architecture suffers from untimely target state update. To address this issue, a generic template update mechanism is proposed based on the dynamic fusion of templates and memory information. The mechanism uses a dual module fusion update strategy. The short-term memory information of search feature map is fused using a memory fusion module to capture target variations. The trusted tracking result of the previous frame is used as a dynamic template. The original and dynamic templates are fused using a weight fusion module from the correlated feature perspective to achieve more accurate target localization using the original and short-term memories during the tracking process. The template update mechanism is applied to three mainstream algorithms, SiamRPN, SiamRPN++ and RBO, and experiments are conducted on the VOT2019 public dataset. The results show that the performance of the algorithms is effectively improved after applying the mechanism. Specially, for the SiamRPN++ algorithm, the average overlap expectation is improved by 6.67%, the accuracy is improved by 0.17%, and the robustness is enhanced by 5.39% after applying the template update mechanism. In addition, the SiamRPN++ algorithm with the mechanism has better tracking performance in complex scenarios with occlusion, deformation and background interference.
A depth image super-resolution reconstruction network (DF-Net) based on dual feature fusion guidance is proposed to address the issues of texture transfer and depth loss in color image guided deep image super-resolution reconstruction algorithms. To fully utilize the correlation between depth and intensity features, a dual channel fusion module (DCM) and a dual feature guided reconstruction module (DGM) are used to perform deep recovery and reconstruction in the network model. The multi-scale features of depth and intensity information are extracted using a input pyramid structure: DCM performs feature fusion and enhancement between channels based on a channel attention mechanism for depth and intensity features; DGM provides dual feature guidance for reconstruction by adaptively selecting and fusing depth and intensity features, increasing the guidance effect of depth features, and overcoming the issues of texture transfer and depth loss. The experimental results show that the peak signal-to-noise ratio (PSNR) and root mean square error (RMSE) of the proposed method are superior to those of methods such as RMRF, JBU, and Depth Net. Compared to the other methods, the PSNR value of the 4× super-resolution reconstruction results increased by an average of 6.79 dB, and the RMSE decreased by an average of 0.94, thus achieving good depth image super-resolution reconstruction results.
The multi-energy computed tomography (CT) technique can resolve the absorption rates of various energy X-ray photons in human tissues, representing a significant advancement in medical imaging. By addressing the challenge of swift degradation in reconstructed image quality, primarily due to non-ideal effects such as quantum noise, a dual-stream Transformer network structure is introduced. This structure utilises the shifted-window multi-head self-attention denoising approach for projection data. The shifted windows Transformer extracts the global features of the projection data, while the locally-enhanced window Transformer focuses on local features. This dual approach capitalizes on the non-local self-similarity of the projection data to maintain its inherent structure, subsequently merged by residual convolution. For model training oversight, a hybrid loss function incorporating non-local total variation is employed, which enhances the network model's sensitivity to the inner details of the projected data. Experimental results demonstrate that our method's processed projection data achieve a peak signal to noise ratio (PSNR) of 37.7301 dB, structure similarity index measurement (SSIM) of 0.9944, and feature similarity index measurement (FSIM) of 0.9961. Relative to leading denoising techniques, the proposed method excels in noise reduction while preserving more inner features, crucial for subsequent accurate diagnostics.
Currently, most point cloud semantic segmentation methods based on graph convolution overlook the critical aspect of edge construction, resulting in an incomplete representation of the features of local regions. To address this limitation, we propose a novel graph convolutional network AE-GCN that integrates edge enhancement with an attention mechanism. First, we incorporate neighboring point features into the edges rather than solely considering feature differences between the central point and its neighboring points. Second, introducing an attention mechanism ensures a more comprehensive utilization of local information within the point cloud. Finally, we employ a U-Shape segmentation structure to improve the network's semantic point cloud segmentation adaptability. Our experiments on two public datasets, Toronto_3D and S3DIS, demonstrate that AE-GCN outperforms most current methods. Specifically, on the Toronto_3D dataset, AE-GCN achieves a competitive average intersection-to-union ratio of 80.3% and an overall accuracy of 97.1%. Furthermore, on the S3DIS dataset, the model attains an average intersection-to-union ratio of 68.0% and an overall accuracy of 87.2%.
Traditional multi-scale fusion methods cannot highlight target information and often miss details and textures in fusion images. Therefore, an infrared and visible light image fusion method based on gradient domain-guided filtering and saliency detection is proposed. This method utilizes gradient domain-guided filtering to decompose the input image into basic and detail layers and uses a weighted global contrast method to decompose the basic layer into feature and difference layers. In the fusion process, phase consistency combined with weighted local energy, local entropy combined with weighted least squares optimization, and average rules are used to fuse feature layers, difference layers, and detail layers. The experimental results show that the multiple indicators of the proposed fusion method are significantly improved compared to those of other methods, resulting in a superior visual effect of the image. The proposed method is highly effective in highlighting target information, preserving contour details, and improving contrast and clarity.
To address challenges involving low accuracy in feature point matching, low matching speed, cracks at the stitching points, and extended stitching time in vehicle undercarriage threat detection imaging, an optimized image-stitching algorithm is proposed. First, the corner detection (FAST) algorithm is used to extract image feature points, and then, the binary robust invariant scalable key point (BRISK) algorithm is used to describe the retained feature points. Second, the fast nearest neighbor search (FLANN) algorithm is used for coarse matching. Next, the progressive uniform sampling (PROSAC) algorithm is used for feature point purification. Finally, the Laplace pyramid algorithm is used for image fusion and stitching. The experimental results show that, when compared with SIFT, SURF, and ORB algorithms, the proposed algorithm improves the image feature matching accuracy by 13.10 percentage points, 8.59 percentage points, and 11.27 percentage points, respectively, in the image data of dangerous objects under the vehicle. The matching time is shortened by 76.26%, 85.36%, and 10.27%, respectively. The image-stitching time is shortened by 63.73%, 64.21%, and 20.07%, respectively, and there are no evident cracks at the stitching point. Therefore, the image-stitching algorithm based on the combination of FAST, BRISK, PROSAC, and Laplace pyramid is a high-quality fast image-stitching algorithm.
Traditional non-real-time image stitching methods can easily lead to global stitching interruption due to local image misalignment. In addition, microscopic images have numerous similar microstructures, causing problems such as long feature detection time and high misalignment rate. To address these issues, a microscopic image prediction stitching algorithm based on carrier stage motion information is proposed. First, the size of the overlapping area between adjacent images is determined by controlling the XY axis movement distance of the electric carrier stage. The accelerated robust feature algorithm is then used to detect feature points in the overlapping area of the image. Second, the range of feature points to be matched is predicted based on the position relationship of the images, and the feature point with the minimum Euclidean distance is selected within the predicted range for matching. Finally, matching point pairs are coarsely screened by the slope of the matching feature points, and precise matching is performed using the random sample consensus algorithm to calculate the homography matrix and complete the image stitching. The improved weighted average algorithm is used to fuse the stitched images. Experimental results show that the proposed algorithm achieves a superior matching rate improvement of 7.95% to 26.52% compared to those obtained via the brute force and fast library for approximate nearest neighbors algorithms, effectively improving the registration accuracy. Moreover, at a resolution of 1600×1200, the multi-image stitching rate of 2 frame·s-1 achieves better results than those obtained by the AutoStitch software.
Building outlines serve as data sources for various applications. However, accurately extracting outlines from scattered and irregular point clouds presents a challenge. To address this issue, a method utilizing the concept of the multi-level minimum bounding rectangle (MBR) is proposed for extracting precise outlines of regular buildings. Initially, the boundary points are segmented into groups using an iterative region growing technique. Subsequently, the group with the maximum boundary points is utilized to identify the initial MBR. The initial MBR is then decomposed into multi-level rectangles, ensuring that the boundary points align with rectangles of different levels. Ultimately, the outlines are generated using the multi-level MBR approach. To evaluate the effectiveness of the proposed method, experiments were conducted on regular buildings in Vaihingen. The results demonstrate that the proposed method achieves an accurate initial MBR with a slightly enhanced efficiency compared to the minimum area and the maximum overlapping methods. The root mean square errors of the extracted outline corners measure 0.71 m, surpassing the performance of four other comparison methods. In conclusion, the proposed method enables the effective extraction of outlines from regular buildings, providing a valuable contribution to subsequent three-dimensional reconstruction tasks.
In order to solve the problems of high missing detection rate of single-model images and low detection speed of existing dual-model image fusion in pedestrian detection tasks under low visibility scenes, a lightweight pedestrian detection network based on dual-model relevant image fusion is proposed. The network model is designed based on YOLOv7-Tiny, and the backbone network is embedded with RAMFusion, which is used to extract and aggregate dual-model image complementary features. The 1×1 convolution of feature extraction is replaced by coordinate convolution with spatial awareness. Soft-NMS is introduced to improve the pedestrian omission in the cluster. The attention mechanism module is embedded to improve the accuracy of model detection. The ablation experiments in public infrared and visible pedestrian dataset LLVIP show that compared with other fusion methods, the missing detection rate of pedestrians is reduced and the detection speed of the proposed method is significantly increased. Compared with YOLOv7-Tiny, the detection accuracy of the improved model is increased by 2.4%, and the detection frames per second is up to 124 frame/s, which can meet the requirements of real-time pedestrian detection in low-visibility scenes.
Deep learning-based object detection algorithms have matured considerably. However, detecting novel classes based on a limited number of samples remains challenging as deep learning can easily lead to feature space degradation under few-shot conditions. Most of the existing methods employ a holistic fine-tuning paradigm to pretrain on base classes with abundant samples and subsequently construct feature spaces for the novel classes. However, the novel class implicitly constructs a feature space based on multiple base classes, and its structure is relatively dispersed, thereby leading to poor separability between the base class and the novel class. This study proposes the method of associating a novel class with a similar base class and then discriminating each class for few-shot object detection. By introducing dynamic region of interest headers, the model improves the utilization of training samples and explicitly constructs a feature space for new classes based on the semantic similarity between the two. Furthermore, by decoupling the classification branches of the base and new classes, integrating channel attention modules, and implementing boundary loss functions, we substantially improve the separability between the classes. Experimental results on the standard PASCAL VOC dataset reveal that our method surpasses the nAP50 mean scores of TFA, MPSR, and DiGeo by 10.2, 5.4, and 7.8, respectively.
This study proposes a deep learning-based color hologram reconstruction method to address the issues of complex reconstruction operations, inaccurate color fusion, and zero-order influence during the reconstruction of large objects. The improved U-Net model is used as the network structure, and the spectrum of color off-axis Fresnel holograms generated by mixing actual photography and simulation is used as training samples to achieve the accurate reconstruction of color holograms. Reconstruction experiments are conducted on simulated holograms and actual digital holograms. Moreover, the results have shown that compared to traditional methods, the proposed method can maintain high resolution and color accuracy of the reconstructed image while achieving improved reconstruction results. The outcomes of the study have potential applications in the reconstruction of color holograms in large-scale inspection fields, and are useful for the application of color holographic detection and deep learning in the field of optical imaging.
A computer-generated hologram (CGH) can be used to detect an aspheric surface with high accuracy. To enhance the encoding efficiency of the CGH, this paper proposes an encoding method for the segmented description of engraved stripes with a circular arc as the primitive, dividing the encoding process into two steps: binary encoding and curve description. The binary encoding employs the Newtonian iteration method to discretize the phase contour dividing line. The curve description combines the dichotomy and the minimum root-mean-square criterion of the residual error. Furthermore, by leveraging the circular arc to encode the discrete points of the engraved stripes, the engraved stripes are obtained. In this paper, the CGH is designed, encoded, and generated for an off-axis aspheric surface. To obtain an encoding accuracy higher than λ/1000, the operation time is only 3 h, the encoded file is only 39 MB, and the etching time is only 40 min. This demonstrates that the proposed method can considerably enhance the encoding efficiency compared with the traditional encoding method. Error analysis suggests that the wavefront root-sum square (RSS) error of the CGH is only 0.00255λ, demonstrating that the proposed encoding method is efficient and feasible.
This study presents a localization method based on the improved iterative closest point (ICP) algorithm to solve the localization problems of mobile robots, such as low positioning accuracy and poor real-time positioning, in traditional 2D environments. The algorithm begins by establishing a pose search space, which systematically explored layer-by-layer, transitioning from lower to higher resolutions. To accelerate the search process and eliminate nonoptimal poses, partial point cloud scanning matching was executed synergistically with multipoint cloud density. Adoption of the frame-to-image method by the point cloud matching enabled the effective utilization of historical frame information. Further enhancements in positioning accuracy were achieved through the sparse matrix pose optimization for obtained optimal pose. Tests conducted on the SLAM Benchmark dataset show that the proposed algorithm is considerably more efficient, boasting a 1.8‒4.9 times efficiency gain over the popular Cartographer algorithm, and has less translation error. Real-world tests conducted on Turtlebot2 reveal that the proposed method exhibits substantially fewer positioning errors than Cartographer and Gmapping, showing superior real-time performance. Compared with the traditional adaptive Monte Carlo relocation (AMCL), the proposed method reduces mean translation errors by 0.035 m and mean rotation errors by 0.001 rad, resulting in higher relocation accuracy.
A parallelizable incremental structure from motion (SFM) recovery reconstruction algorithm is employed to address low efficiency and susceptibility to scene drift when reconstructing large-scale unmanned aerial vehicle image datasets. First, the vocabulary tree image retrieval results are used to constrain the spatial search range and improve the efficiency of image feature matching. Second, by considering the feature matching number and the global positioning system (GPS) information obtained by the drone platform, an undirected weighted scene map is constructed, and a normalized cut algorithm is selected to divide the scene map into multiple overlapping subsets. Further, each subset is distributed on multicore central processing units (CPUs), and the incremental SFM reconstruction algorithm is executed in parallel. Finally, based on the strategy of common reconstruction points between subsets and priority merging of strongly correlated subsets, subset merging is achieved. In addition, combining GPS information to add positional constraints to the beam adjustment (BA) cost function eliminates the errors introduced by each BA optimization execution. To verify the effectiveness of the algorithm, experiments are conducted on three unmanned aerial vehicle datasets. The experimental results show that the proposed algorithm not only significantly improves the efficiency of pose estimation and scene reconstruction compared with the original incremental SFM reconstruction algorithm but also reasonably optimizes the accuracy of the reconstruction results.
Imaging resolution of the ptychography is limited by the numerical aperture and CCD (charge coupled device) pixel size. When the CCD target surface is limited, the numerical aperture is limited, and the high-frequency information of the edge of the CCD target surface is easy to miss under the condition that the collected spot is large. In addition, the larger pixel size leads to insufficient sampling rate during imaging, and some detailed high-frequency information will be lost. We propose a high-resolution ptychography method, which can simultaneously solve the resolution problem limited by the numerical aperture and CCD pixel size. First, the extrapolation method is used to supplement the higher-order diffraction information lost due to the limited numerical aperture, and the image reconstructed by the extrapolation method is substituted into the generative adversarial network based on the multi-weight loss function, which can quickly solve the problem of pixel size limitation and improve the imaging resolution. The multi-weight loss function is the weighted sum of mean square error, feature map error and adversarial error. By setting reasonable weights, the pixel and visual level can be balanced. The simulation and experimental results show that this method has a significant effect on improving the resolution of the ptychography and has high computational efficiency.
We propose a 3D point cloud semantic segmentation algorithm based on density awareness and self-attention mechanism to address the issue of insufficient utilization of inter point density information and spatial location features in existing 3D point cloud semantic segmentation algorithms. First, based on the adaptive K-Nearest Neighbor (KNN) algorithm and local density position encoding, a density awareness convolutional module is constructed to effectively extract key density information between points, enhance the depth of information expression of initial input features, and enhance the algorithm's ability to capture local features. Then, a spatial feature self-attention module is constructed to enhance the correlation between global contextual information and spatial location information based on self-attention and spatial-attention mechanisms. The global and local features are effectively aggregated to extract deeper contextual features, enhancing the segmentation performance of the algorithm. Finally, extensive experiments are conducted on the public S3DIS dataset and ScanNet dataset. The experimental results show that the mean intersection over union of our algorithm reaches 69.11% and 72.52%, respectively, shows significant improvement compared with other algorithms, verifying the proposed algorithm has good segmentation and generalization performances.
Rapid identification and precise positioning of surrounding targets are prerequisites and represent the foundation for safe autonomous vehicle driving. A point cloud 3D object detection algorithm based on an improved SECOND algorithm is proposed to address the challenges of inaccurate recognition and positioning in voxel-based point cloud 3D object detection methods. First, an adaptive spatial feature fusion module is introduced into a 2D convolutional backbone network to fuse spatial features of different scales, so as to improve the model's feature expression capability. Second, by fully utilizing the correlation between bounding box parameters, the three-dimensional distance-intersection over union (3D DIoU) is adopted as the bounding box localization regression loss function, thus improving regression task efficiency. Finally, considering both the classification confidence and positioning accuracy of candidate boxes, a new candidate box quality evaluation standard is utilized to obtain smoother regression results. Experimental results on the KITTI test set demonstrate that the 3D detection accuracy of the proposed algorithm is superior to many previous algorithms. Compared with the SECOND benchmark algorithm, the car and cyclist classes improves by 2.86 and 3.84 percentage points, respectively, under simple difficulty; 2.99 and 3.89 percentage points, respectively, under medium difficulty; and 7.06 and 4.27 percentage points, respectively, under difficult difficulty.
During camera calibration process based on a circular calibration board, when the lens distortion is large, the image quality decreases, and the circular projection edge becomes blurry, resulting in calibration errors. Accordingly, a high-precision camera technique based on subpixel edge detection and center correction compensation is proposed. First, the Canny-Zernike moment method was used to extract subpixel-level circular feature contour points. Moreover, edge point chains were used to connect independent contour points to obtain closed-loop accurate feature contours, enhancing the ability to extract fuzzy edge contours. Second, the inner and outer contours were sampled separately, and points were taken to fit the ellipse. The mean of the two centers was used as the feature points, and an ordered feature point set was obtained through the three-point judgment sorting method for rough calibration. Finally, the rough calibration parameters were used to calibrate the sampling point set of the contour, and the center coordinates were reobtained before backprojection onto the image for precise camera calibration, achieving center correction compensation calibration under distortion. The experimental results show that the proposed method effectively improves the accuracy of camera calibration when the lens distortion is large.
Lensless imaging systems use masks instead of lenses, reducing costs and making equipment lighter. However, before object recognition, reconstructing an image is necessary. This reconstruction involves parameter tuning and time-consuming calculations. Hence, a reconstruction-free object recognition scheme, which directly trains networks to recognize objects on encoded images captured via lensless cameras, that saves computing resources and protects privacy, is proposed herein. Using lensless cameras with a phase mask and an amplitude mask, the real MNIST dataset is collected and the simulated MNIST and Fashion MNIST datasets are generated. Subsequently, the ResNet-50 and Swin_T networks are trained on these datasets for object recognition. The results show that with respect to the simulated MNIST, Fashion MNIST, and real MNIST datasets, the highest recognition accuracy achieved by the proposed scheme is 99.51%, 92.31%, and 98.06%, respectively. These accuracies are comparable to those achieved by the reconstructed object recognition scheme, proving that the proposed scheme is an efficient end-to-end scheme that provides privacy protection. Moreover, the proposed scheme is verified using two types of masks and two types of conventional backbone classification networks.
The study of the jamming effects on visible-light imaging systems irradiated by supercontinuum spectrum lasers has vast potential applications. Focusing on the jamming effect of the supercontinuum spectrum laser, experiments were conducted to analyze its interference on visible-light imaging systems under varying radiation brightness backgrounds. A white-light fiber laser was utilized to generate a supercontinuum spectrum interference source, and an experimental system was constructed to evaluate the jamming effects of the supercontinuum spectrum laser on visible-light imaging systems. Jamming threshold data for detectors at different irradiance intensities were obtained, along with a mathematical relationship model between the detector's saturation pixel number and the jamming laser's power density. Results indicate that the detector's saturation pixel number is approximately logarithmically linear in relation to the interference laser' power density. Additionally, the visible-light imaging system is more vulnerable to interference when operating under low-irradiance backgrounds. These experimental findings provide valuable insights for designing, demonstrating, and operating supercontinuum spectrum laser jamming equipment.
The pulse-dilation framing camera, with a short magnetic focus, is a two-dimensional, ultrafast diagnostic device with a long drift region. It evaluates the paraxial spatial resolution and detection area by the point spatial resolution of the on-axis and off-axis, respectively. However, because of the spatial nonuniformity of the Gaussian image plane caused by the field curvature, the overall spatial resolution of the camera is difficult to evaluate. Therefore, this study proposes a new method to quantify the spatial resolution of a pulse-dilation framing camera. The proposed method is based on a model constructed using the COMSOL software. In this model, the three-dimensional imaging surface is reconstructed based on the characteristics of the field curvature. The degree of deviation between the imaging surface and the Gaussian image plane is analyzed by standard deviation (SD), and the spatial resolution of the Gaussian image plane is obtained by combining the point spatial resolution and the overall modulation. The spatial resolution uniformity of the Gaussian image plane is quantified using relative error. The results of our study show that, when the lens aperture is 200 mm, slit width is 10 mm, axial width is 100 mm, length of drift region is 400 mm, imaging radius is 21 mm, and the cathode voltage is -3.75 kV, with the change in magnetic field, the degree of deviation between the imaging surface and the Gaussian image plane, and the spatial resolution of the Gaussian image plane both have an upward parabolic shape. When the imaging magnetic field is 41.97 Gs (1 Gs=10-4 T), the SD of the deviation of the two image planes is minimized to 2.82 mm, the spatial resolution of the Gaussian image plane is optimal at 292.80 m, and the modulation difference characterizing the spatial uniformity is minimized to 330%. In conclusion, this study proposes a quantifiable reference method for evaluating the optimal spatial resolution performance of a pulse-dilation framing camera with a short magnetic focus.
As crucial constraints of ptychography, the richness and accuracy of diffraction patterns directly affect the quality of reconstruction images. This paper proposes a high-dynamic-range ptychography using maximum likelihood noise estimation (ML-HDR). Herein, assuming the linear response of the detector, a compound Gaussian noise model is established; the weight function is optimized according to the ML estimation; and a high signal-to-noise ratio diffraction pattern is further synthesized from multiple low dynamic range diffraction patterns. The reconstruction quality of single exposure, conventional HDR, and ML-HDR is compared. The simulation and experiment results show that ML-HDR can widen the dynamic range by 8 bits and enhance the reconstruction resolution by 2.83 times compared with the single exposure. Moreover, compared with conventional HDR, ML-HDR can enhance the contrast and uniformity of the reconstruction image in the absence of additional hardware parameters.
Cracks are one of the main road surface diseases, and timely and effective crack detection and evaluation are crucial for road maintenance. To achieve fast and accurate semantic segmentation of road crack images, a road crack detection method based on the DeepLabv3+ model is proposed. To reduce the number of model parameters and improve inference speed, MobileNetv3 is used as the model's backbone feature extraction network, and Ghost convolution is used instead of ordinary convolution in the atrous spatial pyramid pooling module to make the model lightweight. To avoid degrading model accuracy by replacing the backbone network, the following measures are adopted. First, a strip pooling module is used in the atrous spatial pyramid pooling module to effectively capture the contextual information of crack structures while avoiding interference from irrelevant regional noise. Second, a lightweight channel attention mechanism, the effective channel attention (ECA) module, is introduced to enhance the feature expression ability, and a shallow feature fusion structure is designed to enrich the image's detailed information, optimizing the model's crack recognition effect. Finally, a mixed loss function is proposed to address the issue of low detection accuracy caused by imbalanced categories in the crack dataset, and transfer learning training is used to improve the model's generalization ability. The experimental results show that the proposed road crack detection model's parameters are only 14.53 MB, which is 93.04% less than the original model parameters, and the average frame rate reaches 47.18, meeting the requirements of real-time detection. In terms of accuracy, the intersection to union ratio and F1 value of this model's crack detection results are 57.21% and 72.76%, respectively, which are superior to classic DeepLabv3+, PSPNet, and U-Net models, as well as advanced FPBHN, ACNet, and other models. The proposed method can significantly reduce the number of model parameters while maintaining road crack detection accuracy and meeting real-time requirements, thus laying the foundation for online detection of road cracks based on semantic segmentation.
A water contact angle measurement method based on the improved Faster RCNN is proposed to address the issues of low accuracy and poor reproducibility caused by manual intervention in traditional water contact angle measurement processes. First, the Faster RCNN backbone network VGG16 was replaced with ResNet101, and the attention mechanism model convolutional block attention module (CBAM) was added at the end of its residual block to enhance the network's ability to extract features. Second, the feature pyramid network (FPN) was incorporated to fully extract feature information at different scales, and the Focal loss function was introduced to solve the problem of imbalanced positive and negative class samples. Finally, edge detection and corner extraction were performed on the located water droplets, and then the iterative reweighted least squares (IRLS) method was used to fit the elliptical contour to calculate the contact angle angle. The experimental results show that the improved Faster RCNN object detection algorithm improves mean average precision by 10.794% and speed by 11 frame/s over the original algorithm. The average standard deviation of contact angle angle measurements is 0.109°.
Identifying the age of ancient bronze vessels requires many relevant historical materials, takes a long time, and has strong subjectivity. We propose a new approach to assist archaeologists in analyzing and dating ancient bronze artifacts. The proposed method applies deep learning methods for age discrimination of ancient bronze artifacts based on image classification pre training weights. First, through multiple basic experiments, EfficientNetV2-L with good discrimination results is selected as the baseline model from four representative network models. Thereafter, EfficientNetV2-L is used to extract features from the ancient bronze ware dataset, and then, the original linear classification layer is replaced with cosin_classifier to reduce the risk caused by variance and improve the model's discrimination ability. Finally, the focal loss function is introduced to replace the original cross entropy loss function for loss calculation. Under the influence of the focusing parameter and class weighting factor, the poor model learning performance caused by a small number of samples and categories is effectively reduced. The proposed method improves the accuracy, precision, recall, F1 score, and area under the curve by 4.1 percentage points, 4.0 percentage points, 4.1 percentage points, 4.2 percentage points, and 0.9 percentage points, respectively, compared to the original EfficientNetV2-L, achieving an optimal accuracy of 91.7% on the test set. Additionally, a model prediction analysis is conducted on controversial bronze artifacts with different stages. The results indicate that deep learning technology is effective in identifying the age of ancient bronze ware datasets, providing reference analysis data and reducing the workload of archaeological experts.
To detect passengers' abnormal behavior in real time, we propose a lightweight escalator passenger' abnormal behavior real-time detection algorithm, YOLO-STE, based on YOLOv5s. First, a lightweight ShuffleNetV2 network was introduced in the backbone network to reduce the number of parameters and its computation. Second, a C3TR module based on Transformer encoding was introduced in the last layer of the backbone network to better extract rich global information and fuse features at different scales. Finally, an SE (Squeeze-and-excitation) attention mechanism was embedded in the feature fusion network of YOLOv5s to better focus on the main information and improve the model accuracy. We developed our dataset and conducted experiments. The experimental results demonstrate that compared with the original YOLOv5s, the mean Average Precision (mAP) of the improved algorithm is 1.9 percentage points higher, reaching 96.1%, and the model size is reduced by 70.8%. Moreover, the improved algorithm's forward propagation time is 39.9% shorter than that of the original YOLOv5s model when deployed and tested on the Jetson Nano hardware. Compared with the original YOLOv5s model, the improved algorithm can better achieve real-time detection of abnormal behavior of escalator passengers, which can better ensure the safety of passengers riding the escalator.
To address the high cost of detection equipment and slow detection speed of traditional algorithms for detecting point defects in laser soldering on the production line, we propose an improved YOLOv5s algorithm that can directly detect defects on the laser soldering equipment. By introducing GhostNetV2 convolution mechanism, the backbone network is lightweight improved, the parameter quantity of the original network model reduced and the detection speed increased. Simultaneously, omni-dimensional dynamic convolution module is used to improve both the feature extraction capability and detection accuracy of the model. The experimental results show that the improved YOLOv5s model has a reduced network parameter quantity of 23.89% compared to the original model. The mean average precision of improved model reached 95.0% on the self-made laser soldering point defect dataset and validation set, reflecting a 1 percentage point improvement over the original model. The detection rate increased by 12.62 frame/s on the experimental platform compared to the original model. Finally, the proposed algorithm is deployed on the laser soldering equipment and can detect corresponding soldering defects at a running speed of 42.2 frame/s, basically meet the real-time welding defect detection needs of laser soldering.
To address the challenges faced in the real-time detection of small-size rockfalls in open-pit mines during the transportation of ores using unmanned carts owing to suboptimal road conditions, intense lighting, and heavy dust, this study proposes a method for detecting small-size rockfalls in open-pit mines based on solid-state lidar. The proposed method employed a double-echo lidar for data acquisition, effectively reducing dust interference and extracting the driving area in front of the vehicle. Subsequently, a ground segmentation algorithm (straight-line fitting) based on fan surfaces was employed to segment the rough and unstructured terrains having slopes. Moreover, a hierarchical grid tree model known as octree was introduced to enhance the efficiency of neighborhood search. Furthermore, the two-color nearest pair method was applied to construct a graph, rapidly generating the clusters. Finally, the concept of adaptive clustering radius ε was adopted for clustering and obtaining the box models of small-size rockfalls. The experimental results demonstrate that the proposed method outperforms the k-d tree-accelerated DBSCAN algorithm, increasing the positive detection rate by 9.61 percentage points and reducing the detection time by 379.77 ms.
A 3D object detection method based on improved PointPillars model is proposed to address the problem of poor detection performance of small objects in current point cloud based 3D object detection algorithms. First, the pillar feature network in the PointPillars model is improved, and a new pillar encoding module is proposed. Average pooling and attention pooling are introduced into the encoding network, fully considering the local detailed geometric information of each pillar module, which improve the feature representation ability of each pillar module and further improve the detection performance of the model on small targets. Second, based on ConvNeXt, the 2D convolution downsampling module in the backbone network is improved to enable the model extract rich context semantic information and global features during feature extraction process, thus enhancing the feature extraction ability of the algorithm. The experimental results on the public dataset KITTI show that the proposed method has higher detection accuracy. Compared with the original network, the improved algorithm has an average detection accuracy improvement of 3.63 percentage points, proving the effectiveness of the method.
A YOLOv8-based defect detection algorithm, YOLOv8-EL, is proposed to address the problems of false detection and missing detection caused by data imbalance, varied defect scales, and complex background textures in photovoltaic (PV) cell defect detection. First, GauGAN is used for data augmentation to address the issue of intra-class and inter-class imbalance, improve model generalization ability, and reduce the risk of overfitting. Second, a context aggregation module is embedded between the backbone network and the feature fusion network to adaptively fuse semantic information from different levels, align local features, reduce the loss of minor defect information, and suppress irrelevant background interference. Finally, a multi-attention detection head is constructed to replace the decoupling head, introducing different attention mechanisms to refine classification and localization tasks, extract key information at the spatial and channel levels, and reduce feature confusion. Experimental results show that the proposed model achieves an average precision of 89.90% on the expanded PV cell EL dataset with a parameter count of 13.13×106, achieving both precision improvement and lightweight deployment requirements. Generalization experiments on the PASCAL VOC dataset demonstrate the improved algorithm's generalization performance.
Regarding the deficiency of traditional deformation monitoring in effectively detailing deformation of local unique monitoring objects due to the overall deformation model, this paper proposes a three-layer mixed deformation model, i.e., block, region, and overall deformation, based on terrestrial 3D laser scanning technology. A block-based deformation calculation method is also designed. This method mainly includes object segmentation, deformation estimation, and deformation fusion, and can automatically extract deformation information of different scales without prior monitoring information. Simulation results show that under this method, the mean angle change estimation error of RANSAC algorithm plane fitting regression is 1.21″, and the estimation reliability increases with an increase in block size within a certain range. The results of the landslide experiment show that the minimum value method has less displacement estimation noise, and a 0.2 m block size segmentation can provide further deformation estimation details. The proposed method is particularly suitable for monitoring fields with nonuniform deformation characteristics, and has certain theoretical and practical significance for promoting the transformation of disaster monitoring from"point monitoring"to"surface monitoring"for landslides and other disasters that are difficult for personnel to reach.
Image matching, which refers to transforming the image to be matched into the coordinate system of the original image, plays important roles in numerous visual tasks. The feature-based image matching method, which can find distinctive features in the image, is widely accepted because of its applicability, robustness, and high accuracy. For improving the performance of feature matching, it is important to obtain more feature matches with high matching accuracy. Aiming at the sparse matching problem of the traditional feature matching algorithm, we propose a dense feature matching method based on the improved deep feature matching algorithm. First, a series of feature maps of the image are extracted through the VGG neural network, and nearest-neighbor matching is performed on the initial feature map to calculate the homography matrix and perform perspective transformation. Then, deep features are fused according to the frequency-domain matching characteristics of feature maps for coarse feature matching. Finally, fine feature matching is performed on the shallow feature map to correct the results of coarse feature matching. Experimental results indicate that the proposed algorithm is superior to other methods, as it obtains a larger number of matches with a higher matching accuracy.
Chlorophyll fluorescence detection technology is widely used as a nondestructive detection method; however, the frequency band of the step pulse or the modulated pulse (PAM) used in the traditional chlorophyll fluorescence detection technology to excite signals is narrow, and a photosynthetic system is a high-order broadband system, which is difficult to excite all the dynamic characteristics. These limit the information richness contained in chlorophyll fluorescence signals. Currently available commercial chlorophyll fluorescence meters do not contain broadband excitation. The absence of this function limits the ability of emerging artificial intelligence algorithms to process complex signals for mining rich information. Thus, in this study, we developed a chlorophyll fluorescence instrument with a broadband excitation function based on the pseudorandom binary sequence (PRBS) signal. The developed instrument can measure the traditional chlorophyll fluorescence induction OJIP and PAM kinetics. The information entropy of chlorophyll fluorescence of five different plants under three different light sources confirmed that the chlorophyll fluorescence excited by PRBS has the highest information entropy. In addition, the instrument can provide chlorophyll fluorescence signals with more information and is expected to contribute to a new scientific instrument for detecting plant physiology and environmental stress.
At present, it is highly subjective for pathologists to identify breast cancer cells in pathological cut images of breast cancer under microscope field of view by naked eyes. Therefore, we design a microscopic image based breast cancer cell recognition system, which includes microscopic image acquisition module and breast cancer cell recognition algorithm implementation module. Through USAF 1951 resolution test board, the microscopic image acquisition module of designed breast cancer recognition system is verified, and the final imaging resolution can reach 2.19 μm. In addition, the designed breast cancer cell recognition algorithm is verified by multiple sets of breast cancer pathological images, and the results show that the average accuracy of the designed breast cancer cell recognition system reaches 93.4%.
Currently, popular neural networks not only struggle to accurately recognize various types of surface targets but also tend to introduce significant noise and errors when handling limited samples and weak supervision. Therefore, this study proposes a dual-network remote sensing image classification method based on dynamic weight deformation, after analyzing the features of remote sensing images. By constructing a flexible, simple, and effective weight dynamic deformation structure, we establish an improved classification network and target recognition network. This introduces the self-verification ability of dual network comparison, thereby enhancing learning performance, error correction, recognition efficiency, supplementing omissions, and improving classification accuracy. Experimental comparisons show that the proposed method is easy to implement and exhibits stronger cognitive ability and noise resistance. It confirms the adaptability of the proposed method to various remote sensing image classification tasks and its vast application potential.
To address issues, such as loss of spectral and spatial detail as well as unclear fusion results during the fusion process, a fusion method based on particle swarm optimization is proposed. The initial step of this method involves preprocessing the original image to derive edge detection matrices for each of the image's channels. Subsequently, the spectral coverage coefficient is determined by employing the least square method to generate a more precise image. Finally, an adaptive injection model framework is proposed, which incorporates a weighted matrix, particle swarm optimization, and error relative global accuracy (ERGAS) index function to optimize the weights for edge detection. The band weights in the dataset are calculated to generate the final fused image. In this study, the performance of five fusion methods is assessed using three remote sensing satellite images of varying resolution (WorldView-2, GF-2, and GeoEye) by quantitatively analyzing six evaluation indicators. The results indicate that the method proposed in this paper outperforms other methods in terms of subjective visual effects and objective quantitative evaluation indicators such as average gradient and spatial frequency. Furthermore, the proposed method realizes a good fusion effect in retaining spectral and spatial information.
A lightweight dual-input change detection network, D-WNet, is proposed to address the issues of traditional semantic segmentation networks being susceptible to interference from shadows and other ground objects, as well as the rough boundary segmentation of buildings. The new network starts with W-Net and uses deep separable convolutional blocks and hollow space pyramid pooling modules to replace the originally cumbersome convolutional and downsampling processes. It utilizes a right-line feature encoder to enhance the fusion of high-dimensional and high-dimensional features and introduces channels and spatiotemporal attention mechanisms in the sampling section of the decoder to obtain effective features of the network in different dimensions. The resulting D-WNet has significantly improved performance. Experiments were conducted on the publicly available WHU and LEVIR-CD building change detection datasets, and the results were compared with the W-Net, U-Net, ResNet, SENet, and DeepLabv3+ semantic segmentation networks. The experimental results show that D-WNet performs well in five indicators (intersection-to-intersection ratio, F1 value, recall rate, accuracy rate, and running time) and has more accurate change detection results for shadow interference and building edge areas.
Environmental perception is a key technology for unmanned driving. However, cameras often lack depth information to locate and detect targets and have poor tracking accuracy; therefore, a target localization and tracking algorithm based on the fusion of camera and LiDAR technologies is proposed. This algorithm obtains the positioning information of the detected target by measuring the proportion of the area of the LiDAR point cloud cluster in the pixel plane within the image detection frame. Subsequently, based on the horizontal and vertical movement speeds of the detected target's contour point cloud in the pixel coordinate system, the center coordinate of the image detection frame is fused to improve the target tracking accuracy. The experimental results show that the accuracy of the proposed target localization algorithm is 88.5417%, and the average processing time per frame is only 0.03 s, meeting real-time requirements. The average error of the horizontal axis of the image detection frame center is 4.49 pixel, the average error of the vertical axis is 1.80 pixel, and the average area overlap rate is 87.42%.
This study proposes an infrared imaging and detection model to address infrared imaging and radiation characteristics of the middle and upper atmospheric background. The applicability of the medium spectral resolution atmospheric radiation transfer mode (MODTRAN) in the infrared band is analyzed, and the strategic high-altitude radiance code (SHARC) is utilized to simulate and analyze the infrared radiation characteristics of the middle and upper atmospheric background under different observation parameters in the 3?5 μm band. Furthermore, a relevant radiation characteristic database is established to complete imaging simulation for infrared radiation scenes in the middle and upper atmospheric background. The results demonstrate that the MODTRAN in the 3?5 and 8?12 μm bands has good computational accuracy at tangent heights below 50 and 70 km, respectively; middle and upper atmospheric background radiance decreases with the increase in the tangent height and solar zenith angle, however, this increases with the observed zenith angle increase; short and long path radiation characteristics are primarily influenced by the path length and atmospheric parameters in the lower atmosphere, respectively; the radiance during the day and night reaches its global maximum at 36 and 34 km, respectively, and local maximum at 75 and 85 km. The results provide theoretical support for the infrared detection of middle and upper atmospheric backgrounds.
To address the issue of incomplete spatial environment information acquisition in traditional two-dimensional (2D) light detection and ranging (LiDAR) mapping, we propose a mapping strategy that leverages the fusion of solid-state LiDAR and 2D LiDAR using the Gmapping algorithm. First, we initiate a planar projection on the solid-state LiDAR point cloud data. Subsequently, the resultant laser data are combined with the optimal particle trajectory within the Gmapping algorithm to construct a grid map. This grid map is then integrated with the grid map carried by the optimal particle, resulting in a fused map designed to identify spatial obstacles. To enhance mapping accuracy, we employe an extended Kalman filter for the dynamic fusion of weights associated with the wheel odometer, laser odometer, and inertial measurement unit. This approach addresses the challenges posed by reduced fusion odometer accuracy in scenarios involving factors such as slippage or feature-matching failures of the laser odometer in environments with limited features. Subsequently, we conducte testing experiments on the fused map and the fusion mileage calculation method. The experimental outcomes demonstrate that the fused map effectively identifies spatial obstacles and the fused odometer exhibits an average positioning accuracy improvement of 17.0% compared to traditional methods.
Diffuse optical imaging is widely used in biomedical research and clinics. Compared with other medical imaging methods, such as magnetic resonance imaging (MRI), X-ray computed tomography (CT), positron emission tomography (PET), and ultrasound imaging, diffuse optical imaging uses diffused light absorbed and scattered by tissues for imaging. This approach is non-invasive and label-free, has a wide field, and quantitatively measures the concentrations of various components such as oxyhemoglobin, deoxyhemoglobin, blood oxygen, water, lipids, and melanin. Furthermore, it collects and assesses tissue functional information. Diffuse optical imaging is advantageous in terms of safety, specificity, and system cost. This article introduces the basic principles of diffuse optical imaging, including the interaction between light and tissue and light propagation models, and summarizes the relevant methods and applications of diffuse optical imaging, including pulse oximetry, diffuse optical spectroscopy, diffuse optical tomography, fluorescence molecular tomography, and spatial frequency domain imaging. Moreover, the prospects for the future development of diffuse optical imaging are presented.
Thyroid nodule is one of the most common clinical nodular lesions in adults, and its incidence rate is always high. Thyroid nodule can be classified into benign and malignant, and the latter is thyroid cancer, which can cause difficulties in breathing and swallowing, and even endanger the life of patients. Therefore, the identification of benign and malignant thyroid nodule is the primary problem in the diagnosis and treatment of thyroid nodule. Deep learning can automatically extract nodule features and complete the preliminary classification of benign and malignant thyroid nodule. With the continuous improvement of classification accuracy of deep learning, it has become an important means of auxiliary diagnosis of benign and malignant thyroid nodule. To better study the classification and auxiliary diagnosis of benign and malignant thyroid nodule, we introduce the commonly used indicators for the evaluation of nodule classification performance, and classify them according to the convolutional neural network, Transformer, deep neural network, generative adversarial network, transfer learning, ensemble learning, and computer-aided diagnosis system based on deep learning, and elaborate their application in the classification of benign and malignant thyroid nodule. We conduct a comprehensive comparative analysis, summarize the existing problems in the current research, and provide prospects for future research directions.
The expansion of high-end products in the tobacco industry and the increasing demand for product quality from consumers have created significant challenges for online tobacco testing technology. In response to problems such as the difficult removal of foreign objects from tobacco production affecting cigarette taste, various complex diseases from tobacco leaves, and difficulty in identifying cigarette packaging defects, traditional manual online detection methods are inefficient and it is difficult to ensure accuracy, which cannot adapt to the high-quality development of China's tobacco industry. From the perspective of elucidating the principle of tobacco online detection based on machine vision, this study systematically elaborates on the research status and latest progress of tobacco online detection technology based on two key aspects: the visual detection principle and deep learning models. Combined with current typical applications, this study analyzes the advantages and limitations of different visual models and deep learning detection methods, and further explores the development trend and prospects of tobacco online detection technology based on machine vision.
Laser imaging radar integrates laser and radar technology, serving as an active photoelectric imaging tool. It boasts high detection accuracy, rich image information, and robust anti-interference capabilities, making it promising in scientific and commercial sectors. As its demand increases, diverse advanced laser imaging radar systems have emerged. This paper outlines the operating principle of this advanced imaging technology, classifies the radar systems, discusses key performances across different classifications globally, compares the advantages and disadvantages of various systems, and concludes with future trends in the technology. This offers insights into the evolution of advanced laser imaging radar technology.